↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
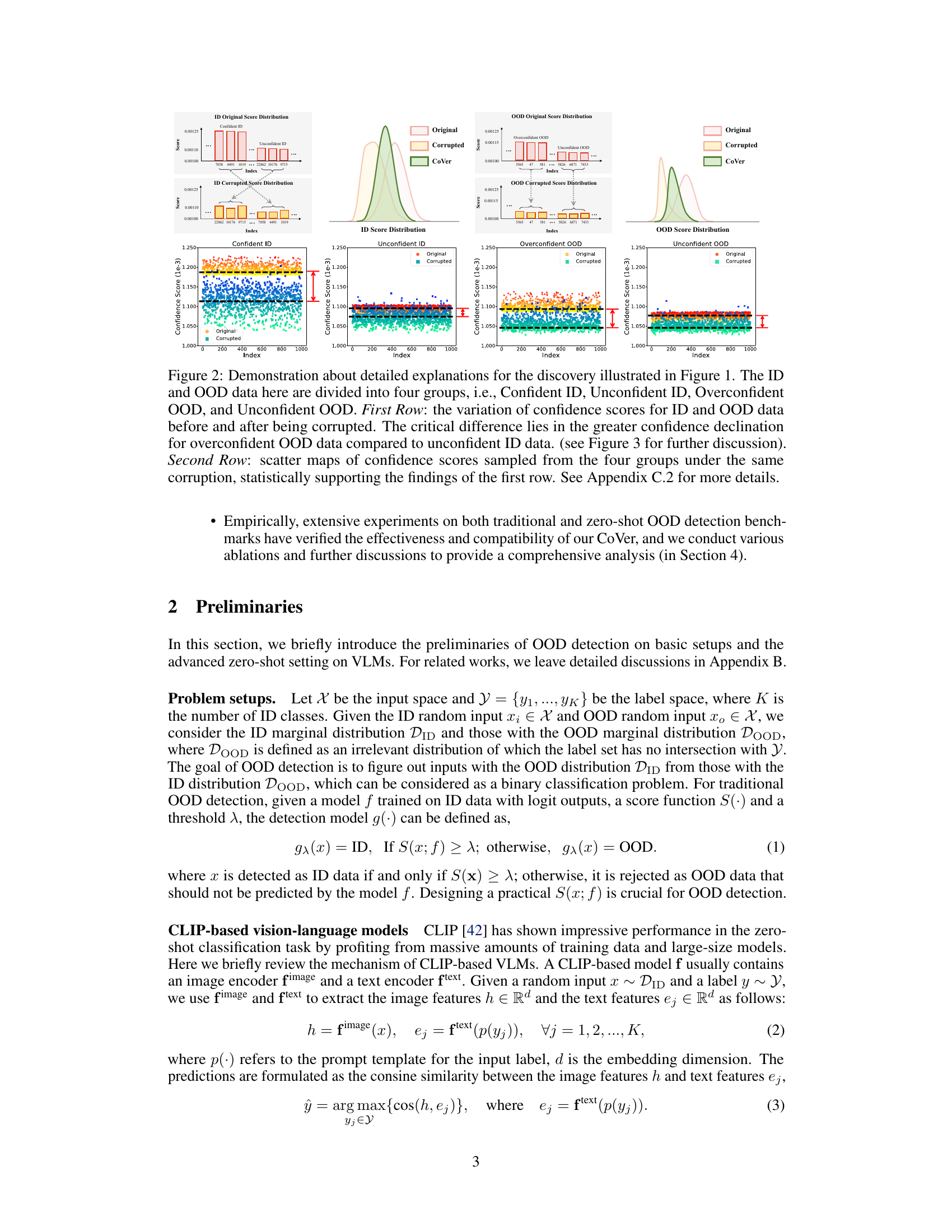
Current out-of-distribution (OOD) detection methods struggle with distinguishing subtle differences between in-distribution (ID) and OOD data because they rely on analyzing a single input, limiting their representation capacity. This can lead to misclassifications, especially with overconfident OOD samples. This paper reveals a phenomenon called ‘confidence mutation’, where OOD data confidence significantly decreases under common image corruptions, while ID data remains relatively stable. This is because of their semantic difference.
To address this, the researchers propose a new method called CoVer (Confidence Average). CoVer cleverly expands input representation by incorporating both original and corrupted inputs. By averaging the model’s confidence scores from these multiple inputs, CoVer enhances the separability of ID and OOD distributions, leading to improved detection accuracy. Extensive experiments show that CoVer significantly outperforms existing methods across various benchmark datasets and is highly compatible with different network architectures.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses a critical challenge in reliable machine learning: out-of-distribution (OOD) detection. By introducing a novel approach that expands input representation using common corruptions, it offers a significant improvement over existing methods that rely on single input analysis. This work opens new avenues for research in robust AI, particularly in safety-critical applications and opens up new avenues in the field of OOD detection and potentially adversarial robustness.
Visual Insights#
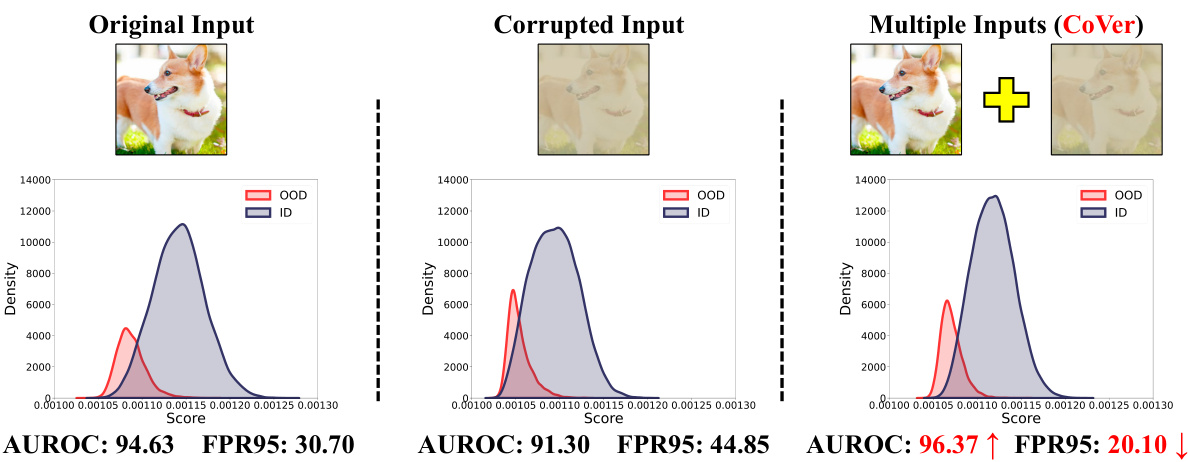
This figure compares the score distributions and detection results using different input methods. The left panel shows the results with a single original input, the middle panel shows the results with a single corrupted input (performing worse but with mutated scores for some OOD samples), and the right panel shows the results with multiple inputs using the proposed CoVer method (achieving variance reduction for the in-distribution data and better separability between in-distribution and out-of-distribution data).
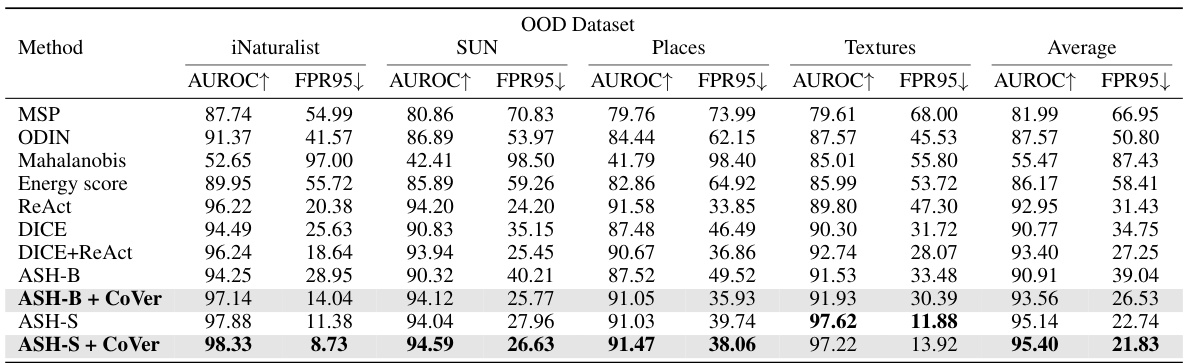
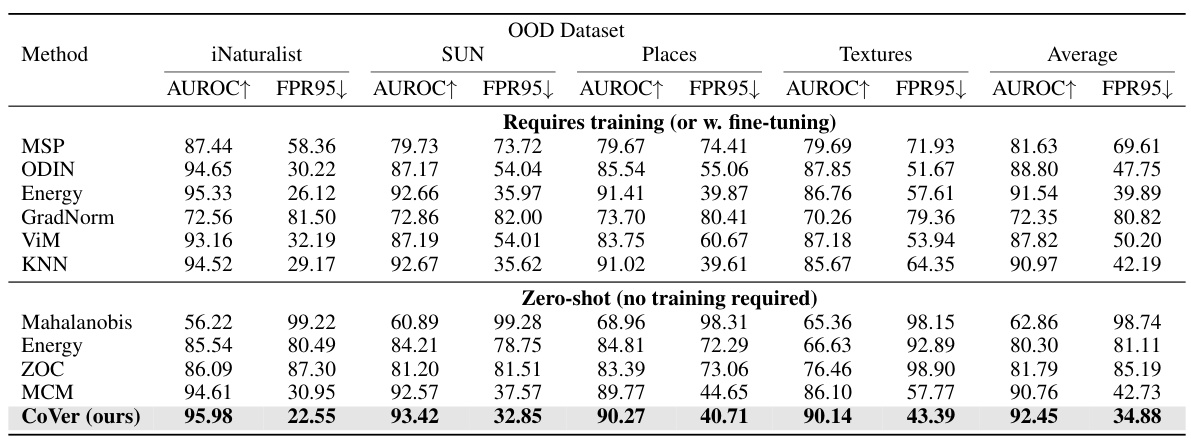
This table presents a comparison of the proposed CoVer method with several existing OOD detection methods. The comparison uses the ResNet-50 architecture and ImageNet-1K as the in-distribution (ID) dataset. The performance is measured using AUROC (Area Under the Receiver Operating Characteristic curve) and FPR95 (False Positive Rate at 95% true positive rate). Higher AUROC and lower FPR95 indicate better performance. The table shows results across four different out-of-distribution (OOD) datasets.
In-depth insights#
Expanded Input OOD#
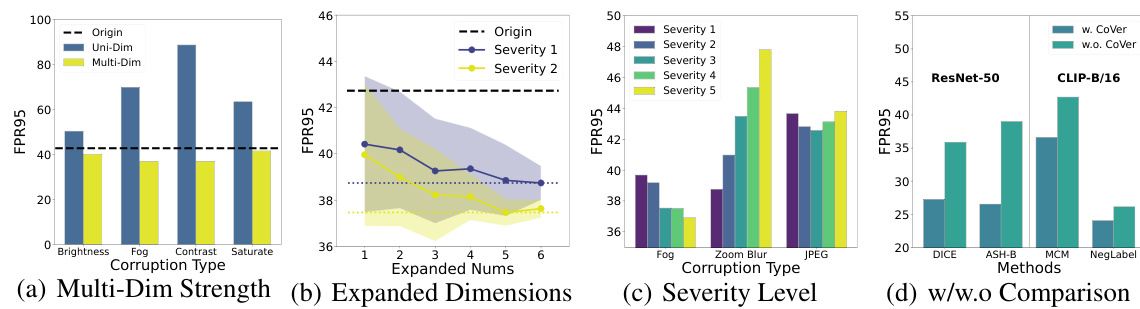
The concept of “Expanded Input OOD” introduces a novel approach to out-of-distribution (OOD) detection by augmenting the input data with various transformations or corruptions before feeding it to the model. This method expands the representation dimension of the input, allowing the model to capture more nuanced information for distinguishing between in-distribution (ID) and OOD samples. The core idea is that OOD samples might exhibit sensitivity to these corruptions and change their confidence score differently than ID samples. This confidence mutation phenomenon, combined with the average confidence across multiple input versions, is the key to improved separability between ID and OOD data. The method demonstrates the effectiveness of input-level augmentation for enhancing OOD detection performance, especially in scenarios where traditional methods relying solely on a single input struggle. While computationally more expensive, the results suggest this trade-off is worth considering for improved robustness in real-world applications where the reliability of OOD detection is crucial.
Confidence Mutation#
The concept of “Confidence Mutation” offers a novel perspective on Out-of-Distribution (OOD) detection. It posits that applying common corruptions to input data causes a disproportionate decrease in model confidence for OOD samples compared to in-distribution (ID) samples. This phenomenon, confidence mutation, is crucial because it highlights the differing resilience of ID and OOD data to perturbations. While single corrupted inputs might not effectively separate ID and OOD data, the averaging of confidence scores across multiple corrupted and original inputs significantly enhances the discriminative power, leading to improved OOD detection. The underlying mechanism suggests that ID data, possessing inherent semantic consistency, retains high confidence even with corruptions, while OOD data’s confidence is more dramatically affected by the removal of non-semantic features. This dynamic, captured by the CoVer method, offers a powerful new way to leverage inherent differences between ID and OOD data for robust OOD detection.
CoVer Framework#
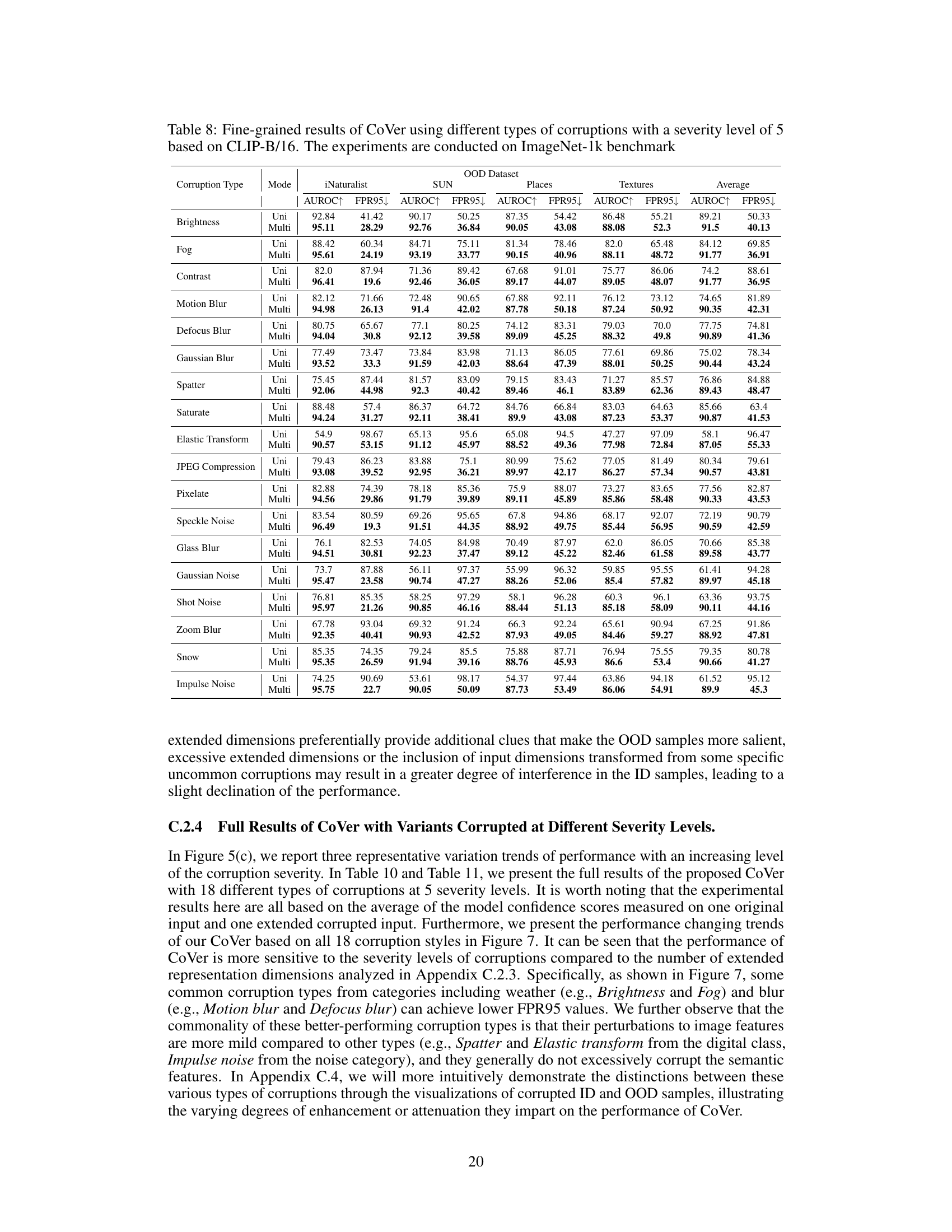
The CoVer framework introduces a novel approach to out-of-distribution (OOD) detection by expanding the input representation dimension. Instead of relying solely on a single input, CoVer leverages multiple inputs created by applying common corruptions to the original input. This strategy reveals a phenomenon called “confidence mutation,” where OOD data exhibit significantly decreased confidence under corruptions, while in-distribution (ID) data maintain higher confidence due to their robust semantic features. CoVer’s innovative approach improves the separability of ID and OOD distributions, leading to more accurate OOD detection. By averaging the confidence scores from the original and corrupted inputs, CoVer effectively captures the dynamic differences and enhances model robustness. The framework’s simplicity and compatibility with various networks, including both single-modal and multi-modal models, make it a significant contribution to the field. Its effectiveness is validated by extensive experiments on multiple benchmarks, demonstrating superior performance compared to existing methods. The study also explores the impact of different corruption types and levels, offering valuable insights for practical implementation.
Zero-Shot OOD#
Zero-shot out-of-distribution (OOD) detection tackles a crucial challenge in deploying machine learning models in real-world scenarios. Traditional OOD methods typically require retraining or fine-tuning on OOD examples, which is often infeasible or impractical. Zero-shot OOD detection, in contrast, leverages pre-trained models, often vision-language models like CLIP, without any further training on OOD data. This significantly reduces the time and resources needed for adaptation, making it more suitable for dynamic environments where new OOD data continuously emerge. However, zero-shot OOD detection presents its own set of difficulties. The effectiveness relies heavily on the quality and representational capacity of the pre-trained model, and there’s a risk of overconfidence or misclassification, particularly when dealing with highly dissimilar OOD examples. Therefore, designing robust scoring functions that effectively capture the discriminative features between ID and OOD data within a zero-shot setting remains a key research focus. Future advancements might explore innovative ways to integrate prior knowledge about OOD distributions or employ more sophisticated representation learning techniques to enhance the performance of zero-shot OOD methods.
Future of CoVer#
The future of CoVer, a novel OOD detection framework, looks promising. Expanding its applicability to diverse data modalities beyond images and text is a key area for future exploration, leveraging the inherent strength of CoVer’s input-side design. Investigating the effectiveness of CoVer in combination with other advanced OOD detection methods, particularly those employing newer architectures and techniques, could yield substantial performance improvements. Furthermore, a deeper theoretical understanding of confidence mutation and its relationship to different corruption strategies, through formal analysis and empirical studies, will enhance CoVer’s robustness and reliability. Finally, developing efficient implementations and optimizing CoVer’s computational costs is crucial for real-world deployments, particularly in resource-constrained environments. Addressing these areas will establish CoVer as a leading method in the field.
More visual insights#
More on figures
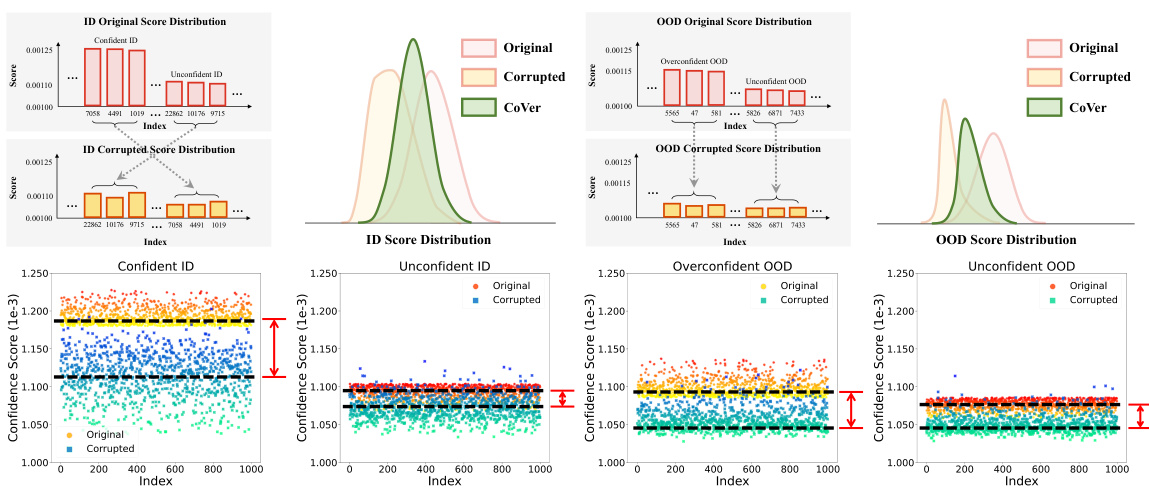
This figure compares the score distributions obtained using three different input methods: a single original input, a single corrupted input, and multiple inputs (CoVer). The left panel shows that using the single original input produces overlapping distributions of in-distribution (ID) and out-of-distribution (OOD) data, making accurate classification difficult. The middle panel shows that while a single corrupted input reduces the model’s confidence, it doesn’t significantly improve the separation. The right panel demonstrates the effectiveness of CoVer by showing that utilizing multiple inputs (the original and its corrupted versions) significantly reduces the variance of the ID distribution and leads to a far better separation of ID and OOD data, resulting in improved detection performance. The improvement is quantified using AUROC (Area Under the Receiver Operating Characteristic curve) and FPR95 (False Positive Rate at 95% True Positive Rate).
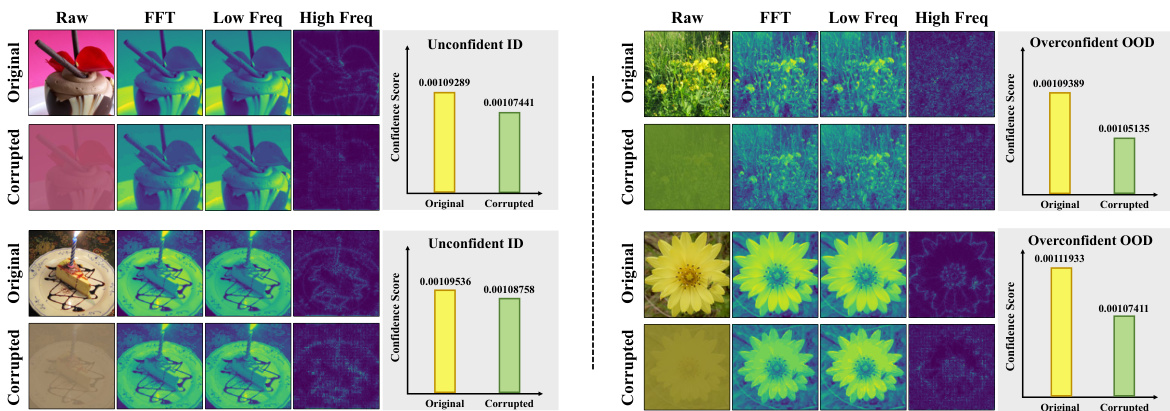
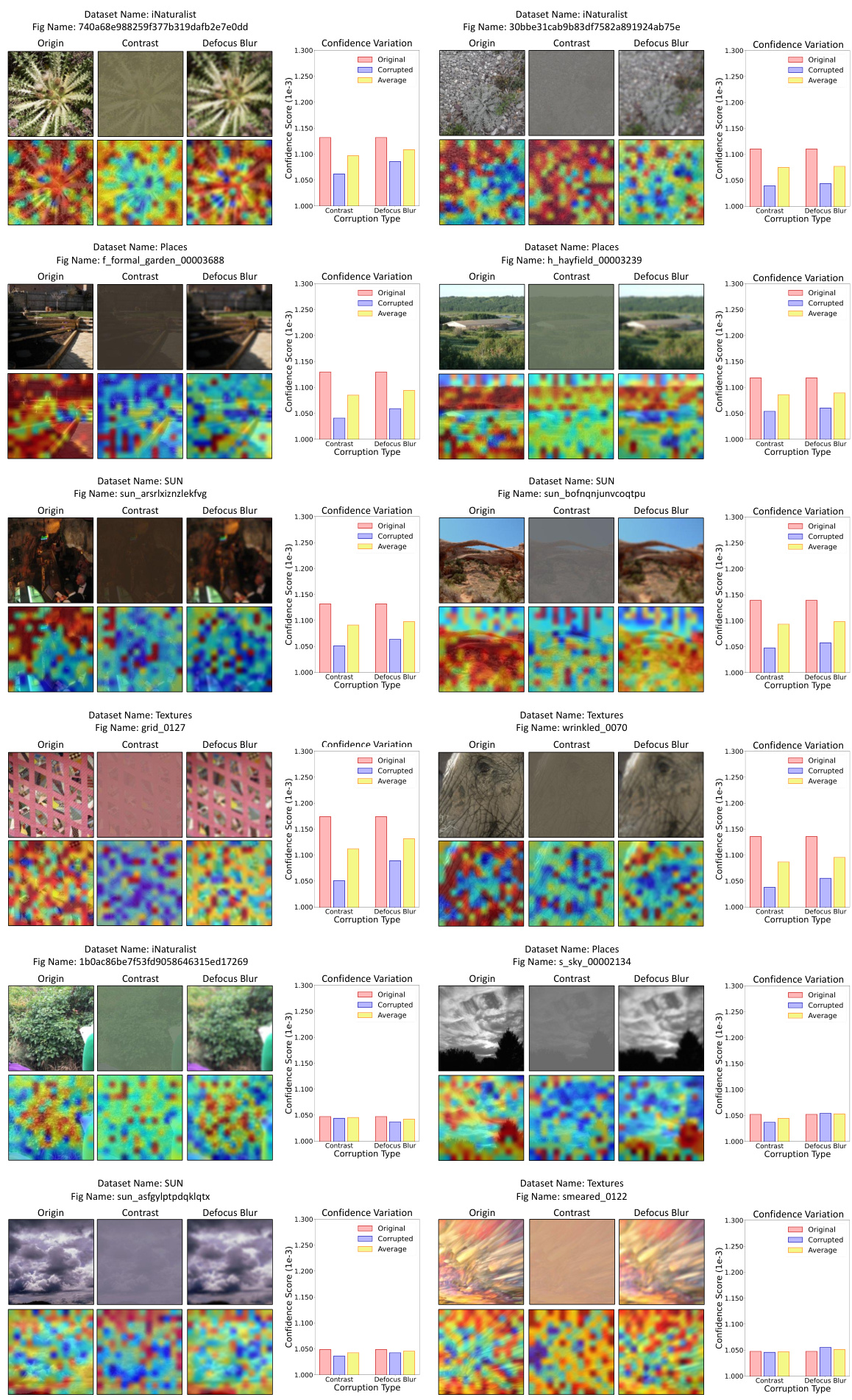
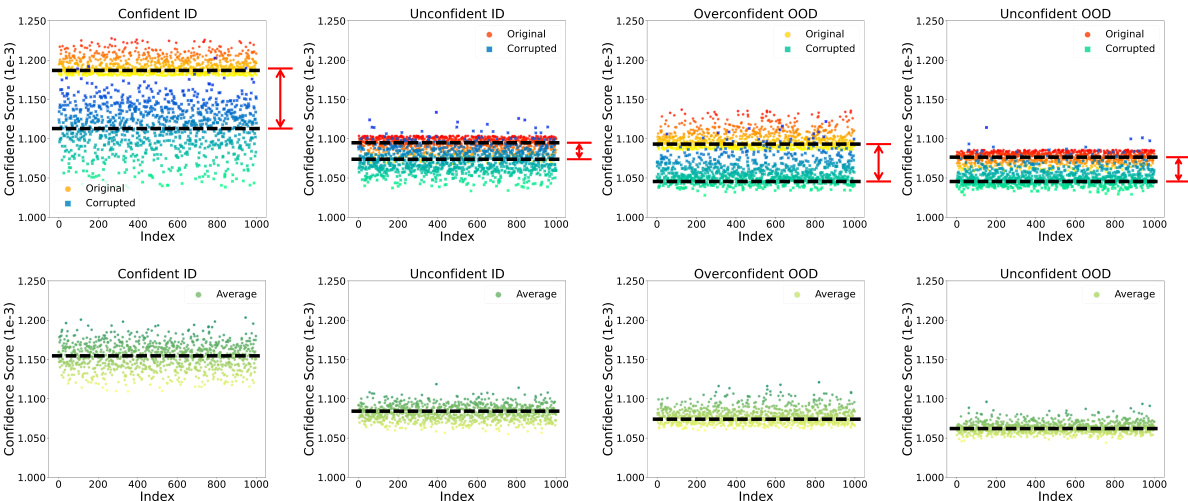
This figure visually explores the concept of ‘confidence mutation’ introduced in the paper. It compares the confidence scores of in-distribution (ID) and out-of-distribution (OOD) samples before and after applying common corruptions to the input images. The left panel focuses on unconfident ID samples, showing that their low-frequency features (semantic features) are robust to corruptions, and the confidence does not change much. In contrast, the right panel demonstrates how the confidence scores of overconfident OOD samples decrease significantly after applying corruptions, highlighting the vulnerability of their non-semantic high-frequency features.

This figure illustrates the architecture of the proposed Confidence Average (CoVer) method for out-of-distribution (OOD) detection. It shows how multiple corrupted versions of an input image are processed by a pre-trained model (single or multi-modal). Different scoring functions are applied to the model outputs, and these scores are then averaged to produce the final CoVer score, improving the separation between in-distribution and out-of-distribution data.
This figure compares the score distributions obtained from three different input methods: using a single original image, a single corrupted image, and multiple images (CoVer). The left panel shows the original input’s distribution, demonstrating some overlap between in-distribution (ID) and out-of-distribution (OOD) data. The middle panel shows that using a single corrupted image reduces overall confidence, but interestingly, the confidence of some OOD samples changes more drastically than those of ID samples. Finally, the right panel illustrates how CoVer, by averaging scores across multiple (original and corrupted) inputs, significantly reduces the variance in the ID data and improves the separation between ID and OOD data. This improvement suggests that expanding the input representation dimension helps improve the accuracy of OOD detection.
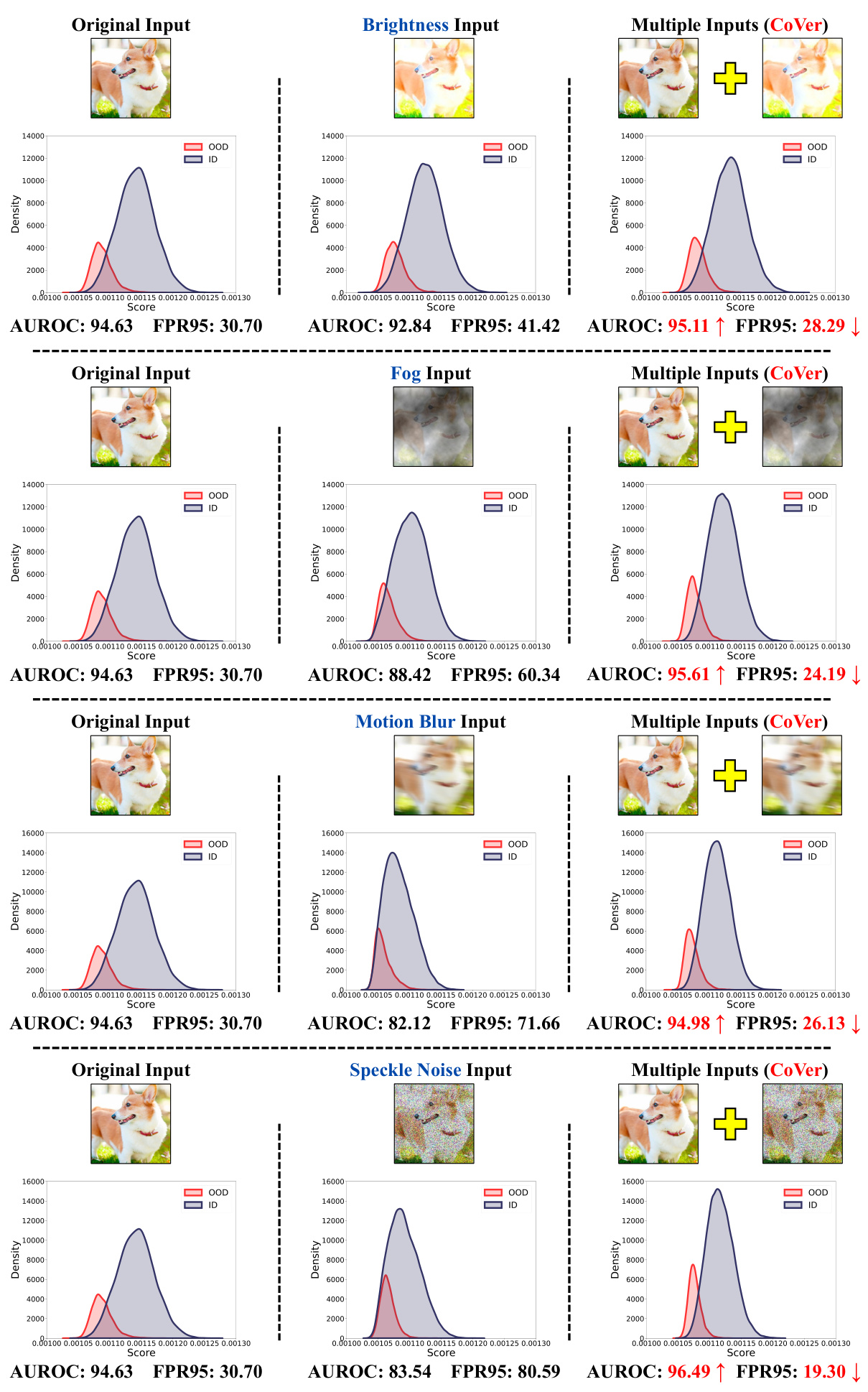
This figure compares the score distributions and detection results obtained using three different input methods: a single original input, a single corrupted input, and multiple inputs (CoVer). The left panel shows the score distribution for a single original input, demonstrating some overlap between in-distribution (ID) and out-of-distribution (OOD) samples. The middle panel shows that using a single corrupted input results in a wider overlap, but also showcases a phenomenon called ‘confidence mutation’, where the confidence score of some OOD samples decreases. The right panel shows that using multiple inputs (CoVer) improves the separability between ID and OOD samples by reducing the variance in the ID distribution and increasing the separation between the two distributions.

This figure compares the score distributions of in-distribution (ID) and out-of-distribution (OOD) data under three different input scenarios: single original input, single corrupted input, and multiple inputs using the proposed CoVer method. The left panel shows that using a single original input results in overlapping ID and OOD distributions. The middle panel demonstrates that using a single corrupted input worsens the performance, but it also induces a phenomenon called ‘confidence mutation’, where the confidence of OOD data decreases more significantly than the confidence of ID data. The right panel showcases that using multiple inputs (CoVer) effectively separates the ID and OOD distributions, improving the overall detection accuracy.

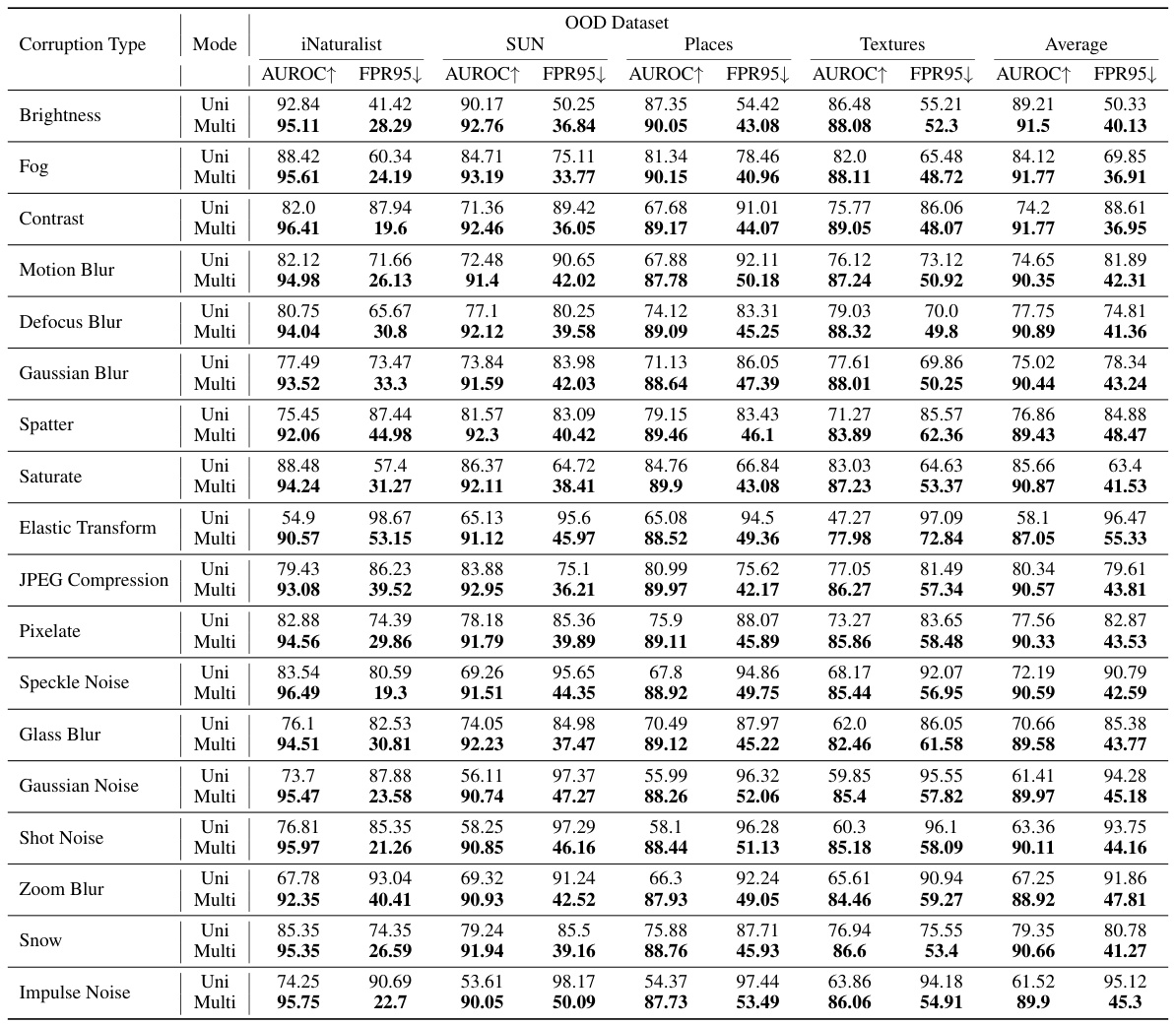
This figure visualizes the effect of 18 different corruption types on a single image. Each corruption type is shown at severity level 1-5 (from minor to major corruption). The figure demonstrates how each corruption transforms the original image, highlighting the diversity of corruptions used in the paper’s experiments.

This figure shows example images corrupted by different corruption types and severity levels. The purpose is to illustrate the range of image transformations used to augment the input data for the Confidence Average (CoVer) method. The different levels of corruption affect the image differently, and these augmentations are a key part of CoVer’s ability to improve the separation between in-distribution (ID) and out-of-distribution (OOD) data.

This figure compares the score distributions for in-distribution (ID) and out-of-distribution (OOD) data under three different input scenarios. The left panel shows results using a single original input image. The middle panel uses a single corrupted input, showing decreased performance but also a phenomenon called ‘confidence mutation’ where the confidence of some OOD samples changes. The right panel uses multiple inputs (the CoVer method), which reduces variance in ID scores and improves separation between ID and OOD distributions, leading to better OOD detection.
This figure compares the score distributions for in-distribution (ID) and out-of-distribution (OOD) data under three different input scenarios: a single original input, a single corrupted input, and multiple inputs (using the proposed CoVer method). The left panel shows the score distribution using the original input, illustrating some overlap between ID and OOD. The middle panel shows the results when using a single corrupted input. While overall performance decreases, the confidence scores for some OOD samples are significantly altered (confidence mutation). The right panel demonstrates the CoVer method, which uses multiple inputs (original and corrupted) to average scores, resulting in reduced variance for the ID data and improved separation between the ID and OOD distributions.
This figure compares the score distributions obtained from three different input methods: a single original input, a single corrupted input, and multiple inputs using the proposed CoVer method. The left panel shows the distribution for a single original input, illustrating overlap between in-distribution (ID) and out-of-distribution (OOD) samples. The middle panel shows the distribution for a single corrupted input, demonstrating that while performance decreases, some OOD samples exhibit a change in confidence scores (‘confidence mutation’). The right panel presents the distribution using CoVer, showing improved separation between ID and OOD data due to variance reduction in the ID distribution and better separability between the two distributions.
More on tables
This table presents a comparison of the proposed CoVer method with various existing OOD detection methods on the ImageNet-1K dataset using ResNet-50 as the backbone. The results are evaluated using two metrics: AUROC (Area Under the Receiver Operating Characteristic Curve) and FPR95 (False Positive Rate at 95% True Positive Rate). Higher AUROC and lower FPR95 values indicate better performance. The table shows that CoVer, particularly when combined with other methods (ASH-B and ASH-S), achieves superior performance to other state-of-the-art methods.
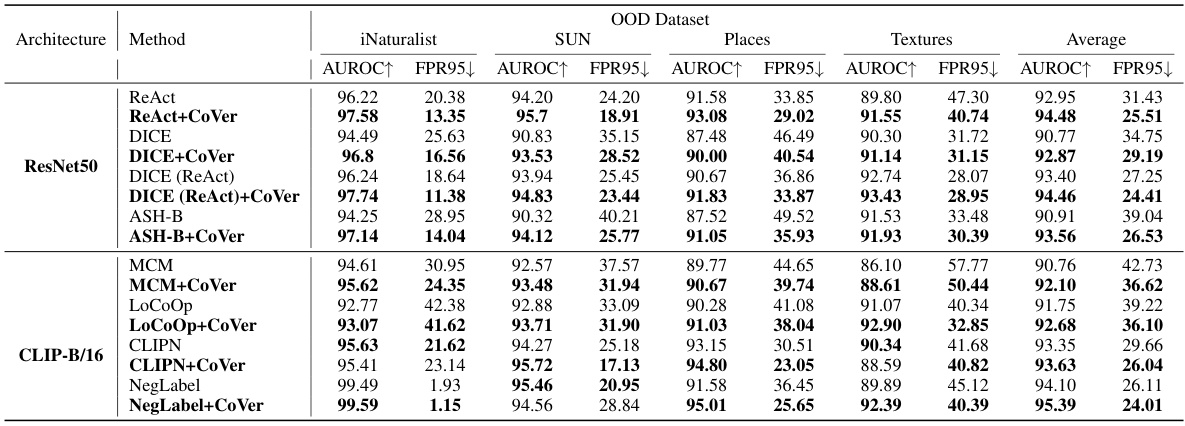
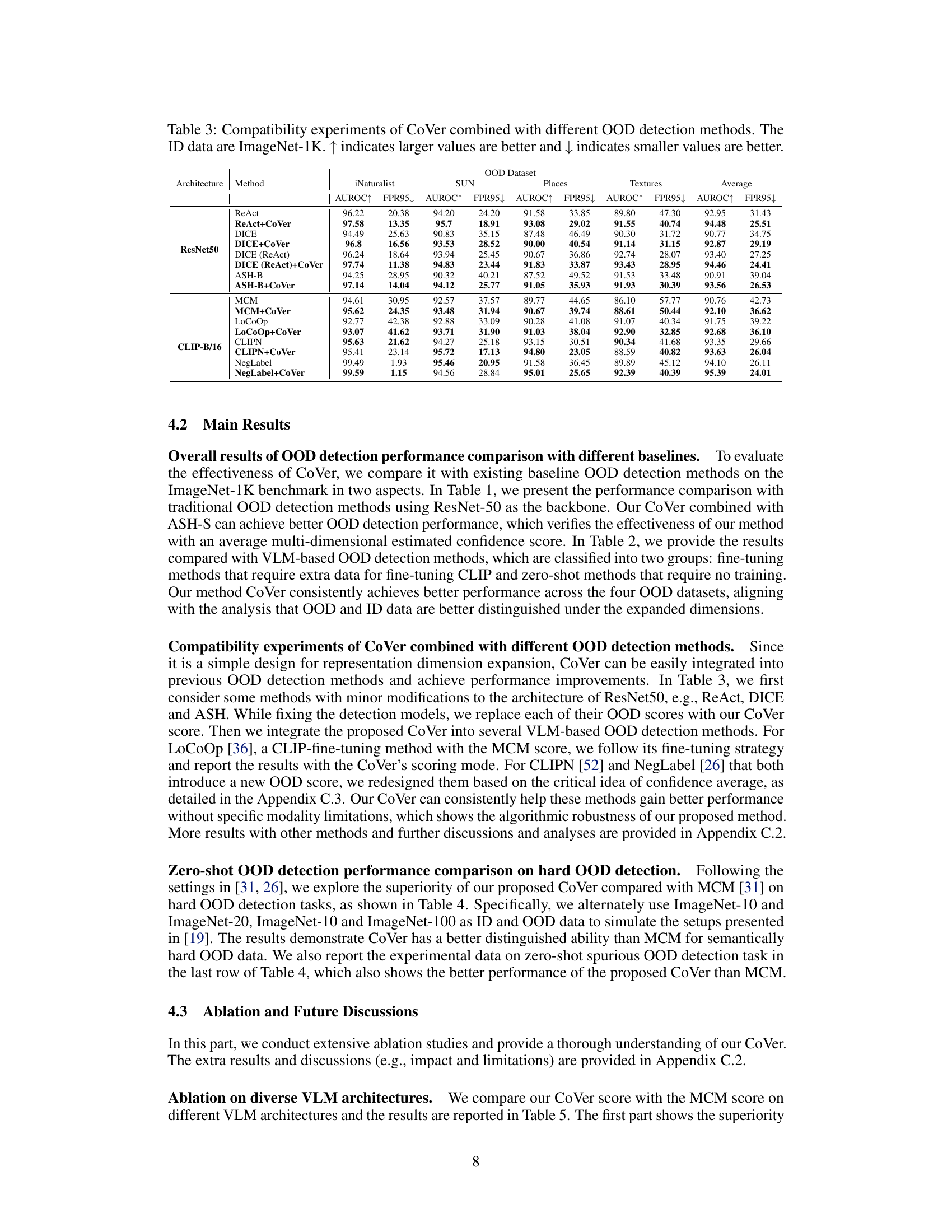
This table presents the results of combining the proposed CoVer method with various other OOD detection methods. It shows that CoVer can be integrated with other existing techniques to improve performance. The results are broken down by OOD dataset (iNaturalist, SUN, Places, Textures) and metric (AUROC and FPR95). The table demonstrates that CoVer enhances the performance of these other OOD detection methods.

This table presents the results of zero-shot out-of-distribution (OOD) detection experiments on challenging datasets. The ‘ID Dataset’ and ‘OOD Dataset’ columns specify the in-distribution and out-of-distribution datasets used for each experiment. The ‘Method’ column indicates whether the MCM or CoVer method was used. The AUROC (Area Under the Receiver Operating Characteristic curve) and FPR95 (False Positive Rate at 95% True Positive Rate) metrics evaluate the performance of each method. Higher AUROC values and lower FPR95 values indicate better performance.

This table presents the results of zero-shot out-of-distribution (OOD) detection experiments using different vision-language model (VLM) architectures. The models were all based on CLIP-B/16. The table shows the Area Under the Receiver Operating Characteristic curve (AUROC) and the False Positive Rate at 95% True Positive Rate (FPR95) for different combinations of in-distribution (ID) and out-of-distribution (OOD) datasets. Higher AUROC values and lower FPR95 values indicate better performance.

This table compares the performance of the proposed CoVer method with several other state-of-the-art OOD detection methods. The comparison is based on the ResNet-50 architecture and uses the ImageNet-1K dataset as the in-distribution (ID) data. Four different out-of-distribution (OOD) datasets are used for evaluation: iNaturalist, SUN, Places, and Textures. The performance metrics used are AUROC (Area Under the Receiver Operating Characteristic curve) and FPR95 (False Positive Rate at 95% True Positive Rate). Higher AUROC values and lower FPR95 values indicate better performance.

This table presents a comparison of the proposed CoVer method with several existing OOD detection methods. The comparison is based on the ResNet-50 architecture using ImageNet-1K as the in-distribution (ID) dataset. Multiple out-of-distribution (OOD) datasets (iNaturalist, SUN, Places, Textures) are used for evaluation. The table shows the AUROC (Area Under the Receiver Operating Characteristic curve) and FPR95 (False Positive Rate at 95% True Positive Rate) for each method and dataset. Higher AUROC and lower FPR95 indicate better performance.
This table compares the performance of the proposed CoVer method with several other state-of-the-art OOD detection methods. The comparison is performed using ResNet-50 as the base model on the ImageNet-1K dataset for in-distribution data and four other datasets (iNaturalist, SUN, Places, Textures) for out-of-distribution data. The metrics used for the comparison are AUROC (Area Under the Receiver Operating Characteristic Curve) and FPR95 (False Positive Rate at 95% True Positive Rate). Higher AUROC and lower FPR95 indicate better performance. The table highlights the improvement achieved by combining CoVer with existing methods.
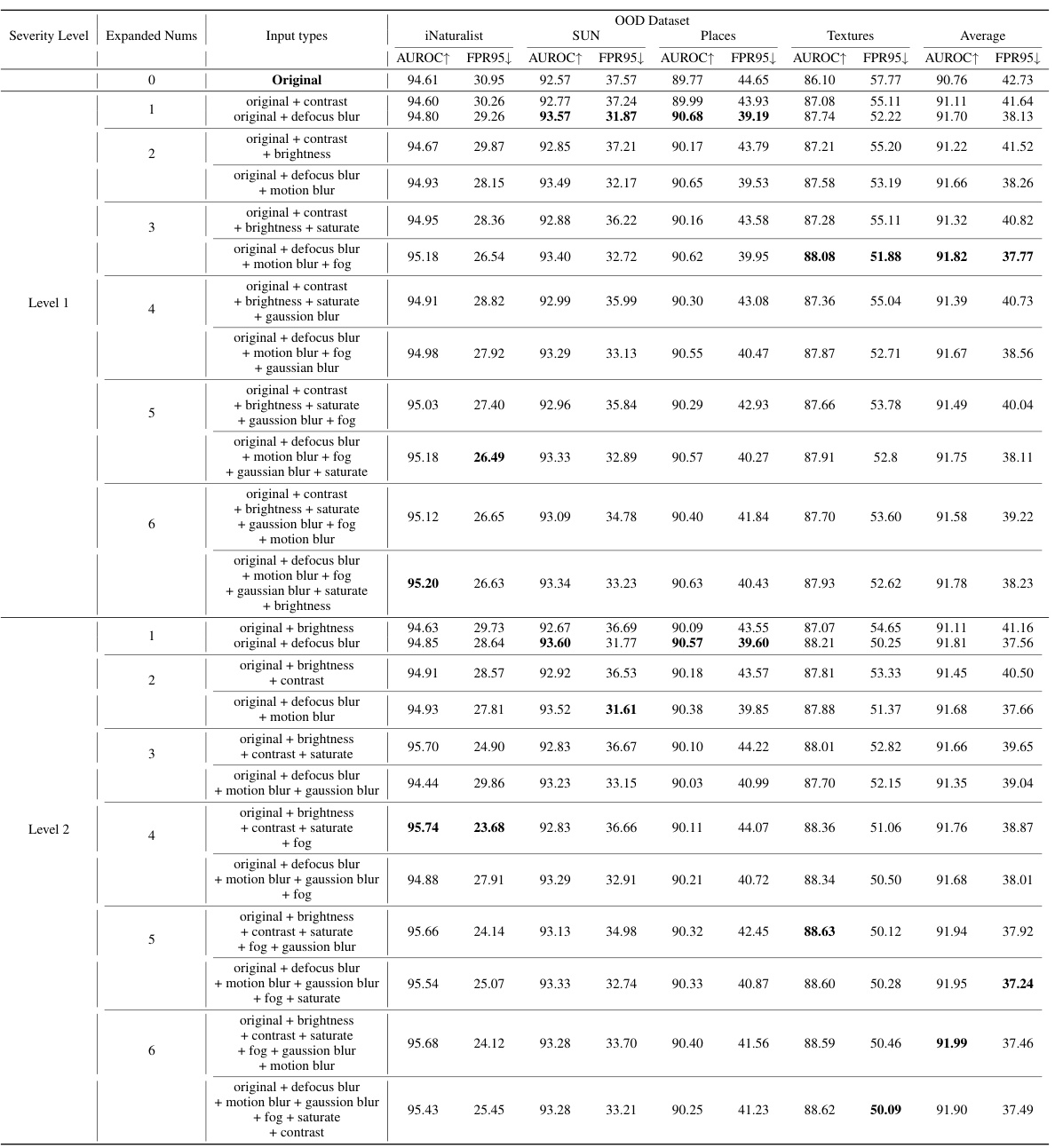
This table presents a comparison of the performance of various OOD detection methods, both with and without the proposed CoVer method. It showcases the compatibility of CoVer by integrating it with existing methods and demonstrating performance improvements across various datasets. The results highlight CoVer’s ability to enhance the performance of different OOD detection approaches.
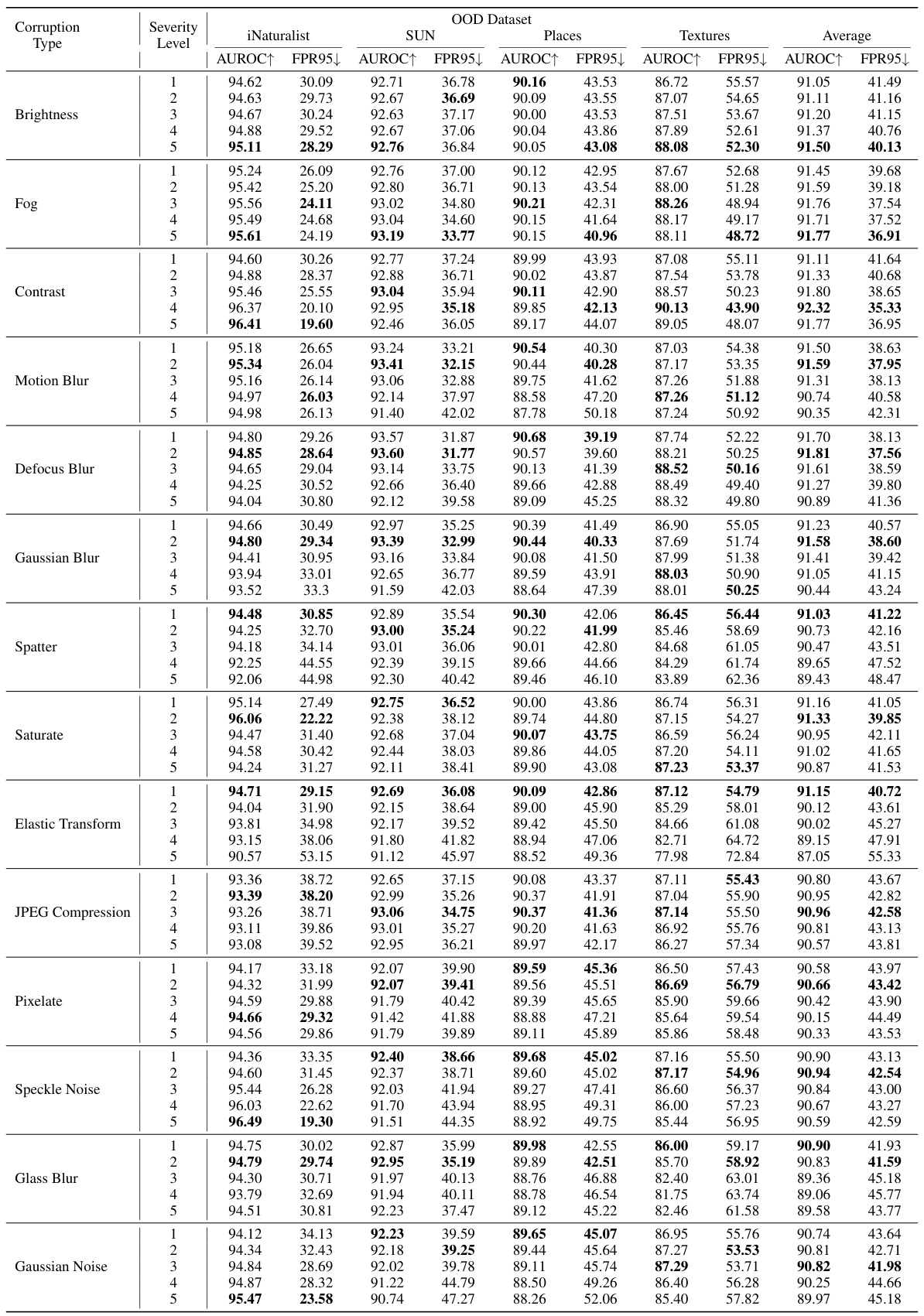
This table presents a comparison of the proposed CoVer method with several other state-of-the-art OOD detection methods. The comparison uses the ResNet-50 architecture and the ImageNet-1K dataset as the in-distribution data. The performance is measured across four different out-of-distribution (OOD) datasets: iNaturalist, SUN, Places, and Textures. Two metrics are used to evaluate the performance: AUROC (Area Under the Receiver Operating Characteristic curve) and FPR95 (False Positive Rate at 95% True Positive Rate). Higher AUROC and lower FPR95 values indicate better performance. The table shows that CoVer, especially when combined with other methods, achieves state-of-the-art performance.
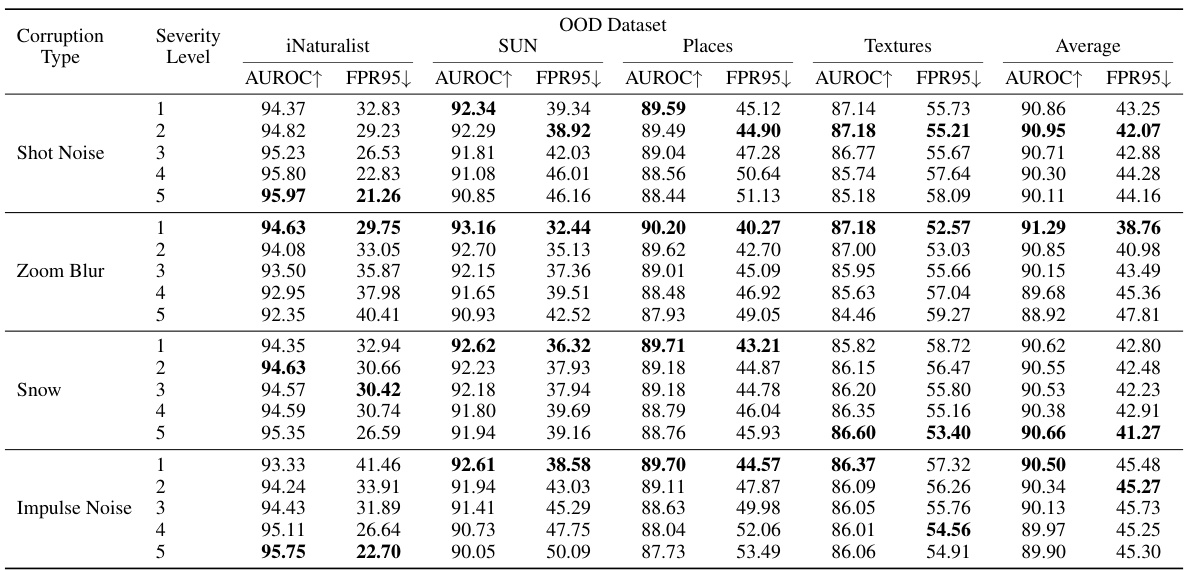
This table compares the performance of the proposed CoVer method with several existing OOD detection methods on the ImageNet-1K dataset using ResNet-50 as the backbone. It shows AUROC (Area Under the Receiver Operating Characteristic curve) and FPR95 (False Positive Rate at 95% True Positive Rate) scores for each method across four different OOD datasets (iNaturalist, SUN, Places, Textures). Higher AUROC and lower FPR95 indicate better performance. The table allows for a comparison of the effectiveness of CoVer against established baselines.
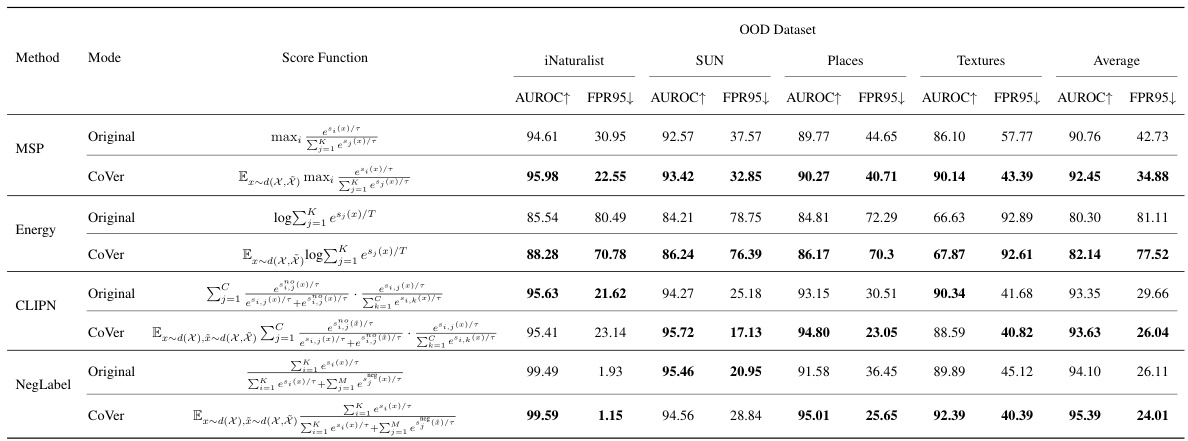
This table compares the performance of several different scoring functions for out-of-distribution (OOD) detection, both in their original form and when modified using the CoVer framework. The results show how the CoVer method, which utilizes multiple input dimensions, affects the performance of each scoring function and whether it improves performance on the ImageNet-1K dataset.
This table compares the performance of the proposed CoVer method with several other state-of-the-art OOD detection methods. The comparison is done using the ResNet-50 architecture and the ImageNet-1K dataset as in-distribution data. The table shows the AUROC (Area Under the Receiver Operating Characteristic curve) and FPR95 (False Positive Rate at 95% True Positive Rate) metrics for four different out-of-distribution (OOD) datasets: iNaturalist, SUN, Places, and Textures. Higher AUROC and lower FPR95 values are preferred, indicating better performance.

This table presents examples of corruption types selected for use in the validation process on the SVHN dataset. The selection process aims to identify corruption types that are effective for enhancing the performance of the proposed OOD detection method. The table shows the ID and validation datasets used, the method applied (MSP), the selected corruption type, and the resulting AUROC and FPR95 values. A checkmark indicates that the corruption type was selected, while an X indicates it was not.

This table presents the results of experiments evaluating the compatibility of the proposed CoVer method with various other OOD detection methods. It shows that CoVer can be integrated into existing methods (ReAct, DICE, ASH-B, MCM, LoCoOp, CLIPN, and NegLabel) to improve their performance. The experiments were performed on the ImageNet-1K dataset, comparing AUROC and FPR95 scores across multiple OOD datasets (iNaturalist, SUN, Places, Textures). The table highlights the improvements achieved by combining CoVer with the other methods, indicating its general applicability and potential as an effective enhancement for diverse OOD detection techniques. The up and down arrows denote whether higher or lower values are preferable for each metric, respectively.

This table presents the results of the Confidence Average (CoVer) method on three challenging out-of-distribution (OOD) datasets: NINCO, NINCO unit-tests, and NINCO subsamples. The experiment uses ResNet50 architecture and ImageNet-1K as the in-distribution dataset. The table compares the Area Under the ROC Curve (AUROC) and False Positive Rate at 95% true positive rate (FPR95) of the ASH method alone against the same method combined with CoVer. Lower FPR95 and higher AUROC indicate better performance. The results showcase the improvement achieved by incorporating CoVer in all three datasets.
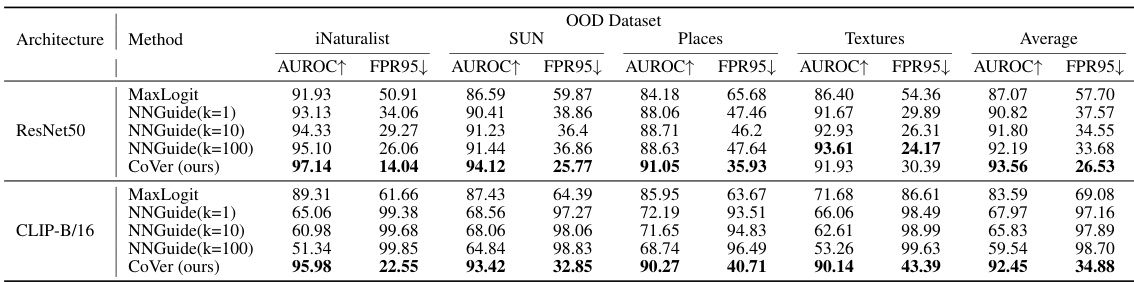
This table presents a comparison of the proposed CoVer method with several other state-of-the-art OOD detection methods. The comparison is based on the ResNet-50 architecture using ImageNet-1K as the in-distribution dataset and four other datasets (iNaturalist, SUN, Places, Textures) as out-of-distribution datasets. The results are evaluated using AUROC (Area Under the Receiver Operating Characteristic curve) and FPR95 (False Positive Rate at 95% True Positive Rate). Higher AUROC and lower FPR95 values indicate better performance.
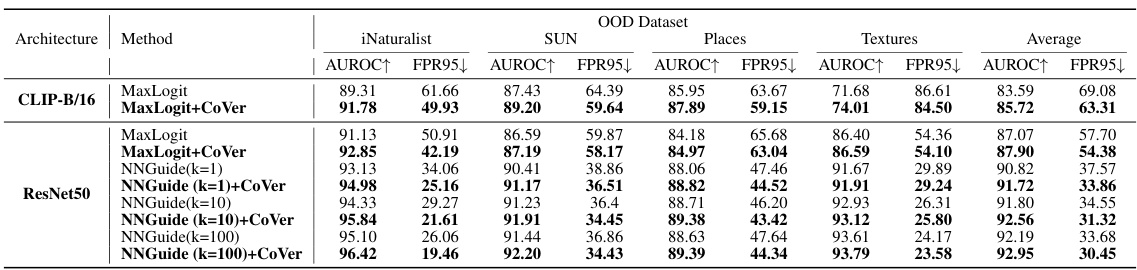
This table compares the performance of the proposed CoVer method with several other state-of-the-art OOD detection methods. The comparison is done using the ResNet-50 architecture and the ImageNet-1K dataset for in-distribution (ID) data, with four different out-of-distribution (OOD) datasets. The metrics used for evaluation are AUROC (Area Under the Receiver Operating Characteristic curve) and FPR95 (False Positive Rate at 95% True Positive Rate). Higher AUROC and lower FPR95 values indicate better performance. The table shows CoVer’s improved performance, especially when combined with other methods.

This table compares the performance of the proposed CoVer method with other state-of-the-art OOD detection methods on the ImageNet-1K dataset using ResNet-50 as the backbone network. The comparison is done using two metrics: AUROC (Area Under the Receiver Operating Characteristic curve) and FPR95 (False Positive Rate at 95% True Positive Rate). Higher AUROC and lower FPR95 values indicate better performance. The table shows that CoVer, especially when combined with other methods, achieves superior performance compared to existing methods.

This table compares the performance of the proposed CoVer method with other anomaly detection and textual OOD detection baselines. The baselines use different approaches: data depth (APPROVED), information projection (REFEREE), and isolation forest. The comparison uses the ResNet50 architecture and the ImageNet-1K dataset. The results show AUROC and FPR95 scores for each method across four OOD datasets (iNaturalist, SUN, Places, Textures).

This table presents a comparison of the proposed CoVer method with other state-of-the-art OOD detection methods. The comparison uses the ResNet-50 architecture and the ImageNet-1K dataset as the in-distribution data. Multiple out-of-distribution (OOD) datasets are used for evaluation: iNaturalist, SUN, Places, and Textures. The results are presented in terms of AUROC (Area Under the Receiver Operating Characteristic curve) and FPR95 (False Positive Rate at 95% True Positive Rate). Higher AUROC and lower FPR95 indicate better performance.
Full paper#