↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current image restoration methods struggle with multiple simultaneous degradations, while all-in-one models often compromise accuracy for generalization. Traditional methods require manual task sequencing, limiting efficiency and potential for optimal outcomes. This leads to suboptimal results and increased processing time.
RestoreAgent uses a multimodal large language model to intelligently analyze images, determine the optimal restoration sequence, and select appropriate models. This autonomous approach improves accuracy and efficiency, exceeding human expert performance. Its modular design ensures easy integration of new tasks and models, paving the way for future advancements in the field.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in image restoration and AI because it introduces RestoreAgent, a novel system that surpasses human experts in handling complex image degradations. Its modular design and reliance on multimodal large language models offers a flexible, adaptable framework for future advancements and integration of new technologies, opening new avenues for research in autonomous image processing and intelligent systems.
Visual Insights#
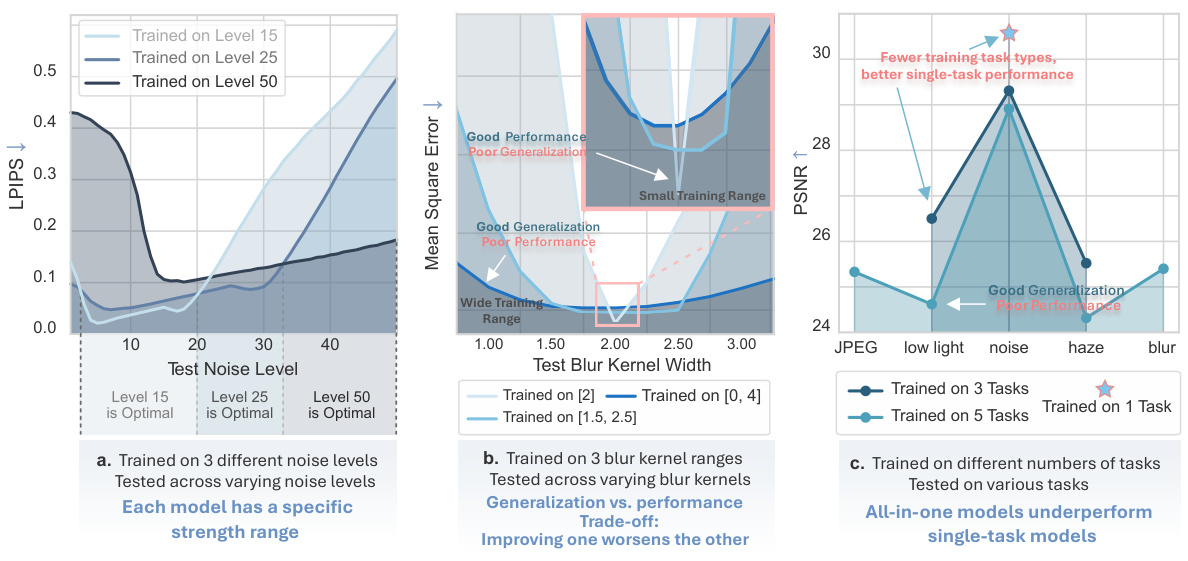
This figure demonstrates the limitations of all-in-one models for image restoration. Panel (a) shows that models trained on specific noise levels perform best within their training range, highlighting the need for task-specific models. Panel (b) illustrates the trade-off between generalization and performance when training on a wider range of blur levels. Panel (c) compares the performance of all-in-one models against single-task models on various tasks, demonstrating the superior performance of specialized models.
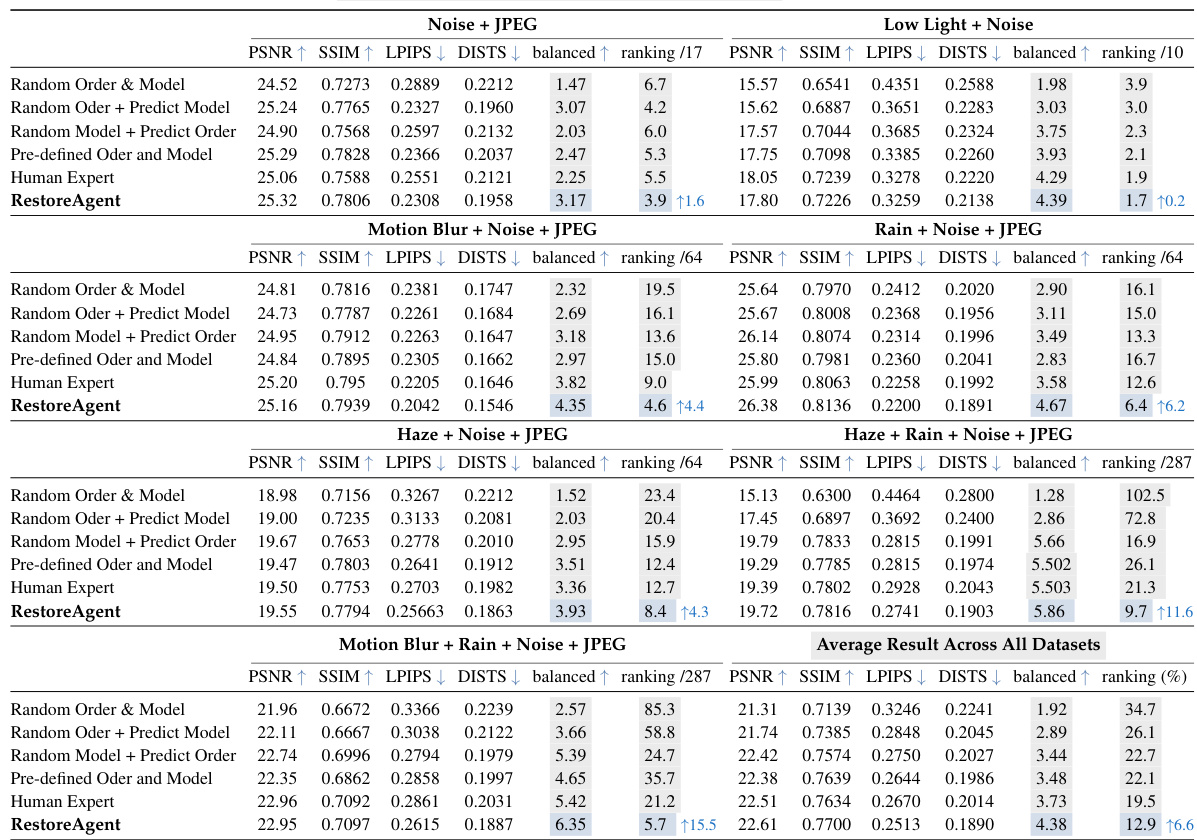
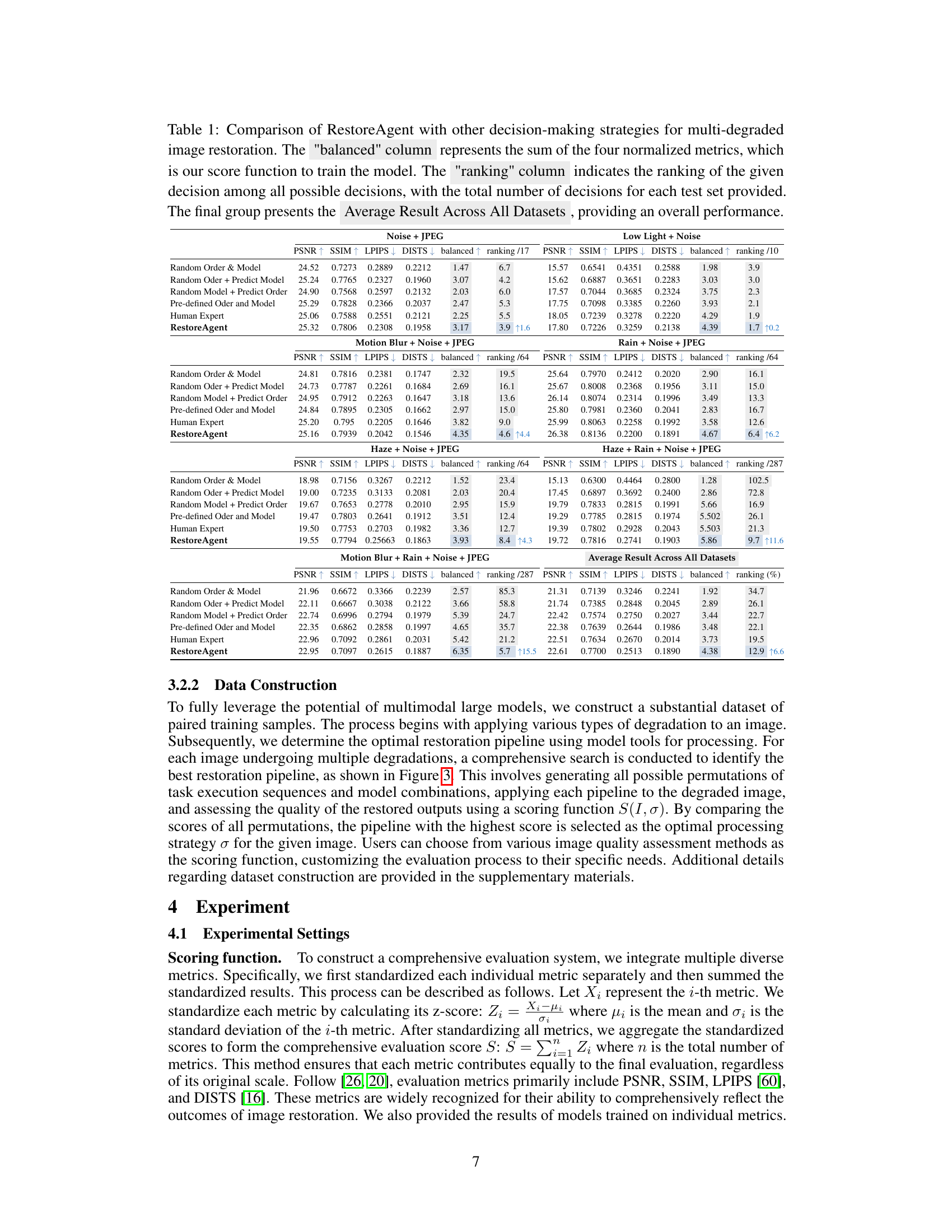
This table presents a comparative analysis of RestoreAgent against several other decision-making strategies for multi-degraded image restoration. It compares the performance across different metrics (PSNR, SSIM, LPIPS, DISTS) for various degradation combinations (Noise+JPEG, Low Light+Noise, Motion Blur+Noise+JPEG, Rain+Noise+JPEG, Haze+Noise+JPEG, Haze+Rain+Noise+JPEG, Motion Blur+Rain+Noise+JPEG) and provides the balanced score and ranking of each strategy. The final row shows the average results across all datasets.
In-depth insights#
Multimodal Restoration#
Multimodal restoration, in the context of image processing, signifies a paradigm shift towards tackling image degradation holistically. Traditional methods typically address individual issues like noise, blur, or compression in isolation. Multimodal restoration leverages the power of multiple data modalities, such as visual and textual information, to achieve more robust and contextually aware results. By integrating diverse models and algorithms, a multimodal system can intelligently assess the types and severity of image impairments, dynamically optimizing the order of restoration tasks and model selection for optimal outcome. The key is the ability to not just identify separate degradation types but to also understand their interdependencies, which allows for a more targeted and effective restoration process, surpassing the limitations of single-modality approaches. This intelligent and adaptive strategy is particularly beneficial for complex real-world images that often suffer from multiple simultaneous degradations. The success of multimodal restoration hinges on the development of powerful and flexible multimodal models capable of seamlessly integrating and coordinating diverse information sources for optimal image reconstruction.
Agent Architecture#
A hypothetical ‘Agent Architecture’ section in a research paper on autonomous image restoration would delve into the system’s design, focusing on the interplay between its core components. It would likely begin by detailing the multimodal large language model (MLLM), explaining its role as the central processing unit. This would entail a description of the chosen MLLM, its capabilities in visual understanding and reasoning, and how it integrates diverse data modalities. The section would then describe the degraded image perception module, detailing its function in analyzing images to detect degradation types. This would be followed by an explanation of the task planning and model selection module, illustrating how the MLLM determines the optimal sequence of restoration tasks and selects appropriate models from a pre-defined library. Crucially, it would elaborate on the adaptive decision-making strategy, highlighting the system’s ability to dynamically adjust the task sequence based on intermediate results. Finally, the architecture section would specify the execution module, outlining how the selected restoration models are invoked and integrated. Throughout, the section would emphasize the system’s modularity and flexibility, showcasing its potential for seamless integration of new tasks and models, reflecting the paper’s contributions towards autonomous image restoration.
Task-Optimal Sequence#
The concept of “Task-Optimal Sequence” in image restoration is crucial because the order in which different restoration tasks (like denoising, deblurring, dehazing) are applied significantly impacts the final result. A suboptimal sequence can lead to cumulative errors where fixing one issue inadvertently introduces or worsens another. RestoreAgent’s approach moves beyond pre-defined or random task orders by dynamically assessing the input image’s specific degradation patterns. This adaptive sequence determination is a key differentiator, enabling the system to optimize the workflow for each image individually, unlike traditional methods that apply a fixed pipeline. The system achieves this through an intelligent, data-driven mechanism likely involving a multimodal large language model, enabling it to effectively manage complex, real-world scenarios with multiple simultaneous degradations. By prioritizing tasks based on image-specific needs, RestoreAgent likely maximizes the effectiveness of individual restoration modules and improves the overall fidelity of the restored image, leading to superior performance compared to both fixed-order and human-expert approaches.
All-in-One Limits#
The concept of “All-in-One Limits” in image restoration highlights the inherent trade-offs in designing models capable of handling multiple degradation types simultaneously. All-in-one models, while aiming for versatility, often compromise performance on individual tasks due to the complexity of learning a broad data distribution. They tend to produce overly smoothed results lacking fidelity, failing to address specific degradation patterns effectively. Furthermore, generalization suffers; these models struggle with unseen degradation types or variations within known types. The limited task scope and compromised performance necessitate a shift towards more specialized, modular approaches for complex scenarios, where a pipeline of task-specific models orchestrated by an intelligent system could yield superior results. This highlights the importance of carefully balancing performance and generalization in model design, indicating a potential need for adaptable, hybrid systems that combine the strengths of all-in-one and specialized models.
Future Extensions#
The paper’s core contribution centers on RestoreAgent, a system for autonomous image restoration using multimodal large language models. Future work should focus on expanding the model’s capabilities. This could involve incorporating a wider range of degradation types (e.g., motion blur, compression artifacts, etc.) and integrating more advanced restoration models. A key area for improvement is enhancing the model’s generalization ability to handle unseen degradation patterns effectively. Further research could investigate the integration of additional visual and textual information beyond the current image input to improve the quality of restoration. Exploring different optimization strategies that are suitable for specific task constraints or user preferences is another promising direction. Finally, a thorough evaluation of RestoreAgent’s performance on a larger, more diverse dataset is necessary to validate its robustness and generalizability in real-world scenarios.
More visual insights#
More on figures

This figure demonstrates the limitations of three different approaches to image restoration: all-in-one models, fixed task execution order, and fixed model for a task. The top row (a1-a3) shows that all-in-one models struggle to handle unseen degradation types and often underperform specialized single-task models. The middle row (b1-b2) illustrates the negative impact of a fixed or random task execution order, where the processing order significantly affects the final restoration quality. The bottom row (c) shows that using a single fixed model for a task is inflexible and limits optimal performance. Images with pink backgrounds highlight cases where the selected method failed to achieve satisfactory results.

This figure demonstrates the limitations of three different approaches to image restoration: all-in-one models, fixed task execution order, and using a single fixed model for each task. The top row (a1-a3) shows that all-in-one models fail to handle unseen degradation types and underperform compared to specialized single-task models. The middle row (b1-b2) illustrates how a fixed or random task execution order can lead to suboptimal results because the order in which degradations are addressed affects the final outcome. The bottom row (c) shows that using a single fixed model for a task is inflexible and may not achieve optimal performance for various degradation patterns. Images with pink backgrounds highlight negative examples that demonstrate the limitations of each method.

This figure demonstrates the limitations of three different approaches to image restoration: all-in-one models, fixed task execution order, and fixed model for a single task. The top row (a1-a3) shows the limitations of all-in-one models: they fail on unseen degradation types, have limited performance compared to specialized models, and underperform when a single task model is combined with an all-in-one model. The middle row (b1-b2) shows the problems of using a fixed or random task execution order: the order greatly affects restoration quality, and applying one restoration task can impact subsequent tasks. The bottom row (c) highlights the inflexibility of using a single fixed model for each task: different patterns of the same degradation type require distinct handling methods. Images with pink backgrounds are examples of failure cases.

This figure demonstrates the limitations of three different approaches to image restoration: all-in-one models, fixed task execution order, and fixed model for each task. The top row (a1-a3) shows that all-in-one models fail on unseen degradation types and underperform specialized single-task models. The middle row (b1-b2) illustrates how the order of task execution significantly impacts the results, demonstrating that a fixed order may be ineffective and that adapting the order based on the specific degradations present in the image is crucial for better performance. Finally, the bottom row (c) shows that a fixed model for a given type of degradation does not always perform well on varying image patterns, underscoring the need for adaptability and selecting the best model for each task based on the specific patterns present in the image. Images with pink backgrounds highlight cases where the chosen approach failed to deliver satisfactory results.
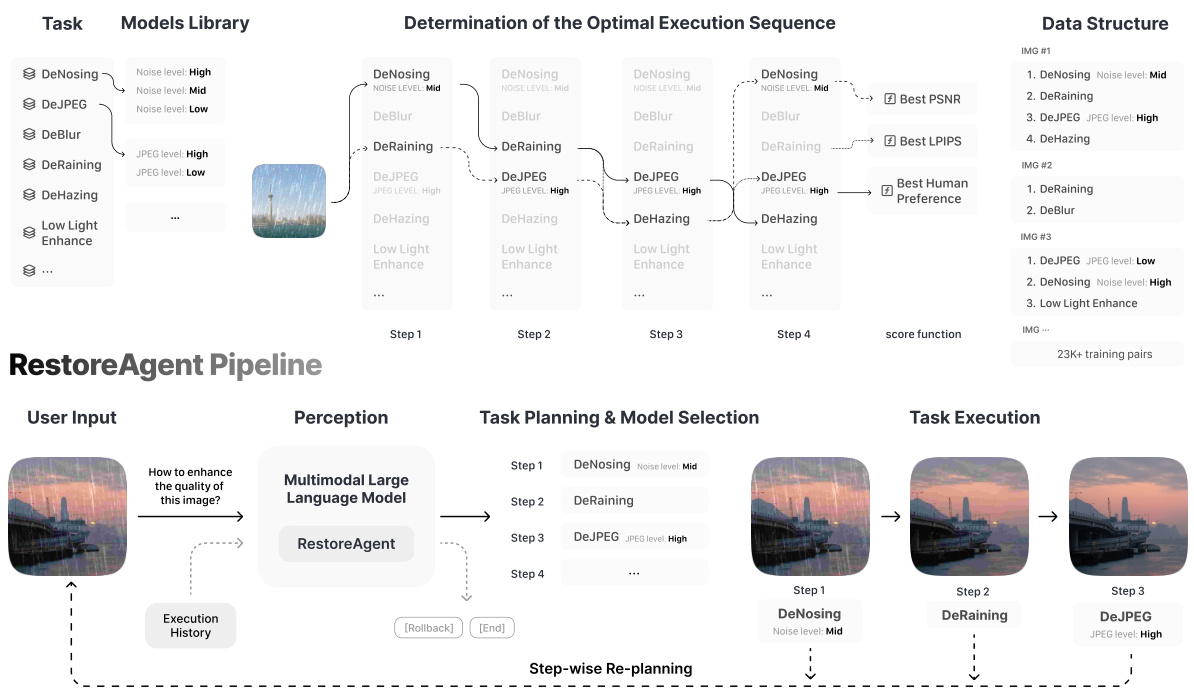
The figure illustrates the data construction workflow and RestoreAgent pipeline. The data construction involves creating training samples with various degradation combinations and their corresponding optimal restoration sequences. These sequences are determined using a scoring function that evaluates different pipeline options and selects the one with the highest score. The RestoreAgent pipeline depicts how the system takes a user input (a degraded image), utilizes a multimodal large language model to plan the restoration tasks and select appropriate models, executes the plan step-by-step, uses the execution history to adjust strategies if necessary, and supports rollback functionality for error correction.

This figure shows examples of image restoration tasks processed by RestoreAgent. Each row represents a different input image with multiple degradation types. The left side shows the sequence of restoration tasks and the models chosen by RestoreAgent, while the right side shows the same input image processed with the tasks performed in a different order or with different models. Images with a pink background highlight cases where RestoreAgent made incorrect decisions, illustrating that the correct task sequence is crucial for optimal restoration results. This showcases the model’s ability to predict the correct task order and model selection for various combinations of degradation types.

This figure compares the performance of RestoreAgent against several all-in-one image restoration methods. It shows visual results on three example images, each degraded with different combinations of noise, haze, JPEG artifacts, and rain. The comparison highlights RestoreAgent’s superior ability to handle complex, multi-type degradations where all-in-one methods struggle.

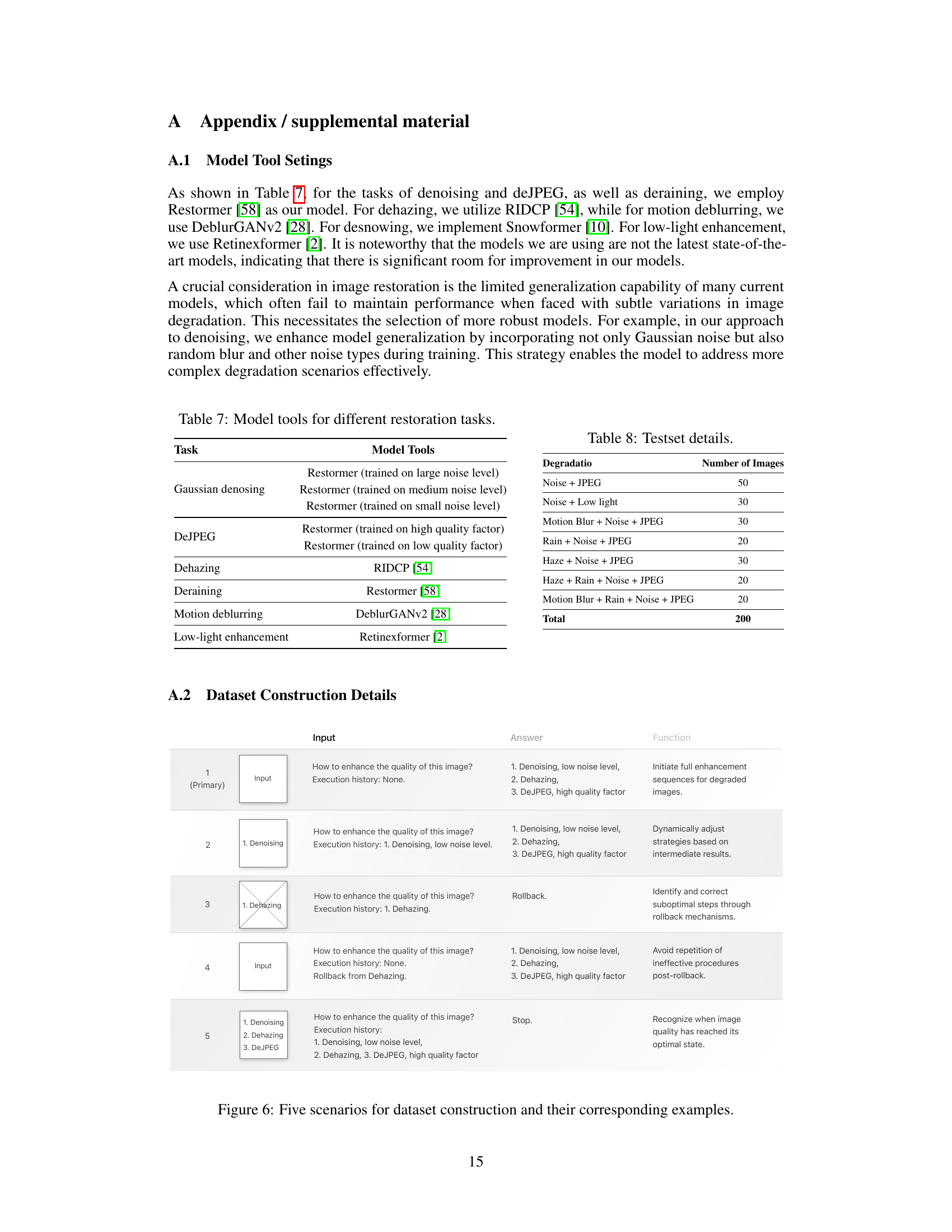
This figure illustrates five scenarios used to construct the dataset for training the RestoreAgent model. Each scenario is designed to improve the model’s ability to handle various situations, including: initiating full enhancement sequences, dynamically adjusting strategies based on intermediate results, identifying and correcting suboptimal steps through rollback mechanisms, avoiding repetition of ineffective procedures after rollback, and recognizing when image quality has reached its optimal state. The scenarios are shown with example prompts and the corresponding model’s responses, demonstrating how the data is structured and the type of information the model is trained on.

This figure demonstrates the challenges faced by human experts in choosing the optimal restoration strategy. The top panel shows that even with the same degradation types (rain, haze, noise, JPEG), different patterns require distinct execution orders. The bottom panel illustrates the difficulty in selecting the single most effective strategy from many possibilities. Suboptimal choices result in poor image quality, highlighting the need for a more automated and systematic approach.
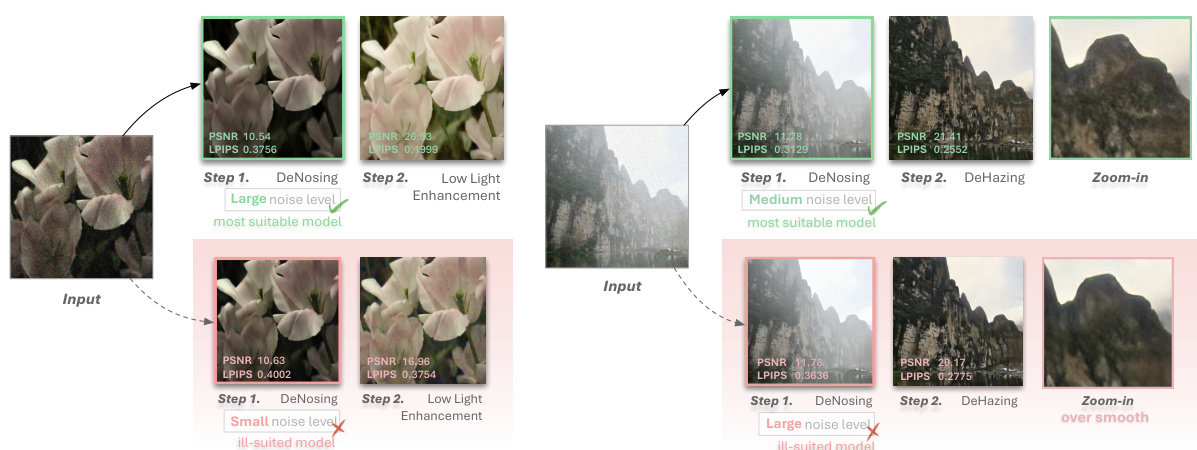
This figure shows two examples of image restoration using RestoreAgent. Each example demonstrates the importance of choosing the right model for a specific task in achieving optimal restoration quality. The top example shows that selecting the appropriate model for denoising, a task with multiple suitable models, significantly impacts the final PSNR and LPIPS scores compared to using an ill-suited model. The bottom example illustrates that choosing the correct model for dehazing is crucial for high-quality restoration and avoiding over-smoothed results. In both examples, the results highlight the importance of RestoreAgent’s ability to select the optimal model for each task, leading to significantly improved image quality.
More on tables
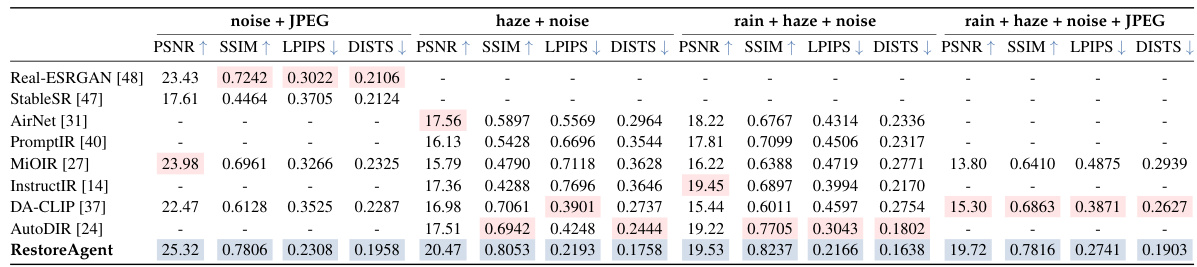
This table presents a quantitative comparison of the RestoreAgent’s performance against several All-in-One image restoration methods across various degradation types (noise + JPEG, haze + noise, rain + haze + noise, and rain + haze + noise + JPEG). The metrics used for comparison are PSNR, SSIM, LPIPS, and DISTS. The best and second-best results for each metric are highlighted, clearly demonstrating RestoreAgent’s superior performance in handling multiple degradation types.
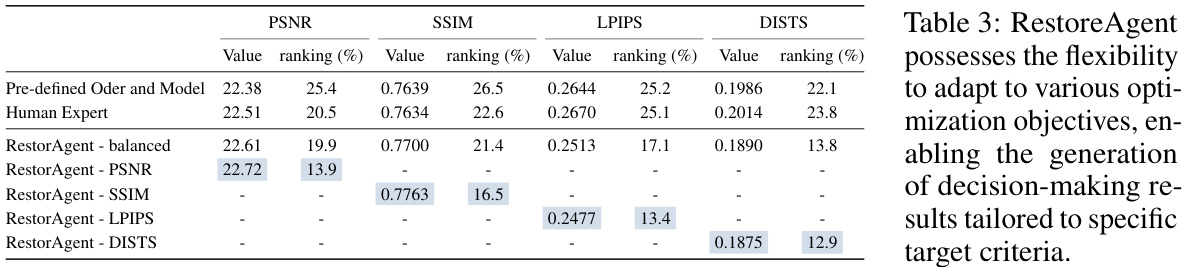
This table compares the performance of RestoreAgent against other methods for multi-degraded image restoration. It evaluates different strategies for choosing restoration tasks and models: random order and model, random order with predicted models, random models with predicted order, pre-defined order and model, human expert selection, and RestoreAgent. The performance is measured using PSNR, SSIM, LPIPS, and DISTS metrics, with a ‘balanced’ score combining all four. The table also shows the ranking of each method among all possible decision combinations.
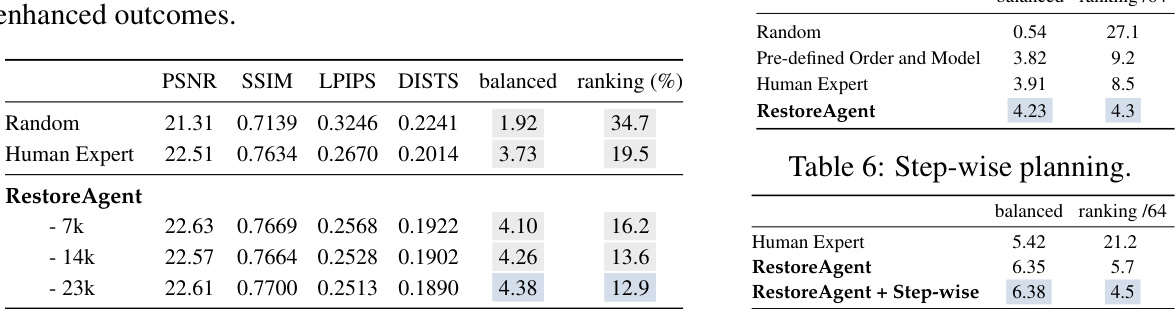
This table presents a comparison of RestoreAgent’s performance against several other decision-making strategies for multi-degraded image restoration across three different types of image degradations. The strategies compared include random order and model selection, a combination of random order and RestoreAgent model prediction, random model selection with predicted order, a pre-defined human expert order and model, a human expert selecting the optimal models and order, and finally the proposed RestoreAgent method. Performance is evaluated using four metrics: PSNR, SSIM, LPIPS, and DISTS, with a ‘balanced’ score combining them. Rankings of each method are given, showing RestoreAgent’s superiority.

This table compares the performance of RestoreAgent against other methods for restoring images with multiple degradations. It shows the PSNR, SSIM, LPIPS, and DISTS scores for each method across different degradation types. The ‘balanced’ score combines these metrics. The ‘ranking’ indicates the method’s position relative to others for each degradation type, and the final row averages the performance across all degradation types.
This table compares the performance of RestoreAgent against four other decision-making strategies for image restoration involving multiple degradations. These strategies include random task order and model selection, combining random order with RestoreAgent’s predicted model, combining random model selection with RestoreAgent’s predicted order, and a pre-defined task order and model. Human expert performance is also included as a benchmark. The table presents the results across multiple metrics (PSNR, SSIM, LPIPS, DISTS) for different degradation combinations and shows the average result across all datasets. The ‘balanced’ score combines the four metrics and the ‘ranking’ shows the performance relative to all possible decision combinations.
Full paper#