↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Existing multiple clustering methods struggle to adapt to diverse user needs, often requiring manual interpretation of results. This paper introduces Multi-Sub, a novel end-to-end approach that uses multi-modal subspace proxy learning to align textual user preferences with visual data representations. By utilizing CLIP and GPT-4, Multi-Sub automatically generates proxy words reflecting user interests as subspace bases, facilitating customized data representation.
Multi-Sub’s key contribution is its simultaneous learning of representations and clustering, unlike traditional methods that separate these stages. This simultaneous optimization significantly improves performance and efficiency. Experiments across numerous datasets consistently demonstrate Multi-Sub’s superiority over existing baselines in visual multiple clustering tasks. The simultaneous learning and enhanced user interaction significantly improve the efficiency and effectiveness of multiple clustering.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses a crucial challenge in multiple clustering: enabling users to easily find desired clustering results based on their interests. The proposed Multi-Sub method offers a novel solution to this problem by incorporating user preferences directly into the clustering process. This work is highly relevant to the growing field of deep multiple clustering and opens up new avenues for research, such as developing more efficient and intuitive ways to interact with clustering algorithms. The method’s superior performance on various datasets demonstrates its practical value and makes it an exciting contribution to the field.
Visual Insights#
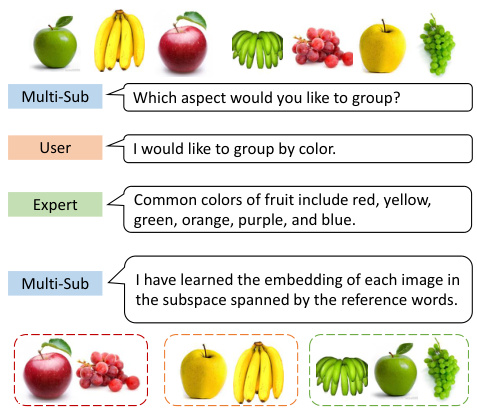
This figure illustrates the Multi-Sub framework, a two-phase iterative approach aligning images with user-defined preferences for clustering. Phase I learns proxy word embeddings by aligning textual prompts with image features in a subspace defined by reference words (common categories from a large language model). Phase II refines the image encoder using a clustering loss, resulting in clustering tailored to the user’s interest. The process iteratively refines both the proxy word embeddings and the image representation, achieving customized clustering results.

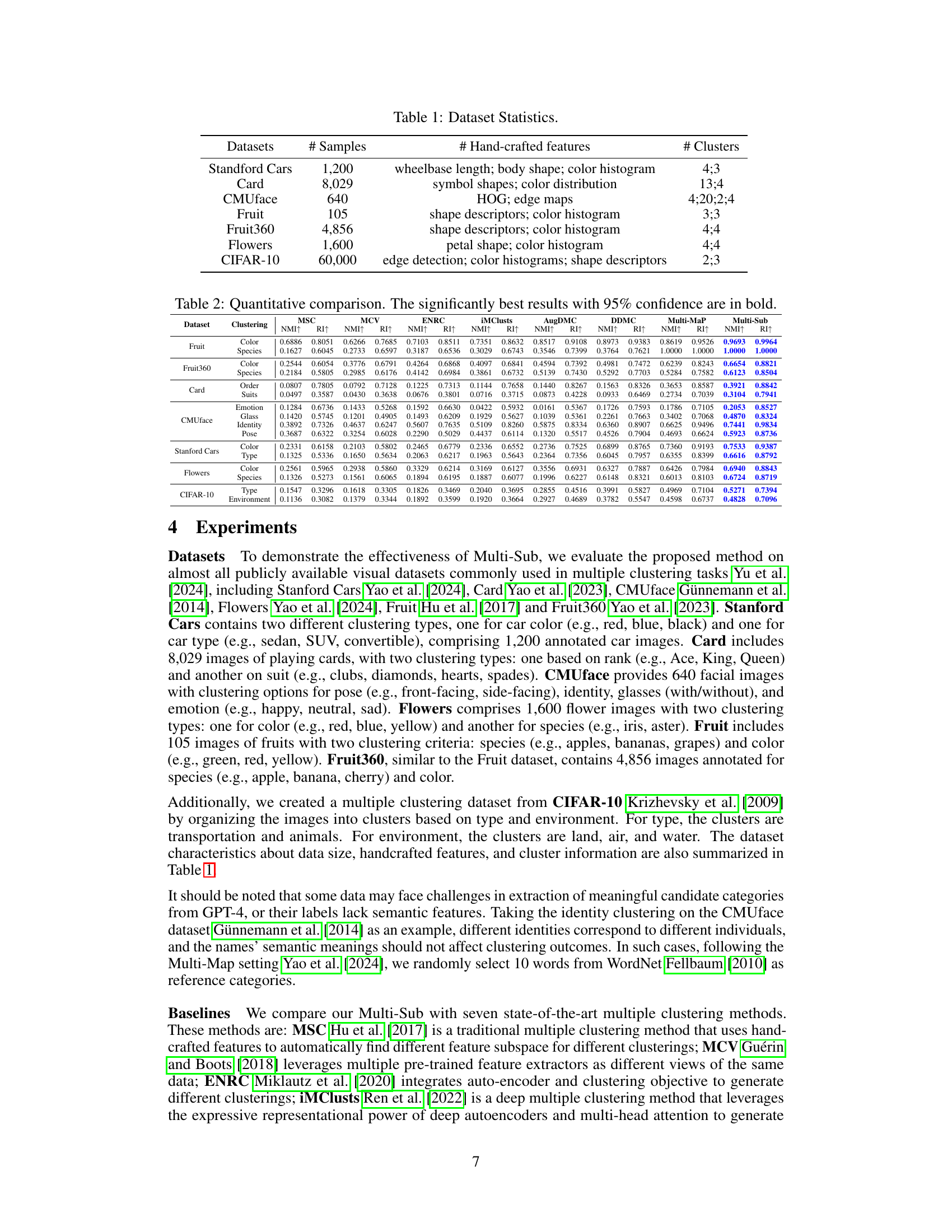
This table presents the statistics of eight datasets used in the paper’s experiments. For each dataset, it shows the number of samples, the types of hand-crafted features used (if any), and the number of clusters used in the multiple clustering tasks. The datasets cover diverse domains, including cars, playing cards, faces, fruits, flowers and general images, demonstrating the broad applicability of the proposed Multi-Sub method.
In-depth insights#
Multi-modal Fusion#
Multi-modal fusion, in the context of the provided research paper, likely refers to the integration of visual and textual data to achieve a more comprehensive understanding of user preferences for customized multiple clustering. The core idea revolves around leveraging the strengths of both modalities: visual data (images of objects) provides rich features, while textual data (user prompts, keywords generated from LLMs) offers explicit semantic meaning and user intent. Effective fusion techniques are crucial, as simply concatenating visual and textual embeddings may not capture the nuanced relationships between them. The paper likely explores methods to align these modalities, perhaps using techniques like cross-attention or subspace projection, to create a unified representation that is then utilized for the clustering tasks. This alignment would ensure that the resulting clusters reflect both the visual characteristics and the underlying textual intent of the user. The success of such fusion depends heavily on the choice of models (e.g., CLIP, GPT-4) and the specific fusion methods employed. A critical aspect is the generation of proxy words from large language models, which act as bridge between textual prompts and visual features; this step is likely crucial for effectively embedding user-specific preferences into the clustering process.
Proxy Learning#
Proxy learning, in the context of the research paper, is a crucial technique for bridging the gap between high-level user preferences and low-level visual data representations. Instead of directly relying on complex, potentially noisy data features, it leverages intermediate representations (proxies) to capture user intent more effectively. These proxies might be generated from large language models, using textual descriptions of user interests to create a subspace within the visual feature space. The method’s ingenuity lies in aligning these proxies with visual data, enabling the model to focus on relevant aspects specified by the user. By automatically learning and refining these proxies, the model implicitly learns to express user preferences in the visual domain, creating a more personalized and effective clustering approach. The effectiveness of proxy learning directly contributes to the enhanced accuracy and efficiency of the multiple clustering system, addressing the challenges of adapting to diverse user needs in data grouping tasks.
Subspace Alignment#
Subspace alignment, in the context of multi-modal learning and clustering, focuses on aligning the feature representations from different modalities (e.g., images and text) within a shared subspace. This is crucial because different modalities typically have distinct feature spaces. Direct comparison or integration becomes challenging without proper alignment. Effective subspace alignment techniques enable models to learn joint representations, capturing the synergistic information across modalities. In the specific case of the research paper, it seems subspace alignment is achieved by leveraging the capabilities of large language models and multi-modal encoders. By generating proxy words representing user preferences, the method effectively bridges the gap between textual and visual representations. The generated proxy words act as basis vectors to define the target subspace, enabling a customized and refined alignment for specific clustering tasks. The success of this approach relies on the ability of the large language model to effectively capture and convey user preferences into semantically meaningful word choices, and the effectiveness of the multi-modal encoder in generating suitable visual and textual representations. This alignment process is an integral part of the entire framework, impacting both the effectiveness of clustering and the interpretability of the results. Ultimately, this alignment method shows potential for improving the efficiency and relevance of multi-modal clustering algorithms for diverse user needs and applications.
Clustering Loss#
The ‘Clustering Loss’ section is crucial for refining the model’s ability to group similar data points together and separate dissimilar ones. It leverages pseudo-labels derived from the proxy word embeddings and image embeddings. This combined representation helps capture the desired user-defined clustering aspect. The loss function itself is composed of two main parts: intra-cluster loss, which aims to minimize distances within clusters promoting compactness, and inter-cluster loss, which maximizes distances between clusters enhancing separability. The combination of these losses, balanced by a hyperparameter lambda (λ), aims for optimally distinct and internally cohesive clusters. The iterative refinement of the image encoder’s projection layer, using this loss function, ensures that the final image representations truly align with the intended clustering defined by the proxy words. Simultaneously learning both the representation and clustering, as opposed to sequential approaches, is a key strength, leading to greater efficiency and improved clustering performance.
Future Works#
Future work could explore several promising avenues. Improving the efficiency and scalability of Multi-Sub, perhaps through architectural optimizations or more efficient proxy word generation methods, is crucial for handling larger datasets and more complex user preferences. Investigating alternative methods for aligning textual interests with visual features, beyond CLIP and GPT-4, could enhance robustness and adaptability. A deeper exploration of the interplay between the choice of large language model and the resulting clustering quality would be valuable, potentially informing better selection criteria based on task characteristics. Finally, applying Multi-Sub to diverse applications beyond image clustering, such as multi-modal data analysis in other domains, would demonstrate its broader utility and impact.
More visual insights#
More on figures
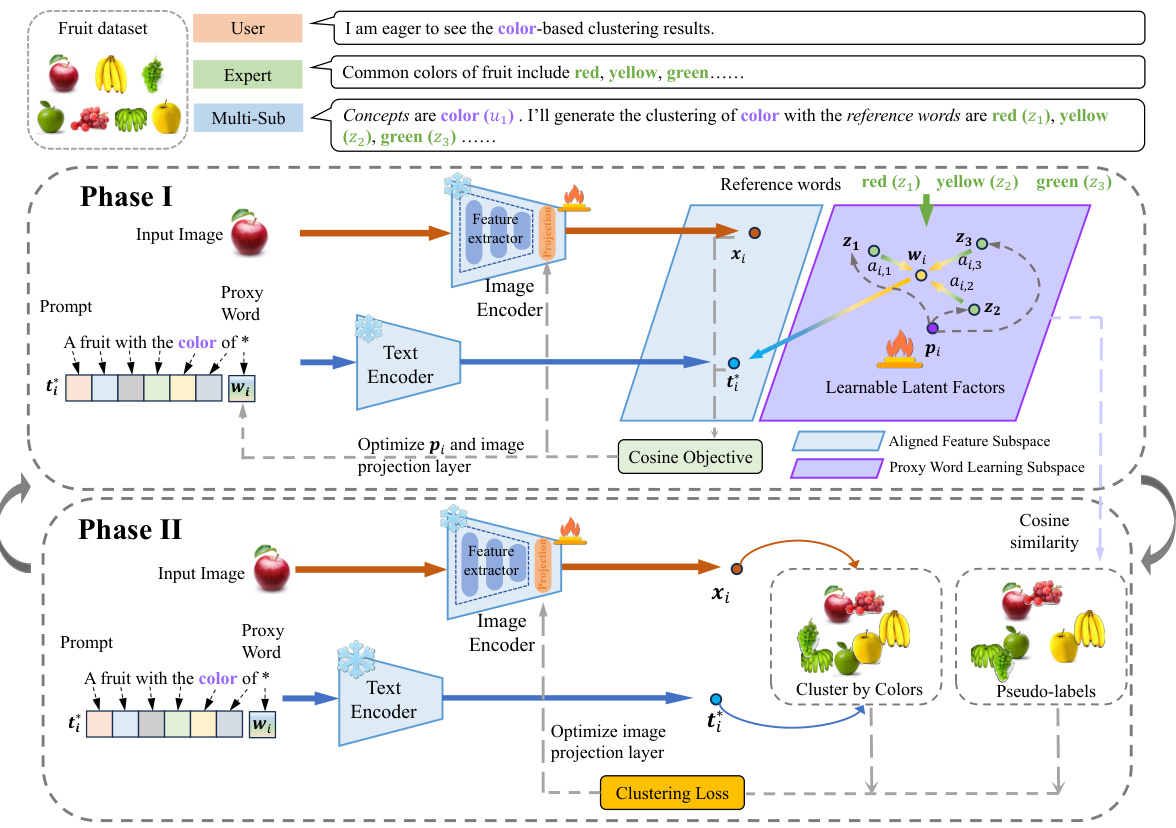
This figure illustrates the Multi-Sub framework, detailing the two phases: Phase I focuses on proxy word learning and alignment between image and text representations based on user preferences, and Phase II refines the image encoder’s projection layer using a clustering loss for improved clustering performance. The framework leverages a latent factor to weight reference word embeddings, creating a proxy word embedding which enhances the alignment between user interest and image features.

This figure illustrates the Multi-Sub framework, which consists of two phases: Proxy Learning and Alignment, and Clustering. Phase I learns proxy word embeddings by aligning user-defined textual prompts with image features using a learnable projection layer and a frozen text encoder. Phase II refines the image encoder using a clustering loss to obtain the final clustering results based on the learned proxy word embeddings. The process iterates between these two phases until convergence.

This figure illustrates the Multi-Sub framework, which is a two-phase iterative approach for aligning and clustering images based on user preferences. Phase I focuses on proxy word learning and alignment between textual prompts and image features, while Phase II refines the image representation and performs clustering using the learned proxy words. The process iterates until convergence, optimizing both alignment and clustering results.
More on tables
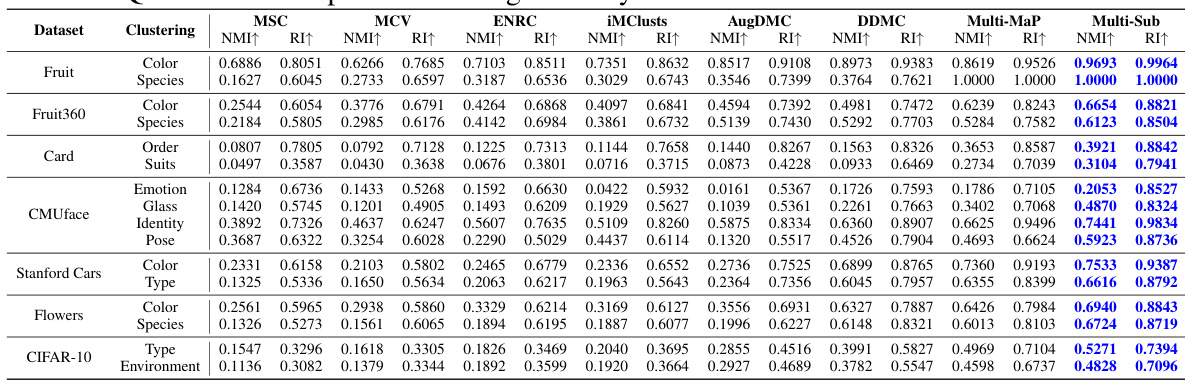
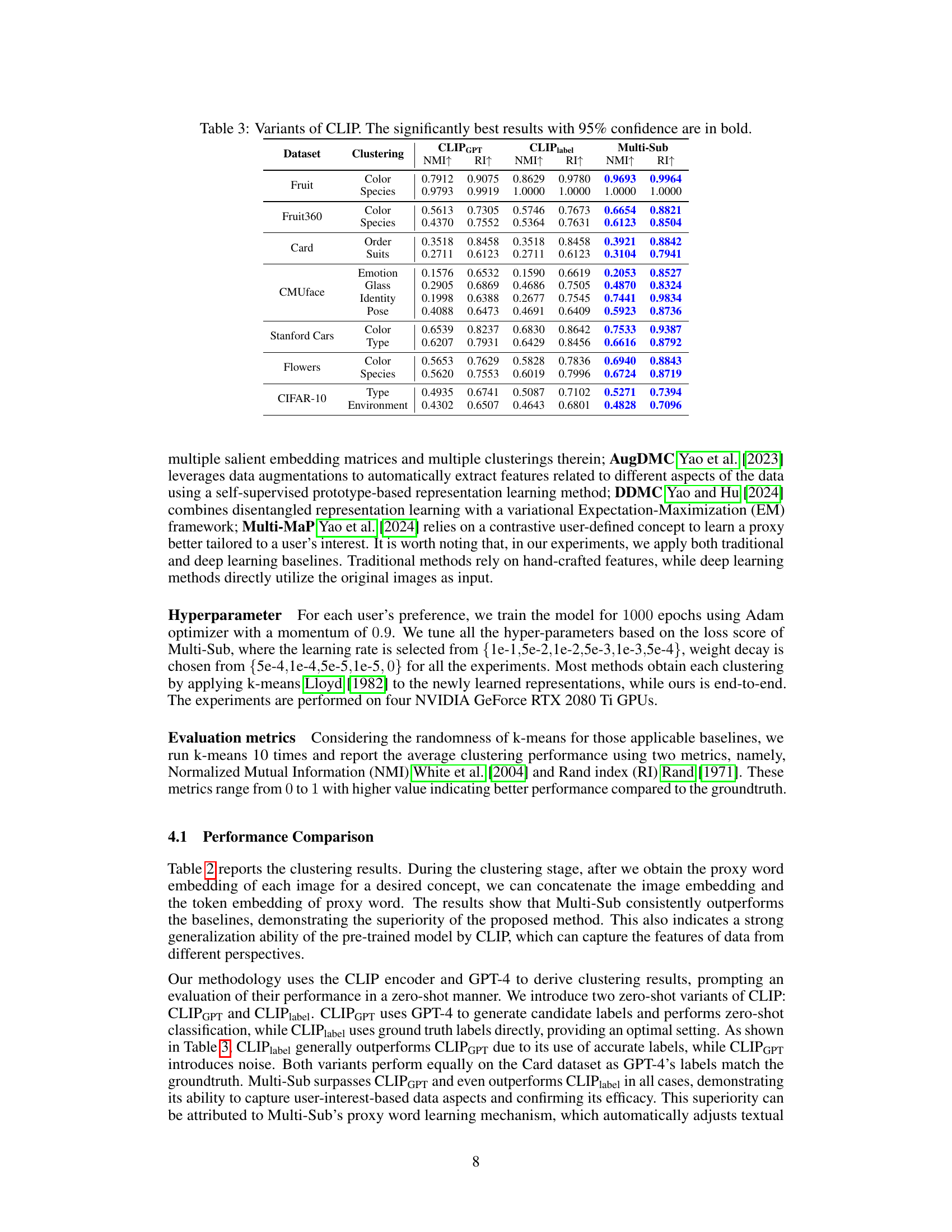
This table presents a quantitative comparison of the proposed Multi-Sub method with several other multiple clustering methods across a range of datasets. The performance is measured using two metrics: Normalized Mutual Information (NMI) and Rand Index (RI). Higher values for both metrics indicate better clustering performance. The table highlights the datasets used, the type of clustering (e.g., by color, species), and the performance of each method on each dataset and clustering type. The best performing method for each dataset and clustering type (with 95% confidence) is shown in bold.
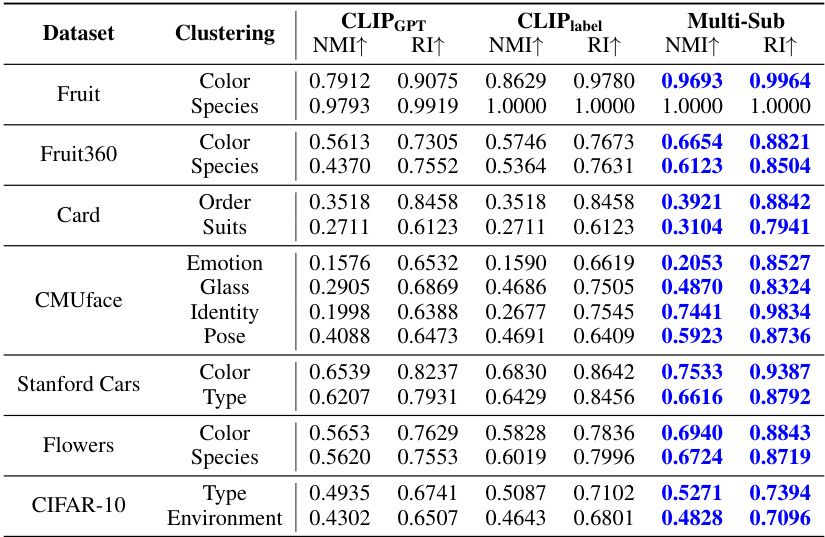
This table compares the performance of three different CLIP variants (CLIP label, CLIPGPT, and Multi-Sub) across various datasets and clustering tasks. The ‘CLIP label’ variant uses ground truth labels, providing an upper bound on performance; ‘CLIPGPT’ uses GPT-4 to generate labels, introducing noise into the process; and ‘Multi-Sub’ represents the proposed method in the paper. The results show the Normalized Mutual Information (NMI) and Rand Index (RI) for each variant, highlighting Multi-Sub’s superior performance in nearly all cases.
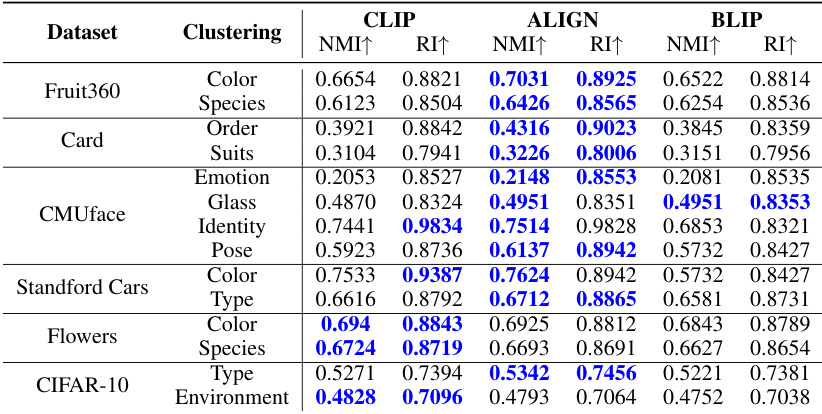
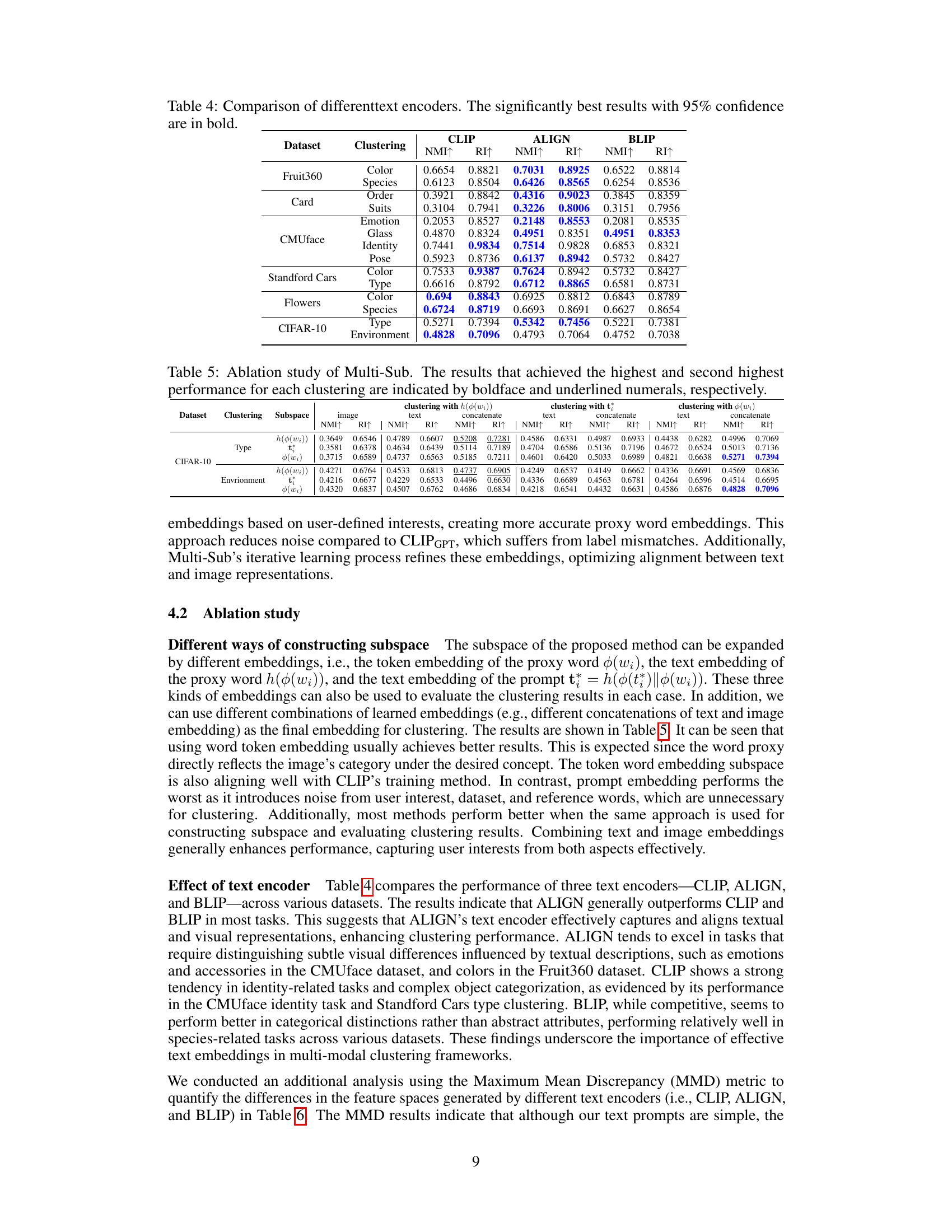
This table compares the performance of three different text encoders (CLIP, ALIGN, and BLIP) across various datasets and clustering tasks. The results are presented in terms of Normalized Mutual Information (NMI) and Rand Index (RI). The highest NMI and RI scores for each dataset and clustering type are shown in bold, indicating statistically significant improvements by ALIGN in most of the cases. This table helps to assess the relative strengths and weaknesses of the different text encoders for use in multiple clustering tasks.

This table presents the ablation study results for the Multi-Sub model, focusing on different ways of constructing the subspace and the impact of various text encoders. It compares the performance (NMI and RI) across various clustering methods using different text and image representations. The highest and second-highest performing methods for each combination are highlighted.
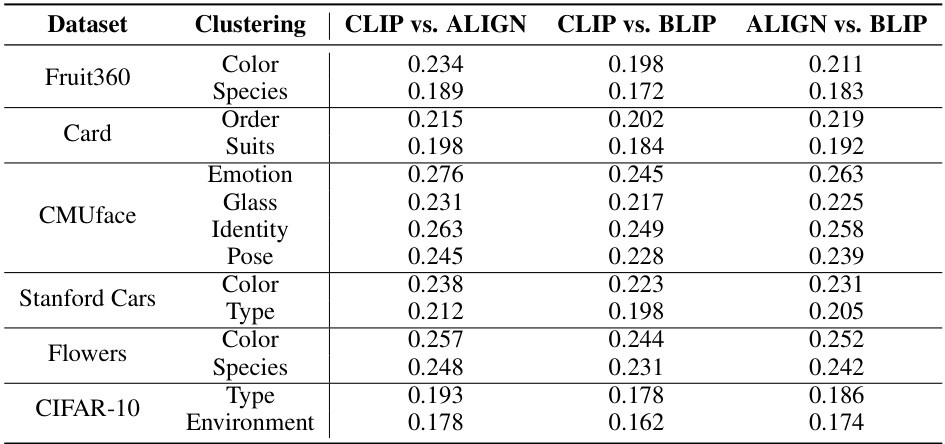
This table compares the performance of three different text encoders (CLIP, ALIGN, and BLIP) across various datasets and clustering tasks (color, species, order, suits, emotion, glass, identity, pose, type, and environment). The best-performing encoder varies depending on the specific dataset and task, highlighting the importance of selecting an appropriate text encoder for optimal results in multi-modal clustering.
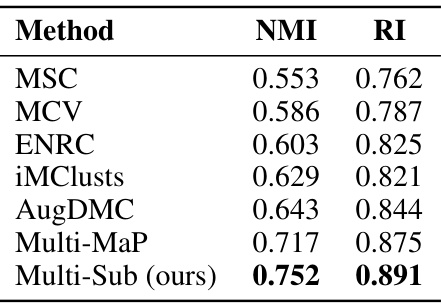
This table presents a comparison of different multiple clustering methods’ performance on the Fruit dataset, specifically focusing on a new clustering task based on the shape of the fruits (round vs. elongated). The results demonstrate Multi-Sub’s adaptability to new user-defined clustering criteria.
Full paper#