↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Federated Graph Learning (FedGL) is vulnerable to model theft and unauthorized copying, lacking effective protection mechanisms. Existing watermarking techniques are either inapplicable to graph data or fall short in terms of performance and robustness guarantees. This work introduces FedGMark, a new approach.
FedGMark addresses these challenges using a two-module design: a Customized Watermark Generator (CWG) that leverages unique graph structures and client information, and a Robust Model Loader (RML) ensuring robustness against watermark removal attacks and layer perturbation attacks. Experiments across various datasets and models demonstrate FedGMark’s superiority in terms of accuracy, robustness, and provable guarantees, significantly improving the security and reliability of FedGL.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in federated learning and graph neural networks. It addresses the critical issue of model ownership protection in the emerging field of federated graph learning. By introducing a certifiably robust watermarking method, the research opens up new avenues for ensuring intellectual property rights and security in collaborative learning environments. Its provable robustness guarantees against various attacks offer significant advancements over existing techniques, paving the way for secure and trustworthy deployment of FedGL models. The detailed evaluation and publicly available code further contribute to the reproducibility and impact of the work.
Visual Insights#
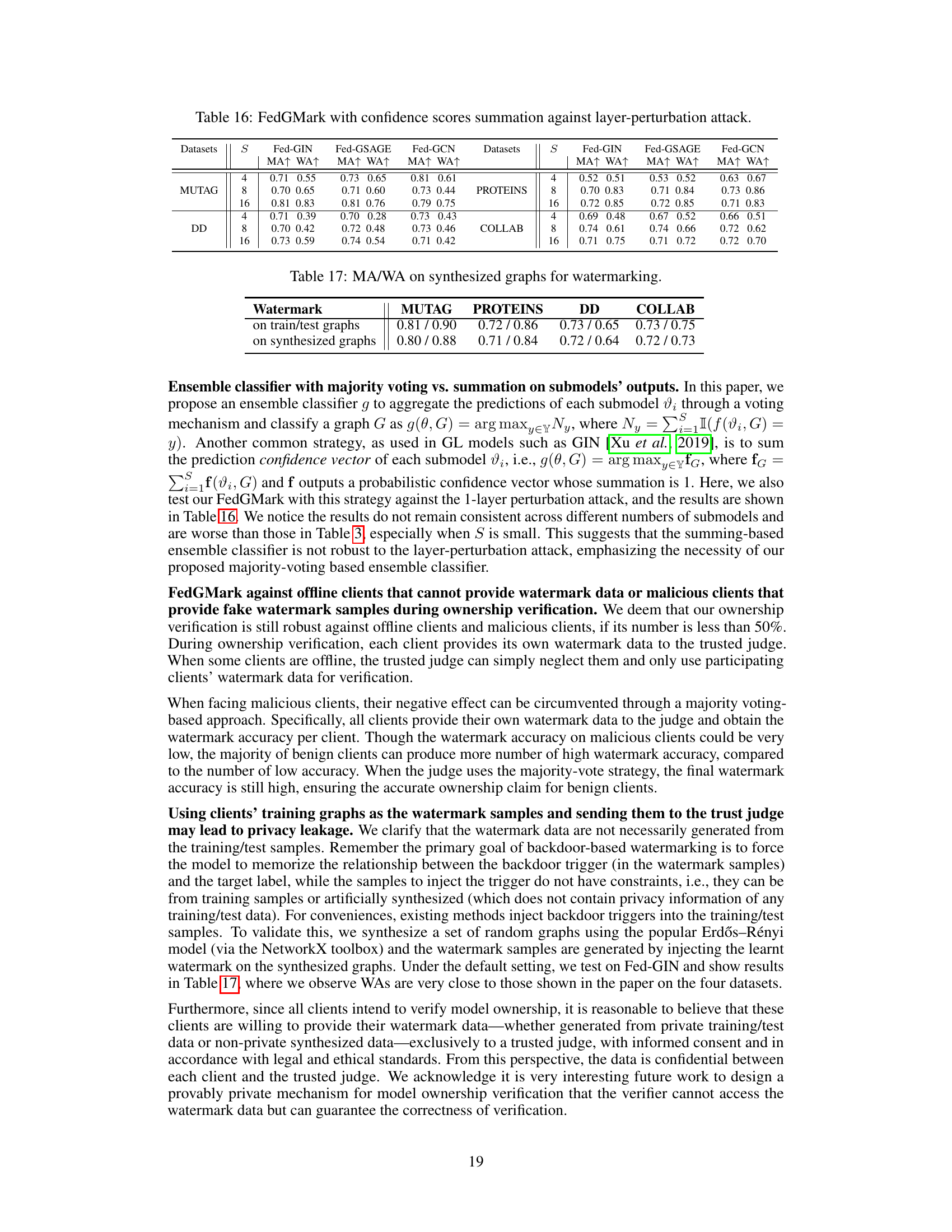
The figure illustrates the overall pipeline of the proposed certified watermarking method, FedGMark. It consists of two main modules: the Customized Watermark Generator (CWG) and the Robust Model Loader (RML). The CWG integrates edge information from client graphs and unique client key features to generate customized and diverse watermarks for individual graphs and clients. The RML utilizes a novel GL architecture with multiple submodels and a voting classifier to enhance robustness against watermark removal attacks. The pipeline showcases how watermarked graphs are generated, loaded into the robust model, and how the model provides a certified robustness guarantee.
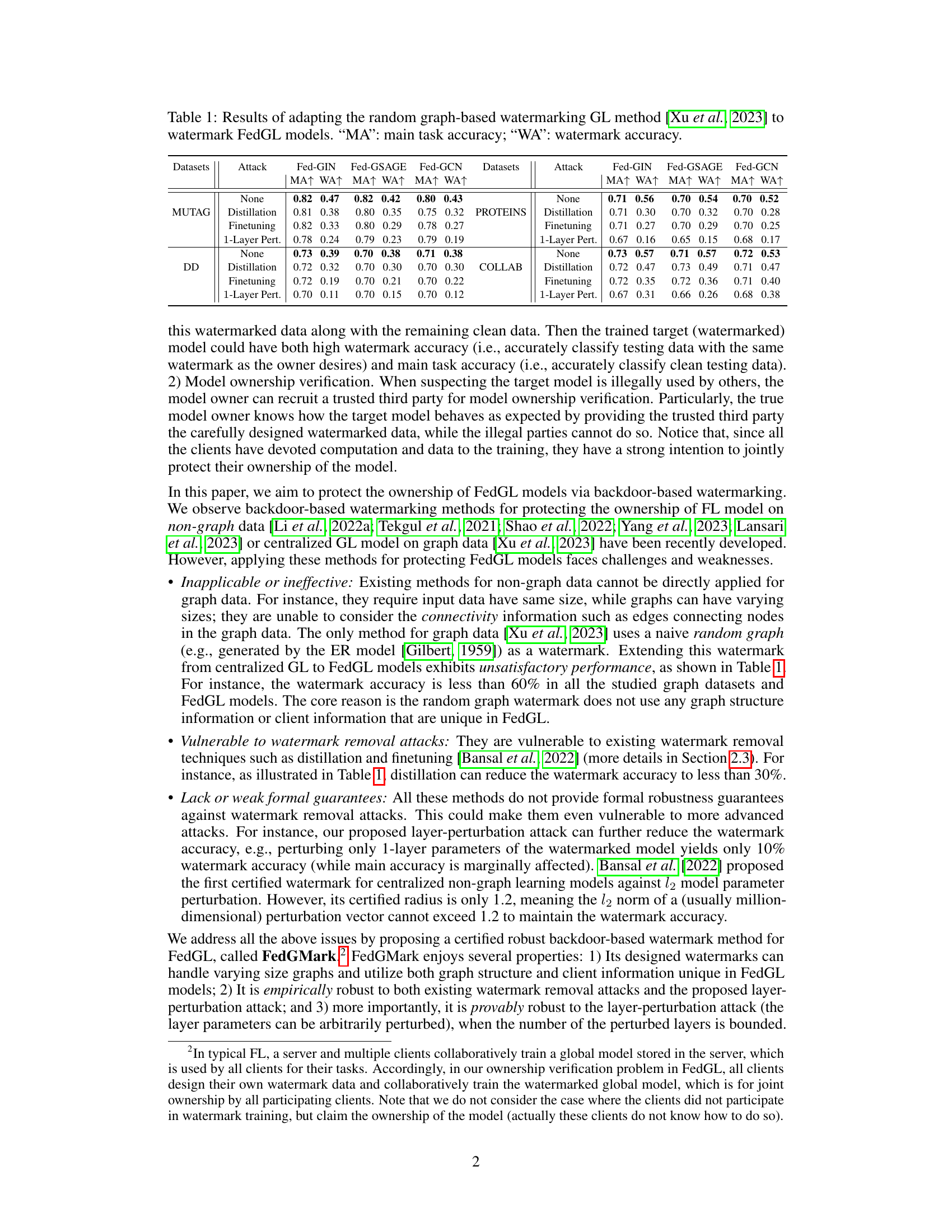
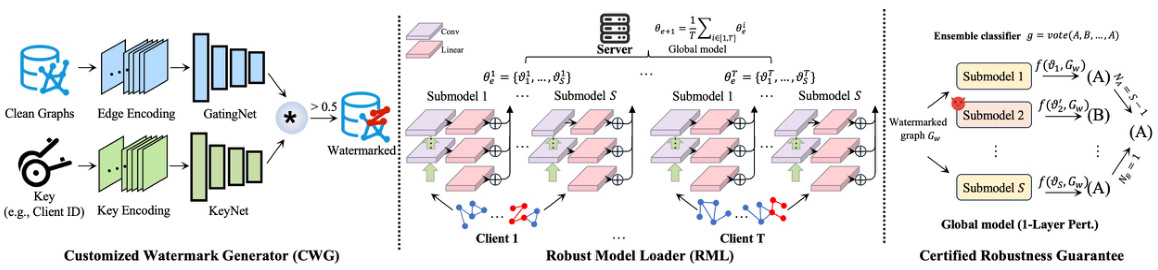
This table presents the results of applying a random graph-based watermarking method (from Xu et al., 2023) to Federated Graph Learning (FedGL) models. It shows the main task accuracy (MA) and watermark accuracy (WA) for different datasets (MUTAG, PROTEINS, DD, COLLAB) and FedGL models (Fed-GIN, Fed-GSAGE, Fed-GCN) under various attacks (None, Distillation, Finetuning, 1-Layer Perturbation). The results demonstrate the limitations of directly applying existing non-FedGL watermarking techniques to FedGL.
In-depth insights#
FedGL watermarking#
Federated graph learning (FedGL) watermarking presents a unique challenge due to the distributed nature of the data and model training. Existing watermarking techniques often fail to adapt effectively to the graph structure and the decentralized learning environment. This necessitates the development of novel methods that are robust against various attacks, including watermark removal attacks, while maintaining the utility of the watermarked model. The ideal solution should leverage the inherent properties of graph data and the federated learning process to embed robust and difficult-to-remove watermarks. Furthermore, formal guarantees of robustness are crucial to ensure the certifiability of the watermarking scheme, providing strong evidence of model ownership against malicious actors. A key area of future research is the exploration of efficient and privacy-preserving watermarking strategies for FedGL, addressing concerns about data leakage and model vulnerability during verification.
Certified robustness#
The concept of “certified robustness” in the context of watermarking for Federated Graph Learning (FGL) is a significant advancement. It moves beyond empirical demonstrations of robustness against watermark removal attacks to formal guarantees. This is crucial because traditional watermarking methods often fail under sophisticated attacks. The authors achieve this certification by employing a novel model architecture and a carefully designed watermark generation process, thus providing provable resilience. This provable robustness is a key strength, as it offers stronger protection against malicious actors seeking to steal or invalidate model ownership, increasing trust and reliability in the system. However, the practicality of achieving high certified robustness needs further investigation, especially considering the trade-off with model accuracy and computational cost. The limited scope of the certification (e.g., specific types of attacks) also warrants attention; future work should explore broader attack models and explore the robustness boundaries more comprehensively.
Layer perturbation#
Layer perturbation, as a threat model in the context of watermarking deep learning models, involves an attacker subtly modifying the model’s internal parameters. Unlike brute-force attacks, it focuses on altering specific layers to minimize impact on the model’s primary functionality while significantly reducing watermark accuracy. This targeted approach makes it a particularly potent attack vector, requiring robust watermarking techniques that can withstand such targeted manipulation. The effectiveness of the layer perturbation attack highlights the need for watermarks that are not only empirically robust but also theoretically certified against such attacks. The development of certified robust methods, which provide formal guarantees on the watermark’s resilience against specific layer perturbation attacks, is crucial for ensuring the reliability of model ownership verification. Such guarantees move beyond empirical evaluation to offer provable security, addressing a major shortcoming of previous watermarking techniques. The use of ensemble methods and model architectures designed to tolerate layer-wise perturbations is shown to improve watermark robustness and is a vital area of further research.
Watermark removal#
Watermark removal techniques pose a significant threat to the effectiveness of watermarking systems. This paper explores various attack strategies, including distillation and finetuning, which aim to remove the watermark without substantially impacting the model’s primary functionality. A novel attack, layer-perturbation, is introduced, demonstrating the capability to significantly reduce watermark accuracy by selectively modifying model parameters. The effectiveness of these attacks highlights the need for robust watermarking schemes capable of withstanding such adversarial manipulations. Formal guarantees and empirical robustness are crucial aspects in designing effective watermarking systems that can withstand the ever-evolving landscape of watermark removal techniques.
Future directions#
Future research could explore more sophisticated watermarking techniques that are robust to a wider range of attacks, including those that leverage advanced adversarial machine learning methods. Formal guarantees against these attacks, potentially leveraging concepts from differential privacy or information-theoretic security, would strengthen the reliability of ownership verification. Furthermore, investigating the impact of different federated learning training protocols on the effectiveness and robustness of FedGMark is crucial. Another area deserving attention is the development of methods for verifying the ownership of FedGL models without the need for a trusted third party. This could involve using cryptographic techniques or distributed ledger technologies. Finally, a significant challenge involves adapting FedGMark to handle various types of graph data and different graph neural network architectures. Extending its capabilities beyond the specific models studied in the paper would enhance the general applicability and practical impact of the work.
More visual insights#
More on figures
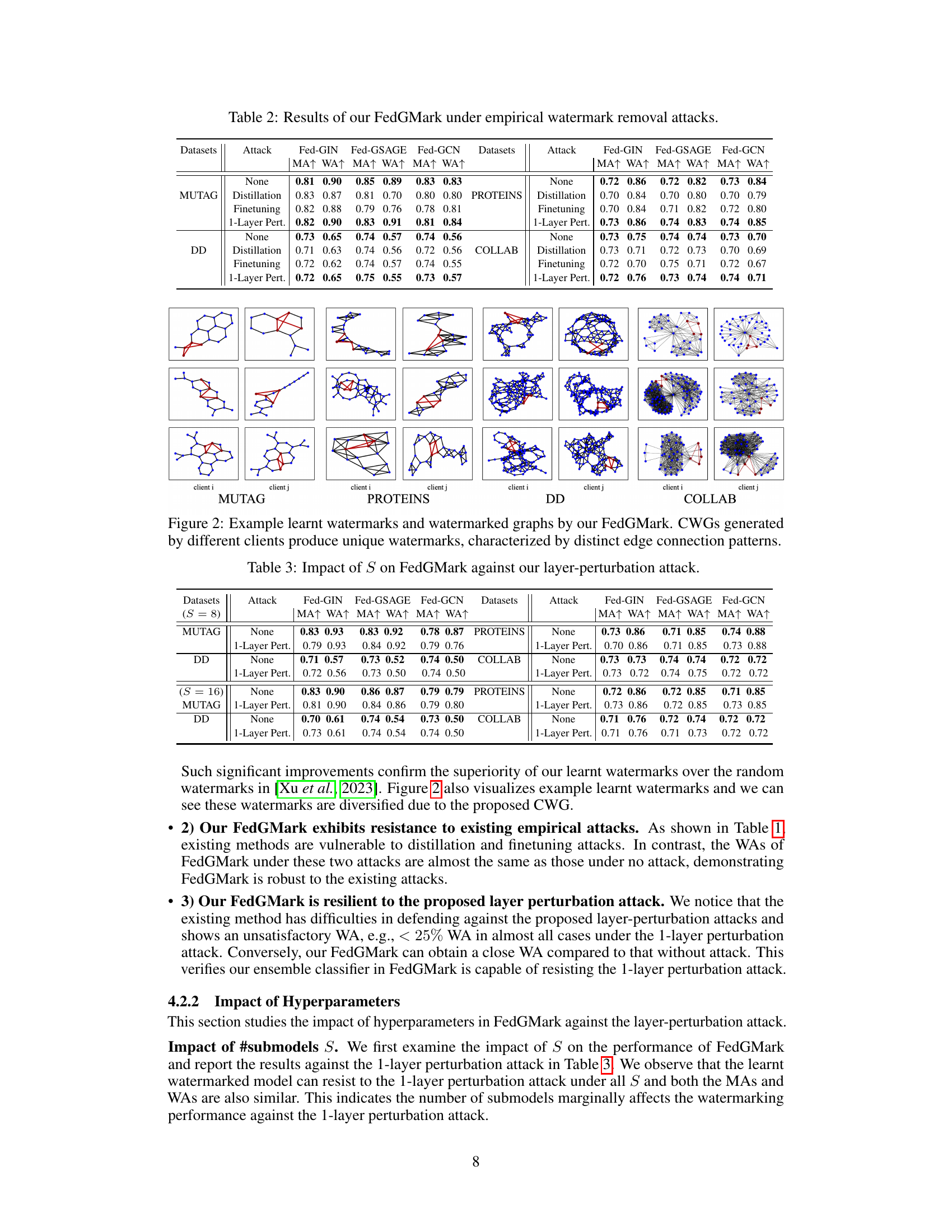
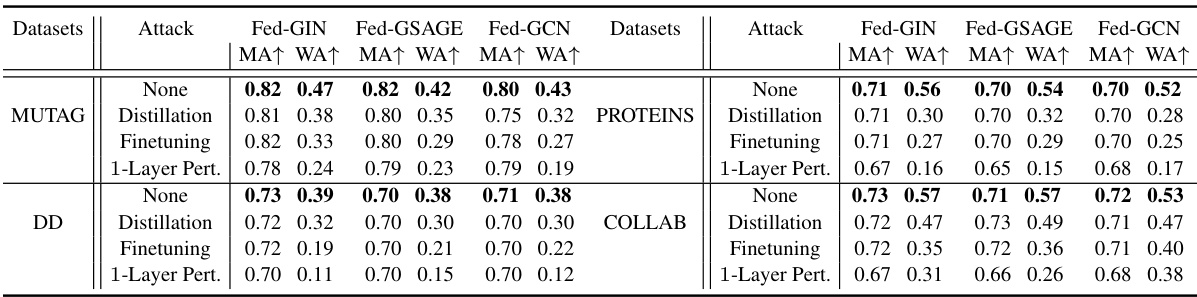
This figure shows example watermarks generated by the Customized Watermark Generator (CWG) module of FedGMark for different clients and datasets. The watermarks are visually distinct, demonstrating the diversity achieved by CWG. This diversity is a key feature enabling FedGMark’s robustness.

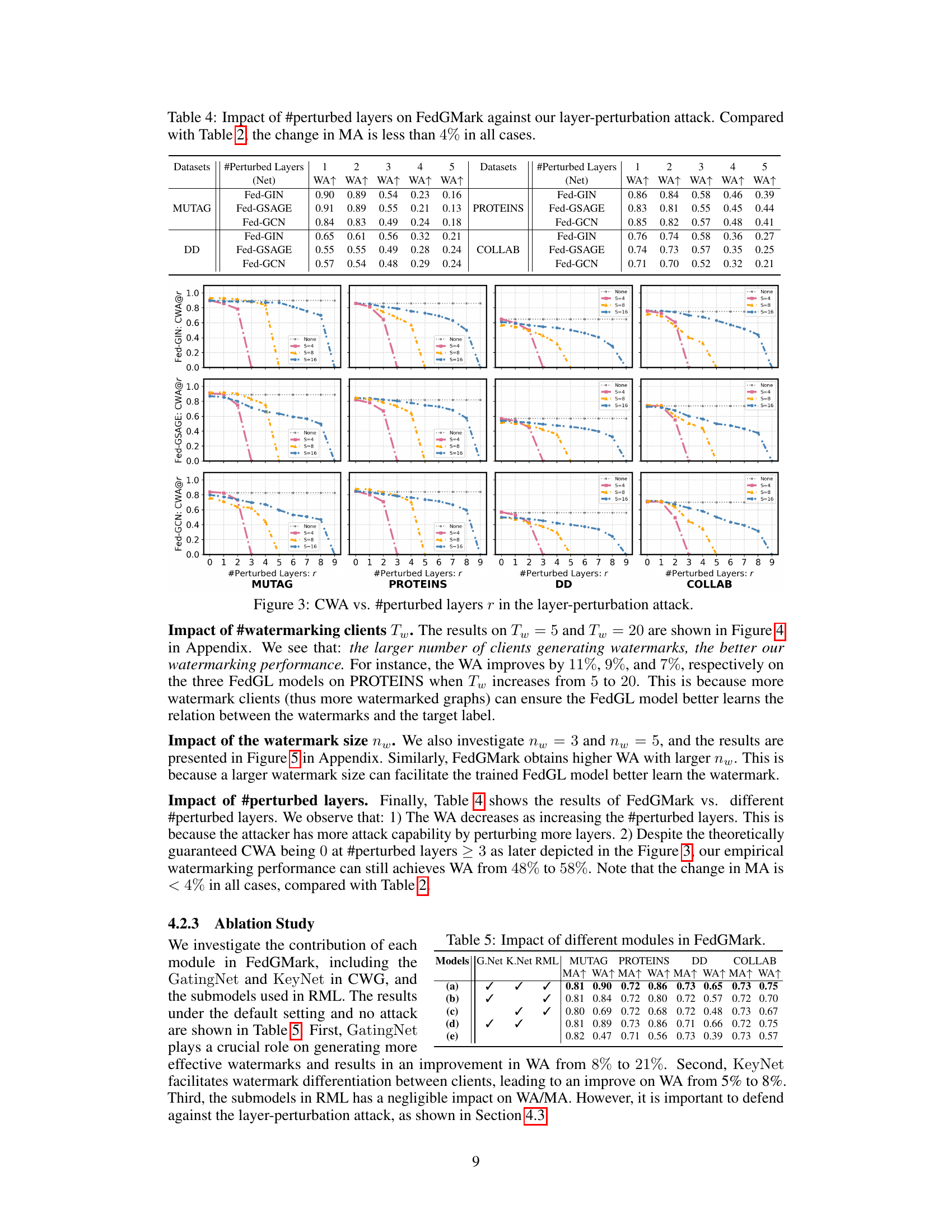
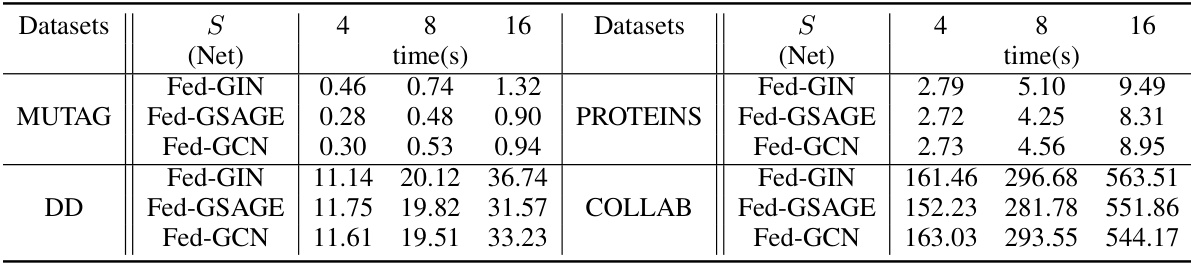
This figure shows the certified watermark accuracy (CWA) against the number of perturbed layers (r) in the layer-perturbation attack for different settings of submodels (S). It illustrates the robustness of FedGMark against this attack, showing how CWA degrades as more layers are perturbed. The plots show that with a larger number of submodels, FedGMark maintains higher CWA even with more perturbed layers, demonstrating its provable robustness.

The figure shows the results of FedGMark under different numbers of watermarking clients (Tw) against prior watermark removal attacks (distillation and finetuning) and layer perturbation attacks. It demonstrates the impact of the number of watermarking clients on the performance of FedGMark. The results indicate that a larger number of watermarking clients generally leads to better performance, particularly in terms of watermark accuracy (WA).
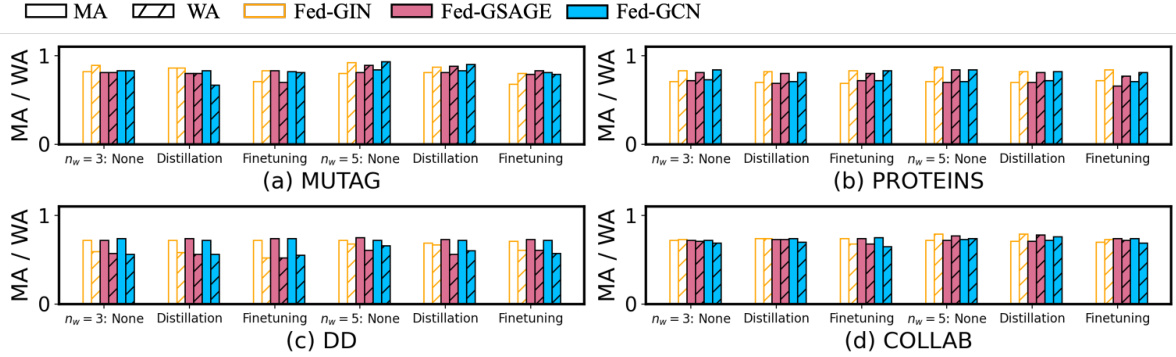
This figure shows the impact of varying the number of watermark nodes (nw) on the performance of FedGMark against different attacks including distillation, finetuning, and the proposed layer perturbation attack. The results are displayed separately for the MUTAG, PROTEINS, DD, and COLLAB datasets. It demonstrates FedGMark’s robustness to these attacks, even when the watermark size is altered.

This figure compares the watermark accuracy (WA) achieved using a global watermark versus four different local watermarks (local 1-4) across four different datasets (MUTAG, PROTEINS, DD, and COLLAB) and three different FedGL models (Fed-GIN, Fed-GSAGE, and Fed-GCN). The results show that while local watermarks are effective, a global watermark, despite not being explicitly used during training, offers slightly better performance. This suggests that the federated training process effectively aggregates the effects of the local watermarks, strengthening the overall watermarking process.
More on tables
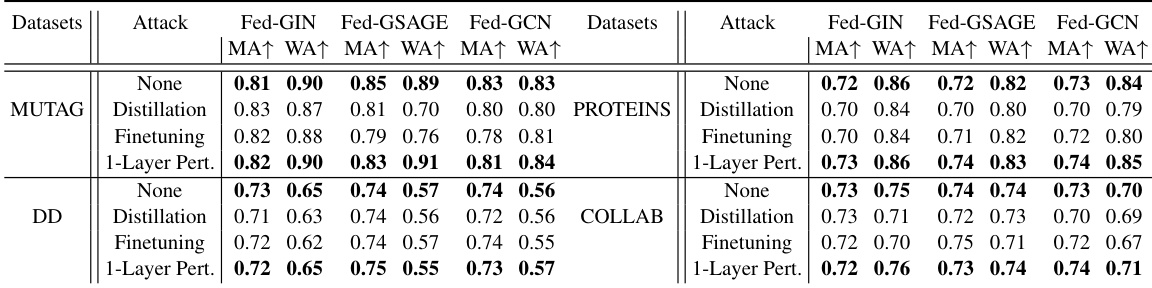
This table presents the results of the FedGMark model under three different watermark removal attacks (Distillation, Finetuning, and 1-Layer Perturbation) and compares its performance to a scenario with no attack. The results are broken down by dataset (MUTAG, PROTEINS, DD, COLLAB) and FedGL model (Fed-GIN, Fed-GSAGE, Fed-GCN). The metrics used are main task accuracy (MA) and watermark accuracy (WA). The table shows that FedGMark is highly robust against these attacks, maintaining high watermark accuracy even under the attacks. This demonstrates its effectiveness in protecting the ownership of FedGL models.

This table presents the results of the proposed FedGMark model when subjected to various watermark removal attacks. It shows the main task accuracy (MA) and watermark accuracy (WA) for three different graph neural network models (Fed-GIN, Fed-GSAGE, Fed-GCN) across four datasets (MUTAG, PROTEINS, DD, COLLAB). The attacks evaluated include distillation, finetuning, and a 1-layer perturbation attack. The table allows for a comparison of the model’s robustness under these attacks by assessing the preservation of both main task accuracy and watermark accuracy.
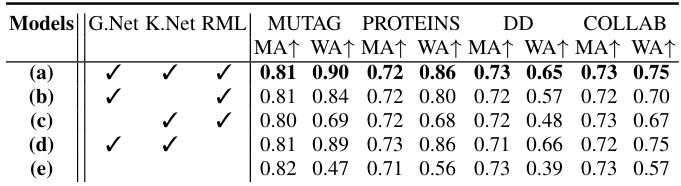
This table presents the results of applying a random graph-based watermarking method to federated graph learning (FedGL) models. It compares the main task accuracy (MA) and watermark accuracy (WA) of different FedGL models (Fed-GIN, Fed-GSAGE, Fed-GCN) on various datasets (MUTAG, PROTEINS, DD, COLLAB) under different attacks (none, distillation, finetuning, 1-layer perturbation). The results show that the existing method yields unsatisfactory performance, with watermark accuracy often less than 60%. This motivates the need for a more robust watermarking method for FedGL, which the paper proposes.

This table presents the results of applying a random graph-based watermarking method to Federated Graph Learning (FedGL) models. The original method, from Xu et al. (2023), was adapted for use in FedGL. The table shows the main task accuracy (MA) and watermark accuracy (WA) for various FedGL models (Fed-GIN, Fed-GSAGE, Fed-GCN) on different datasets (MUTAG, PROTEINS, DD, COLLAB) under different attacks (None, Distillation, Finetuning, 1-Layer Perturbation). The results highlight the performance of this adapted watermarking method and its vulnerability to watermark removal attacks.

This table presents the results of applying a random graph-based watermarking method to Federated Graph Learning (FedGL) models. It compares the main task accuracy (MA) and watermark accuracy (WA) across different datasets (MUTAG, PROTEINS, DD, COLLAB) and FedGL models (Fed-GIN, Fed-GSAGE, Fed-GCN). Different attacks (None, Distillation, Finetuning, 1-Layer Pert.) are also tested to evaluate the robustness of the watermarking method. The low watermark accuracy across all datasets and models highlights a key limitation addressed in the paper.

This table presents the results of applying a random graph-based watermarking technique from existing literature to Federated Graph Learning (FedGL) models. It compares the main task accuracy (MA) and watermark accuracy (WA) under different attack scenarios (none, distillation, finetuning, and 1-layer perturbation). The goal is to show the limitations of directly applying existing watermarking methods to FedGL, motivating the need for a more robust approach. The table demonstrates that existing methods yield unsatisfactory performance, particularly when subjected to watermark removal attacks like distillation and finetuning. This highlights the need for a new watermarking method specifically designed for FedGL.

This table presents the results of the FedGMark model under various empirical watermark removal attacks, including distillation, finetuning, and a 1-layer perturbation attack. It shows the main task accuracy (MA) and watermark accuracy (WA) for three different FedGL models (Fed-GIN, Fed-GSAGE, Fed-GCN) across four graph datasets (MUTAG, PROTEINS, DD, COLLAB). The results demonstrate the robustness of FedGMark against these attacks, maintaining high watermark accuracy even after the attacks.
This table presents the results of the FedGMark model under three different watermark removal attacks: distillation, finetuning, and a 1-layer perturbation attack. It shows the main task accuracy (MA) and watermark accuracy (WA) for the FedGMark model on four different datasets (MUTAG, PROTEINS, DD, and COLLAB) using three different FedGL models (Fed-GIN, Fed-GSAGE, and Fed-GCN). The table compares the performance of FedGMark under no attack, with the performances after each attack. This allows assessment of the model’s robustness against attempts to remove the watermark.

This table presents the results of applying a random graph-based watermarking method (from Xu et al., 2023) to Federated Graph Learning (FedGL) models. It evaluates the main task accuracy (MA) and watermark accuracy (WA) across various datasets (MUTAG, PROTEINS, DD, COLLAB) and FedGL models (Fed-GIN, Fed-GSAGE, Fed-GCN) under different attacks (None, Distillation, Finetuning, 1-Layer Perturbation). The table shows that this adaptation yields unsatisfactory watermark accuracy (mostly less than 60%), highlighting the need for more sophisticated techniques.

This table compares the performance of the FedGMark model on two types of datasets: IID (independently and identically distributed) and Non-IID (non-independently and identically distributed). The IID datasets assume that data across different clients is similar, while the Non-IID datasets have varying data distributions among clients which is more common in real world scenarios. The results are shown in terms of Main task accuracy (MA) and Watermark accuracy (WA). These results demonstrate the robustness and effectiveness of FedGMark in handling non-IID data, a key challenge in federated learning.

This table presents the results of the FedGMark model’s performance against malicious clients. The experiment simulates scenarios with varying percentages (0%, 10%, 20%, 30%, and 40%) of malicious clients whose watermarked data has been mislabeled. The table shows the Main task Accuracy (MA) and Watermark Accuracy (WA) achieved in each scenario across four different datasets (MUTAG, PROTEIN, DD, and COLLAB). This demonstrates the model’s robustness to different levels of malicious attacks.

This table presents the results of the FedGMark method under different empirical watermark removal attacks (distillation, finetuning, and 1-layer perturbation). For each of the four datasets (MUTAG, PROTEINS, DD, and COLLAB) and three FedGL models (Fed-GIN, Fed-GSAGE, and Fed-GCN), the table shows the main task accuracy (MA) and watermark accuracy (WA) under each attack. The results demonstrate the robustness of FedGMark against these attacks, with WAs remaining high even after the attacks are applied.

This table presents the results of the FedGMark model under three different watermark removal attacks: distillation, finetuning, and a 1-layer perturbation attack. It compares the Main task accuracy (MA) and Watermark accuracy (WA) across four different graph datasets (MUTAG, PROTEINS, DD, COLLAB) and three different Federated Graph Learning (FedGL) models (Fed-GIN, Fed-GSAGE, Fed-GCN). The ‘None’ row shows the performance without any attack.

This table presents the Main task accuracy (MA) and Watermark accuracy (WA) achieved by FedGMark on synthesized graphs used for watermarking. The results are shown for four different datasets: MUTAG, PROTEINS, DD, and COLLAB. The table compares the performance on graphs used in training/testing with those on newly synthesized graphs, providing insights into the model’s generalizability and robustness.
Full paper#