↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Link prediction, a fundamental task in graph machine learning, traditionally employs heuristic methods or single graph neural network (GNN) models. However, these approaches often fail to achieve optimal performance as different node pairs within a graph require varied information for accurate predictions. This paper identifies this limitation and demonstrates its consequences.
To address the above issues, the authors propose a novel mixture-of-experts (MoE) model, Link-MoE, to enhance link prediction. Link-MoE uses various GNNs as “experts” and a gating function to selectively choose the most suitable expert for each node pair, based on multiple types of pairwise information. This adaptive approach yields substantial performance improvements on diverse benchmark datasets. The results showcase Link-MoE’s superior performance compared to traditional heuristic and GNN-based methods, significantly advancing the state-of-the-art in link prediction.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses a critical limitation in link prediction: the one-size-fits-all approach. By introducing Link-MoE, a mixture-of-experts model, it demonstrates how to improve link prediction accuracy by using various models selectively based on data characteristics. This innovative approach has the potential to significantly advance the field and inspire further research into adaptive models for various graph-related tasks. The improved performance on benchmark datasets highlights the effectiveness and potential of this new methodology. This work opens up new avenues for researchers to explore improved link prediction methods and enhance their effectiveness.
Visual Insights#
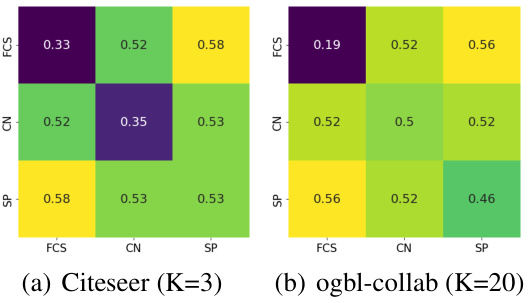
This figure shows the Hits@K (a metric evaluating the ratio of correctly predicted links among top K predictions) for three individual heuristics (Feature Cosine Similarity (FCS), Common Neighbors (CN), Shortest Path (SP)) and their combinations. The results are shown for two datasets, Citeseer (K=3) and ogbl-collab (K=20), visualizing how combining heuristics improves the prediction accuracy compared to using individual heuristics alone. The heatmap illustrates the overlapping ratios of the different heuristic combinations.
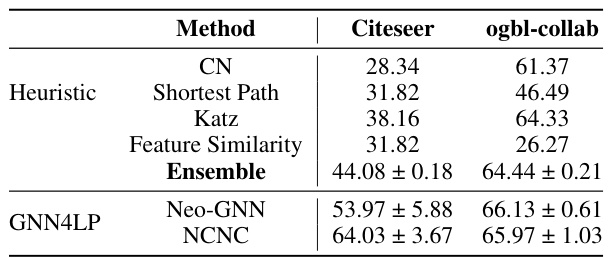
This table presents the performance comparison of several methods for link prediction on the Citeseer and ogbl-collab datasets. It shows the performance of individual heuristics (Common Neighbors, Shortest Path, Katz, and Feature Similarity), and their ensemble using a simple MLP. It also includes the performance of several GNN4LP models for context and comparison. The results highlight that combining multiple heuristics can improve performance but that GNN4LP models generally perform better than simple heuristic combinations.
In-depth insights#
GNN4LP Synergy#
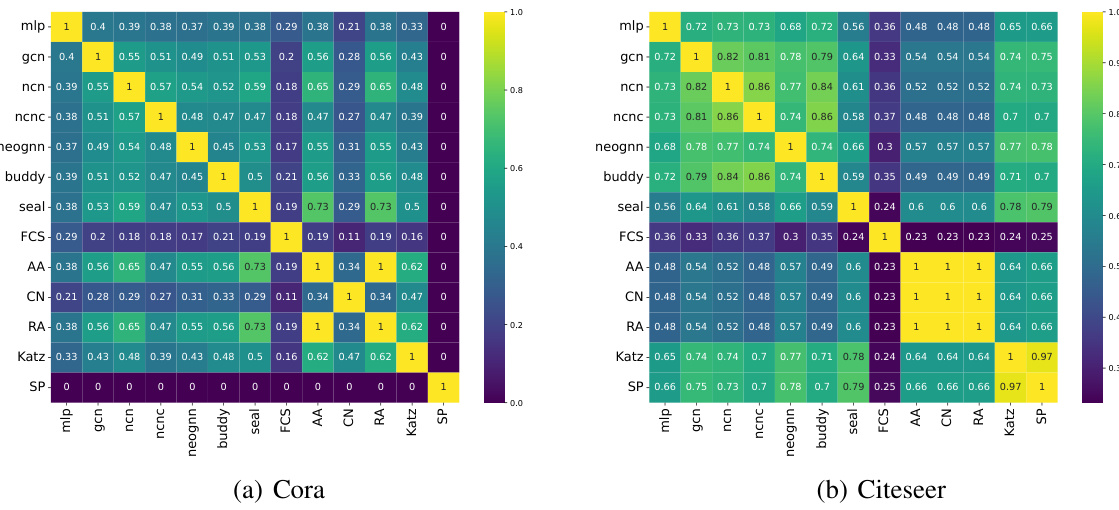
The heading ‘GNN4LP Synergy’ suggests an exploration of how different Graph Neural Network-based Link Predictors (GNN4LPs) can be combined effectively. The core idea revolves around leveraging the complementary strengths of various GNN4LP models. Instead of relying on a single GNN4LP, which might excel in certain scenarios but underperform in others, a synergistic approach aims to combine multiple methods to achieve robust and superior link prediction results. This could involve ensemble methods or more sophisticated strategies that dynamically select the best-suited predictor for each node pair based on relevant graph characteristics. The analysis likely investigates the overlapping and unique predictive capabilities of each GNN4LP model, possibly using metrics like Jaccard similarity to quantify their combined power. Understanding and mitigating redundancy between GNN4LPs is crucial for optimal synergy, and this exploration likely delves into the effectiveness of diverse heuristic measures to inform the selection process. The ultimate goal is to demonstrate that a well-designed combination of GNN4LPs significantly surpasses the performance of any single model, achieving improved accuracy and robustness in link prediction.
Link-MoE Model#
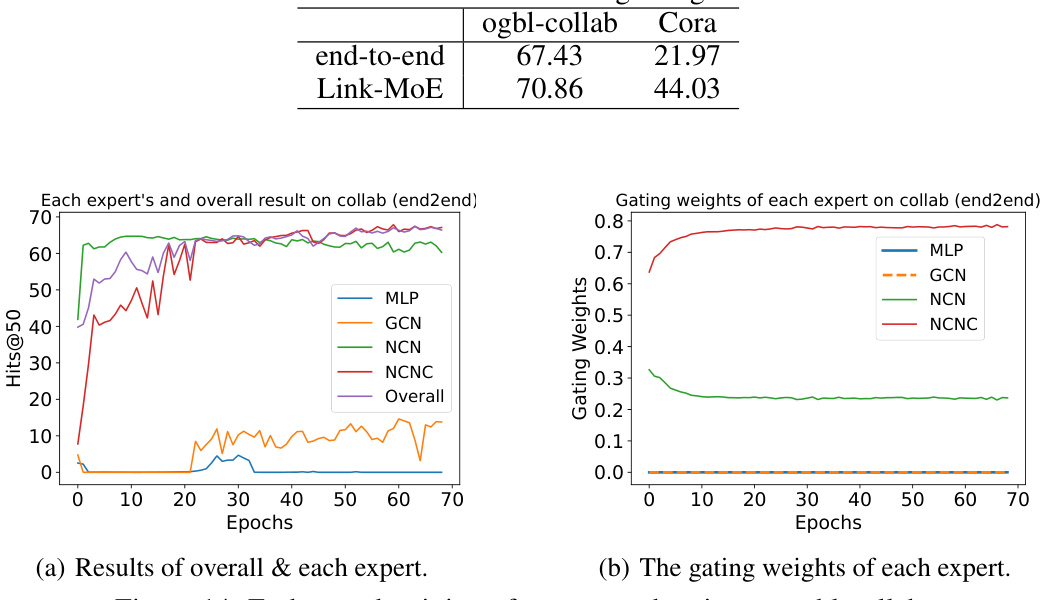
The proposed Link-MoE model introduces a novel mixture-of-experts (MoE) approach for link prediction. Its core innovation lies in its adaptive selection of expert models, each specializing in a particular type of pairwise relationship within the graph. Instead of uniformly applying a single model across all node pairs, Link-MoE leverages a gating mechanism trained on various heuristic features (local/global structural and feature proximity) to strategically assign each pair to the most suitable expert. This adaptive strategy allows Link-MoE to exploit the complementary strengths of different experts (various GNNs and heuristic models) resulting in a significant performance boost across diverse real-world datasets. The gating function’s reliance on heuristic features makes it particularly effective at identifying appropriate models for unique node pairs. The two-stage training process (individual expert training followed by gating model training) is efficient, avoiding the common issues encountered in end-to-end training of MoE models. Link-MoE’s flexibility permits seamless integration of new expert models, making it adaptable and extensible. The results demonstrate Link-MoE’s superior performance compared to single models, suggesting the potential of MoE architectures for tackling complex link prediction tasks.
Heuristic Blending#
Heuristic blending in link prediction involves combining multiple, simple heuristics to improve predictive accuracy. Instead of relying on a single, potentially limited heuristic, such as common neighbors or shortest paths, this approach leverages the strengths of several heuristics by aggregating their results. This can lead to a more robust and comprehensive understanding of the relationships between nodes. The challenge lies in effectively combining the heuristics, as they may capture different aspects of the link structure and may be correlated or conflicting. Effective blending techniques might involve weighted averaging, or more sophisticated machine learning models to learn the optimal combination of heuristics, considering dataset specifics. This strategy can provide a strong baseline, complementing or enhancing more complex methods like graph neural networks. While the simplicity of individual heuristics is beneficial, careful consideration of how they interact is crucial for successful blending.
Adaptive Gating#
Adaptive gating, in the context of a Mixture of Experts (MoE) model for link prediction, is a crucial mechanism that dynamically assigns weights to different expert models based on the characteristics of each node pair. This adaptability is key because different node pairs may require different types of information (local vs. global structural features, feature similarity, etc.) for accurate prediction. A fixed weighting scheme would be suboptimal. The effectiveness of adaptive gating hinges on the design of the gating function. It must effectively learn to map node-pair features and/or heuristics to appropriate weights for each expert. The choice of input features (e.g., common neighbors, shortest paths, node features) significantly impacts the gating function’s ability to make informed decisions. A well-designed gating mechanism ensures that the most suitable expert model is given the highest weight for each prediction, leading to improved overall accuracy and efficiency compared to using a single expert model or a fixed weighting scheme. The performance gains are especially noteworthy when dealing with datasets containing heterogeneous node pairs with diverse relationships.
Future of MoE#
The future of Mixture of Experts (MoE) models in link prediction appears bright, given their capacity to surpass traditional methods and even enhance the performance of existing Graph Neural Networks (GNNs). Further research should explore adaptive routing mechanisms that go beyond simple heuristics, perhaps leveraging more sophisticated graph embeddings or even incorporating attention mechanisms to dynamically weight expert contributions. Investigating the scalability of MoE approaches to handle extremely large graphs is crucial, as is the need for more efficient training strategies, given the inherent complexity of training multiple expert models simultaneously. A key area for advancement lies in the development of more diverse and robust expert models, moving beyond the existing GNNs. The incorporation of transformers or other advanced architectures could potentially unlock even greater predictive power. Finally, thorough exploration of the theoretical underpinnings of MoE models in graph settings will be necessary to explain their successes and guide future developments.
More visual insights#
More on figures
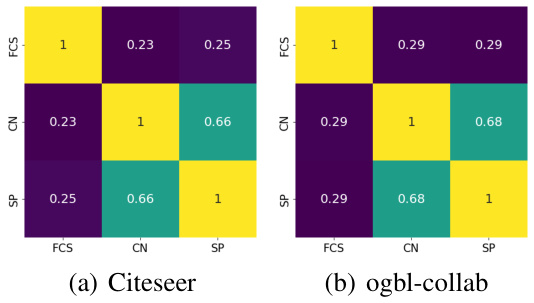
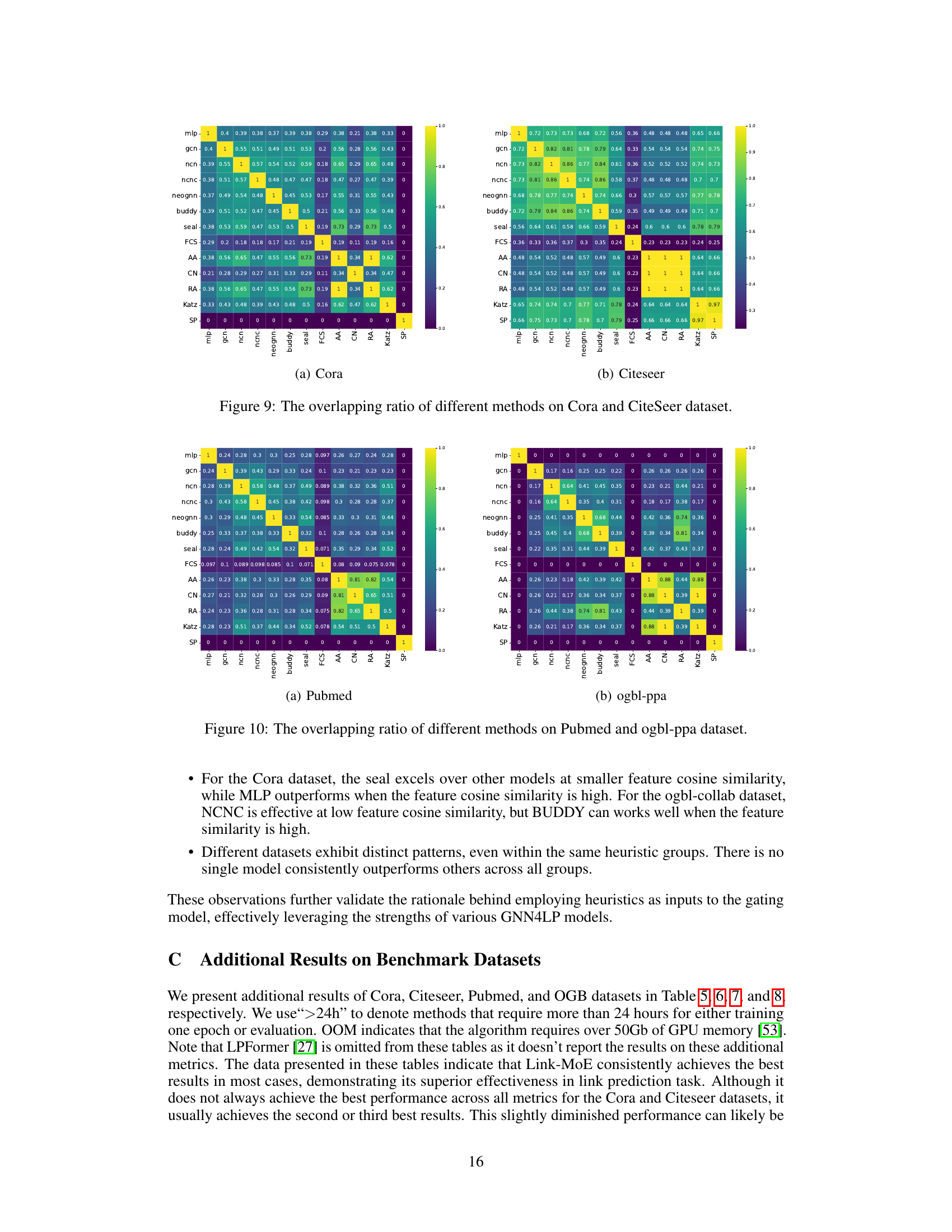
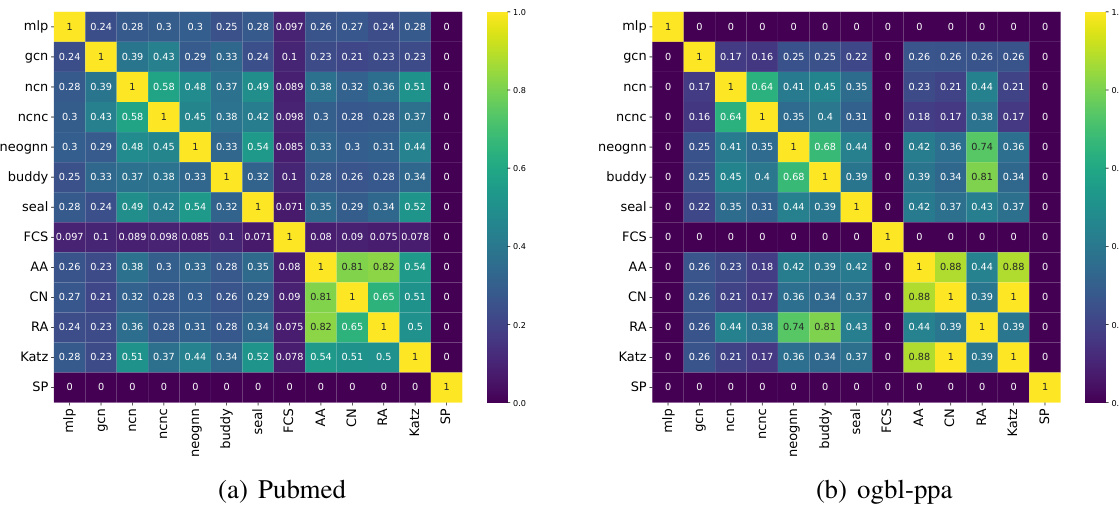
The figure shows the overlapping ratio between pairs of heuristics (Common Neighbors, Shortest Path, Feature Cosine Similarity) in the Citeseer and ogbl-collab datasets. The overlapping ratio is calculated using the Jaccard coefficient, which measures the similarity between the sets of correctly predicted node pairs by different heuristics. A higher overlapping ratio indicates a higher similarity between the node pairs predicted correctly by two heuristics, implying that they are capturing similar information. The results show that the overlapping ratio varies across different pairs of heuristics and datasets, suggesting that different heuristics capture different information and might be complementary to each other.
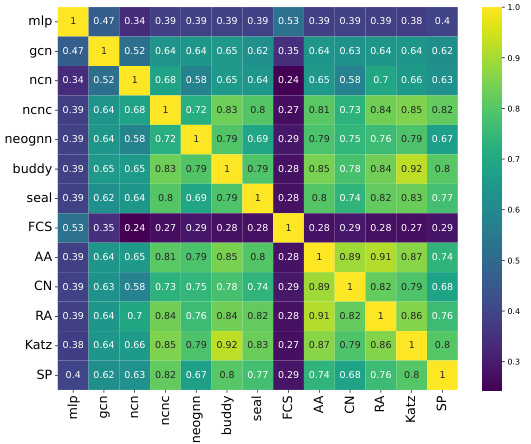
This heatmap visualizes the Jaccard similarity between pairs of different link prediction methods on the ogbl-collab dataset. Each cell represents the Jaccard Index, measuring the overlap between the sets of links correctly predicted by two methods. A higher value indicates greater overlap, suggesting that the methods predict similar sets of links. Lower values imply less overlap, indicating that the methods identify distinct sets of links. This figure shows that different GNN4LP models and heuristics have varying degrees of overlap in their predictions.
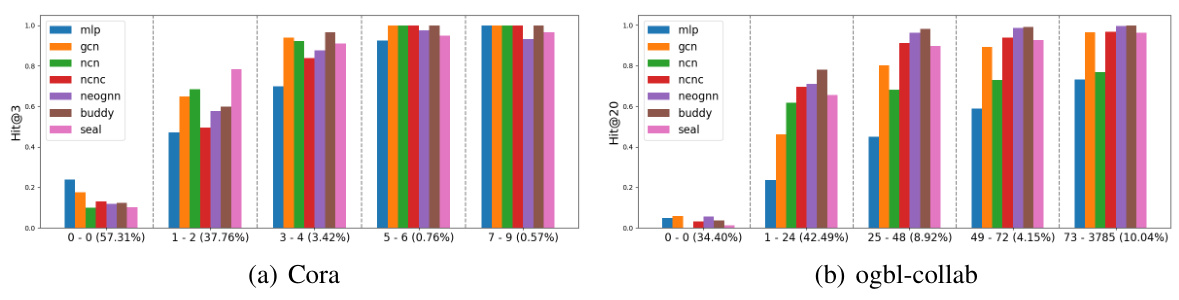
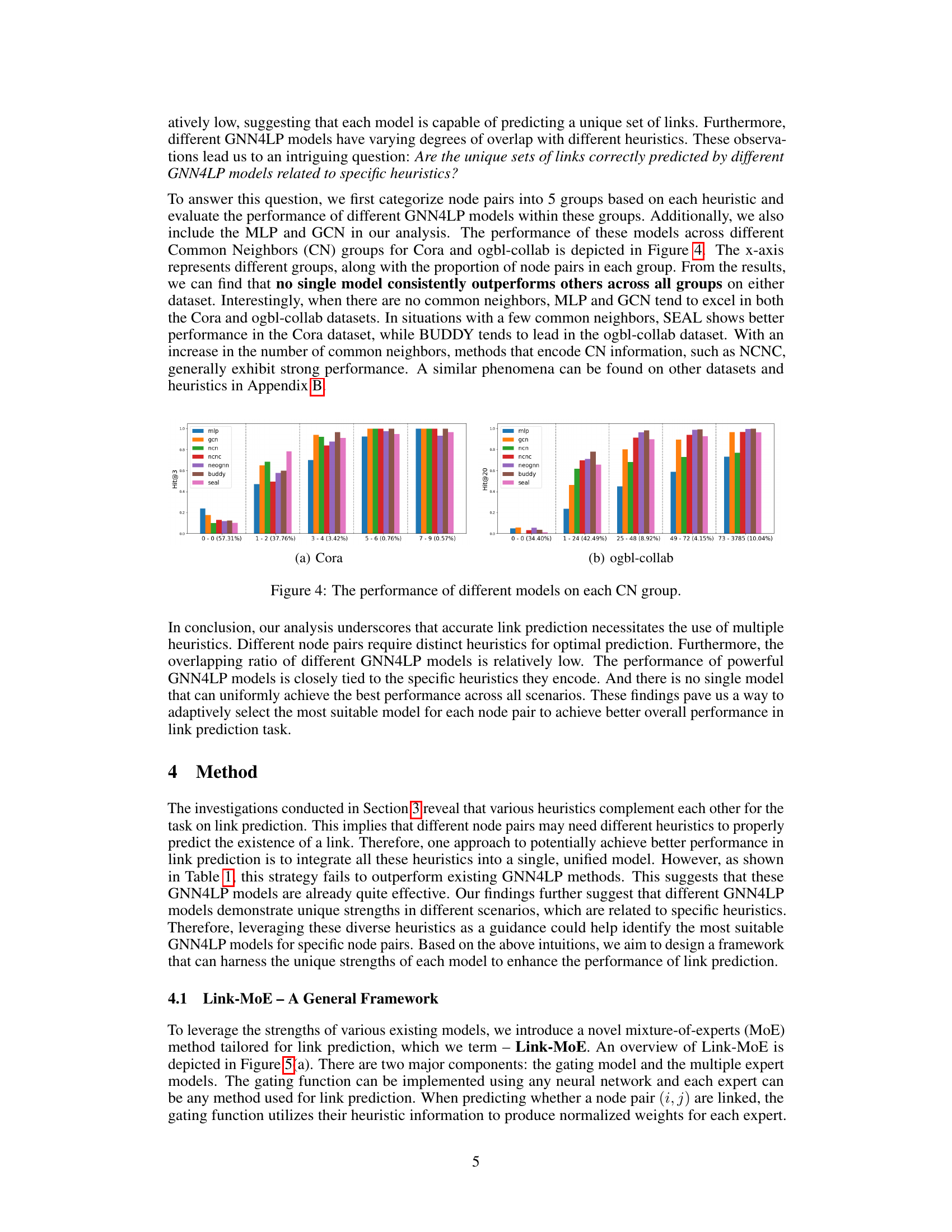
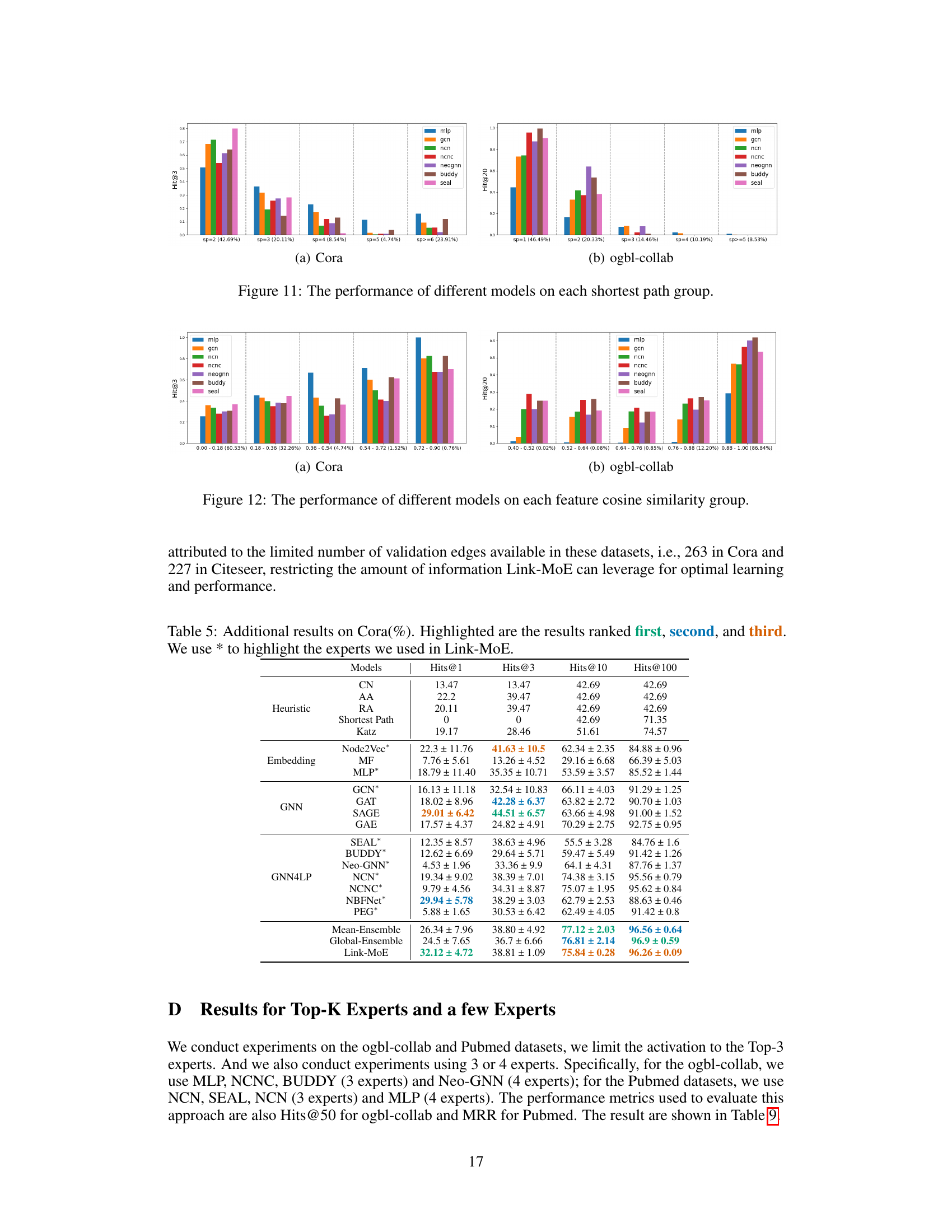
The figure shows the performance of different GNN4LP models (MLP, GCN, NCN, NCNC, NeoGNN, BUDDY, SEAL) across different groups of node pairs categorized by the number of common neighbors (CN). The x-axis represents the different CN groups, with the proportion of node pairs in each group indicated. The y-axis shows the performance metric (Hits@3 for Cora and Hits@20 for ogbl-collab). The figure illustrates that no single model consistently outperforms others across all CN groups on either dataset, demonstrating that different models are better suited for node pairs with varying numbers of common neighbors.
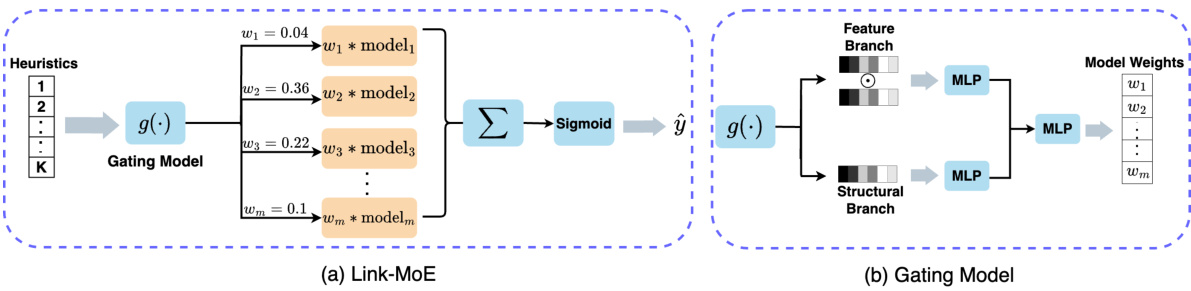
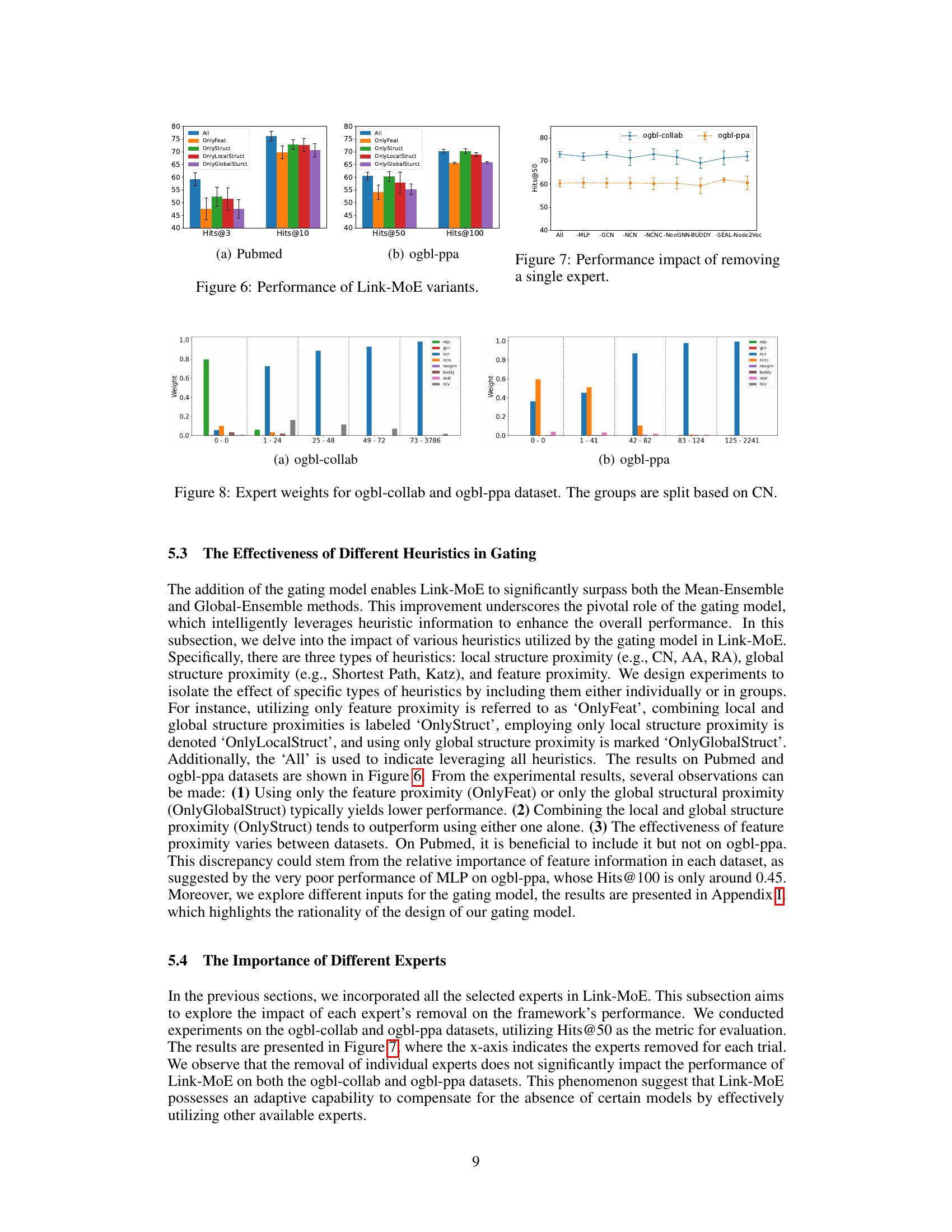
This figure illustrates the architecture of the Link-MoE model, a mixture-of-experts model for link prediction. The model consists of two main components: a gating model and multiple expert models. The gating model takes heuristic information (local structure proximity, global structure proximity, and feature proximity) as input and produces normalized weights for each expert model. These weights determine the contribution of each expert to the final prediction. The expert models are various GNN4LP models which produce their own probability for link existence. The final output is a weighted sum of the expert models’ predictions which is passed through a sigmoid function. The gating model itself is composed of two MLPs, one for feature-based heuristics and one for structural heuristics. These two branches are concatenated and passed through a final MLP with a softmax activation.
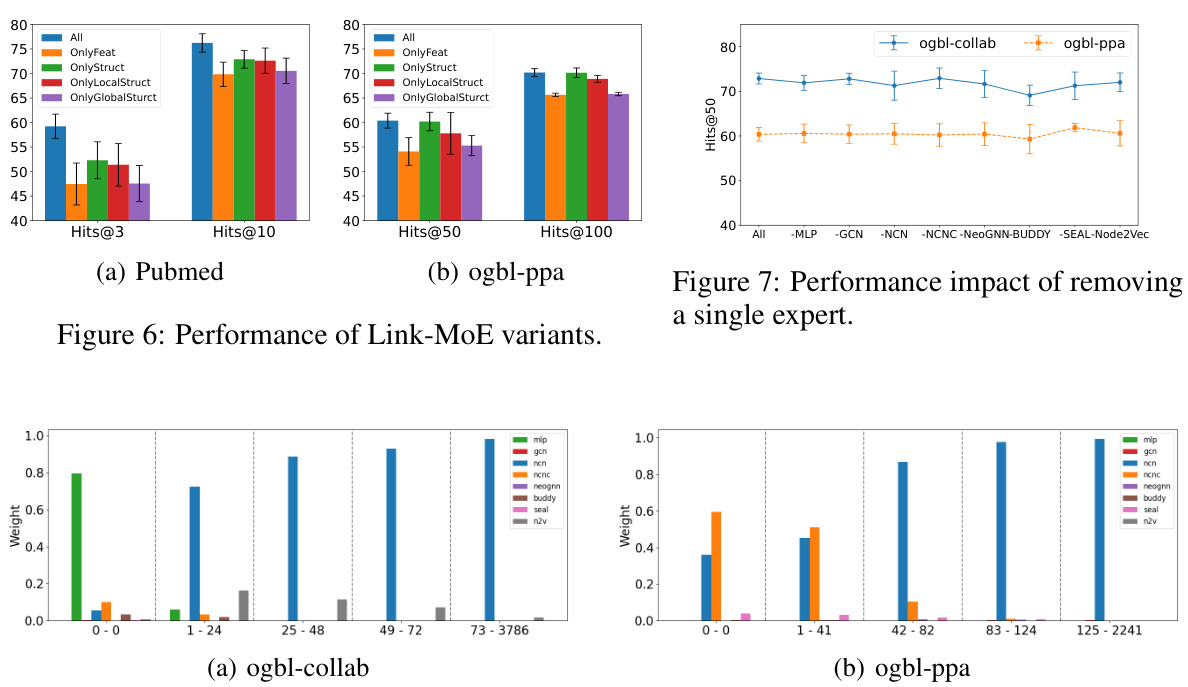
The figure shows the Hits@K values for different combinations of heuristics (Common Neighbors, Shortest Path, and Feature Cosine Similarity) on the Citeseer and ogbl-collab datasets. It demonstrates that combining multiple heuristics generally improves performance compared to using a single heuristic alone. The performance of each individual heuristic also varies across datasets, highlighting the need for adaptable methods that can select appropriate heuristics for different datasets and node pairs.
This figure shows the Hits@K (K=3 for Citeseer and K=20 for ogbl-collab) results of using different combinations of heuristics for link prediction. It demonstrates the individual performance of each heuristic (CN, SP, FCS) and the improvements achieved by combining them. The results highlight the complementarity of heuristics and how combining them can lead to better prediction accuracy.
The figure shows a heatmap representing the Jaccard similarity between pairs of link prediction methods on the ogbl-collab dataset. Each cell (i, j) shows the Jaccard index between the set of correctly predicted links by method i and the set of correctly predicted links by method j. A higher value indicates more overlap in the links predicted by the two methods. The methods included are a mix of heuristic methods, GNN-based methods, and ensemble methods. The heatmap helps to visualize the degree of complementarity between the different approaches and identifies which methods tend to predict similar links and which ones tend to predict distinct sets of links.

This figure shows the performance of different link prediction models (MLP, GCN, NCN, NCNC, NeoGNN, BUDDY, SEAL) across various groups of node pairs categorized by their shortest path length. The x-axis represents the shortest path length between nodes in each group, while the y-axis shows the Hits@3 and Hits@20 metrics (depending on the dataset) reflecting the model’s performance within each group. This visualization helps to understand how different models perform under varying degrees of global structural proximity (as shortest path length represents). It is observed that different models have different strengths under varying shortest path length.
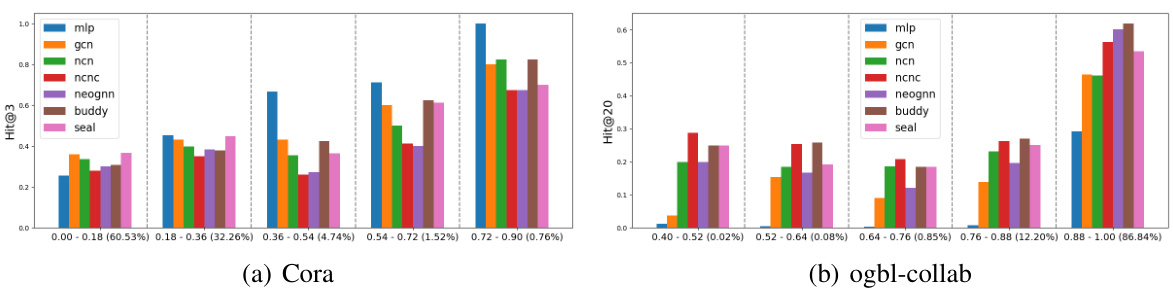
This figure shows the performance of various GNN-based link prediction models across different groups of node pairs categorized by their number of common neighbors. The x-axis represents the different CN groups, and the y-axis shows the Hits@3 or Hits@20 metric (depending on dataset size). The figure demonstrates that no single model consistently outperforms others across all groups on the Cora and ogbl-collab datasets. For instance, when there are no common neighbors, MLP and GCN tend to perform well. With an increase in common neighbors, models that explicitly encode CN information, like NCNC, tend to perform better. This observation highlights the absence of a universally superior model, and that using multiple models or adopting a model-selection strategy could improve overall prediction accuracy.
This figure shows the Hits@K (K=3 for Citeseer and K=20 for ogbl-collab) results for different combinations of heuristics used in link prediction. It demonstrates the performance of individual heuristics (CN, SP, FCS) and their combinations. The diagonal shows the individual heuristic performance. The off-diagonal elements show the performance when combining heuristics.
The figure shows the Hits@K (K=3 for Citeseer and K=20 for ogbl-collab) for three individual heuristics (Common Neighbors, Shortest Path, and Feature Cosine Similarity) and their combinations. The results demonstrate that combining multiple heuristics generally enhances overall performance compared to using a single heuristic. The performance of each heuristic also varies across different datasets.
More on tables
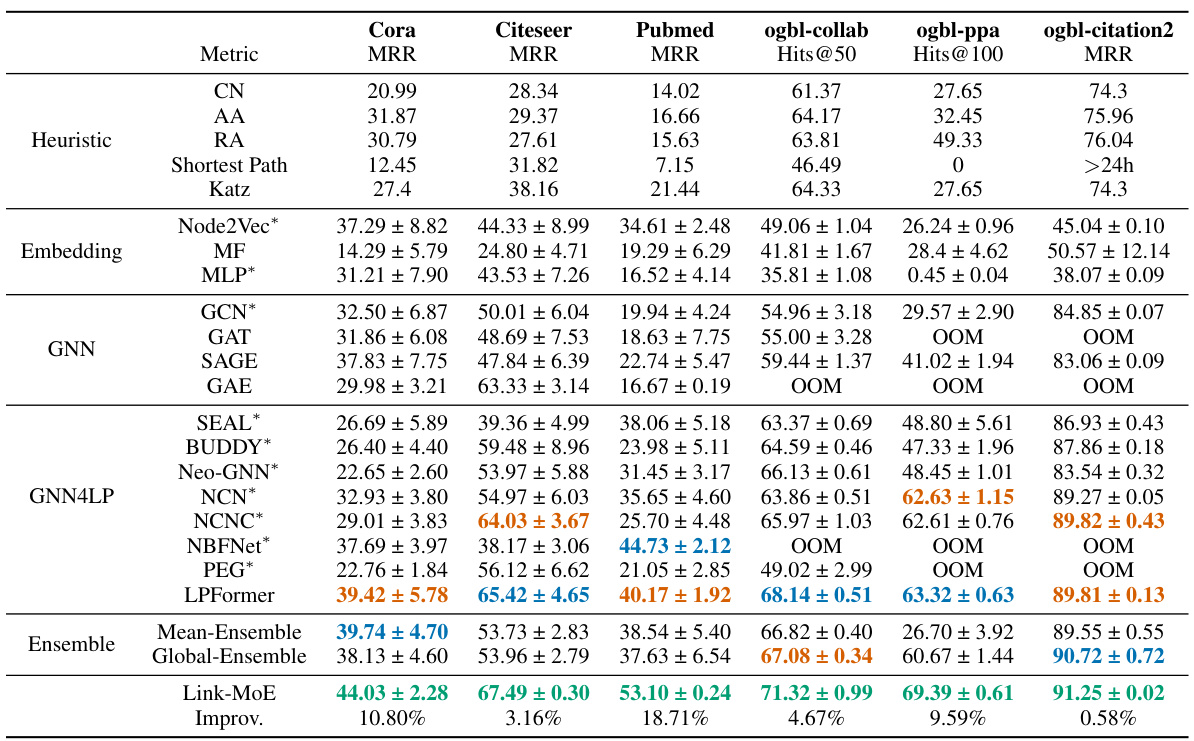
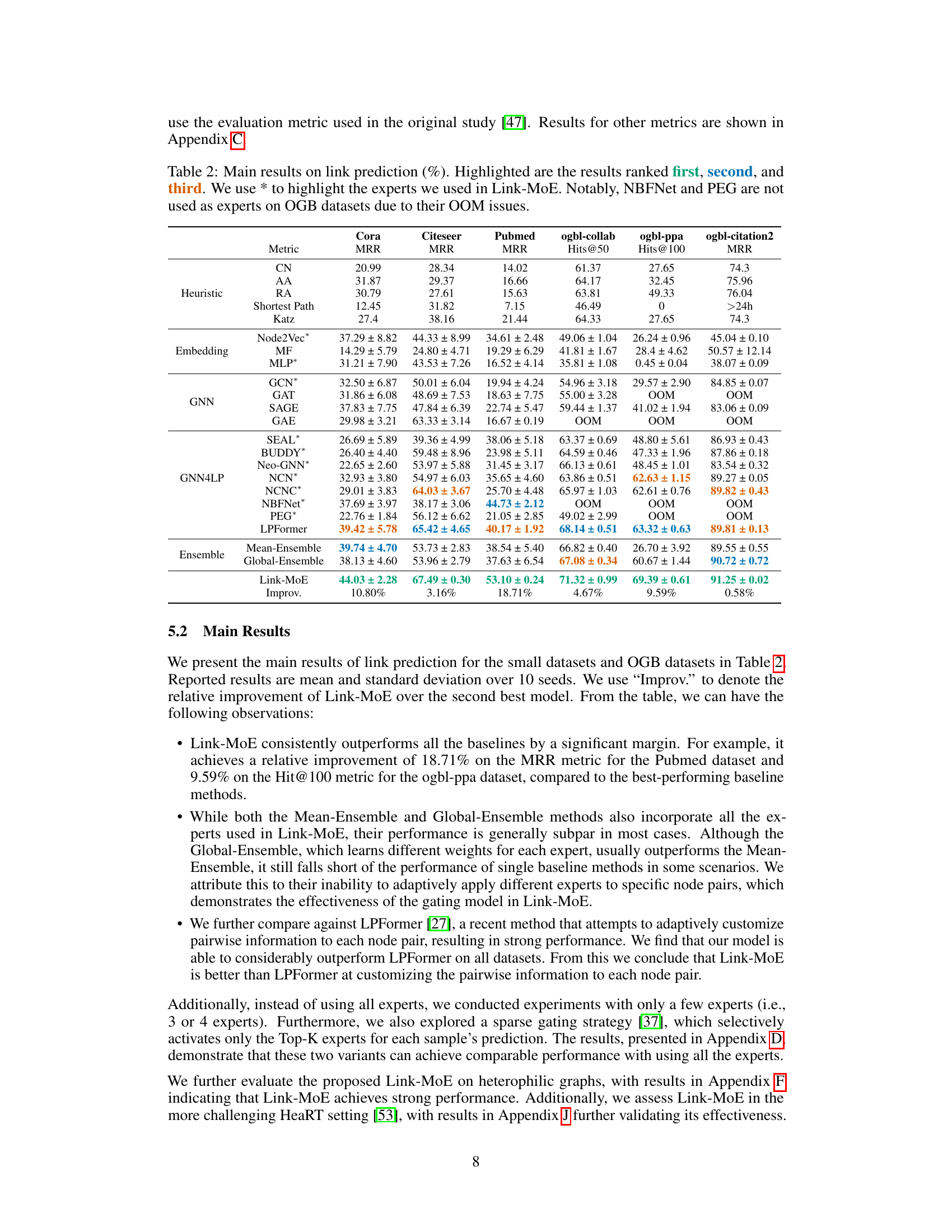
This table presents the main results of the link prediction experiments conducted on eight benchmark datasets. The results are shown in terms of Mean Reciprocal Rank (MRR) and Hits@K (where K varies based on the dataset). It compares the performance of Link-MoE against several baseline methods, including heuristic methods, embedding methods, Graph Neural Networks (GNNs), and other state-of-the-art GNN4LP methods. The table highlights the top three performing methods for each dataset and metric and indicates which methods were used as experts within the Link-MoE model. It also notes that due to out-of-memory (OOM) errors, NBFNet and PEG were not used as experts on the larger OGB datasets.

This table presents the key statistics for eight datasets used in the paper’s experiments, including the number of nodes, edges, and the mean node degree. It also specifies the train/validation/test split ratio used for each dataset. The datasets represent a mix of homophilic and heterophilic graph types to ensure a comprehensive evaluation of the proposed method.
This table shows the main results of the link prediction task on eight benchmark datasets, including three citation networks (Cora, Citeseer, Pubmed) and five OGB datasets. It compares the performance of the proposed Link-MoE model against various baselines, including heuristic methods, embedding methods, GNNs, and other GNN4LP methods. The table reports the Mean Reciprocal Rank (MRR) and Hits@K metrics. Results are highlighted to show the top three performers for each dataset. Note that NBFNet and PEG are excluded from OGB datasets due to memory issues.
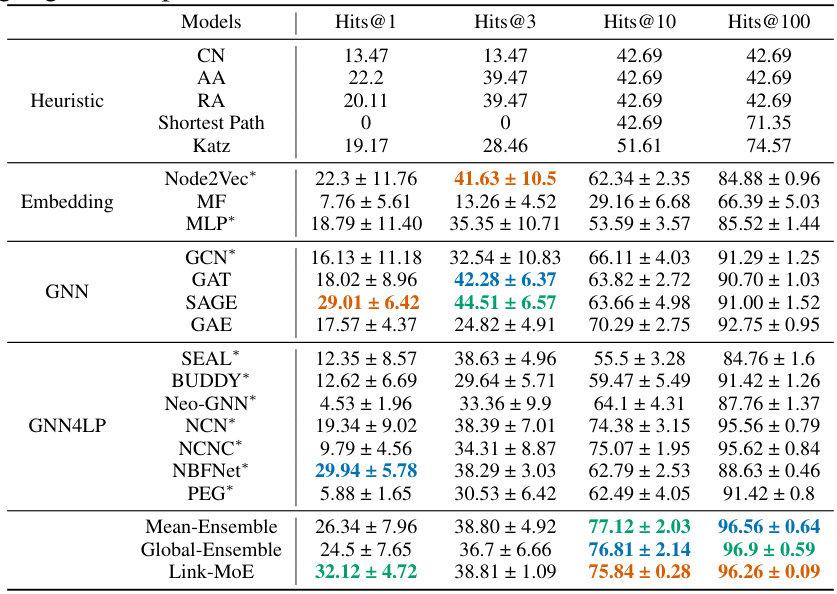
This table presents the main results of the link prediction task on several datasets, comparing the performance of Link-MoE against various baseline methods, including heuristics, embedding methods, GNNs, and other GNN4LP models. The table highlights the top three performers for each metric and dataset, indicating Link-MoE’s superior performance. The use of * indicates which models were used as experts within the Link-MoE model. It also notes that NBFNet and PEG were excluded from OGB datasets due to memory limitations.
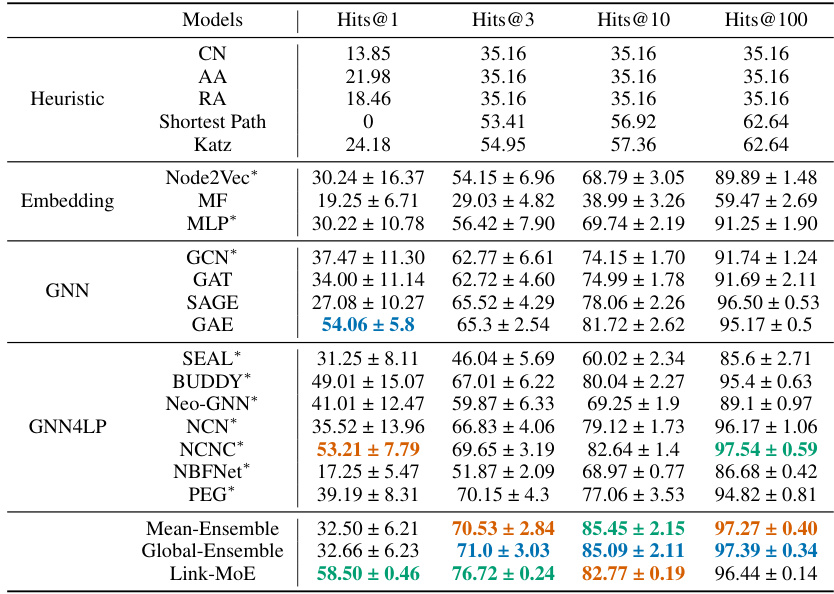
This table presents the main results of the link prediction experiments conducted on eight datasets (Cora, Citeseer, Pubmed, ogbl-collab, ogbl-ppa, ogbl-citation2, Chameleon, and Squirrel). It compares the performance of Link-MoE against various baseline methods, including heuristic approaches, embedding methods, Graph Neural Networks (GNNs), and state-of-the-art GNN4LP models. The table shows the Mean Reciprocal Rank (MRR) for smaller datasets and Hits@K for larger datasets. The best performing models are highlighted for each dataset and metric. It’s worth noting that NBFNet and PEG were excluded from the OGB dataset experiments due to out-of-memory (OOM) issues.
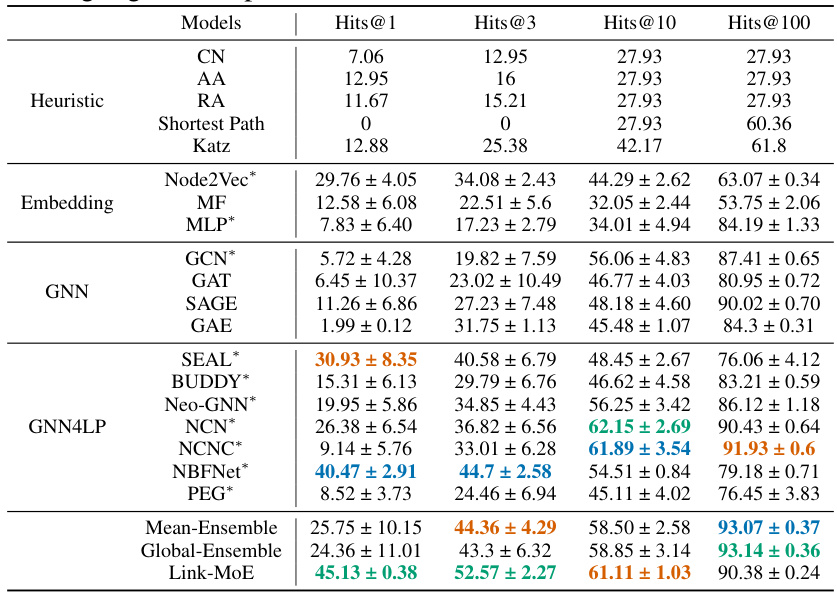
This table presents the main results of the link prediction experiments conducted on various datasets (Cora, Citeseer, Pubmed, ogbl-collab, ogbl-ppa, ogbl-citation2). It compares the performance of the proposed Link-MoE model against several baseline methods, including heuristic methods, embedding methods, various GNNs, and other GNN4LP models. The table highlights the top three performing methods for each dataset and metric (MRR and Hits@K). The results demonstrate Link-MoE’s superior performance compared to other methods and emphasize the impact of utilizing a mixture of experts (MoE) approach.
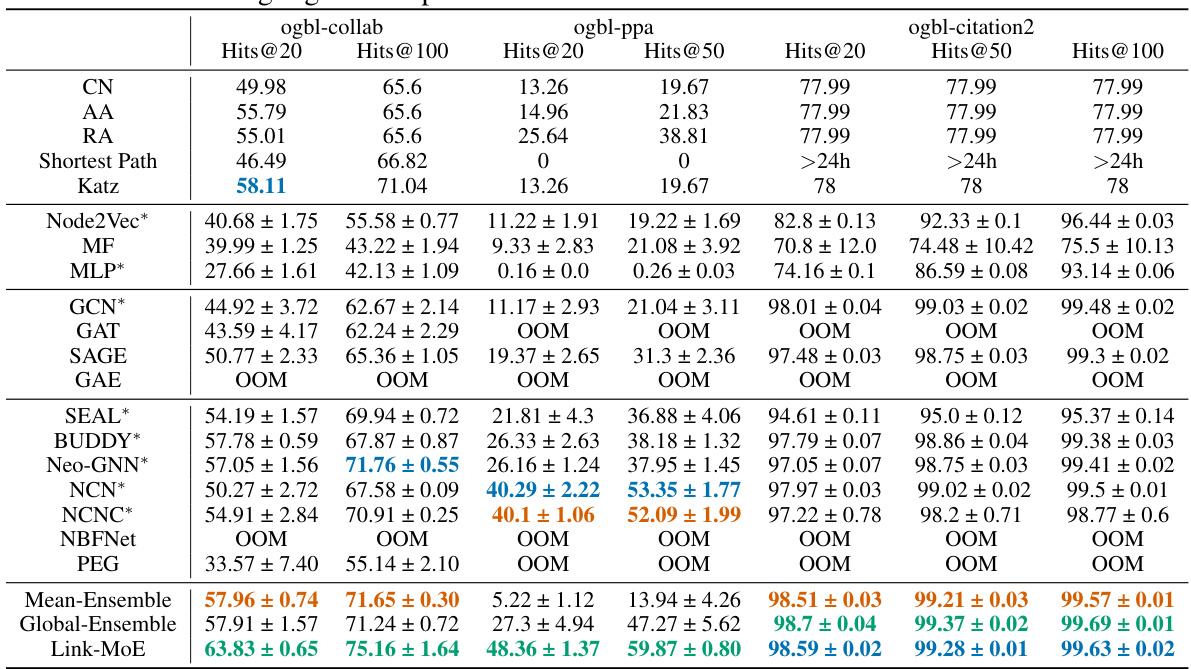
This table presents the main results of the link prediction experiments conducted on various datasets (Cora, Citeseer, Pubmed, ogbl-collab, ogbl-ppa, and ogbl-citation2). It compares the performance of Link-MoE against several baseline methods, including heuristic methods, embedding methods, GNNs, and other GNN4LP models. The results are reported as mean and standard deviation over 10 runs for each method and dataset. The best performing models for each metric are highlighted. NBFNet and PEG were not included in the OGB dataset experiments due to out-of-memory errors.
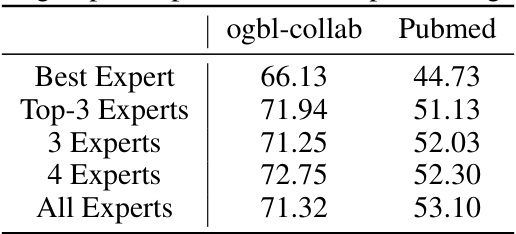
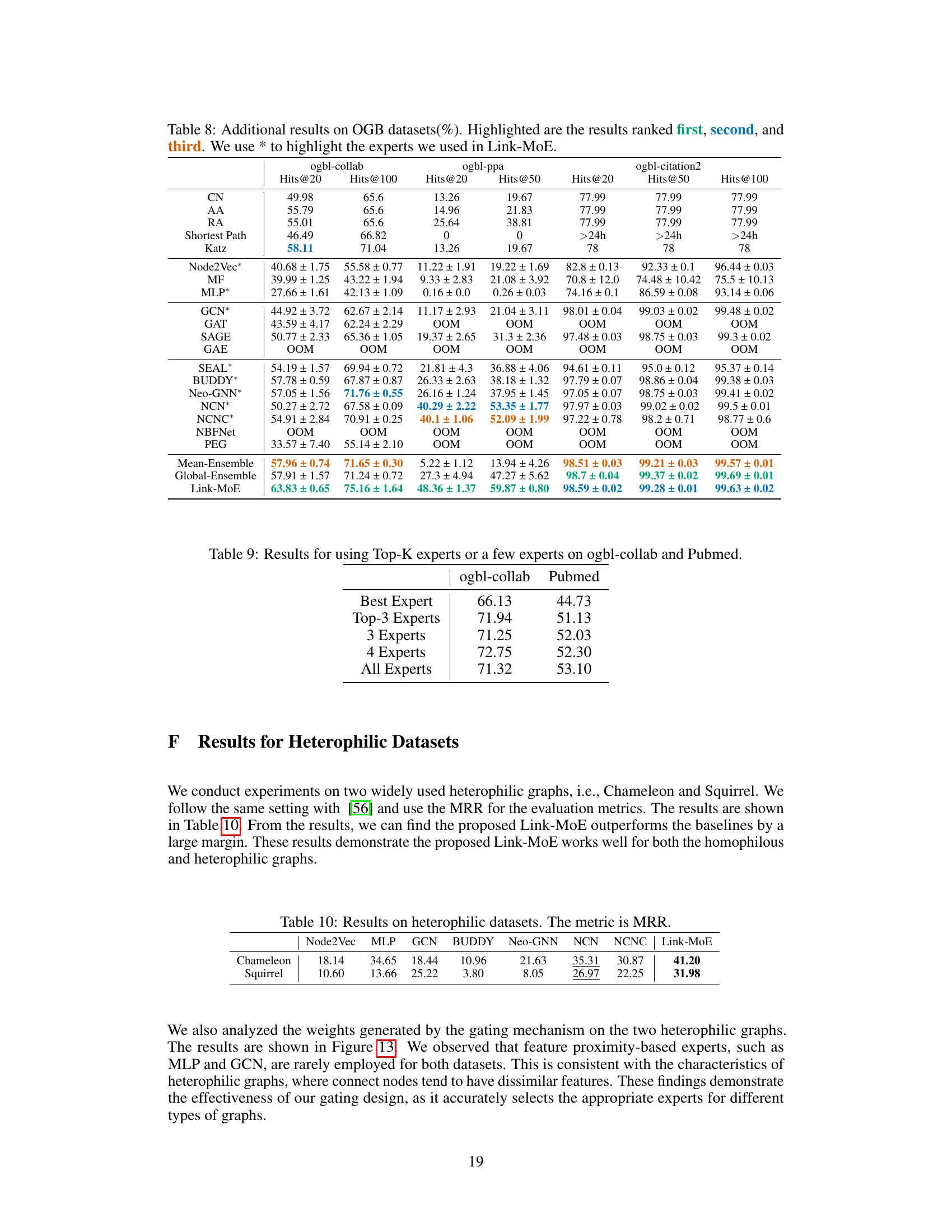
This table presents the results of experiments conducted on the ogbl-collab and Pubmed datasets using different numbers of experts in the Link-MoE model. The results show Hits@50 for ogbl-collab and MRR for Pubmed. The ‘Best Expert’ row indicates the performance of the single best-performing expert model. The rows ‘Top-3 Experts’, ‘3 Experts’, ‘4 Experts’, and ‘All Experts’ show the performance when using the top 3, a selected 3, a selected 4, and all experts, respectively. The comparison shows the improvement in performance gained by using multiple experts with Link-MoE compared to individual best experts.

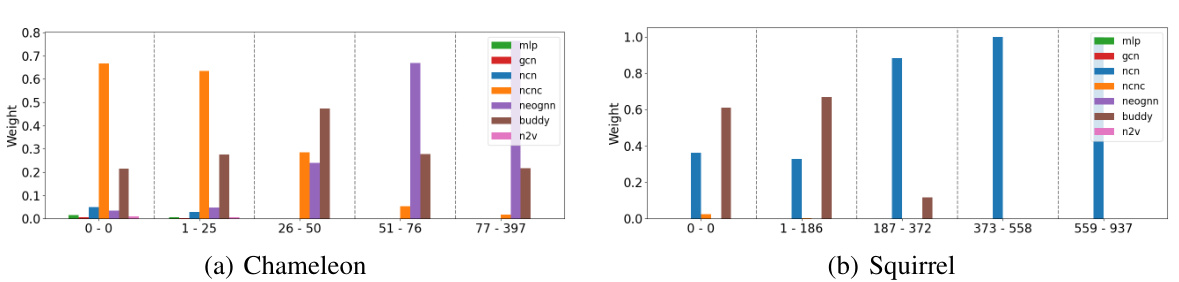
This table presents the Mean Reciprocal Rank (MRR) achieved by different link prediction models on two heterophilic graph datasets: Chameleon and Squirrel. The results show the performance of various baselines (Node2Vec, MLP, GCN, BUDDY, Neo-GNN, NCN, NCNC) and the proposed Link-MoE model. The MRR metric is a ranking metric commonly used in link prediction to measure the quality of the predicted rankings.
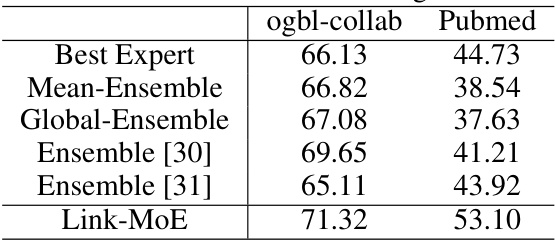
This table compares the performance of Link-MoE against two ensemble baselines (Mean-Ensemble and Global-Ensemble) and two other ensemble methods from existing literature on the ogbl-collab and Pubmed datasets. The results highlight that Link-MoE significantly outperforms these ensemble approaches, emphasizing the advantage of its dynamic gating mechanism which assigns weights to each expert model based on specific node pairs.
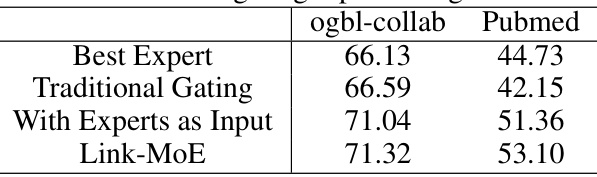
This table compares the performance of Link-MoE with different gating inputs on the ogbl-collab and Pubmed datasets. It shows the results for using only node features in the gating mechanism (Traditional Gating), using both node features and expert model predictions (With Experts as Input), and the full Link-MoE model. The results demonstrate the effectiveness of the designed gating model.

This table presents the main results of the link prediction experiments conducted on several benchmark datasets (Cora, Citeseer, Pubmed, ogbl-collab, ogbl-ppa, ogbl-citation2). It compares the performance of Link-MoE against various baseline methods, including heuristic approaches, embedding methods, GNNs, and other GNN4LP models. The results are reported as Mean Reciprocal Rank (MRR) and Hits@K (where K varies by dataset). Significant improvements achieved by Link-MoE are highlighted.

This table presents the main results of the link prediction experiments conducted on various datasets. It compares the performance of the proposed Link-MoE model against several baseline methods, including heuristic methods, embedding methods, GNNs, and other GNN4LP models. The results are presented in terms of Mean Reciprocal Rank (MRR) and Hits@K metrics. The table highlights the top three performing models for each dataset and indicates which models were used as experts within the Link-MoE framework. It also notes that due to out-of-memory (OOM) errors, NBFNet and PEG were not included as experts in the experiments using OGB datasets.
Full paper#