↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Deep reinforcement learning (RL) agents often struggle with non-stationarity during training, leading to performance issues. This paper focuses on Proximal Policy Optimization (PPO), a widely used RL algorithm. Previous research highlighted this issue in off-policy algorithms, but this work extends the analysis to on-policy methods like PPO.
The study reveals that PPO agents are susceptible to representation collapse, characterized by a decrease in the representation rank and capacity loss—similar to off-policy algorithms. This collapse is worsened by higher non-stationarity and is linked to the trust region mechanism in PPO becoming ineffective. Importantly, the paper introduces Proximal Feature Optimization (PFO), a novel auxiliary loss function that regularizes representation dynamics, mitigating the performance issues observed.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in reinforcement learning as it uncovers a critical link between representation collapse, trust region issues, and performance degradation in Proximal Policy Optimization (PPO). It introduces a novel regularization technique to mitigate these problems and provides valuable insights into improving the robustness and stability of deep reinforcement learning algorithms.
Visual Insights#

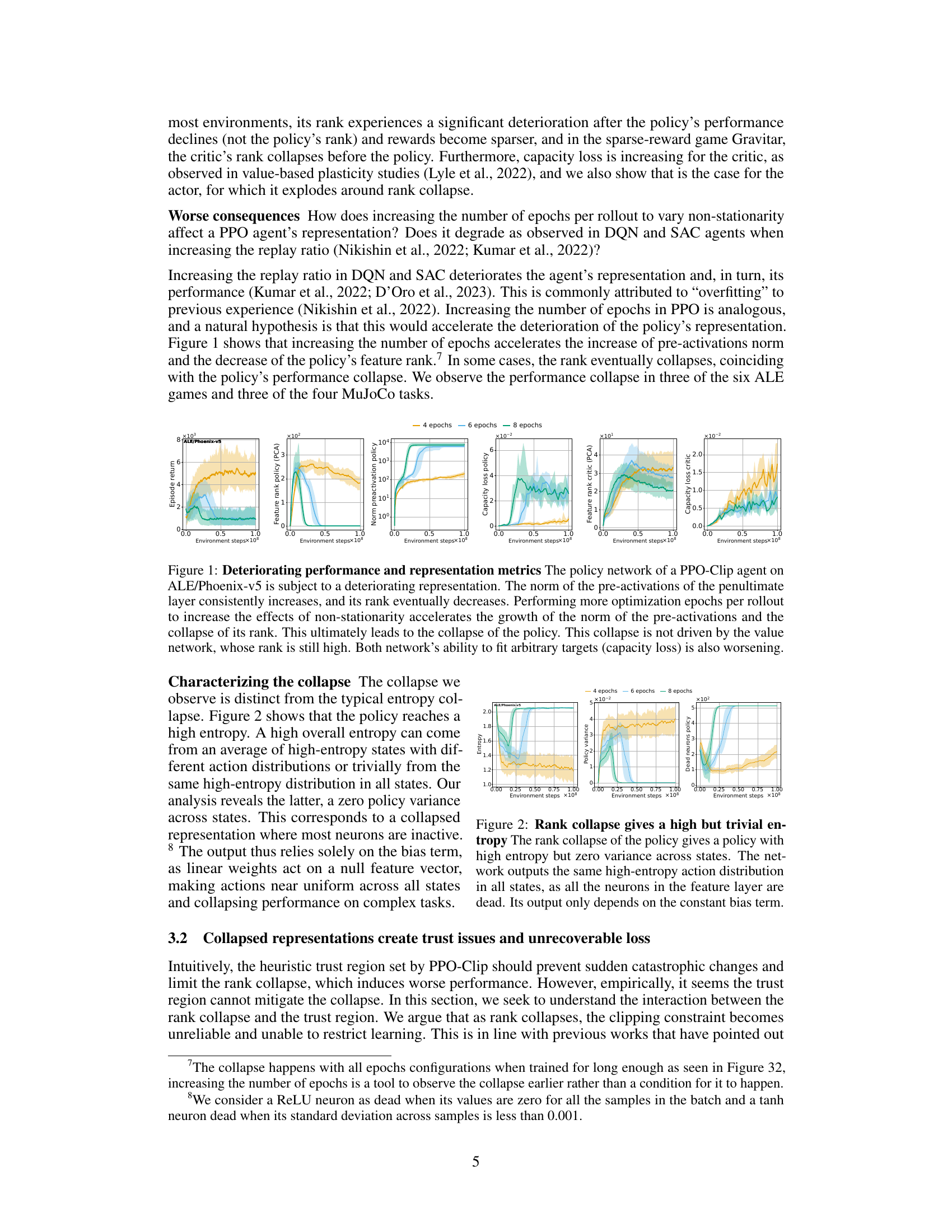
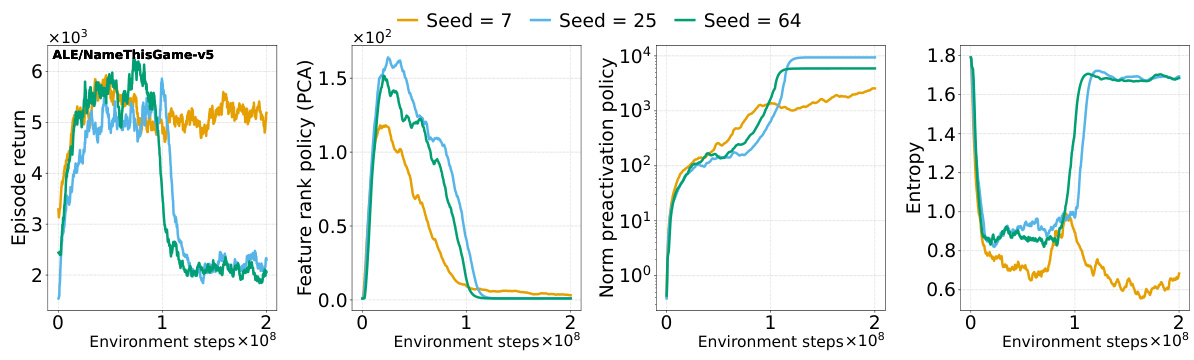
This figure illustrates the deterioration of the policy network representation in PPO, specifically on the ALE/Phoenix-v5 game. As training progresses, the norm of the pre-activations in the penultimate layer steadily increases, while the feature rank (using PCA) decreases. Increasing the number of optimization epochs per rollout exacerbates this trend, leading to a performance collapse. Importantly, this collapse is not due to the value network, whose rank and capacity remain relatively stable. The figure shows how capacity loss (the ability to fit random targets) worsens for both the actor and the critic networks.

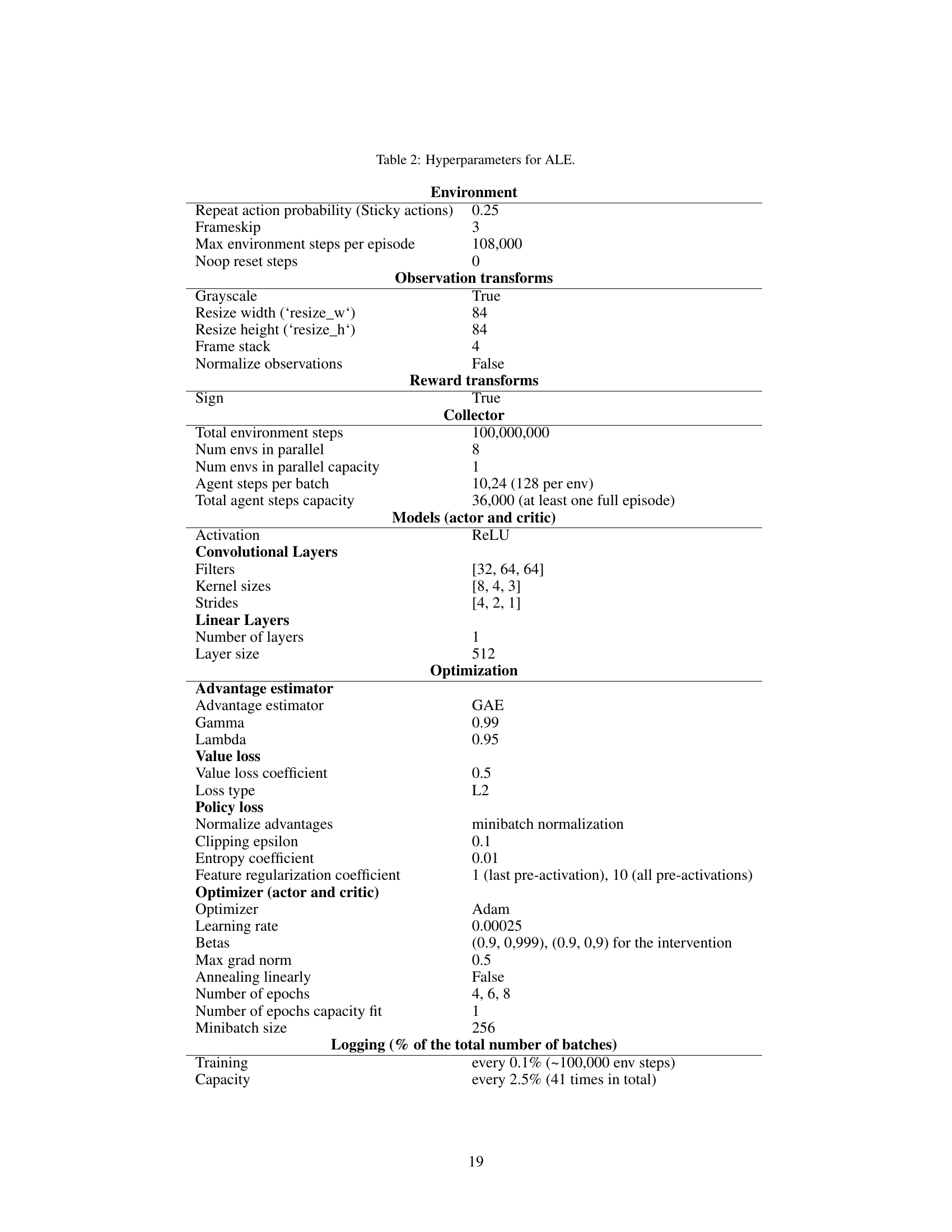
This table lists all the hyperparameters used for the experiments conducted on the Arcade Learning Environment (ALE). It details settings for the environment (e.g., sticky actions, frame skip, observation transformations), the data collection process (e.g., total steps, parallel environments), model architecture (e.g., convolutional and linear layers, activation function), the optimization process (e.g., optimizer, learning rate, loss functions), and logging frequency.
In-depth insights#
PPO’s Rep Collapse#
Proximal Policy Optimization (PPO) is a popular reinforcement learning algorithm known for its stability. However, this paper reveals a critical vulnerability: representation collapse. Under conditions of strong non-stationarity (where the data distribution shifts dramatically during training), PPO’s representational capacity degrades. This isn’t a simple performance drop; it’s a fundamental failure to learn meaningful features, which the authors term a “loss of plasticity.” The trust region mechanism, usually a strength of PPO, becomes ineffective when representations collapse, leading to a catastrophic performance failure. Critically, this collapse impacts the actor (the policy network) even if the critic (the value network) maintains reasonable performance. This suggests that representation quality is crucial for the effective function of PPO’s trust region, and that simply constraining policy updates isn’t enough to prevent fundamental representational failures. The research emphasizes that early detection of representation degradation is essential, suggesting the implementation of auxiliary loss functions to regularize representation dynamics.
Trust Region Issues#
The concept of a trust region in reinforcement learning, particularly within algorithms like Proximal Policy Optimization (PPO), aims to constrain policy updates, preventing drastic changes that might destabilize training. However, this paper reveals that trust regions are not immune to the detrimental effects of representation collapse. When a model’s representation of the environment deteriorates—indicated by reduced feature rank and capacity loss—the trust region mechanism becomes ineffective. This is because the assumptions underlying the trust region, such as gradient orthogonality across states, no longer hold. Collapsing representations lead to highly correlated gradients, making the clipping mechanism designed to confine policy changes within the trust region ineffective. Consequently, the policy can still drastically shift, even with the trust region in place, ultimately resulting in performance collapse. The study highlights the intricate link between representation quality and the effectiveness of the trust region, demonstrating that representation collapse exacerbates trust region failure, creating a vicious cycle that undermines the algorithm’s stability and prevents recovery.
Representation Loss#
Representation loss, a critical issue in reinforcement learning (RL), signifies the degradation of an agent’s ability to effectively represent the environment’s state space. Non-stationarity, inherent in RL due to the ever-changing policy, exacerbates this problem. As the agent’s policy improves, the distribution of states and rewards it observes shifts, making it difficult for the network to maintain a consistent and informative representation. This manifests as a decrease in the rank of the learned representation, meaning the network relies on fewer features to represent a wider range of states, limiting its ability to discriminate between nuanced situations. Consequently, performance suffers, and the agent’s ability to learn new tasks (plasticity) diminishes. Capacity loss, another aspect of representation loss, reflects the reduced ability of the network to fit arbitrary target functions. These issues are often observed in conjunction with the failure of mechanisms such as trust regions, designed to stabilize training, highlighting a deep connection between representation quality and learning stability in RL. Addressing representation loss requires developing effective methods to regularize representation dynamics and enhance the network’s ability to adapt to non-stationary data, thus maintaining plasticity and maximizing performance.
Proximal Feature Opt#
Proximal Feature Optimization (PFO) is presented as a novel technique to address the issue of representation collapse in Proximal Policy Optimization (PPO). PFO regularizes the change in the network’s pre-activations, aiming to keep them within a controlled range during policy updates. This is in contrast to PPO’s trust region mechanism, which focuses on the policy outputs. The rationale is that by controlling the representation dynamics, the method seeks to improve the reliability of the trust region in PPO, preventing its failure under conditions of representation degradation. The paper presents empirical evidence suggesting that PFO effectively mitigates the performance collapse associated with representation collapse in PPO, showing improvements in representation metrics (feature rank and capacity loss) and performance. The intervention is simple to implement, adding an auxiliary loss term to the existing PPO objective, and doesn’t require extensive model changes. The results, however, are environment-specific, suggesting that the effectiveness of PFO might depend on the characteristics of the environment. Further research is suggested to investigate the generalizability of PFO and to explore how it interacts with other factors contributing to representation issues in reinforcement learning.
Future Research#
Future research directions stemming from this paper could explore several promising avenues. Extending the Proximal Feature Optimization (PFO) loss to other RL algorithms beyond Proximal Policy Optimization (PPO) is crucial to assess its generalizability and impact on representation collapse. Investigating the interaction between PFO and other interventions (e.g., Adam modifications) might reveal synergistic effects or unexpected trade-offs. A deeper theoretical analysis could formalize the connection between representation collapse, trust region issues and the observed performance degradation. This involves understanding why trust regions are ineffective under poor representations. Furthermore, a more comprehensive exploration of reward sparsity’s role in exacerbating representation collapse is needed, potentially leading to tailored solutions for sparse reward environments. Finally, applying these findings to continual learning settings and analyzing the long-term effects of representation degradation in those scenarios would be beneficial. These future directions collectively aim at creating robust and adaptable RL agents capable of handling the complexities of non-stationarity.
More visual insights#
More on figures
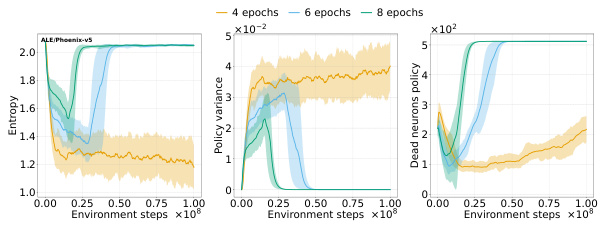
This figure shows the representation dynamics of a Proximal Policy Optimization (PPO) agent trained on the ALE/Phoenix-v5 game. It demonstrates how increasing the number of optimization epochs (which increases non-stationarity) leads to a deterioration in the agent’s representation. Specifically, the norm of pre-activations in the policy network increases, and the feature rank decreases. The capacity loss (both actor and critic) increases as the rank deteriorates. Notably, this collapse is primarily in the actor, not the critic. The figure highlights the connection between representation collapse and performance collapse in PPO.

This figure shows that the policy network in a Proximal Policy Optimization (PPO) agent trained on the ALE/Phoenix-v5 game exhibits deteriorating representation metrics as training progresses. Specifically, the norm of the pre-activations in the penultimate layer consistently increases, while the feature rank (principal component analysis) decreases. Increasing the number of optimization epochs per rollout exacerbates these trends, leading to a collapse in the policy’s performance. Importantly, this collapse is not caused by the value network, which remains largely unaffected. The capacity loss (inability to fit arbitrary targets) also worsens for both the policy and value networks.

The figure shows that the policy network of a Proximal Policy Optimization (PPO) agent trained on the ALE/Phoenix-v5 game exhibits a decrease in representation quality over time, as measured by the norm of pre-activations and feature rank. Increasing the number of optimization epochs per rollout exacerbates this deterioration, ultimately leading to a collapse in the policy’s performance. Interestingly, the value network’s representation remains relatively stable, suggesting that the performance collapse is primarily driven by the actor network’s inability to maintain a good representation. The capacity loss for both the actor and critic networks also increases significantly as the representation quality declines.
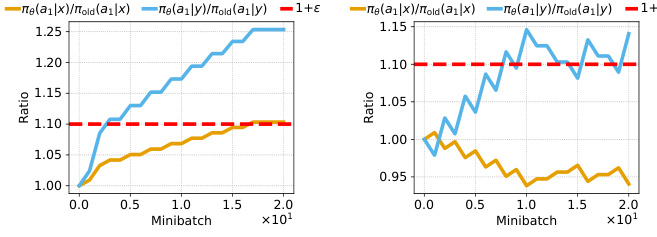
This figure shows a simulation of a toy setting to illustrate the effect of rank collapse on the trust region in PPO. Two state-action pairs (x, a1) and (y, a1) are considered, with α representing the linear relationship between their feature representations (φ(y) = αφ(x)). The left panel (α > 0) demonstrates that when the gradients of the unclipped samples align with those of the clipped samples, the probability ratios will continue to go beyond the clipping limits. The right panel (α < 0) shows that when the gradients counteract, the ratios can be lower than the clipping limits. This illustrates how collapsed representations, where features are highly correlated, can bypass the clipping mechanisms of PPO and lead to trust-region violations.
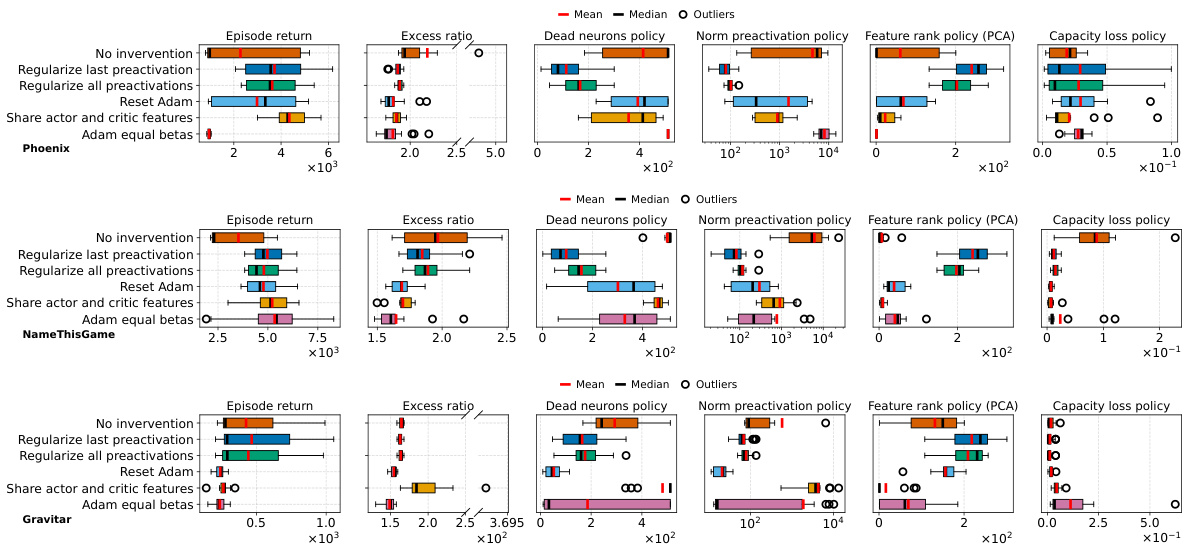
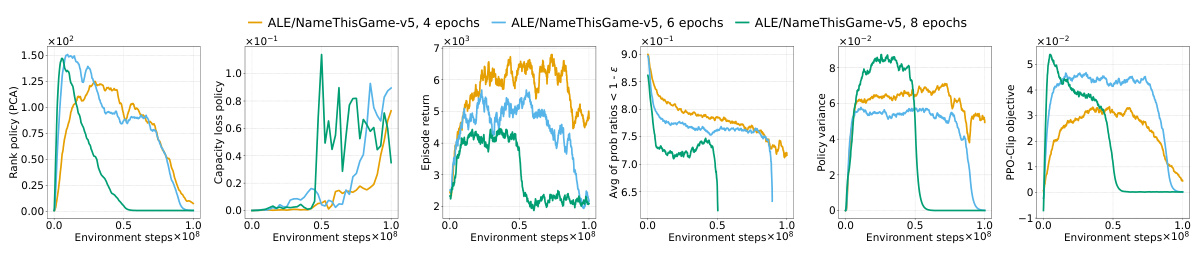
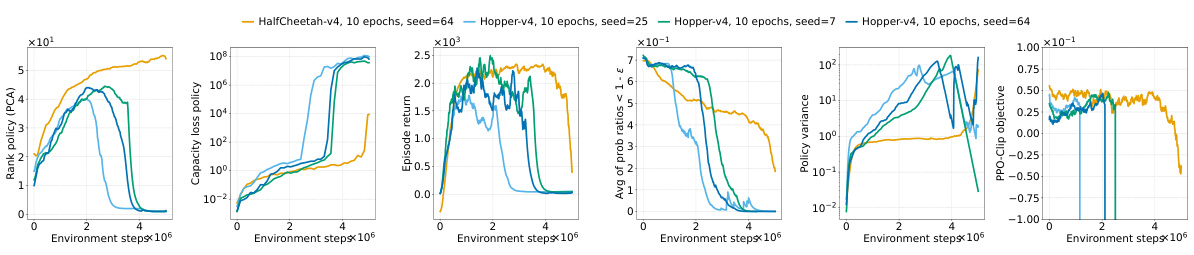
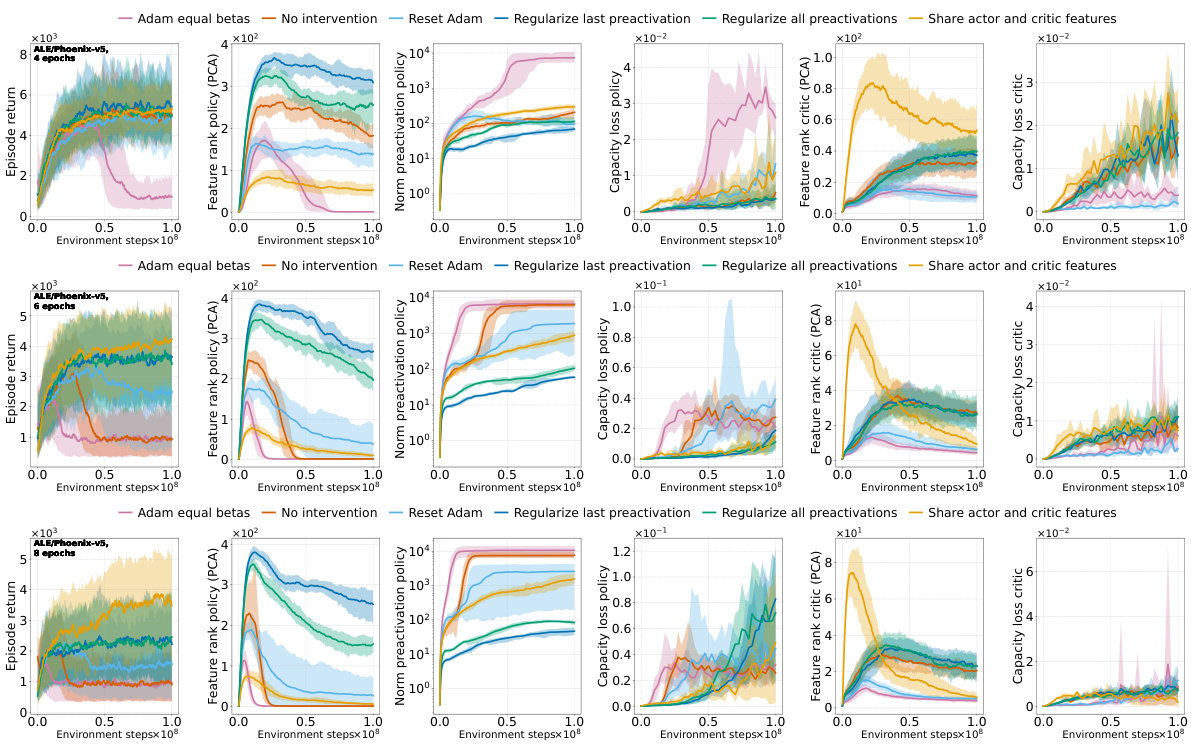
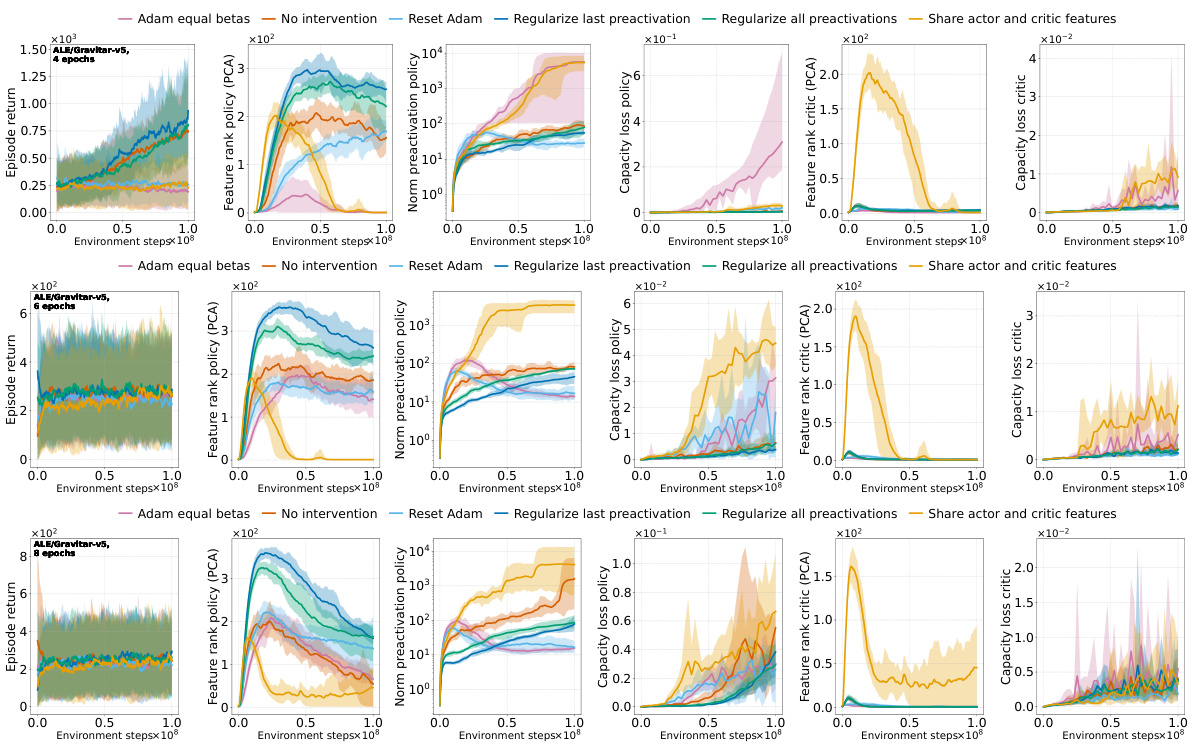
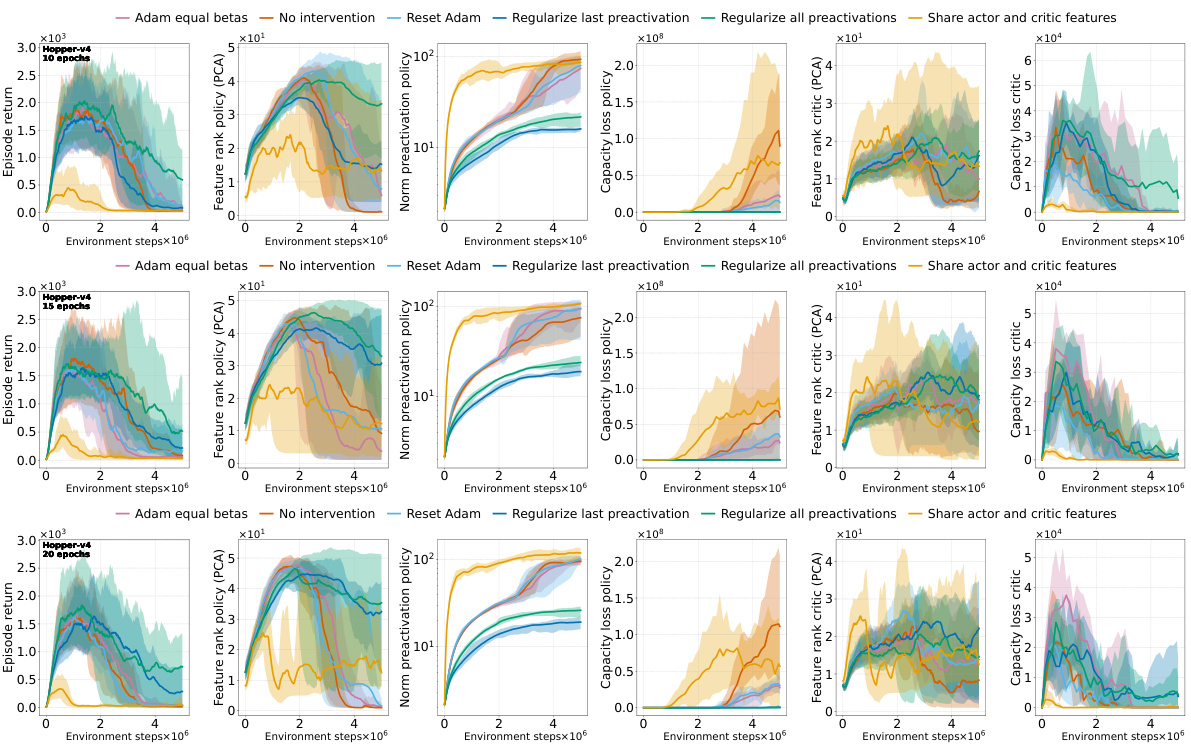
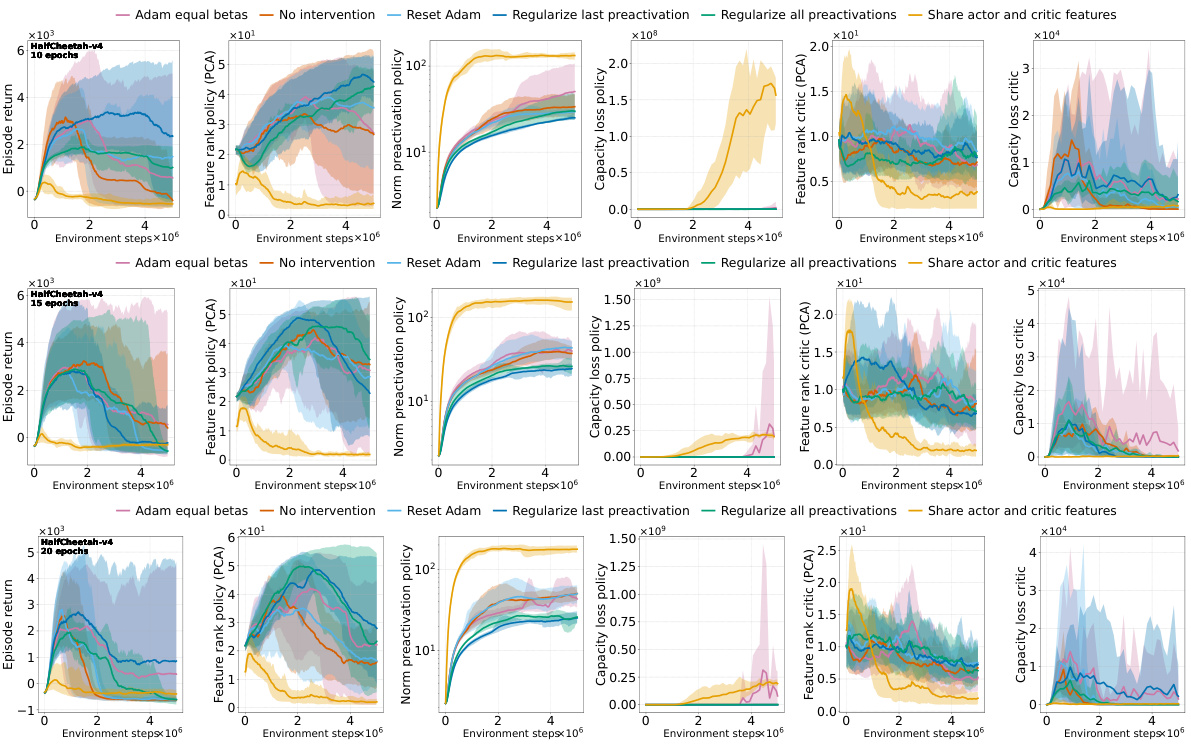
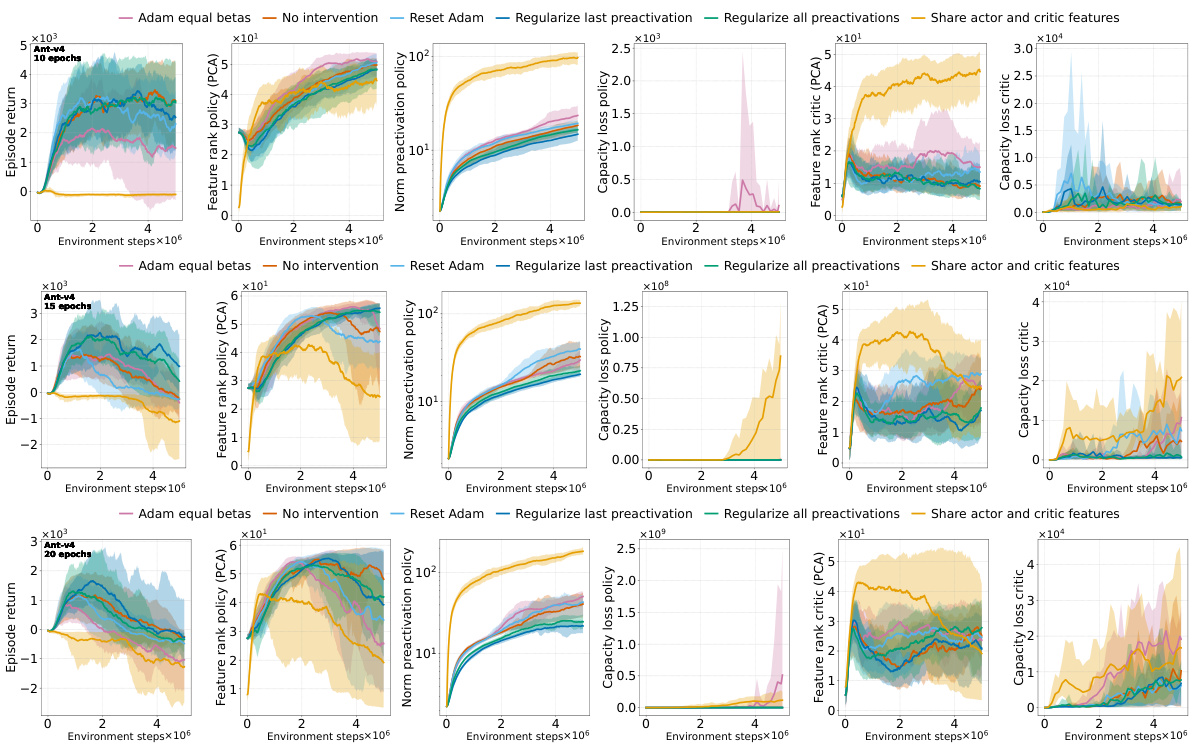
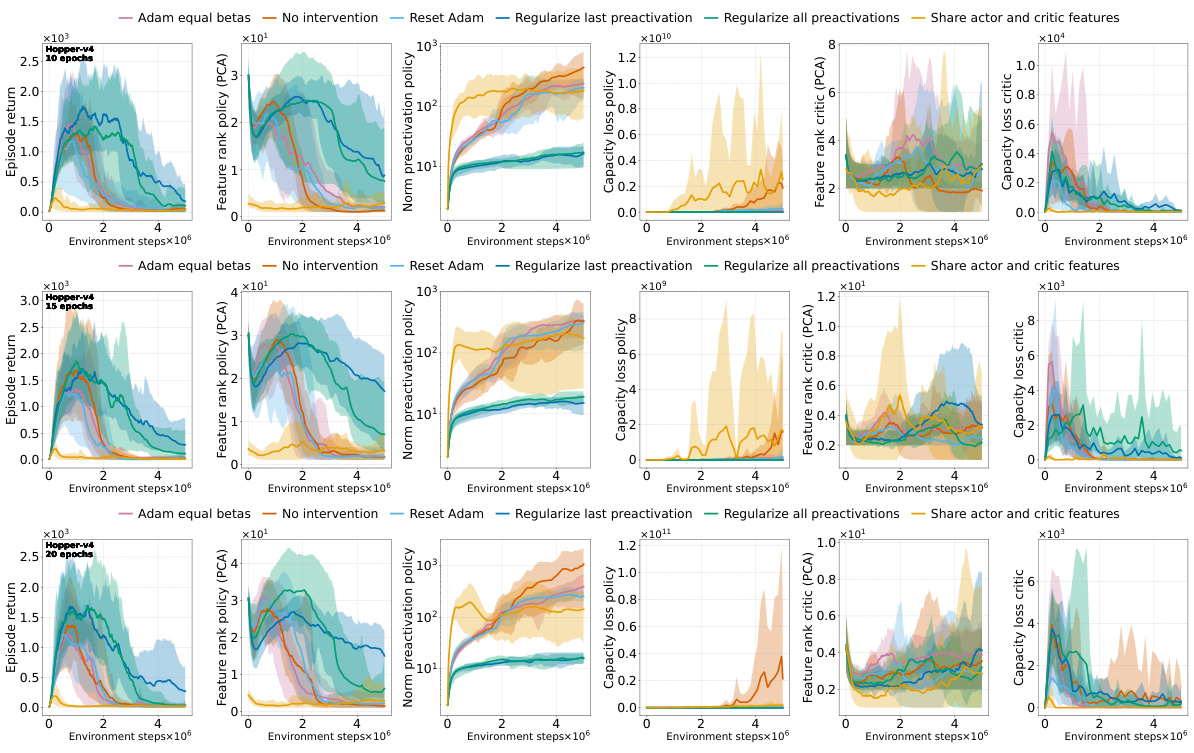
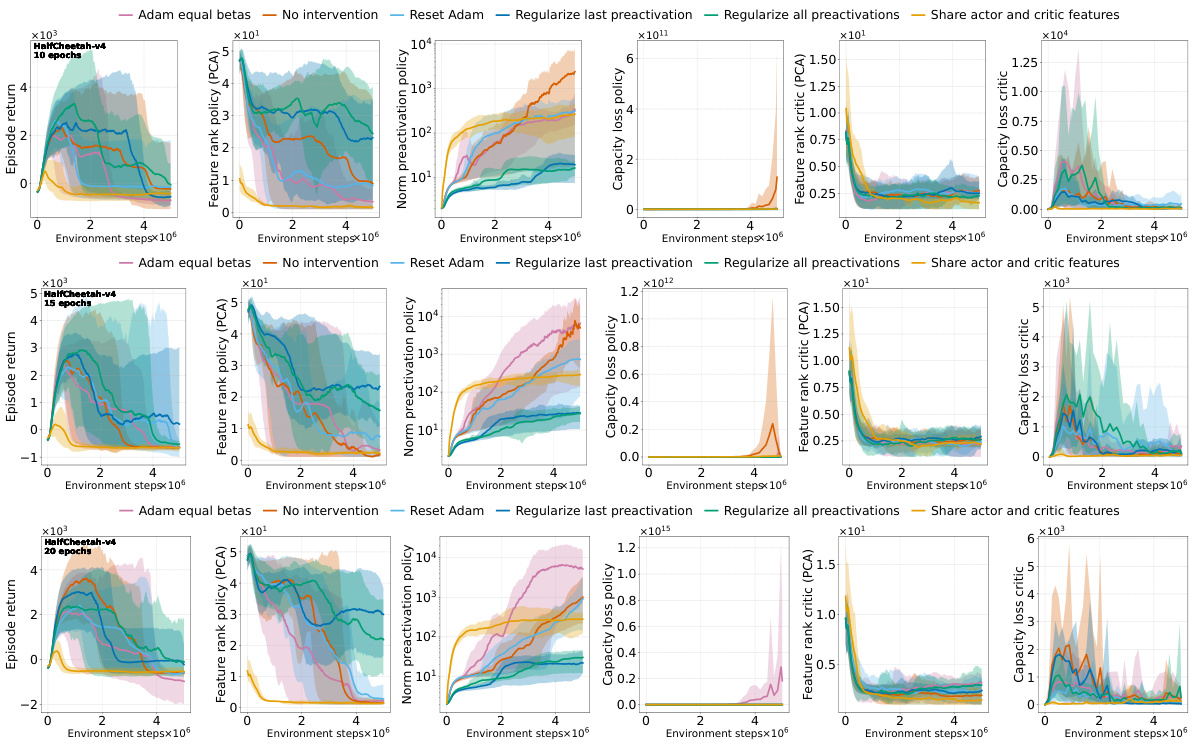
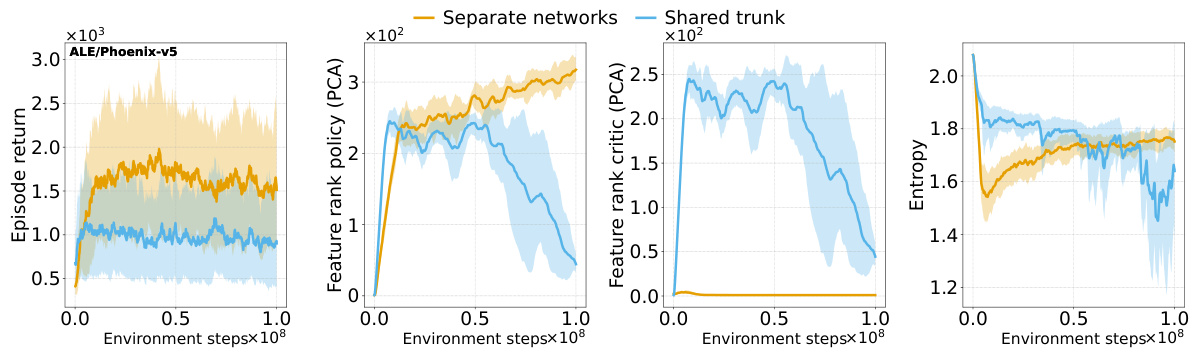
This figure shows the effects of different interventions to mitigate the performance collapse of PPO agents. It compares the results of no intervention, regularizing features (PFO), resetting Adam’s optimizer, sharing the actor-critic trunk, and using Adam with equal betas. The top and middle rows show results for ALE games Phoenix and NameThisGame, respectively, while the bottom row presents results for Gravitar. The results indicate that regularizing features and sharing the actor-critic trunk improve representations and mitigate performance collapse in Phoenix and NameThisGame. However, sharing the trunk negatively impacts performance in Gravitar, possibly due to reward sparsity causing value network collapse.
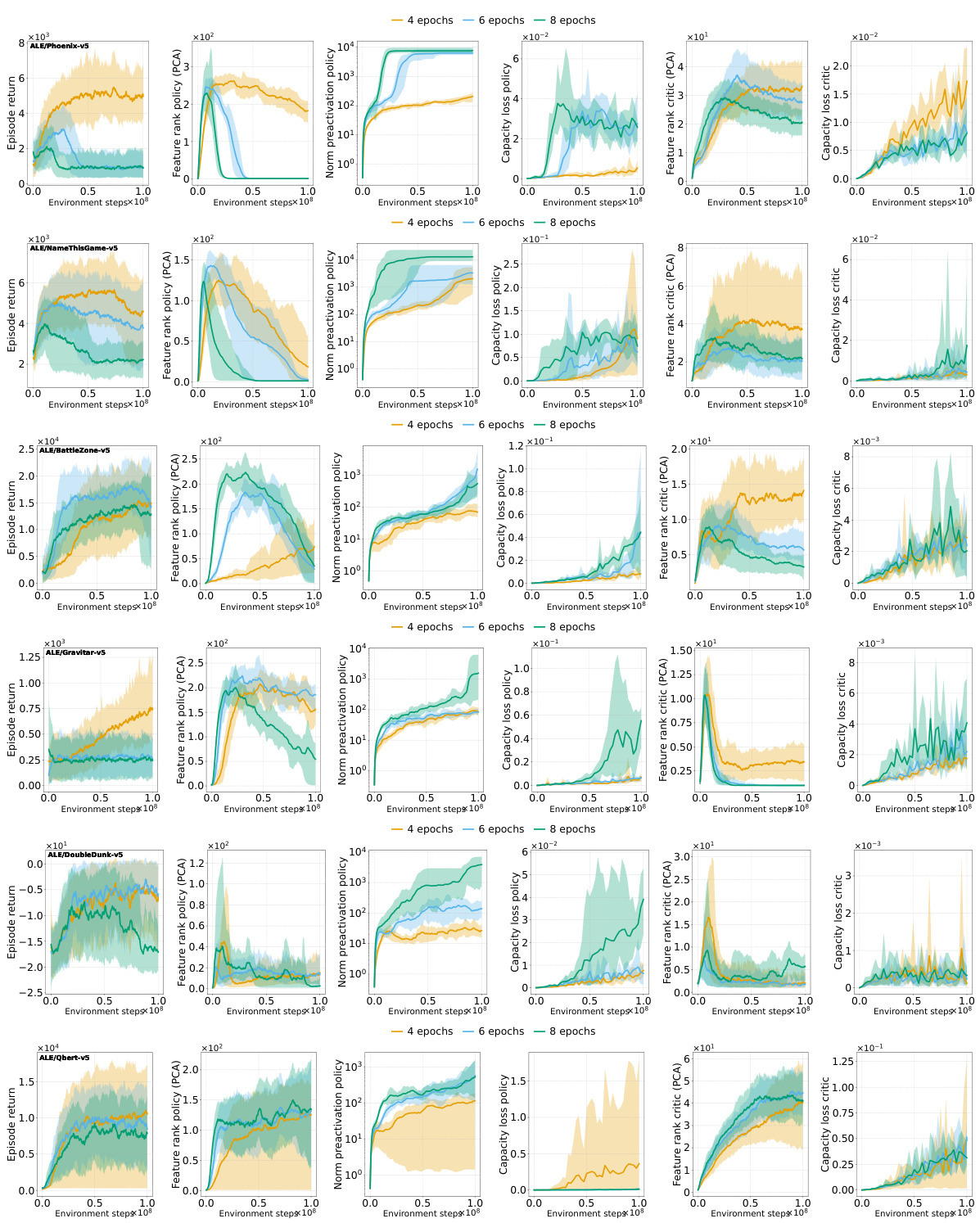
The figure shows how the performance and representation metrics of a Proximal Policy Optimization (PPO) agent on the ALE/Phoenix-v5 game deteriorate over time. Specifically, it illustrates how increasing the number of optimization epochs (a way to increase non-stationarity) worsens the problem. The key metrics tracked are: the norm of pre-activations in the policy network, the feature rank (approximated rank via PCA) of the policy and critic networks, and the capacity loss (ability to fit random targets) of both networks. The results show a clear pattern where increased non-stationarity leads to higher pre-activation norms, lower feature rank, and higher capacity loss, ultimately resulting in a collapse in the agent’s performance. Notably, this collapse is not caused by the critic network (value network).

This figure shows the change in performance and representation metrics for a PPO-Clip agent on ALE/Phoenix-v5. It demonstrates that as training progresses, the norm of the pre-activations of the policy network’s penultimate layer increases while its rank decreases. This deterioration is accelerated when increasing the number of optimization epochs per rollout. The collapse in the policy’s rank coincides with a collapse in performance. Notably, the critic network does not exhibit this same deterioration.
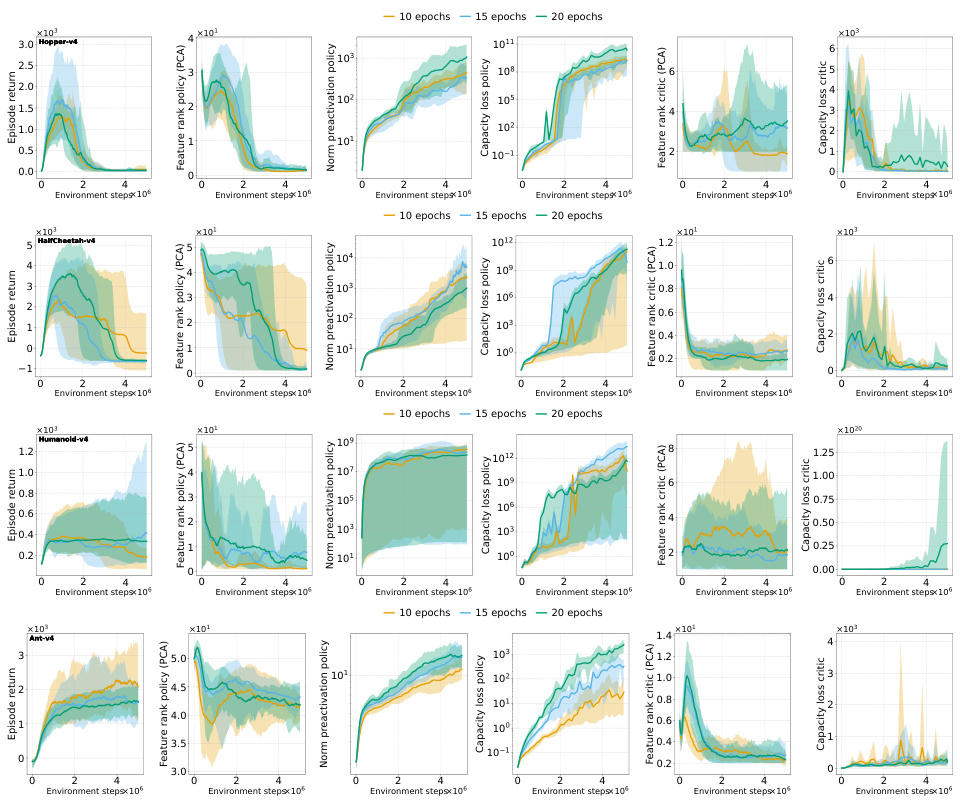
This figure illustrates how the policy network of a Proximal Policy Optimization (PPO) agent trained on the ALE/Phoenix-v5 game exhibits deteriorating performance and representation quality as training progresses. Specifically, it shows that the norm of the pre-activations in the penultimate layer of the policy network steadily increases while the rank (a measure of representational capacity) decreases. Increasing the number of optimization epochs per rollout exacerbates this trend, leading to a performance collapse, while the critic’s representation remains largely unaffected. This highlights the connection between representation collapse and performance collapse, indicating that the trust region mechanism in PPO is ineffective in preventing the representation quality deterioration.

This figure displays how the performance and representation of the policy network of a Proximal Policy Optimization (PPO) agent on the ALE/Phoenix game changes over time. As the agent trains (environment steps increase), the norm of the pre-activations increases, and the rank of the representation decreases. This happens more quickly when more optimization epochs are used per rollout, indicating that non-stationarity exacerbates the issue. The collapse in representation rank corresponds to a collapse in the policy’s performance. This is contrasted with the critic network which remains stable throughout. Additionally, the capacity loss (ability to fit random targets) of both networks shows a clear correlation with the representation collapse.
This figure shows how the performance and representation metrics of a Proximal Policy Optimization (PPO) agent evolve during training on the ALE/Phoenix-v5 game. Specifically, it demonstrates the deterioration of the representation (increasing pre-activation norm and decreasing feature rank) and the eventual collapse in policy performance as the number of training epochs increases. It also highlights that the value network’s representation remains relatively stable, indicating that the performance collapse is primarily driven by the actor network and its capacity loss.

The figure displays the results of training a Proximal Policy Optimization (PPO) agent on the ALE/Phoenix-v5 game. It demonstrates how increasing the number of epochs per rollout (a way to control non-stationarity) leads to a deterioration in the policy network’s representation. Key metrics tracked include the norm of pre-activations (increasing), feature rank (decreasing), and capacity loss (increasing). The deterioration in the policy’s representation directly impacts its performance, leading to a performance collapse. Notably, this collapse is not influenced by the value network, which maintains a high rank and doesn’t experience similar deterioration. The figure visually shows that increased non-stationarity, brought about by more epochs per rollout, negatively impacts representation quality, which in turn leads to performance collapse.
This figure shows that in the ALE/Phoenix-v5 environment, the policy network of a Proximal Policy Optimization (PPO) agent experiences a decline in representation quality over time. As training progresses, the norm of the pre-activations (a measure of the representation’s complexity) increases consistently, while its rank (a measure of the representation’s dimensionality) decreases. This deterioration is accelerated by increasing the number of optimization epochs per rollout, which amplifies the effects of non-stationarity. The consequence is a collapse in the policy’s performance, while the value network remains unaffected. The figure also highlights the worsening capacity loss (the agent’s ability to fit new targets) for both the policy and value networks.
The figure shows the changes in several metrics during the training of a Proximal Policy Optimization (PPO) agent on the ALE/Phoenix-v5 game. It illustrates how the performance of the agent’s policy network degrades over time. This degradation is linked to changes in the representation learned by the network. Specifically, the norm of the pre-activations increases while the rank decreases. Increasing the number of optimization epochs per rollout worsens this effect, leading to performance collapse. Interestingly, the value network’s performance and representation remain relatively stable.

The figure shows the representation and performance metrics of a Proximal Policy Optimization (PPO) agent trained on the ALE/Phoenix-v5 game. It demonstrates that as the number of optimization epochs per rollout increases (increasing non-stationarity), the norm of the policy network’s pre-activations grows, while the feature rank decreases. This deterioration in representation coincides with a collapse in policy performance, but not in the value network’s performance, nor its representation. The capacity loss for both networks also worsens.

The figure displays how the representation metrics (feature rank and capacity loss) and performance of a PPO agent on the ALE/Phoenix-v5 game deteriorate over training time. The deterioration is accelerated by increasing the number of optimization epochs per rollout, which simulates stronger non-stationarity. It shows a consistent increase in the norm of pre-activations, a decrease in feature rank, and a capacity loss that worsens in both the actor (policy network) and the critic (value network). This deterioration is linked to a performance collapse of the agent. Importantly, the critic network maintains a high rank and capacity, suggesting that the performance collapse is primarily driven by the deterioration of the actor’s representation.

This figure displays the results of training a Proximal Policy Optimization (PPO) agent on the Atari game Phoenix. It shows how the representation quality, measured by the norm of pre-activations, rank of the feature matrix, and capacity loss, deteriorates over time, leading to a collapse in performance. Increasing the number of optimization epochs per rollout worsens this degradation, showing the impact of non-stationarity. Interestingly, the value network’s representation remains relatively stable, indicating that the problem is specific to the policy network.

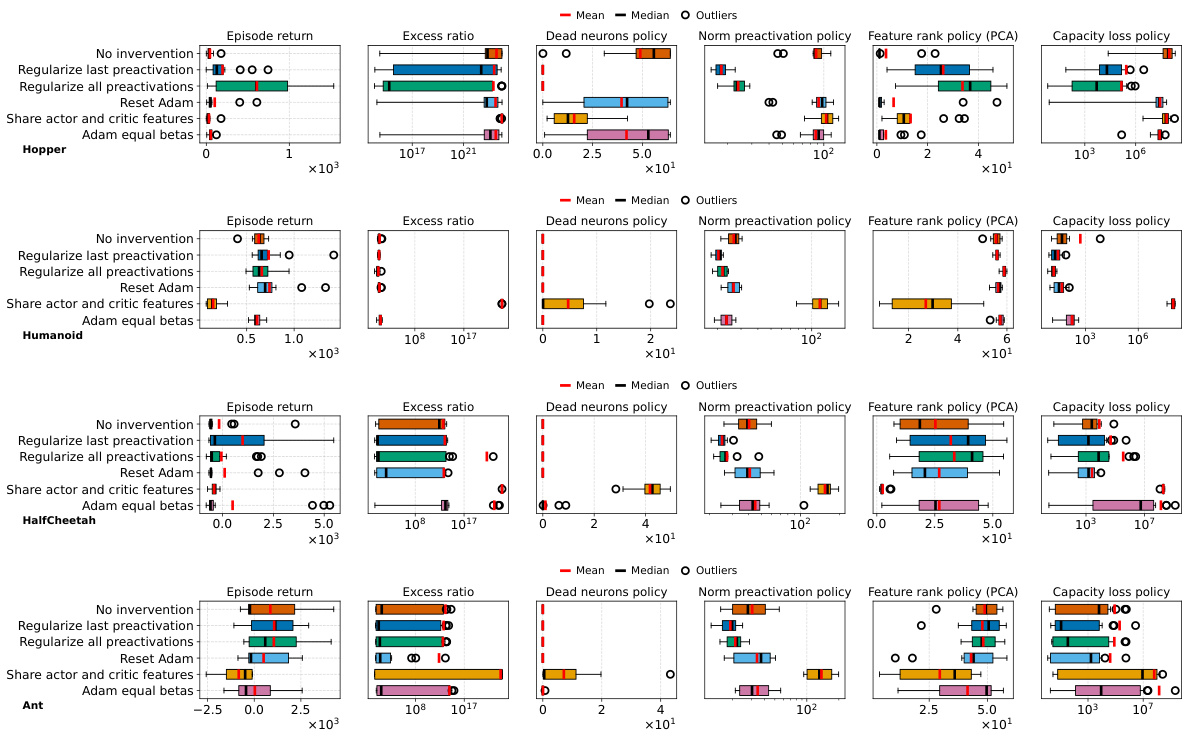
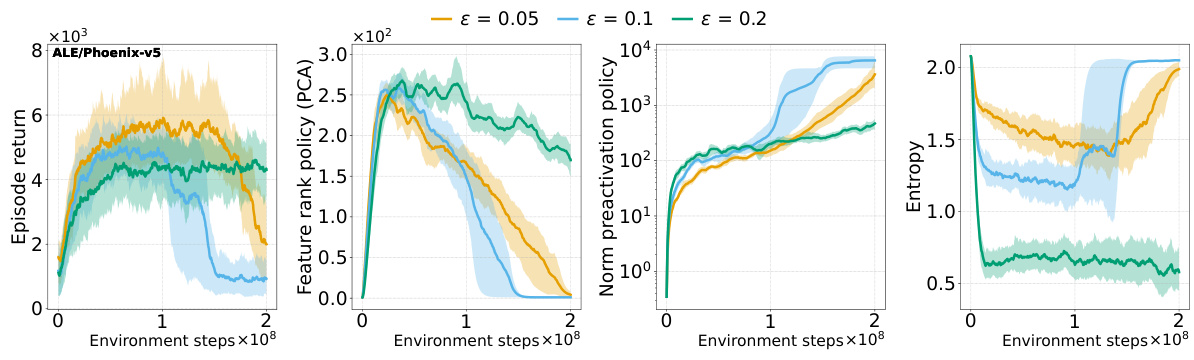
This figure shows the results of several interventions to mitigate the negative effects of non-stationarity on the performance of PPO agents. The interventions include regularizing the difference between features of consecutive policies (PFO), sharing actor-critic features, resetting Adam optimizer, and using equal betas for Adam. The results are presented as boxplots showing the distributions of various metrics (episode return, excess ratio, number of dead neurons, norm of pre-activations, feature rank, capacity loss) across different interventions. The findings show that PFO and sharing the actor-critic trunk are beneficial for most of the games/tasks, while using equal betas for Adam demonstrates improvement on some games but doesn’t prevent collapse. In particular, sharing the actor-critic network in the game with sparse reward (Gravitar) produces a worse policy representation due to rank collapse.
The figure shows the training curves for a Proximal Policy Optimization (PPO) agent trained on the Atari game Phoenix. The curves illustrate how the performance of the PPO agent deteriorates along with the degradation of its representation. As the number of epochs increases, the representation collapse and performance collapse happen earlier during training, while the value network’s performance remains stable. The results highlight a relationship between non-stationarity, representation degradation, and performance collapse.

This figure shows the results of several interventions to mitigate the performance collapse of PPO agents. Boxplots compare the performance (episode return), representation quality (feature rank, pre-activation norm, dead neurons), and trust region behavior (excess ratio) across different interventions and environments (ALE and MuJoCo). It demonstrates that regularizing the feature representations and reducing non-stationarity (with PFO) improves representation metrics and performance. However, sharing the actor-critic trunk negatively impacts representation and performance in sparse reward environments.
This figure shows the results of an experiment where a Proximal Policy Optimization (PPO) agent was trained on the Atari game Phoenix. The top two plots show the norm of the pre-activations and the feature rank of the policy network over the course of training. As the number of optimization epochs per rollout increases, which simulates stronger non-stationarity, the pre-activation norm increases while the feature rank decreases. This leads to a collapse in the policy’s performance. The bottom two plots show the feature rank and capacity loss of the critic network. In contrast to the actor network, the critic network’s representation remains relatively stable even as the policy network collapses, suggesting that the collapse is not primarily driven by the critic’s performance. The capacity loss (ability to fit random targets) metric illustrates worsening model plasticity for both actor and critic networks as training progresses.

This figure shows how the representation quality of the policy network in a Proximal Policy Optimization (PPO) agent deteriorates over time during training. It demonstrates that increasing the number of optimization epochs (which increases non-stationarity) accelerates the decline in representation rank and increases the norm of pre-activations. This deterioration is accompanied by a performance collapse, while the value network remains relatively unaffected. The figure also shows a decrease in the ability of both the policy and value networks to fit arbitrary targets (capacity loss).
This figure illustrates the deterioration of policy representation in a Proximal Policy Optimization (PPO) agent trained on the ALE/Phoenix-v5 game. It shows that as the number of epochs per rollout increases (increasing non-stationarity), the norm of pre-activations in the policy network increases, while its rank decreases. This representation degradation leads to a collapse in policy performance. Interestingly, the critic network’s representation remains relatively stable, highlighting that the performance collapse is primarily driven by the actor’s deteriorating representation and capacity to fit arbitrary targets.
This figure displays the results of training a Proximal Policy Optimization (PPO) agent on the Atari game Phoenix. It shows how several key metrics change over the course of training. The main observation is that as the agent’s performance deteriorates, the representation learned by the policy network degrades. This degradation is characterized by an increase in the norm of pre-activations (a measure of the representation’s complexity), and a decrease in the feature rank (a measure of the representation’s dimensionality). The figure also illustrates that increasing the number of training epochs (which increases the non-stationarity of the training data) exacerbates this phenomenon, leading to a more rapid collapse in performance. Interestingly, the performance of the critic network (which estimates the value function) remains stable, suggesting that the problem is specific to the policy network’s representation learning.

The figure shows how the representation metrics and performance of a Proximal Policy Optimization (PPO) agent change over time during training. Specifically, it illustrates how increasing the number of epochs (iterations) per rollout, which increases non-stationarity, leads to a worsening of the representation (increasing pre-activation norm, decreasing feature rank) and ultimately a collapse in policy performance. Importantly, it shows that this collapse is not due to problems with the value network, but rather problems with the policy network.
This figure displays the performance and representation metrics of a PPO-Clip agent trained on the ALE/Phoenix-v5 game. It shows that as the number of optimization epochs per rollout increases, the norm of the pre-activations in the policy network increases, while its rank decreases, eventually collapsing. This collapse coincides with a drop in performance. Interestingly, the critic network’s representation remains relatively stable, suggesting that the collapse is primarily driven by the policy network’s deteriorating representation. Capacity loss (the network’s ability to fit arbitrary targets) also worsens for both policy and critic networks. The figure highlights the interconnectedness of representation quality, trust region effectiveness, and overall performance in PPO.
The figure shows the impact of increasing non-stationarity on the representation and performance of a PPO agent. As the number of epochs increases, the norm of pre-activations in the policy network increases while its rank decreases. This representation collapse is linked to a performance collapse, unlike the critic, whose performance and representation do not collapse.
This figure shows the deterioration of representation metrics in PPO agents over time. It tracks several metrics for both actor (policy) and critic networks during training on the ALE/Phoenix-v5 game, and plots these against the number of environment steps. It shows that increased non-stationarity (achieved by increasing the number of epochs) exacerbates the degradation of the policy representation and leads to a collapse in performance. This is reflected in a sharp increase in the norm of pre-activations, a decrease in feature rank and a significant increase in capacity loss.

The figure shows the results of training a Proximal Policy Optimization (PPO) agent on the Atari game Phoenix. It demonstrates that as training progresses and the agent improves, the network’s representation starts to degrade. This degradation is characterized by a consistent increase in the norm of pre-activations, while the feature rank (a measure of the representation’s dimensionality) steadily decreases. Increasing the number of training epochs per rollout, which increases non-stationarity, exacerbates this degradation, ultimately leading to a collapse in the agent’s performance. The figure also contrasts the policy network’s degradation with the value network, illustrating that the value network’s representation remains relatively stable. Finally, it shows that the capacity loss for both networks (their ability to regress to random targets) worsens.
This figure shows how the representation and performance of a Proximal Policy Optimization (PPO) agent on the ALE/Phoenix-v5 game deteriorate during training. It tracks several metrics: the norm of pre-activations in the policy network, the feature rank of the policy (using Principal Component Analysis to approximate rank), the capacity loss of the policy network, and the same metrics for the critic network. Increasing the number of optimization epochs per rollout (a way to increase the non-stationarity of the training data) exacerbates the problem, leading to a decrease in the representation rank and an increase in the norm of the pre-activations. This ultimately results in a collapse in performance of the agent, which is not attributable to the critic network’s performance. The capacity loss (inability to fit arbitrary targets) increases for both the actor and critic networks as the representation deteriorates.

The figure displays how representation metrics and performance of a Proximal Policy Optimization (PPO) agent change over training time. The plot shows that the norm of the policy network pre-activations consistently increases, whereas the feature rank decreases, leading to a performance collapse. Increasing the number of epochs per rollout (increasing non-stationarity) aggravates this effect. Interestingly, the value network’s metrics remain stable, indicating the problem is specific to the policy.

This figure displays the results of training a Proximal Policy Optimization (PPO) agent on the ALE/Phoenix-v5 game. It shows that as the number of epochs per rollout increases (increasing non-stationarity), the performance of the agent deteriorates. This is linked to a decline in the quality of the representation learned by the policy network, evidenced by an increase in the norm of pre-activations and a decrease in feature rank. The figure also highlights that the capacity loss (inability to fit arbitrary targets) increases for both the policy and the value network, exacerbating the performance collapse. Interestingly, the collapse primarily affects the policy network, whereas the value network remains relatively unaffected.
The figure shows how the performance and representation metrics of a Proximal Policy Optimization (PPO) agent change during training on the ALE/Phoenix-v5 game. It demonstrates that as the number of epochs (optimization steps) per rollout increases, the norm of pre-activations in the policy network increases while its rank (a measure of representation quality) decreases. This deterioration is linked to a capacity loss (the agent’s inability to fit arbitrary targets) and ultimately leads to a performance collapse. Importantly, the critic network’s representation remains stable, indicating that the problem is specific to the policy network. The figure visually presents the changes in these metrics across different numbers of epochs.
This figure shows how the policy network of a Proximal Policy Optimization (PPO) agent trained on the ALE/Phoenix-v5 game exhibits a deterioration in its representation over time. The norm of the pre-activations in the penultimate layer steadily increases, while the rank of the representation decreases. Increasing the number of optimization epochs per rollout exacerbates this issue, leading to a collapse in the policy’s performance. Notably, the value network remains unaffected by this representation collapse. The figure also demonstrates a worsening of the capacity loss, indicating a decreasing ability of both the actor and the critic to fit arbitrary targets.
This figure shows how the representation quality of the policy network in a Proximal Policy Optimization (PPO) agent deteriorates over time during training. It uses ALE/Phoenix-v5 as an example, demonstrating that as the number of training epochs increases (representing higher non-stationarity), the norm of pre-activations in the penultimate layer increases, and the feature rank (PCA) decreases. This deterioration is linked to a performance collapse in the PPO agent, while the critic network remains relatively unaffected. Notably, both the policy and critic exhibit capacity loss (worsening ability to fit random targets). The figure visually depicts the correlation between representation collapse and performance collapse.
This figure shows that the policy network of a Proximal Policy Optimization (PPO) agent trained on the ALE/Phoenix-v5 game exhibits deteriorating representation metrics over time. Specifically, the norm of pre-activations in the penultimate layer increases while the feature rank decreases. Increasing the number of optimization epochs (which increases non-stationarity) accelerates this trend, ultimately resulting in performance collapse of the agent’s policy. Importantly, the critic network’s performance and representation remain stable throughout, highlighting that the problem is specific to the actor. The capacity loss, which indicates the network’s ability to fit arbitrary targets, increases for both actor and critic, further illustrating the representational decline.

This figure shows that the policy network of a Proximal Policy Optimization (PPO) agent trained on the ALE/Phoenix-v5 game exhibits deteriorating representation metrics over time. Specifically, the norm of pre-activations in the penultimate layer increases steadily, while the feature rank (as determined by Principal Component Analysis) decreases. Increasing the number of optimization epochs per rollout (to amplify the effects of non-stationarity) worsens these trends, ultimately causing a performance collapse of the policy network. Importantly, this collapse is not caused by the value network, whose rank remains high. The capacity loss of both networks, indicating their decreasing ability to regress to arbitrary targets, also increases as the representation deteriorates.

This figure shows the evolution of various metrics during the training of a Proximal Policy Optimization (PPO) agent on the Atari game Phoenix. It demonstrates that as the training progresses, the norm of the policy network’s pre-activations increases while its rank decreases. Increased training epochs (more non-stationarity) exacerbates this effect, ultimately leading to a performance collapse. Interestingly, the critic network’s performance and representation remain relatively stable, highlighting that the collapse is specific to the actor. The capacity loss of both actor and critic also increases, indicating reduced learning ability.

The figure shows how the representation metrics (norm of pre-activations, feature rank, and capacity loss) of the policy and value networks in a Proximal Policy Optimization (PPO) agent evolve during training, particularly as the number of optimization epochs per rollout increases. The results show a deterioration of the representation and ultimately lead to performance collapse.

The figure displays the dynamics of representation metrics and performance of a Proximal Policy Optimization (PPO) agent trained on the Atari game Phoenix. It shows that as the agent’s performance deteriorates, the norm of its policy network’s pre-activations increases while its rank decreases, indicating a deterioration of the representation. Increasing the number of optimization epochs per rollout exacerbates these effects, leading to a performance collapse. Importantly, this collapse is not caused by a failure of the value network, highlighting that the problem is specific to the policy network’s representation learning.

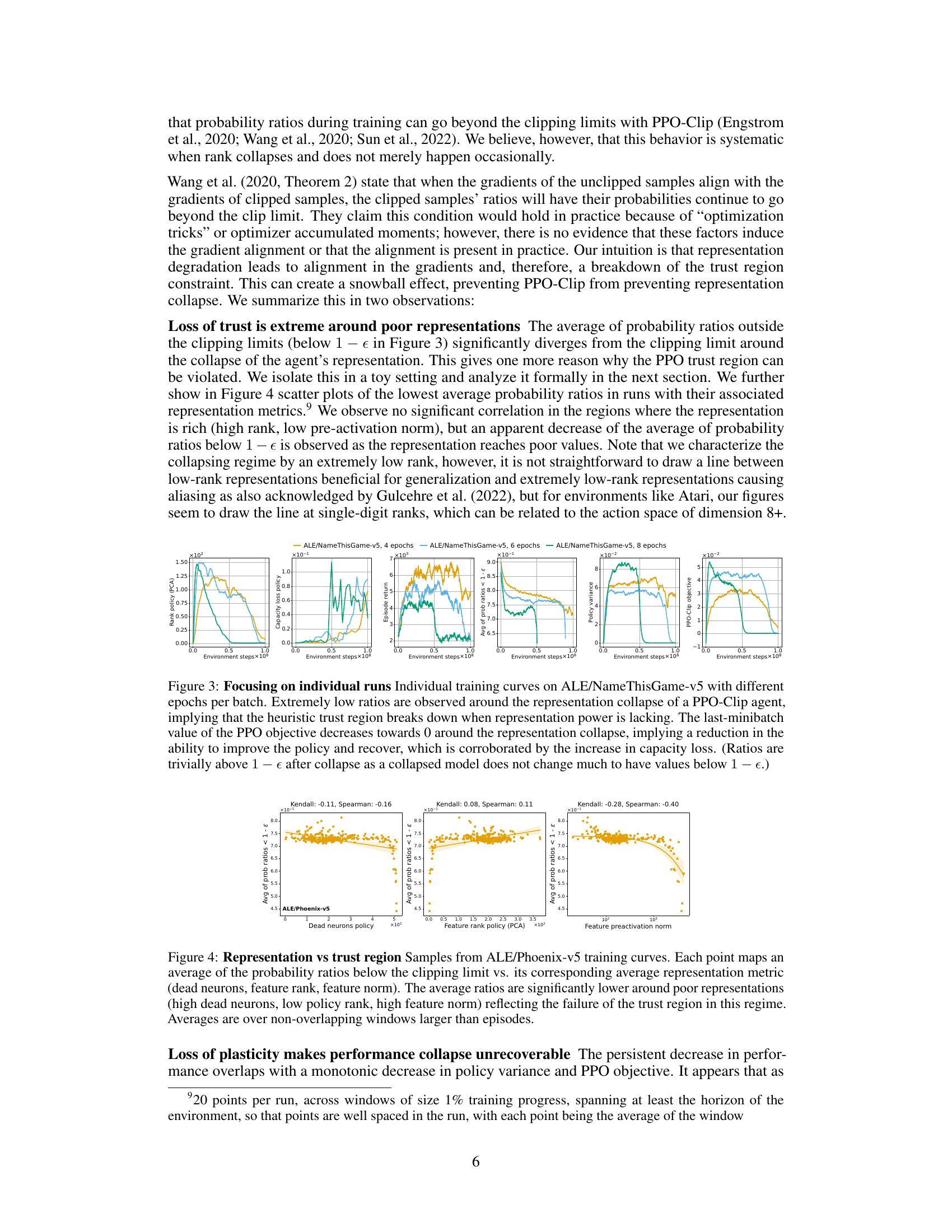
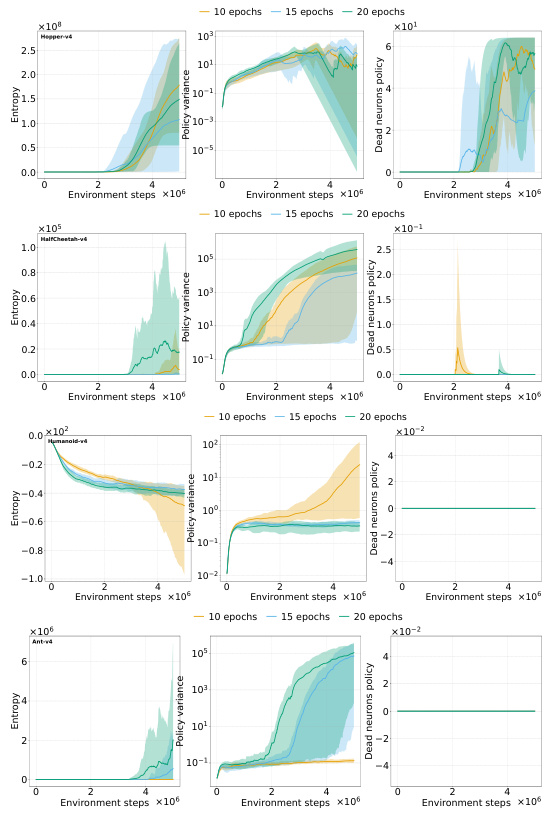
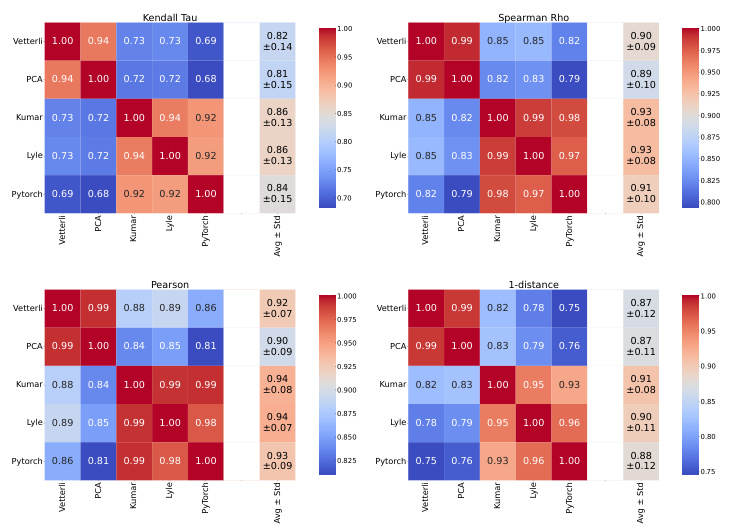
This figure shows the relationship between the representation quality of a PPO agent and the effectiveness of its trust region mechanism. Each point represents the average probability ratios that fall outside the clipping limits of the trust region and an average representation metric (dead neurons, feature rank, and feature norm). The results demonstrate that when the representation quality deteriorates (characterized by a high number of dead neurons, a low feature rank, and a high feature norm), the probability ratios significantly drop below the clipping limit, suggesting a failure of the trust region to prevent catastrophic changes to the policy in this regime.
More on tables

This table lists the hyperparameters used in the toy setting to simulate the effects of rank collapse on the trust region, as shown in Figure 5 of the paper. It includes details about the environment (sampling of states and actions), the policy network architecture, and the optimization process (clipping epsilon, optimizer, learning rate, minibatch size, number of epochs, and number of steps). This setup is designed to create a simplified scenario to demonstrate how the PPO trust region constraint can be bypassed when representations collapse.

This table lists the hyperparameters used for the Arcade Learning Environment (ALE) experiments in the paper. It includes details about the environment setup (sticky actions, frameskip, image resizing), the data collection process (number of environments, total steps), model architecture (convolutional and linear layers), the optimization process (optimizer, learning rate, clipping epsilon, entropy bonus), and logging frequency.
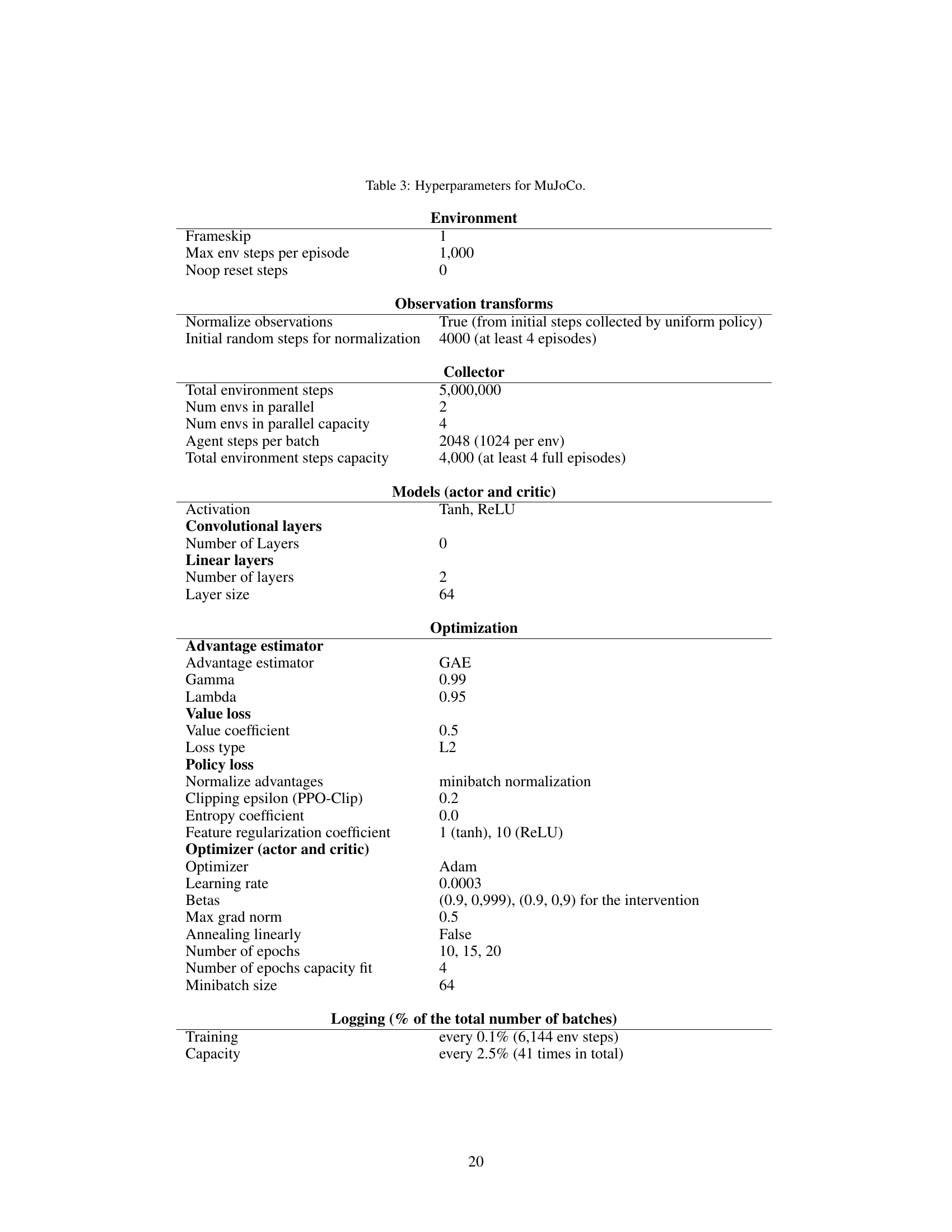
This table lists the hyperparameters used in the MuJoCo experiments. It covers environment settings (frameskip, maximum steps per episode, etc.), observation transformations (normalization), data collection details (total steps, number of parallel environments), model architecture (activation functions, layer sizes), optimization parameters (advantage estimator, value loss, policy loss, learning rate, betas, etc.), and logging frequency for various metrics (training, capacity). The table also indicates whether or not minibatch normalization and linearly annealing were applied. In short, it provides a complete specification of the experimental setup for the MuJoCo reinforcement learning tasks.
Full paper#