↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Synthetic face recognition (SFR) is crucial due to privacy concerns surrounding the use of real facial data. Current methods struggle to generate diverse yet identity-consistent synthetic faces, hindering the performance of trained face recognition models. This limitation arises from the difficulty in balancing inter-class diversity (differences between identities), intra-class diversity (variations within an identity), and intra-class identity preservation (consistency of an individual’s features across different images).
The researchers introduce ID³, a novel diffusion-based SFR model that directly addresses these issues. ID³ leverages an innovative ID-preserving loss function and a corresponding sampling algorithm to generate high-quality synthetic face images that maintain identity while exhibiting both inter-class and intra-class diversity. Rigorous testing on five challenging benchmarks shows that ID³ significantly outperforms existing state-of-the-art methods, demonstrating its potential to revolutionize privacy-preserving face recognition.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses a critical challenge in face recognition: the need for large, high-quality datasets while preserving privacy. The proposed method, ID³, offers a novel approach to generating synthetic datasets that outperforms existing methods in terms of accuracy and diversity, opening new avenues for research in privacy-preserving AI and synthetic data generation. Its theoretical grounding and practical effectiveness make it a significant contribution to the field.
Visual Insights#

This figure illustrates the forward pass of the ID³ model, showing how it uses an image, its attributes, and its embedding to generate a denoised image. The process involves adding noise to the image, using a diffusion model to process it, and a denoising network to reconstruct a cleaned image conditioned on the identity and attributes. The loss function is composed of terms for denoising, one-step reconstruction, an inner product term related to identity preservation, and a constant.
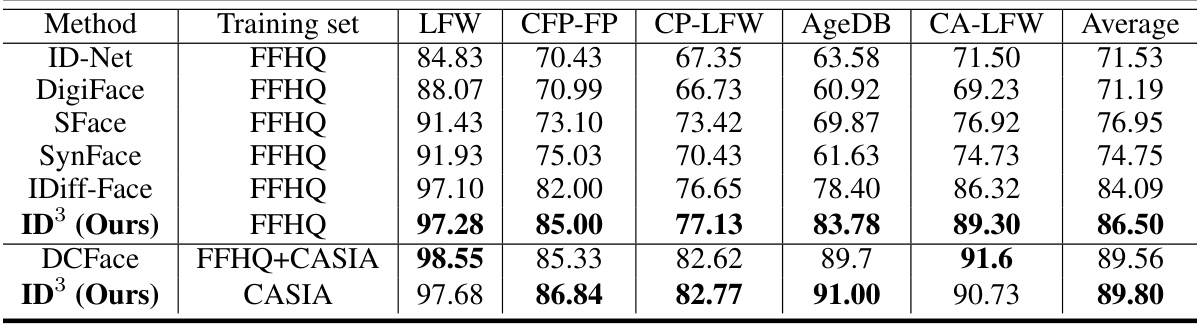
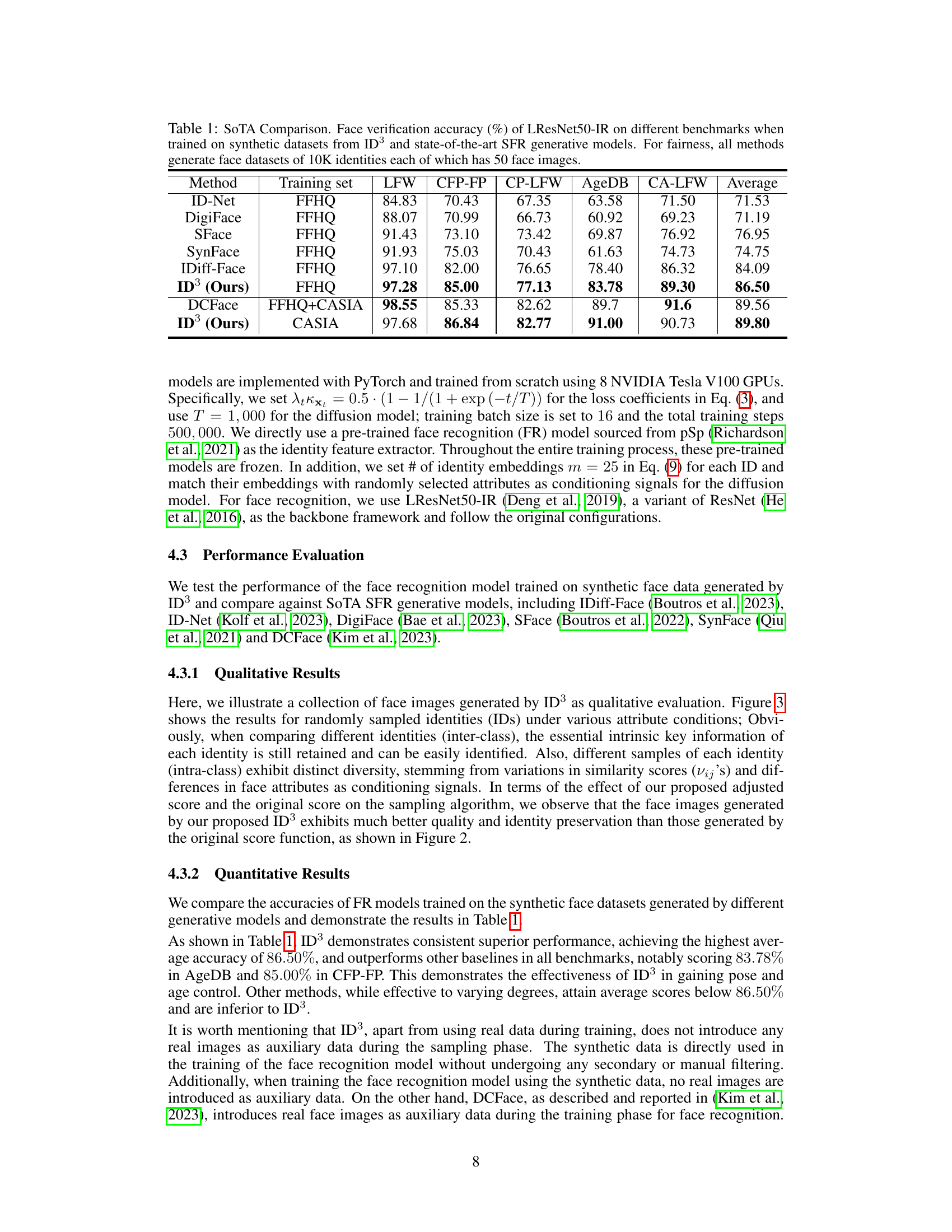
This table compares the face verification accuracy of the LResNet50-IR model on five benchmark datasets (LFW, CFP-FP, CP-LFW, AgeDB, and CA-LFW) when trained on synthetic face datasets generated by different methods, including the proposed ID³ model and several state-of-the-art (SOTA) models. The table highlights the performance improvement achieved by ID³ in comparison to the SOTA methods. All methods used the same number of identities and images in their synthetic datasets to ensure fair comparison.
In-depth insights#
ID³: SFR Model#
The proposed ID³ model presents a novel approach to Synthetic Face Recognition (SFR) by leveraging diffusion models. Its core innovation lies in addressing the limitations of existing diffusion-based SFR methods. ID³ explicitly incorporates identity preservation and inter/intra-class diversity, achieving a balance between generating realistic and diverse synthetic faces while maintaining identity consistency. This is achieved through a carefully designed loss function that includes an identity-preserving term, theoretically grounded to maximize a lower bound of conditional log-likelihood. Furthermore, ID³ introduces a novel sampling algorithm, operating on an adjusted gradient vector field, to ensure identity-consistent sample generation. The model’s effectiveness is demonstrated by its superior performance on various benchmarks compared to state-of-the-art SFR approaches, showcasing its potential for creating high-quality, privacy-preserving training datasets for facial recognition systems.**
ID-Preserving Loss#
An ID-preserving loss function in synthetic face recognition (SFR) is crucial for generating realistic and diverse synthetic faces while maintaining identity consistency. It aims to balance two often-conflicting objectives: diversity (both inter- and intra-class) and identity preservation. A well-designed ID-preserving loss would penalize deviations from the target identity embedding, encouraging the model to generate faces that are consistent with the specified identity. However, it must avoid overly restricting the model, preventing the generation of diverse facial attributes (pose, age, expression, etc.) within each identity. The success of such a loss function hinges on its ability to effectively guide the model towards the desired balance between identity preservation and diversity, without sacrificing the quality of the generated images. This might involve careful weighting of different loss components (e.g., reconstruction loss, identity loss, and possibly diversity-promoting losses), or the use of advanced techniques like regularization or adversarial training. Theoretical analysis supporting the effectiveness of the loss function (e.g., relating it to a lower bound on the likelihood) would significantly strengthen the proposed approach. The choice of identity embedding method also matters: a robust and discriminative embedding is critical for effective identity preservation.
Sampling Algorithm#
The effectiveness of diffusion models in generating synthetic face datasets hinges significantly on the employed sampling algorithm. A naive approach, operating directly on the score vector field without incorporating identity information, can lead to identity inconsistencies and lack of diversity. This paper proposes an innovative ID-preserving sampling algorithm. Theoretically grounded in maximizing a lower bound of adjusted conditional log-likelihood, it operates on a modified gradient vector field. This modification incorporates identity-preserving constraints to ensure that the generated samples exhibit identity consistency. By operating on an adjusted gradient vector field, the algorithm efficiently guides the sampling process, leading to higher quality and more realistic synthetic faces. The algorithm’s design is crucial for obtaining a training dataset that closely resembles real-world face data, enabling robust face recognition model training, while safeguarding privacy.
Dataset Generation#
The process of generating a synthetic face dataset is critical for the success of this research. The paper proposes a novel approach that prioritizes identity preservation while simultaneously maximizing intra-class and inter-class diversity. This is achieved through a multi-stage process involving solving the Tammes problem to optimally distribute identity embeddings, introducing variations within each identity group using random perturbations, and finally, leveraging a new sampling algorithm to generate diverse yet consistent facial appearances. The integration of identity-preserving loss functions and a theoretically-justified sampling technique sets this method apart, offering strong theoretical guarantees. The overall goal is to create a synthetic dataset that closely mimics the distribution of real-world face data, thus enabling the training of robust and accurate face recognition models while adhering to privacy regulations. The method’s effectiveness is validated by extensive experiments on five challenging benchmarks, showing significant advantages compared to state-of-the-art approaches.
SFR Benchmarks#
Evaluating Synthetic Face Recognition (SFR) models necessitates robust benchmarks. These benchmarks should encompass a variety of challenges mirroring real-world scenarios, including variations in pose, lighting, age, and image quality. Standard face recognition datasets, adapted for SFR evaluation, could provide a starting point but might require modifications to account for the unique characteristics of synthetic data. The metrics employed should directly relate to FR performance, such as verification accuracy and identification accuracy. A critical aspect is the need for diverse and representative synthetic datasets that adequately mimic the distribution of real-world facial data. This ensures that the benchmarks are not only challenging but also provide meaningful insights into the generalizability and robustness of SFR models. Furthermore, the evaluation process should be transparent and reproducible, detailing the data generation process, model training parameters, and evaluation protocols. Only with comprehensive and carefully designed benchmarks can the field of SFR move forward in a reliable and meaningful manner. The development of standardized benchmarks is crucial for fair comparisons and accelerates progress in SFR research.
More visual insights#
More on figures

This figure illustrates the forward pass of the ID³ model during training. It shows how the model takes an image, its corresponding identity embedding (from a face recognition model), and its predicted attributes as input. The image is then noised using a diffusion process, and a denoising network is used to reconstruct the original image from this noisy version, conditioned on the identity and attributes. The training loss is a combination of a denoising term, a one-step reconstruction term, an inner-product term, and a constant, aiming to preserve identity while generating diverse facial attributes.

This figure compares the quality of face images generated using two different score functions: the adjusted score function (∇ log p(x|y, s)) and the original score function (∇ log p(x|y, s)). The adjusted score function, a key innovation in the ID³ model, incorporates an additional term to preserve identity while increasing diversity. The figure visually demonstrates that the adjusted score function produces significantly higher-quality images compared to the original score function, showcasing the benefits of ID³’s approach.

This figure displays a qualitative comparison of face images generated by the proposed ID³ model (top row) and the existing IDiff-Face model (bottom row). The goal is to show the visual differences between the two models in terms of identity preservation, intra-class diversity, and overall image quality. The top row, representing ID³, shows a variety of images showcasing different facial attributes and poses, yet maintaining consistent identity within each identity group. The bottom row, representing IDiff-Face, serves as a comparison, highlighting potential differences in the quality and diversity of generated images. This visual comparison is used to support the claim that ID³ generates higher-quality images with better identity preservation and diversity.

The figure illustrates the dataset generation process. First, N anchor embeddings (wi) are generated on a unit hypersphere, aiming for maximal separation. For each anchor, m identity embeddings (yij) are generated, clustering near the anchor but with some variance, controlled by the variables (vij). These embeddings serve as conditioning signals along with attributes (sij) for generating diverse yet identity-consistent face images using the ID³ model. Each colored group on the sphere represents one identity, and the corresponding face images are shown to the right.

This figure shows the distribution of cosine similarity scores for both inter-class and intra-class comparisons of face embeddings generated by the ID³ model. The top panel shows the distribution for [lb, ub] = [0.5, 0.7], where lb and ub are lower and upper bounds of uniform distributions used for sampling, while the bottom panel displays the distribution for [lb, ub] = [0.7, 0.9]. The x-axis represents the cosine similarity, ranging from -1 to 1, and the y-axis shows the frequency counts. The distributions demonstrate the model’s ability to generate both diverse (inter-class) and consistent (intra-class) face images.

This figure compares the distribution of pose angles in datasets generated by different models. The distributions from IDiffFace, ID³ PoseOnly 1, ID³ PoseOnly 2, and ID³ PoseOnly 3 are shown, alongside the distribution of pose angles in the FFHQ dataset. The purpose of this comparison is to illustrate the impact of varying the degree of control over the pose attribute during dataset generation on the final distribution of pose angles within the generated datasets. Different distributions can affect the performance of face recognition models trained on these datasets.
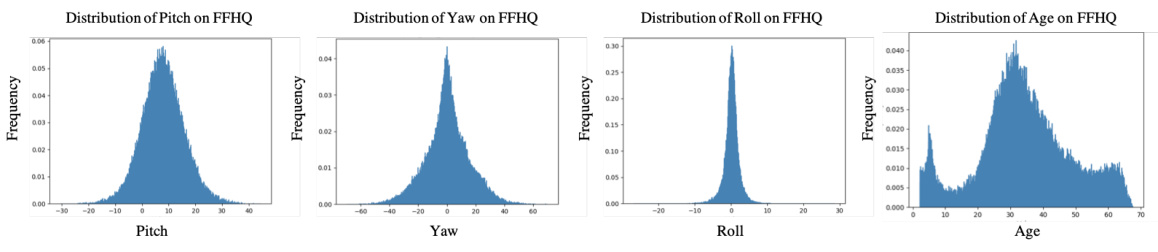
This figure presents the distributions of pitch, yaw, roll angles, and age within the FFHQ dataset. Each subplot shows a histogram representing the frequency of different values for a specific attribute (pitch, yaw, roll, or age). These distributions demonstrate the range and commonality of these attributes within the training dataset used for the ID³ model, providing context for the model’s performance in generating images with diverse facial characteristics.
More on tables
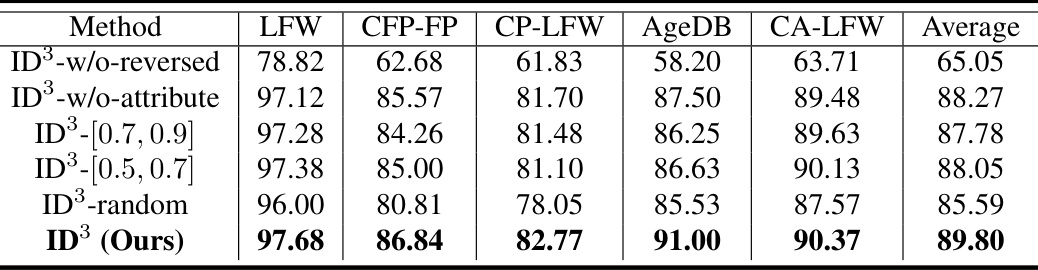
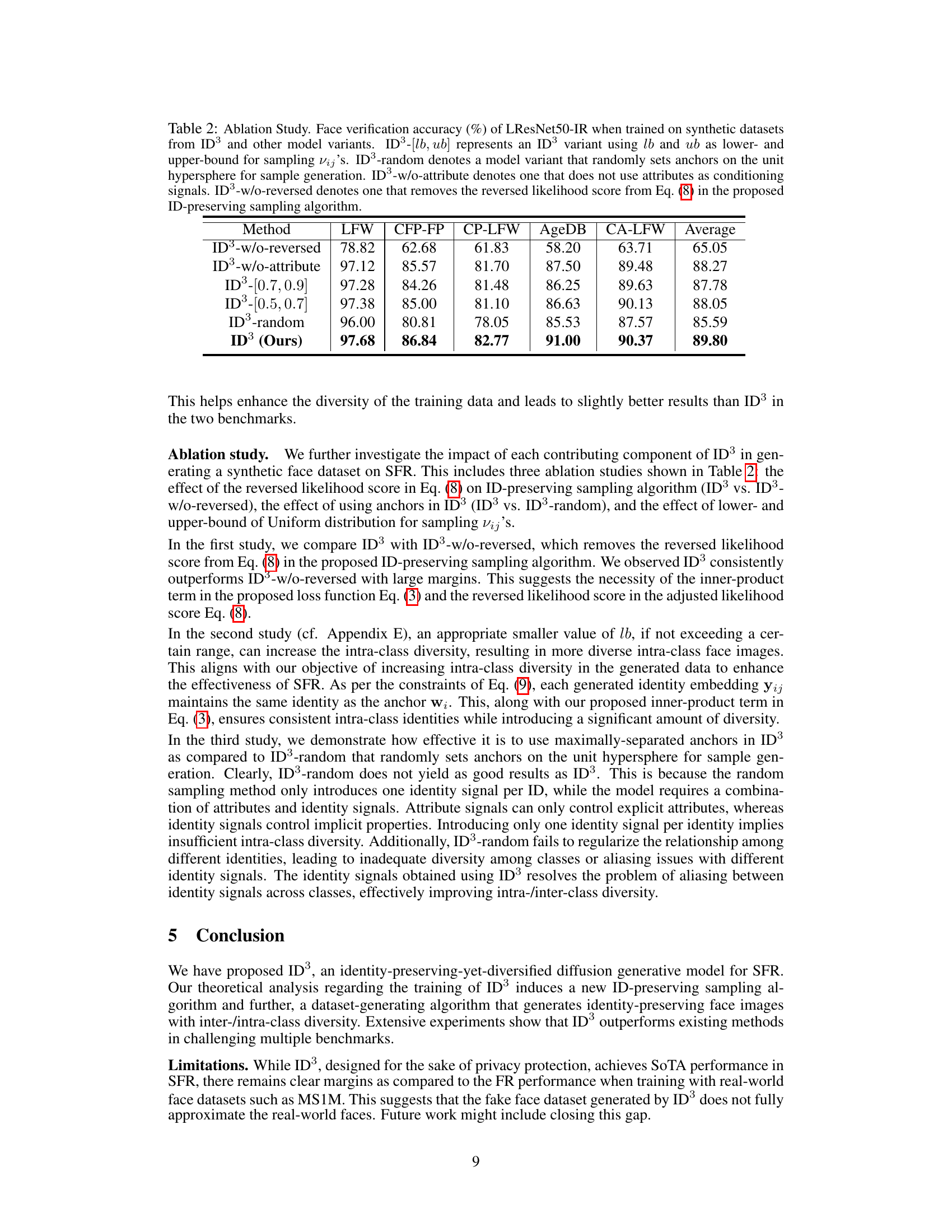
This table presents the results of an ablation study conducted to evaluate the impact of different components of the ID³ model on face verification accuracy. The study compares the performance of the full ID³ model against variations where components such as the reversed likelihood score, attribute conditioning, and the anchor generation method are removed or altered. The results show the relative contribution of each component to the overall accuracy.

This table compares the face verification accuracy of the LResNet50-IR model on five benchmark datasets (LFW, CFP-FP, CP-LFW, AgeDB, and CALFW) when trained on synthetic face datasets generated by ID³ and other state-of-the-art (SOTA) methods. The table shows that ID³ achieves the highest average accuracy across all benchmarks, demonstrating its effectiveness in generating high-quality synthetic data for face recognition.
Full paper#