↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Current end-to-end methods for social relation reasoning from images suffer from limited generalizability and interpretability. This paper introduces SocialGPT, a modular framework that uses vision foundation models (VFMs) to translate image content into text, and large language models (LLMs) to perform text-based reasoning. This approach addresses the shortcomings of existing methods by leveraging the strengths of both VFMs and LLMs.
SocialGPT incorporates systematic design principles to effectively bridge the gap between VFMs and LLMs. It achieves competitive zero-shot results without additional model training, and its use of LLMs allows for interpretable answers. However, manual prompt design for LLMs is tedious, therefore, the paper proposes Greedy Segment Prompt Optimization (GSPO) to automatically optimize prompts. GSPO significantly improves the performance of the system, demonstrating its effectiveness in handling long prompts and generalizing well to different image styles.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel framework for social relation reasoning that combines the strengths of vision and language models. This approach offers improved generalizability and interpretability compared to traditional end-to-end methods. Furthermore, the paper introduces a greedy segment prompt optimization technique to enhance performance, opening up new avenues for automatic prompt engineering research. The zero-shot performance and explainable reasoning capabilities of this framework have significant implications for computer vision and AI. It provides a strong baseline for future research and advances the state-of-the-art in social relationship recognition.
Visual Insights#

This figure compares two different approaches to social relation reasoning. (a) shows a traditional end-to-end learning approach, where a single neural network is trained on labeled image data to directly predict the social relationship. This approach is limited in terms of generalizability and interpretability. (b) shows the proposed SocialGPT framework, which uses a modular design combining Vision Foundation Models (VFMs) and Large Language Models (LLMs). VFMs extract visual information and convert it into a textual description, which is then fed to LLMs for reasoning and prediction. This approach offers better generalizability and interpretability. SocialPrompt, a manually designed prompt, or an optimized prompt is used to instruct the LLM.
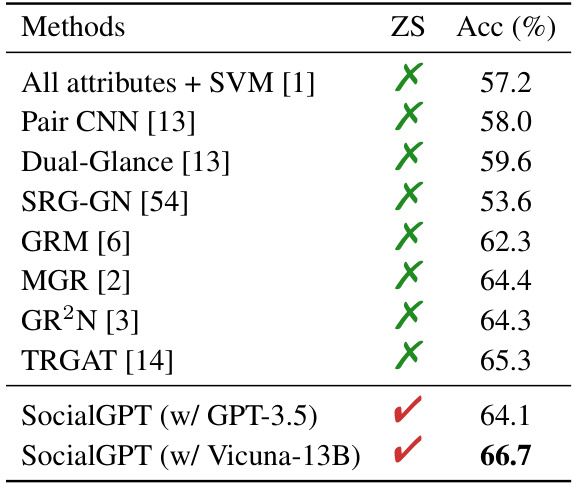
This table compares the zero-shot accuracy of SocialGPT with several other state-of-the-art methods on the PIPA dataset. The ‘ZS’ column indicates whether the method is zero-shot (meaning no training on the PIPA dataset was used), and the ‘Acc (%)’ column shows the accuracy achieved by each method. The table highlights the competitive performance of SocialGPT, especially when using the Vicuna-13B language model.
In-depth insights#
SocialGPT Framework#
The SocialGPT framework presents a novel approach to social relation reasoning by cleverly combining the strengths of Vision Foundation Models (VFMs) and Large Language Models (LLMs). Instead of relying on traditional end-to-end training, SocialGPT leverages VFMs for image perception, translating visual information into a structured textual format. This textual representation, a ‘social story’, then serves as input for LLMs, which perform the reasoning task. This modular design facilitates better generalizability and interpretability, offering a strong baseline for social relationship recognition and the ability to generate explainable answers. A key innovation is the introduction of systematic design principles for integrating VFMs and LLMs, optimizing their individual contributions within the overall framework. The framework is not reliant on extensive model training, making it significantly more efficient and accessible. Further enhancements include the Greedy Segment Prompt Optimization (GSPO) algorithm, which dynamically improves LLM performance by optimizing the prompts used for reasoning. SocialGPT’s modular design and GSPO contribute to improved performance, generalizability and the unique ability to provide interpretable results, addressing limitations of previous end-to-end approaches.
Prompt Optimization#
Prompt optimization is a crucial aspect of effective large language model (LLM) utilization, especially when applying LLMs to complex tasks like social relationship recognition. The paper explores this by introducing Greedy Segment Prompt Optimization (GSPO), an innovative approach addressing the challenge of optimizing long prompts. GSPO tackles the problem of optimizing long prompts by focusing on segment-level optimization, efficiently searching for optimal prompt variations via a greedy search guided by gradient information. This approach is particularly well-suited for tasks where the prompt incorporates diverse information extracted from a vision model, such as image features and contextual details. The effectiveness of GSPO is demonstrated through significant performance gains compared to a baseline zero-shot approach, showcasing its value in improving the accuracy and robustness of LLM-based systems. The modular nature of the system, combining VFMs and LLMs, emphasizes the importance of bridging the gap between visual perception and textual reasoning, with prompt optimization serving as a key enabler of this integration. This work highlights the importance of not only creating effective prompts but also efficiently optimizing them, particularly in scenarios where prompt engineering is complex and time-consuming.
Vision-Language Fusion#
Vision-language fusion aims to bridge the gap between visual and textual data, creating a unified representation that leverages the strengths of both modalities. Effective fusion is crucial because it allows systems to understand images in a more nuanced way, going beyond simple object recognition to encompass contextual understanding and complex reasoning. This often involves transforming the data, for example, generating image captions from visual features or extracting visual information based on textual prompts, thus enriching the understanding of each modality. Different approaches to fusion exist, including early fusion (combining features early in the processing pipeline) and late fusion (integrating higher-level representations). The optimal strategy often depends on the specific task and available resources. Recent advances in large language models (LLMs) and vision foundation models (VFMs) have significantly enhanced vision-language fusion capabilities. LLMs provide strong reasoning and text-based processing skills, while VFMs excel at visual perception and feature extraction. However, simply combining these powerful tools isn’t sufficient. Careful design of the fusion architecture, especially prompt engineering for LLMs and appropriate feature extraction from VFMs, is necessary to achieve state-of-the-art performance. Future research directions include exploring more efficient and robust fusion methods, developing new techniques for handling noisy or incomplete data, and improving the interpretability of fusion models to ensure their trustworthiness and reliability.
Zero-Shot Reasoning#
Zero-shot reasoning, a fascinating area of research, aims to enable AI models to perform tasks they haven’t explicitly been trained for. This capability is crucial for building more adaptable and generalizable AI systems. In the context of visual reasoning, zero-shot approaches bypass the need for large labeled datasets, a significant limitation of traditional methods. By leveraging the knowledge encoded within pre-trained models and employing clever prompting techniques, zero-shot reasoning demonstrates impressive results. However, generalizability across diverse domains remains a challenge. While current approaches showcase promising results on specific benchmarks, a key focus of future research involves addressing the robustness of zero-shot reasoning methods and extending their applicability to a broader range of complex real-world scenarios. Understanding and mitigating biases present in pre-trained models is also crucial for achieving ethical and reliable zero-shot reasoning capabilities. Further investigation into techniques that enhance model interpretability and provide explanations for their decisions is essential for building trust and promoting wider acceptance of such systems.
Future Extensions#
Future extensions of SocialGPT could explore more sophisticated prompting strategies beyond greedy segment optimization, perhaps employing reinforcement learning or evolutionary algorithms for more efficient prompt discovery. Integrating more advanced reasoning capabilities into LLMs, such as external knowledge bases or symbolic reasoning modules, is crucial for handling complex social relationships. Improving the robustness and generalizability of the model by incorporating diverse datasets, addressing biases in the training data, and handling unseen image styles remains a key challenge. Finally, exploring applications beyond image analysis, such as video understanding or multimodal social relation reasoning, offers exciting avenues for future research. Addressing potential ethical concerns associated with automated social analysis, such as privacy and bias, is paramount and warrants further investigation.
More visual insights#
More on figures

This figure compares two different approaches to social relation reasoning. (a) shows the traditional end-to-end learning-based framework, which uses a single neural network trained on labeled data. (b) presents the proposed SocialGPT framework, which uses a modular approach that combines vision foundation models (VFMs) and large language models (LLMs). The VFMs extract visual information from the image, which is then converted into text and fed into the LLMs for reasoning. The LLMs generate the final answer. SocialGPT offers better generalizability and interpretability compared to the end-to-end method.

This figure illustrates the SocialGPT framework. It shows how the system processes an input image: First, the Vision Foundation Models (VFMs) extract visual information, converting it into a textual ‘social story.’ This story includes details obtained from dense captions and task-oriented captions generated by querying a VFM (BLIP-2) about the image using SAM (Segment Anything Model) for object segmentation. The resulting social story, enriched with symbols for easy reference, is then fed into Large Language Models (LLMs) along with a structured prompt called ‘SocialPrompt.’ This prompt guides the LLMs to reason about the social story and produce an explainable answer regarding the social relationship depicted in the image. The SocialPrompt is divided into four segments: System, Expectation, Context, and Guidance, each playing a crucial role in the reasoning process.

This figure shows an example of how the SocialGPT framework generates a social story from an input image. The process begins with an image depicting a family at a golf course. The image is processed using the Segment Anything Model (SAM) to identify objects and people, which are labeled with symbols for reference. BLIP-2 is then used to generate detailed captions for each object or person. Finally, all the information extracted is fused into a coherent and human-readable textual story. This story provides detailed information on the objects and people present, as well as the setting and scene of the image. The created social story serves as input for the LLM during the reasoning phase.

This figure illustrates the SocialGPT framework, which consists of two main phases: perception and reasoning. In the perception phase, Vision Foundation Models (VFMs) process the input image and convert it into a textual social story. This story includes a detailed description of the image content, including objects and their relationships. The reasoning phase uses Large Language Models (LLMs) to analyze the social story and answer questions about the social relations depicted in the image. The LLMs are guided by a structured prompt called SocialPrompt, which ensures the LLMs provide explainable answers. The overall framework demonstrates the combination of visual perception and textual reasoning for social relation recognition.

This figure visualizes the interpretability of the SocialGPT model. It shows the three stages of the process: 1) The input image showing people interacting; 2) The segmentation masks generated by SAM, highlighting the identified individuals; 3) The social story generated by the model based on the image content and 4) The model’s output (answer) with an explanation justifying the relationship prediction. The explanations provided by the model demonstrate its ability to provide clear and reasoned outputs. This highlights SocialGPT’s capability of not only correctly identifying social relationships but also explaining its reasoning process, making it a more interpretable model compared to traditional, black-box methods.

This figure visualizes SocialGPT’s ability to correctly identify social relationships and provide reasonable explanations. It shows the system’s process, starting from the input image, to the creation of SAM masks, a generated social story, and finally, an interpretable answer. Two examples are given to illustrate both successful predictions and the reasoning process leading to these predictions. The examples highlight the model’s ability to accurately interpret visual cues and translate them into a coherent narrative that the LLM can readily use to make its determination.

This figure shows the comparison between the default SAM masks and the SAM masks generated by the proposed method in the paper. The default SAM masks tend to over-segment objects into multiple fine-grained parts, while the proposed method produces more comprehensive masks. For example, in the top row, the default SAM masks segment the three girls into many small regions of hair, face, hands, etc. The improved method produces larger, coherent masks that better represent the objects as wholes. The same is true for the lower row of images, showing a group of women. The improved masks should be more suitable for creating image captions and for social relation reasoning.

This figure illustrates the SocialGPT framework which consists of two main phases: the perception phase and the reasoning phase. In the perception phase, Vision Foundation Models (VFMs) are used to process an input image and convert it into a textual representation called a ‘social story.’ This social story contains information about the people and objects in the image, including their attributes and relationships. The reasoning phase then uses Large Language Models (LLMs) to analyze this social story and answer questions about the social relationships depicted in the image. The LLMs are guided by a structured prompt called SocialPrompt, which helps to ensure that the answers are accurate and interpretable. The whole framework is a modular design that combines VFMs and LLMs for better social relation recognition.
More on tables

This table presents the ablation study results on the PIPA dataset using the Vicuna-7B model in a zero-shot setting. It analyzes the contribution of each component of the SocialGPT framework by removing one component at a time and measuring the accuracy. The components include Dense Captions, Task-oriented Captions, different symbol referencing methods (coordinate vs. caption), the Social Story, and each segment of the SocialPrompt. The results show the impact of each component on the overall performance.

This table compares the performance of the proposed SocialGPT model with existing state-of-the-art methods on the PISC dataset for social relation recognition. It highlights the zero-shot accuracy (ZS Acc (%)) achieved by each method. The ‘X’ indicates that the method is fully supervised, while a checkmark signifies a zero-shot approach. The table showcases that SocialGPT using Vicuna-13B achieves competitive performance even without any training data.
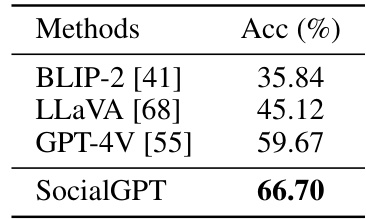
This table compares the performance of SocialGPT using the Vicuna-13B model against other existing Vision-Language Models on the PIPA dataset for social relation recognition. It shows SocialGPT’s superior performance in zero-shot setting compared to other models that require end-to-end training. The accuracy metric used is Acc (%).

This table presents the results of prompt tuning using Greedy Segment Prompt Optimization (GSPO) on different LLMs for social relation reasoning. It shows the accuracy achieved by SocialGPT with and without GSPO on two datasets, PIPA and PISC, for various LLMs (Vicuna-7B, Vicuna-13B, Llama2-7B, Llama2-13B). The Δ column indicates the improvement in accuracy achieved by using GSPO. The table highlights the effectiveness of GSPO in improving the performance of SocialGPT across different LLMs and datasets.
Full paper#



















