↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Multi-modal learning, which aims to analyze data from multiple sources (modalities), has faced challenges due to conventional approaches focusing solely on either inter-modality or intra-modality dependencies. These approaches may not be optimal because they ignore the interaction between modalities and their relationship to the target label. This limitation is especially problematic when the strengths of these relationships vary across datasets.
The paper proposes a new framework, I2M2, that tackles this limitation by jointly modeling both inter- and intra-modality dependencies. I2M2 shows substantial improvements over traditional methods in various applications including healthcare and vision-and-language tasks. Its flexibility and adaptability make it a promising solution for future research in multi-modal learning.
Key Takeaways#
Why does it matter?#
This paper is crucial because it introduces a novel framework, I2M2, that addresses limitations in current multi-modal learning approaches. By jointly modeling inter- and intra-modality dependencies, I2M2 offers a more robust and adaptable solution for diverse multi-modal tasks. Its superior performance across multiple real-world datasets highlights its potential to advance various research fields.
Visual Insights#

This figure shows three different graphical models representing the data generation process in supervised multi-modal learning with two modalities (x, x’) and an output label (y). Model (a) is the proposed model showing that the label influences both modalities individually (intra-modality dependencies) and their interaction (inter-modality dependencies) through a selection variable (v=1). Model (b) represents conventional approaches focusing only on inter-modality dependencies, where the label only affects the modalities indirectly via the selection variable. Model (c) shows another conventional approach that focuses only on intra-modality dependencies by assuming the modalities are independent given the label.

This table presents a comparison of the accuracy achieved by different multi-modal learning methods on the AV-MNIST dataset. The methods compared include using only the image modality, only the audio modality, intra-modality modeling (considering each modality separately), and inter-modality modeling using two different techniques (late fusion (LF) and low-rank multimodal fusion (LRTF)). The results also include the performance of the proposed I2M2 (Inter- & Intra-Modality Modeling) framework using both LF and LRTF. The table highlights the best-performing methods in bold, demonstrating the superiority of I2M2.
In-depth insights#
Multimodal Modeling#
Multimodal modeling tackles the challenge of integrating information from diverse sources to achieve a unified understanding. It acknowledges that different modalities, such as text, images, and audio, offer complementary perspectives, and thus their combined analysis leads to richer insights than analyzing them in isolation. Effective multimodal modeling requires careful consideration of how to represent and combine these heterogeneous data types. This often involves designing intricate architectures that can handle the varying structures and dimensionality of different modalities, as well as strategies to align and fuse the information they provide. The choice between early fusion (combining modalities at the outset) and late fusion (combining them after individual processing) significantly impacts the model’s performance. Successful multimodal modeling hinges on resolving inherent challenges such as modality bias (where one modality dominates the analysis), missing modalities, and the computational cost of managing large datasets. Research in this field explores innovative techniques, such as attention mechanisms and advanced fusion architectures to alleviate these issues, and seeks to develop robust and efficient methods for extracting valuable insights from diverse data sources.
I2M2 Framework#
The I2M2 framework presents a novel approach to supervised multi-modal learning by jointly modeling both inter- and intra-modality dependencies. Unlike traditional methods that focus solely on one type of dependency, I2M2 integrates both, leading to more robust and accurate predictions. The framework’s strength lies in its ability to adaptively handle varying strengths of inter- and intra-modality relationships across different datasets. It achieves this by incorporating individual modality classifiers, which capture intra-modality dependencies, and an additional classifier that integrates interactions between modalities. This integrated approach avoids the limitations of methods relying only on either inter- or intra-modality information, offering improved performance and flexibility. The generative model underpinning I2M2 provides a principled framework that helps explain discrepancies observed in multi-modal learning across various applications. Empirical evaluations demonstrate I2M2’s superior performance compared to traditional methods, establishing its potential as a powerful tool for enhancing the effectiveness of multi-modal learning systems.
Experimental Results#
The experimental results section should thoroughly detail the methodology and findings, comparing the proposed I2M2 framework against existing inter- and intra-modality methods across various datasets. Key aspects to highlight include the datasets’ characteristics (size, modality types, and complexities), the specific metrics employed (accuracy, AUROC, etc.), and a clear visualization of the results (tables, graphs). A crucial part is demonstrating the superior performance of I2M2, explaining the reasons for improvement, and showing how the approach handles different dependency strengths across tasks. Statistical significance should be rigorously addressed, and the robustness of the model in handling distributional shifts needs to be discussed. Addressing any limitations and potential failure cases is also essential for providing a balanced and comprehensive analysis of the proposed approach’s performance.
Limitations of I2M2#
The I2M2 framework, while demonstrating strong performance across diverse multi-modal tasks, presents some limitations. Computational cost scales linearly with the number of modalities, making it potentially inefficient for high-modality scenarios. The proposed solution of using a single network with null tokens for missing modalities is promising but requires further investigation. Model initialization presents a challenge, with separate pre-training of individual modality models proving more effective than joint training from scratch, highlighting potential optimization difficulties in the joint training process. The reliance on a linear relationship between model complexity and the number of modalities might limit its scalability to extremely high-dimensional multi-modal data. While I2M2 addresses the shortcomings of previous approaches that focus solely on inter- or intra-modality dependencies, these limitations should be considered when applying it to new, large-scale multi-modal datasets.
Future Research#
The paper’s discussion on future research directions is crucial for advancing multi-modal learning. Addressing the linear scaling of model size with added modalities is vital; the proposed solution of using a single network with null tokens for missing modalities warrants further investigation. Improving initialization strategies is also key; the findings regarding separate pre-training of individual modalities before joint fine-tuning should be explored to develop more efficient end-to-end training methods. Investigating the impact of spurious correlations in data on model performance is essential. Addressing these challenges could improve the efficiency and reliability of multi-modal models, leading to better generalization and robustness. Further research into understanding and mitigating the negative societal impacts of improved multi-modal technology is crucial for responsible innovation.
More visual insights#
More on figures

This figure compares the performance of different multi-modal learning methods on the fastMRI dataset for four knee pathologies (ACL, Meniscus, Cartilage, and Others). The methods compared are: root-sum-of-squares (RSS) unimodal, magnitude unimodal, phase unimodal, intra-modality modeling, inter-modality modeling, and the proposed I2M2 method. The results show that I2M2 achieves performance comparable to intra-modality modeling, indicating that the inter-modality dependencies contribute less to the prediction task in this specific case than the intra-modality dependencies.

This figure shows the results of the proposed I2M2 model and other baselines on the fastMRI dataset. The results are displayed as AUROC scores for four knee pathologies: ACL, Meniscus, Cartilage, and Others. The different models compared are: root-sum-of-squares (RSS) method, magnitude-only model, phase-only model, intra-modality model, inter-modality model, and the proposed I2M2 model. The figure demonstrates that I2M2 performs comparably to the intra-modality model in this specific case, suggesting that the inter-modality dependencies are less critical for prediction compared to intra-modality dependencies.

This figure displays the Area Under the Receiver Operating Characteristic Curve (AUROC) for different models on the fastMRI dataset. The models tested are: root-sum-of-squares (RSS), magnitude-only, phase-only, intra-modality, inter-modality, and the proposed I2M2 method. The results show that I2M2 performs comparably to intra-modality, suggesting that in this case, inter-modality dependencies contribute less to the prediction of the knee pathologies than intra-modality dependencies.

This figure displays a bar chart comparing the AUROC (Area Under the Receiver Operating Characteristic Curve) performance of different models on the fastMRI dataset for four knee pathologies: ACL, Meniscus, Cartilage, and Others. The models compared include root-sum-of-squares (RSS), magnitude-only, phase-only, intra-modality, inter-modality, and the proposed I2M2 method. The chart shows that I2M2 achieves comparable performance to the intra-modality model. This suggests that while both inter- and intra-modality dependencies are considered in I2M2, the intra-modality dependencies might be more impactful for this specific task.

This figure visualizes examples from the VQA-VS OOD (out-of-distribution) test sets to illustrate how I2M2 handles spurious dependencies. It shows examples where the question, image, or both contain elements that are spuriously correlated with certain answers in the training data (e.g., the word ‘kite’ in the image is correlated with the answer ‘kite’). The figure demonstrates that I2M2, by using a product of experts, correctly predicts the target label even when these spurious correlations are absent, unlike individual models.

This figure displays the VQA scores obtained on various out-of-distribution (OOD) test sets from the VQA-VS dataset. The scores are shown for different models: image-only, text-only, intra-modality, inter-modality, and the proposed I2M2 model. The results are categorized into text-based, image-based, and multi-modal OOD test sets, further broken down into specific subsets. The main observation is that the I2M2 method consistently outperforms the other methods across all types of OOD test sets, demonstrating its robustness.
More on tables
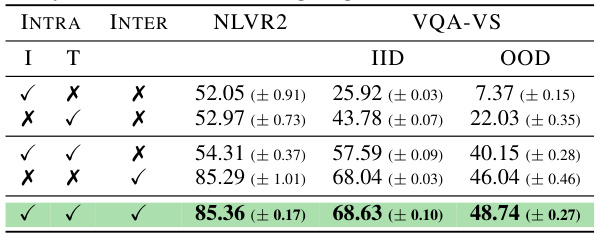
This table presents the accuracy and VQA scores achieved by different models (Intra-modality, Inter-modality, and I2M2) on two datasets, NLVR2 and VQA-VS. For each dataset, the results show the performance of models trained using only the image modality (I), only the text modality (T), both image and text modalities but separately (Intra), and both modalities jointly (Inter and I2M2). The best performance for each metric (accuracy and VQA score) is shown in bold, indicating that I2M2 generally outperforms or matches the best of the other approaches across both datasets.

This table presents the effect of pre-training on the performance of the I2M2 model across different knee pathologies in the fastMRI dataset. It compares the AUROC scores obtained with and without pre-training, showing that pre-training significantly improves performance for all pathologies. The improved performance with pre-training highlights the importance of initializing models appropriately for multimodal learning and supports the proposed I2M2 framework.
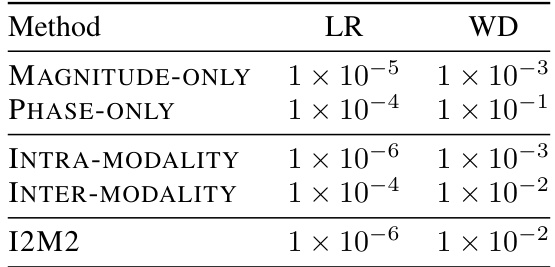
This table presents the hyperparameters used for training different models on the fastMRI dataset. It shows the learning rate (LR) and weight decay (WD) values used for the magnitude-only, phase-only, intra-modality, inter-modality, and I2M2 models. These hyperparameters were likely determined through a process of hyperparameter tuning, where different combinations of values were tested and the optimal combination was chosen based on the model’s performance.
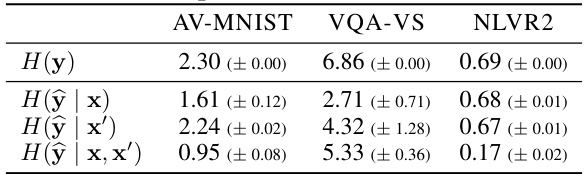
This table presents the entropy values for the label (y) distribution and the average entropy of predictions (ŷ) generated by individual modality models (image-only and text-only) and the combined inter-modality model in three different datasets: AV-MNIST, VQA-VS, and NLVR2. It demonstrates the information gain from incorporating multiple modalities by showing the reduction in entropy from individual modalities to the combined model. Lower entropy values indicate higher predictability, highlighting the effectiveness of integrating information from different modalities.
Full paper#