↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Implicit Neural Representations (INRs) have shown promise in various signal reconstruction tasks, but their reliance on single networks for the entire domain limits their efficiency and scalability. Existing methods struggle with high-frequency signals and lack the ability to perform localized operations, hindering their flexibility. Furthermore, parallelization capabilities remain underdeveloped, impacting computation time.
To address these issues, this paper introduces Neural Experts, a novel MoE-based INR architecture. This framework subdivides the input domain, allowing for localized fitting of piecewise continuous functions. The method incorporates a manager network that dynamically routes inputs to the most appropriate expert network, and innovative pretraining and conditioning techniques further optimize the model’s performance and address local minima issues. Extensive evaluation across image, audio, and 3D reconstruction tasks demonstrates significant improvements in accuracy and efficiency compared to standard INRs and other MoE variants.
Key Takeaways#
Why does it matter?#
This paper is important because it presents Neural Experts, a novel and effective method for improving implicit neural representations (INRs). It addresses limitations of existing INRs by introducing a Mixture of Experts (MoE) architecture, leading to faster, more accurate, and memory-efficient reconstruction across diverse tasks. This opens new avenues for research in areas such as localized signal editing and improved scalability of INRs.
Visual Insights#
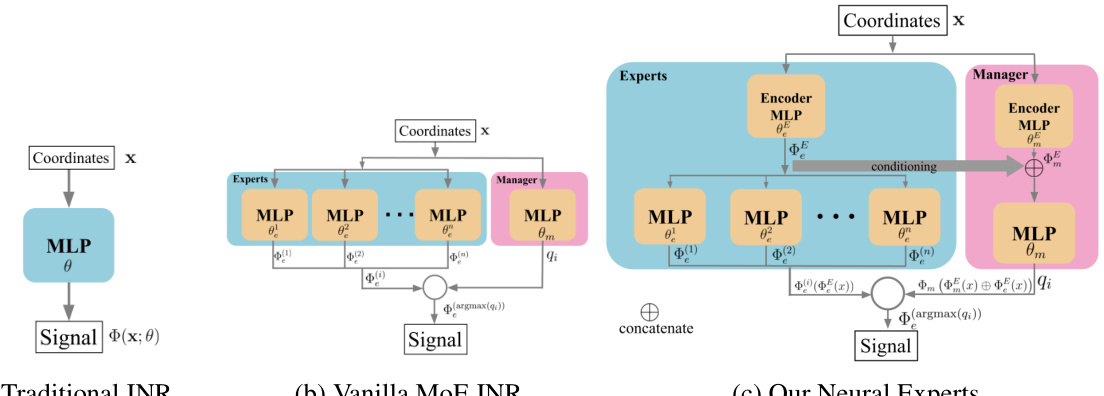
This figure compares three different architectures for implicit neural representations (INRs): a traditional INR using a single MLP, a vanilla MoE INR that naively applies the MoE approach, and the proposed Neural Experts architecture. The key difference in the proposed method is the addition of conditioning and pretraining for the manager network, which significantly improves performance and reduces the number of parameters needed for accurate signal reconstruction. The figure clearly illustrates the flow of information in each architecture.

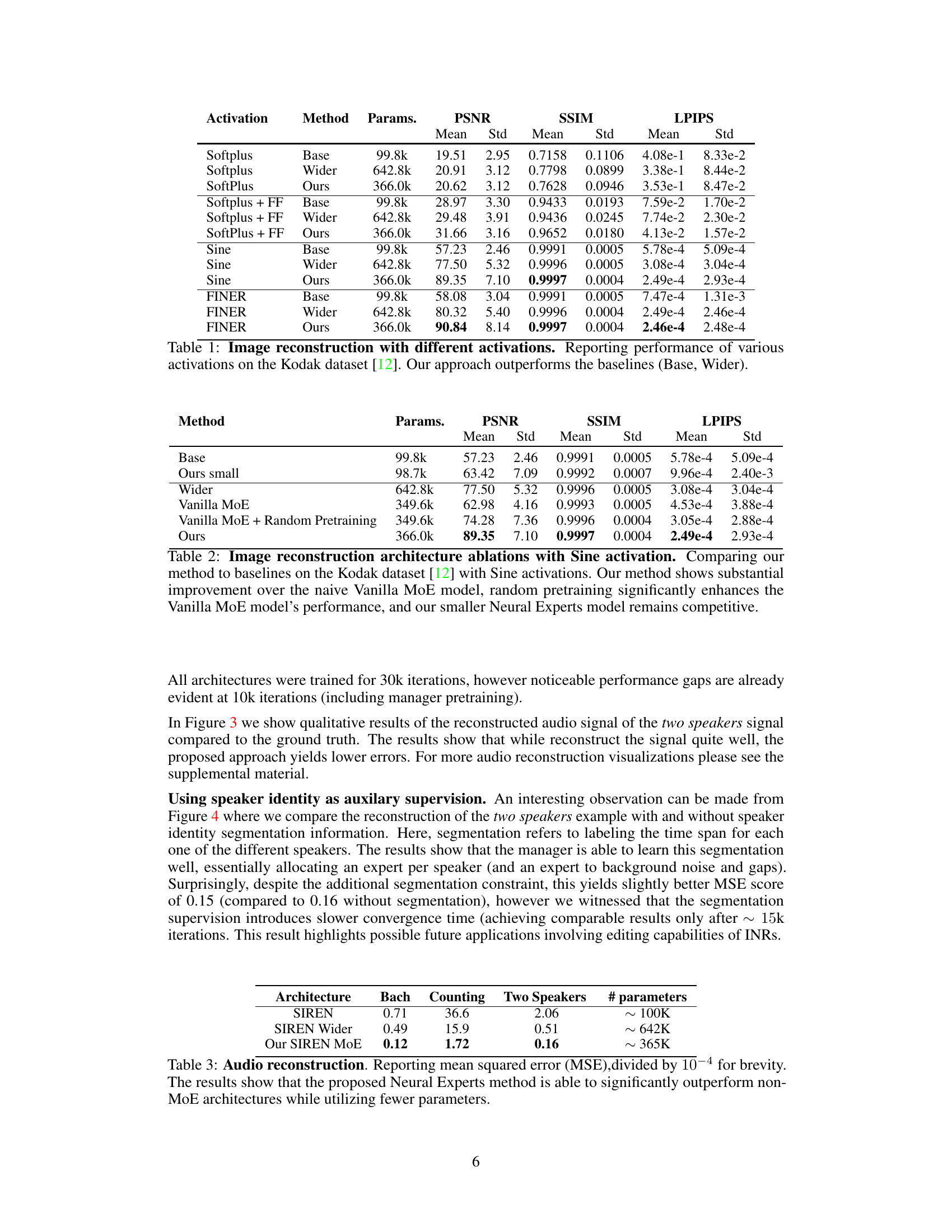
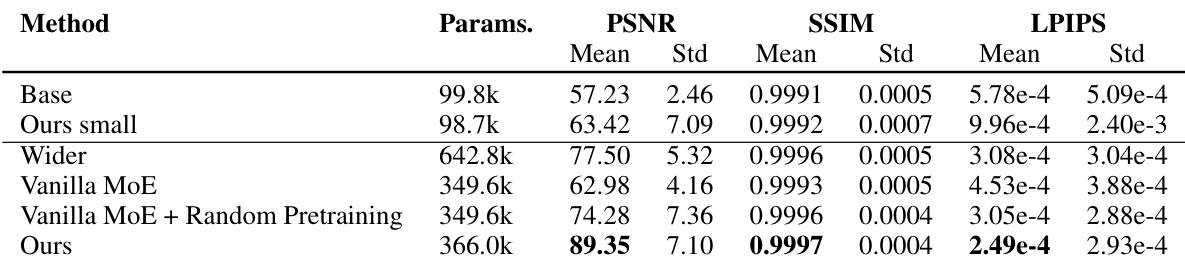
This table compares the performance of different activation functions (Softplus, Softplus+FF, Sine, FINER) on the Kodak image dataset using three different methods: a baseline model, a wider variant with more parameters, and the proposed Neural Experts method. PSNR, SSIM, and LPIPS scores are provided to evaluate image reconstruction quality. The table highlights the superior performance of the Neural Experts method, particularly when compared to the wider baseline, even with fewer parameters.
In-depth insights#
MoE-INR Approach#
The MoE-INR approach presents a novel architecture that significantly improves upon traditional implicit neural representations (INRs). By incorporating a Mixture of Experts (MoE) framework, this method allows for the learning of local, piecewise continuous functions, effectively overcoming limitations of globally-constrained single-network INRs. The key innovation lies in the simultaneous domain subdivision and local fitting, leading to improved speed, accuracy, and memory efficiency. This is achieved through the interaction of expert networks, each specializing in a sub-region of the input space, and a manager network that dynamically routes inputs to the most appropriate expert. The introduction of novel conditioning and pre-training methods for the manager network is crucial, enhancing convergence and avoiding poor local minima. Evaluation across diverse reconstruction tasks (images, audio, 3D shapes) demonstrates superior performance compared to traditional INRs, highlighting the efficacy of this approach for complex signal representation and reconstruction. The method’s flexibility and scalability make it a promising direction for future research in implicit neural representations.
Manager Network#
The Manager Network is a crucial component of the Mixture of Experts (MoE) architecture for Implicit Neural Representations presented in this paper. Its primary role is to dynamically route input coordinates to the most appropriate expert network based on the input’s features. This routing is not predetermined but learned during training, enabling the model to efficiently partition the input space and allocate specialized experts to different regions. The effectiveness of the Manager Network is significantly enhanced by a novel conditioning mechanism, which incorporates information from both the expert encoders and the Manager’s own encoder, thereby improving the quality of its routing decisions. Additionally, a smart pretraining strategy is employed to initialize the Manager Network, ensuring that it starts the training with a balanced expert assignment, preventing potential biases or local minima during optimization. This innovative approach allows the model to efficiently reconstruct signals by combining the strengths of specialized local models and the global overview provided by the Manager Network.
Ablation Studies#
Ablation studies systematically remove or modify components of a model to assess their individual contributions. In the context of a research paper on implicit neural representations, ablation studies might explore the impact of various architectural choices, such as the type of activation function, the number of layers in the network, or the conditioning techniques used. A key aspect would be evaluating the effect of removing the mixture-of-experts (MoE) component; comparing performance against the baseline model (without MoE) to highlight the MoE’s contribution to overall effectiveness. The choice of conditioning methods also warrants careful evaluation via ablation, comparing different ways to combine encoder outputs to determine the optimal configuration for the manager network. Finally, the manager network’s pretraining strategy could be ablated, examining the impact of different initialization and pretraining methods on model convergence and reconstruction accuracy. These analyses reveal the relative importance of different architectural components and training choices, leading to a better understanding of the model’s design principles.
Future Work#
The ‘Future Work’ section of this research paper on Neural Experts for Implicit Neural Representations offers exciting avenues for expansion. Extending the approach to larger-scale models using parallelization techniques is crucial for tackling even more complex and high-dimensional signals. Furthermore, integrating Neural Experts with diffusion models to enable localized signal generation presents a compelling direction for enhanced control and editing capabilities. This would open up possibilities for creative applications such as image and video manipulation. Another promising area lies in exploring the potential of local editing. This could involve developing techniques for selectively modifying specific regions of a signal while preserving the integrity of the overall representation. Finally, investigating applications in diverse fields beyond those considered in the paper, such as medical imaging, scientific visualization, and robotics, could demonstrate the wide applicability and versatility of the Neural Expert architecture.
Limitations#
The research paper’s “Limitations” section, while acknowledging the inherent constraints of the proposed method, could benefit from a more detailed analysis. The discussion of limitations is concise, mentioning the challenges of fitting low-frequency signals with SoftPlus MLPs and the trade-off between training time and the number of experts. However, the impact of these limitations on the overall performance and generalizability of the model across diverse datasets and tasks warrants deeper exploration. For instance, a more thorough investigation into the sensitivity of the model to hyperparameter choices and the impact of variations in input data quality could strengthen the assessment of its robustness. A quantitative analysis of the impact of local minima on model convergence, along with strategies to mitigate this, would enhance the limitations section. Finally, comparing the efficiency and scalability of the proposed method against other state-of-the-art INRs under comparable conditions would offer a valuable benchmark and further clarify the scope and applicability of the “Neural Experts” approach.
More visual insights#
More on figures

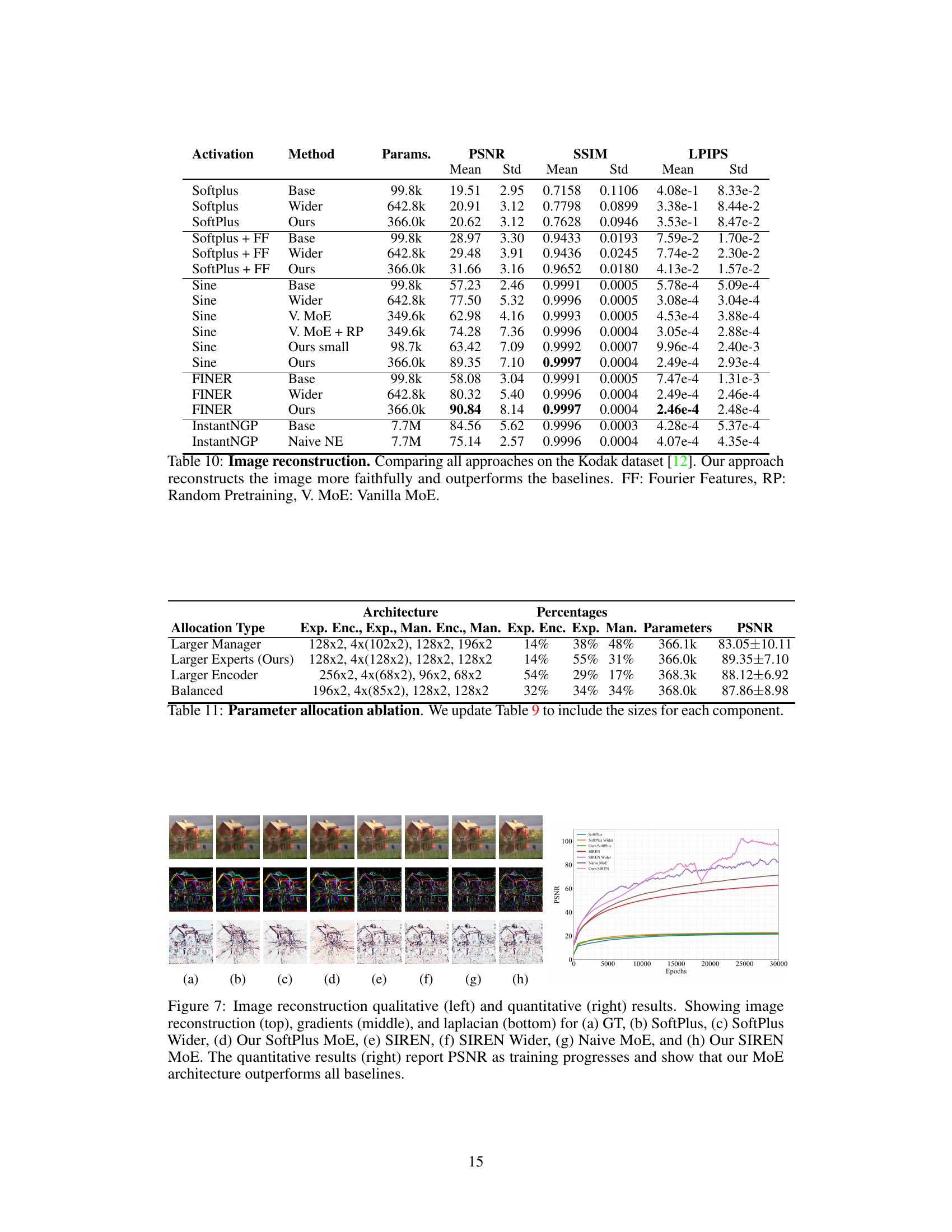
This figure shows a comparison of image reconstruction results using different methods: ground truth (GT), SoftPlus, SoftPlus Wider, SoftPlus MoE (proposed method), SIREN, SIREN Wider, Naive MoE, and SIREN MoE. The left side displays qualitative results showing the reconstructed image, its gradient, and its Laplacian. The right side provides quantitative results showing the Peak Signal-to-Noise Ratio (PSNR) over training epochs. The results demonstrate the superiority of the proposed Neural Experts architecture.

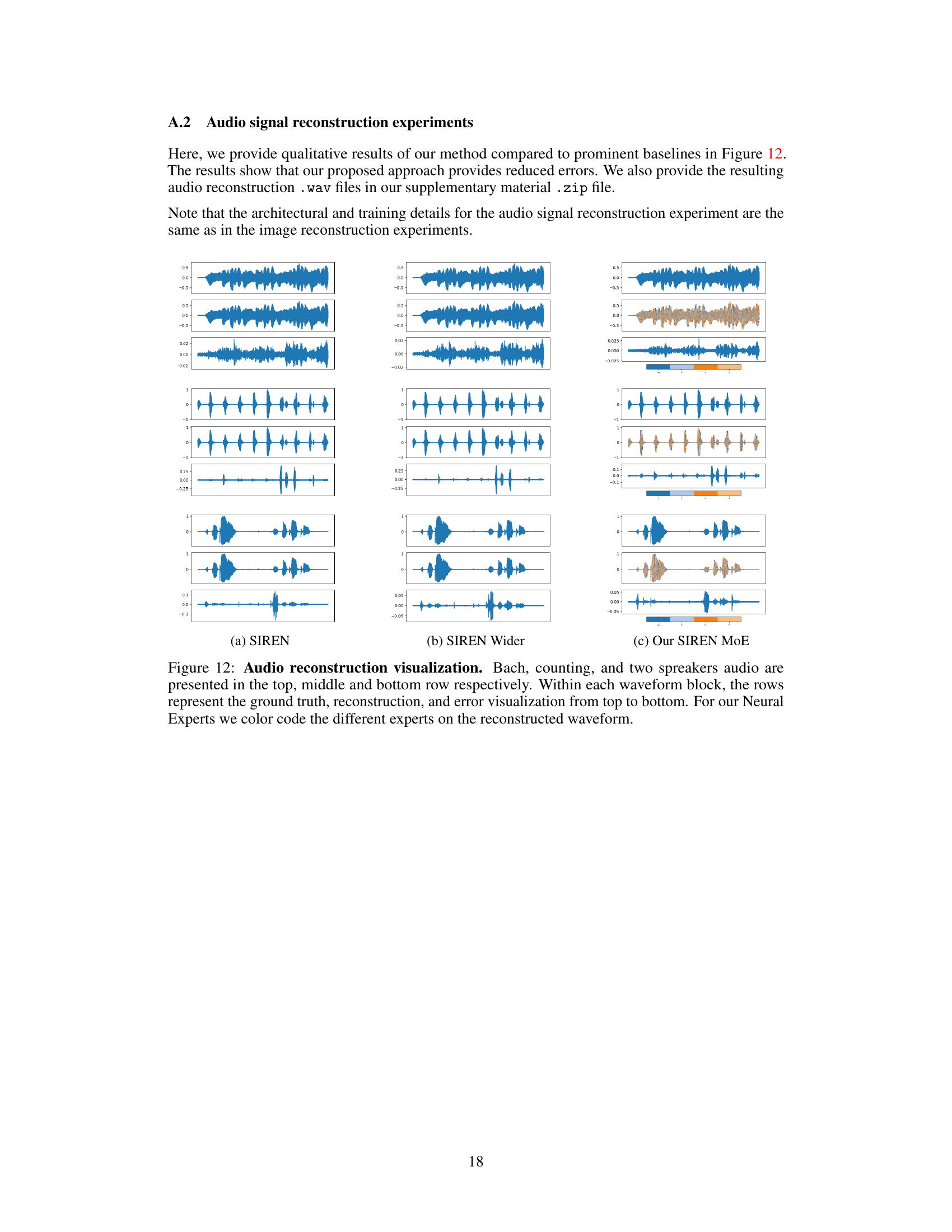
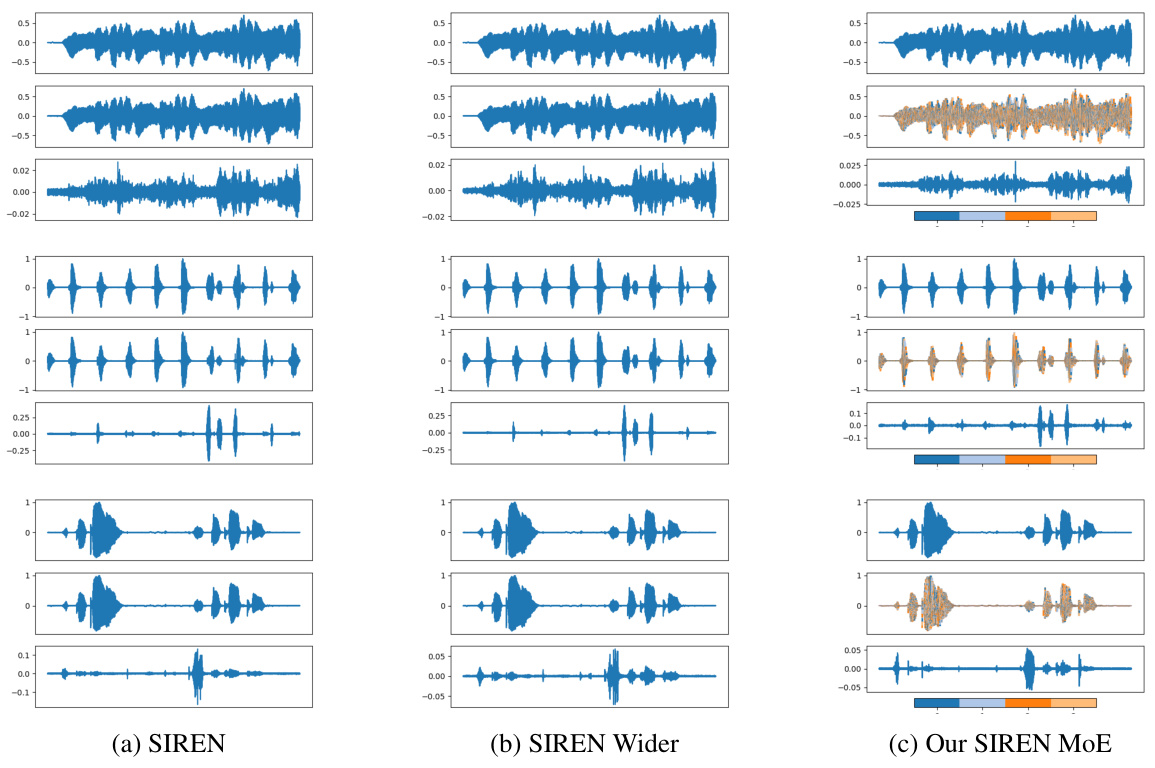
This figure compares audio reconstruction results using three different methods: SIREN, SIREN Wider, and the proposed Neural Experts method. Each method’s reconstruction is displayed alongside the ground truth audio signal for two-speaker audio. The error between the reconstruction and the ground truth is also shown. The Neural Experts method uses color-coding to visually represent different ’experts’ that contribute to the final reconstruction.

This figure visualizes the audio reconstruction results for three different methods: SIREN, SIREN Wider, and the proposed Neural Experts model. Each section shows a waveform block with three rows: the ground truth audio, the reconstructed audio, and the error between the two. The Neural Experts approach uses color-coding to highlight which expert was responsible for reconstructing which parts of the waveform, demonstrating its ability to divide the task among specialized subnetworks.
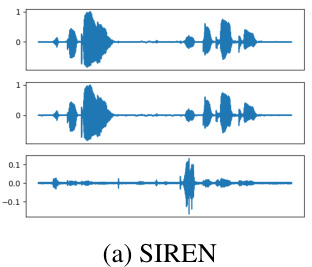
This figure compares the audio reconstruction results from three different methods: SIREN, SIREN Wider, and the proposed Neural Experts model. Each row in the figure shows the ground truth, the reconstruction, and the reconstruction error for a specific audio segment. The color-coding in the Neural Experts reconstruction highlights which expert was responsible for each part of the reconstruction.

This figure visualizes the audio reconstruction results for three different methods: SIREN, SIREN Wider, and the proposed Neural Experts model. Each row in each waveform block represents a different stage: ground truth, reconstruction, and reconstruction error. The Neural Experts model uses different colored lines to represent individual experts in the reconstruction, highlighting the method’s ability to partition the signal and reconstruct the components separately.

This figure visualizes the audio reconstruction results for three different methods: SIREN, SIREN Wider, and the proposed Neural Experts method. Each section shows three waveforms: ground truth, reconstruction, and error. The Neural Experts section highlights the contribution of individual experts by color-coding their respective parts of the reconstruction. This demonstrates the method’s ability to divide the audio signal into meaningful sub-regions and process each sub-region independently.
This figure shows a comparison of 3D surface reconstruction results between the proposed Neural Experts method and a SIREN baseline on the Thai Statue shape. Three visualizations are provided: the output mesh (reconstructed surface), an error colormap highlighting reconstruction errors, and a final expert segmentation illustrating how different parts of the shape were handled by different experts in the MoE architecture. The Neural Experts method is shown to reconstruct finer details and exhibit fewer large errors compared to the SIREN model, showcasing the effectiveness of the proposed approach in capturing complex geometric structures. The colormap visually demonstrates the distribution of errors, and the expert segmentation highlights the spatial division of labor among experts, indicating localized modeling of the shape.

This figure visualizes the expert selection process during pretraining and after full training for different pretraining methods. Each column represents a different pretraining method: None, SAM, Kmeans, Grid, and Random. The top row shows the expert selection before any training on the reconstruction task, while the bottom row shows the final expert selection after training. Each color represents the region assigned to a specific expert. The figure demonstrates how different pretraining strategies lead to different initial expert assignments and how these assignments evolve during the training process. The differences highlight the influence of pretraining on the final segmentation of the input space and potentially the performance of the reconstruction.
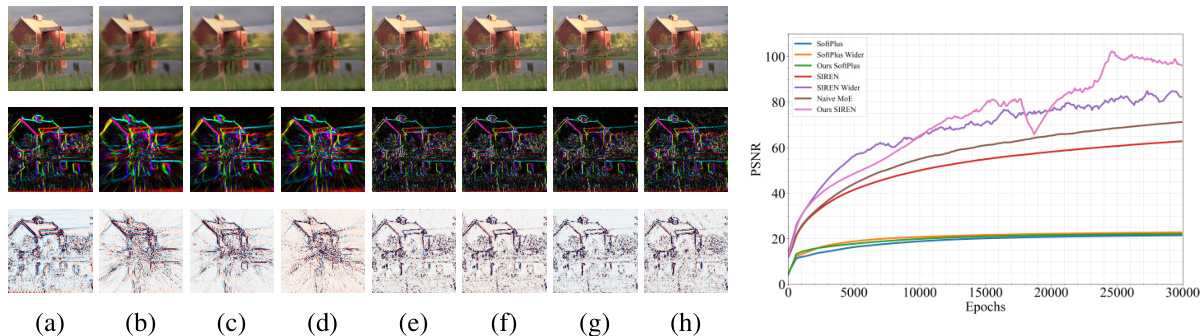
This figure shows a comparison of image reconstruction results using different methods. The left side displays qualitative results, showing the reconstructed image, its gradient, and its Laplacian for each method. The right side shows a quantitative comparison based on PSNR (Peak Signal-to-Noise Ratio) over training epochs. The results demonstrate that the proposed ‘Neural Experts’ approach, particularly with Sine activations, significantly outperforms existing baselines in image reconstruction.

This figure presents a comparison of image reconstruction results using different methods: ground truth (GT), SoftPlus, SoftPlus Wider, SoftPlus Mixture of Experts (MoE), SIREN, SIREN Wider, Naive MoE, and SIREN MoE. Both qualitative (image, gradients, Laplacian) and quantitative (PSNR over training epochs) results are shown. The quantitative results demonstrate the superior performance of the proposed Neural Experts approach, particularly when using Sine activations.

This figure shows a comparison of image reconstruction results between different methods: ground truth (GT), SoftPlus, SoftPlus Wider, SoftPlus MoE (Mixture of Experts), SIREN, SIREN Wider, Naive MoE, and SIREN MoE. Qualitative results (left) display the reconstructed images, their gradients, and Laplacian matrices for each method. Quantitative results (right) show the Peak Signal-to-Noise Ratio (PSNR) over training epochs. The results demonstrate that the Neural Experts architecture using Sine activations achieves superior performance.

This figure compares image reconstruction results of different methods, including the proposed Neural Experts. Qualitative results in the left panel show reconstructed images, their gradients, and Laplacians (a measure of image sharpness). The right panel shows the quantitative comparison using PSNR (Peak Signal-to-Noise Ratio) for several models with different activation functions. The proposed method achieves the highest PSNR, demonstrating its superior performance in image reconstruction.

This figure shows a comparison of image reconstruction results using different methods: ground truth (GT), SoftPlus, SoftPlus Wider, SoftPlus Mixture of Experts (MoE), SIREN, SIREN Wider, Naive MoE, and SIREN MoE. The left side displays qualitative results showing the reconstructed image, its gradients, and its Laplacian. The right side shows quantitative results, specifically the Peak Signal-to-Noise Ratio (PSNR) over training epochs. The results demonstrate that the proposed Neural Experts architecture, particularly with Sine activations, achieves superior performance.
This figure compares three different architectures for implicit neural representations (INRs). (a) shows a traditional INR using a single multi-layer perceptron (MLP). (b) illustrates a naive mixture-of-experts (MoE) approach, where multiple experts are used but without the crucial conditioning and pretraining of the manager network proposed in the paper. (c) presents the authors’ proposed ‘Neural Experts’ architecture, which incorporates a conditioned and pretrained manager network to significantly improve performance. The key improvements in (c) are highlighted as key elements of their approach.

This figure shows the results of 3D surface reconstruction on the Thai Statue shape using the proposed Neural Experts method and compares it to the SIREN method. The figure includes three parts: the output mesh, the error colormap, and the expert segmentation. The output mesh visually demonstrates the reconstruction of the Thai statue shape. The error colormap shows the difference between the reconstructed surface and the ground truth surface. Warmer colors indicate larger errors, and cooler colors indicate smaller errors. Expert segmentation shows which expert in the model was responsible for reconstructing each part of the shape.

This figure compares the 3D surface reconstruction results between the proposed Neural Experts method and the SIREN baseline method on the Thai Statue shape. The figure shows three aspects for each method: the output mesh, the error colormap (showing the distance to the ground truth surface, with lighter colors indicating smaller errors), and the expert segmentation (showing how the input space was divided among different expert networks in the Neural Experts method). The results demonstrate the ability of the Neural Experts model to capture finer details, resulting in a mesh with significantly fewer large errors compared to SIREN.

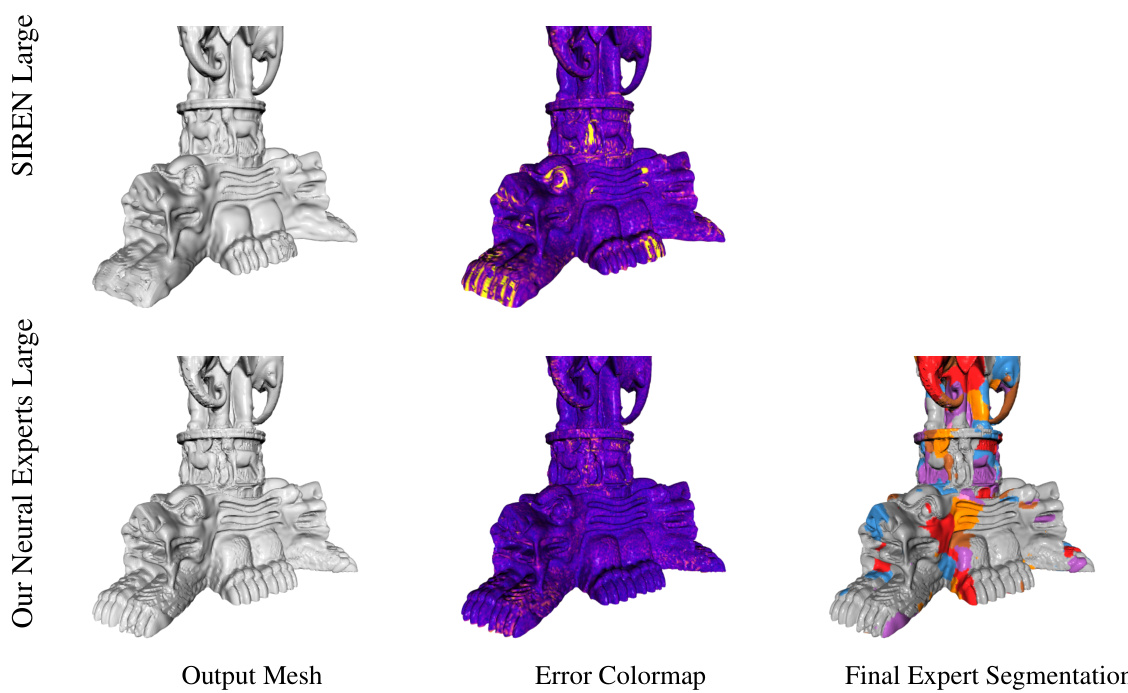
This figure compares the results of surface reconstruction on the Lucy shape using three different methods: SIREN Large, Our Neural Experts Large (the proposed method), and Our Neural Experts Large. Each method’s output mesh, error colormap, and expert segmentation are shown. The colormaps visualize the difference between the reconstructed surface and the ground truth. The expert segmentation shows how different subnetworks (experts) contribute to the overall reconstruction. The results demonstrate that the proposed method, Our Neural Experts Large, achieves better overall reconstruction quality, especially in high-detail areas such as the torch.

This figure compares three different architectures for Implicit Neural Representations (INRs): a traditional INR using a single MLP, a vanilla MoE INR, and the proposed Neural Experts architecture. The key difference is the introduction of a manager network in the MoE and Neural Experts models, which routes the input to different expert networks. The Neural Experts method further enhances this by incorporating conditioning and pretraining techniques for the manager network, improving signal reconstruction and reducing the number of parameters needed.
More on tables
This table presents ablation studies on the Sine activation function, comparing different architectural variations of the proposed Neural Experts model with baseline models (Vanilla MoE, Vanilla MoE with random pretraining). It demonstrates the model’s improved performance and the effectiveness of random pretraining. The table highlights the substantial improvement of the proposed model over baselines, while showing that even a smaller version remains competitive.

This table presents the mean squared error (MSE) for audio reconstruction using SIREN, SIREN Wider, and the proposed Neural Experts model (Our SIREN MoE). The results are shown for three audio types: Bach (music), Counting (single-speaker speech), and Two Speakers (two-speaker speech). The MSE is divided by 10000 for compactness. The table demonstrates the significant improvement in audio reconstruction performance of the Neural Experts model compared to the baseline SIREN models, while having fewer parameters.

This table presents a comparison of 3D shape reconstruction performance between the proposed Neural Experts method and a baseline SIREN model, using two different sizes (Small and Large). The evaluation metrics are Trimap IoU (with a boundary distance d of 0.001) and Chamfer distance. The results demonstrate that Neural Experts achieves significantly better reconstruction with fewer parameters.

This table presents the ablation study on different conditioning options for the proposed Neural Experts model. It compares the Peak Signal-to-Noise Ratio (PSNR) achieved by four different conditioning methods: no conditioning, max pooling, mean pooling, and concatenation of encoder outputs. The results show that concatenating the encoder outputs yields the best performance, highlighting the importance of this design choice for improving the model’s accuracy.

This table shows the results of an ablation study on the conditioning of the expert encoder outputs in the Neural Experts model. Different conditioning methods were tested, including no conditioning, max pooling, mean pooling, and concatenation. The results show that concatenation of the encoder outputs yields the best performance, significantly outperforming the other methods.
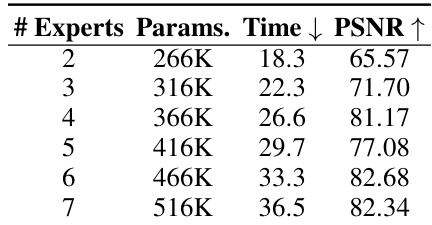
This table shows the impact of varying the number of experts on model performance. Increasing the number of experts improves PSNR (peak signal-to-noise ratio), a metric measuring image quality, but also increases the number of parameters and training time. The results suggest an optimal number of experts that balances performance gains against computational cost. The data shows a trade-off: More experts lead to better PSNR but also more parameters and longer training time.
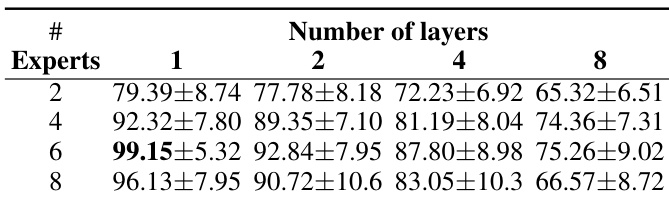
This table presents an ablation study on the impact of varying the number of experts and layers in the model’s architecture on its performance. The results suggest a trade-off between these two factors; fewer layers combined with more experts seem to improve performance, although there are diminishing returns with an increasing number of experts.

This table shows the impact of different parameter allocation strategies on the performance of the Neural Experts model. The model’s architecture is kept consistent, except for the distribution of parameters across its three main components: Expert Encoder, Experts, and Manager. Despite significant variation in the distribution, the PSNR remains relatively consistent, except when a larger portion of the parameters is allocated to the Manager component. This suggests that a balanced distribution of parameters is optimal for the best overall model performance.
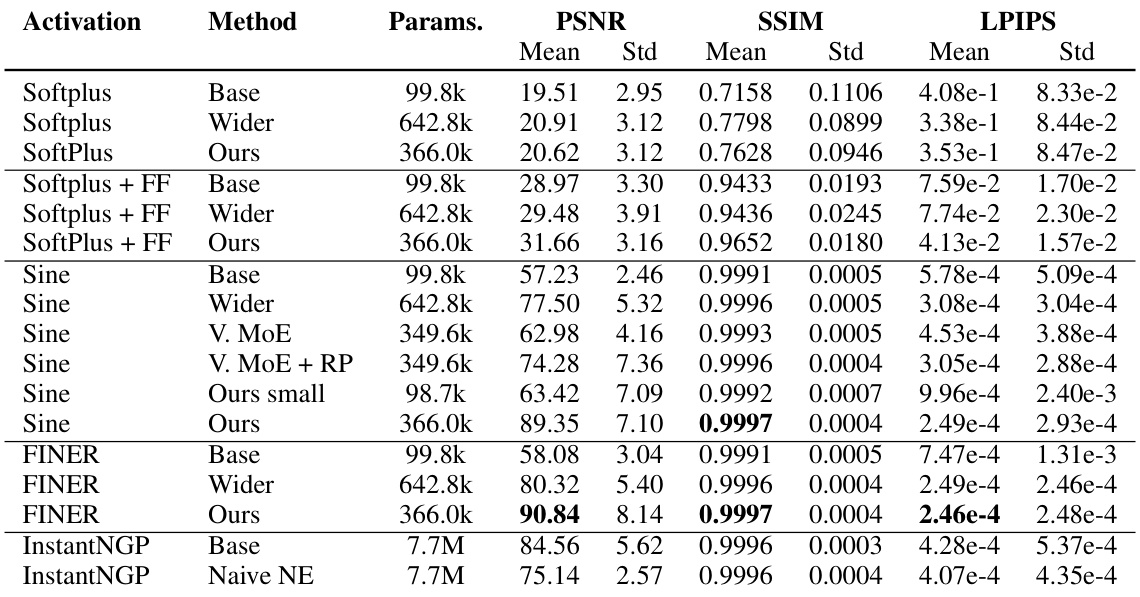
This table presents a comparison of image reconstruction performance using different activation functions (Softplus, Softplus + FF, Sine, FINER) and model architectures (Base, Wider, Ours). The ‘Base’ and ‘Wider’ columns represent baseline models with varying numbers of parameters, while the ‘Ours’ column shows the performance of the proposed Neural Experts method. The results demonstrate that the Neural Experts method achieves superior PSNR, SSIM, and LPIPS scores compared to the baselines.

This table presents an ablation study on the effect of different parameter allocations across the various components of the Neural Experts model. It shows the architecture (number of layers and width of each component: expert encoder, experts, manager encoder, manager) and percentage of total parameters allocated to each component for four different allocation strategies: Larger Manager, Larger Experts (the authors’ proposed method), Larger Encoder, and Balanced. The PSNR (Peak Signal-to-Noise Ratio) results for each configuration are also provided, demonstrating that the model performs well with different parameter allocation strategies and highlighting the robustness of the architecture.
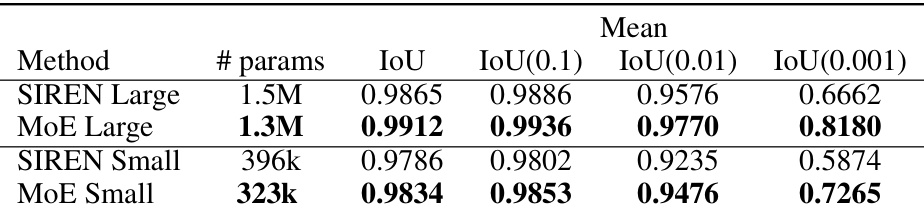
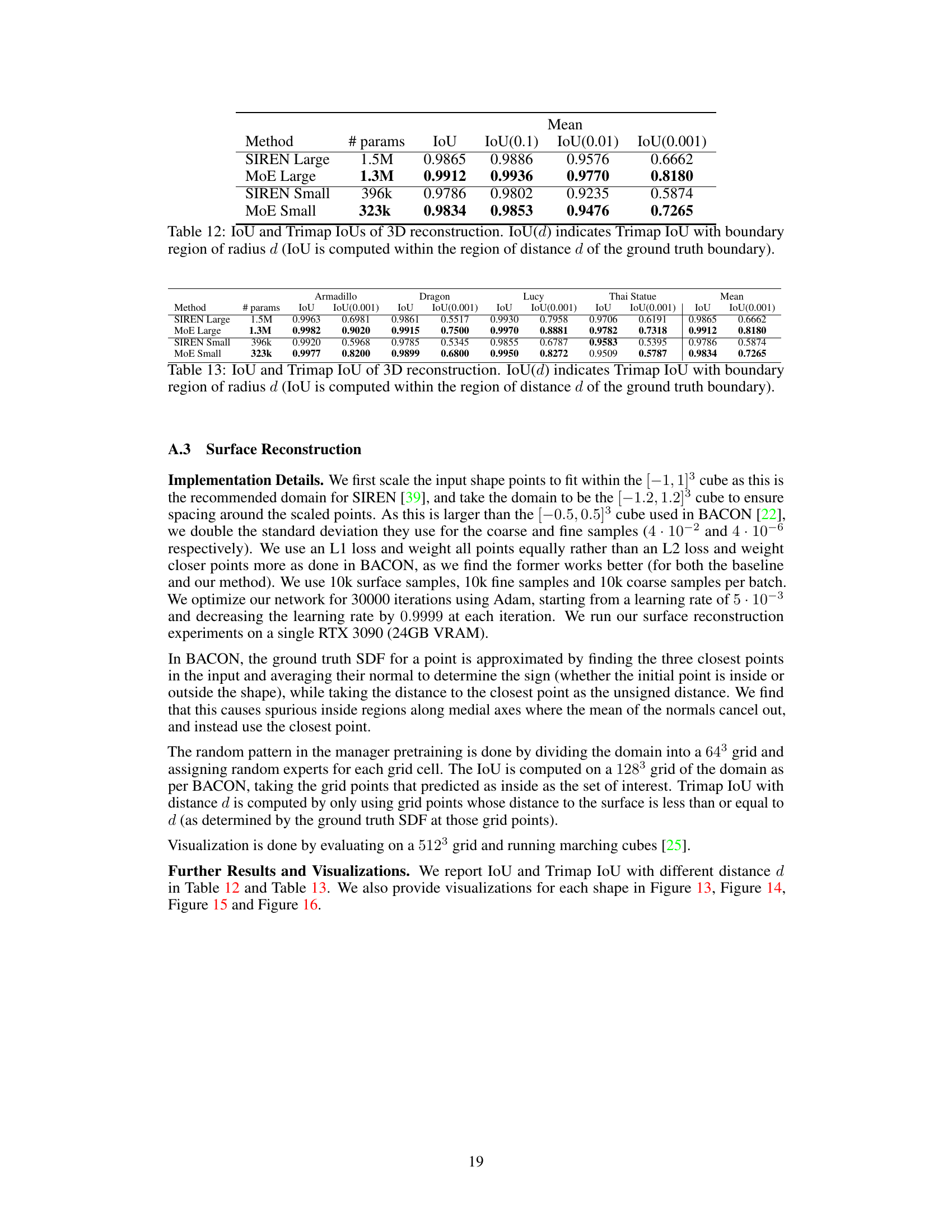
This table presents the Intersection over Union (IoU) and Trimap IoU scores for 3D surface reconstruction using different methods. Trimap IoU, denoted as IoU(d), is calculated within a boundary region of radius d around the ground truth shape. The table compares two model sizes (Large and Small) for both SIREN and the proposed MoE (Mixture of Experts) method, showing that the MoE method generally achieves better results for both model sizes.

This table presents the performance of different methods on 3D shape reconstruction using IoU and Trimap IoU metrics. Trimap IoU is calculated within different distances (d) from the ground truth shape boundary, providing more nuanced evaluation of boundary accuracy. The results show the IoU, IoU(0.1), IoU(0.01), and IoU(0.001) values for different models on various shapes. The table helps assess how well the models capture the shape’s boundary and finer details.
Full paper#