↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Visual reinforcement learning (RL) struggles with generalization across different environments due to overfitting on task-irrelevant visual features. Existing solutions using auxiliary tasks often fail to sufficiently address this issue. The distribution shift between training and deployment settings, such as variations in lighting or backgrounds, exacerbates this problem.
The paper introduces SMG, a novel method leveraging image reconstruction. SMG employs two separate model branches for task-relevant and -irrelevant feature extraction. By incorporating two consistency losses, SMG further emphasizes task-relevant features. Experiments on challenging benchmark tasks demonstrate SMG’s superior performance, achieving state-of-the-art generalization, particularly excelling in video-background and robotic manipulation settings. SMG’s plug-and-play design makes it easily integrable with existing RL algorithms.
Key Takeaways#
Why does it matter?#
This paper is crucial because it tackles the significant challenge of generalization in visual reinforcement learning (RL), a critical hurdle in deploying RL algorithms to real-world applications. The proposed SMG method offers a novel, effective solution to this problem, with potential impacts across various RL domains, particularly robotics and those involving complex visual backgrounds. Its plug-and-play architecture makes it easily adaptable to existing RL frameworks, fostering wider adoption. Further research building on SMG could lead to advancements in handling variations in visual data, improving sample efficiency, and driving more robust RL systems.
Visual Insights#
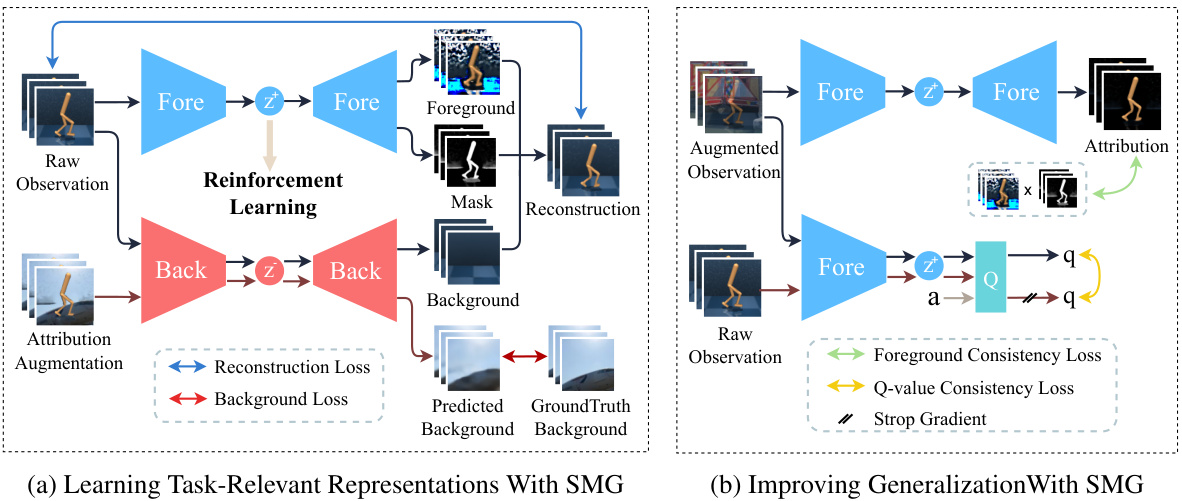
This figure illustrates the architecture of the Separated Models for Generalization (SMG) method. Panel (a) shows how SMG learns task-relevant representations by separating foreground and background information from raw visual observations using two separate model branches. Each branch has its own reconstruction path, resulting in foreground and background reconstruction losses. Panel (b) demonstrates how SMG improves generalization using two consistency losses: foreground consistency loss and Q-value consistency loss. These losses guide the agent’s focus toward task-relevant areas, improving its ability to generalize to unseen environments. The figure uses arrows to visually represent the flow of data and the types of losses involved in the process.
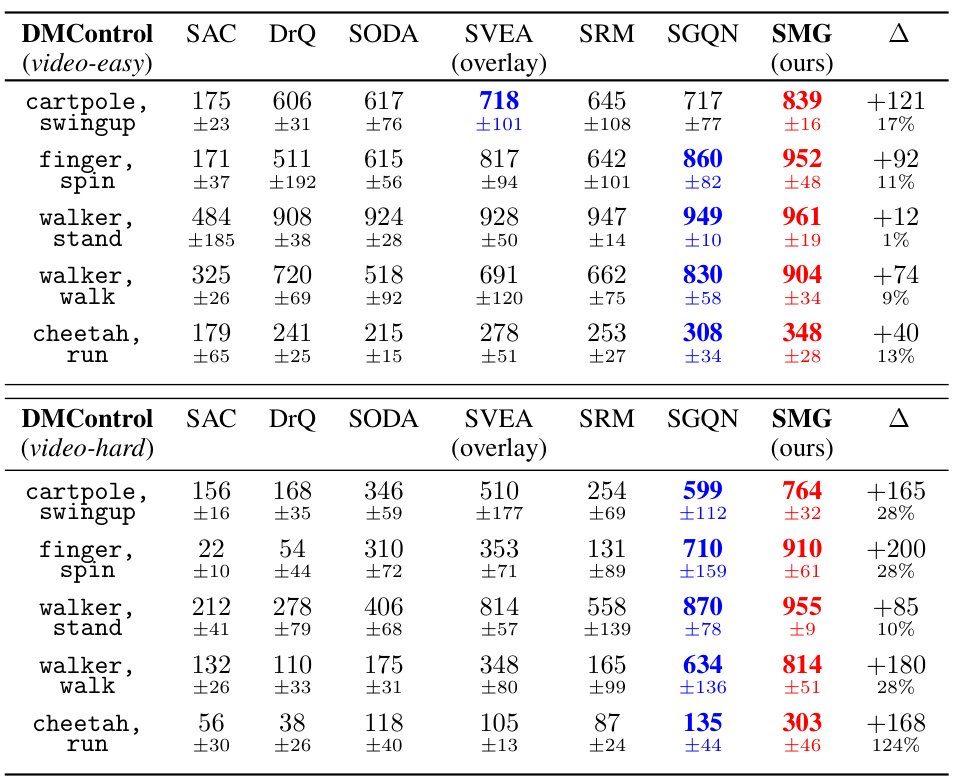
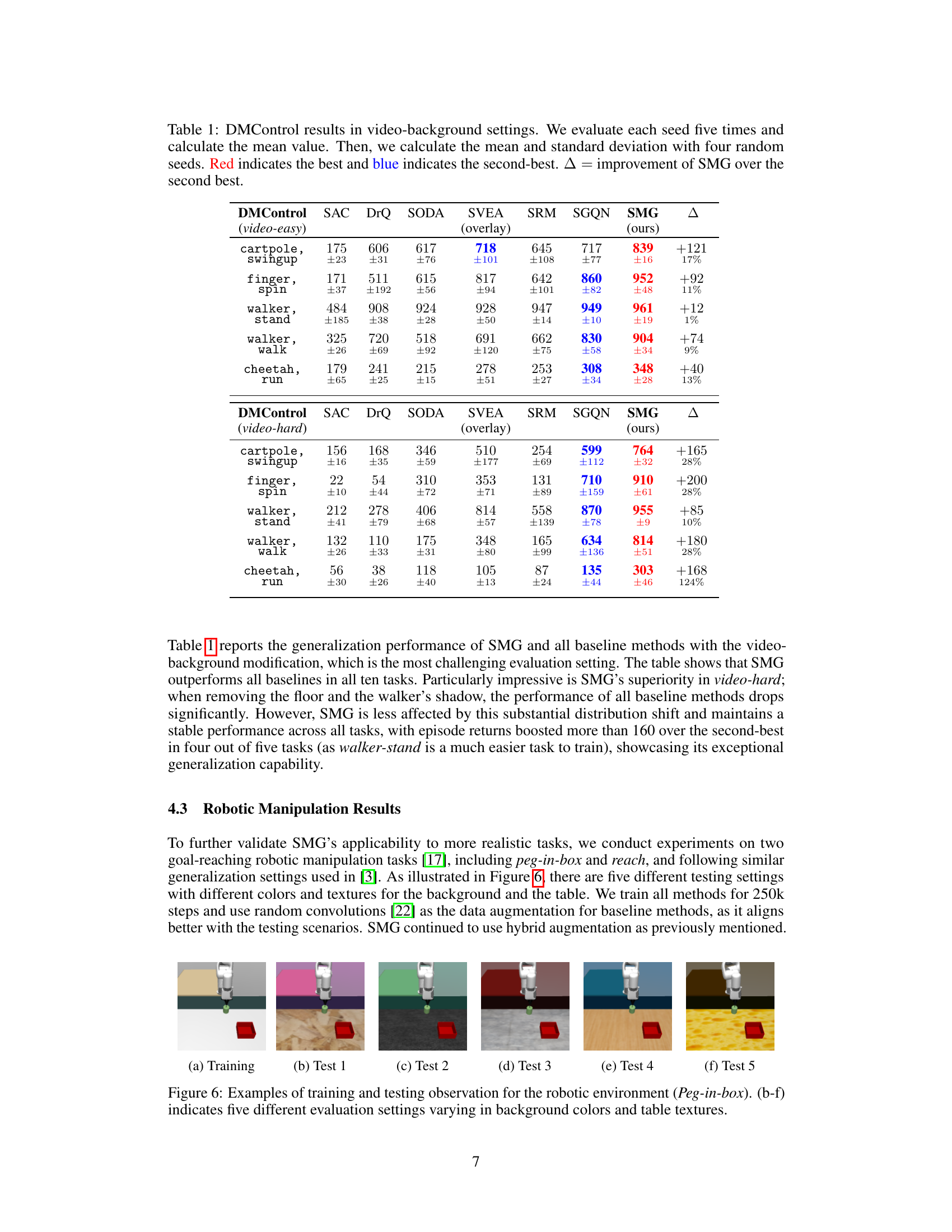
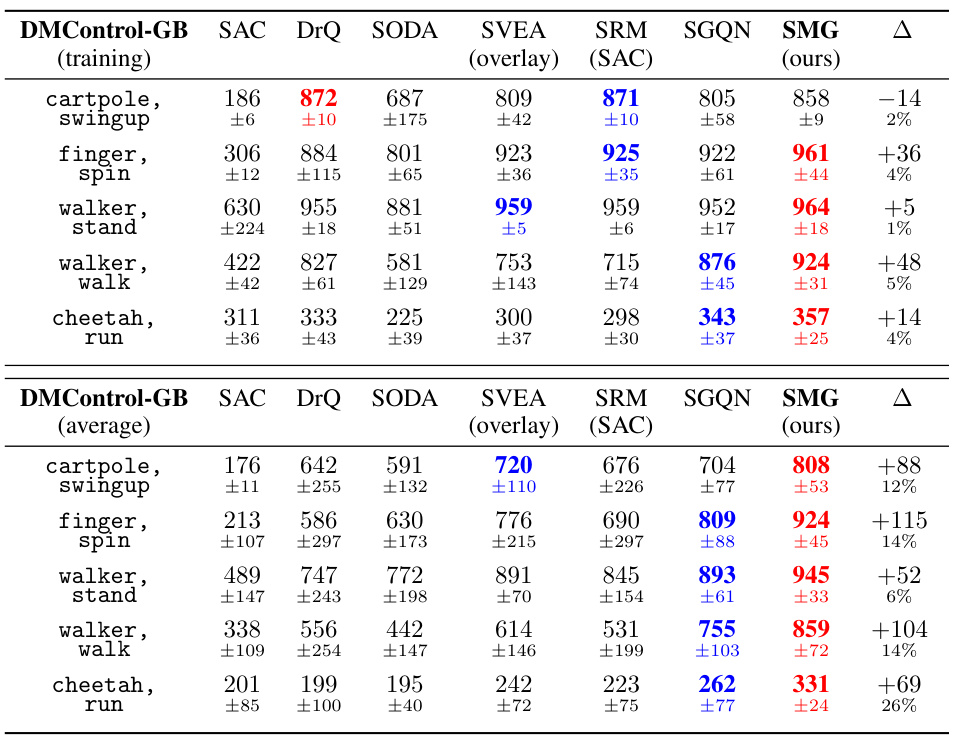
This table presents the generalization performance of SMG and other baseline methods across five DMControl tasks under video-background settings (the most challenging settings). The table shows the mean and standard deviation of the results obtained using four random seeds, with each seed evaluated five times. The ‘Δ’ column indicates the performance improvement of SMG compared to the second-best performing method for each task. Red highlights the best performing method, while blue highlights the second-best.
In-depth insights#
Visual RL Generalization#
Visual Reinforcement Learning (RL) faces a significant challenge in generalizing to unseen environments. Overfitting to training data is a common issue, hindering performance on new, even slightly different, tasks. While data augmentation techniques help, they often fail to address the core problem: learning task-relevant features and ignoring irrelevant ones. Current approaches using auxiliary tasks show promise, but incorporating image reconstruction hasn’t been widely successful due to concerns about overfitting to irrelevant image features. Disentangling relevant from irrelevant information within the visual input is key to improving generalization. A promising direction is separating model components to handle task-relevant and task-irrelevant information independently. This allows leveraging the benefits of reconstruction losses without the drawbacks of overfitting. Additional consistency losses, focusing the agent on relevant areas even across variations in the environment, further enhance the generalization capability. This approach emphasizes the significance of focus on what matters for successful visual RL generalization.
SMG Architecture#
The SMG architecture is a novel approach to visual-based reinforcement learning that focuses on improving generalization. Its core innovation lies in separating the representation learning process into two distinct branches: one for task-relevant features and another for task-irrelevant features. This separation is achieved through a cooperative reconstruction scheme, preventing overfitting to background noise. The architecture cleverly incorporates two consistency losses to ensure the agent focuses on the task-relevant information even under variations in background or other distractors. This strategy effectively guides the agent’s attention, leading to improved zero-shot generalization in challenging environments. The modular design allows for seamless integration with existing RL algorithms, making it a versatile and easily adaptable approach. The thoughtful combination of separated models and consistency losses marks a significant advance, potentially paving the way for more robust and generally applicable visual RL agents.
Consistency Losses#
The concept of Consistency Losses in the context of visual-based reinforcement learning is crucial for enhancing generalization across unseen environments. The core idea revolves around ensuring that the model’s learned representations remain consistent across different variations of the input data. This consistency is enforced by training the model to produce similar outputs (e.g., Q-values, attributions) for both original and augmented observations. Foreground consistency loss focuses on aligning the agent’s focus on task-relevant areas, irrespective of background changes. This prevents overfitting to task-irrelevant features and improves robustness to visual distractions. Q-value consistency loss enhances the stability of the value function by promoting consistent Q-value estimations across different input variations. By regularizing the Q-values, this loss helps prevent the model from producing inconsistent action values and encourages better generalization. The careful design and application of these consistency losses are key to the success of the proposed method, significantly improving the generalization capabilities of the agent, especially in more challenging visual environments.
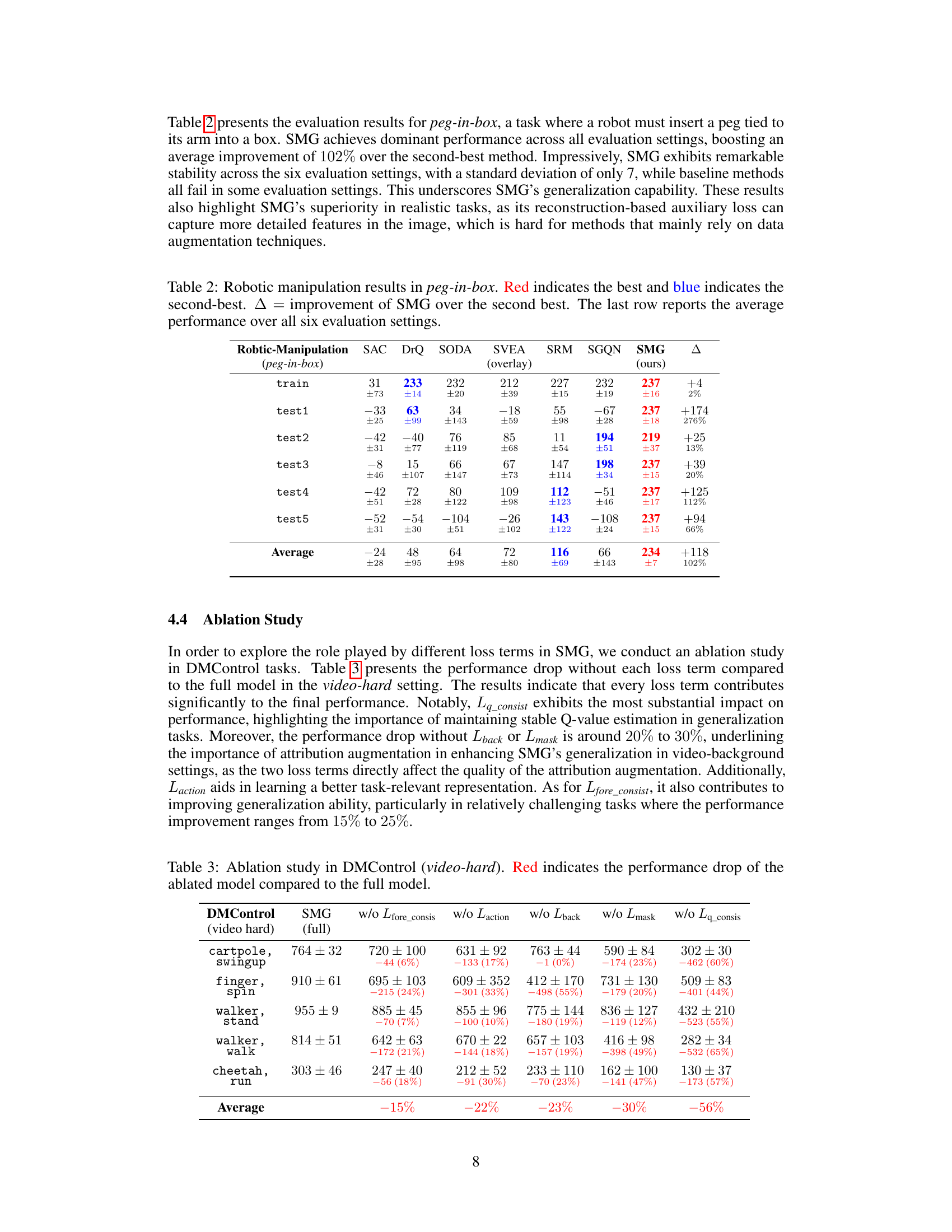
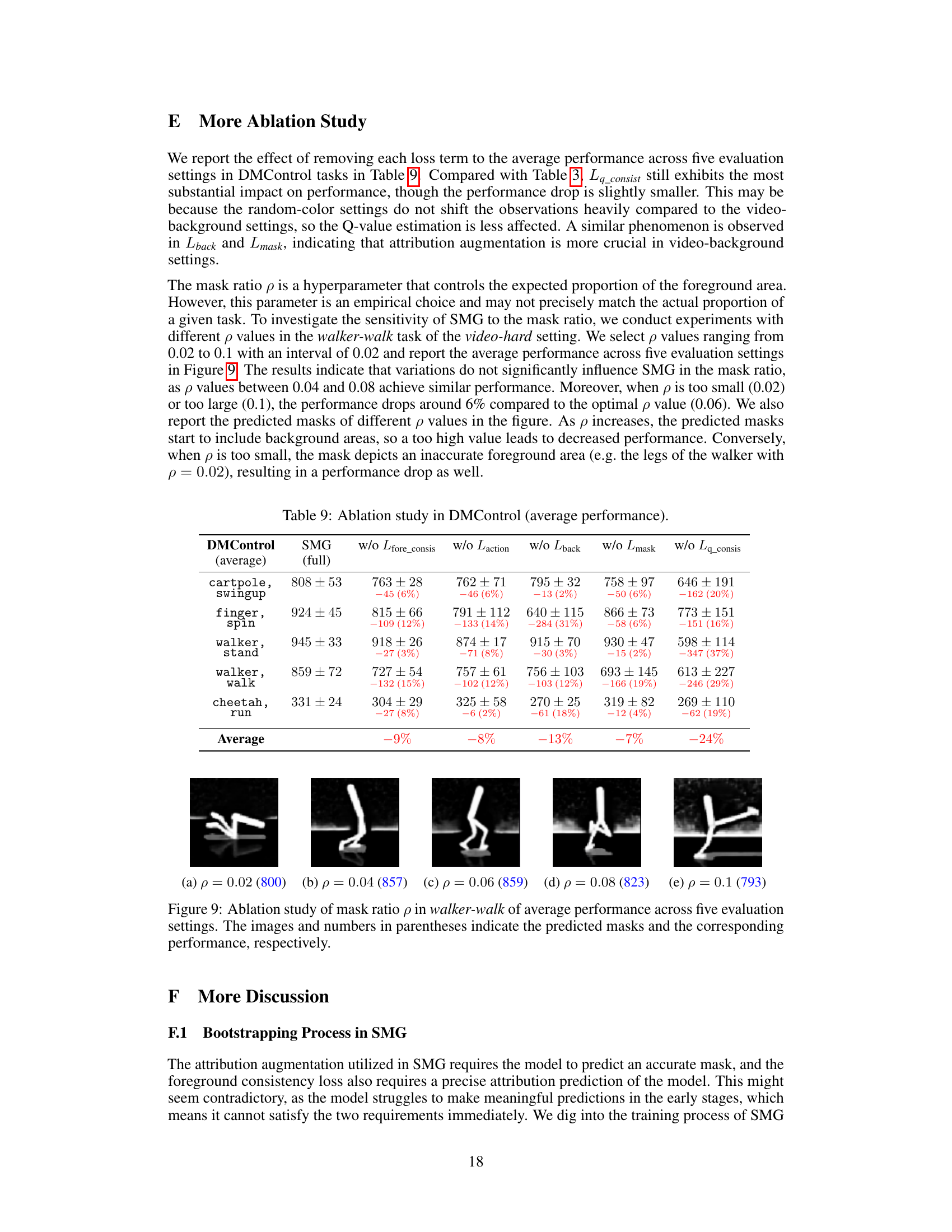
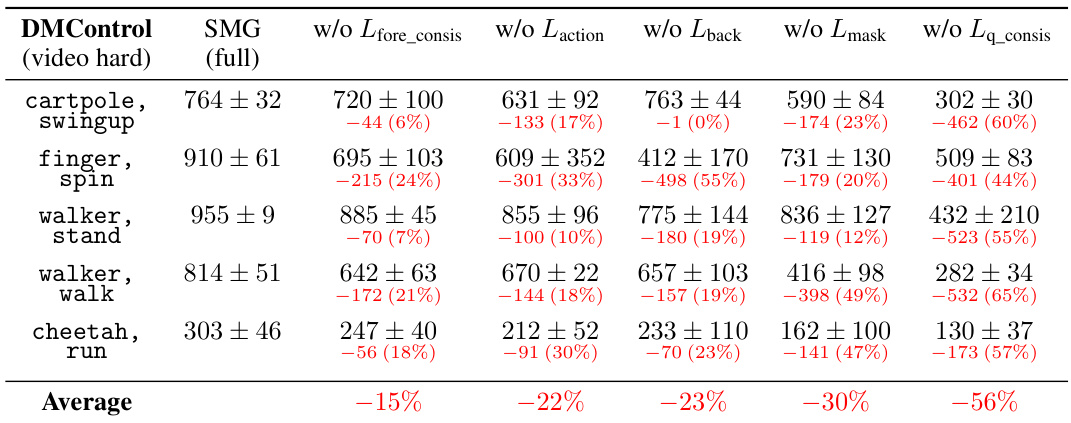
Ablation Studies#
Ablation studies systematically remove components of a model to assess their individual contributions. In the context of a reinforcement learning (RL) model for visual generalization, such as the one described, an ablation study would be crucial for understanding the impact of different design choices. Removing key components, such as the reconstruction loss, background reconstruction loss, foreground consistency loss, or Q-value consistency loss, would reveal how each element affects performance. The results would demonstrate the importance of each component for robust generalization, ideally showing that removing any single element leads to a performance drop. This analysis clarifies the effectiveness of each aspect of the architecture and helps justify the overall model design. A successful ablation study highlights the synergistic effects of the model’s components, demonstrating that the integrated system is superior to its constituent parts and that each component contributes in a non-redundant way to the overall generalization ability. This type of analysis provides strong evidence for the model’s novelty and effectiveness.
Future Work#
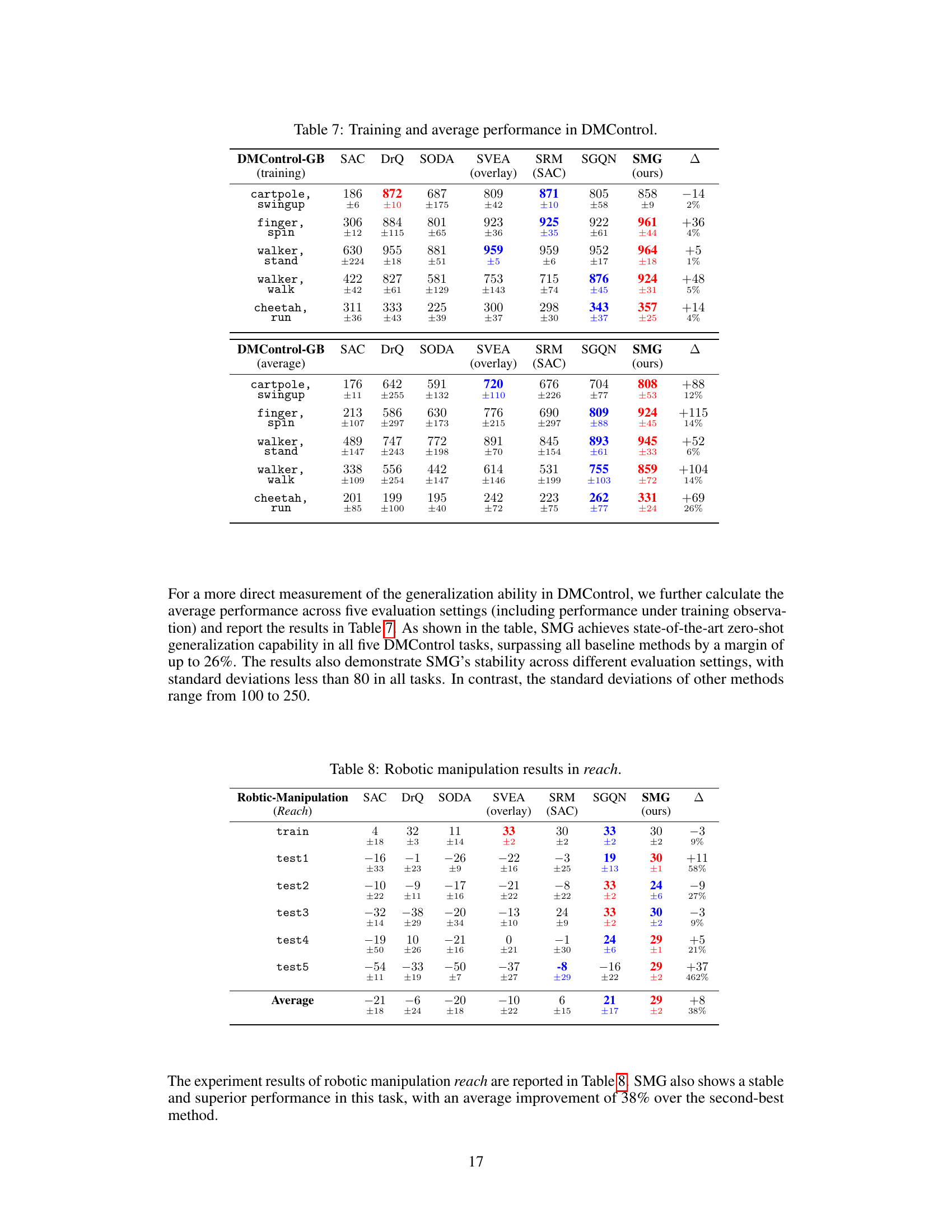
The paper’s “Future Work” section hints at several promising avenues. Extending SMG to more complex scenarios with numerous task-relevant objects is crucial, acknowledging the limitations of accurately learning masks in such situations. This suggests a need for more robust mask generation methods, potentially involving advanced feature extraction techniques and attention mechanisms. Improving the handling of non-static camera viewpoints is another key area, as this is a common challenge in real-world applications. Addressing this would require developing more robust methods for viewpoint normalization or incorporating temporal consistency models. Lastly, rigorous testing in more realistic and varied robotic manipulation tasks would strengthen the model’s generalizability claims. This includes testing with broader background variations, object types and environmental factors, emphasizing real-world robustness. The current tests, while informative, focus on a limited set of tasks. More comprehensive real-world evaluation is needed to fully validate the generalizability potential of SMG.
More visual insights#
More on figures

This figure illustrates a robotic manipulation task where the goal is to move the robot arm to a red target. The left side shows four different scenarios with variations in background colors and textures. Despite these variations, the key aspects for the robot to focus on remain consistent: the arm’s orientation and the target’s position. This highlights the concept of task-relevant features – information essential for successful task completion, which should be prioritized by the RL agent. The right-hand side of the figure uses a simplified, black-background view to clearly show which parts of the scene are ‘Control Relevant’ (directly affected by agent actions) and ‘Reward Relevant’ (associated with the reward signal).

This figure shows two types of data augmentations used in the Separated Models for Generalization (SMG) method. (a) shows an overlay augmentation where a random image is overlaid onto the original observation, simulating the video background setting. (b) shows an attribution augmentation, where the background is randomly augmented according to the mask generated by the model, allowing the model to focus on the task-relevant areas.

This figure visualizes the reconstruction process of the Separated Models for Generalization (SMG) method in three different tasks from the DMControl suite: walker-walk, cheetah-run, and peg-in-box. For each task, it shows the training observation, the evaluation observation (under a color-hard or video-hard setting), the predicted mask, the reconstructed background, the attribution (the area the agent focuses on), and the final reconstruction. The figure demonstrates how SMG disentangles foreground (task-relevant) and background (task-irrelevant) information, allowing it to generalize better to unseen environments. The color-hard settings change the colors of the environments, and the video-hard settings replace the backgrounds with random videos.

This figure shows examples of the walker-walk task from the DMControl benchmark used to evaluate generalization performance. It demonstrates the different levels of visual changes applied to the environment during testing, progressing from subtle color alterations (Color-easy, Color-hard) to complete background video replacements and removal of context cues (Video-easy, Video-hard). The training observation is presented for comparison.

This figure shows six images of a robotic manipulation task. The top row shows the training images for the Peg-in-box task, and the bottom row shows five different testing images where the background colors and table textures vary. These variations represent different unseen scenarios to evaluate the generalization capability of the proposed reinforcement learning model.

This figure visualizes the effect of removing the mask ratio loss (Lmask) and the background reconstruction loss (Lback) from the SMG model. The leftmost image (a) shows the results from the complete SMG model, where a mask is accurately generated to isolate the relevant foreground (the walking figure) from the background. The middle image (b) shows the result when Lmask is removed; the mask is nearly all white, indicating that the model fails to differentiate the foreground from the background resulting in poor attribution augmentation. The rightmost image (c) displays the results without Lback; this demonstrates that the background is overly reconstructed and contains foreground features, again leading to a poor attribution augmentation. These results highlight the importance of both loss terms in improving model performance.

This figure shows the architecture of the Separated Models for Generalization (SMG) method. It illustrates two main parts. The first part (a) shows how SMG learns task-relevant representations from visual observations using two separate model branches for foreground and background, employing a cooperative reconstruction approach. This avoids overfitting to task-irrelevant features. The second part (b) demonstrates how SMG improves generalization by incorporating foreground and Q-value consistency losses to guide the agent’s attention to task-relevant features across varying scenarios.
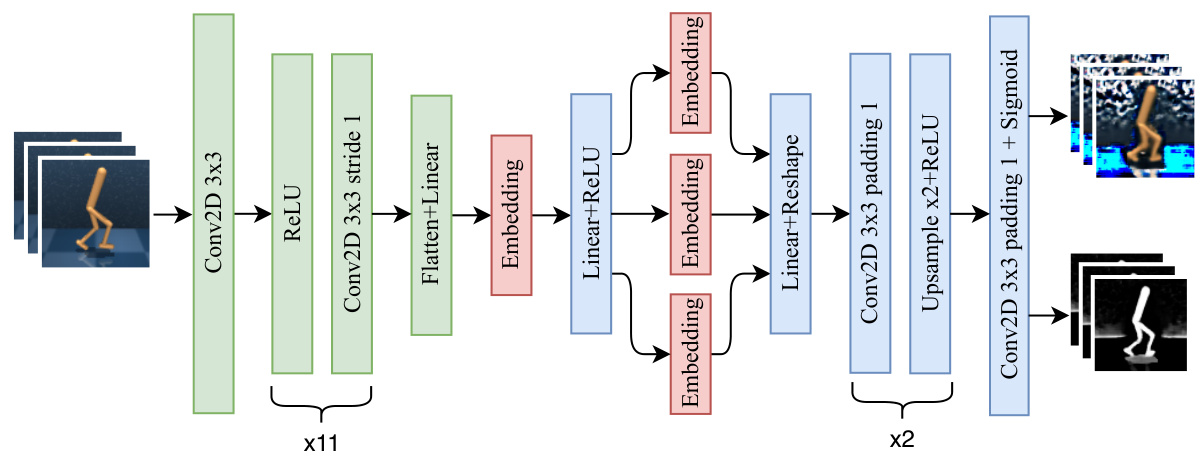
This figure shows the architecture of the Separated Models for Generalization (SMG) network. The input is a stack of three consecutive frames (9x84x84). The encoder consists of convolutional layers to extract features, followed by a fully connected layer and embedding. The embedding is then split to feed three decoder branches. Each branch mirrors the encoder to reconstruct one of the three input frames. The foreground decoder produces the reconstructed foreground image and an attention mask, and the background decoder reconstructs the background. These components are crucial for learning task-relevant visual representations.

This figure visualizes the evolution of the model’s ability to generate masks and attribution augmentations during training. It demonstrates how, in the early stages, the masks are inaccurate and the augmentations are less effective. As training progresses, the masks become increasingly accurate, the augmentations reflect a better focus on task-relevant areas, and the model’s performance improves.
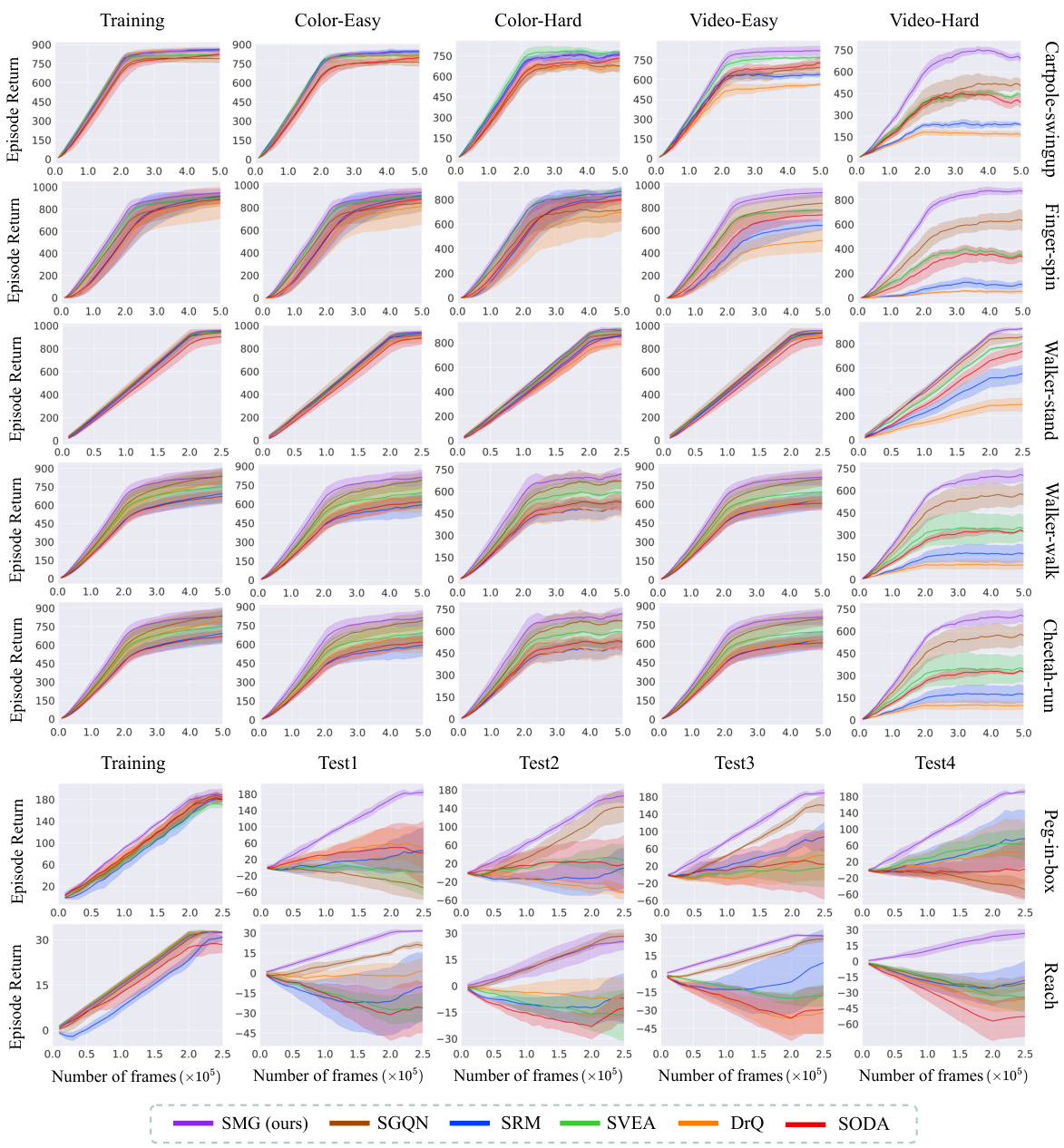
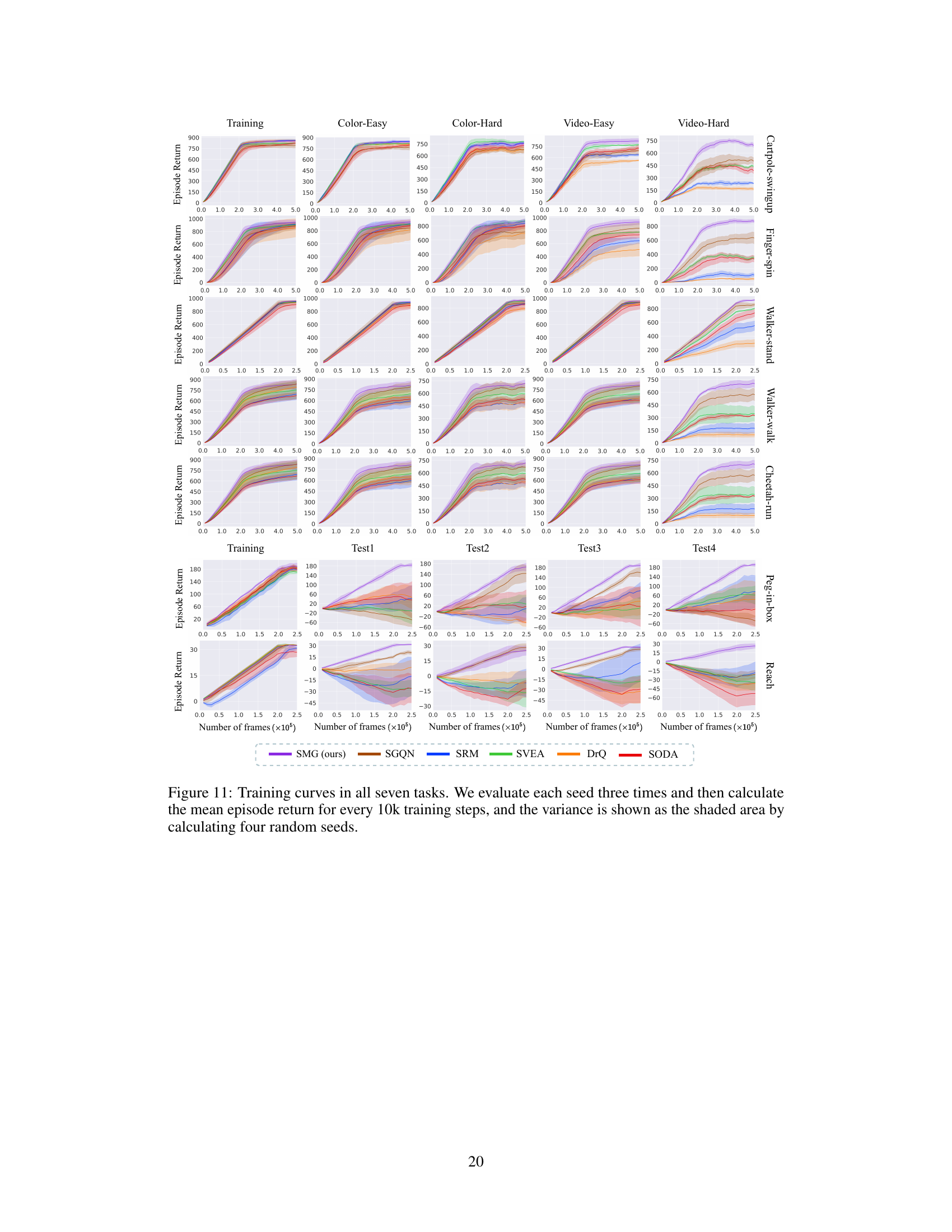
This figure shows the training curves for seven different reinforcement learning tasks across various evaluation settings. Each curve represents the average episode return over multiple runs, with shaded areas indicating variance. The x-axis represents the number of training frames (in units of 10,000), and the y-axis shows the episode return. The results show that SMG consistently outperforms other algorithms, particularly in more challenging video-background settings.
More on tables
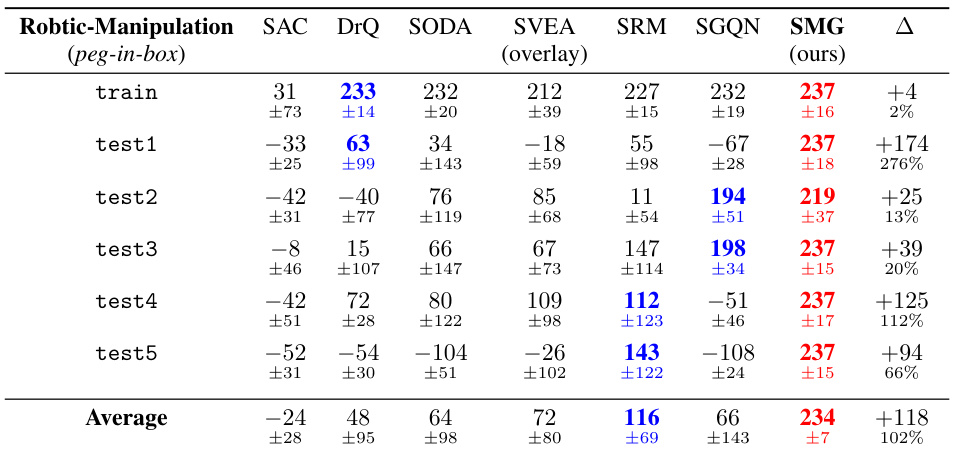
This table presents the generalization performance of SMG and other baseline methods on five DMControl tasks under video-background settings. The results are averaged over four random seeds and show the mean and standard deviation. The table highlights SMG’s superior performance, particularly in challenging video-hard settings.
This table presents the generalization performance of SMG and baseline methods across five DMControl tasks under video-background settings, which is considered the most challenging evaluation scenario. The results are averaged across four random seeds, with each seed evaluated five times. The table shows SMG’s average return for each task, along with the mean and standard deviation, and highlights the performance improvement of SMG over the next-best performing method (second-best).

This table presents the generalization performance of SMG and other baseline methods on five DMControl tasks under video-background settings. The video-background settings are designed to challenge generalization ability. The table shows the mean and standard deviation of the performance across four random seeds. The Δ column shows the performance improvement of SMG over the second-best method for each task. The results demonstrate SMG’s superior generalization performance.

This table presents the generalization performance of SMG and other baseline methods on DMControl tasks under video-background modifications. It shows the mean and standard deviation of the results across four random seeds, indicating which method performs best (red) and second best (blue) for each task. The delta column (∆) shows the improvement of SMG over the second-best performer. The video-background setting is particularly challenging, designed to test generalization capabilities.

This table presents the generalization performance of SMG and other baseline methods on five DMControl tasks under video-background settings, which simulate real-world scenarios with changing video backgrounds. The results are averaged over multiple runs with different random seeds. The table highlights SMG’s superior performance, especially in challenging video-hard settings, compared to the other algorithms. The Δ column shows the performance improvement of SMG over the second-best method for each task.
This table presents the generalization performance of SMG and other baseline methods across five DMControl tasks under video-background settings. The video-background setting makes the tasks more challenging by modifying the background of the environment. The table shows the mean and standard deviation of the scores achieved by each method across four random seeds. The best performing method is highlighted in red, and the second best is highlighted in blue. The last column (Δ) shows the improvement in score achieved by SMG over the second best-performing method.
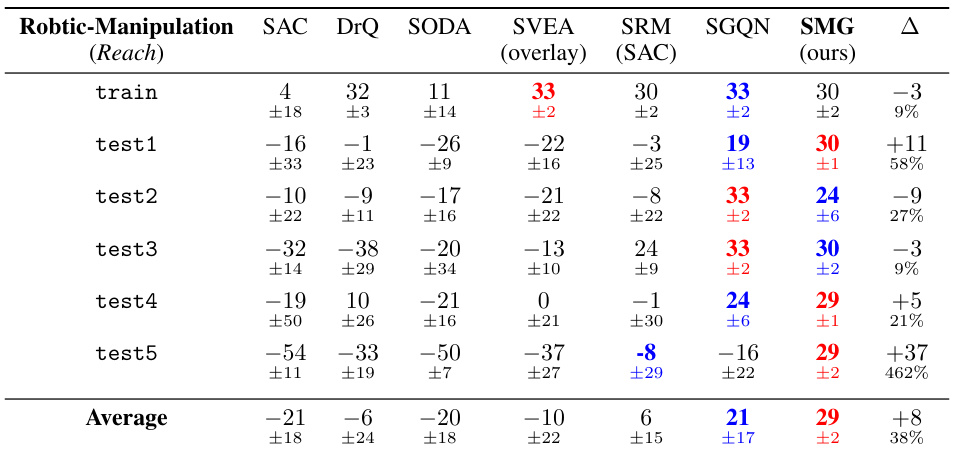
This table presents the generalization performance of SMG and other baseline methods across various DMControl tasks under video-background settings, which are considered the most challenging. The results are averages across multiple runs and include mean values, standard deviations, and the improvement achieved by SMG compared to the second-best performing method. The table highlights SMG’s superior performance, particularly in more difficult video-background settings.

This table presents the generalization performance of SMG and several baseline methods across five DMControl tasks under video-background modifications. The results are averaged over four random seeds and show SMG’s performance compared to baselines (SAC, DrQ, SODA, SVEA, SRM, SGQN). The table highlights SMG’s superior performance in video-background settings, particularly in more challenging scenarios (video-hard). The Δ column shows the improvement in performance of SMG over the second-best performing method for each task.
Full paper#