↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Existing unsupervised multiplex graph learning (UMGL) methods struggle with real-world data containing noise and primarily focus on redundant scenarios, neglecting unique task-relevant information. This limits their applicability and performance. The reliability of graph structures is a key, overlooked factor.
The paper introduces Information-aware Unsupervised Multiplex Graph Fusion (InfoMGF) to address these issues. InfoMGF refines the graph structure to remove noise and simultaneously maximizes shared and unique task-relevant information using novel graph augmentation strategies. Theoretical analysis and experiments on various benchmarks demonstrate InfoMGF’s superior performance and robustness over existing methods, surprisingly even outperforming supervised approaches.
Key Takeaways#
Why does it matter?#
This paper is crucial because it addresses a critical limitation in existing unsupervised multiplex graph learning methods by tackling non-redundant scenarios and capturing view-unique information. It opens avenues for more realistic and robust graph learning applications and even surpasses sophisticated supervised approaches in experimental results. This is significant for researchers working with real-world, noisy graph data, pushing the boundaries of unsupervised learning techniques.
Visual Insights#

This figure illustrates the concept of non-redundancy in multiplex graphs. Panel (a) shows a Venn diagram representing the overlap and unique information between multiple graphs (views). Panel (b) provides a concrete example of a multiplex graph, highlighting shared and unique task-relevant edges. Panel (c) presents an empirical study demonstrating the significant amount of unique task-relevant information in real-world multiplex graphs, particularly in the ACM dataset.
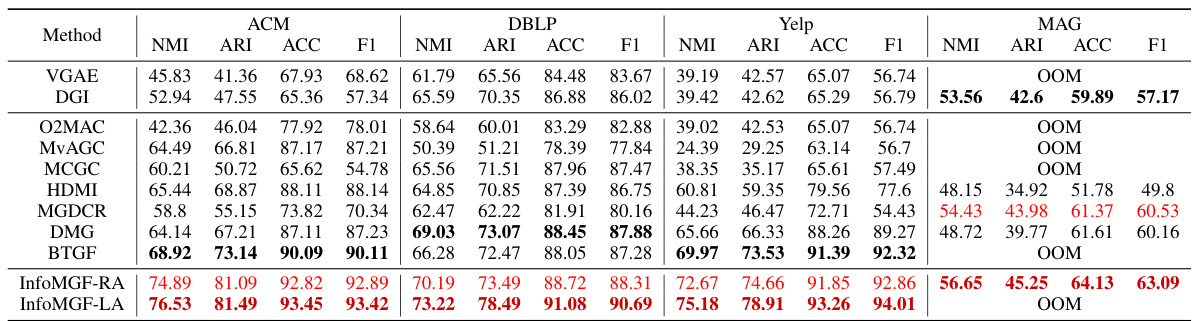
This table presents the results of node clustering experiments performed on four real-world benchmark multiplex graph datasets (ACM, DBLP, Yelp, and MAG). It compares the performance of InfoMGF (with two variants) against several other state-of-the-art unsupervised clustering methods (VGAE, DGI, O2MAC, MvAGC, MCGC, HDMI, MGDCR, DMG, and BTGF). The results are evaluated using four metrics: Normalized Mutual Information (NMI), Adjusted Rand Index (ARI), Accuracy (ACC), and F1-score. The top three highest results for each metric and dataset are highlighted.
In-depth insights#
Multiplex Graph Reliability#
The reliability of multiplex graphs, crucial for accurate learning, is often overlooked. Real-world multiplex graphs are messy, containing irrelevant noise and missing connections, which severely hinder the performance of unsupervised multiplex graph learning (UMGL) algorithms. Traditional UMGL methods that rely on maximizing mutual information across different views fail to address this issue. InfoMGF, on the other hand, explicitly tackles the problem by using graph structure refinement to remove irrelevant noise, thus focusing on learning from reliable parts of the structure. This focus on reliability is a significant contribution, highlighting the importance of data quality for effective multiplex graph representation learning, and showcasing the need for more robust methods capable of handling the inherent messiness of real-world datasets.
InfoMGF Framework#
The InfoMGF framework is presented as a novel approach to unsupervised multiplex graph structure learning. It addresses the limitations of existing methods by directly tackling the reliability of graph structures and handling non-redundant scenarios. InfoMGF uses a two-module design: a graph structure refinement module to eliminate noise and a task-relevant information maximization module to preserve crucial information. The refinement stage enhances the reliability of each graph view by applying a graph learner and post-processing techniques. A key innovation is the simultaneous maximization of both view-shared and view-unique task-relevant information, which is achieved through graph augmentation and mutual information maximization strategies. This addresses the non-redundancy inherent in real-world multiplex graphs where task-relevant information can be unique to certain views. InfoMGF’s theoretical analyses guarantee its effectiveness and comprehensive experimental results demonstrate its superiority over state-of-the-art baselines across various tasks and under different noise conditions. The framework represents a significant advancement in UMGL, offering improved robustness and even outperforming sophisticated supervised approaches in certain situations.
Graph Augmentation#
Graph augmentation, in the context of this research paper, is a crucial technique for enhancing the reliability and effectiveness of unsupervised multiplex graph learning. The core idea revolves around strategically modifying the input graph structures to mitigate the impact of noise and redundancy while maximizing the capture of task-relevant information. Two main augmentation strategies are explored: random edge dropping, a simpler approach involving the random removal of edges, and learnable generative augmentation, a more sophisticated method that leverages a learned graph augmentation generator to produce optimal augmentations. The key to successful augmentation lies in its ability to enhance both view-shared and view-unique task-relevant information, thereby addressing the non-redundant nature of real-world multiplex graphs. Theoretical analysis supports the effectiveness of these methods, demonstrating how they contribute to minimizing task-irrelevant information and improving the quality of the learned graph representation. The choice between random and learnable augmentation represents a trade-off between simplicity and performance, with learnable augmentation offering superior results but at a higher computational cost. Overall, graph augmentation is shown to be instrumental in achieving superior unsupervised learning outcomes compared to approaches that rely solely on the original, potentially noisy graph structures.
Robustness Analysis#
A Robustness Analysis section in a research paper would systematically evaluate the model’s resilience to various perturbations and noisy conditions. It would likely involve simulated attacks or data corruptions to assess performance degradation. Key aspects would include testing against variations in the input data (e.g., adding noise, deleting edges or features, masking information), model parameters (e.g., different initialization strategies), and changes to the underlying graph structure (e.g., removing or adding edges). Quantitative metrics such as accuracy, precision, recall, or F1-score would be used to measure performance in different scenarios. The results would showcase the model’s behavior under different stress conditions, highlighting its strengths and weaknesses. A robust model should exhibit consistent performance even with significant variations in the input data or model settings. Further investigation into the causes of performance degradation would be invaluable. This could lead to specific recommendations on how to further enhance the model’s robustness.
Future of UMGL#
The future of Unsupervised Multiplex Graph Learning (UMGL) hinges on addressing its current limitations. Improving the reliability of graph structures is paramount, as real-world data often contains noise and irrelevant information. Methods that incorporate robust graph structure refinement techniques, such as those leveraging graph neural networks and advanced noise reduction strategies, will be crucial. Moving beyond contrastive learning to effectively capture view-unique information is another key area, potentially using techniques like generative models or novel self-supervised learning methods. Scalability is another challenge; future UMGL methods will need to efficiently handle very large and complex multiplex graphs. Finally, developing more sophisticated theoretical frameworks to guarantee the effectiveness and robustness of algorithms, along with improved evaluation metrics, are essential to further advancing this field.
More visual insights#
More on figures

The figure illustrates the InfoMGF framework which consists of two main modules: Graph Structure Refinement and Task-Relevant Information Maximization. The Graph Structure Refinement module refines each individual graph in the multiplex graph to remove irrelevant noise, resulting in refined graphs. These refined graphs are then fed into the Task-Relevant Information Maximization module. This module aims to maximize both shared and unique task-relevant information across the refined graphs, ultimately leading to a fused graph. This fused graph, along with learned node representations, is then used for various downstream tasks such as node classification and node clustering.
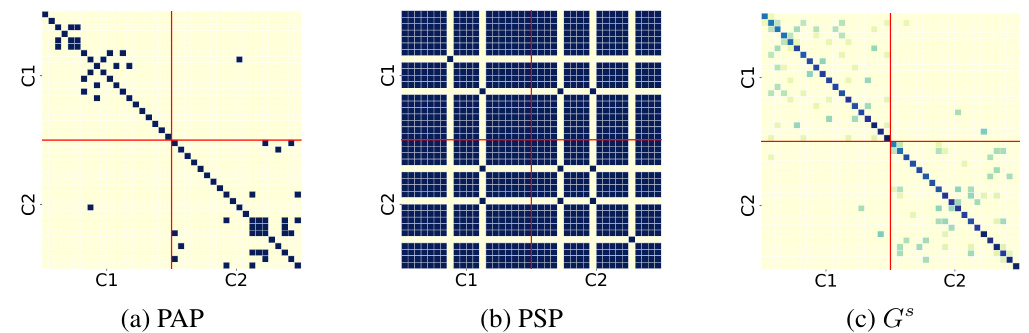
The figure visualizes the adjacency matrices of the original multiplex graphs (PAP and PSP) and the learned fused graph (Gs) on a subgraph of the ACM dataset. The heatmaps show the relationships between nodes in each view. Darker colors indicate stronger connections. The figure highlights InfoMGF’s ability to effectively remove inter-class edges (irrelevant noise) and retain intra-class edges (task-relevant information) from the original graphs, resulting in a cleaner, more informative fused graph.
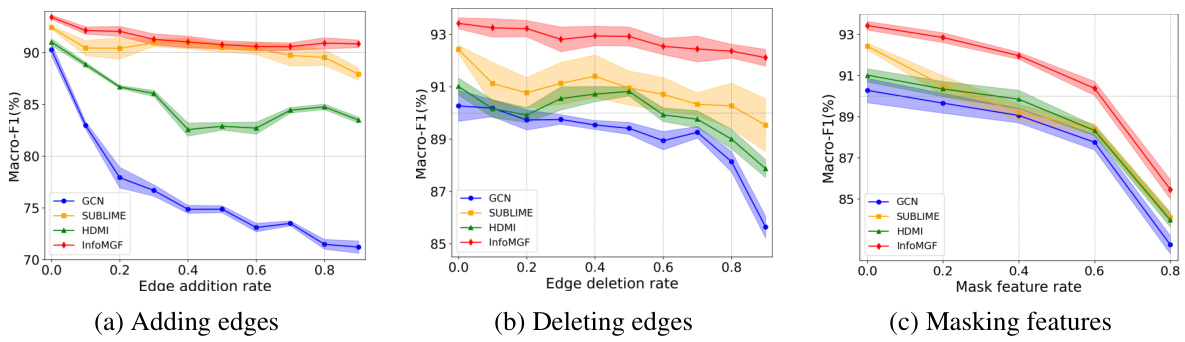
The figure shows the robustness analysis of InfoMGF and other methods (GCN, SUBLIME, and HDMI) against random noise on the ACM dataset. Three types of noise are considered: (a) adding edges, (b) deleting edges, and (c) masking features. The plots show the Macro-F1 scores for node classification as the noise rate increases. InfoMGF consistently demonstrates superior robustness compared to the other methods, maintaining high performance even with significant noise injection.
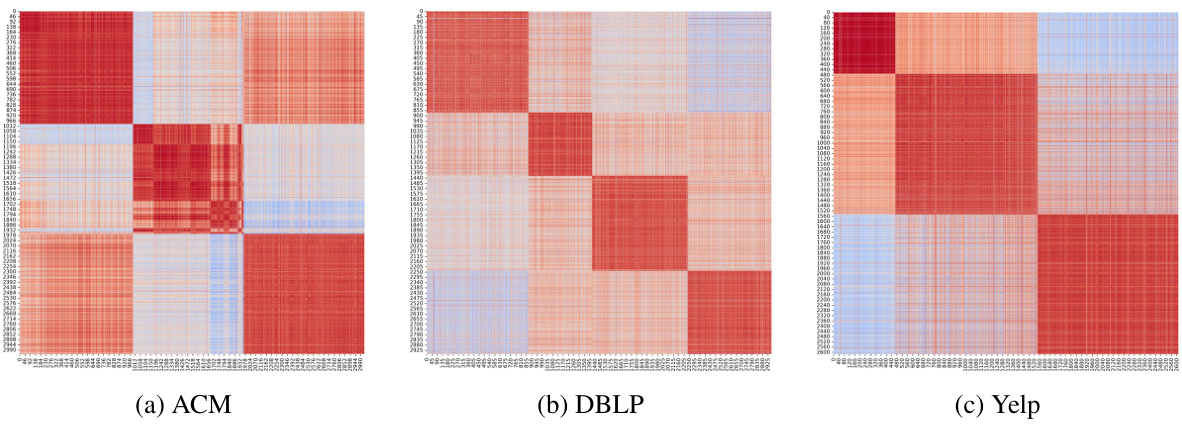
The figure visualizes the adjacency matrices of subgraphs from the ACM dataset, comparing the original graphs (PAP and PSP views) with the learned fused graph (Gs) produced by InfoMGF-LA. The heatmaps show the edge weights between nodes, with warmer colors indicating stronger connections. The goal is to illustrate how InfoMGF refines the graph structure by removing inter-class edges and retaining intra-class edges, leading to improved performance in downstream tasks. Nodes are reordered by class label (C1 and C2) to highlight the differences more clearly.
This figure presents a robustness analysis of the InfoMGF model on the ACM dataset against different types of noise: edge addition, edge deletion, and feature masking. The performance of InfoMGF is compared to other baselines (GCN, SUBLIME, and HDMI) across varying levels of noise. The results demonstrate InfoMGF’s superior robustness compared to baselines, especially under high noise levels. This highlights the model’s ability to effectively manage task-irrelevant information and retain sufficient task-relevant information.
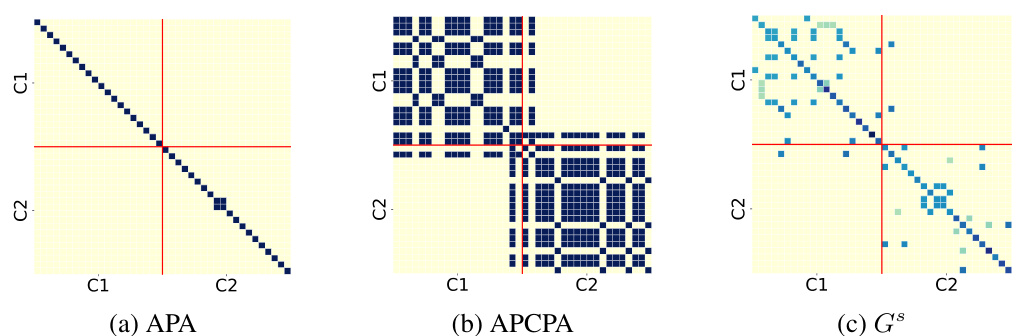
This figure visualizes the adjacency matrices of the original and learned graphs for the DBLP dataset. It shows three heatmaps: one for each of the original graph views (APA and APCPA), and one for the fused graph (Gs) learned by the InfoMGF model. The heatmaps use color intensity to represent the edge weights, allowing for a visual comparison of the original graph structures to the refined structure learned by the model. The red lines divide the heatmaps to show different classes of nodes.
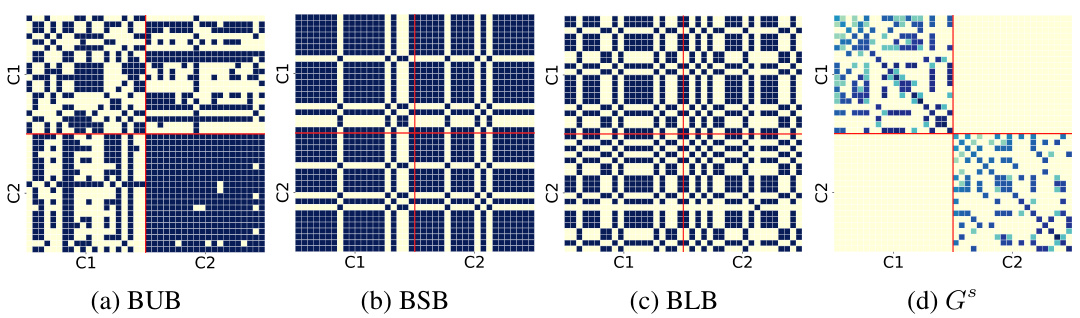
The figure visualizes the adjacency matrices of the original and learned graphs for the Yelp dataset. It shows heatmaps of the original BUB, BSB, and BLB graphs, alongside the fused graph (Gs) generated by InfoMGF-LA. The heatmaps illustrate the relationships between nodes (businesses) within each graph, with warmer colors representing stronger connections. The comparison highlights how InfoMGF refines the graph structure, removing inter-class edges and enhancing intra-class connections, improving the quality of the graph representation for downstream tasks.
More on tables

This table presents the results of node classification experiments using various methods. It compares the performance of supervised and unsupervised methods, with and without the use of graph structure learning. The ‘Available Data for GSL’ column indicates whether the method used labeled data during training, highlighting the difference between supervised and unsupervised approaches. The Macro-F1 and Micro-F1 scores are used as evaluation metrics. The table shows that the proposed InfoMGF-LA method outperforms other methods across different datasets.
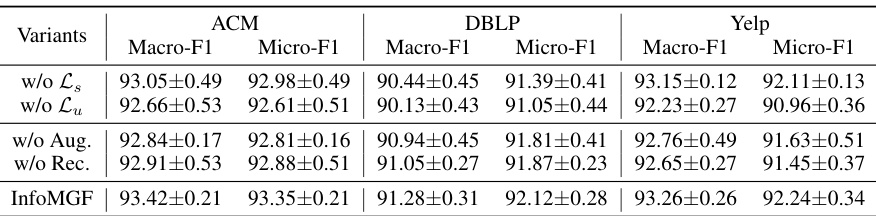
This table presents the ablation study results of the InfoMGF model. It shows the performance of InfoMGF and its variants (without maximizing shared task-relevant information, without maximizing unique task-relevant information, without graph augmentation, and without reconstruction loss) on three benchmark datasets (ACM, DBLP, and Yelp) in terms of Macro-F1 and Micro-F1 scores for node classification. It helps to understand the contribution of each component in the InfoMGF framework.
This table presents the quantitative results of node clustering experiments conducted on four benchmark datasets (ACM, DBLP, Yelp, and MAG). The results are shown for various unsupervised node clustering methods. The table displays performance metrics (NMI, ARI, ACC, F1) for each method on each dataset. The top three performing methods for each dataset are highlighted. ‘OOM’ indicates that the method ran out of memory.
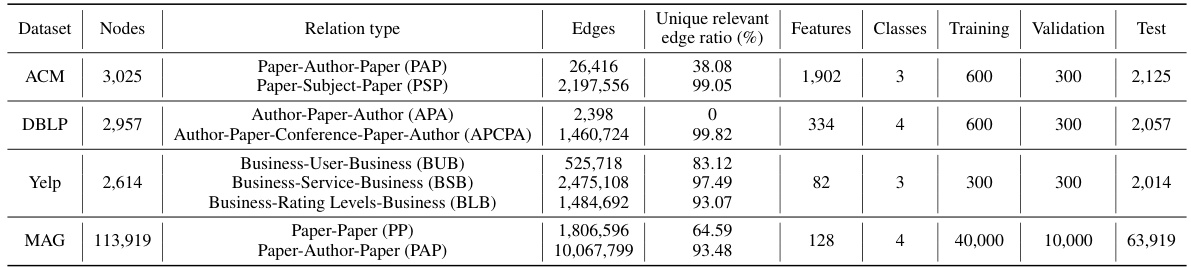
This table presents the quantitative results of node clustering experiments on four different datasets using various methods. The results are expressed as percentages and are broken down by dataset and method. The top 3 performing methods for each dataset are highlighted. The abbreviation ‘OOM’ stands for ‘out of memory’, indicating that the experiment could not complete due to insufficient memory resources.

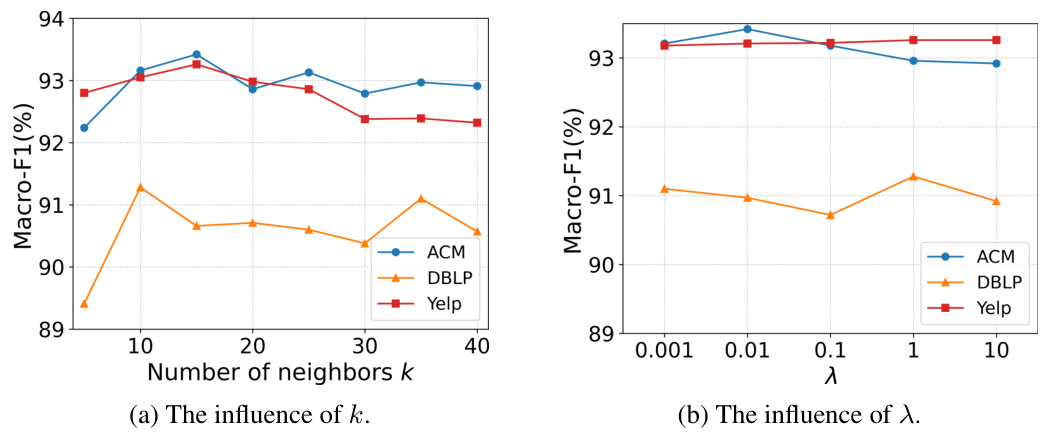
This table shows the hyperparameter settings used for the InfoMGF model across four different datasets (ACM, DBLP, Yelp, and MAG). It details the number of epochs (E), learning rate (lr), hidden dimension (dh), representation dimension (d), number of nearest neighbors (k), aggregation order (r), number of layers (L), random feature masking probability (ρ), temperature parameter (Tc), random edge dropping probability (Ps), generator learning rate (lrgen), Gumbel-Max temperature (T), and hyperparameter λ for InfoMGF-LA. Note that for the MAG dataset, the random edge dropping probability (ρ) is 0 as the generative augmentation method is used.
Full paper#



















