↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Current benchmarks for evaluating the robustness of large vision-language models (LVLMs), like CLIP, primarily focus on ImageNet-related spurious features, potentially overestimating their robustness. This limitation is problematic because it doesn’t fully reflect how these models perform in real-world scenarios with diverse and realistic spurious correlations.
This paper introduces CounterAnimal, a novel dataset designed to assess CLIP’s reliance on realistic spurious features found in large web-scale data. Experiments demonstrate that CLIP models, despite their impressive performance, struggle with these novel biases and that simply scaling up model parameters or using better pre-training data doesn’t entirely solve the issue. The paper also offers theoretical insights which explain why the contrastive learning objective used by CLIP may not fully prevent the reliance on such features. These findings are important because they challenge existing assumptions about CLIP’s robustness and highlight the need for more realistic benchmarks and improved training strategies.
Key Takeaways#
Why does it matter?#
This paper is crucial because it challenges the commonly held belief about CLIP models’ robustness. By introducing a novel benchmark dataset and theoretical analysis, it sheds light on the limitations of existing evaluation methods and provides valuable insights into how large vision language models learn spurious correlations. This research opens new avenues for improving the robustness and generalization abilities of these models, which is highly relevant to the rapidly evolving field of multi-modal AI.
Visual Insights#

This figure displays example images from the CounterAnimal dataset, specifically focusing on the ‘ice bear’ class. The dataset is designed to highlight CLIP’s reliance on spurious correlations. The images are divided into two groups: ’easy’ (ice bears in snowy backgrounds) and ‘hard’ (ice bears in grassy backgrounds). The significant drop in zero-shot accuracy from the easy group to the hard group (97.62% to 70.91%) demonstrates how the model’s performance degrades when spurious correlations are disrupted. The difference shows that the model relies heavily on the background as a spurious feature for correct classification, rather than on the intrinsic visual features of the ice bear itself.

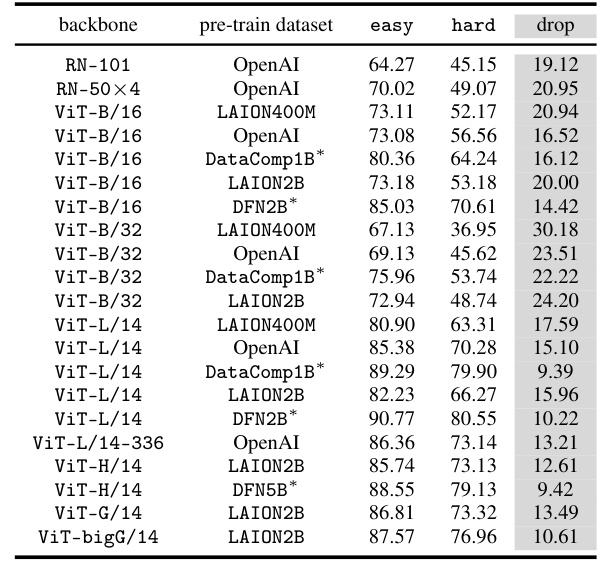
This table presents the zero-shot accuracy of the CLIP-LAION400M-ViT-B/32 model on a subset of the CounterAnimal dataset. The dataset is designed to highlight the model’s reliance on spurious features (correlations between animal classes and their backgrounds). For each animal class, two groups of images are shown: an ’easy’ group with commonly associated backgrounds and a ‘hard’ group with less common backgrounds. The table shows the accuracy for each group and the difference (drop) in accuracy between them. This difference indicates the degree to which the model is relying on the background as a spurious feature rather than solely on the animal itself for classification. Larger drops in accuracy suggest a greater reliance on spurious features.
In-depth insights#
CLIP’s Spuriousness#
The study delves into the spurious correlations learned by CLIP models, challenging the widely held belief of their superior robustness. The core argument revolves around the discrepancy between existing benchmarks (often ImageNet-derived) and the actual spurious features present in CLIP’s massive training data (like LAION). This mismatch leads to an overestimation of CLIP’s robustness. The authors introduce CounterAnimal, a novel dataset designed to specifically expose these real-world spurious correlations, demonstrating that CLIP models, despite impressive performance, are still susceptible to such biases. The research highlights the generic nature of these spurious correlations across various CLIP model architectures and training data, a finding corroborated by theoretical analysis. This analysis suggests limitations in the CLIP objective function regarding inherent robustness, prompting the exploration of alternative strategies such as larger models and higher-quality pretraining data to mitigate this issue. CounterAnimal therefore serves as a crucial benchmark for evaluating and improving the genuine out-of-distribution robustness of large vision-language models.
CounterAnimal Dataset#
The CounterAnimal dataset represents a novel contribution in evaluating the robustness of large vision-language models (LVLMs) like CLIP. Unlike existing benchmarks focusing on ImageNet biases, CounterAnimal targets real-world spurious correlations learned by CLIP during training on large-scale web data. It cleverly identifies pairs of image groups within animal classes that differ only in their backgrounds yet trigger significantly different performance from CLIP. This approach helps to isolate and quantify the reliance of CLIP models on spurious visual cues, providing a more accurate assessment of their generalization capabilities beyond ImageNet-centric biases. The dataset’s rigorous curation process, which includes manual cleaning and background labeling, further enhances its reliability and suitability for benchmarking robust LVLMs. CounterAnimal’s innovative design makes it a valuable resource for advancing research on robustness and addressing the limitations of current evaluation methods.
Robustness Analysis#
A robust model should generalize well to unseen data and variations. A robustness analysis would explore this by evaluating model performance under various conditions, including distribution shifts (changes in data characteristics), adversarial attacks (designed to fool the model), and noisy data. The goal is to identify vulnerabilities and quantify the model’s resilience. Analyzing the impact of spurious correlations, where the model relies on irrelevant features instead of true signals, is crucial. Counterfactual examples, where individual inputs are modified, can reveal reliance on such correlations. Finally, the analysis should ideally delve into the underlying reasons for robustness or fragility, potentially using theoretical analysis to explain observed behaviors. Theoretical justification provides deeper understanding beyond empirical results, leading to more informed model design and improved robustness.
CLIP’s Limitations#
CLIP, despite its impressive performance, exhibits limitations primarily stemming from its reliance on spurious correlations within its training data. The model’s tendency to leverage easily identifiable visual cues (backgrounds, etc.) rather than true semantic understanding makes it vulnerable to distribution shifts and out-of-distribution generalization issues. This inherent bias, captured effectively by the CounterAnimal dataset, highlights that CLIP’s robustness may be overestimated when evaluated using datasets based on ImageNet’s biases. Simply increasing model size or training data doesn’t fully mitigate these issues, indicating that more sophisticated training techniques focusing on genuine semantic understanding are needed to enhance CLIP’s robustness and generalizability.
Future Directions#
Future research could explore several promising avenues. Expanding the CounterAnimal dataset to encompass a wider range of object categories and background variations is crucial for strengthening its generalizability and robustness as a benchmark. Investigating alternative training paradigms beyond contrastive learning, such as techniques that explicitly address spurious correlations, may yield models more resilient to distribution shifts. Developing novel evaluation metrics that go beyond simple accuracy and capture the nuanced ways in which models utilize spurious correlations is another key area. Furthermore, a deeper theoretical understanding of how different model architectures and training objectives interact with spurious features would be invaluable. Finally, a comparative analysis with other large vision-language models is warranted to understand the extent to which the observed phenomena are specific to CLIP or represent broader trends in the field.
More visual insights#
More on figures
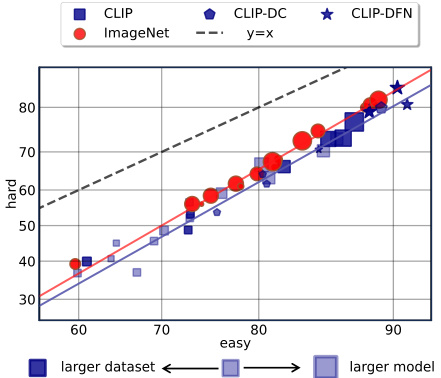
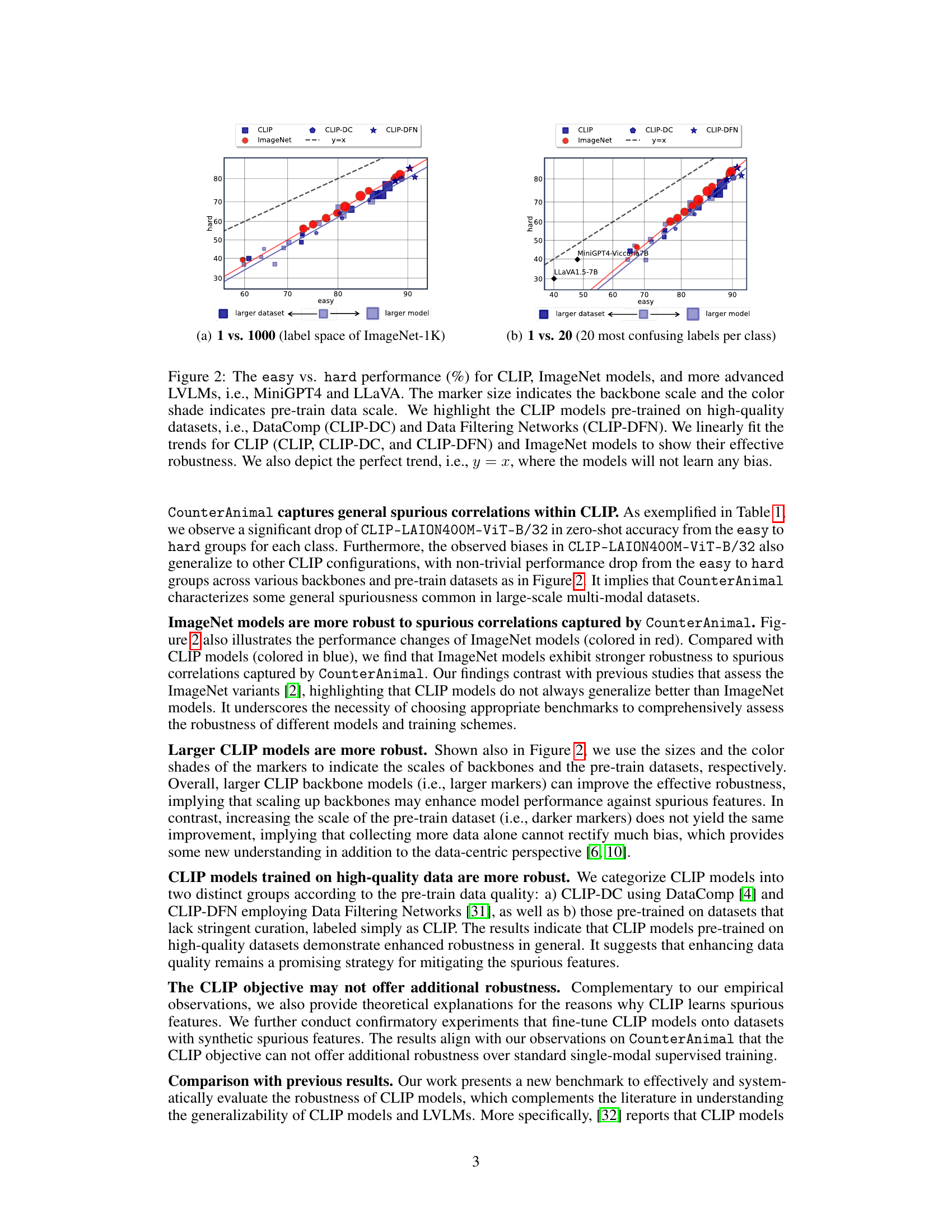
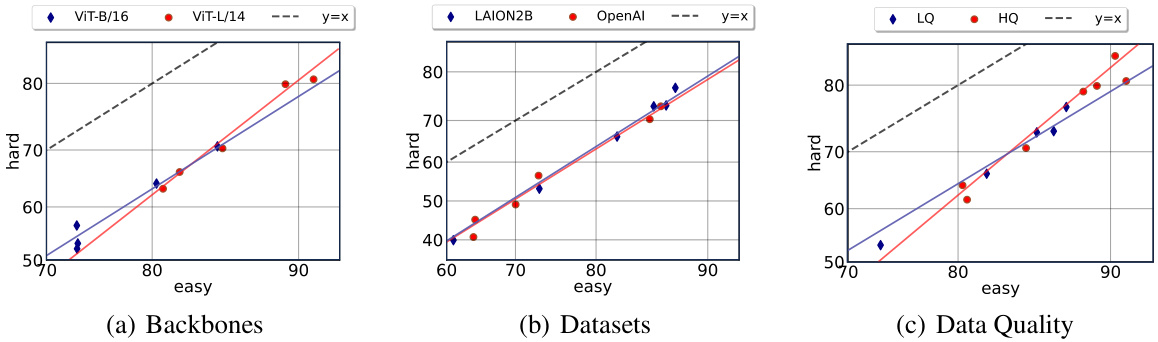
This figure compares the performance of various CLIP and ImageNet models on an ’easy’ versus ‘hard’ task, designed to evaluate robustness against spurious correlations. The x-axis represents performance on the easy task, and the y-axis shows performance on the hard task. Points closer to the y=x line indicate better robustness, as performance on both tasks is similar. The figure shows that larger models and those trained on higher quality data exhibit improved robustness. ImageNet models are shown to be more robust than many CLIP models.

This figure compares the performance of different vision-language models (VLMs) and ImageNet models on the CounterAnimal dataset. The x-axis represents the performance on the ’easy’ subset of the dataset (animals in common backgrounds), while the y-axis represents performance on the ‘hard’ subset (animals in uncommon backgrounds). Points closer to the y=x line indicate better robustness, as performance is consistent across both sets. The figure demonstrates that CLIP models, especially those trained on higher-quality data, are more robust to this type of spurious correlation compared to ImageNet models, Larger models generally perform better.

This figure shows the distribution of images in the CounterAnimal dataset. Each bar represents a different animal class. The height of the blue portion of the bar indicates the number of images in the ’easy’ group (images with common backgrounds), and the height of the orange portion represents the number of images in the ‘hard’ group (images with uncommon backgrounds). The figure visually displays the class imbalance and the distribution of easy versus hard samples across different animal categories in the CounterAnimal dataset.

This figure shows the performance drop in accuracy between easy and hard groups for each animal class in the CounterAnimal dataset. The x-axis represents the class ID, and the y-axis shows the difference in zero-shot accuracy between easy and hard samples, indicating the impact of spurious correlations associated with background changes. A larger drop indicates a stronger reliance on spurious features.

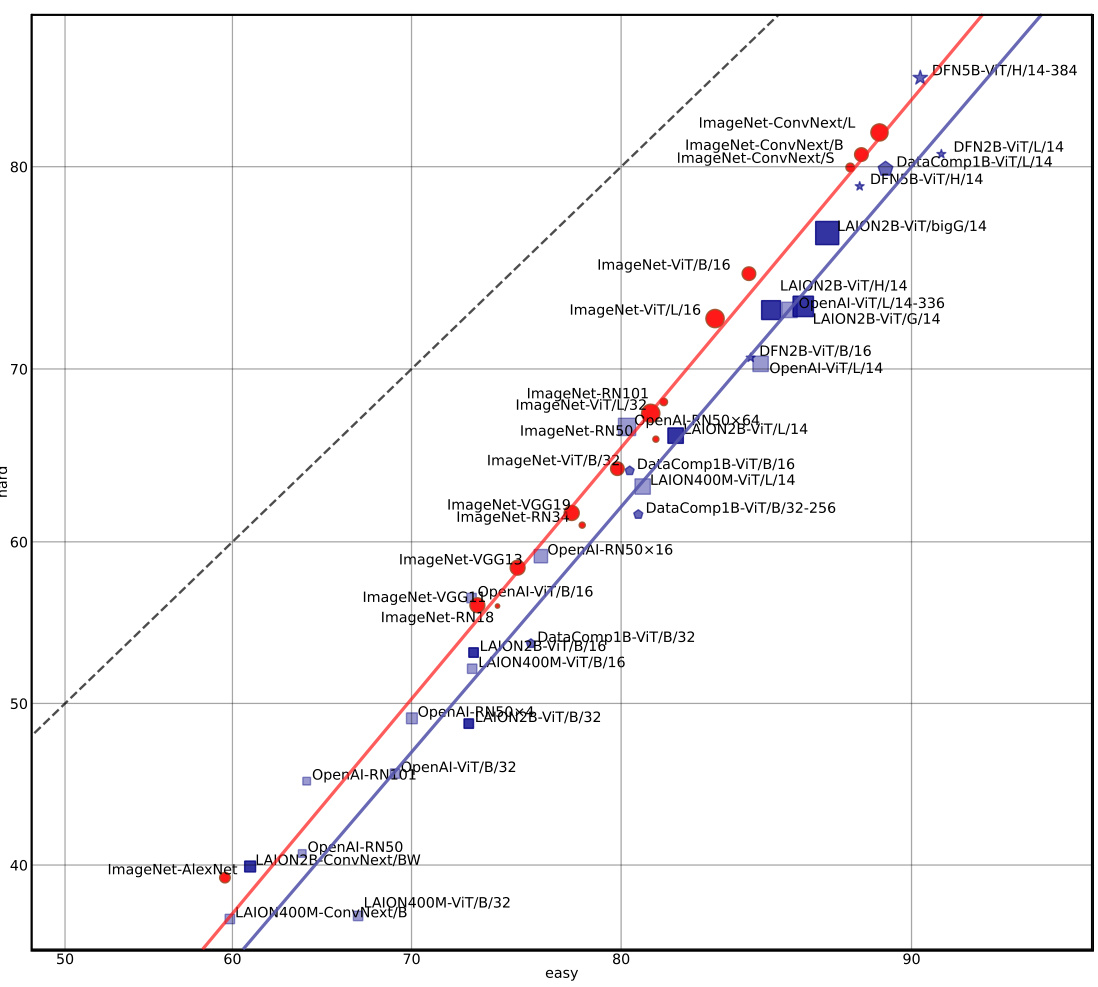
This figure presents a comparison of the performance of different vision models on the CounterAnimal dataset. The x-axis represents the easy group’s performance, and the y-axis represents the hard group’s performance. Each point represents a specific model, with the size of the point indicating the size of the model’s backbone and the color of the point indicating the size of the pre-training dataset used to train the model. The models are categorized as CLIP models, ImageNet models, and advanced Large Vision Language Models (LVLMs). The figure shows that CLIP models are less robust to spurious correlations than ImageNet models and that the robustness of CLIP models can be improved by scaling up the parameters and using higher-quality pre-trained data.

This figure compares the performance of various vision-language models (VLMs) and ImageNet models on the CounterAnimal dataset. It shows the zero-shot accuracy on ’easy’ (images with common backgrounds) versus ‘hard’ (images with less common but plausible backgrounds) samples. The size of the markers indicates the model’s size (backbone), and the color indicates the size of the pre-training data. High-quality pre-training data (DataComp, Data Filtering Networks) lead to improved robustness against spurious correlations.
This figure compares the performance of various CLIP and ImageNet models, including more advanced large vision language models like MiniGPT4 and LLaVA. The x-axis represents the performance on ’easy’ samples (animals in commonly seen backgrounds), and the y-axis represents the performance on ‘hard’ samples (animals in uncommon backgrounds). The size of the markers represents the model size (backbone scale), and their color represents the scale of pre-training data. The plot shows that larger CLIP models generally perform better on both easy and hard samples but still exhibit a performance drop from easy to hard samples, indicating the influence of spurious correlations. In contrast, ImageNet models show greater robustness to spurious correlations.

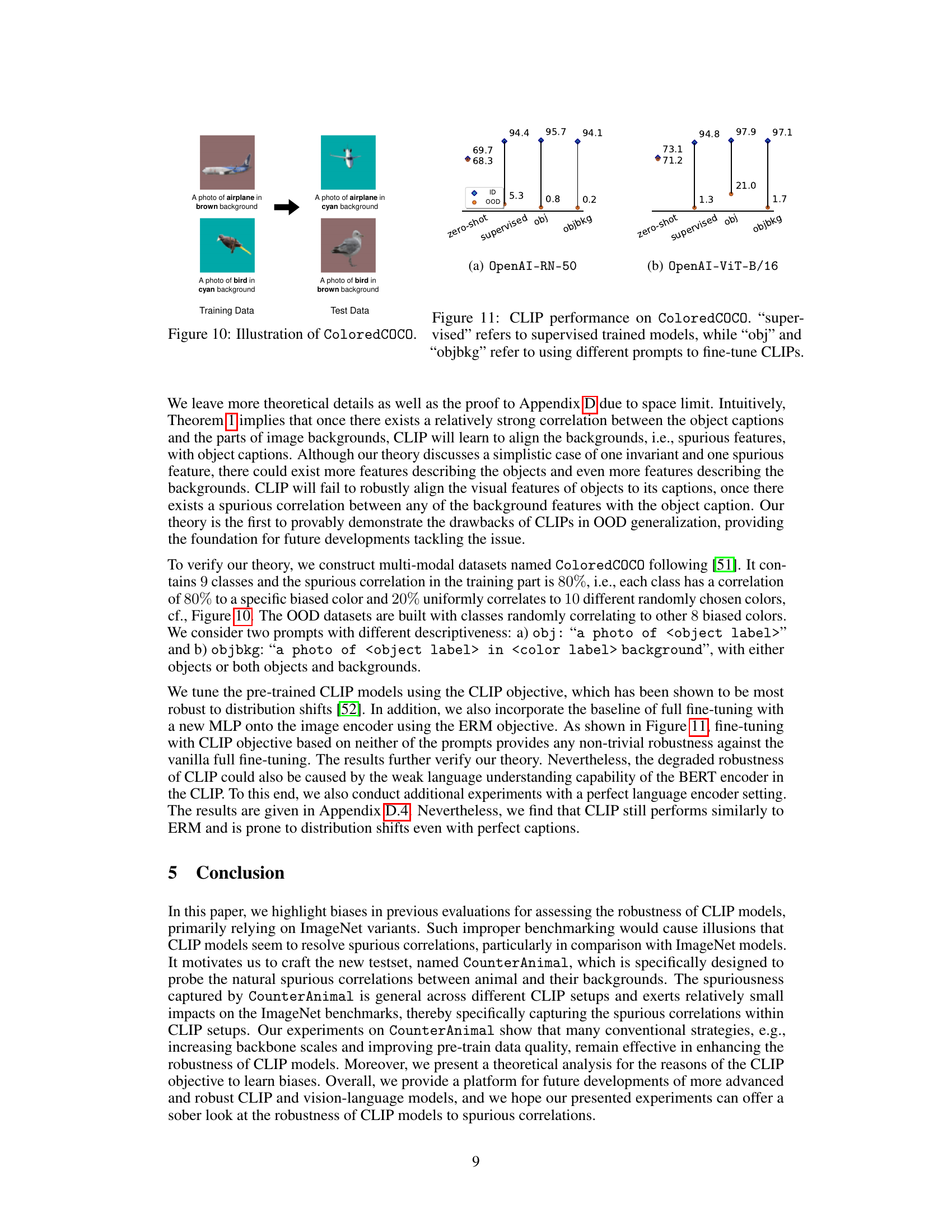
This figure shows examples from the ColoredCOCO dataset. The dataset contains images of objects with backgrounds of a specific color (training data), and test data contains images of the same objects with backgrounds of different colors. This illustrates the concept of spurious correlations, where the model might incorrectly associate the object with the color of its background rather than the object itself. This dataset is used in the paper to evaluate the robustness of CLIP models against spurious correlations.

This figure compares the performance of various vision-language models (VLMs) and ImageNet models on the CounterAnimal dataset. The x-axis represents the performance on the ’easy’ subset of the data, and the y-axis represents the performance on the ‘hard’ subset. The ’easy’ set contains images of animals in typical backgrounds, whereas the ‘hard’ set contains images of the same animals in less common backgrounds. The figure aims to illustrate the models’ robustness to spurious features (correlations learned from the training data which are not generally applicable to new data). The size of the marker indicates the model’s size and color represents the amount of training data used. The diagonal line (y=x) represents a perfect trend where the model generalizes equally across both ’easy’ and ‘hard’ sets. The plot demonstrates that larger CLIP models (larger markers) are more robust to spurious features, while increasing the size of the training dataset does not always improve robustness in the same manner.

This figure shows the distribution of images in the CounterAnimal dataset. Each bar represents an animal class. The height of the left portion of each bar shows the number of ’easy’ images (animals in commonly occurring backgrounds), and the right portion shows the number of ‘hard’ images (animals in less common backgrounds) for that class. This visualization helps to understand the class-wise distribution of samples for each group and provides insights into the dataset’s construction.

This figure shows 16 examples from the MultiColoredMNIST dataset. Each image is a digit from the MNIST dataset, but colored with different shades. This dataset is used to evaluate the robustness of CLIP models to spurious correlations between the digit and its color, where the color acts as a spurious feature. The variations in color across the examples highlight the controlled nature of the spurious correlation introduced.

This figure compares the performance of various models (CLIP, ImageNet models, MiniGPT4, and LLaVA) on easy and hard subsets of the CounterAnimal dataset. The x-axis represents the easy subset performance, and the y-axis represents the hard subset performance. Points closer to the y=x line indicate better robustness against spurious correlations. The size of the markers indicates the size of the model backbone, and the color indicates the scale of the pre-training data. CLIP models trained on higher quality data (CLIP-DC and CLIP-DFN) show better robustness than those trained on standard datasets. ImageNet models demonstrate greater robustness to spurious features than most CLIP models.
This figure shows the comparison of ’easy’ and ‘hard’ performance on the CounterAnimal dataset for various models, including CLIP models with different backbone sizes and training data, ImageNet models, and more advanced Large Vision Language Models (LVLMs). The x-axis represents the ’easy’ group’s performance and the y-axis represents the ‘hard’ group’s performance. The size of the markers indicates the backbone scale, and the color indicates the pre-training data size. The linear fit of the trends helps visualize the effective robustness. The ideal scenario (no bias learned) is represented by the y=x line.
This figure compares the performance of CLIP and ImageNet models on the CounterAnimal-I dataset. CounterAnimal-I is a variation of the CounterAnimal dataset, where the easy and hard splits are determined using ImageNet models instead of CLIP models. The x-axis represents the performance on easy examples, while the y-axis represents performance on hard examples. The diagonal line (y=x) indicates perfect performance; points above the line suggest a model performs better on hard examples, and vice versa. The plot shows that ImageNet models are generally more robust to the spurious correlations captured by CounterAnimal-I than CLIP models.

This figure compares the performance of various vision models (CLIP, ImageNet models, MiniGPT4, and LLaVA) on the CounterAnimal dataset. The x-axis represents the ’easy’ group performance (animals in commonly seen backgrounds), while the y-axis represents the ‘hard’ group performance (animals in less-common backgrounds). Each point represents a specific model, with marker size indicating model scale and color indicating the scale of pre-training data. High-quality pre-trained data (DataComp and Data Filtering Networks) are highlighted. The plots show how well different models perform when the background context changes and how well CLIP-based models handle this shift relative to other model types.

This figure shows the performance drop of CLIP-LAION400M-ViT-B/32 model for each animal class in the CounterAnimal dataset, in the context of ‘1 vs. 1000’ setup. The horizontal axis represents the class IDs while the vertical axis shows the percentage drop in accuracy between the easy group (animals in commonly appeared backgrounds) and the hard group (animals in less commonly but still plausible backgrounds). A higher bar indicates a larger performance drop, suggesting a stronger reliance on spurious features related to background for that specific animal class. The figure visually depicts how much the model’s performance is affected by the background changes for each animal.

This figure shows a comparison of the performance of CLIP and ImageNet models on the CounterAnimal-I dataset, using a 1 vs. 1000 setup. The x-axis represents the performance on the ’easy’ subset of the dataset, while the y-axis represents the performance on the ‘hard’ subset. The diagonal line represents the case where the performance is identical on both easy and hard subsets. Points above this line indicate better performance on the ‘hard’ set compared to the ’easy’ set, and vice versa. The plot shows that CLIP models demonstrate greater sensitivity to the spurious features than the ImageNet models. Different colored markers and sizes might indicate different model architectures or sizes, or the training datasets used.

This figure compares the performance of CLIP and ImageNet models on the CounterAnimal-I dataset. The x-axis represents the easy set’s performance, and the y-axis represents the hard set’s performance. Each point represents a model, and the size of the point may indicate the model’s scale or complexity. The diagonal line represents equal performance on easy and hard sets. Points above the line indicate better generalization than points below. The plot visually demonstrates CLIP models’ reliance on spurious features (their performance is more significantly impacted by the shift from ’easy’ to ‘hard’ groups), while ImageNet models seem less affected.

This figure shows the performance comparison between CLIP and ImageNet models on the CounterAnimal-I dataset using a 1 vs. 1000 setup. The x-axis represents the easy group’s performance, and the y-axis represents the hard group’s performance. Each point represents a specific model, with the size of the point indicating the model scale. The trend lines help visualize how well each type of model handles spurious correlations. The diagonal line (y=x) indicates perfect performance (no difference between easy and hard groups). Points above the line suggest better robustness to spurious correlations than those below.

This figure shows the performance comparison between CLIP and ImageNet models on the CounterAnimal-I dataset. The x-axis represents the easy set performance, and the y-axis represents the hard set performance. The diagonal line represents the ideal case where the performance is equal for both easy and hard sets. The points above the diagonal line indicate that CLIP models are more robust than ImageNet models to spurious correlations. The points below the line indicate that ImageNet models are more robust than CLIP models. The figure demonstrates that CLIP models are more sensitive to changes in background compared to ImageNet models, suggesting that CLIP models rely on spurious correlations more heavily than ImageNet models.
More on tables
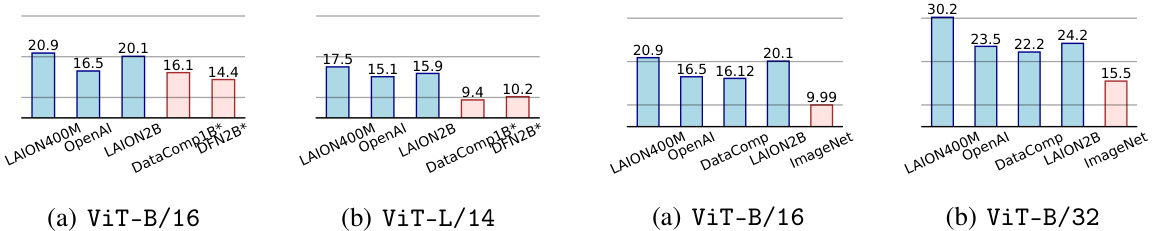
This table presents the results of a zero-shot classification task on the CounterAnimal dataset using various CLIP models. The ’easy’ column shows the accuracy of the model on images with common backgrounds, while ‘hard’ shows accuracy on images with uncommon backgrounds. The ‘drop’ column shows the difference between ’easy’ and ‘hard’ accuracy, representing the model’s sensitivity to spurious correlations based on backgrounds. The table includes models with different backbones (e.g., ViT-B/16, ViT-L/14) and pre-trained on different datasets (e.g., LAION400M, LAION2B, OpenAI, DataComp1B, DFN2B), highlighting the impact of model architecture and training data on robustness against spurious features. Models pre-trained on high-quality datasets are marked with an asterisk (*).
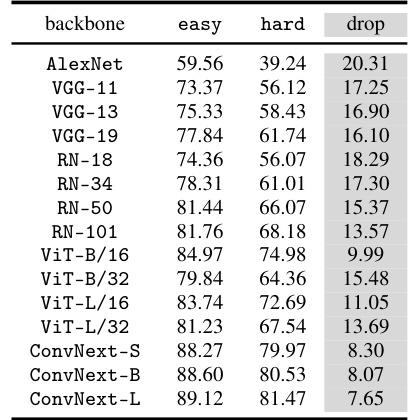
This table presents the results of a 1 vs. 1000 classification task on the CounterAnimal dataset using various ImageNet models. The ’easy’ column shows the accuracy when animals are presented in their common backgrounds, while the ‘hard’ column shows the accuracy in uncommon backgrounds. The ‘drop’ column calculates the difference between easy and hard accuracies, reflecting the impact of spurious correlations on the model’s performance. It demonstrates the comparative robustness of ImageNet models against spurious correlations compared to CLIP models, showing that ImageNet models are more robust to these specific spurious features.
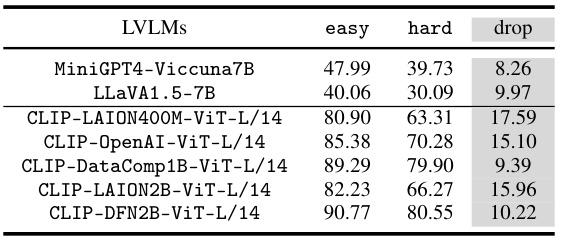
This table presents the results of the 1 vs. 20 evaluation setup on the CounterAnimal dataset. The 1 vs. 20 setup uses the top 20 most confusing classes for each animal class (determined by CLIP-LAION400M-ViT-B/32) as the candidate label space, making the evaluation more computationally efficient for large language models. The table shows the ’easy’ and ‘hard’ group performance and the performance drop for several advanced large vision language models (LVLMs), including MiniGPT4-Viccuna7B and LLaVA1.5-7B, as well as several CLIP models with different backbones and pre-training datasets. Appendix F contains more results for CLIP and ImageNet models.

This table presents the zero-shot accuracy of various CLIP models on the CounterAnimal dataset. The ’easy’ column shows the accuracy when animals are shown in typical backgrounds, while the ‘hard’ column shows accuracy when animals are shown in less common backgrounds. The ‘drop’ column indicates the difference between easy and hard accuracy, representing the impact of spurious correlations. The table also notes which pre-trained datasets had high-quality data (*). This provides a quantitative assessment of how well different CLIP models are robust to spurious background correlations.

This table lists the specific versions of CLIP checkpoints used in the paper’s main experiments. It details the backbone architecture (e.g., ViT-B/16, ViT-L/14), the pre-training dataset (e.g., LAION400M, LAION2B, DataComp1B), and the corresponding checkpoint identifier (e.g., E31, S34B B88K, XL S13B B90K). This information is crucial for reproducibility, allowing readers to replicate the experimental results using the exact same model versions.

This table presents a comparison of the performance of CLIP models and standard supervised learning models on the ColoredCOCO dataset. The ColoredCOCO dataset was specifically designed to evaluate the robustness of models against spurious correlations. The table shows the in-distribution and out-of-distribution performance for various models and approaches, including zero-shot, object-centric, and object-background prompts. The ‘drop’ column indicates the difference in performance between in-distribution and out-of-distribution settings. This table provides empirical evidence for the study’s claims on the limitations of the CLIP objective in achieving additional robustness.

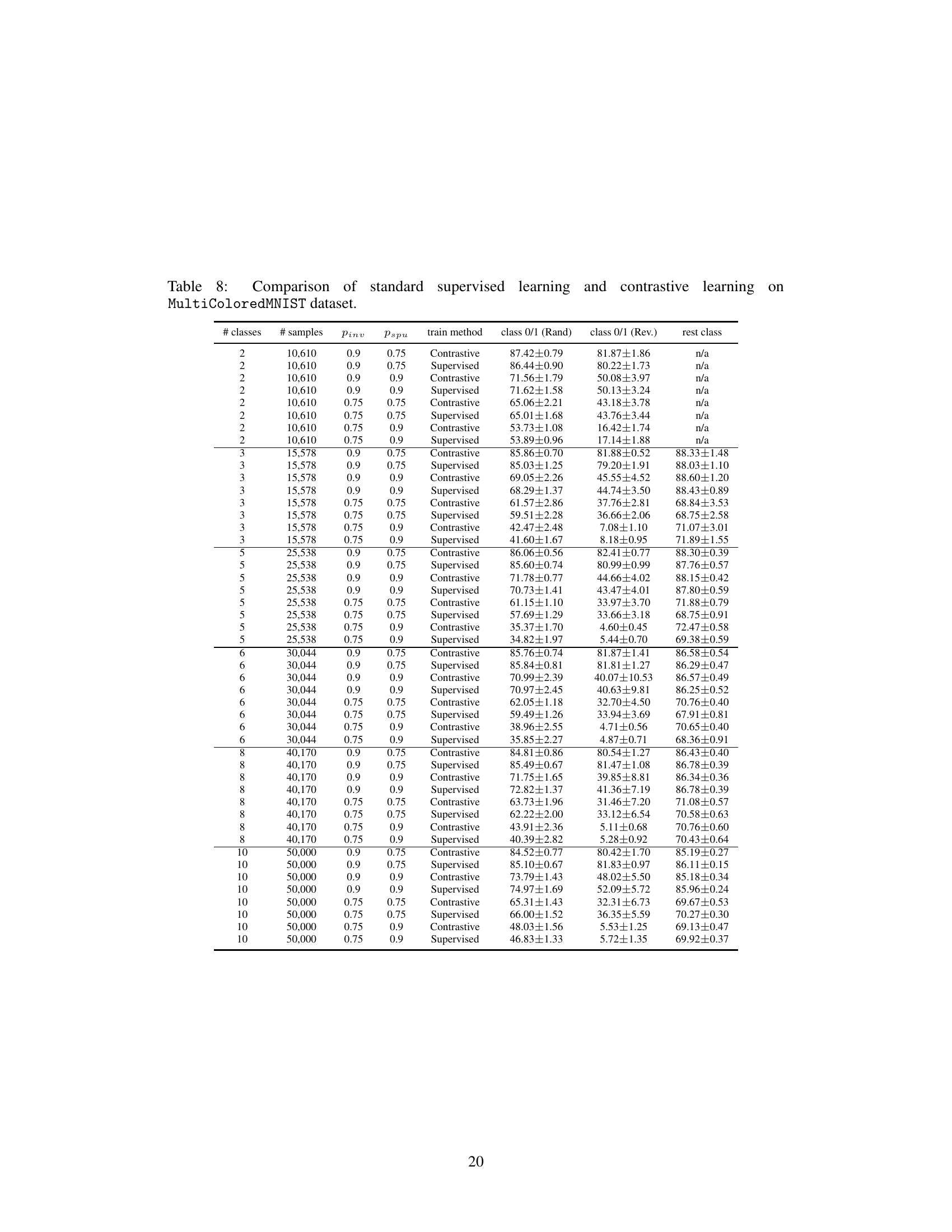
This table presents the results of experiments comparing standard supervised learning and contrastive learning on the MultiColoredMNIST dataset. The results are broken down by the number of classes, number of samples, invariant feature correlation (Pinv), spurious feature correlation (Pspu), and training method (Contrastive or Supervised). For each configuration, the table shows the performance on classification tasks using two different test sets: one where the classes and colors are randomly correlated, and another where they are reversely correlated. The results are presented as mean ± standard deviation of the classification accuracy. The table helps analyze how different training paradigms and data characteristics affect the model’s robustness to spurious correlations.
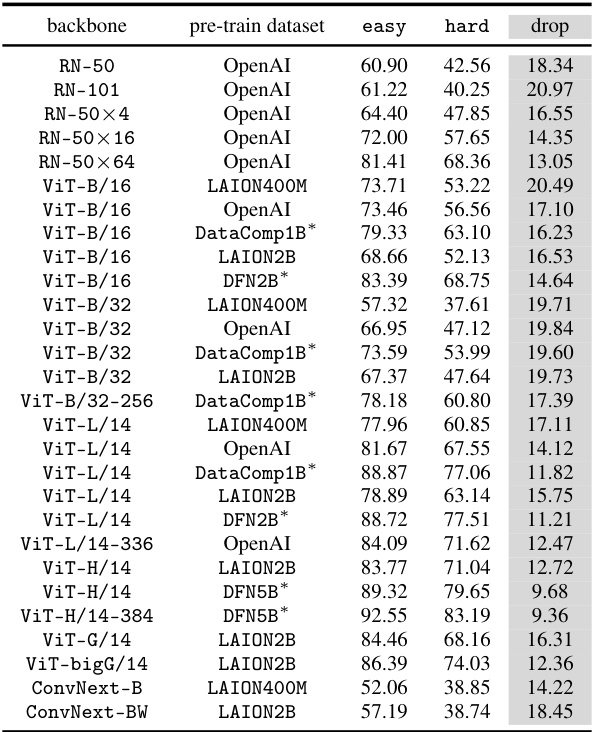
This table presents the zero-shot accuracy results of various CLIP models on the CounterAnimal dataset. It shows the performance on both ’easy’ and ‘hard’ subsets of the data, representing scenarios where the model is expected to perform well and poorly, respectively. The difference between ’easy’ and ‘hard’ accuracies (the ‘drop’ column) indicates the model’s vulnerability to spurious correlations. The table includes different CLIP model architectures (backbones) and pre-training datasets, highlighting the impact of these factors on robustness. Models trained on high-quality datasets are marked with an asterisk (*), allowing for a comparison of performance influenced by data quality.
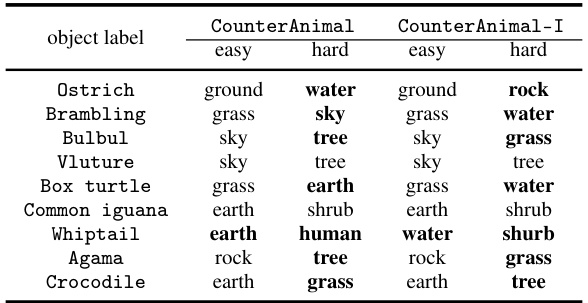
This table compares the animal classes and their corresponding easy and hard background labels in both the original CounterAnimal dataset and a modified version, CounterAnimal-I. The difference highlights how different models (CLIP vs. ImageNet) identify and use spurious correlations within the data. The bolded background names showcase how easy and hard groups differ depending on which model (CLIP or ImageNet) created the splits.
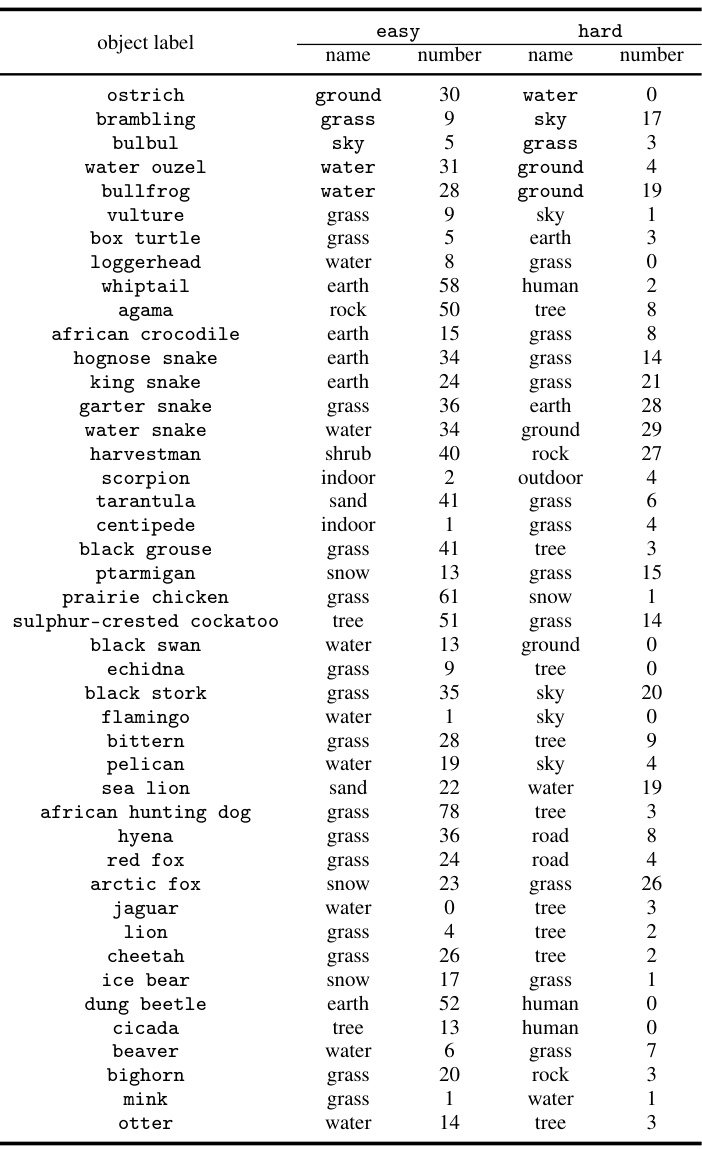
This table presents the results of a zero-shot classification experiment using various CLIP models on the CounterAnimal dataset. The experiment compares performance on ’easy’ and ‘hard’ subsets of the dataset, representing different levels of spurious correlation. The table shows the accuracy achieved on each subset, and the difference between the two (‘drop’), for various CLIP models using different backbones (e.g. ViT-B/16, ViT-L/14) and pre-training datasets (e.g. LAION400M, OpenAI, DataComp1B, LAION2B, DFN2B). Models trained on higher-quality datasets are marked with an asterisk. The ‘drop’ column highlights the sensitivity of CLIP models to spurious features, indicating a reliance on spurious correlations present in the data.

This table presents the zero-shot accuracy results of various CLIP models on the CounterAnimal dataset. The ’easy’ column shows the accuracy when the animal images are presented with their typical backgrounds, while the ‘hard’ column shows the accuracy when presented with less typical, but still plausible, backgrounds. The ‘drop’ column indicates the difference in accuracy between easy and hard conditions. The table highlights the impact of different backbones (model architectures), pre-training datasets, and dataset quality on the model’s robustness to spurious features. Models trained on higher quality data (marked with *) generally show smaller accuracy drops, indicating increased robustness.

This table presents the results of a 1 vs. 1000 classification task on the CounterAnimal dataset using various CLIP models. The ’easy’ and ‘hard’ columns represent the accuracy of the models on image-text pairs with common and uncommon backgrounds, respectively. The ‘drop’ column shows the performance difference between the easy and hard groups. Models trained on higher-quality datasets are marked with an asterisk (*). The table helps to assess the robustness of CLIP models to spurious features by comparing their performance on easy and hard subsets.

This table presents the results of a zero-shot classification experiment using various CLIP models on the CounterAnimal dataset. The experiment compares the performance of CLIP models with different backbones (e.g., ViT-B/16, ViT-B/32, ViT-L/14), pretrained on different datasets (including LAION400M, LAION2B, DataComp1B, and DFN2B). The ’easy’ and ‘hard’ columns represent the accuracy on subsets of the data designed to highlight the reliance of CLIP models on spurious features. The ‘drop’ column shows the difference in accuracy between the ’easy’ and ‘hard’ sets, indicating the sensitivity of the model to spurious correlations. Models trained on higher-quality datasets (marked with an asterisk) generally show smaller accuracy drops.
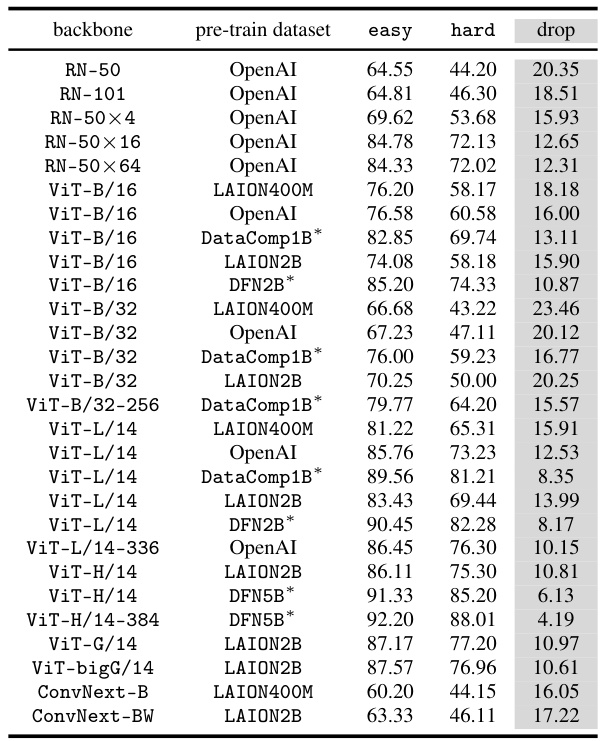
This table presents the zero-shot accuracy of various CLIP models on the CounterAnimal dataset. The ’easy’ column shows the accuracy when the animal images are presented with common backgrounds, while the ‘hard’ column shows accuracy with uncommon backgrounds. The ‘drop’ column is the difference between ’easy’ and ‘hard’ accuracies, indicating the model’s sensitivity to spurious correlations caused by background changes. The table includes models with different backbones (e.g., ViT-B/16, ViT-L/14) and pre-trained on various datasets (e.g., LAION400M, LAION2B, OpenAI, DataComp1B, DFN2B). Models trained on higher quality datasets (marked with *) are expected to show less of a drop in accuracy.

This table presents the results of a zero-shot classification task using various CLIP models on the CounterAnimal dataset. The task involves classifying images of animals into their respective classes. The ’easy’ group represents images with commonly seen backgrounds, while the ‘hard’ group has less common backgrounds, designed to highlight the impact of spurious features. The table shows the accuracy for both groups (’easy’ and ‘hard’), along with the performance drop, which represents the difference in accuracy between the easy and hard groups. The asterisk (*) indicates that the model is trained on high-quality data. This data helps in analyzing CLIP’s robustness to spurious correlations.

This table presents the results of a 1 vs. 20 evaluation setup on the CounterAnimal dataset using various ImageNet models. The ’easy’ and ‘hard’ columns show the model’s accuracy on subsets of data designed to be easily and hardly classified, respectively, based on spurious correlations. The ‘drop’ column indicates the difference between the ’easy’ and ‘hard’ accuracies, representing the model’s vulnerability to spurious features.
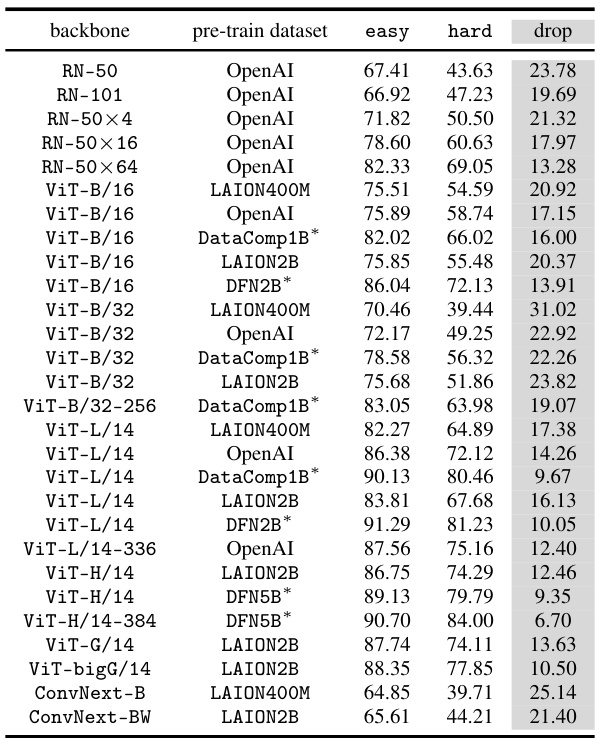
This table presents the results of a zero-shot classification task using various CLIP models on the CounterAnimal dataset. The ’easy’ and ‘hard’ columns represent the accuracy of the model on subsets of the data, where the ’easy’ subset contains images with commonly associated backgrounds and the ‘hard’ subset contains images with less commonly associated backgrounds. The ‘drop’ column shows the difference in accuracy between the easy and hard subsets. This table demonstrates the effect of various model architectures (backbones) and pre-training data (datasets) on the models’ susceptibility to spurious correlations present in the data. High quality data is marked with an asterisk (*).

This table presents the results of a 1 vs. 20 evaluation setup on the CounterAnimal dataset using various ImageNet models. The 1 vs. 20 setup uses a smaller subset of the ImageNet labels (the top 20 most confusing ones, determined by the CLIP model’s performance), making it computationally less expensive than a full 1 vs. 1000 evaluation. The table shows the performance (easy and hard) and the performance drop for various ImageNet models with different backbones. This allows for a comparison of ImageNet model robustness against the spurious correlations captured in the CounterAnimal dataset, using a more efficient evaluation method than the full 1 vs 1000 setup.
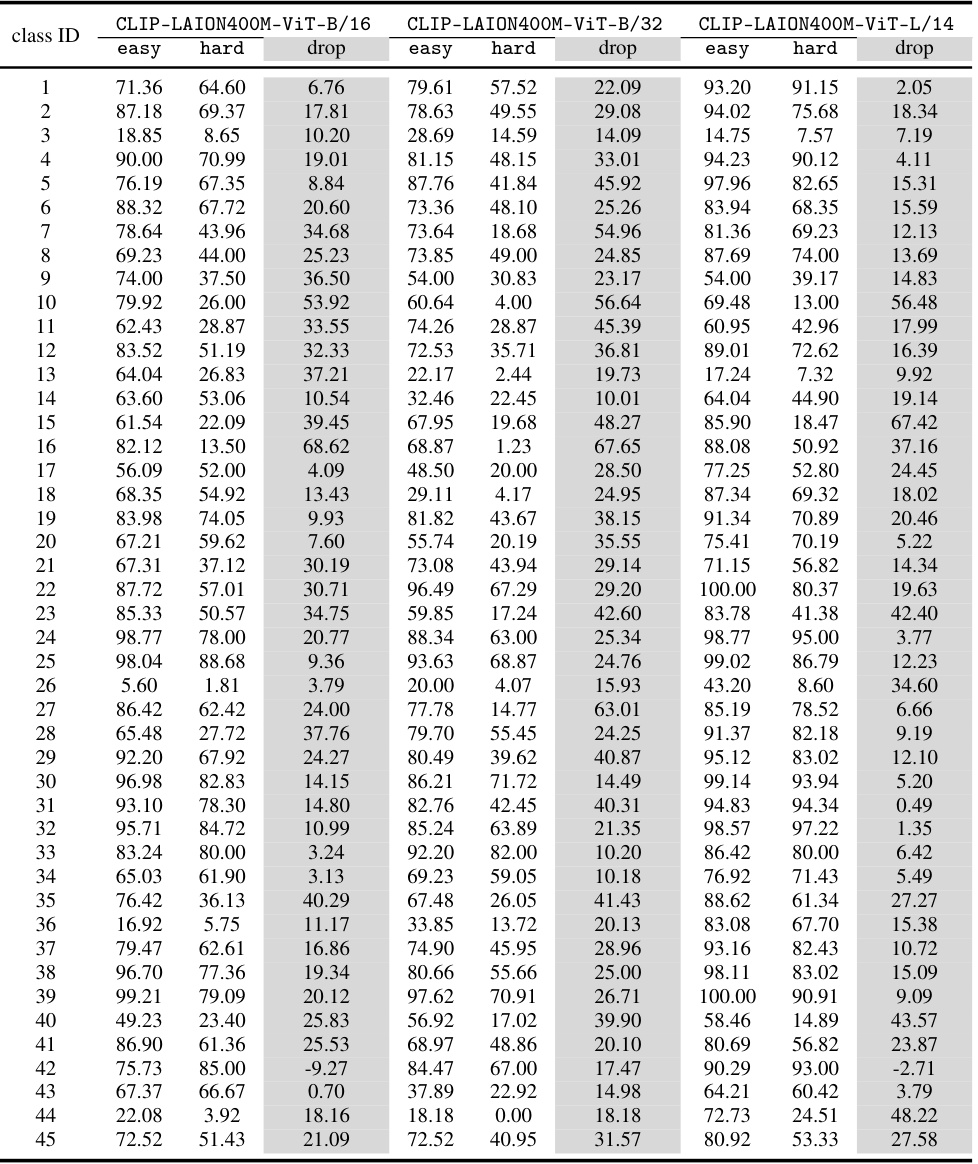
This table presents the results of a zero-shot classification experiment using various CLIP models on the CounterAnimal dataset. It shows the accuracy achieved by each model on ’easy’ and ‘hard’ subsets of the dataset. The ’easy’ subset contains images with common backgrounds, while the ‘hard’ subset contains images with less common backgrounds that challenge the model’s robustness. The table also indicates which pre-trained datasets were of higher quality. The difference between easy and hard subset accuracies reveals the model’s sensitivity to spurious correlations.

This table presents the results of a 1 vs. 1000 classification task, where the goal is to correctly identify the object from 1000 possible ImageNet classes. The table evaluates various CLIP models with different backbones (e.g., ViT-B/16, ViT-B/32, ViT-L/14) and pre-trained on different datasets (e.g., LAION400M, LAION2B, OpenAI, DataComp1B, DFN2B). The ’easy’ and ‘hard’ columns represent the accuracy of the models on subsets of images with commonly and less commonly seen background scenarios, respectively. The ‘drop’ column shows the performance difference between the easy and hard groups, indicating the model’s robustness to background variations. Models trained on high-quality datasets (marked with *) generally show smaller performance drops.
Full paper#