↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current multiview image generation methods suffer from camera mismatch, inefficiency, and low resolution, leading to poor-quality results. Existing methods often assume a predefined camera type, causing distortions when this assumption is violated. The computational cost of multiview attention also becomes prohibitive at higher resolutions.
Era3D introduces a diffusion-based camera prediction module to address the camera mismatch problem. A novel row-wise attention layer significantly reduces the computational cost of multiview attention. Era3D generates high-quality multiview images with up to 512x512 resolution, while reducing the computational complexity of multiview attention by 12 times. This allows for detailed 3D mesh reconstruction from diverse single-view images, outperforming baseline multiview diffusion methods.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses limitations in existing multiview image generation methods, particularly the issues of camera prior mismatch, inefficiency, and low resolution. Era3D’s efficient row-wise attention mechanism significantly reduces computational complexity, enabling the generation of high-resolution multiview images. This advances the field of single-view 3D reconstruction and opens new avenues for research in high-fidelity 3D content creation.
Visual Insights#

This figure compares the 3D reconstruction results of Era3D with several baseline methods on the Google Scanned Objects (GSO) dataset. It showcases input images alongside the 3D mesh reconstructions produced by each method. The comparison highlights Era3D’s ability to generate higher-quality meshes with finer details compared to the other methods, demonstrating its superior performance in reconstructing complex 3D shapes from single images.
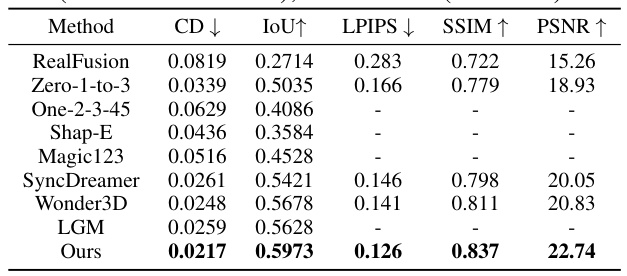
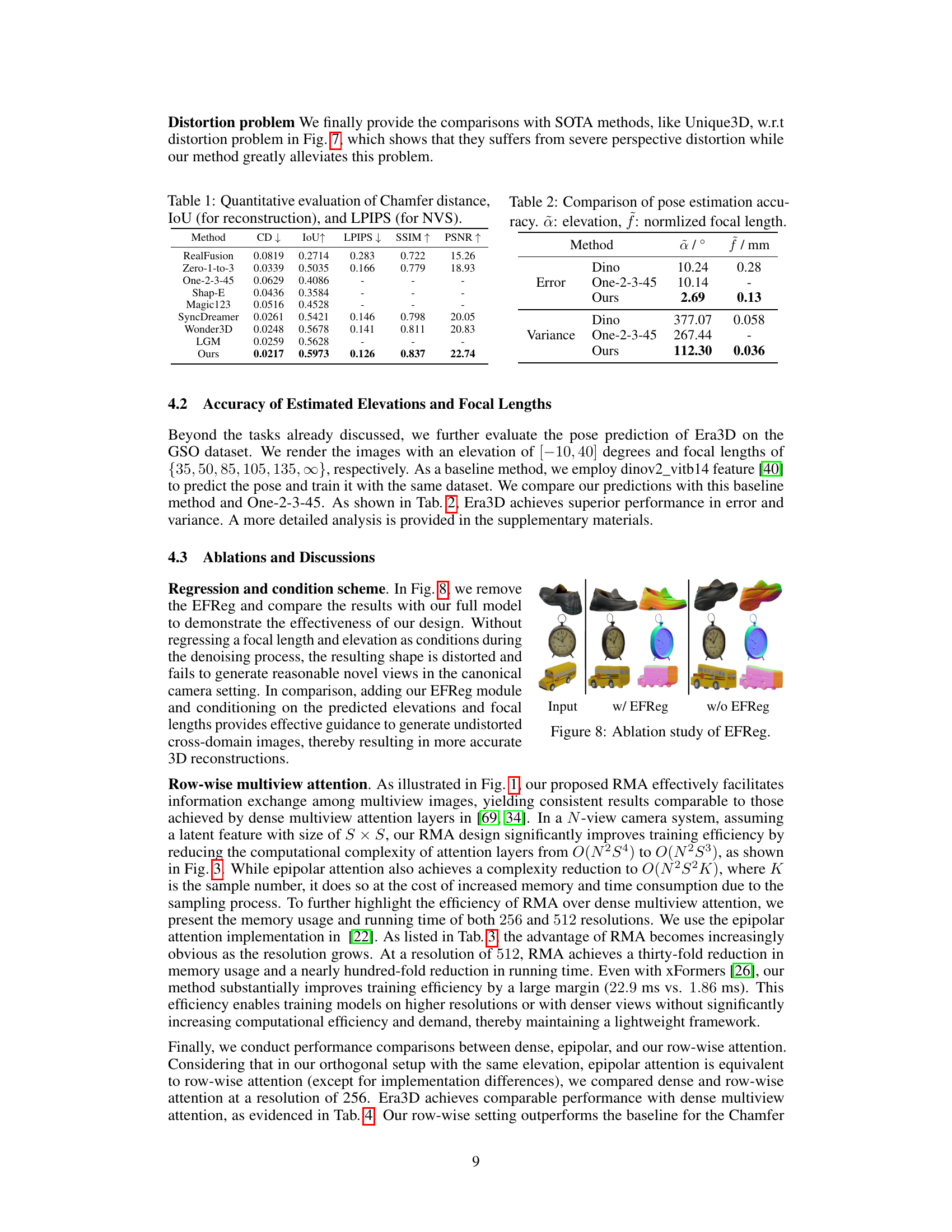
This table presents a quantitative comparison of different single-view 3D reconstruction methods. It shows the Chamfer distance (CD), which measures the geometric difference between two point clouds, the Intersection over Union (IoU), which assesses the overlap between the reconstructed and ground truth 3D meshes, the Learned Perceptual Image Patch Similarity (LPIPS), which evaluates the visual similarity of generated and ground truth images, the Structural Similarity Index (SSIM), and the Peak Signal-to-Noise Ratio (PSNR). Lower CD and LPIPS scores, and higher IoU, SSIM, and PSNR values indicate better performance. The table allows for a direct comparison of the proposed method (Ours) against several state-of-the-art methods.
In-depth insights#
Multiview Diffusion#
Multiview diffusion, a prominent approach in 3D reconstruction, aims to generate multiple consistent views of an object from a single input image. The core challenge lies in effectively capturing and leveraging cross-view dependencies to ensure realistic and coherent scene representations. Existing methods often grapple with computational limitations, particularly at high resolutions, due to the complexity of dense attention mechanisms. Furthermore, assumptions about camera parameters can lead to distortions if violated. Innovative techniques like row-wise attention aim to address computational cost by exploiting epipolar geometry, reducing the computational burden associated with full-image attention. Another critical aspect is handling inconsistent camera parameters. Methods that address the camera mismatch problem tend to enhance the robustness and generalization ability of the reconstruction, enabling better quality results even when dealing with images obtained under various imaging conditions. Overall, multiview diffusion offers a powerful and efficient pathway for 3D generation, but ongoing research continues to refine these techniques to improve efficiency, resolution, and handling of complex scenes.
Row-wise Attention#
The proposed row-wise attention mechanism offers a compelling approach to address the computational limitations of traditional multiview attention in high-resolution image generation. By leveraging the epipolar geometry inherent in multiview setups with orthogonal cameras, it cleverly restricts attention to rows within the feature maps, drastically reducing computational cost compared to dense multiview attention. This efficiency gain is particularly crucial for high-resolution images, enabling the generation of detailed 3D meshes which was previously computationally infeasible. The simplicity and efficiency of row-wise attention are key advantages, making it a practical and scalable solution for multiview diffusion models. However, the reliance on orthogonal camera assumptions might limit its generalizability to scenarios with arbitrary camera parameters, representing a potential limitation for real-world applications. Future work could explore ways to extend the benefits of row-wise attention to more general camera configurations while maintaining computational efficiency.
Camera Prediction#
Accurate camera parameter estimation is crucial for high-fidelity 3D reconstruction from a single image. A ‘Camera Prediction’ module, as implied by the title, would ideally leverage deep learning to infer camera intrinsics (focal length, sensor size) and extrinsics (pose, viewpoint) directly from the input image. This is a challenging task because these parameters are inherently ambiguous from a single 2D perspective. Robustness to variations in image content, lighting, and viewpoint is essential. A successful camera prediction module needs to be computationally efficient, particularly for high-resolution images, and it must generalize well to unseen data. A strong camera prediction module could enhance existing multi-view generation approaches by enabling more realistic and consistent synthetic views. This is especially important if the input image does not conform to a predefined camera model. By accurately predicting camera parameters, one can address issues of perspective distortion and improve the overall quality of 3D reconstructions derived from multi-view image generation techniques. The accuracy of the 3D models will depend heavily on the accuracy of this prediction.
High-Res Generation#
Generating high-resolution images is a significant challenge in the field of image generation. Many existing methods struggle to produce sharp, detailed visuals at higher resolutions due to computational constraints and limitations in model architecture. A key focus in improving high-resolution image generation involves enhancing the model’s capacity to capture and represent fine-grained details. This might involve modifications to the network architecture, incorporating attention mechanisms that can focus on small image regions, or training with larger datasets containing higher resolution images. Efficient techniques are crucial for overcoming the computational cost of processing high-resolution images. Efficient attention mechanisms and optimized training strategies become essential for achieving high-resolution generation within reasonable time and resources. The fidelity and realism of generated high-resolution images are also paramount. Success relies on employing techniques such as super-resolution, improving the model’s ability to capture and generate diverse textures, and utilizing advanced loss functions that prioritize both visual quality and perceptual similarity to real-world images. Overall, advancements in high-resolution image generation often hinge on a combination of architectural innovations, training improvements, and careful consideration of computational efficiency and image quality metrics.
Future Enhancements#
Future enhancements for Era3D could focus on several key areas. Improving the handling of intricate geometries and open meshes is crucial, perhaps by incorporating alternative 3D representations beyond Neural SDFs or employing more sophisticated mesh reconstruction methods. Addressing the limitations of the current 6-view generation process would improve the overall accuracy and quality of the generated models. This could involve incorporating more views, or developing more effective techniques for generating consistent and high-resolution multiview images from a limited number of views. Developing a more robust camera pose and focal length prediction module that can handle a wider variety of camera parameters and image conditions would increase the model’s real-world applicability and reduce distortion artifacts. Exploring different attention mechanisms or refining the current row-wise attention to improve computational efficiency while preserving image quality would enhance the model’s performance. Investigating the use of larger datasets and more advanced training techniques could further boost generation quality, detail and overall fidelity. Finally, research into making Era3D more robust to noisy and incomplete input images would broaden its utility.
More visual insights#
More on figures

This figure shows the results of Era3D on various single-view images. Given a single image as input, Era3D generates multiple high-resolution (512x512) images from different viewpoints, as if viewed from an orthogonal camera. These generated images can then be used to reconstruct a 3D mesh model using the NeuS method.

This figure illustrates three different types of multiview attention mechanisms used in multiview image generation. (a) shows a dense attention approach, where all features are processed together. (b) and (c) demonstrate the epipolar attention method, that leverages epipolar geometry to reduce computational cost. (d) and (e) show the canonical camera setting and the row-wise attention approach developed in this paper. Row-wise attention takes advantage of aligned epipolar lines and orthogonal cameras in the canonical setting to further optimize computational complexity.
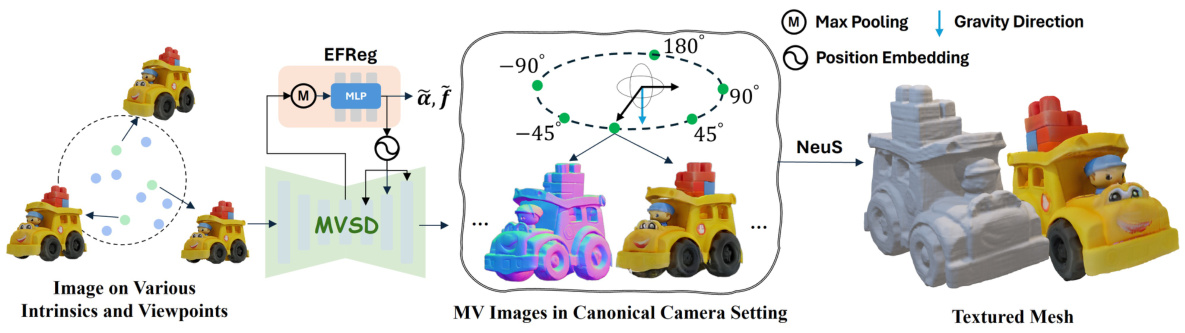
This figure shows the overall pipeline of Era3D for 3D mesh reconstruction from a single-view image. It begins with an input image that may have arbitrary intrinsic and viewpoint parameters. The EFReg (Elevation and Focal Length Regression) module estimates the camera parameters (elevation and focal length) which are used to guide the multiview diffusion process (MVSD). The MVSD generates high-quality, multiview consistent images and normal maps (in a canonical orthogonal camera setting). Finally, these images are input to the NeuS (Neural Implicit Surface) module, which reconstructs a textured 3D mesh.

This figure compares the 3D reconstruction results of different methods on the GSO dataset. The input images are shown alongside the 3D meshes generated by Wonder3D, LGM, One-2-3-45, Shape-E, and Era3D. The comparison highlights that Era3D produces significantly more detailed and higher-quality 3D meshes compared to the other methods. This demonstrates Era3D’s superiority in reconstructing complex 3D shapes from a single image.

This figure compares the novel view synthesis quality achieved by different methods (LGM, Wonder3D, Magic123, and Era3D) on 3D meshes reconstructed from single-view images generated using the SDXL model. It visually demonstrates the differences in the quality of generated novel views, showcasing the performance of Era3D in terms of detail, realism, and overall visual consistency.

This figure compares the 3D reconstruction results of Era3D, Wonder3D, and Unique3D on both the GSO dataset (synthetic objects) and in-the-wild images. It visually demonstrates Era3D’s superior performance in handling perspective distortion. While other methods produce distorted reconstructions, Era3D generates accurate and visually appealing 3D models even when input images are taken from perspective cameras with varying viewpoints and focal lengths.

This ablation study compares the results of the full model (with EFReg) against a model without the Elevation and Focal Length Regression module. The figure shows that the absence of EFReg leads to distortions and inaccuracies in the generated novel views, whereas including EFReg results in significantly improved quality and detail in the generated images.
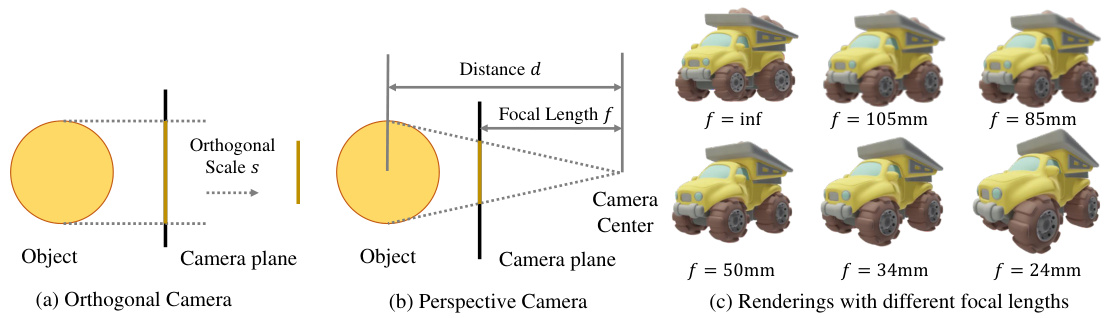
This figure illustrates the equivalence between orthogonal and perspective camera models used in the paper’s experiments. It shows how renderings from both types of cameras can be made similar in size to reduce training bias. The left panel (a) depicts the setup for an orthogonal camera, where the distance from the camera to the object is determined by the orthogonal scale ’s’ and focal length ‘f’. The middle panel (b) shows the perspective camera setup, where the distance ’d’ is calculated as f/s to create a similar image size. The right panel (c) displays renderings of the same object created with different focal lengths (∞, 105mm, 85mm, 50mm, 34mm, 24mm), highlighting the impact of focal length on perspective distortion. The figure is essential for understanding the camera canonicalization method employed in Era3D.

This figure illustrates different types of multiview attention layers used in multiview image generation. It compares dense attention, general camera setting with epipolar attention, canonical camera setting, and the proposed row-wise attention. The key difference highlighted is the computational complexity reduction achieved by the row-wise attention method in the canonical camera setting due to its alignment with image rows, leading to O(N2S3) complexity compared to higher complexities in other methods.

This figure shows qualitative comparisons of 3D reconstruction results between Era3D and other state-of-the-art methods (Wonder3D and Unique3D). The results are presented for both the GSO dataset (Google Scanned Objects) and in-the-wild images. The comparison highlights Era3D’s ability to mitigate the perspective distortion artifacts that affect other methods, especially when dealing with images captured under different camera settings (variable intrinsics and viewpoints).

This figure compares the results of Era3D and other state-of-the-art methods on the GSO and in-the-wild datasets. It demonstrates Era3D’s ability to generate high-quality multiview images and 3D meshes even when the input images have severe perspective distortions, while other methods suffer from artifacts and inaccuracies. The figure showcases the robustness of Era3D to inconsistent camera intrinsics and demonstrates its ability to improve the quality of 3D reconstruction compared to existing methods.

This figure shows additional results of 3D reconstruction from single-view images obtained from the internet. The left column displays the input images; the subsequent columns display the generated multiview images, normal maps, and final 3D mesh reconstructions. A variety of objects are shown, demonstrating the model’s ability to handle diverse input imagery and generate realistic 3D models.
More on tables

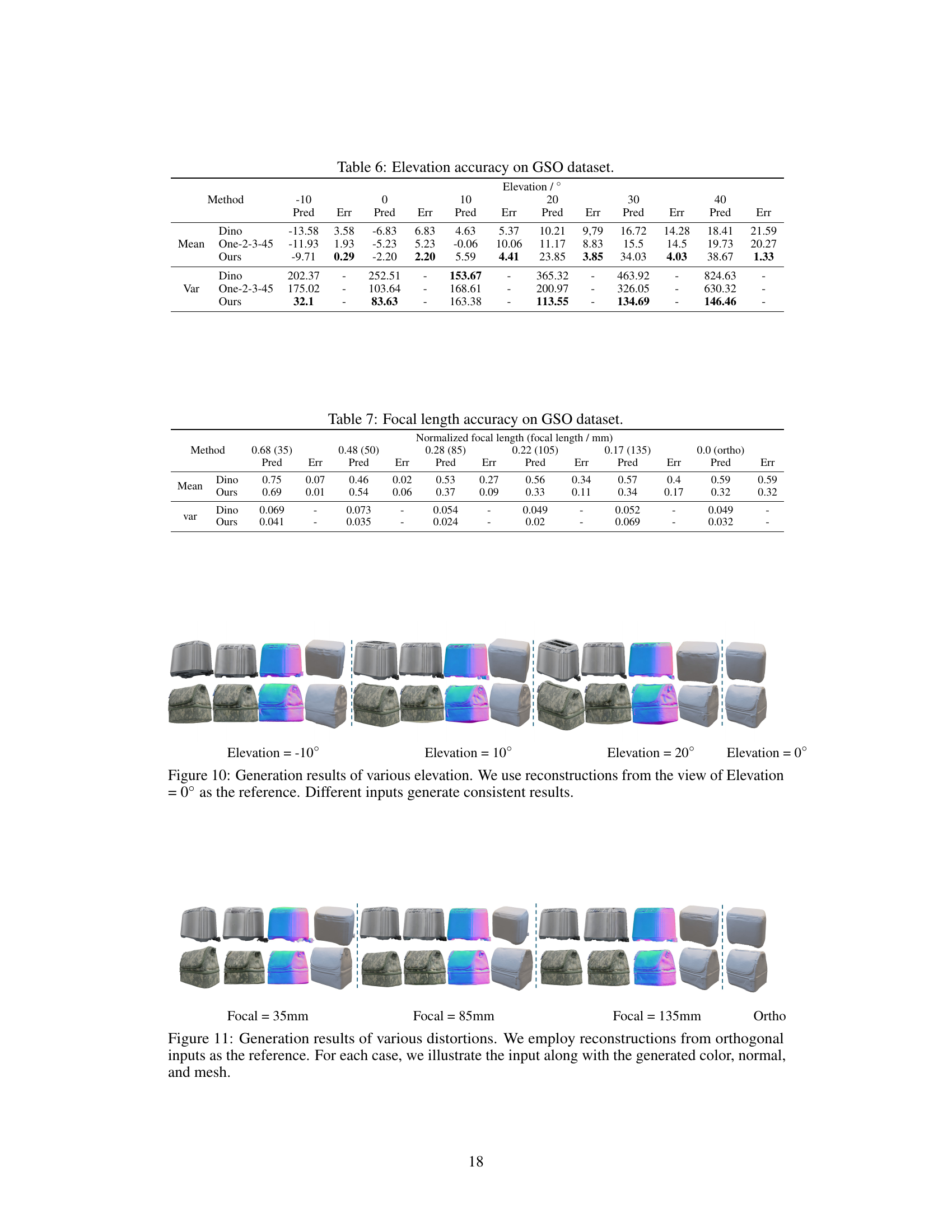
This table compares the accuracy of elevation and focal length estimation of three different methods: Dino, One-2-3-45, and the proposed method. The accuracy is evaluated using error and variance for both elevation (in degrees) and normalized focal length. The proposed method shows significantly lower error and variance compared to the baselines.

This table compares the memory usage (in gigabytes) and running time (in milliseconds) of three different multiview attention mechanisms: dense, epipolar, and row-wise. The comparison is made for two image resolutions: 256x256 and 512x512. It also shows the impact of using the xFormers library for optimization. The row-wise attention method is shown to be significantly more efficient in terms of both memory and time, especially at higher resolution.

This table presents a quantitative comparison of the performance of dense and row-wise multiview attention methods at a resolution of 256. It shows the Chamfer Distance (CD), Intersection over Union (IoU), Learned Perceptual Image Patch Similarity (LPIPS), Peak Signal-to-Noise Ratio (PSNR), and Structural Similarity Index (SSIM). Lower CD and LPIPS values indicate better performance, while higher IoU, PSNR, and SSIM values represent better quality.

This table presents a quantitative evaluation of the accuracy of elevation prediction on the Google Scanned Objects (GSO) dataset. Three methods (Dino, One-2-3-45, and Ours) are compared, showing the predicted elevation (Pred) and the error (Err) for various true elevations (-10°, 0°, 10°, 20°, 30°, 40°). Additionally, the variance (Var) of the predictions is shown for each method. The results show that the ‘Ours’ method demonstrates superior performance with lower error and variance compared to the other methods.

This table presents a quantitative comparison of different methods for 3D reconstruction and novel view synthesis. The metrics used are Chamfer distance (CD), which measures the distance between point clouds, Intersection over Union (IoU), which assesses the overlap between predicted and ground truth volumes, and Learned Perceptual Image Patch Similarity (LPIPS), which evaluates the perceptual similarity of generated images to ground truth images. Lower CD and higher IoU and SSIM values indicate better performance.

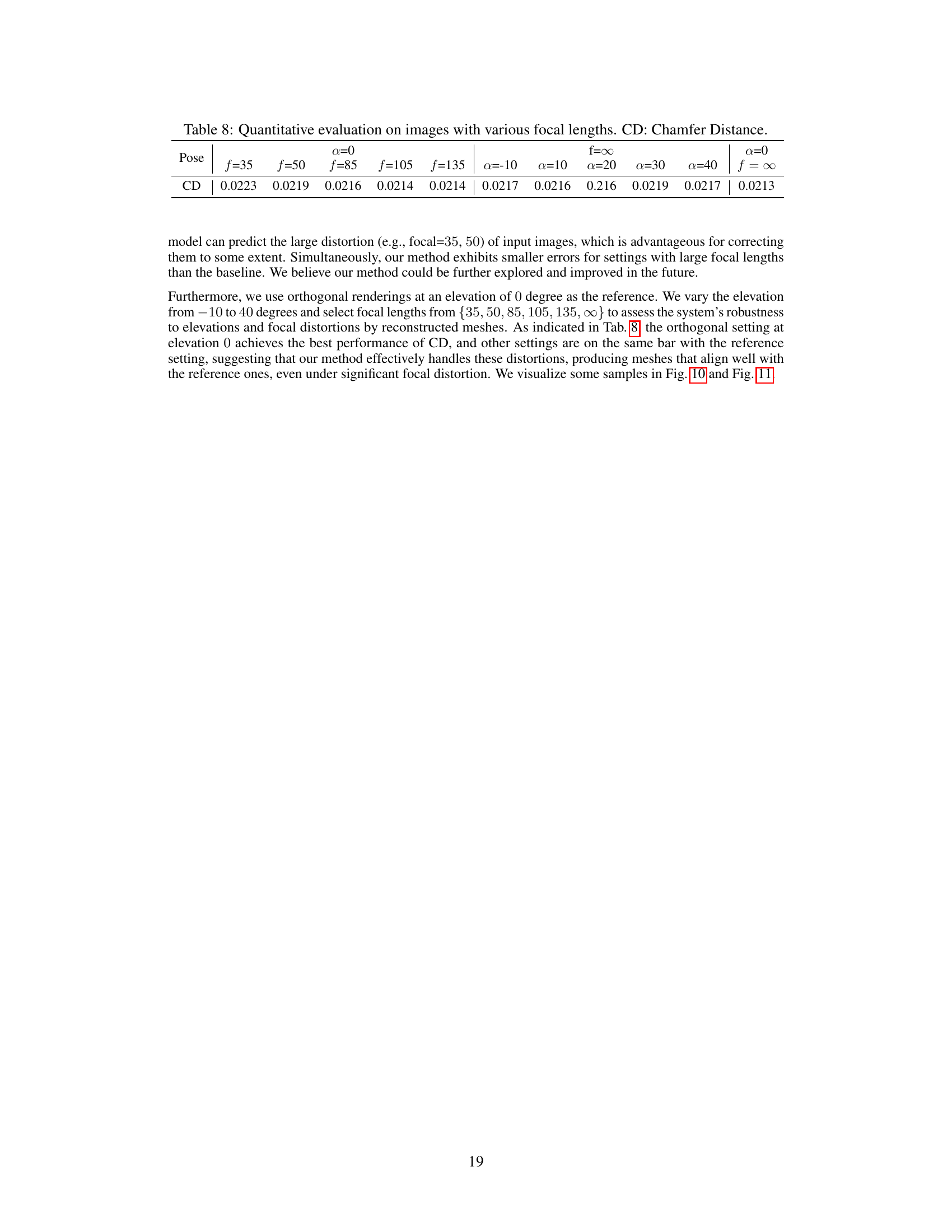
This table presents a quantitative assessment of image quality and 3D mesh reconstruction accuracy using the Chamfer Distance (CD) metric. The evaluation considers images generated with different focal lengths (f) and elevation angles (α). The results demonstrate the robustness of the method across varying camera parameters, showcasing its ability to generate high-quality images even under significant focal distortions.
Full paper#