↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
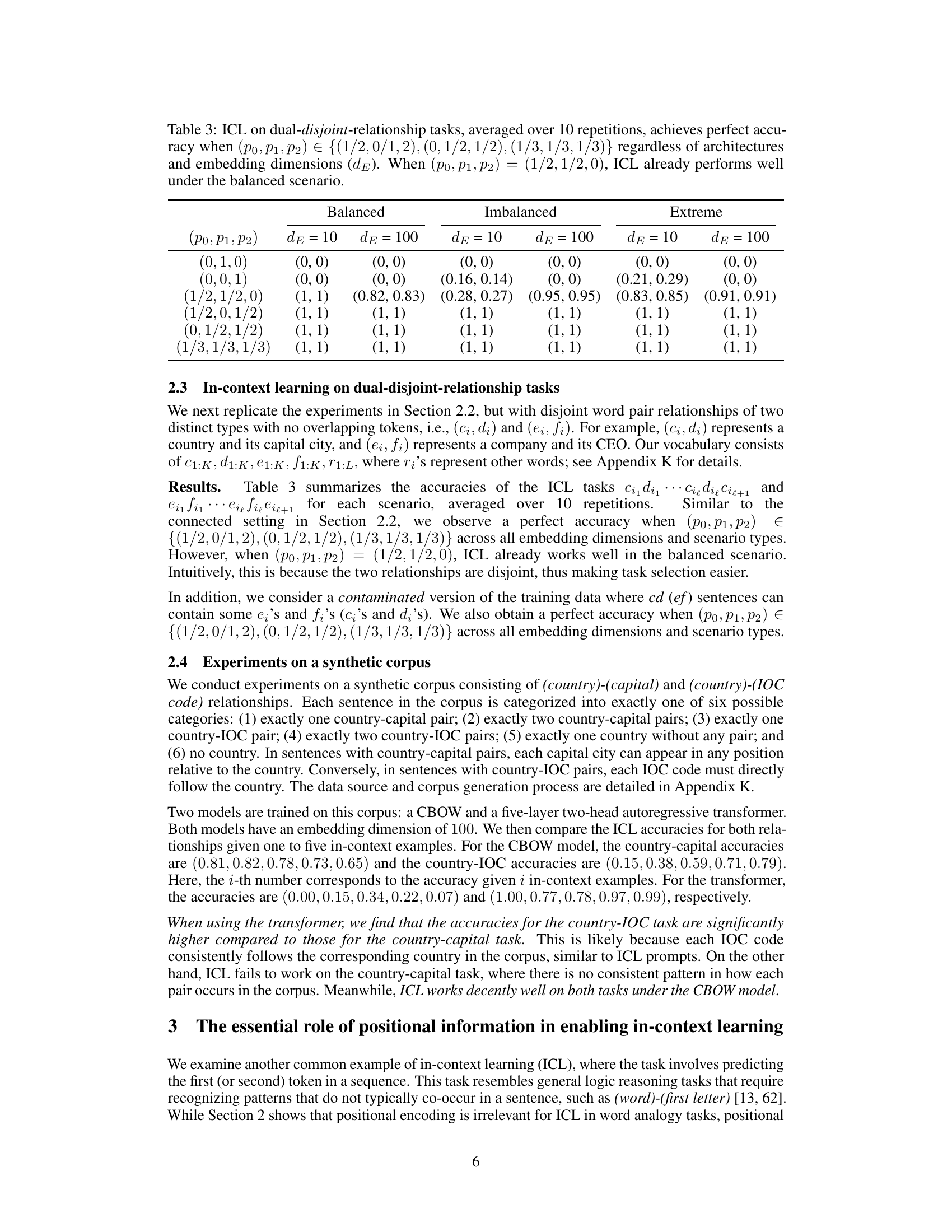
Large language models (LLMs) exhibit impressive in-context learning (ICL) abilities, enabling them to perform new tasks based on examples alone. However, existing ICL theories mostly assume structured training data, unlike the unstructured text data used to train LLMs. This creates a gap in our understanding of how LLMs achieve ICL. This paper addresses this gap by investigating what factors in the training data enable successful ICL.
The researchers investigate various ICL tasks, including word analogy and logic reasoning, using different language models and exploring the impact of data structure. They find that word analogy can emerge solely from word co-occurrence, even in simple language models, but positional information is critical for logic reasoning. Interestingly, they identify cases where ICL fails: tasks requiring generalization to new patterns and analogy completion with fixed training positions. These findings highlight the importance of specific training data structures for successful ICL in LLMs.
Key Takeaways#
Why does it matter?#
This paper is crucial because it challenges existing assumptions about in-context learning (ICL) in large language models (LLMs). By demonstrating that ICL can emerge from simpler mechanisms than previously thought, and identifying crucial data structural elements, it opens new avenues for understanding and improving LLMs. This research directly impacts the development of more efficient and effective LLMs, shaping future research directions in this rapidly evolving field.
Visual Insights#
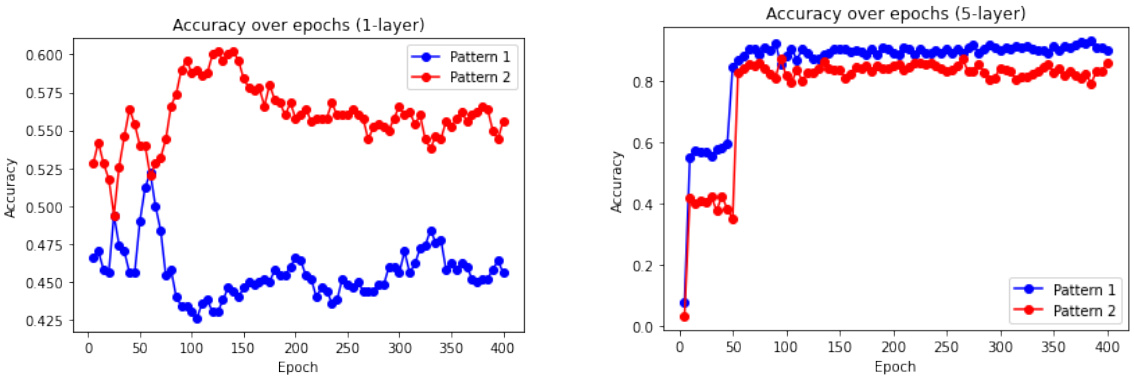
This figure shows the accuracy of one-layer and five-layer transformer models over epochs when trained on sequences with two patterns (abcadefd and abcbdefe). The left panel displays the accuracy for a one-layer model, illustrating its inability to distinguish between the two patterns. The right panel shows the accuracy of a five-layer model, which successfully differentiates between the two patterns.

This table presents the average accuracy of In-context Learning (ICL) on single-relationship word analogy tasks. The experiments are performed across different embedding dimensions (de) and averaged over 10 repetitions for both clean and corrupted data. The results show consistent and good performance across the embedding dimensions, supporting Theorem 1. Even in the corrupted setting, where some word pairs are replaced with other words, there is excellent ICL performance under certain scenarios.
In-depth insights#
ICL from unstructured data#
The study of “ICL from unstructured data” reveals crucial insights into the capabilities of large language models (LLMs). LLMs, despite being trained on unstructured text data, exhibit impressive in-context learning (ICL) abilities. This challenges the common assumption that structured training data is necessary for effective ICL. The research explores how semantic relationships, inherent in the co-occurrence of words within unstructured data, enable LLMs to perform tasks like word analogy completion. Positional information, however, is shown to be critical for logic reasoning tasks that demand generalization to unseen patterns. The study highlights that ICL’s success is heavily dependent on the structural elements within training data, with failures observed when relevant word pairs appear only in fixed positions or when tasks require generalizing to unseen meta-patterns. This underscores the importance of considering both the semantic and structural properties of training data when analyzing and improving ICL in LLMs.
CBOW and word analogy#
The continuous bag-of-words (CBOW) model, a foundational neural network architecture, offers valuable insights into in-context learning (ICL). CBOW’s ability to predict a word based on its surrounding context implicitly captures semantic relationships. This is crucial for word analogy tasks. CBOW’s success stems from its capacity to learn word co-occurrence patterns. These patterns reflect semantic similarity; words often appearing in similar contexts will have closer embeddings. Consequently, the model can solve word analogies by identifying analogous relationships in the vector space. While sophisticated transformer models have surpassed CBOW in various tasks, studying CBOW in this context reveals fundamental ICL mechanisms: simple co-occurrence modeling is sufficient for many analogy tasks. This understanding highlights that complex architectures aren’t always necessary, and simpler models can effectively capture core semantic knowledge, shedding light on the ICL’s underlying mechanics. However, CBOW’s limitations become apparent when dealing with complex tasks needing positional information or generalization to novel unseen patterns. Thus, while CBOW provides insights into basic semantic relationships for word analogies, more sophisticated techniques are needed for more challenging ICL tasks.
Positional information’s role#
The research paper highlights the crucial role of positional information in in-context learning (ICL), particularly for tasks beyond simple word analogies. While co-occurrence modeling suffices for tasks involving semantically related frequently co-occurring word pairs, positional information becomes essential for more complex tasks like logic reasoning. The paper demonstrates that models trained solely on co-occurrence information struggle with tasks requiring generalization to unseen patterns or those where relevant word pairs only appear in specific training positions. Incorporating positional information, either explicitly through positional embeddings or implicitly through multi-layer architectures, enables the model to recognize patterns and generalize to new tokens or contexts. The findings reveal that the effectiveness of ICL heavily depends not just on what information is present in the training data, but critically, on how that information is structured. The nuanced interplay between co-occurrence and positional information underscores the importance of considering the structural elements within the training data when examining LLMs’ ICL capabilities.
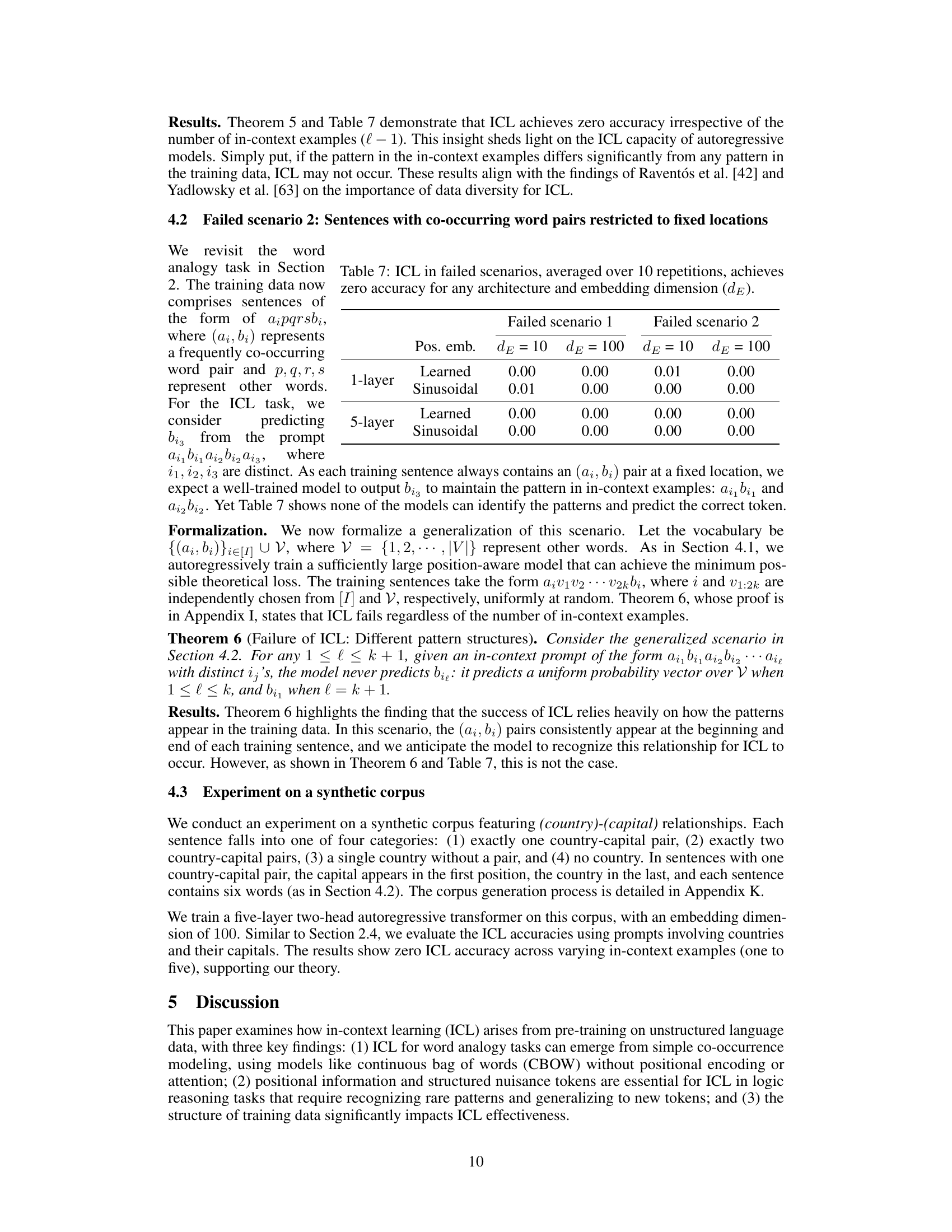
ICL failures and limitations#
The paper explores scenarios where in-context learning (ICL) fails, despite the impressive capabilities demonstrated by large language models (LLMs). Two key failure modes are identified: one involving logic reasoning tasks that require generalization to unseen patterns, and another concerning analogy completion where relevant word pairs appear only in fixed training positions. These failures highlight the critical role of structural elements within training data for successful ICL. The limitations underscore that simply modeling co-occurrence isn’t sufficient; positional information and specific data structures are crucial, especially for complex tasks. Further research should focus on understanding the interaction between model architecture and data structure to improve ICL robustness and address these limitations. The analysis of failure cases provides valuable insights into the inherent limitations of current LLMs’ ICL abilities and guides future research directions towards more reliable and robust in-context learning.
Future Research Directions#
Future research could explore scaling up the experiments to larger datasets and more diverse ICL tasks. A deeper investigation into the interplay between various architectural choices (e.g., attention mechanisms, number of layers, positional embeddings) and ICL performance across diverse tasks is needed. Theoretical work should focus on developing more precise models that capture the nuances of ICL, moving beyond co-occurrence to incorporate aspects like positional information and pattern generalization. Finally, it would be beneficial to explore the interaction between ICL and other learning paradigms, such as transfer learning and meta-learning, to enhance the model’s ability to learn new concepts from limited data. Analyzing the impact of different pre-training objectives and data structures on ICL is critical for improving its effectiveness and reliability.
More visual insights#
More on tables
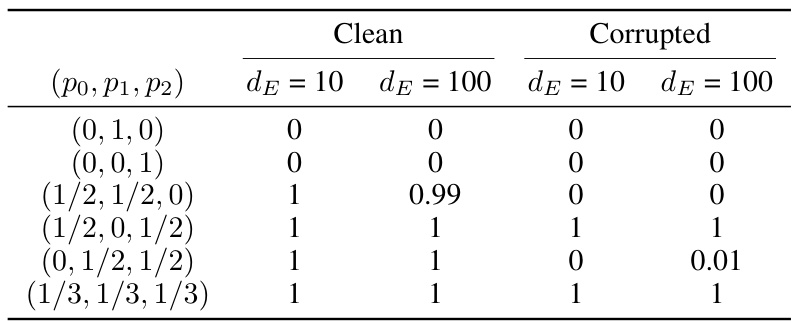
This table presents the average accuracy of In-context learning (ICL) on single-relationship word analogy tasks. The experiments were conducted with different embedding dimensions (dE = 10 and dE = 100) and different probabilities for the number of (ci, di) pairs in each sentence. Two scenarios are considered: a ‘clean’ scenario, and a ‘corrupted’ scenario. The results show the ICL performance is consistent across different embedding dimensions in the clean and corrupted scenarios, supporting Theorem 1.

This table presents the results of in-context learning (ICL) experiments on dual-connected-relationship word analogy tasks. It shows the accuracy of a CBOW model trained on sentences containing two distinct word relationships in different scenarios. The scenarios vary in the probability distribution of these relationships: balanced, imbalanced, and extreme. The results demonstrate that perfect ICL accuracy is achieved under certain probability distributions, regardless of model architecture and embedding dimensionality. However, in other distributions, performance depends on factors like imbalance and embedding dimensionality.

This table shows the results of in-context learning (ICL) experiments on dual-connected-relationship word analogy tasks. The experiments varied the probability of having zero, one, or two distinct word pairs in a sentence, along with the balance of those pairs in the data. The table shows that ICL performance is perfect under certain conditions (specific probabilities of word pair occurrences), and is robust to architectural choices and embedding dimensionality. When only a single type of relationship is prevalent, ICL is still effective under balanced conditions.
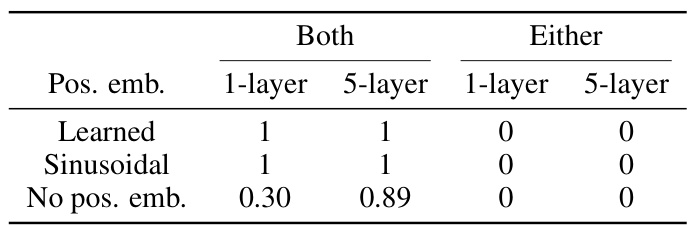
This table presents the results of an experiment assessing the accuracy of single and multi-layer transformer models in predicting the last token of sequences following the pattern x1x2x3x1. The experiment varied the number of layers (1 or 5), the type of positional embedding (learned, sinusoidal, or none), and whether each token in the vocabulary was used as the first token in both training and test sets (Both) or only one of them (Either). The results demonstrate that positional embeddings are crucial for achieving high accuracy, especially with only one layer, and that for the model to generalize well, each token should be present as the first token in both the training and test sets.
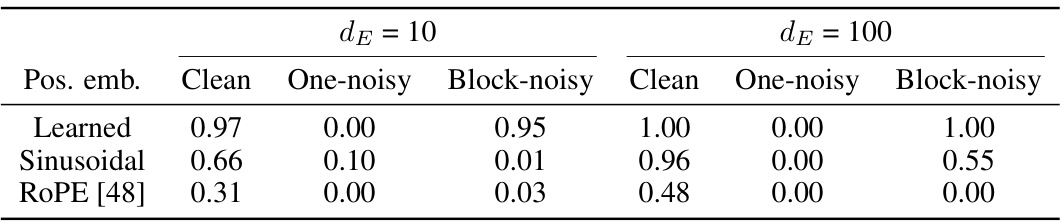
This table presents the results of in-context learning (ICL) experiments on single-pattern tasks. It shows the accuracy of different models (with different positional embedding methods) under three scenarios: clean data, data with one randomly inserted noise token, and data with a block of noise tokens. The results highlight the importance of positional information and the type of positional embedding used, especially in noisy scenarios. Learned positional embeddings are shown to significantly improve performance in noisy scenarios compared to sinusoidal or ROPE embeddings.
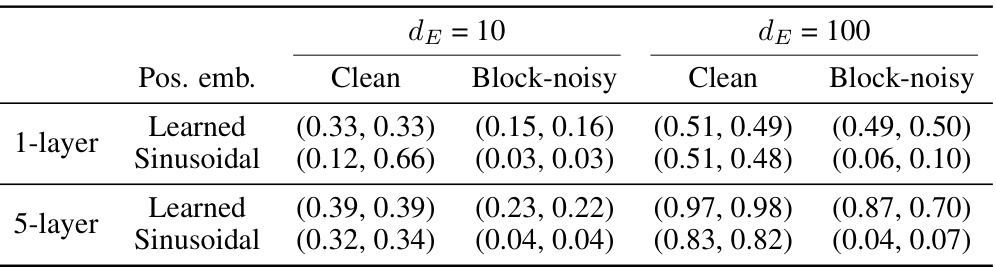
This table presents the results of in-context learning (ICL) experiments on single-pattern tasks with different noise conditions. The accuracy of predicting the last token in a sequence (abacdc) is evaluated under three scenarios: clean (no noise), one-noisy (one random token inserted), and block-noisy (three consecutive random tokens inserted). The table shows that accuracy is high in the clean scenario but significantly lower in the noisy scenarios. Learned positional embeddings improve performance in the block-noisy condition, whereas sinusoidal embeddings are better in the one-noisy condition. This highlights the importance of positional information and data structure for ICL.
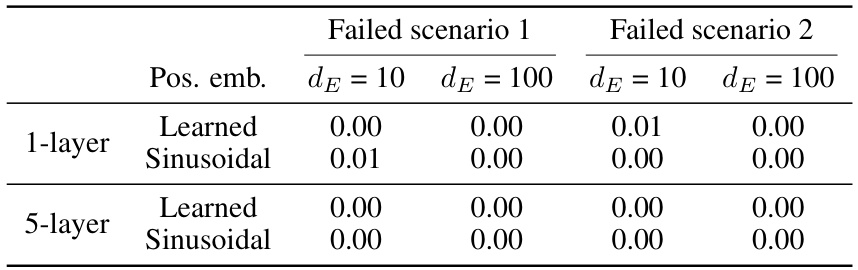
This table presents the results of in-context learning (ICL) experiments in two scenarios where ICL fails, regardless of the model architecture or embedding dimension. The experiments are performed using both learned and sinusoidal positional embeddings with 1-layer and 5-layer models. The results demonstrate that in both scenarios, the accuracy of ICL is zero, indicating a complete failure of ICL to learn in these specific setups.
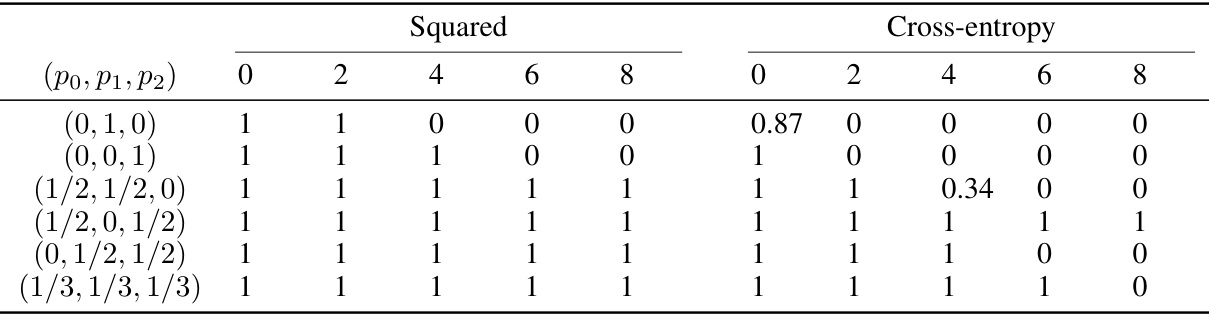
This table shows the accuracy of In-context Learning (ICL) in a clean scenario (without noise) for single-relationship word analogy tasks using the Continuous Bag-of-Words (CBOW) model. It compares the performance using two different loss functions (squared loss and cross-entropy loss) and various numbers of in-context examples (0 to 8). The embedding dimension (dE) is set to 100. The results are averaged over 10 repetitions.
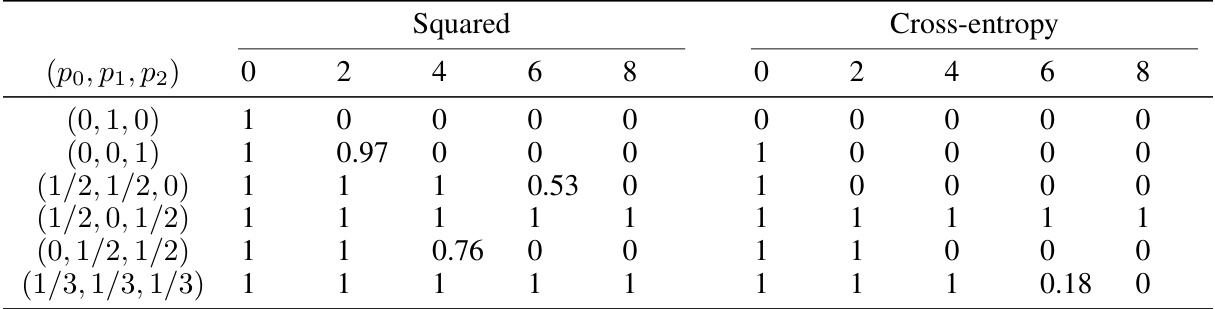
This table presents the results of in-context learning (ICL) experiments using a continuous bag-of-words (CBOW) model on a single-relationship word analogy task. The experiment is performed with a corrupted dataset where training sentences have a 25% chance of a word pair being replaced with a word and random token. The table shows average accuracy across 10 repetitions for both squared loss and cross-entropy loss functions. The ‘accuracy’ values represent the proportion of correct predictions for different numbers of in-context examples (0 to 8) and varying probabilities of having 0, 1, or 2 word pairs in a training sentence.
Full paper#