↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Large Language Models (LLMs) are powerful but demand significant computational resources. Knowledge distillation (KD) aims to transfer knowledge from a large, high-performing LLM (teacher) to a smaller, more efficient one (student), but existing KD methods often struggle to effectively address performance differences across various domains. This leads to uneven performance improvements and suboptimal model efficiency.
DDK, a novel framework, dynamically adjusts the training data to focus more on domains where the student model lags behind. It uses a smooth factor updating mechanism to maintain stability. Experiments show that DDK significantly improves student model performance compared to baseline methods across diverse domains and model architectures, demonstrating its effectiveness in creating efficient and powerful LLMs.
Key Takeaways#
Why does it matter?#
This paper is significant because it introduces a novel approach to knowledge distillation for large language models (LLMs), addressing a critical challenge in the field. By dynamically adjusting the composition of the distillation dataset based on domain-specific performance gaps, DDK improves the efficiency and effectiveness of LLM training, leading to better performing smaller models and opening new avenues for research in model compression and efficient LLM deployment.
Visual Insights#

This figure shows the perplexity (PPL) scores for different LLMs across various domains. The LLMs tested include a baseline student model, and then that same model after three different types of training: Continual Pretraining (CPT), Knowledge Distillation (KD), and the authors’ proposed method, Distilling Domain Knowledge (DDK). The teacher model’s PPL is shown for comparison. The graph visually demonstrates how DDK improves the student model’s performance, especially in domains where it initially lagged behind the teacher model. The domains are categorized into general-purpose text data (Common Crawl, C4, The Stack, Wikipedia, Books, ArXiv, StackExchange) and Chinese-language data (Chinese Books, Chinese Common Crawl).

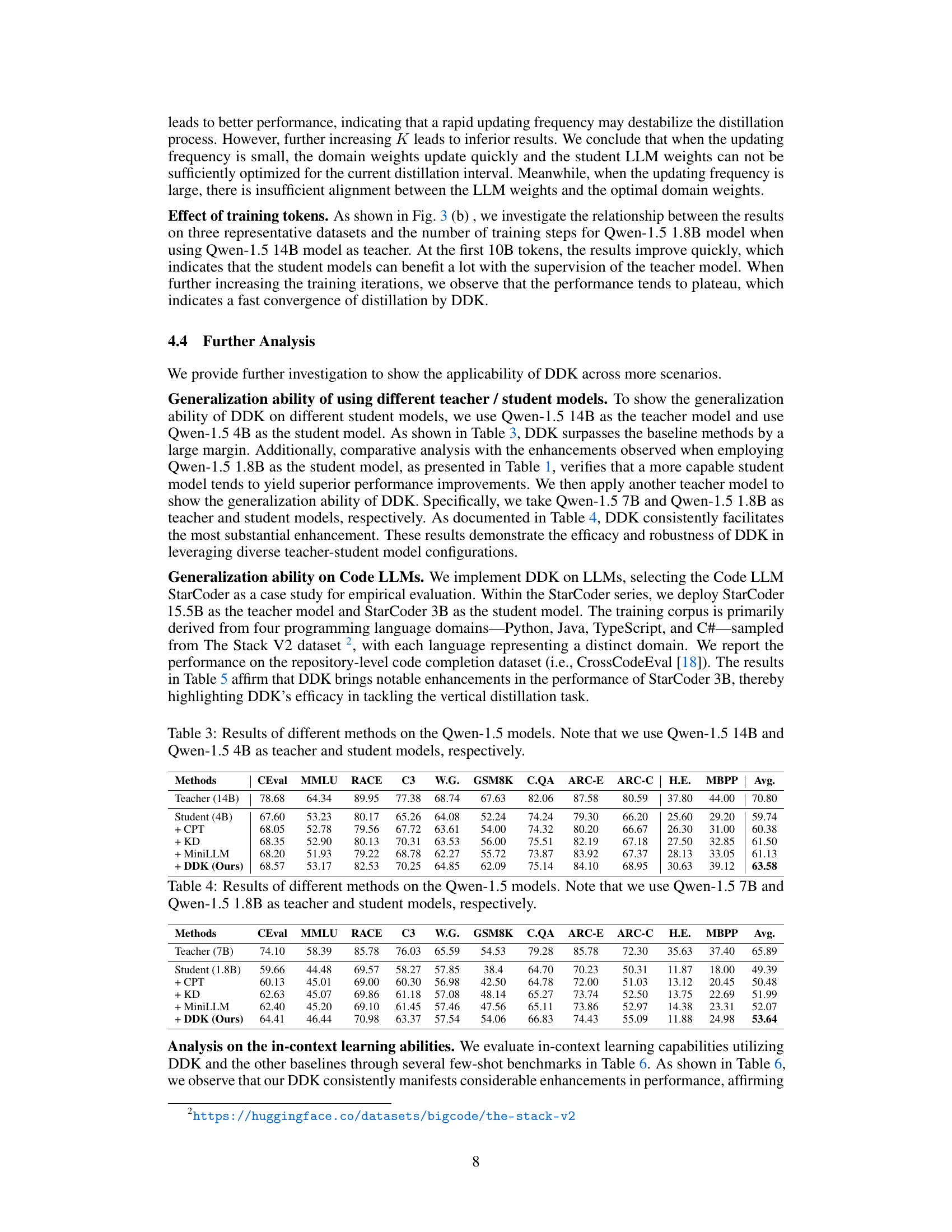
This table presents a comparison of different knowledge distillation methods on the Qwen-1.5 large language model. It uses Qwen-1.5 14B as the teacher model and Qwen-1.5 1.8B as the student model. The table shows the performance of each method across several benchmark datasets, including evaluation metrics such as perplexity and accuracy. The methods compared include the baseline student model, models using continuous pre-training (CPT), traditional knowledge distillation (KD), task-aware distillation (TED), MiniLLM, and the proposed DDK method.
In-depth insights#
Domain-Aware KD#
Domain-aware knowledge distillation (KD) addresses the limitations of traditional KD methods in large language models (LLMs) by acknowledging the heterogeneity of data domains. Standard KD often struggles to effectively transfer knowledge across disparate domains, leading to uneven performance improvements. A domain-aware approach would likely involve techniques such as domain-specific loss functions or weighted data sampling to prioritize domains where the student model lags behind the teacher. This could involve dynamically adjusting weights based on performance discrepancies during training, ensuring that the distillation process focuses sufficient attention on challenging areas, resulting in a more robust and generalized student model. Careful consideration of domain representation is crucial to successfully implement domain-aware KD; this might include identifying relevant domain-specific features or using domain embeddings. The effectiveness of such techniques should be evaluated through comprehensive benchmarking across diverse domains to demonstrate the overall performance gains compared to standard KD and other model compression techniques. Ultimately, a well-designed domain-aware KD method is key to creating more efficient and effective, smaller LLMs that generalize well across various application scenarios.
DDK Framework#
The Distilling Domain Knowledge (DDK) framework presents a novel approach to knowledge distillation for large language models (LLMs). Instead of a uniform distillation process, DDK dynamically adjusts the training data composition based on performance discrepancies across different domains. This addresses the limitations of existing methods that overlook these discrepancies, leading to inefficient knowledge transfer and suboptimal performance. By continuously monitoring the performance gaps and smoothly adjusting data weights, DDK ensures a more stable and effective distillation process, resulting in significantly improved student model performance compared to conventional methods and continuous pre-training baselines. The key innovation lies in its domain-specific data sampling strategy guided by a dynamically updated domain discrepancy factor, allowing the framework to focus on the domains where the student model most lags behind. This adaptive strategy, combined with a factor smoothing mechanism, enhances both the stability and efficiency of the knowledge transfer process, contributing to a more robust and effective LLM distillation solution.
Data Sampling#
Data sampling strategies are crucial for successful knowledge distillation, especially when dealing with large language models (LLMs) and diverse data domains. Effective sampling ensures that the student LLM receives a balanced representation of the knowledge from the teacher LLM, addressing performance discrepancies across different domains. A key challenge is dynamically adjusting the sampling based on the evolving performance gap between the teacher and student. This dynamic adaptation requires a mechanism to quantify domain-specific performance differences and update the sampling probabilities accordingly. Strategies like domain knowledge-guided sampling, which prioritizes domains where the student underperforms, are vital for efficient knowledge transfer. However, simply shifting focus to underperforming domains may introduce instability. Therefore, smooth updating mechanisms that prevent drastic shifts in data composition are critical to maintaining the stability and robustness of the distillation process. Furthermore, the choice of sampling method significantly impacts the final student model’s performance and generalizability. Careful consideration of these factors is necessary for optimal knowledge distillation, leading to high performing, efficient student LLMs.
Ablation Study#
An ablation study systematically removes components or features of a model to assess their individual contributions. In the context of a Large Language Model (LLM) distillation paper, this section would likely investigate the impact of key techniques, such as the domain knowledge-guided sampling strategy and the factor smooth updating mechanism. By disabling each component in turn, researchers quantify its effect on the student model’s performance across various domains. This analysis helps determine whether the proposed method relies on a particular component for its success, or whether it exhibits robustness and strength even with altered settings. Significant performance drops when removing certain components would highlight their importance, showcasing the efficacy and necessity of the proposed techniques within the DDK framework. Conversely, minimal performance changes after removal indicate redundancy or robustness to variations, suggesting the algorithm’s stability and potential adaptability to diverse scenarios. The results thus reveal the essential parts of the method, identifying strengths and weaknesses while providing valuable insights into the algorithm’s design and the contribution of each individual element.
Future Works#
Future work for this research could explore several promising avenues. Extending DDK to encompass more diverse LLM architectures beyond Qwen and LLaMA is crucial for broader applicability. Investigating the effects of varying the factor smooth updating frequency (K) and the temperature (T) parameters would provide deeper insights into their impact on stability and performance. Exploring different domain knowledge-guided sampling strategies could lead to more efficient and effective distillation. A comprehensive comparative study against a wider range of knowledge distillation methods, particularly those employing advanced techniques like meta-learning, would strengthen the evaluation. Finally, developing a theoretical framework to analyze the interplay between domain discrepancy and distillation effectiveness would offer a deeper understanding of DDK’s mechanism.
More visual insights#
More on figures

This figure illustrates the DDK framework’s distillation process. It begins by dividing the training dataset into distinct domains. DDK then dynamically adjusts the distribution of domain-specific data, focusing more on domains where the student model underperforms. The proportions allocated to each domain are recalculated periodically using a factor smooth updating approach, ensuring a stable and robust distillation process.

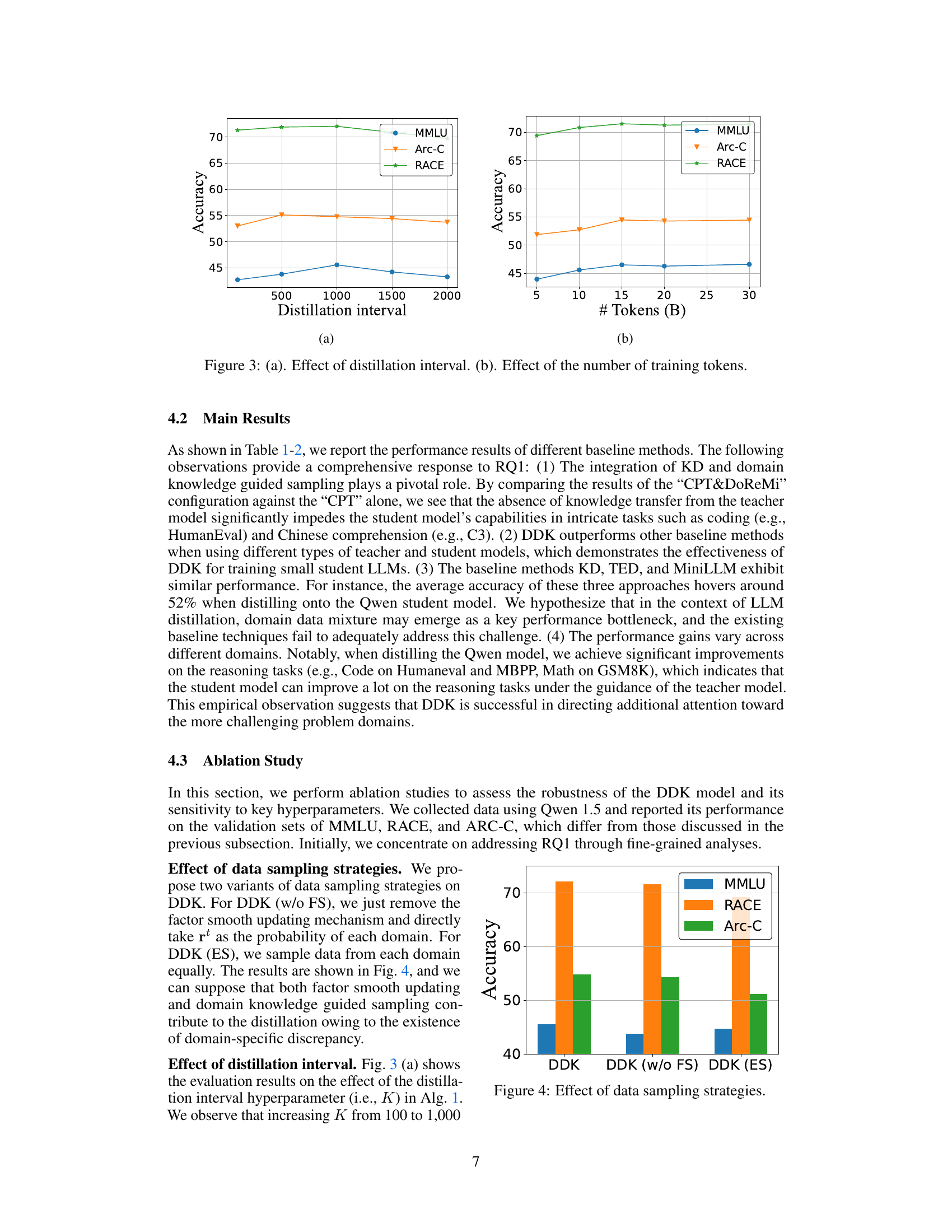
This figure shows the ablation study results on the effects of two hyperparameters in the DDK framework: distillation interval and the number of training tokens. The left subfigure (a) illustrates how varying the distillation interval affects the accuracy on three benchmark datasets (MMLU, Arc-C, and RACE). The right subfigure (b) displays how changing the number of training tokens impacts the same three datasets. The results demonstrate the optimal ranges for both hyperparameters, which contribute to the overall effectiveness of the DDK method in improving the performance of student LLMs.
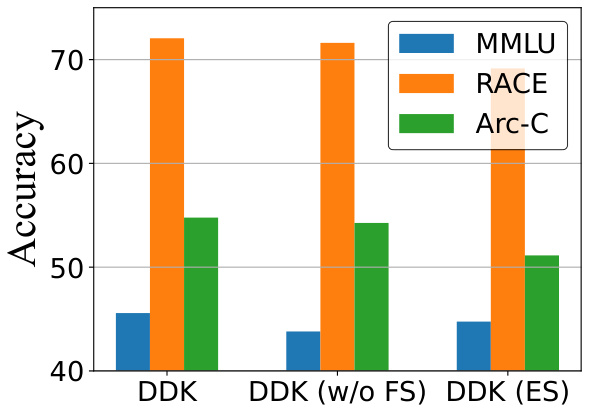
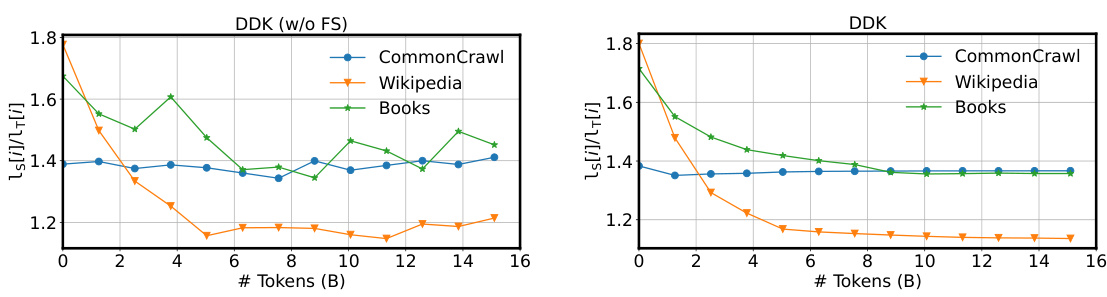
This figure compares the performance of three different data sampling strategies used in the DDK framework on three benchmark datasets: MMLU, RACE, and Arc-C. The strategies compared are the full DDK method, DDK without factor smoothing (w/o FS), and DDK with equal sampling (ES). The chart shows that the standard DDK approach achieves superior accuracy across all three datasets, indicating the value of the dynamic data sampling and factor smoothing in improving the effectiveness of the knowledge distillation.
This figure shows the effects of two hyperparameters on the performance of the DDK model. The left graph (a) illustrates how changing the distillation interval (how often the domain discrepancy factor is recalculated) impacts the model’s performance across three domains. The right graph (b) shows how the number of training tokens affects model performance. These ablation studies help to demonstrate the robustness and optimal parameter settings for the DDK model.
More on tables
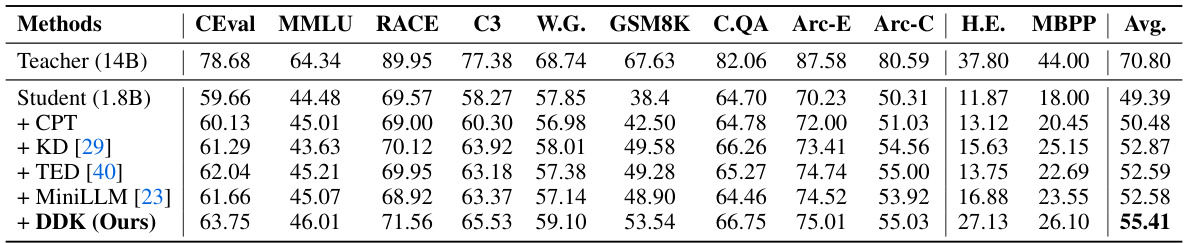
This table presents the performance comparison of different methods on the Qwen-1.5 large language models. It shows the results obtained using various techniques, including the baseline student model (Qwen-1.5 1.8B), continuous pre-training (+CPT), standard knowledge distillation (+KD), task-aware distillation (+TED), MiniLLM, and the proposed DDK method. The evaluation is performed across multiple benchmark datasets, encompassing evaluation metrics for various tasks like common sense reasoning, multiple-choice questions, and code generation.
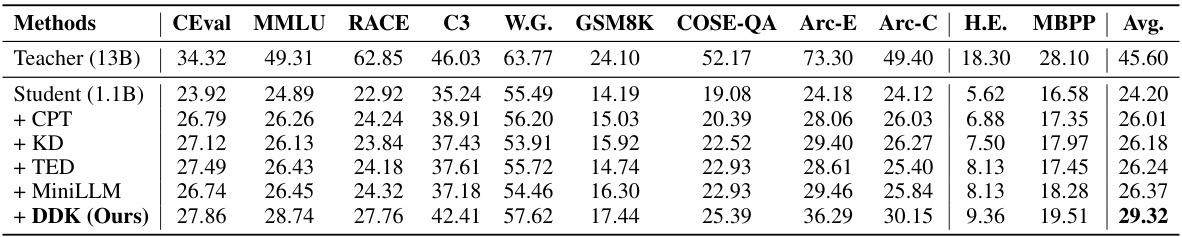
This table presents the results of different knowledge distillation methods applied to LLaMA models. It compares the performance of a smaller student model (TinyLLaMA 1.1B) against a larger teacher model (LLaMA2 13B) across various evaluation metrics (CEval, MMLU, RACE, C3, W.G., GSM8K, COSE-QA, Arc-E, Arc-C, H.E., MBPP) after different knowledge distillation techniques were applied. The methods compared include: Continuously pre-trained baseline (CPT), standard Knowledge Distillation (KD), Task-aware filter-based knowledge distillation (TED), MiniLLM, and the proposed Distill Domain Knowledge (DDK) method. The average performance across all metrics is also included for each method.

This table presents the results of different knowledge distillation methods on the Qwen-1.5 language models. It compares the performance of a smaller student model (Qwen-1.5 4B) trained using different techniques against a larger teacher model (Qwen-1.5 14B). The methods compared include: Continuous Pretraining (CPT), Knowledge Distillation (KD), Task-aware Enhanced Distillation (TED), MiniLLM, and the proposed method, Distilling Domain Knowledge (DDK). The evaluation metrics used are several benchmark datasets (CEval, MMLU, RACE, C3, Winogrande, GSM8K, CommonsenseQA, Arc-E, Arc-C, HumanEval, and MBPP), providing a comprehensive assessment of performance across various tasks and domains.

This table presents the results of different knowledge distillation methods on the Qwen-1.5 language models. It compares the performance of a larger teacher model (Qwen-1.5 14B) to a smaller student model (Qwen-1.5 1.8B) across various downstream tasks. The tasks include several benchmark evaluations measuring common sense reasoning, knowledge, and language understanding. Different methods like Continuous Pre-training (CPT), standard Knowledge Distillation (KD), Task-aware Embedding Distillation (TED), MiniLLM, and the proposed Distilling Domain Knowledge (DDK) are compared. The table displays the performance of each method on each task, providing a quantitative assessment of their effectiveness in improving the student model’s performance.

This table presents the results of different knowledge distillation methods on the StarCoder large language models. It compares the performance of a smaller student model (StarCoder 3B) after distillation, using a larger teacher model (StarCoder 15.5B) as a source of knowledge. The methods compared include: using the teacher model directly, continued pre-training (CPT), standard knowledge distillation (KD), and the proposed DDK method. Performance is measured on the EM (exact match) and ES (exact set) metrics across four programming languages (Python, Java, TypeScript, and C#), with an average score calculated across all languages. DDK aims to improve upon the performance of previous techniques by dynamically focusing on domain areas where the student model is underperforming.
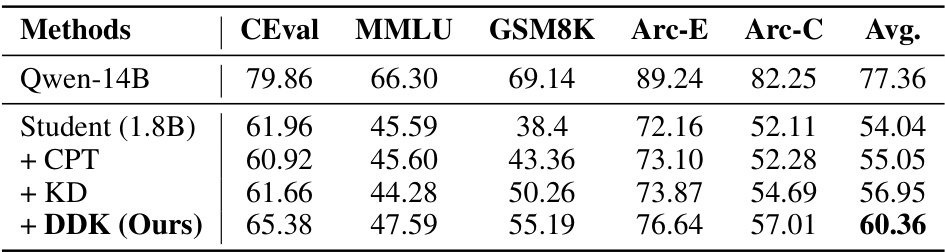
This table presents the few-shot (5-shot) performance results on several benchmark datasets using different knowledge distillation methods. It compares the performance of a small Qwen-1.5 1.8B model (student) against the performance of a larger Qwen-1.5 14B model (teacher) across five datasets (CEval, MMLU, GSM8K, Arc-E, and Arc-C). The methods compared include the baseline student model, continuous pre-training (CPT), traditional knowledge distillation (KD), and the proposed DDK method. The average performance across all datasets is also reported. This data helps to illustrate the effectiveness of DDK in improving the few-shot learning capabilities of a smaller language model through knowledge distillation.
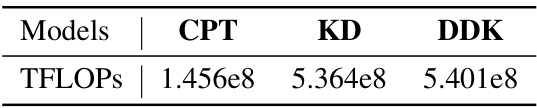
This table shows the training computational costs (measured in TFLOPs) for three different methods: CPT (Continued Pre-training), KD (Knowledge Distillation), and DDK (Distilling Domain Knowledge). It compares the costs when using the Qwen-1.5 14B model as a teacher model to distill to the Qwen-1.5 1.8B student model for KD and DDK. CPT represents continuing the pre-training of the student model without knowledge distillation.
Full paper#