↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Multimodal Sentiment Analysis (MSA) struggles with real-world data where information from different modalities (text, audio, visual) may be incomplete. This incompleteness significantly reduces the accuracy of MSA models. Existing methods either use complex feature interactions, prone to error accumulation, or lack proper semantic alignment, resulting in inaccurate predictions.
This paper proposes a novel Hierarchical Representation Learning Framework (HRLF) to resolve these issues. HRLF uses a three-pronged approach: 1) Fine-grained Representation Factorization disentangles modality-specific and sentiment-relevant features, enhancing the robustness; 2) Hierarchical Mutual Information Maximization progressively aligns multi-scale representations, refining sentiment understanding; and 3) Hierarchical Adversarial Learning further aligns latent distributions of representations, improving the overall robustness. Extensive experiments demonstrate HRLF’s superior performance across multiple datasets with different missing data scenarios.
Key Takeaways#
Why does it matter?#
This paper is important because it tackles the crucial problem of missing data in multimodal sentiment analysis (MSA), a common issue in real-world applications. The proposed solution, a Hierarchical Representation Learning Framework (HRLF), offers a novel approach to handle incomplete data, improving the robustness and accuracy of MSA models. This work is highly relevant to current trends in robust AI and opens new avenues for research in handling incomplete data in various machine learning tasks.
Visual Insights#

This figure shows an example of how missing modalities can lead to incorrect predictions in traditional multimodal sentiment analysis models. In the top example, all modalities (language, audio, and visual) are present, and the model correctly predicts a negative sentiment. In the bottom example, parts of the language and audio modalities, and some visual frames, are missing, causing the model to incorrectly predict a positive sentiment. The pink areas highlight intra-modality missingness (missing frames within a modality), while the yellow areas show inter-modality missingness (entire modalities missing). This illustrates the challenge of handling incomplete data in multimodal sentiment analysis.

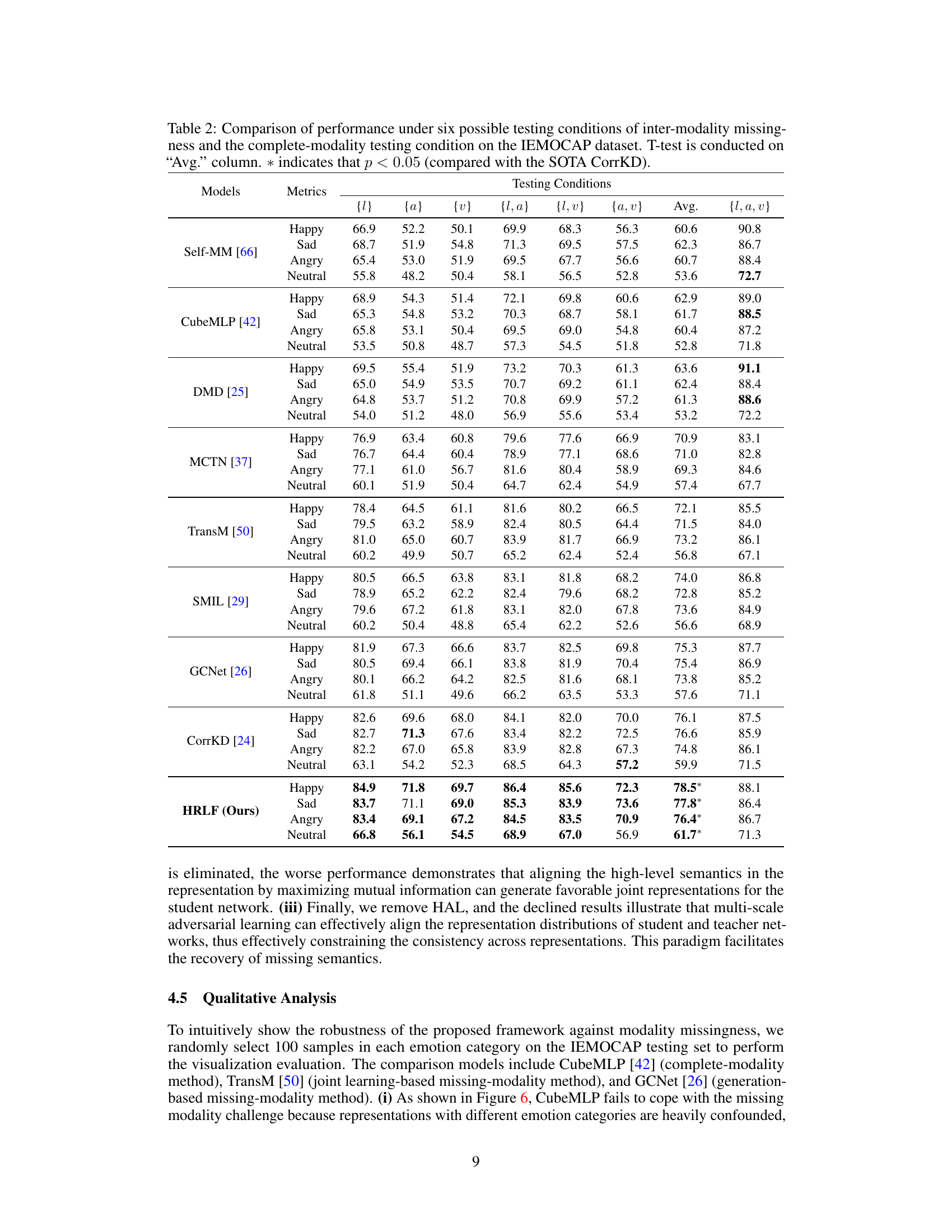
This table compares the performance of various models on the MOSI and MOSEI datasets under different conditions of missing modalities. It shows the average F1 scores for each model under six scenarios of missing data (only one modality available, two modalities available etc.), and also includes results when all modalities are available. The results are statistically analyzed using a t-test to compare against the state-of-the-art (SOTA) CorrKD model, highlighting significant improvements of the proposed HRLF model.
In-depth insights#
Robust MSA#
Robust Multimodal Sentiment Analysis (MSA) tackles the challenge of accurately interpreting sentiment from multiple modalities (text, audio, video) even when data is incomplete or noisy. A key focus is handling missing modalities, a common real-world scenario where some data might be unavailable due to technical issues or privacy concerns. Existing methods often struggle with this, leading to inaccurate sentiment predictions. Robust MSA aims to develop models that are resilient to these imperfections, producing reliable results despite data incompleteness. This involves designing techniques to either estimate missing data (imputation), or build models that can effectively learn from incomplete data without needing to fill in the gaps. The ultimate goal is increased reliability and generalizability of MSA systems across various real-world applications where perfect data is unrealistic.
HRLF Framework#
The Hierarchical Representation Learning Framework (HRLF) for robust incomplete multimodal sentiment analysis is a novel approach designed to address challenges posed by missing modalities in real-world applications. Its core innovation lies in a three-stage process: First, fine-grained representation factorization disentangles modality-specific and sentiment-relevant features, improving robustness to missing data. Second, hierarchical mutual information maximization aligns multi-scale representations across modalities, strengthening cross-modal interactions. Finally, hierarchical adversarial learning refines the latent distribution of sentiment representations, ensuring more robust predictions. This framework offers a significant advancement by addressing issues with existing methods that often struggle with incomplete data and generating non-robust joint representations. The three components work synergistically, demonstrating a unique strength in mitigating the adverse effects of missing information while significantly improving performance across various datasets. The integration of factorization, information maximization, and adversarial learning makes HRLF particularly well-suited to handling the uncertainties inherent in real-world multimodal data.
Factorized Learning#
Factorized learning approaches aim to decompose complex representations into simpler, disentangled components. This is particularly valuable in multimodal settings where data from different modalities (e.g., text, audio, video) needs to be integrated. By separating modality-specific features from shared, sentiment-relevant features, factorized models improve robustness to missing modalities, a common problem in real-world applications. This disentanglement allows the model to focus on the sentiment information while filtering out noise or irrelevant modality-specific characteristics. Such a decomposition can also increase model interpretability, making it easier to understand how different modalities contribute to the overall sentiment prediction. A key challenge in factorized learning lies in designing effective mechanisms to achieve this separation of components and to ensure that important information is not lost in the process. Different approaches exist, such as using autoencoders, variational autoencoders, or generative adversarial networks, each with its own strengths and weaknesses. The effectiveness of a factorized approach highly depends on the specific dataset and task, requiring careful consideration of the chosen method and hyperparameter tuning.
Multimodal Distillation#
Multimodal distillation, in the context of research papers, is a technique that leverages the strengths of multiple modalities (text, audio, video) to enhance the learning process. It’s particularly useful when dealing with incomplete or noisy data. The core idea is to transfer knowledge from a teacher model trained on complete, high-quality multimodal data to a student model trained on incomplete or noisy data. This transfer helps the student model learn better representations despite missing or corrupted information. The process often involves distilling not just the final predictions but also intermediate representations from the teacher to improve the student’s understanding of the underlying patterns. This is a powerful approach because it takes advantage of the complementary information available in different modalities. However, a key challenge lies in effectively aligning and transferring information across modalities, especially when significant data is missing from one or more modalities. Successful multimodal distillation requires careful consideration of feature extraction, representation alignment, and knowledge transfer mechanisms to optimize student model performance. Research often explores methods to factorize modality-specific information from modality-invariant aspects to improve robustness and generalization. This allows the student model to learn from the complementary information even in the presence of missing modalities.
Ablation Studies#
Ablation studies systematically remove components of a model to assess their individual contribution. In this context, it is crucial to carefully select which components to ablate. Removing essential elements might lead to drastic performance drops, while minor components may show little to no impact. The results should be interpreted cautiously, acknowledging the limitations of such an approach. The goal is to demonstrate the necessity and impact of each component, and not simply to find the minimal working model. Robustness is key: If small changes in the model lead to large performance fluctuations, then it suggests a fragile architecture. Ideally, ablation studies should be designed such that the results can be generalized to similar systems rather than specific implementations. A successful ablation study should provide clear insights into the model’s design and the interplay between its different parts, providing a better understanding of why it works as it does.
More visual insights#
More on figures
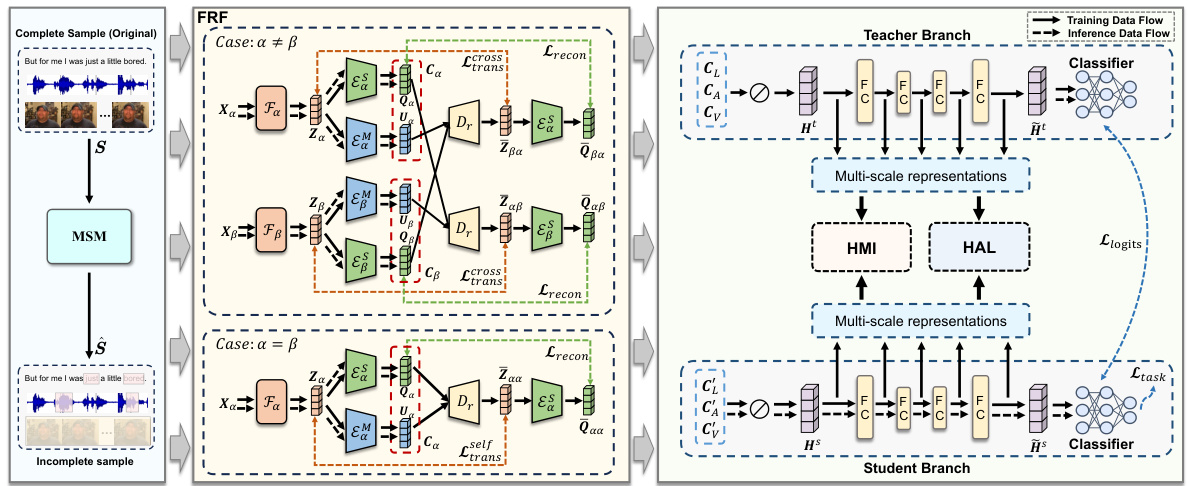
This figure illustrates the architecture of the Hierarchical Representation Learning Framework (HRLF) for robust incomplete multimodal sentiment analysis. It shows three main modules: Fine-grained Representation Factorization (FRF), which disentangles modality representations into sentiment-relevant and modality-specific parts; Hierarchical Mutual Information (HMI) maximization, which aligns multi-scale representations between teacher and student networks; and Hierarchical Adversarial Learning (HAL), which refines the latent distributions of these representations. The figure depicts the data flow during training (teacher branch and student branch learning together) and inference (only student branch). The FRF module is central, showing how it processes both complete and incomplete samples (with intra- and inter-modality missing data), using intra- and inter-modality translations and reconstruction to extract sentiment information even with missing data.

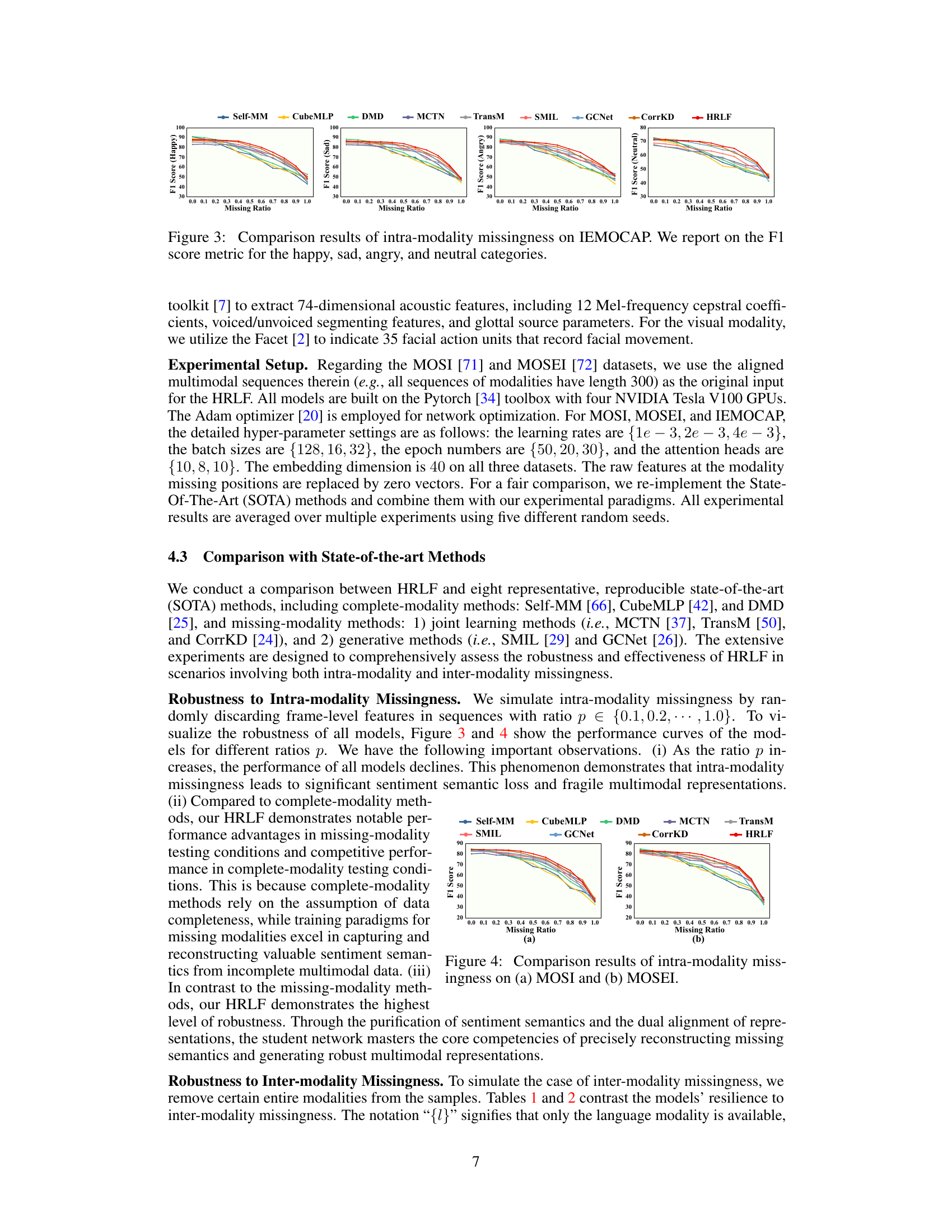
This figure shows the performance of different models on the IEMOCAP dataset when facing intra-modality missingness. The x-axis represents the missing ratio (from 0 to 1), and the y-axis represents the F1 score for each of the four emotion categories (happy, sad, angry, and neutral). The lines represent different models, showing how their performance degrades as the missing ratio increases.
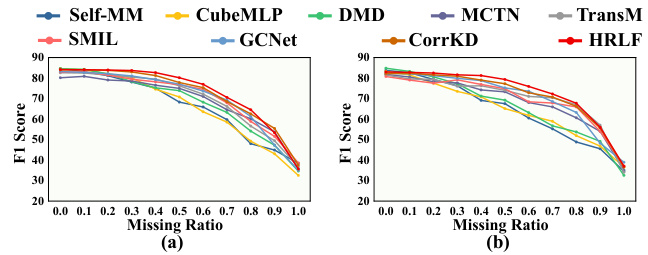
This figure shows the performance of different models on the IEMOCAP dataset under varying levels of intra-modality missingness. Intra-modality missingness refers to situations where some frames within a given modality (language, audio, or visual) are missing. The x-axis represents the missing ratio (from 0 to 1), and the y-axis shows the F1 score, a common metric for evaluating the accuracy of classification models. The results are broken down by emotion category (happy, sad, angry, neutral). This graph helps to visualize and understand the robustness of each model when facing incomplete data. HRLF, the proposed model, is highlighted in red.
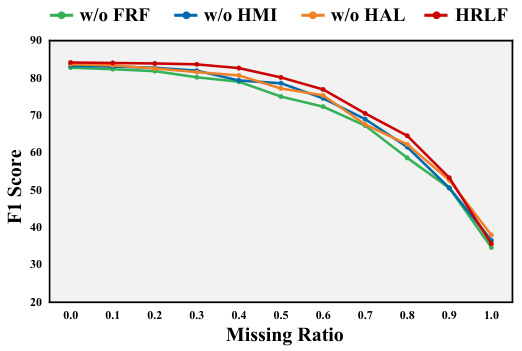
This figure shows the ablation study results on the MOSI dataset for intra-modality missingness. It compares the performance of the proposed HRLF model against versions where key components (Fine-grained Representation Factorization (FRF), Hierarchical Mutual Information (HMI) maximization, and Hierarchical Adversarial Learning (HAL)) have been removed. The x-axis represents the missing ratio (percentage of missing features), and the y-axis represents the F1 score. The plot shows that removing any one of the three components significantly reduces the F1 score, demonstrating their importance to the overall performance of HRLF. The HRLF model consistently achieves the highest F1 score across all missing ratios.

This figure visualizes the representations learned by four different models (CubeMLP, TransM, GCNet, and HRLF) for four emotion categories on the IEMOCAP dataset. The visualization uses t-SNE to project the high-dimensional representations into a 2D space. The results show that HRLF produces more distinct and separable clusters for each emotion category, suggesting better performance in distinguishing emotions, especially under the condition of missing modalities.
Full paper#