↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current pay-per-token pricing for LLMs creates a moral hazard; providers prioritize cheaper models over optimal ones, compromising quality. This is especially problematic in high-stakes applications where quality is paramount.
The study proposes a pay-for-performance framework using cost-robust contracts which are mathematically characterized using hypothesis testing in statistics. The framework successfully addresses cost uncertainty and offers optimal contracts that align economic incentives, leading to higher-quality LLM outputs. Empirical evidence supports the efficacy and cost-efficiency of this approach.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on incentivizing high-quality LLM text generation and contract design. It offers a novel framework for creating cost-robust contracts that address moral hazard issues, and provides valuable insights for both theoretical and applied research in AI.
Visual Insights#

The figure illustrates the interaction protocol between the principal and agent in a text generation task. The principal commits to a payment scheme based on the quality of the generated text and sends a prompt to the agent. The agent then selects a text generator, generates a response, and incurs a cost. Finally, the principal evaluates the quality of the response and pays the agent according to the predetermined scheme.

This table summarizes the correspondence between the economic objectives of minimizing budget and pay, their corresponding objective functions, the statistical objectives in hypothesis testing (minimizing false positives and negatives or minimizing the ratio of false positives to true positives), and their respective risk functions. Theorem 1 in the paper establishes this relationship.
In-depth insights#
Incentivizing LLMs#
Incentivizing large language models (LLMs) is crucial for their responsible development and deployment. Current pay-per-token pricing structures create a moral hazard, where providers prioritize cost reduction over quality, potentially using cheaper, less effective models without the user’s knowledge. Pay-for-performance (P4P) contracts, as proposed in the research, offer a solution by aligning incentives. This approach employs automated quality evaluation to determine payment based on the generated text’s quality, incentivizing higher performance. However, the paper highlights the challenge of cost uncertainty, where the actual costs of using a given LLM are unknown to the client. The solution proposed introduces cost-robust contracts, which incentivize quality even with incomplete information about the providers’ internal cost structure, thus improving the overall quality and reliability of LLM-generated content.
Cost-Robust Contracts#
The core concept of “Cost-Robust Contracts” addresses the critical issue of moral hazard in the LLM text generation market. Traditional pay-per-token models incentivize providers to use cheaper, lower-quality LLMs to maximize profit, a risk to clients unaware of the internal model selection. The proposed solution introduces contracts where payment is tied to performance, evaluated via automated quality metrics. This pay-for-performance approach is made robust to the unknown inference costs of different LLMs by characterizing optimal contracts through a direct correspondence to statistical hypothesis tests. Cost-robust contracts guarantee that the most advanced LLM is used regardless of the precise cost structure, sacrificing only a marginal increase in objective value compared to cost-aware alternatives. This framework offers flexibility in accommodating diverse evaluation benchmarks and optimality objectives (min-budget, min-pay, min-variance), providing empirically validated, practical solutions to align incentives in the LLM market and ensure high-quality text generation.
Hypothesis Tests#
The concept of “Hypothesis Tests” within the context of contract design for LLMs offers a powerful framework for incentivizing quality text generation. By framing the problem statistically, the authors elegantly connect the principal’s economic objectives (min-budget, min-pay) to the statistical risk inherent in choosing the wrong hypothesis (Type I and Type II errors). This crucial link allows for a direct correspondence between optimal contracts and minimax hypothesis tests, providing both theoretical grounding and a practical method for deriving contracts. The utilization of composite hypothesis tests, where the null hypothesis is a set of distributions rather than a single one, is particularly important due to the uncertainty regarding the agent’s internal costs. This cost-robust approach addresses the critical challenge of unknown inference costs, providing guarantees on the agent’s behavior even under uncertainty. The use of likelihood ratio tests, along with the notions of sum-optimal and ratio-optimal tests, further reinforces the mathematical rigor and provides clear guidelines for contract design. The inherent connection between statistical hypothesis testing and contract design creates a robust and interpretable framework, transforming the abstract concept of incentivizing quality into a well-defined and solvable statistical problem.
Empirical Evaluation#
The Empirical Evaluation section is crucial for validating the theoretical claims of the research paper on incentivizing quality text generation via statistical contracts. It evaluates the proposed cost-robust contract framework using established Large Language Model (LLM) evaluation benchmarks. The experiments likely cover both binary-outcome and multi-outcome settings, showcasing the adaptability of the framework across various tasks and evaluation metrics. Key aspects assessed may include the trade-off between cost and performance for different LLM models under cost-robust and cost-aware contracts. The findings should highlight the practical implications of cost-robust contracts, examining their effectiveness in incentivizing the use of high-quality, yet potentially costly, LLMs while maintaining cost-efficiency. A crucial aspect of the evaluation should be the demonstration of the robustness of the contracts against uncertainty in the LLM providers’ true inference costs, thereby proving the practicality of the method. Statistical measures such as the budget, expected payment, and variance of contracts under different objectives (e.g., min-budget, min-pay, min-variance) will likely be reported and compared to establish the practical efficacy and cost-effectiveness of the approach. Overall, this section should rigorously demonstrate that the proposed contract mechanism effectively aligns incentives and improves the quality of machine-generated text in real-world scenarios.
Future Directions#
Future research could explore refining the cost estimation models for LLM inference, moving beyond simplistic energy consumption metrics to encompass more nuanced factors like infrastructure costs and fluctuating market prices. Improving the robustness of cost-robust contracts is crucial, especially by addressing scenarios with incomplete information about the agent’s cost structure and exploring different risk aversion levels. The applicability of the framework could be extended to various LLM tasks beyond those evaluated, encompassing diverse evaluation metrics and focusing on fairness and bias mitigation in contract design. A particularly promising avenue is to investigate more sophisticated contract forms beyond binary or simple multi-outcome structures, potentially incorporating machine learning techniques for personalized contract design. Finally, the ethical implications of incentivizing LLM performance through contracts warrant further examination, focusing on issues of transparency, accountability, and the potential for unintended consequences within the LLM market.
More visual insights#
More on tables

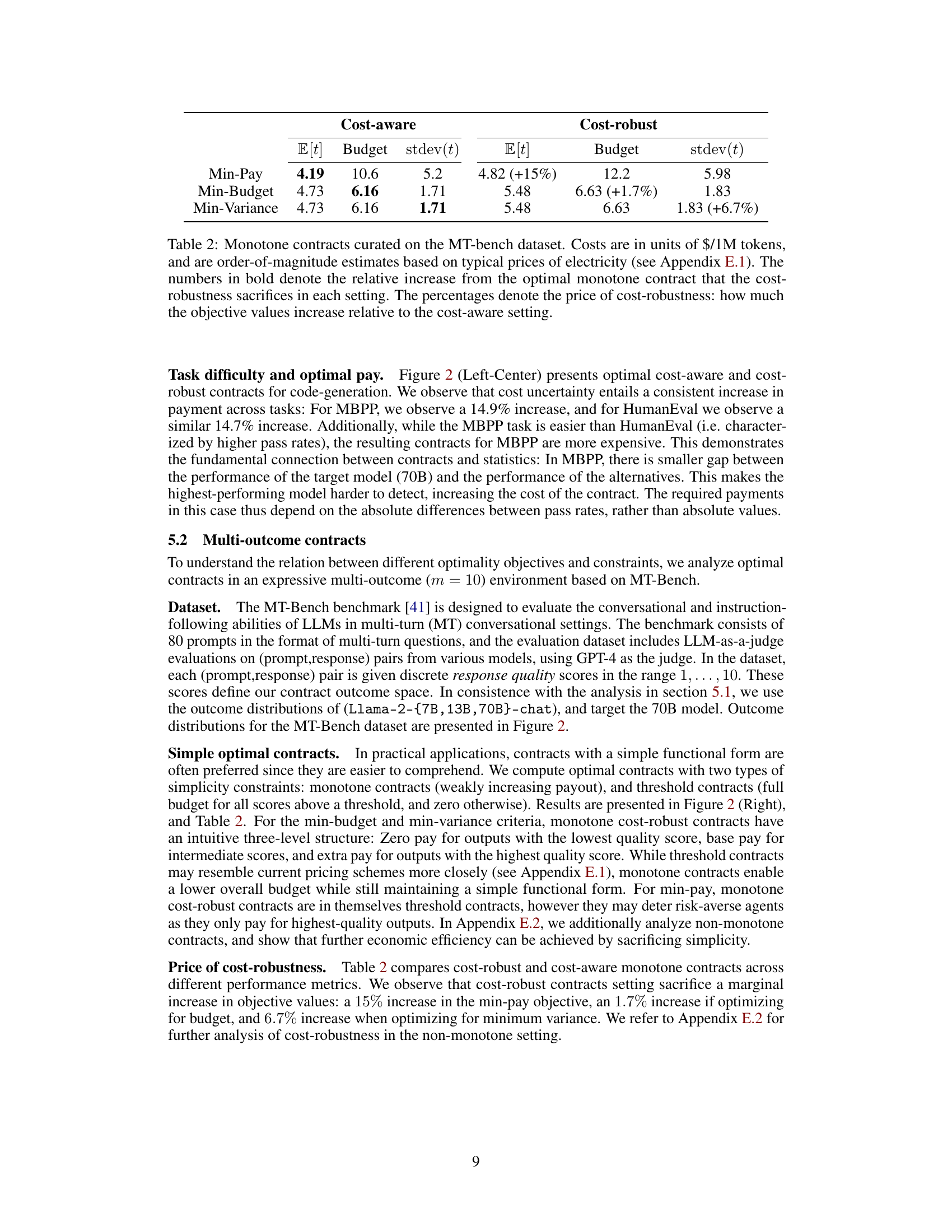
This table compares the performance of cost-aware and cost-robust monotone contracts for the MT-bench dataset, in terms of expected payment, budget, and standard deviation. It shows the cost (increase in objective values) of ensuring cost robustness for each optimization objective. The cost is expressed both as an absolute value and a percentage increase compared to the cost-aware contract.
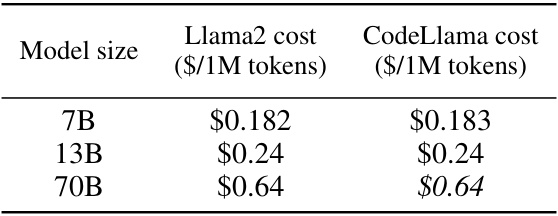
This table presents the estimated costs of using different sized language models from the Llama2 and CodeLlama families. The costs are expressed in dollars per million tokens and are calculated based on energy consumption data from the Hugging Face LLM Performance Leaderboard, using a conservative cost estimate of $0.105 per kWh. The table shows that costs increase with model size, as expected.

This table shows the average output length (verbosity) for three different sizes of Llama-2 chat models (7B, 13B, and 70B parameters). The authors note that since the values are similar, they simplified their cost calculations by assuming that model size does not significantly impact the response length.

This table presents a comparison of cost-aware and cost-robust contracts in a non-monotone setting, focusing on three optimization objectives: minimizing expected payment, minimizing maximum payment, and minimizing variance. For each objective, it shows the expected payment (E[t]), maximum payment (maxtj), and standard deviation (stdev(t)) for both cost-aware and cost-robust contracts. The percentage increase in each metric for the cost-robust contract compared to the cost-aware contract is also provided, illustrating the trade-off between robustness and optimality.

This table compares the performance of cost-aware and cost-robust contracts for three different optimization objectives (min-pay, min-budget, and min-variance) when monotonicity constraints are not imposed. It shows that cost-robust contracts offer only a small increase in the objective values compared to the cost-aware contracts.
Full paper#