↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Large-scale AI models suffer from biases and safety issues due to inadequately curated training datasets containing unwanted visual data. Manually removing this unwanted content is impractical given the massive size of modern datasets. Existing methods often require extensive, computationally expensive training on additional data, limiting efficiency and practicality.
The proposed Hassle-Free Textual Training (HFTT) method addresses these limitations by using only textual data to train detectors for unwanted visual content. HFTT introduces a novel loss function that greatly reduces the need for human annotation, coupled with a clever textual data synthesis technique that effectively emulates the unknown visual data distribution. Experiments demonstrate HFTT’s effectiveness in out-of-distribution detection and hateful image detection, highlighting its versatility and efficiency.
Key Takeaways#
Why does it matter?#
This paper is crucial because it tackles the critical issue of unwanted visual data in large AI models. It presents a novel, efficient solution, significantly reducing the need for human labor and opening new avenues for research in AI safety and bias mitigation. The approach has implications across multiple fields, from OOD detection to identifying hateful content, demonstrating its broad applicability.
Visual Insights#

This figure illustrates the Hassle-Free Textual Training (HFTT) method. The training phase uses only textual data and a pre-trained vision-language model (VLM) to train trainable embeddings. These embeddings are then used in the test phase to classify images based on cosine similarity to task embeddings (which define the specific task, e.g., hateful image detection or OOD detection).

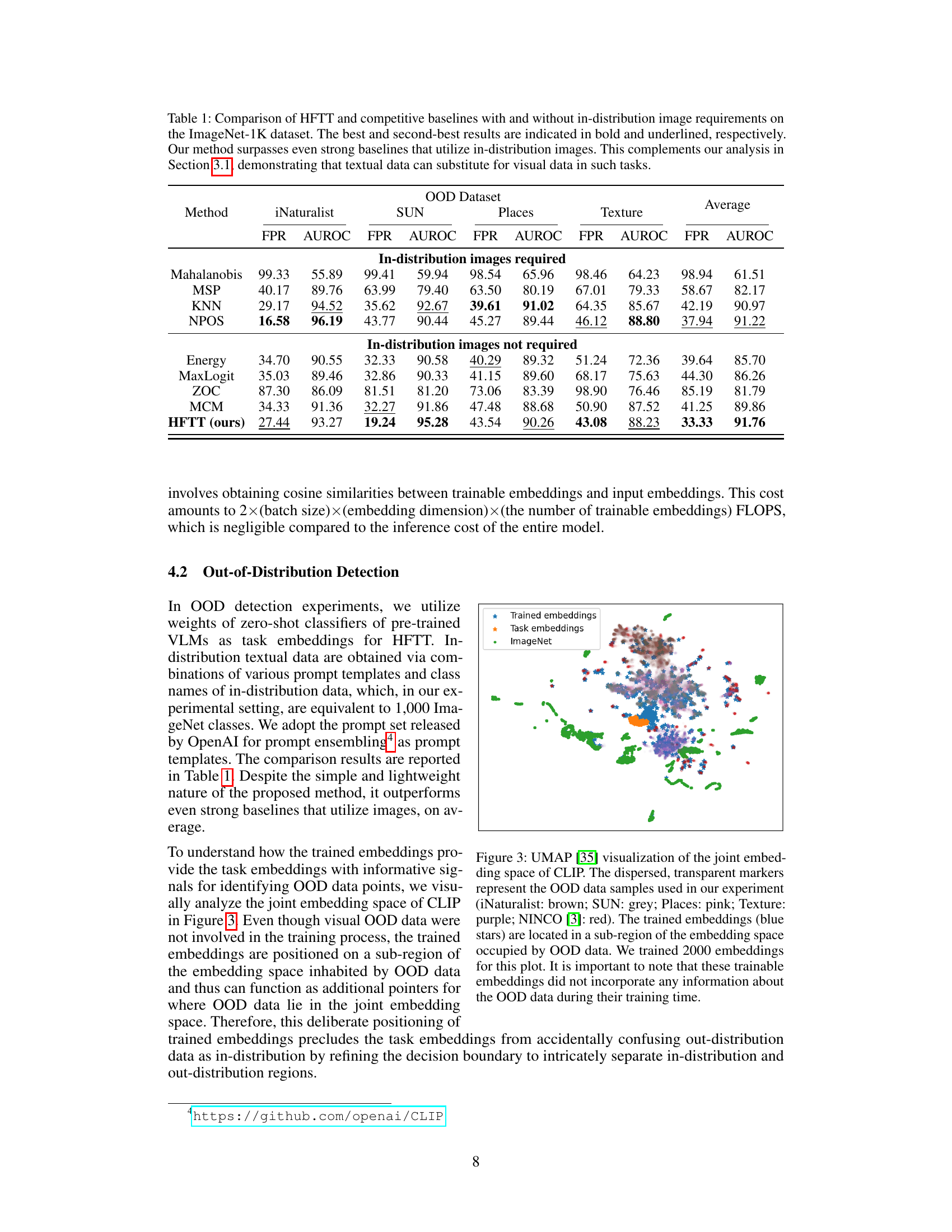
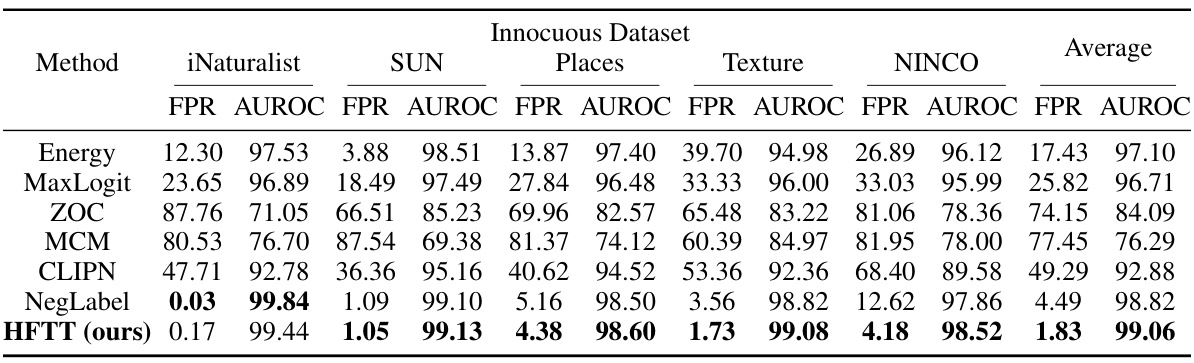
This table compares the performance of the proposed Hassle-Free Textual Training (HFTT) method against several other state-of-the-art methods for out-of-distribution (OOD) detection on the ImageNet-1k dataset. It highlights the effectiveness of HFTT, which uses only textual data for training, even when compared to methods that require in-distribution images. The results support the paper’s claim that textual data can effectively substitute for visual data in certain tasks.
In-depth insights#
HFTT: Core Idea#
The core idea behind Hassle-Free Textual Training (HFTT) is the innovative use of textual data to train visual data detectors, bypassing the need for laborious visual data annotation. HFTT leverages the power of pre-trained vision-language models, demonstrating that a model capable of effectively partitioning visual data can be learned using only textual data. This is achieved through a novel objective function which reduces the dependence on human annotation and clever textual data synthesis techniques which emulate the unknown visual data distribution during training, therefore greatly improving efficiency and reducing costs. The method’s unique characteristics extend its utility beyond traditional out-of-distribution detection, allowing applications to more abstract concepts such as hateful image detection. This text-only training paradigm eliminates ethical concerns associated with collecting and annotating unwanted visual data, offering a more responsible and efficient approach to data curation in the age of large-scale AI.
Text-Only Training#
The concept of ‘Text-Only Training’ in the context of visual data processing is a significant departure from traditional methods. It challenges the established paradigm of requiring large, labeled image datasets for training visual models, instead proposing that models can be effectively trained using only textual data. This approach hinges on the ability of powerful vision-language models (VLMs) to bridge the semantic gap between text and images. By leveraging the rich representations learned by these models from a massive multimodal dataset, the method aims to transfer knowledge from text to image classification tasks. This opens avenues for reducing the reliance on expensive and time-consuming image annotation, making the training process more efficient and scalable. However, the success of such an approach crucially depends on the quality and representativeness of the textual data used, as well as the ability of the VLM to generalize effectively to unseen visual data. Further research is needed to explore the limitations and potential biases inherent in this method, and to investigate its performance across different visual tasks and VLMs. Ultimately, the success of text-only training will determine the extent to which it can revolutionize visual AI development, and if it can overcome the fundamental hurdle of generalizing visual representations learned solely from textual data.
OOD Detection#
Out-of-distribution (OOD) detection is a crucial aspect of ensuring the reliability and safety of machine learning models, particularly in real-world applications. Traditional methods often relied on post-hoc anomaly scores or outlier exposure techniques, which have limitations in effectively identifying OOD instances, especially in complex or high-dimensional data. The advent of vision-language models (VLMs) has offered new avenues for OOD detection, leveraging the rich semantic information encoded by these models to better distinguish in-distribution from out-of-distribution data. However, many VLM-based approaches still suffer from the need for extensive additional visual data, hindering sample efficiency and potentially raising ethical concerns. Recent advancements, such as the Hassle-Free Textual Training (HFTT) method described in this paper, explore innovative training strategies to address these challenges. HFTT demonstrates that textual data alone can be effectively used to train detectors capable of partitioning visual data, significantly reducing reliance on visual data annotation and potentially expanding the applicability of OOD detection to more abstract concepts. The key innovation lies in its novel loss function and textual data synthesis technique, enabling the method to imitate the integration of unknown visual data distributions at no extra cost. The effectiveness of HFTT is validated through experiments on various OOD datasets and tasks, showcasing its superiority over traditional techniques while avoiding ethical pitfalls often associated with image-centric approaches.
Hate Speech#
The concept of “hate speech” within the context of this research paper likely involves the detection and filtering of online content expressing prejudice or hate towards specific groups. The paper likely explores techniques for identifying such harmful language using natural language processing (NLP) and potentially computer vision if image analysis is also involved. A significant challenge is likely the subjectivity inherent in defining hate speech, which varies across cultures and contexts. The authors likely discuss the ethical implications of automatically identifying and removing this content, acknowledging the potential for bias and censorship. The paper probably investigates performance metrics for evaluating hate speech detection systems such as precision, recall, and F1-score. Furthermore, the study might also explore methods for mitigating bias in these systems, ensuring fairness and avoiding the disproportionate targeting of certain groups. The limitations might involve handling sarcasm, satire, and nuanced language, all of which can be extremely challenging for automated systems. Overall, the analysis likely focuses on the technical aspects, challenges, and ethical considerations of detecting hate speech within large datasets of text and images, ultimately aiming to develop robust and fair detection systems.
Future Work#
Future research directions stemming from this work could explore several promising avenues. Extending HFTT to other modalities beyond visual data would be valuable, such as applying it to audio or textual data containing unwanted elements like hate speech or misinformation. Investigating the robustness of HFTT to adversarial attacks is crucial for real-world applications where malicious actors might attempt to bypass the detection mechanism. A deeper exploration into the theoretical underpinnings of HFTT, possibly through information-theoretic analyses, could provide a more rigorous justification for its effectiveness. Analyzing the impact of different pre-trained VLM architectures on HFTT’s performance is another key area. Finally, applying HFTT to tasks requiring more abstract or nuanced definitions of ‘unwanted content’ would showcase the method’s versatility and generalizability, moving beyond the well-defined boundaries of OOD or hate speech detection. These future directions present exciting opportunities to enhance the practicality and applicability of HFTT for a broader range of applications.
More visual insights#
More on figures
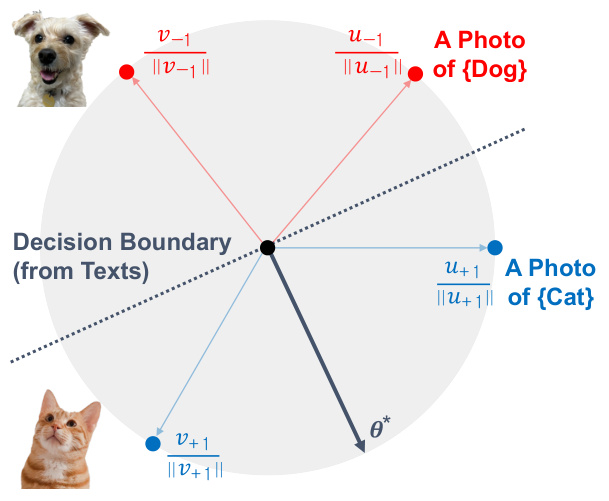
This figure illustrates the proposed Hassle-Free Textual Training (HFTT) method. It shows the training and testing phases. In the training phase, only textual data (text corpus) and a text encoder are used to generate task embeddings and trainable embeddings. The testing phase uses these trained embeddings along with an image encoder to classify images based on cosine similarity. Different tasks are represented by different task embeddings; for example, hateful image detection uses hate speeches as embeddings while out-of-distribution (OOD) detection uses class names from the training set.
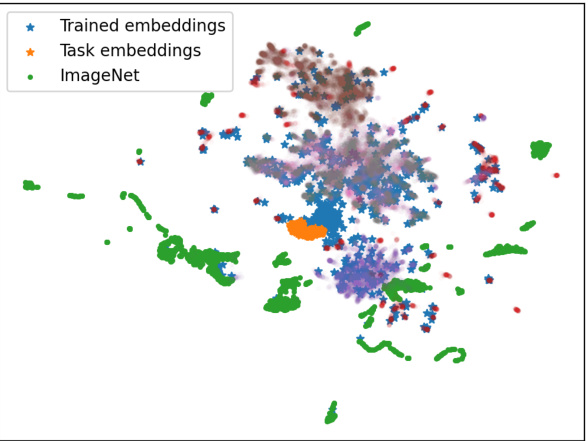
This UMAP visualization shows the joint embedding space of CLIP. Different colors represent different OOD datasets. The blue stars are the trained embeddings from the HFTT method, which are clustered in a region of the embedding space that overlaps with the OOD data, demonstrating that despite not using any visual OOD data during training, the model learned to separate in-distribution and out-of-distribution data.
More on tables
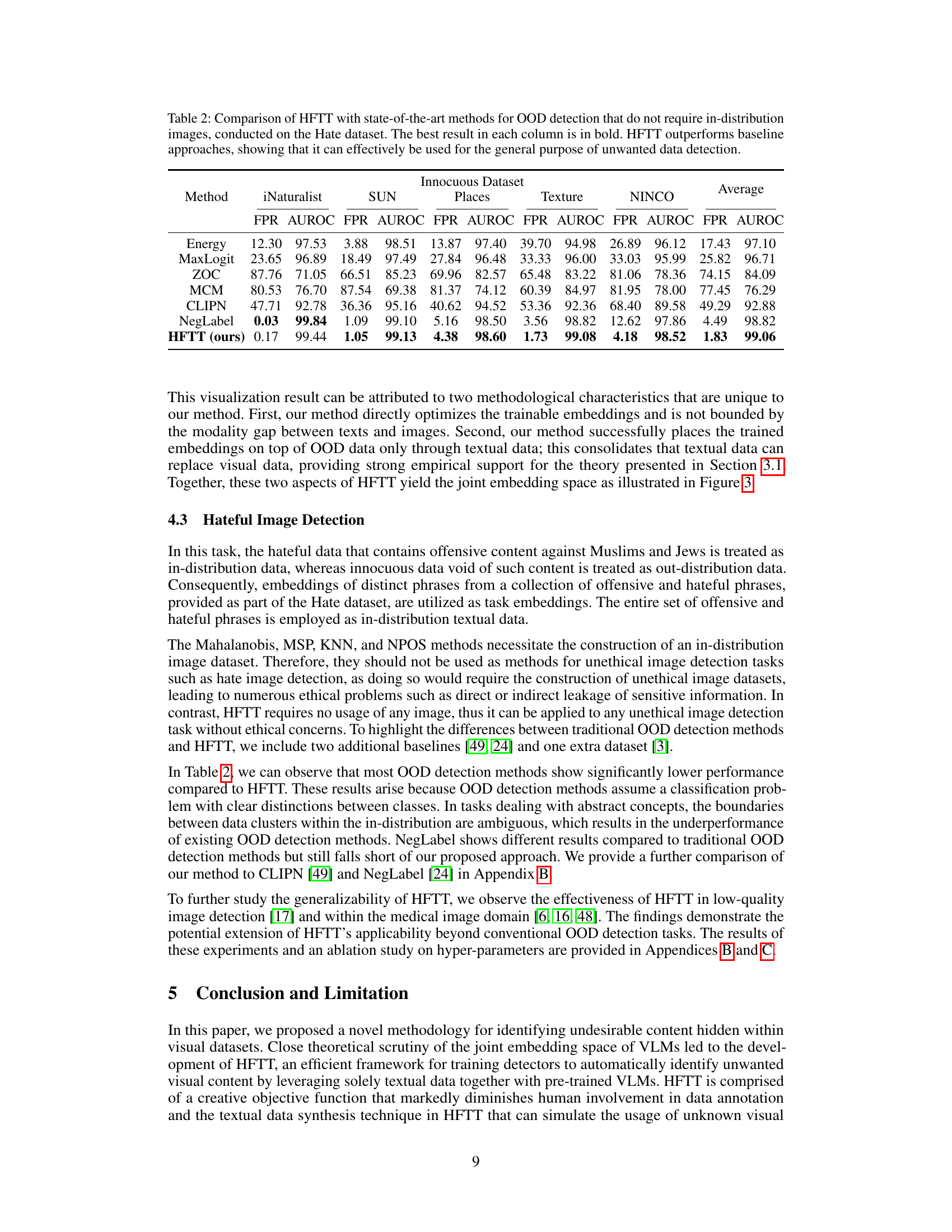
This table compares the performance of the Hassle-Free Textual Training (HFTT) method against other state-of-the-art out-of-distribution (OOD) detection methods on a dataset focused on hateful images. It highlights that HFTT, which doesn’t need in-distribution images for training, still surpasses methods that do require such images. This demonstrates HFTT’s effectiveness in detecting unwanted visual data.
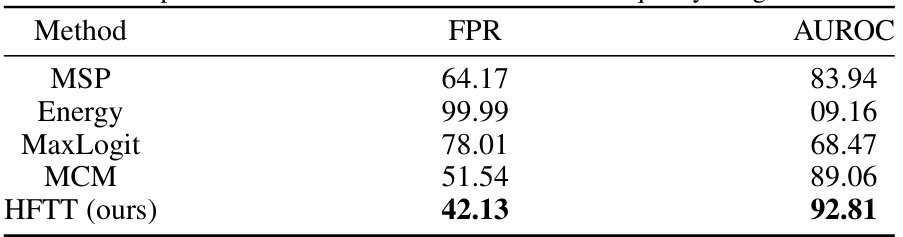
This table compares the performance of the proposed Hassle-Free Textual Training (HFTT) method against existing baselines on a low-quality image detection task. It shows the False Positive Rate (FPR) and Area Under the Receiver Operating Characteristic curve (AUROC) for each method, demonstrating HFTT’s superior performance in identifying corrupted images. The results highlight HFTT’s effectiveness even compared to methods that utilize in-distribution images.
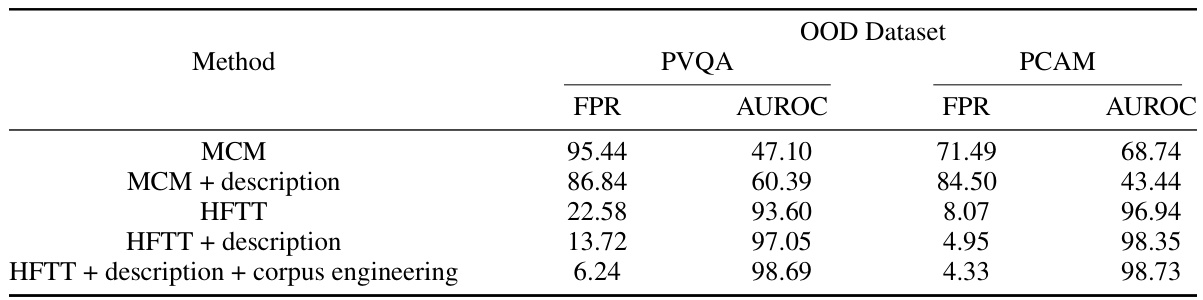
This table compares the performance of HFTT and MCM on two medical image datasets (PVQA and PCAM), using the ISIC-18 dataset as in-distribution data. It shows the false positive rate (FPR) and area under the receiver operating characteristic curve (AUROC) for each method, with and without additional descriptions and corpus engineering. The results demonstrate that HFTT outperforms MCM, especially when incorporating additional context.
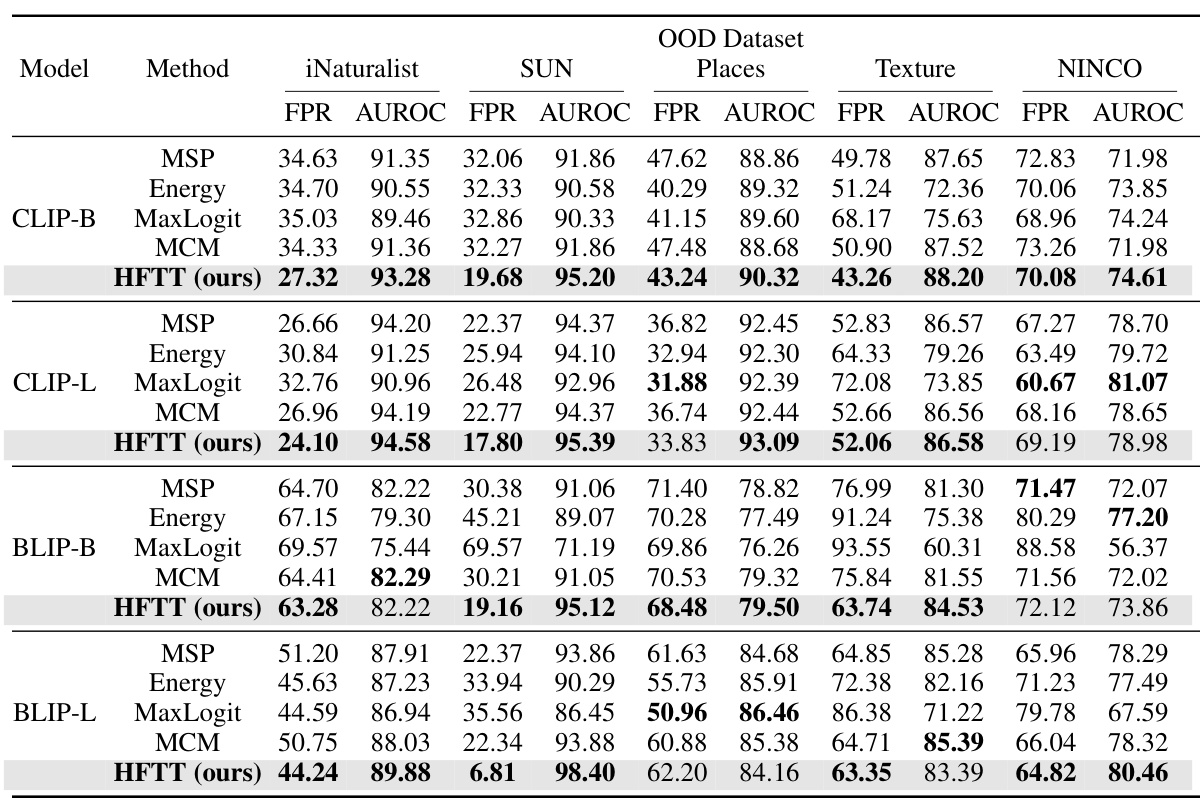
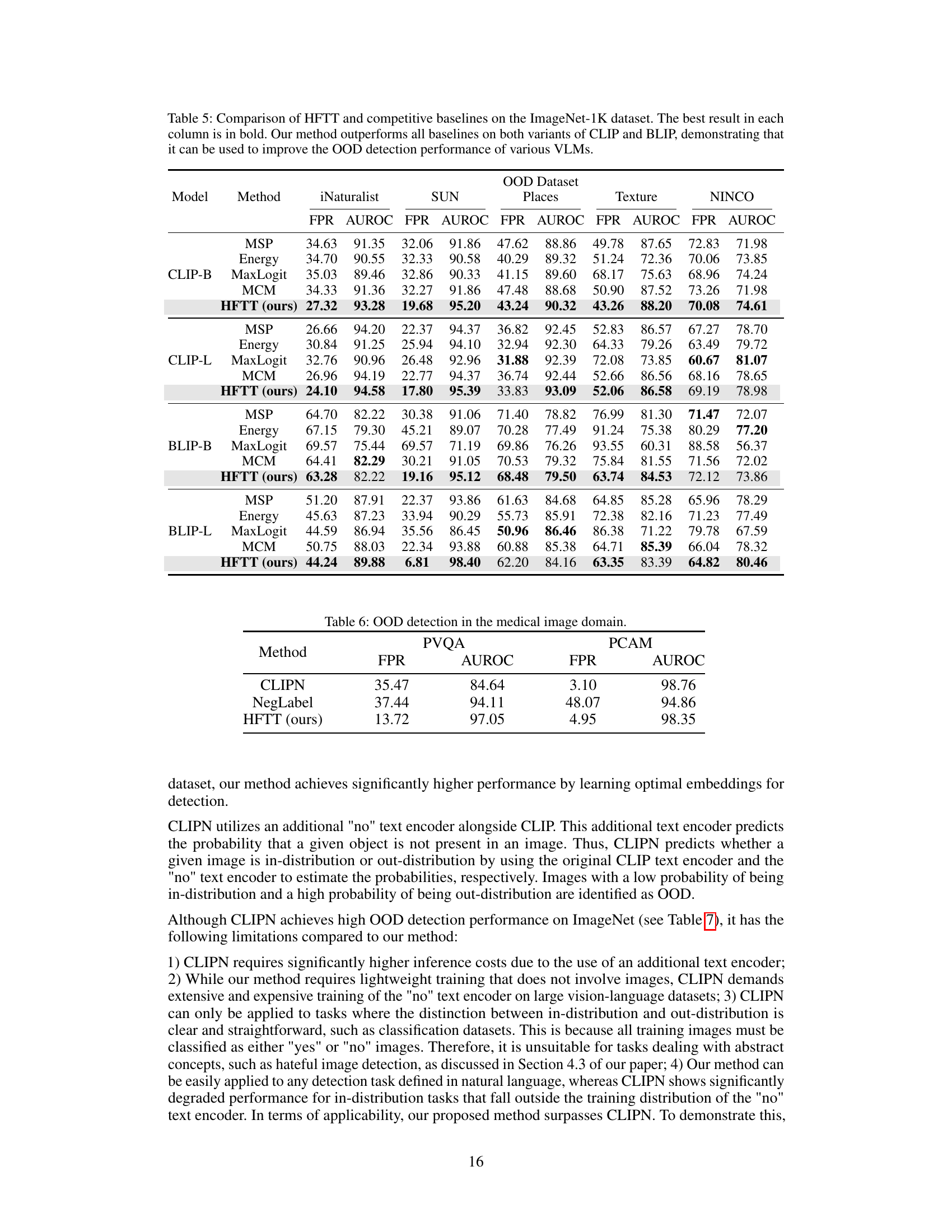
This table compares the performance of the proposed Hassle-Free Textual Training (HFTT) method against several other state-of-the-art methods for out-of-distribution (OOD) detection on the ImageNet-1k dataset. It highlights the performance of HFTT even when compared to methods that require in-distribution images, thereby supporting the paper’s claim that textual data can effectively replace visual data for OOD detection.
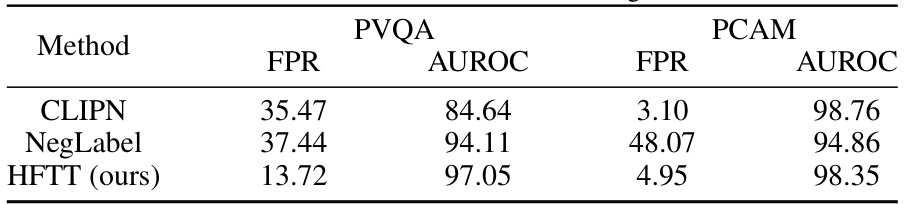
This table compares the performance of the proposed Hassle-Free Textual Training (HFTT) method against the Maximum Mean Discrepancy (MMD) method for out-of-distribution (OOD) detection in medical image datasets. The datasets used are PVQA (visual question answering) and PCAM (breast cancer detection). The metrics used for comparison are the False Positive Rate (FPR) and Area Under the Receiver Operating Characteristic curve (AUROC). The table shows HFTT significantly outperforms MCM on both datasets, indicating its superior performance for OOD detection in medical image analysis.

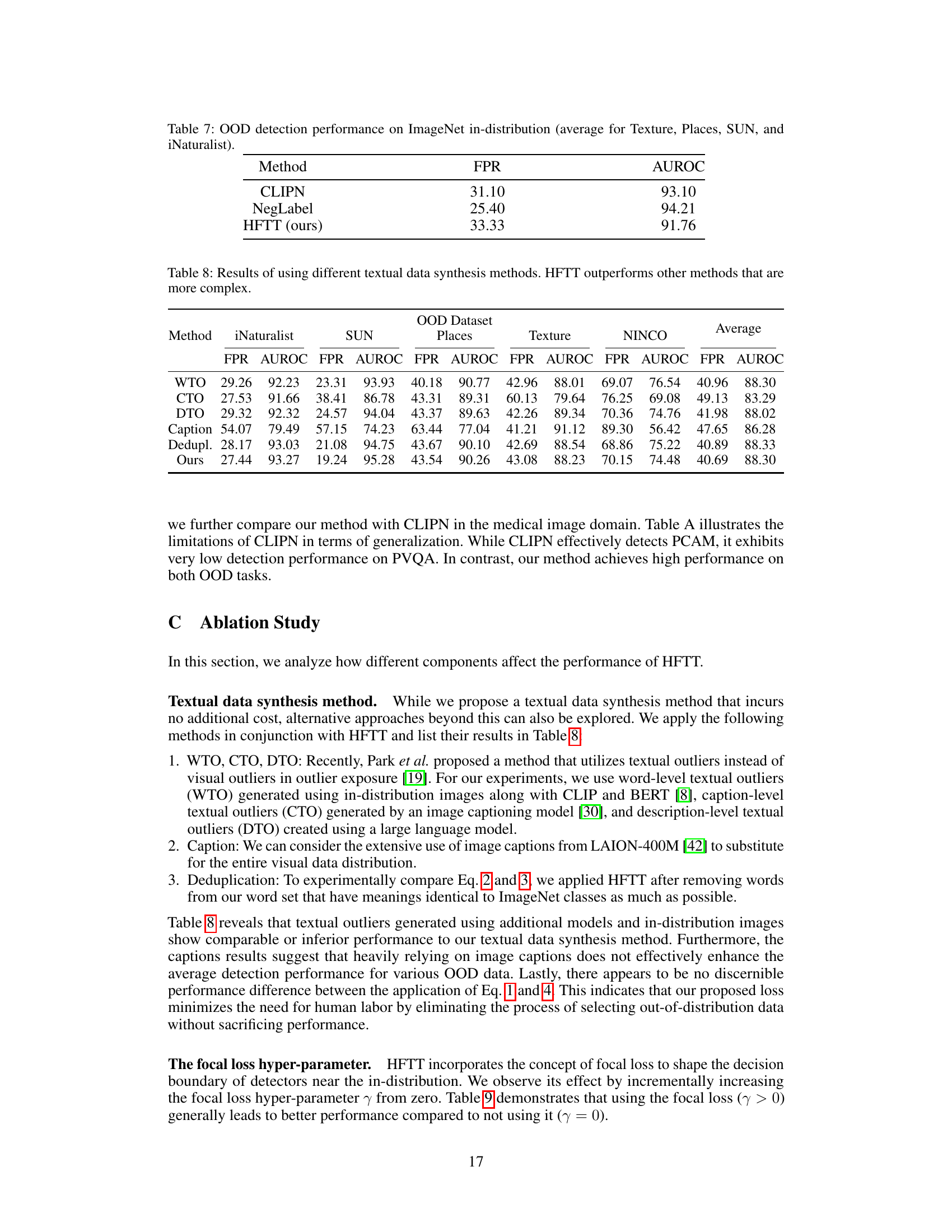
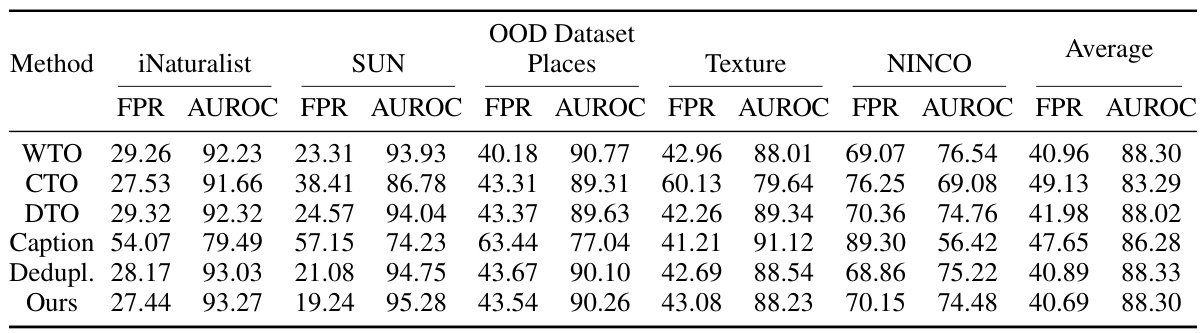
This table presents the results of out-of-distribution (OOD) detection experiments performed on the ImageNet dataset. Specifically, it shows the False Positive Rate (FPR) and Area Under the Receiver Operating Characteristic curve (AUROC) for three different methods: CLIPN, NegLabel, and the authors’ proposed method, HFTT. The results are averaged across four different out-of-distribution datasets: Texture, Places, SUN, and iNaturalist. This table demonstrates the relative performance of the three methods in identifying out-of-distribution samples within the ImageNet dataset.
This table compares the performance of the proposed Hassle-Free Textual Training (HFTT) method against other state-of-the-art Out-of-Distribution (OOD) detection methods on the ImageNet-1k dataset. It shows that HFTT achieves better results than methods that require in-distribution images, supporting the paper’s claim that textual data can replace visual data in OOD detection.
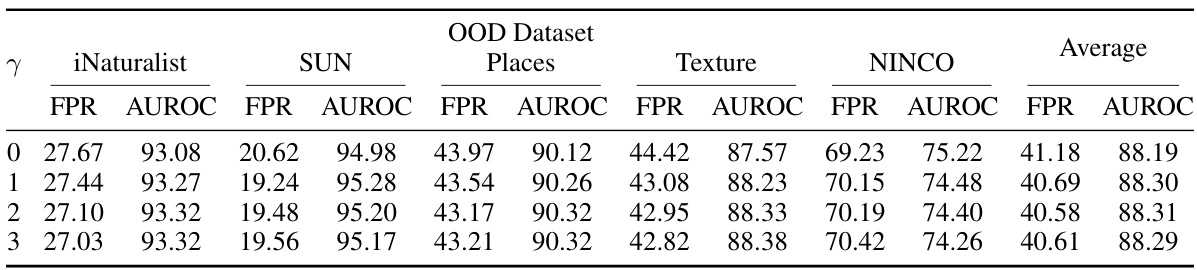
This table presents the results of an ablation study on the effect of the focal loss hyperparameter (γ) on the performance of the Hassle-Free Textual Training (HFTT) method. It shows the AUROC and FPR values for different γ values (0, 1, 2, and 3) across five different OOD datasets (iNaturalist, SUN, Places, Texture, and NINCO). The results suggest that while the performance is relatively stable across different γ values, using a focal loss (γ > 0) generally leads to better performance compared to not using it (γ = 0).

This table presents the results of an ablation study on the effect of the temperature parameter in the final Softmax layer of the proposed Hassle-Free Textual Training (HFTT) model. Different temperature values (1.0, 0.1, and 0.01) were tested on the OOD detection task using five different OOD datasets (iNaturalist, SUN, Places, Texture, and NINCO), along with the ImageNet-1k dataset as the in-distribution data. The table shows the False Positive Rate (FPR) and Area Under the ROC Curve (AUROC) for each temperature setting and dataset. The purpose is to evaluate how sensitive the model’s performance is to this hyperparameter and how it impacts the balance between in-distribution and out-distribution detection.

This table presents the results of an ablation study on the number of trainable embeddings (N) used in the Hassle-Free Textual Training (HFTT) method. It shows how the performance of HFTT in out-of-distribution (OOD) detection varies with different values of N, across five different OOD datasets and an average performance. The results demonstrate that HFTT can achieve good performance even with a small number of trainable embeddings.
Full paper#