↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Generating high-quality long videos is challenging due to the significant computational and data resources required to train models for such tasks. Existing methods often struggle to maintain global consistency and fidelity when extending short-video models. Directly applying short-video models to long videos leads to significant degradation, primarily due to the distortion of high-frequency components.
FreeLong tackles this challenge by introducing a novel spectral blending approach. It balances the frequency distribution of long video features by blending low-frequency components (from global video features representing the entire sequence) with high-frequency components (from local video features focusing on shorter subsequences). This method maintains global consistency while incorporating fine-grained details, significantly improving the quality of generated long videos. The effectiveness of FreeLong has been demonstrated on multiple base models, achieving consistent improvements across various metrics.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a training-free method for generating high-quality, long videos using existing short-video diffusion models. This is significant because training long-video diffusion models requires substantial resources. The proposed method, FreeLong, offers a practical solution for researchers and practitioners, enabling them to extend the capabilities of existing models without additional training and opening new avenues for long-video generation research.
Visual Insights#

This figure compares the results of generating short (16 frames) and long (128 frames) videos using two different approaches. The first row shows videos generated by directly extending pre-trained short video diffusion models (LaVie and VideoCrafter). While temporally consistent, these long videos lack detail. The second row shows videos produced by the proposed method, FreeLong. FreeLong improves the generation of long videos by maintaining the temporal consistency while greatly enhancing the fine spatial-temporal details, resulting in higher fidelity video.

This table presents a quantitative comparison of different methods for long video generation. The methods compared are: Direct sampling (directly sampling 128 frames from short video models), Sliding window (applying temporal sliding windows to short video models), FreeNoise [19] (a method that introduces repeat input noise to maintain temporal coherence), and the proposed FreeLong method. The comparison is based on six metrics: Subject consistency (Sub), Background consistency (Back), Motion smoothness (Motion), Temporal Flickering (Flicker), Imaging quality (Imaging), and Inference time. Higher scores indicate better performance for the first five metrics, while lower scores indicate better performance for inference time.
In-depth insights#
Training-Free Video Gen#
Training-free video generation methods offer a compelling alternative to traditional approaches by eliminating the need for extensive training data and computational resources. The core idea revolves around adapting pre-trained models designed for short video sequences to generate longer videos. This approach presents several advantages, such as reduced training time and costs, making long-video generation more accessible. However, directly applying short-video models to long sequences often leads to degradation in video quality, including distortions in high-frequency components. Key challenges include maintaining global temporal consistency while preserving fine-grained details. Effective training-free methods often involve innovative techniques to balance these conflicting requirements, such as incorporating frequency blending mechanisms to integrate low-frequency global features with high-frequency local details. SpectralBlend Temporal Attention, for instance, demonstrates the potential of frequency-domain operations to enhance fidelity and coherence. The success of these methods hinges on carefully addressing the limitations of pre-trained models and mitigating the adverse effects of extending them beyond their original design parameters. Future research could explore more advanced techniques to handle complex scenarios and further improve both the quality and efficiency of training-free video generation.
SpectralBlend Attention#
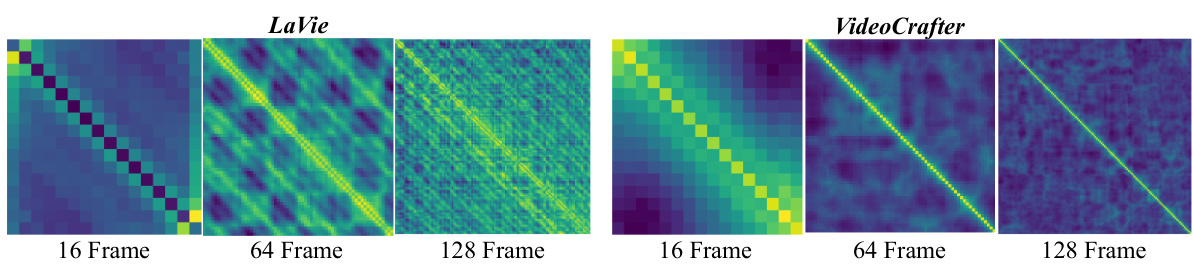
The conceptual innovation of “SpectralBlend Attention” lies in its frequency-domain approach to feature fusion. Instead of directly combining global and local video features in the spatial-temporal domain, it leverages the power of 3D Fourier Transforms to decompose these features into their frequency components. This allows for the targeted integration of low-frequency global features (essential for overall consistency) with high-frequency local features (crucial for preserving fine details). The spectral blending then reconstructs a refined feature representation in the time domain, ideally balancing global coherence and local fidelity. This approach elegantly tackles the challenge of long video generation by addressing the observed distortion of high-frequency components in long sequences, a problem often encountered when directly extending short-video models. The training-free nature of the method makes it highly practical and adaptable, offering a significant advancement in long video generation techniques.
Frequency Analysis#
The heading ‘Frequency Analysis’ suggests a crucial investigation into the spectral characteristics of video data, particularly concerning the impact of video length on frequency components. The authors likely analyzed the signal-to-noise ratio (SNR) across different frequency bands (low and high) for varying video lengths. This likely revealed a degradation in high-frequency components as video length increased, indicating a loss of fine detail and texture in longer videos. Conversely, an increase in temporal high-frequency components might have been observed, suggesting the introduction of temporal artifacts like flickering. This analysis would provide critical insights into why simply extending short-video diffusion models to longer sequences resulted in poor video quality, paving the way for the proposed ‘SpectralBlend’ solution. The frequency analysis would support the core claim that the method effectively balances global consistency (low frequencies) with local detail fidelity (high frequencies), and thus forms a strong foundation for the paper’s technical contribution.
Long-Video Challenges#
Generating long videos presents unique challenges absent in short-video generation. Computational costs explode exponentially with increased frame count, demanding significantly more memory and processing power. Data requirements also escalate dramatically; acquiring and annotating sufficiently large, high-quality long-video datasets is a major hurdle. Maintaining temporal coherence across extended sequences is difficult, as models must capture long-range dependencies and avoid inconsistencies or jarring transitions. Preserving high fidelity in long videos becomes challenging; detail can be lost or artifacts introduced, especially when directly extending short-video models. Finally, handling diverse scene changes and multi-prompt scenarios demands sophisticated temporal modeling to ensure smooth transitions and maintain consistency between vastly different visual and narrative elements.
Future Work#
Future research directions stemming from FreeLong could explore several promising avenues. Extending FreeLong to handle even longer video sequences (e.g., >512 frames) and higher resolutions is a natural progression, requiring investigation into more efficient memory management and computational strategies. Improving the model’s capacity to seamlessly manage dynamic scene changes and complex transitions would significantly enhance the realism and narrative coherence of generated videos. A key challenge is enhancing the model’s ability to faithfully render high-frequency components in longer videos, potentially through incorporating more sophisticated frequency filtering techniques or refining the spectral blending method. Investigating the impact of different training data characteristics on model performance and video quality is essential. Finally, exploring alternative attention mechanisms beyond SpectralBlend-TA could potentially yield further improvements in temporal consistency and fidelity. The potential for applying FreeLong to other generative video tasks, including video editing and inpainting, should also be examined.
More visual insights#
More on figures
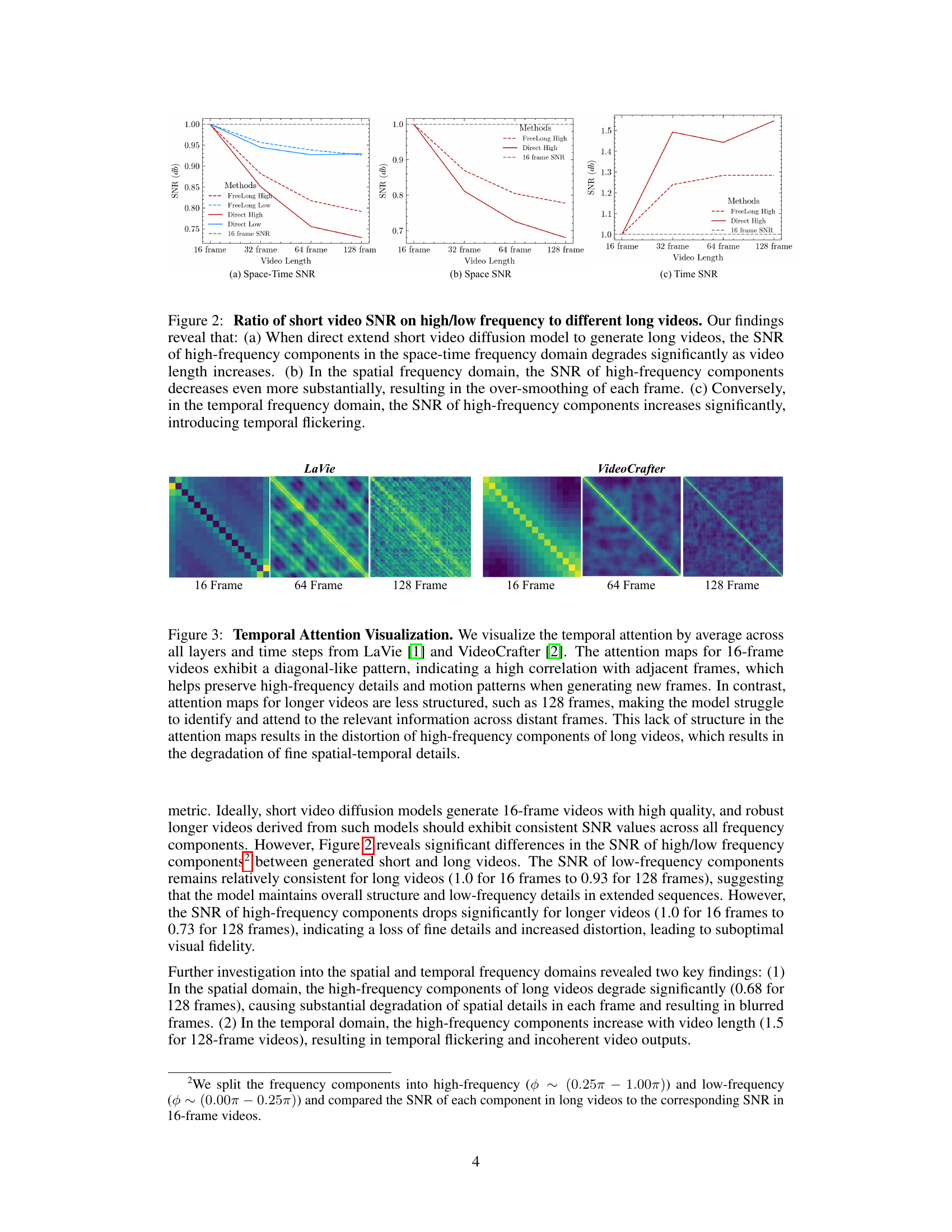
This figure presents a frequency analysis of long videos generated by directly extending short video diffusion models. It shows that extending these models to generate longer videos leads to a decrease in high-frequency spatial components and an increase in high-frequency temporal components. The SNR (signal-to-noise ratio) of high-frequency components decreases significantly as video length increases in the space-time and spatial domains. This results in a loss of detail and over-smoothing. Conversely, in the temporal domain, the SNR of high-frequency components increases, leading to temporal flickering. This observation motivates the approach used in FreeLong to balance these frequency components.
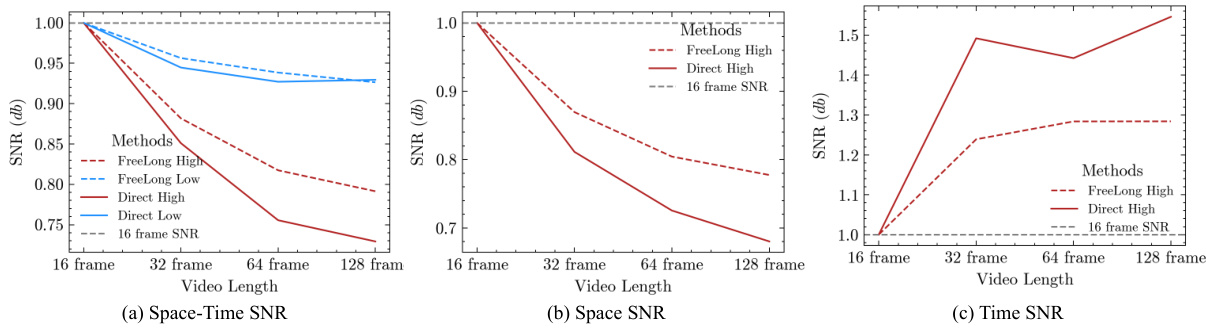
This figure visualizes the temporal attention mechanisms in LaVie and VideoCrafter models for generating videos of different lengths (16, 64, and 128 frames). The visualization shows that the attention maps for short videos (16 frames) have a clear diagonal pattern, signifying strong correlations between adjacent frames and contributing to the preservation of fine details. In contrast, for longer videos (64 and 128 frames), the attention maps become less structured, indicating that the model has difficulty capturing long-range temporal dependencies. This lack of structure leads to the distortion of high-frequency components, ultimately degrading the quality of the generated videos.
FreeLong uses SpectralBlend Temporal Attention to generate high-fidelity and consistent long videos. It decouples local and global attention, applies a frequency filter to blend low-frequency global features and high-frequency local features, and uses the resulting blended feature in iterative denoising.

This figure shows a comparison of long video generation results using different methods: Direct sampling, Sliding Window, FreeNoise, and FreeLong. It demonstrates that FreeLong generates videos that maintain both consistency and high fidelity by effectively blending low-frequency global features and high-frequency local features, while the other methods fail to achieve either or both qualities. Two examples are shown: a yacht passing under a bridge and a woman sitting near a fire. For each example, 16 frames from each approach are displayed, visually showcasing the qualitative differences.

This ablation study visualizes the effects of using only global features, only local features, a direct combination of global and local features, low-frequency components of global features, high-frequency components of local features, and the combined approach of FreeLong on video generation. The results show that global features alone maintain consistency but lose detail, while local features maintain detail but lose consistency. Combining them directly also results in poor quality. Only FreeLong’s method, by selectively combining low-frequency global and high-frequency local features, manages to achieve both high fidelity and temporal consistency.

This figure showcases the effectiveness of FreeLong in generating videos from multiple prompts. Each row represents a different scene described by a sequence of prompts. The generated video smoothly transitions between the scenes, demonstrating the model’s ability to maintain visual coherence and motion consistency despite the changes in description.

This figure shows the results of generating videos longer than 128 frames using the FreeLong method. It demonstrates the method’s ability to maintain both temporal consistency (smooth transitions) and high fidelity (visual quality) even with significantly increased video length. Four examples are provided, each showing a sequence of frames from a short video (128 frames) to a much longer video (512 frames). The consistent quality across these varying lengths highlights FreeLong’s scalability for long video generation.

This figure shows more examples of long videos generated using FreeLong. Each row represents a different video, showing frames from 10, 40, 70, 100, and 120 frames. The videos showcase FreeLong’s ability to generate high-fidelity long videos across a variety of scenes and subjects. The results demonstrate the temporal consistency and visual quality of FreeLong, preserving details and natural motion over extended durations.

This figure demonstrates the adaptability of FreeLong to different base video diffusion models. By simply replacing the temporal attention mechanism with FreeLong’s SpectralBlend-TA, various models (Modelscope, ZeroScope, Animatediff, OpenSora) successfully generate long, consistent videos with high fidelity, showcasing FreeLong’s model-agnostic nature and effectiveness.
Full paper#