↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Deploying deep neural networks on resource-limited devices like microcontrollers (MCUs) is challenging due to memory constraints and the need for continuous adaptation to changing environments. Test-time adaptation (TTA) offers a potential solution, but existing methods struggle with the memory demands of backpropagation and the lack of normalization layer support on MCUs. This leads to either memory exhaustion or poor performance.
TinyTTA addresses these limitations by introducing a novel self-ensemble early-exit strategy and a weight standardization technique. This method reduces memory usage significantly, enabling continuous adaptation with small batches. The researchers also developed a dedicated MCU library, TinyTTA Engine, to facilitate on-device TTA implementation. Their experiments demonstrate that TinyTTA significantly improves TTA accuracy and efficiency on various devices, including resource-constrained MCUs.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on edge AI and resource-constrained devices. It presents a novel solution for efficient test-time adaptation, a critical challenge in deploying machine learning models in real-world IoT scenarios. The proposed method, TinyTTA, and accompanying library pave the way for more adaptable and responsive AI applications in resource-limited environments, opening up exciting avenues of research in model optimization and on-device learning.
Visual Insights#
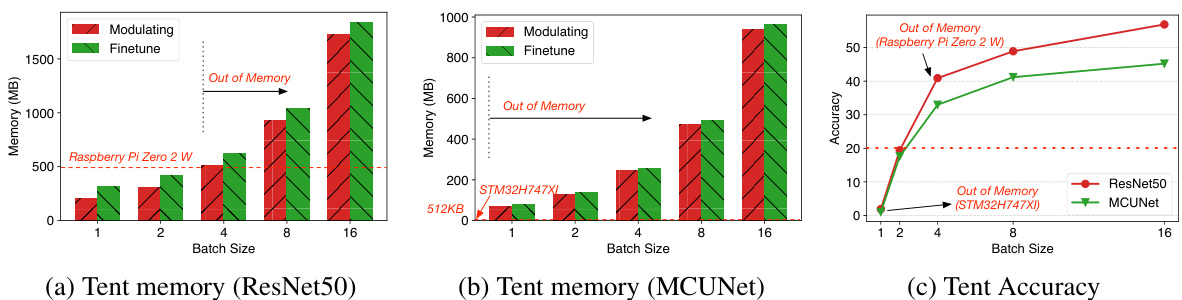
This figure shows the results of a motivation study that compares the memory usage and accuracy of modulating and fine-tuning test-time adaptation (TTA) methods on different hardware platforms (Raspberry Pi Zero 2W and STM32H747 MCU) and different batch sizes. The results demonstrate that both modulating and fine-tuning TTA methods are memory-intensive, leading to out-of-memory issues on resource-constrained devices, especially at larger batch sizes. Also, the accuracy of TTA methods is highly dependent on the batch size, with smaller batch sizes resulting in lower accuracy. This highlights the challenges of applying TTA to resource-constrained devices.
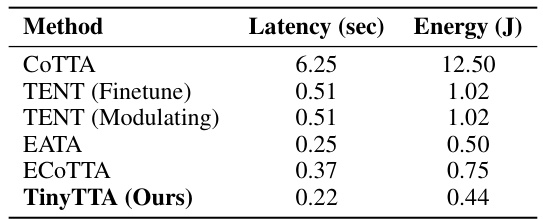
This table presents the latency and energy consumption per image for different Test-Time Adaptation (TTA) methods evaluated on the CIFAR10C dataset using a Raspberry Pi Zero 2W. It compares the efficiency of TinyTTA against other state-of-the-art TTA methods, demonstrating its superior performance in terms of both reduced latency and energy consumption.
In-depth insights#
TinyTTA: On-device TTA#
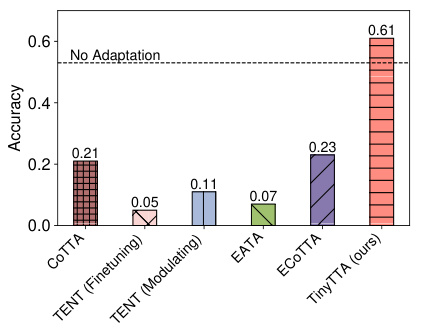
TinyTTA presents a novel approach to on-device test-time adaptation (TTA), addressing the limitations of existing methods in resource-constrained environments. Its core innovation lies in a self-ensemble early-exit strategy, partitioning the pre-trained model into submodules and allowing samples to exit early based on confidence, thus reducing computational and memory overhead. This is particularly crucial for microcontrollers (MCUs) with limited resources. The use of weight standardization (WS) further enhances efficiency, replacing traditional normalization layers which are often resource-intensive. TinyTTA Engine, a custom MCU library, facilitates the practical deployment of this framework, showcasing its feasibility on real-world edge devices. The results demonstrate significant accuracy improvements and reduced resource usage compared to existing baselines, highlighting TinyTTA’s potential to enable efficient TTA on a wider range of resource-constrained devices.
Self-Ensemble TTA#
Self-Ensemble Test-Time Adaptation (TTA) represents a novel approach to enhance the efficiency and adaptability of deep learning models, particularly in resource-constrained environments. The core idea involves partitioning a pre-trained model into smaller, self-contained submodules. Each submodule approximates the full model’s capabilities, allowing for early exits during inference, based on a confidence measure, thus significantly reducing computational costs. Early exits are crucial for efficiency, as samples with high confidence can be predicted quickly by early submodules, whereas those with low confidence or significant distribution shifts require further processing through subsequent submodules. This approach intelligently balances efficiency and accuracy, dynamically adapting to varying levels of distribution shift and memory constraints. The self-ensemble structure is key to managing memory limitations since it avoids the substantial memory overhead associated with conventional TTA methods that involve backpropagation through the entire network. By cleverly grouping similar layers into submodules, the technique also addresses the challenge of limited memory often found on resource-constrained edge devices. This method therefore provides a promising path for deploying adaptable and computationally efficient deep learning models in real-world, resource-scarce scenarios.
Early-exit Strategy#
The early-exit strategy, a crucial component of TinyTTA, addresses the inherent memory limitations of edge devices by enabling efficient test-time adaptation (TTA). Instead of processing each sample through the entire pre-trained network, TinyTTA partitions the network into submodules and allows samples to exit early from specific submodules based on predicted confidence. This significantly reduces computational overhead. Samples easily classified with high confidence exit early, bypassing subsequent layers. Those requiring more processing continue until a reliable prediction is achieved. This design not only enhances efficiency but also accommodates mixed distribution shifts, adapting dynamically to varying levels of data shift. Early-exit and self-ensembling combined enable continuous adaptation with smaller batch sizes, further reducing memory consumption and improving latency on constrained hardware. The confidence level, a hyperparameter determined via entropy calculation, guides the early-exit decision, ensuring that only necessary processing occurs. This adaptive approach improves accuracy and efficiency while remaining practical for deployment on resource-constrained edge devices.
WS-based Normalization#
The paper introduces a novel normalization technique called Weight Standardization (WS), designed to address the limitations of traditional normalization layers within the context of Test-Time Adaptation (TTA) on memory-constrained edge devices. Unlike Batch Normalization (BN) or Group Normalization (GN), which normalize activations, WS normalizes weights. This offers several key advantages. First, it eliminates the need for storing and updating batch statistics, which is crucial for memory-limited settings like microcontrollers (MCUs). Second, WS is inherently batch-agnostic, meaning its performance is unaffected by batch size, unlike BN and GN, which often suffer accuracy degradation with small batch sizes. Third, WS avoids the need for explicit normalization layers commonly fused with convolutional layers in MCU implementations, simplifying the deployment process and reducing complexity. By directly standardizing weights, WS effectively mimics the effect of normalization layers without the memory overhead, making it a particularly suitable choice for efficient TTA on resource-constrained edge devices.
MCU Deployment#
The successful deployment of TinyTTA on MCUs represents a significant advancement in the field of edge AI. The STM32H747 MCU, with its limited 512KB SRAM, posed a considerable challenge, necessitating careful optimization strategies. TinyTTA’s efficiency stems from its innovative self-ensemble and early-exit mechanisms, significantly reducing memory footprint and computational overhead. The development of the TinyTTA Engine, a custom MCU library, was crucial, providing the necessary backward propagation capabilities within the constrained hardware environment. The successful implementation showcases the feasibility of deploying sophisticated TTA frameworks on resource-scarce MCUs. TinyTTA’s performance on the MCU surpasses existing TTA methods, achieving higher accuracy while simultaneously consuming less memory and power. This accomplishment highlights the effectiveness of TinyTTA’s design choices and the potential for widespread application of similar methods across different edge devices. The MCU deployment results establish TinyTTA as a pioneering framework enabling real-time, on-device adaptation in resource-constrained environments, paving the way for more sophisticated edge AI applications.
More visual insights#
More on figures

This figure illustrates the TinyTTA framework, showcasing its four key modules: (a) self-ensemble network partitioning the pre-trained model into submodules for memory efficiency, (b) early exits to optimize inference based on confidence levels, (c) weight standardization (WS) for batch-agnostic normalization, and (d) the TinyTTA Engine for on-device deployment on MCUs and MPUs. The diagram visually represents the flow of data and the functionality of each module within the TinyTTA framework.

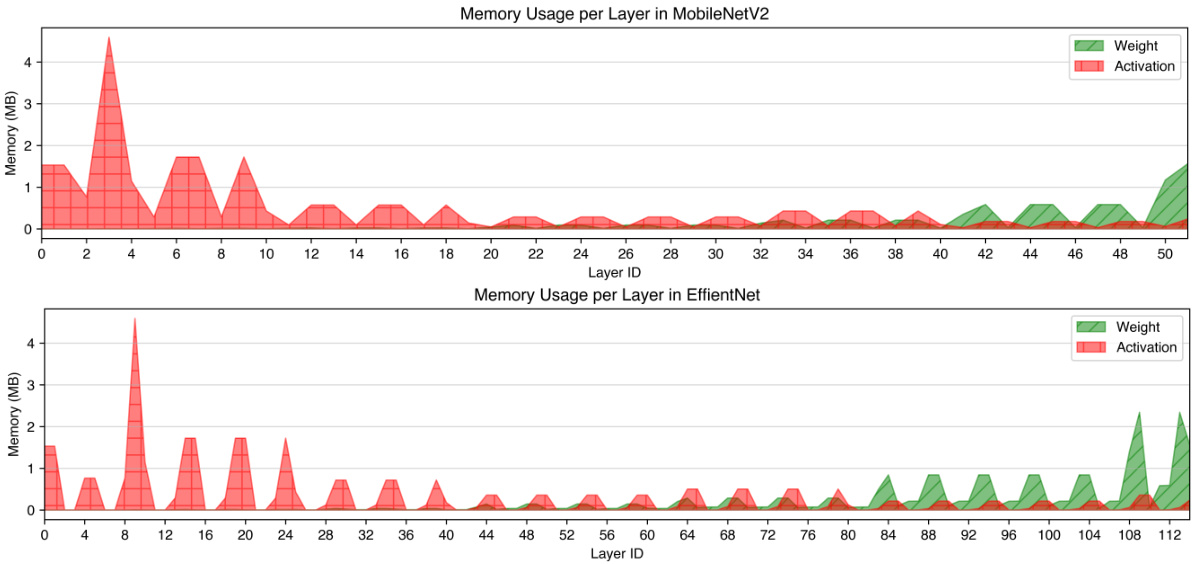
This figure shows the memory usage (in MB) per layer during fine-tuning and modulation-based test-time adaptation (TTA) using ResNet50 on CIFAR-10 dataset with batch size of 1. It highlights that both methods show significant memory usage for activations, whereas the memory used for weights is minimal. This observation emphasizes the challenge in adapting models with limited memory on edge devices.

This figure illustrates the TinyTTA Engine’s two-phase operation: compile time and execution time. During compile time, the pre-trained model is processed. Backbone operations are fused to improve efficiency and the backpropagation is enabled for TinyTTA exits. Then the backbone is frozen and quantized. During execution time, the optimized model is loaded onto the MCU to perform on-device TTA.
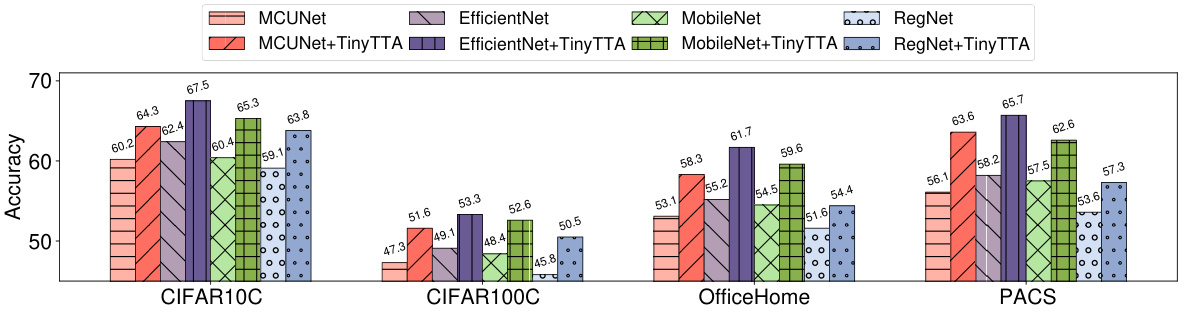
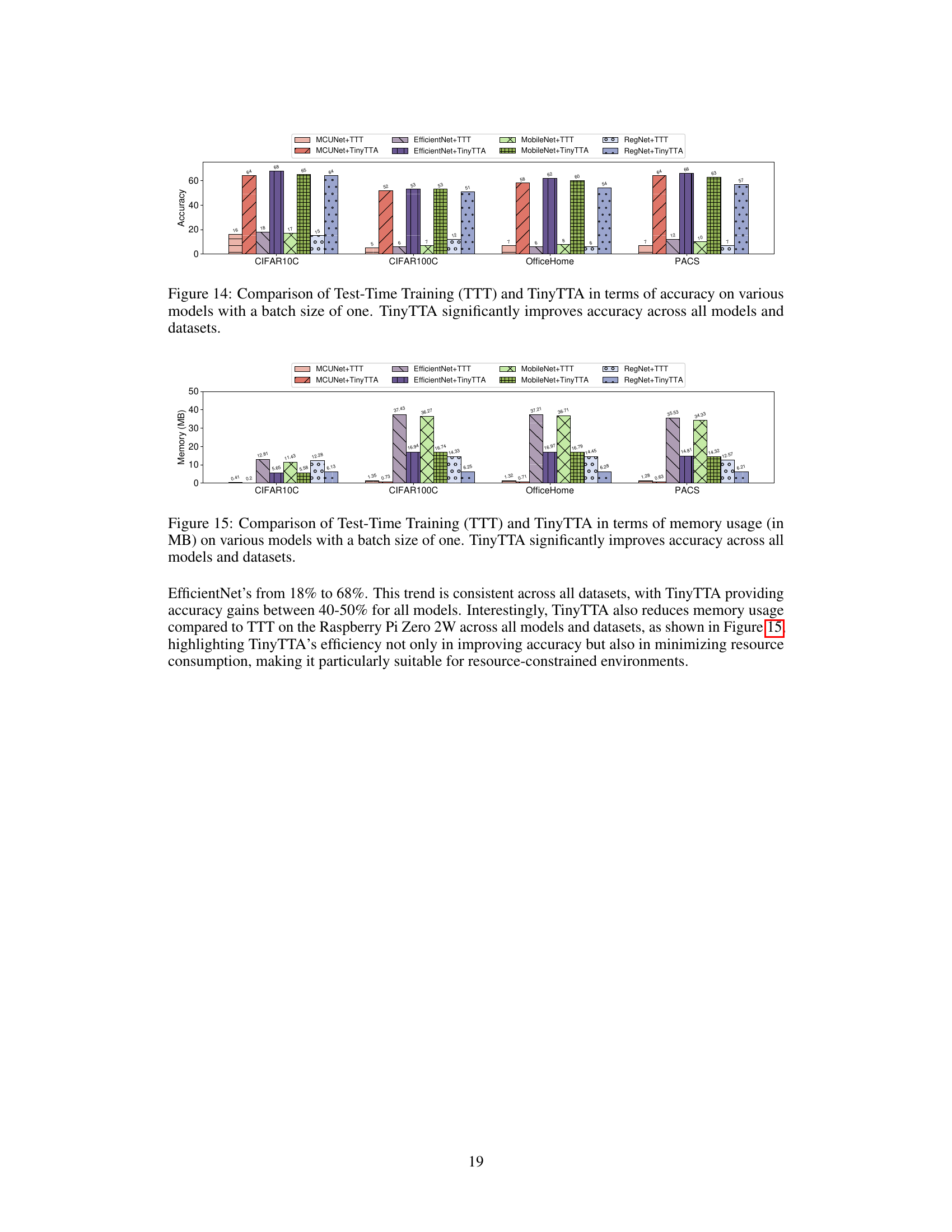
This figure compares the performance of four different models (MCUNet, EfficientNet, MobileNet, and RegNet) on four datasets (CIFAR10C, CIFAR100C, OfficeHome, and PACS) with and without TinyTTA. It shows that TinyTTA consistently improves the accuracy of all models across all datasets, highlighting its effectiveness in adapting to various distribution shifts.

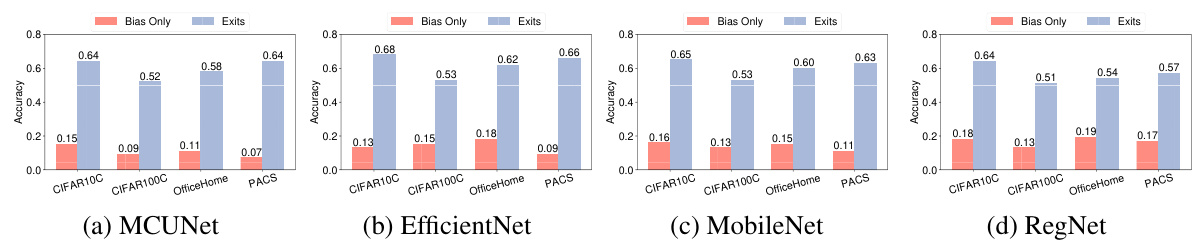
This figure compares the performance of TinyTTA with other state-of-the-art Test Time Adaptation (TTA) methods across four different datasets (CIFAR10C, CIFAR100C, OfficeHome, PACS) and four different model architectures (MCUNet, EfficientNet, MobileNet, RegNet). The key takeaway is that TinyTTA achieves the best accuracy while using significantly less memory, especially on resource-constrained MCUs. Part (a) highlights TinyTTA’s unique ability to perform TTA on MCUs. Parts (b-d) visually demonstrate TinyTTA’s superior performance in terms of accuracy and memory efficiency for the other model architectures.

This ablation study shows the trade-offs between accuracy and memory usage for different configurations of TinyTTA across four datasets. The configuration using all components (self-ensembles, early-exits, and WS) achieves the best balance between accuracy and memory. Removing components individually results in decreased accuracy and/or increased memory usage, highlighting the importance of each component for optimal performance.

This figure compares the performance of modulating and fine-tuning methods for test-time adaptation (TTA) under different levels of domain shift. It shows that for larger domain shifts (severity level 5), the modulating model tends to collapse and predict fewer classes, while for smaller domain shifts (severity level 3), the modulating method is more robust than fine-tuning. The experiments use ImageNet-C with fog noise and the ResNet50 model.

This figure compares the accuracy of TinyEngine (using TENT) and TinyTTA on four different datasets (CIFAR10C, CIFAR100C, OfficeHome, and PACS) and four different model architectures (MCUNet, EfficientNet, MobileNet, and RegNet). The results show that TinyTTA consistently outperforms TinyEngine, demonstrating the effectiveness of its dynamic early exit mechanism for adapting to varying data distributions.
This figure presents a motivation study comparing different Test-Time Adaptation (TTA) methods. Subfigures (a) and (b) show the memory usage of modulating and fine-tuning TTA methods on Raspberry Pi Zero 2W and STM32H747 respectively, highlighting the memory-intensive nature of these methods and the resulting out-of-memory issues on resource-constrained devices. Subfigure (c) demonstrates the strong dependence of TTA accuracy on the batch size, suggesting that larger batch sizes are typically necessary for satisfactory performance but are often impractical on resource-limited devices.
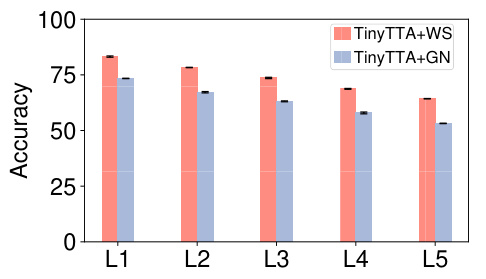
This figure compares the performance of TinyTTA using Weight Standardization (WS) and Group Normalization (GN) across various levels of distribution shifts (L1 to L5) in the CIFAR-10C dataset. The results show TinyTTA with WS consistently outperforming TinyTTA with GN across all levels, highlighting the effectiveness of WS in maintaining accuracy under distribution shifts.
This figure compares the performance of different Test-Time Adaptation (TTA) methods on the Musan Keywords Spotting test dataset using the MicroNets model. The Musan dataset is a challenging, real-world dataset with various noisy audio conditions, making it a good test for the robustness of TTA techniques. TinyTTA significantly outperforms the other methods, demonstrating its resilience to noise and its ability to maintain high accuracy even with noisy or distorted data. The results highlight the effectiveness of TinyTTA in real-world scenarios where adaptation to changing environments is critical.
This figure shows the results of a motivation study comparing different test-time adaptation (TTA) methods. Subfigures (a) and (b) illustrate that both modulating and fine-tuning TTA methods consume a large amount of memory, resulting in out-of-memory errors when deployed on resource-constrained devices like microcontrollers (MCUs). Subfigure (c) demonstrates that the accuracy of TTA methods is highly dependent on batch size, indicating a trade-off between memory usage and performance.

This figure compares the performance of four different model architectures (MCUNet, EfficientNet, MobileNet, and RegNet) on four corrupted datasets (CIFAR10C, CIFAR100C, OfficeHome, and PACS) with and without using TinyTTA for test-time adaptation. The results show that TinyTTA consistently improves the accuracy of all models on all datasets, even when adapting to only a single batch of data.

This figure presents a comparison of model performance with and without TinyTTA across four different datasets (CIFAR10C, CIFAR100C, OfficeHome, and PACS) using four different model architectures (MCUNet, EfficientNet, MobileNet, and RegNet). The bar chart visually represents the accuracy achieved by each model both with and without TinyTTA. The results show that TinyTTA consistently improves the accuracy of all models across all datasets, highlighting its effectiveness in improving model adaptability and robustness.
More on tables

This table presents a comparison of the performance of the baseline model (Inference Only) and TinyTTA on a STM32H747 microcontroller unit (MCU) using the MCUNet model and the CIFAR10C dataset. It shows the accuracy achieved, the SRAM and Flash memory usage, the latency, and the energy consumption for both models. The results highlight TinyTTA’s ability to improve accuracy while maintaining efficiency in a resource-constrained environment.
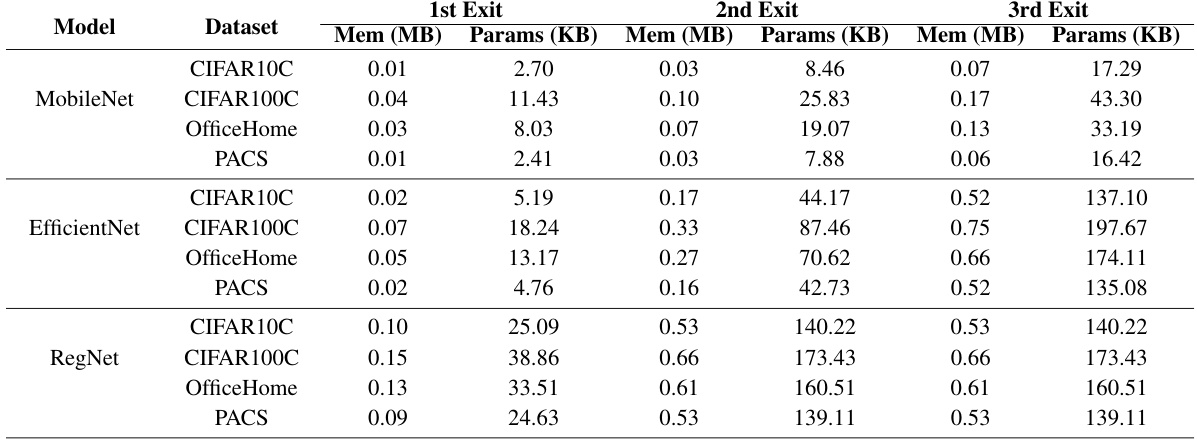
This table presents the memory overhead (in MB) and the number of additional parameters (in KB) introduced by adding early-exit branches to three different model architectures (MobileNet, EfficientNet, and RegNet) across four different datasets (CIFAR10C, CIFAR100C, OfficeHome, and PACS). The table shows the overhead for each of the three early exits added to each model. For example, for MobileNet on CIFAR10C, the first early exit adds 0.01 MB of memory and 2.70 KB of parameters, while the third early exit adds 0.07 MB of memory and 17.29 KB of parameters. The table highlights the relatively low memory overhead and parameter increase introduced by the early exit branches, even for larger and more complex models like EfficientNet and RegNet.
Full paper#