↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
LLM-based autonomous agents have shown promise in tackling complex tasks, but improving their collaborative capabilities remains a challenge. Existing multi-agent systems often struggle with credit assignment—determining each agent’s contribution to the overall outcome—and may lack efficient training methods for collaborative scenarios. Moreover, relying solely on environmental rewards to generate reflections can be ineffective.
To address these issues, the authors propose COPPER, a novel framework that integrates self-reflection mechanisms. COPPER uses counterfactual rewards to assess individual agent contributions, and it fine-tunes a shared reflector to automatically adjust prompts for actor models, thereby improving reflection quality and training stability. Evaluations on various tasks demonstrate COPPER’s enhanced capabilities and generalization performance across different actor models, showcasing its potential to advance the field of multi-agent collaboration with LLMs.
Key Takeaways#
Why does it matter?#
This paper is important because it presents COPPER, a novel framework that significantly improves multi-agent collaboration using large language models (LLMs). It addresses the crucial challenge of credit assignment in multi-agent systems and demonstrates excellent generalization across different LLMs. This work is highly relevant to the burgeoning field of LLM-based agents and opens new avenues for research in improving collaboration, reflection mechanisms, and the efficiency of multi-agent systems. The findings are directly applicable to various downstream applications and will likely inspire further development in improving the reasoning and decision-making abilities of AI systems.
Visual Insights#
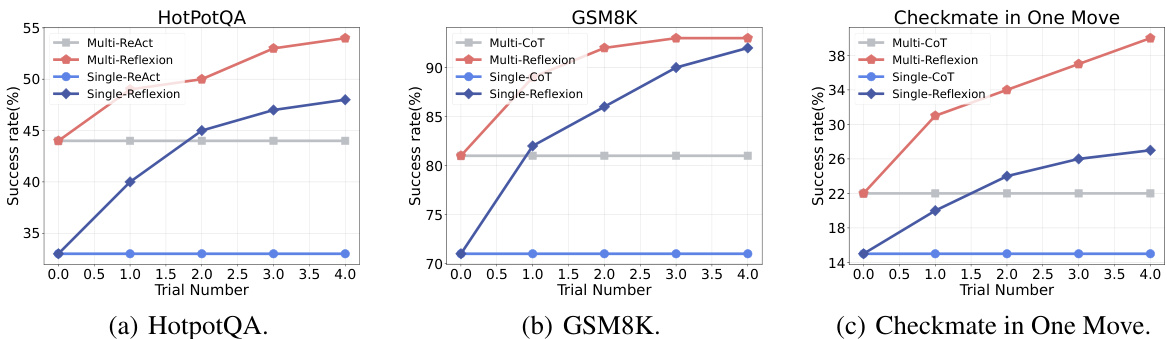
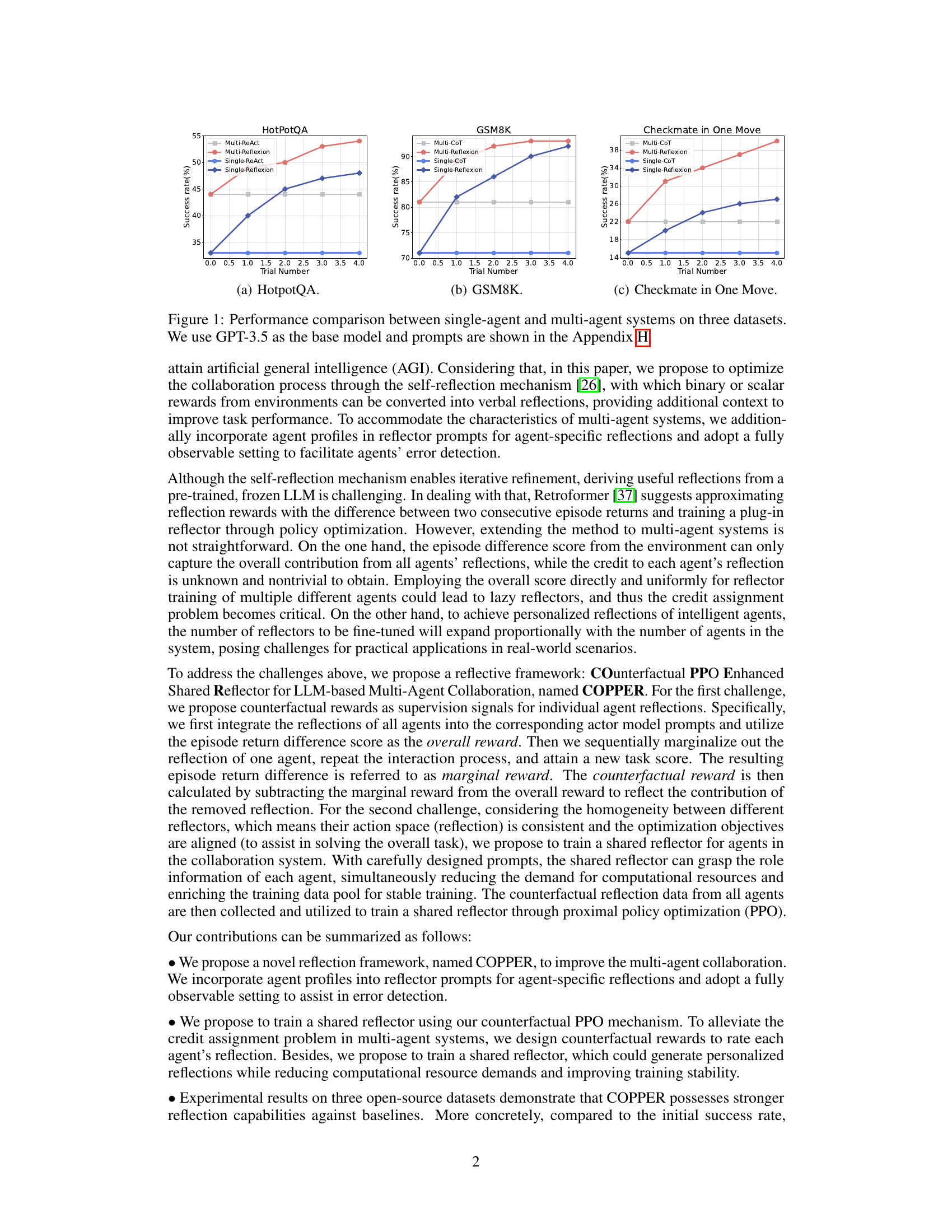
This figure presents a comparison of the success rates achieved by single-agent and multi-agent systems across three different datasets: HotpotQA, GSM8K, and Checkmate in One Move. The results are displayed as success rates plotted against the number of trials performed, illustrating the performance progression of each system over multiple attempts. The use of GPT-3.5 as the base model and prompts is noted, with further detail available in Appendix H of the paper.

This table shows the amount of training data generated by the original LongChat model, broken down by dataset (HotPotQA, GSM8K, Checkmate in One Move) and category (total, positive examples, negative examples). It provides a quantitative overview of the data used in the supervised fine-tuning stage of the reflector model training within the COPPER framework.
In-depth insights#
Reflective Multi-Agent Systems#
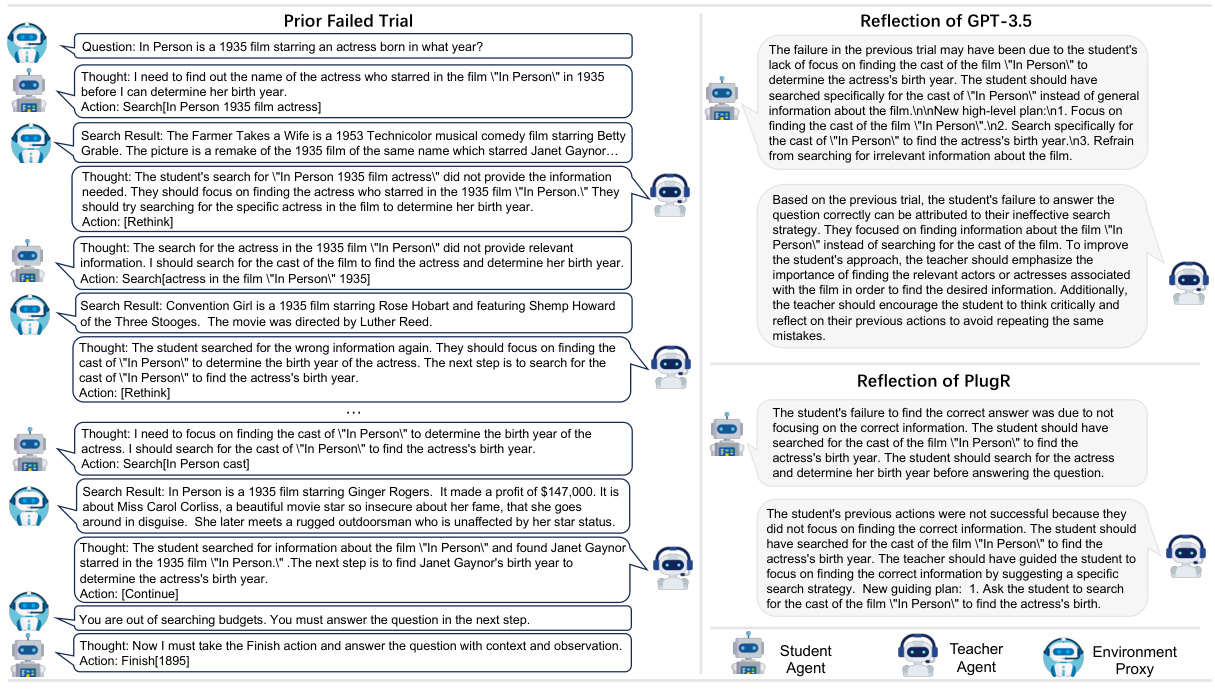
Reflective multi-agent systems represent a significant advancement in AI, moving beyond traditional reactive or deliberative models. The core idea is to integrate a self-reflection mechanism within each agent, allowing it to analyze its past actions, assess their effectiveness, and adapt its future behavior accordingly. This contrasts with systems where agents merely react to their environment or follow pre-programmed plans. The reflective capability is crucial for enhancing collaboration, as agents can learn from each other’s successes and failures, improve their understanding of the shared task, and adjust their strategies dynamically. This necessitates a sophisticated architecture that allows for communication, information sharing, and individual reflection. Challenges include credit assignment, determining which agent’s actions contributed most significantly to a particular outcome, and designing effective reward functions that incentivize collaborative behavior rather than individualistic pursuits. The integration of large language models (LLMs) is particularly promising, as their powerful language processing capabilities enable detailed reflections and nuanced communication among agents. However, this also raises issues related to the computational cost and potential biases embedded in LLMs. Research in reflective multi-agent systems is opening new possibilities for creating more robust, adaptable, and intelligent collaborative AI systems.
Counterfactual Reward Shaping#
Counterfactual reward shaping is a powerful technique for improving the performance of reinforcement learning agents, especially in complex multi-agent environments. The core idea is to estimate the contribution of a single agent’s action by comparing the outcome with a counterfactual scenario where that action is not taken. This helps address the credit assignment problem, which is particularly challenging in multi-agent settings where it is difficult to isolate the impact of individual agents. By fine-tuning a shared reflector model using counterfactual rewards, the system can learn more effective and personalized reflections, improving overall collaboration and task completion. Counterfactual rewards provide a more nuanced signal for training than traditional reward signals because they explicitly consider the causal effect of individual actions. However, a key challenge is the computational cost of generating counterfactual trajectories and the potential bias in counterfactual estimations. Careful design of the counterfactual scenario and robust estimation methods are crucial for the success of this approach. The method’s effectiveness relies on accurate counterfactual prediction which in turn is reliant on the model’s ability to generalize and understand complex interactions.
Shared Reflector Training#
Training a shared reflector model offers a compelling approach to enhance multi-agent collaboration using Large Language Models (LLMs). Instead of training numerous individual reflectors for each agent, which becomes computationally expensive and challenging to manage as the number of agents grows, a shared reflector processes prompts from all agents, generating personalized reflections based on the context and agent roles. This approach not only reduces computational cost but also enhances training stability due to the larger and more diverse training dataset. The key to success lies in crafting carefully designed prompts that provide sufficient context for the shared reflector to effectively tailor its reflections to specific agents. Furthermore, counterfactual rewards provide effective supervision signals, helping the reflector learn to generate helpful reflections by assessing the impact of each agent’s reflection on the overall system performance. Careful consideration should be given to designing this reward mechanism to fairly assess individual contributions and prevent issues like lazy reflectors. Overall, the shared reflector training strategy presents a scalable and efficient solution for augmenting LLM-based multi-agent systems with self-reflection capabilities, overcoming limitations of training individual reflectors for each agent.
Generalization and Scalability#
A crucial aspect of evaluating any machine learning model, especially in multi-agent systems, is its capacity for generalization and scalability. Generalization refers to the model’s ability to perform well on unseen data or tasks beyond the training set; a model that overfits the training data will not generalize effectively. In the context of multi-agent systems, this means the model should adapt its strategies and collaborative approaches to novel situations and interactions among agents with varying levels of expertise. Scalability addresses the model’s capacity to handle increasingly large-scale problems. This is important because real-world applications of multi-agent systems often involve a vast number of agents and complex interactions, which necessitates models capable of efficient and timely processing without sacrificing accuracy. Therefore, a successful multi-agent system must possess strong capabilities in both generalization and scalability. A model that achieves high accuracy on a small-scale training dataset but struggles with novel situations or larger datasets lacks both generalization and scalability. In order to fully assess the model’s utility, a thorough analysis of its performance on a range of scales and under diverse conditions is critical. This includes testing performance across datasets and assessing the model’s robustness to variations in agent capabilities and environmental complexity. This is crucial to confirm its potential for broader application.
Limitations and Future Work#
The research paper’s limitations section should delve into the inherent challenges of using counterfactual rewards and the computational demands of training multiple reflectors. Addressing the credit assignment problem in multi-agent systems remains a complex issue, and while counterfactual rewards offer a solution, limitations should discuss their efficacy across different task complexities and agent numbers. The reliance on pre-trained LLMs, despite their impressive capabilities, inherently limits the reflective process. Future work could explore methods for more efficient data collection and improved reward modeling, perhaps leveraging techniques like imitation learning to overcome data sparsity and improve training stability. Investigating alternative reflection mechanisms that are less computationally intensive while retaining the effectiveness of self-reflection is also crucial. Additionally, a thoughtful discussion on the generalizability of COPPER across varied LLM architectures and task domains needs to be included, noting where performance might degrade. Finally, research into handling more complex and dynamic environments, exploring aspects such as partial observability and decentralized control, is needed to expand COPPER’s applicability beyond the controlled settings of the experiments.
More visual insights#
More on figures

This figure provides a visual representation of the COPPER framework. The left side shows the multi-agent reflection process, detailing the steps involved: agent selection, memory update, observation, and action generation. The right side illustrates the construction of counterfactual rewards used for fine-tuning the shared reflector, a key component of the COPPER model. The figure highlights the interaction between the agents, environment, and the reflection module in a multi-agent setting.

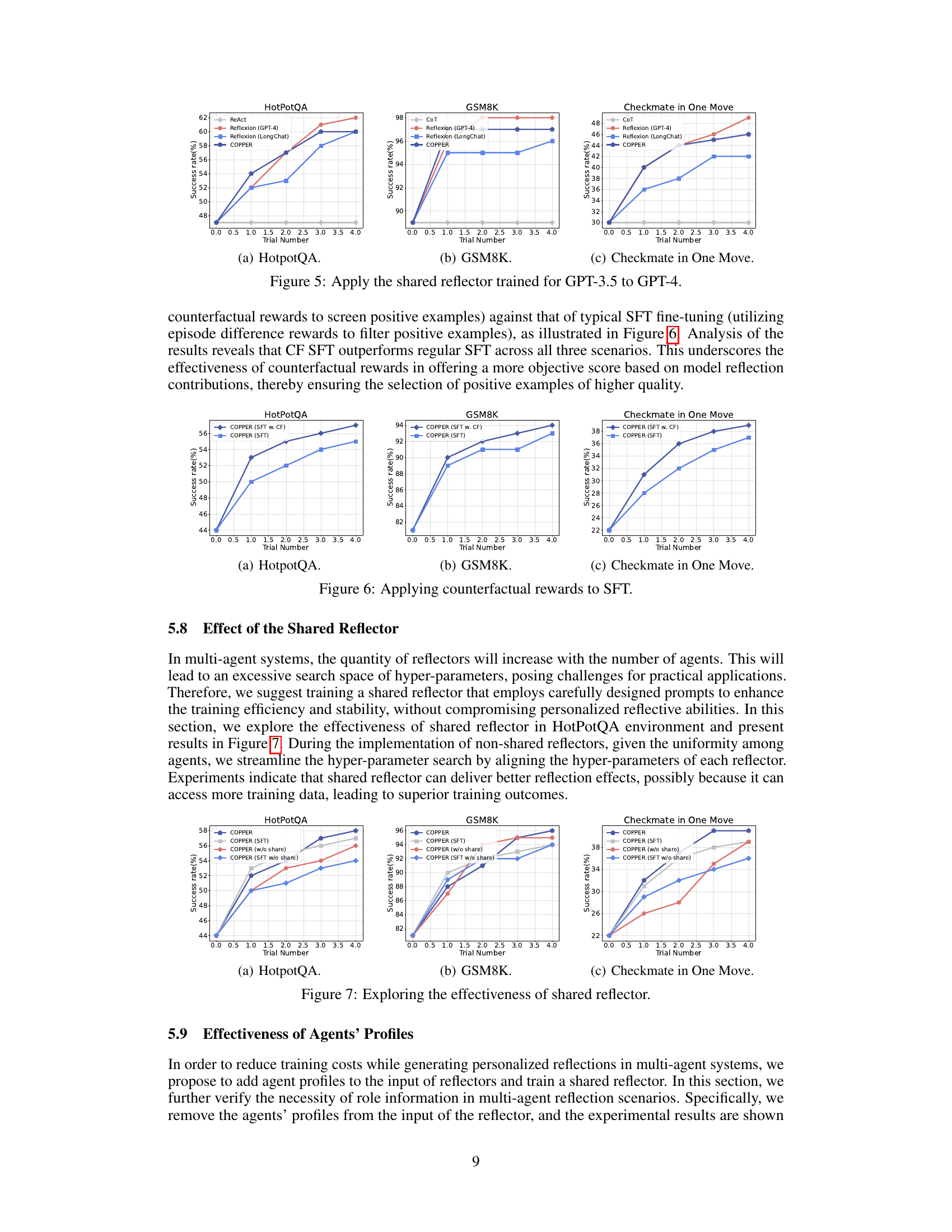
This figure shows the performance comparison between the proposed COPPER model and several baseline models across three different datasets: HotPotQA, GSM8K, and Checkmate in One Move. Each dataset represents a different type of task (multi-hop question answering, mathematics, and chess, respectively). The x-axis represents the trial number, indicating the number of attempts to complete the task. The y-axis shows the success rate (percentage of successful attempts). The figure illustrates that COPPER consistently outperforms the baselines across all three datasets, demonstrating its superior performance in multi-agent collaboration.

This figure compares the performance of the proposed COPPER model against several baseline models across three different datasets: HotpotQA, GSM8K, and Checkmate in One Move. Each dataset represents a different type of task, allowing for a comprehensive evaluation of the model’s generalization capabilities. The x-axis represents the number of trials, and the y-axis represents the success rate. The figure shows that COPPER consistently outperforms the baseline models across all three datasets, demonstrating its superior performance in multi-agent collaboration tasks.
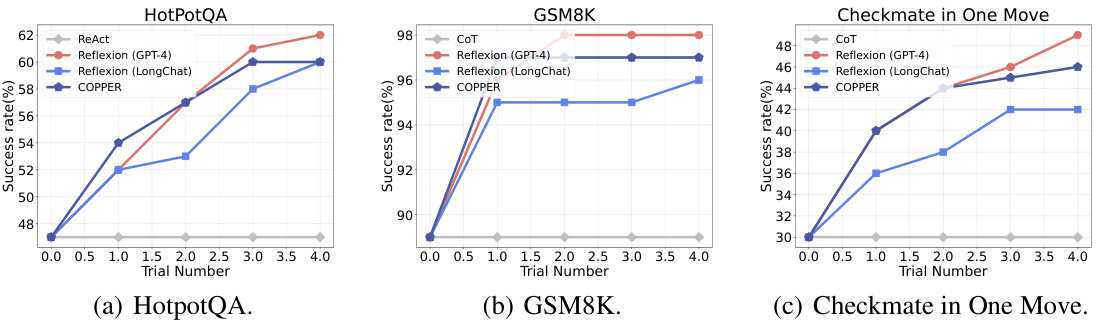
The figure compares the success rates of COPPER against various baselines (ReAct, Reflexion using GPT-3.5 and LongChat, and Retroformer) across three datasets: HotPotQA, GSM8K, and Checkmate in One Move. The x-axis represents the trial number, and the y-axis shows the success rate (%). It demonstrates COPPER’s improved performance over the baselines, especially after multiple trials, highlighting its stronger reflection capabilities and generalization across different tasks.

This figure compares the performance of single-agent and multi-agent systems on three different datasets: HotpotQA, GSM8K, and Checkmate in One Move. The success rate (y-axis) is plotted against the trial number (x-axis) for each system. The single-agent systems are compared to their multi-agent counterparts. GPT-3.5 is used as the base language model across all experiments. The specific prompts are detailed in Appendix H of the paper.
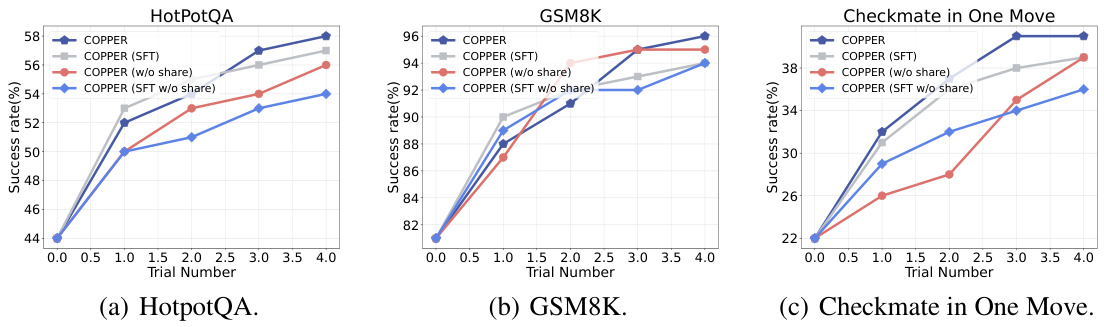
This figure compares the performance of the proposed COPPER model against several baseline methods across three different datasets: HotpotQA, GSM8K, and Checkmate in One Move. The x-axis represents the trial number, indicating the iterative nature of the experiments. The y-axis shows the success rate (in percentage). Each line represents a different model, demonstrating the improvement of COPPER over the baselines in terms of success rate across multiple trials. The results demonstrate the effectiveness of the COPPER model in multi-agent collaboration tasks.
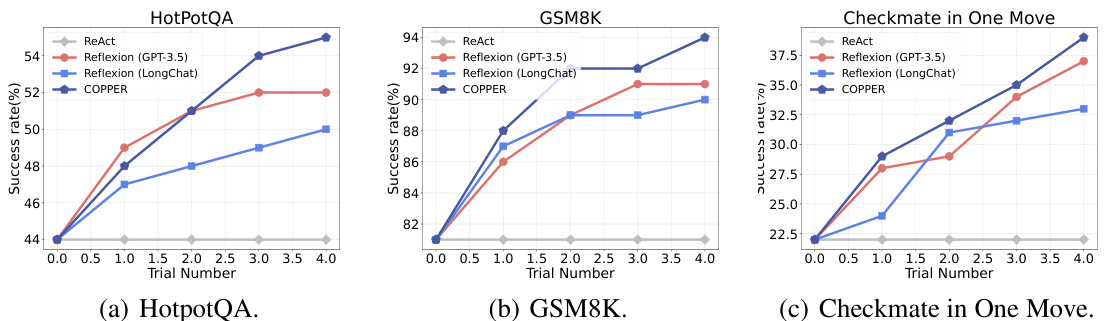
This figure shows the performance comparison between the proposed COPPER model and several baseline models across three different datasets: HotPotQA, GSM8K, and Checkmate in One Move. The x-axis represents the trial number, and the y-axis represents the success rate (%). The figure illustrates that COPPER consistently outperforms the baseline models across all three datasets, demonstrating its improved ability to enhance the reflection capabilities of agents in multi-agent systems.

This figure compares the performance of the proposed COPPER model against several baseline models across three different datasets: HotPotQA, GSM8K, and Checkmate in One Move. Each dataset represents a different type of task (multi-hop question answering, math problem solving, and chess, respectively). The x-axis shows the trial number, indicating the number of attempts made to complete the task, while the y-axis shows the success rate (%). The figure demonstrates that COPPER consistently outperforms the baseline models in terms of success rate across all three datasets, especially as the number of trials increases.
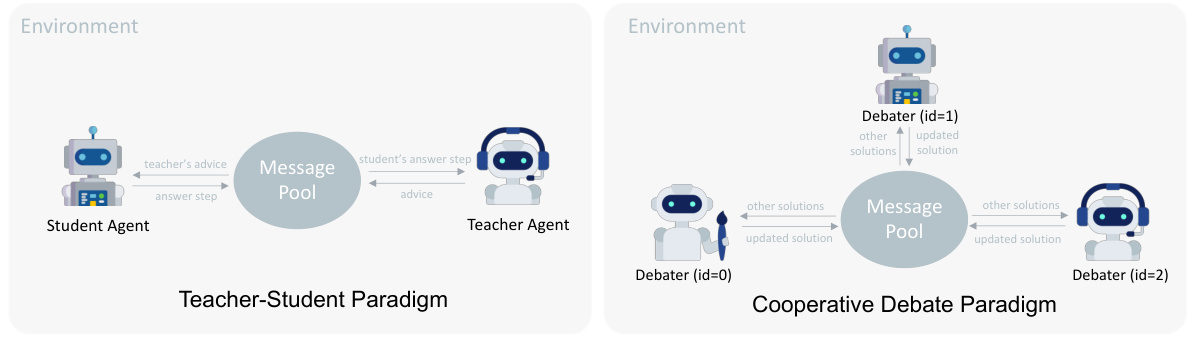
This figure illustrates the two main collaboration paradigms used in the paper’s experiments: the Teacher-Student paradigm and the Cooperative Debate paradigm. The Teacher-Student paradigm involves a student agent interacting with an environment and receiving guidance from a teacher agent. Information is exchanged through a message pool. The Cooperative Debate paradigm involves multiple debaters (agents) who exchange information through a message pool to collaboratively solve a task. Both paradigms involve the use of a message pool as a mechanism for agents to communicate and share information during the problem-solving process.
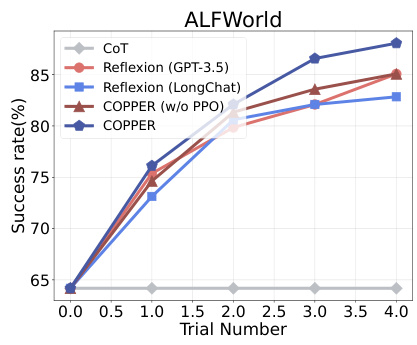
This figure compares the performance of the proposed COPPER model against several baseline methods across three different datasets: HotpotQA, GSM8K, and Checkmate in One Move. Each dataset represents a distinct type of task (multi-hop question answering, mathematics problem solving, and chess, respectively). The x-axis indicates the trial number, showing performance improvement over multiple trials. The y-axis displays the success rate (percentage). The figure visually demonstrates that COPPER consistently outperforms the baselines in all three tasks.
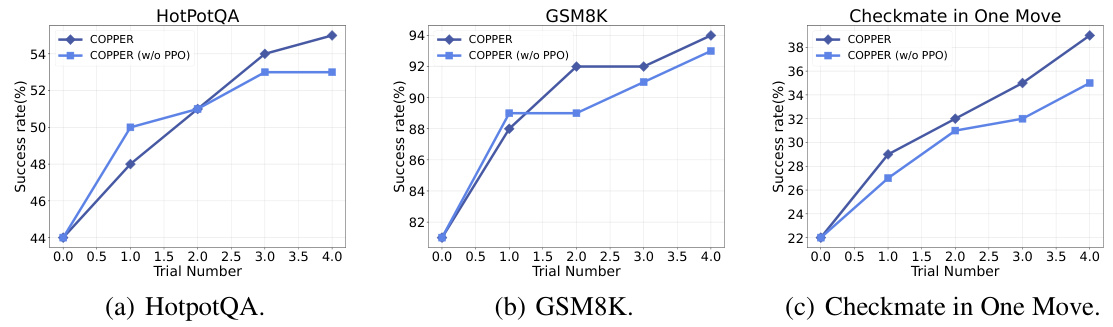
This figure presents a comparison of the success rates of COPPER and various baseline models across three different datasets: HotpotQA, GSM8K, and Checkmate in One Move. The x-axis represents the trial number, and the y-axis shows the success rate (%). The results illustrate that COPPER consistently outperforms the baselines, demonstrating significant improvements in multi-agent collaboration across diverse tasks and complexities.

This figure compares the performance of the proposed COPPER model against several baseline models across three different datasets: HotPotQA, GSM8K, and Checkmate in One Move. The x-axis represents the trial number, and the y-axis shows the success rate (%). The figure visually demonstrates the superior performance of COPPER compared to other methods, highlighting its improved reflection capabilities, especially after multiple trials.

This figure compares the performance of single-agent and multi-agent systems on three different datasets: HotpotQA, GSM8K, and Checkmate in One Move. The success rate (y-axis) is plotted against the trial number (x-axis). Each dataset’s plot shows the success rate for single-agent systems using both ReAct and Reflexion methods, along with results for multi-agent systems using the same methods plus the COPPER model. GPT-3.5 is used as the base model for all systems, with prompts specified in Appendix H. The figure illustrates the improved performance of the COPPER model in multi-agent settings compared to the single-agent baselines.
This figure compares the success rates of single-agent and multi-agent systems on three different datasets: HotpotQA, GSM8K, and Checkmate in One Move. The x-axis represents the trial number, and the y-axis represents the success rate (%). The single-agent models are compared against multi-agent versions incorporating the self-reflection mechanisms proposed in the paper. GPT-3.5 is used as the base language model for all systems. The specific prompts used for each system are detailed in Appendix H of the paper.

This figure compares the performance of the proposed model, COPPER, against several baselines across three different datasets: HotPotQA, GSM8K, and Checkmate in One Move. Each dataset represents a different type of task (multi-hop question answering, arithmetic reasoning, and chess, respectively). The graphs show the success rate (percentage of tasks successfully completed) over multiple trials (attempts to solve the problem). COPPER consistently outperforms the baselines across all three datasets, demonstrating improved performance in multi-agent collaboration through its self-reflection mechanism.

This figure shows a comparison of the success rates of different models on three datasets: HotPotQA, GSM8K, and Checkmate in One Move. The models compared are ReAct, CoT, Reflexion (using both GPT-3.5 and LongChat as reflectors), Retroformer (multi-agent), and COPPER. The graph plots the success rate against the trial number (number of attempts). COPPER consistently outperforms the other models, demonstrating improved performance with each trial.
Full paper#