↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Current novel view synthesis (NVS) and 3D generation methods often struggle with generalization to real-world scenes and heavily rely on accurate camera poses. This limits their practical applicability for complex 3D scene editing tasks like object removal, insertion, and replacement. Many existing approaches also suffer from multi-view inconsistencies and high computational costs.
MVInpainter tackles these issues by reformulating 3D editing as a multi-view 2D inpainting problem. Instead of generating entirely new views, it partially inpaints multiple views guided by a reference image, significantly reducing complexity. The method uses video priors for motion consistency, appearance guidance from concatenated reference features, and slot attention for implicit pose control, eliminating the need for explicit camera poses. Experiments across object-centric and forward-facing datasets demonstrate MVInpainter’s effectiveness in diverse tasks, showing improved performance and generalization compared to existing methods.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel approach to 3D scene editing that simplifies the complex problem of multi-view consistency by framing it as a multi-view 2D inpainting task. This significantly reduces the reliance on accurate camera poses, a major limitation of many existing 3D editing methods, opening up possibilities for real-world applications. Furthermore, the proposed method’s high-level optical flow control improves its scalability and applicability. It provides a unified framework for both 2D and 3D editing, facilitating further research on integrating 2D generative models into 3D scene editing.
Visual Insights#
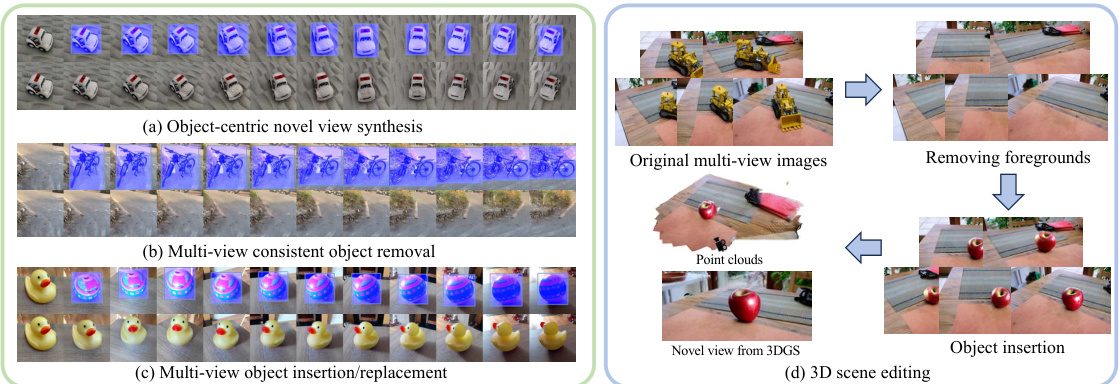
This figure showcases the capabilities of MVInpainter in handling various 2D and 3D editing tasks. Panel (a) demonstrates novel view synthesis, where a single edited image is used to generate consistent views. Panel (b) shows multi-view object removal, where the object is removed from multiple views in a consistent manner. Panel (c) illustrates multi-view object insertion/replacement, where objects are inserted or replaced in various viewpoints, maintaining consistency across the views. Lastly, panel (d) demonstrates MVInpainter’s application in real-world 3D scene editing using methods such as Dust3R, Multi-View Stereo, and 3D Gaussian Splatting for generating consistent 3D outputs.

This table presents a quantitative comparison of object-centric novel view synthesis (NVS) methods on the CO3D and MVImgNet datasets. It includes metrics such as PSNR, LPIPS, FID, and KID to evaluate the quality and consistency of the generated views. The Omni3D dataset is used as a zero-shot test set to assess generalization capabilities. Enlarged bounding box masks were used to avoid issues related to masking shape leakage.
In-depth insights#
Multi-view Inpainting#
Multi-view inpainting, as a concept, presents a novel approach to 3D scene editing by extending the capabilities of 2D image manipulation. Instead of generating entirely new views from scratch, which is computationally expensive and prone to errors, this method focuses on inpainting (filling in missing regions) across multiple views of a scene simultaneously. This is achieved by utilizing a reference image, which is either a natural image or an image already modified using 2D editing tools. This edited reference acts as a guide to consistently complete the masked areas in other views, ensuring coherence across different perspectives. The core advantage lies in its simplicity and efficiency: it significantly reduces the complexity of novel view synthesis, and avoids the need for accurate camera pose estimation, making it more practical and robust for real-world applications. However, challenges remain in handling complex scenes with significant variations in lighting, shadow, and object occlusion across views, as well as in preserving fine details and ensuring seamless integration with the background. Future research should explore more sophisticated techniques for handling these challenges and expanding the method’s ability to synthesize more complex 3D scenes.
Pose-Free 3D Editing#
Pose-free 3D editing represents a significant advancement in computer vision and graphics, offering the potential to revolutionize how we interact with and manipulate 3D scenes. Traditional methods heavily rely on precise camera pose estimation, limiting their applicability to controlled environments and hindering real-world applications. Pose-free techniques aim to overcome this limitation by learning to edit 3D content directly from images without explicit knowledge of camera positions. This is achieved through sophisticated deep learning models that capture and reason about 3D scene geometry and appearance from 2D observations. The challenge lies in achieving consistent edits across multiple viewpoints without relying on accurate pose information. Success in pose-free 3D editing requires robust algorithms capable of handling variations in lighting, viewpoint, and occlusion, along with effective methods for synthesizing coherent 3D structures from 2D data. The potential benefits are substantial, including enhanced user experience in 3D modeling and animation software, more realistic and efficient virtual and augmented reality experiences, and improved accessibility to 3D editing tools for a wider range of users. Future research directions might explore more sophisticated deep learning architectures, improved methods for handling occlusions and ambiguity, and the integration of physics-based modeling to improve realism. Pose-free 3D editing is a rapidly evolving field with the potential to transform the way we interact with 3D digital content.
Ref-KV Attention#
The proposed Ref-KV attention mechanism is a novel approach to enhance multi-view consistency in image inpainting. It leverages the key and value features from a reference view (presumably a high-quality, edited view), concatenating them spatially with the corresponding features from the target views within the self-attention blocks of the U-Net architecture. This injection of reference information is crucial because it allows the model to better understand the appearance and context of the target regions, even when those regions are masked or incomplete. Unlike methods relying on full frame concatenation, Ref-KV’s spatial concatenation is more efficient, focusing only on relevant features and avoiding memory issues. The effectiveness of Ref-KV rests on its ability to guide the attention mechanism, thereby ensuring that the model generates consistent visual details across all views. This is a significant improvement over traditional approaches that struggle with cross-view consistency in 3D scene editing tasks, where preserving appearance and structural integrity is critical. The pose-free nature of Ref-KV further enhances its utility, making it suitable for scenarios with unreliable or missing camera pose information. Its integration with other components of the MVInpainter framework suggests that Ref-KV is a powerful tool that helps bridge the gap between 2D and 3D image editing.
Motion Priors#
Incorporating motion priors significantly enhances the accuracy and realism of video prediction and novel view synthesis. By leveraging pre-trained models on video data, the system gains an understanding of realistic temporal dynamics, enabling it to generate more plausible and consistent results across different views. This approach bypasses the need for explicit camera pose information, a significant advantage for real-world applications with varying or unknown viewpoints. The choice of a video model, and how its features are integrated into the framework, is crucial. Effective integration requires careful consideration of how to seamlessly blend video-based motion information with appearance information from other sources. This might involve techniques such as attention mechanisms, which selectively weigh the influence of video features and other modalities for accurate motion synthesis. Successfully integrating motion priors requires addressing potential challenges, such as handling inconsistencies between motion information and other visual cues, ensuring temporal coherence across the generated sequence, and managing computational costs. The effectiveness of motion priors relies on the quality and representativeness of the training data, hence the system’s ability to generalize to unseen scenarios depends heavily on the diversity and quality of the videos used for training the motion prior model.
Future Directions#
Future research could explore improving the robustness of MVInpainter to handle more complex scenes and diverse viewpoints, perhaps by incorporating more sophisticated 3D scene understanding models or employing techniques like neural radiance fields (NeRFs). Addressing the limitations of handling scenes with significant background changes or occlusions could enhance the method’s applicability. Another direction involves improving the efficiency of the pose-free flow grouping module or exploring alternative methods for implicit pose estimation. Improving the fidelity and efficiency of the multi-view consistent inpainting model could also be explored. Investigating the potential of extending MVInpainter to other modalities beyond RGB images, such as depth or point clouds, is another promising area. Finally, research could also focus on developing more sophisticated methods for generating and using masks, particularly in complex scenes, or exploring the use of more advanced masking techniques from recent literature, potentially allowing for more robust and effective object editing and insertion.
More visual insights#
More on figures

This figure shows the overall workflow of the MVInpainter model. It starts with a 2D inpainted image, then uses MVInpainter-F (for forward-facing scenes) for optional multi-view object removal. After that, MVInpainter-O (for object-centric scenes) is used for multi-view synthesis and/or object insertion. Finally, optional 3D reconstruction (using 3DGS and LPIPS) is done. The main contribution of the paper is highlighted as the multi-view inpainting part.
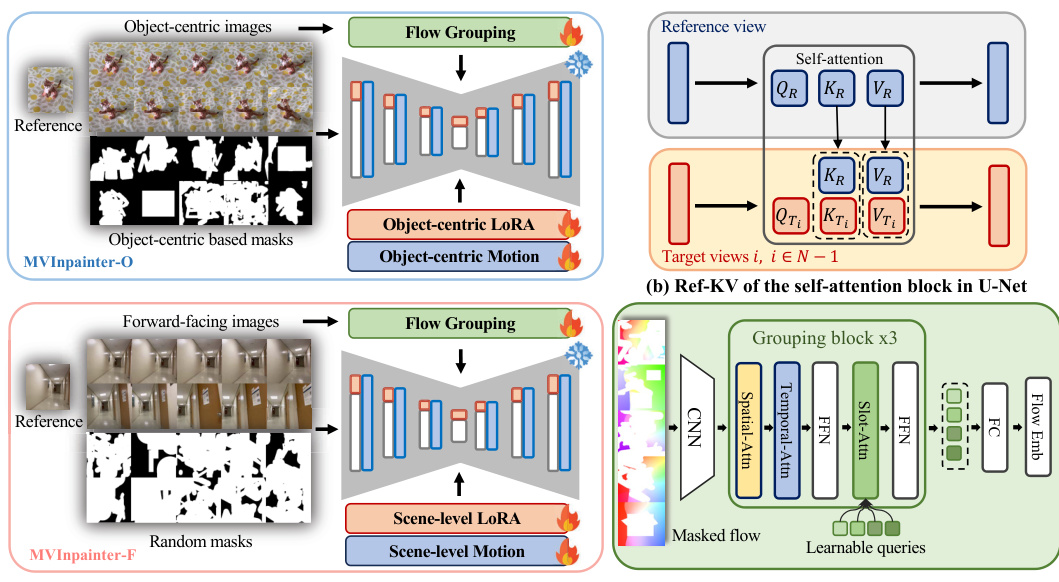
This figure shows the architecture of MVInpainter, a multi-view consistent inpainting model. It’s composed of three parts: an overview of the model’s framework, a detailed look at the Ref-KV (Reference Key & Value) concatenation used in the self-attention blocks, and an explanation of the slot-attention-based flow grouping used for pose-free learning. MVInpainter-O is trained on object-centric data for object-level novel view synthesis, while MVInpainter-F handles forward-facing data for object removal and scene-level inpainting.

This figure illustrates the inference pipeline of MVInpainter, a multi-view consistent inpainting model. It shows three key stages: (a) The overall pipeline which includes object removal (using MVInpainter-F), mask adaptation, and object insertion (using MVInpainter-O). (b) Details on the heuristic masking adaptation process, where masks are created based on the convex hull of identified object points. (c) Shows the perspective warping technique used to adapt the object’s perspective across different views, utilizing matches from a basic plane and the bottom face of the object, refined with Grounded-SAM to ensure accurate matching.

This figure shows a comparison of object-centric novel view synthesis (NVS) results on three datasets (CO3D, MVImgNet, and Omni3D) using four different methods: LeftRefill, Nerfiller, ZeroNVS, and the proposed MVInpainter. The first row displays the input masked images and the reference images. The subsequent rows present the generated results from each method for each input. The figure highlights the superior performance of MVInpainter in generating visually realistic and consistent views compared to other methods. The Omni3D results showcase MVInpainter’s zero-shot generalization capabilities.

This figure shows the inference pipeline of the proposed MVInpainter model. It demonstrates the three main stages: object removal, mask adaptation, and object insertion. Panel (b) details the heuristic masking adaptation process, illustrating how masks are created based on the convex hull of the object. Panel (c) describes the perspective warping technique used to accurately transform the object across multiple views. The process uses matches from a basic plane, which are filtered using the Grounded-SAM method [58], ensuring accurate perspective transformation.

This figure shows a qualitative comparison of the results obtained using different components of the MVInpainter model on the CO3D dataset. The top row displays the reference and masked input images. The second row shows the results without using video priors from AnimateDiff, while the third row presents the results with video priors. The fourth row shows the results without using Ref-KV (Reference Key&Value concatenation), while the fifth row displays the results with Ref-KV. The comparison illustrates the impact of these components on the appearance and consistency of the generated images across different viewpoints.

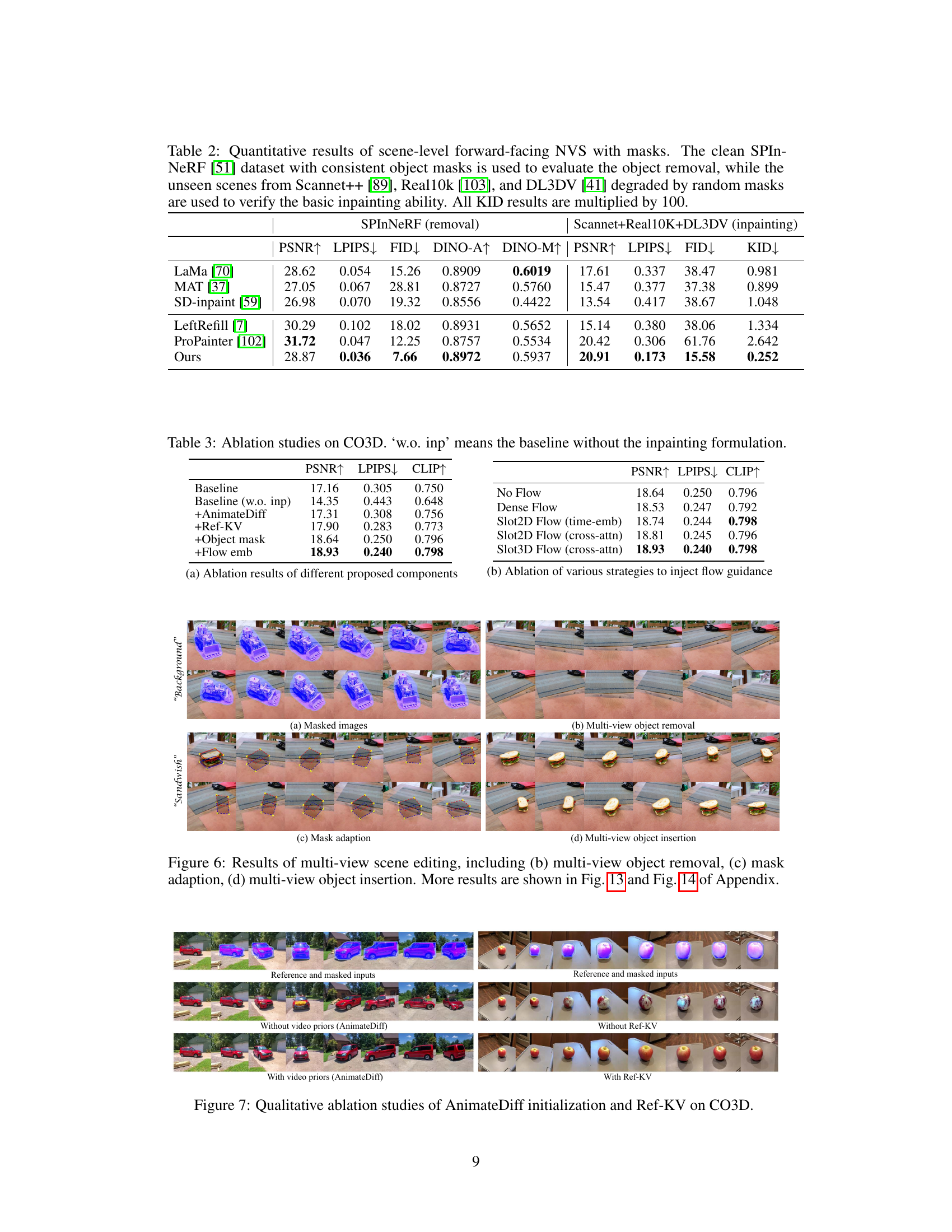
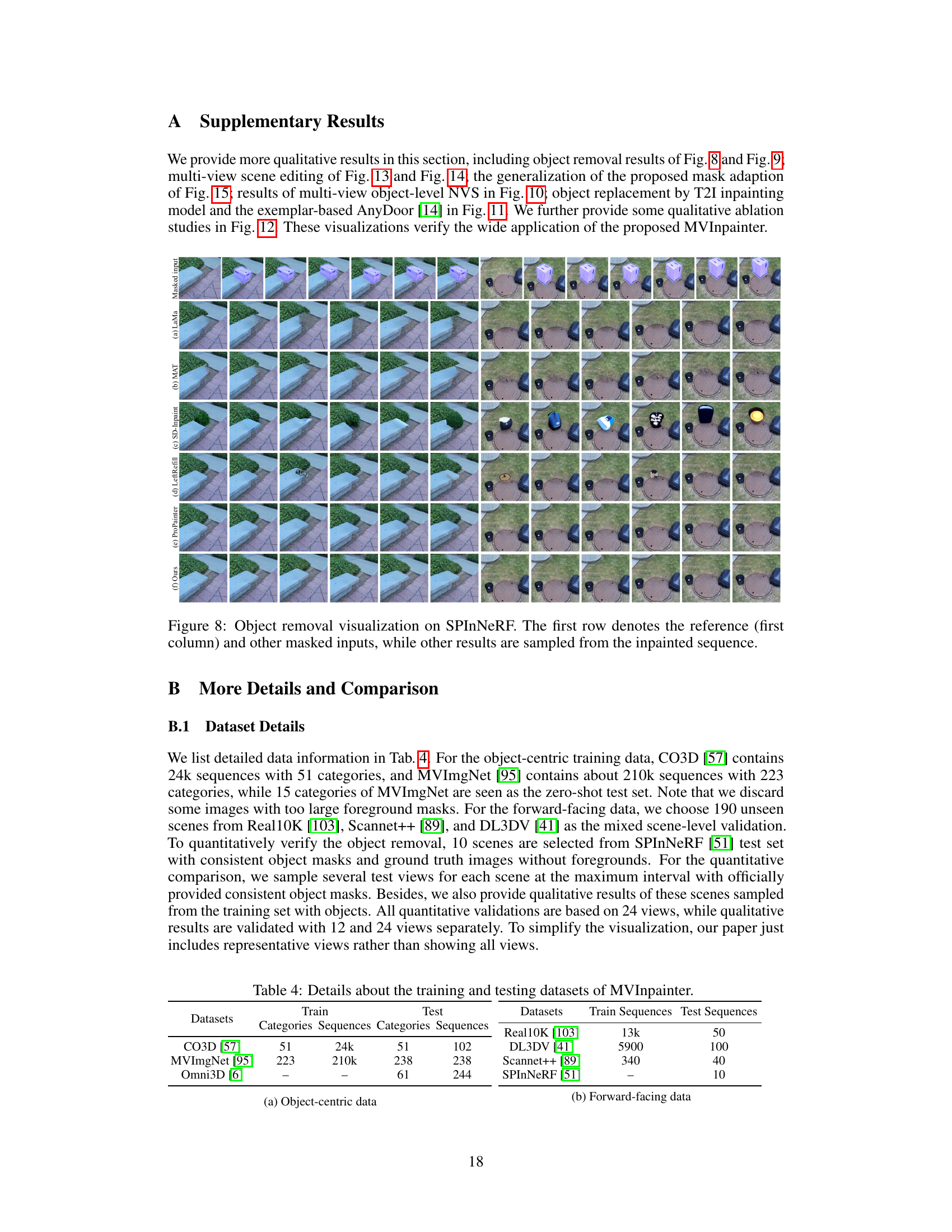
This figure shows a comparison of object removal results on the SPInNeRF dataset using different methods. The first row displays the masked input images, where the target object is missing. The subsequent rows present the results generated by various methods, including LaMa, MAT, SD-Inpaint, LeftRefill, ProPainter, and the proposed MVInpainter. The figure visually demonstrates the effectiveness of MVInpainter in generating visually appealing and consistent object removal results across multiple views.

This figure showcases the capabilities of MVInpainter in addressing various 2D and 3D editing tasks. It demonstrates the method’s ability to perform novel view synthesis (generating new views from existing ones), multi-view object removal (consistently removing an object from multiple viewpoints), and multi-view object insertion/replacement (consistently adding or replacing objects across different views). Importantly, the method achieves consistency without explicit camera pose information, making it applicable to real-world 3D scenes using point cloud data.

This figure demonstrates the capabilities of MVInpainter in various 2D and 3D editing tasks. (a) shows novel view synthesis, where a single edited view is extended to multiple consistent views. (b) illustrates multi-view object removal, showcasing consistent object removal across multiple views. (c) displays multi-view object insertion/replacement, where objects are added or replaced across views maintaining consistency. Finally, (d) shows how the model can extend to real-world 3D scene editing using point clouds generated from methods such as Dust3R and 3DGS, maintaining consistent object manipulation.

This figure shows the results of object replacement in multiple views using a text-to-image (T2I) inpainting model and the AnyDoor method. Different objects are shown being replaced or inserted into various scenes. The results demonstrate the capability of these methods to seamlessly integrate new objects into existing scenes while maintaining visual consistency across multiple viewpoints.

This figure shows a qualitative comparison of the results obtained using different flow guidance strategies in the MVInpainter model. The top row displays the reference images and masked inputs. Subsequent rows show results obtained without flow guidance, with dense flow guidance, and with slot-attention-based flow grouping. The comparison highlights how the choice of flow guidance impacts the inpainting results, particularly for challenging scenes involving significant viewpoint changes, such as stop signs and laptops.
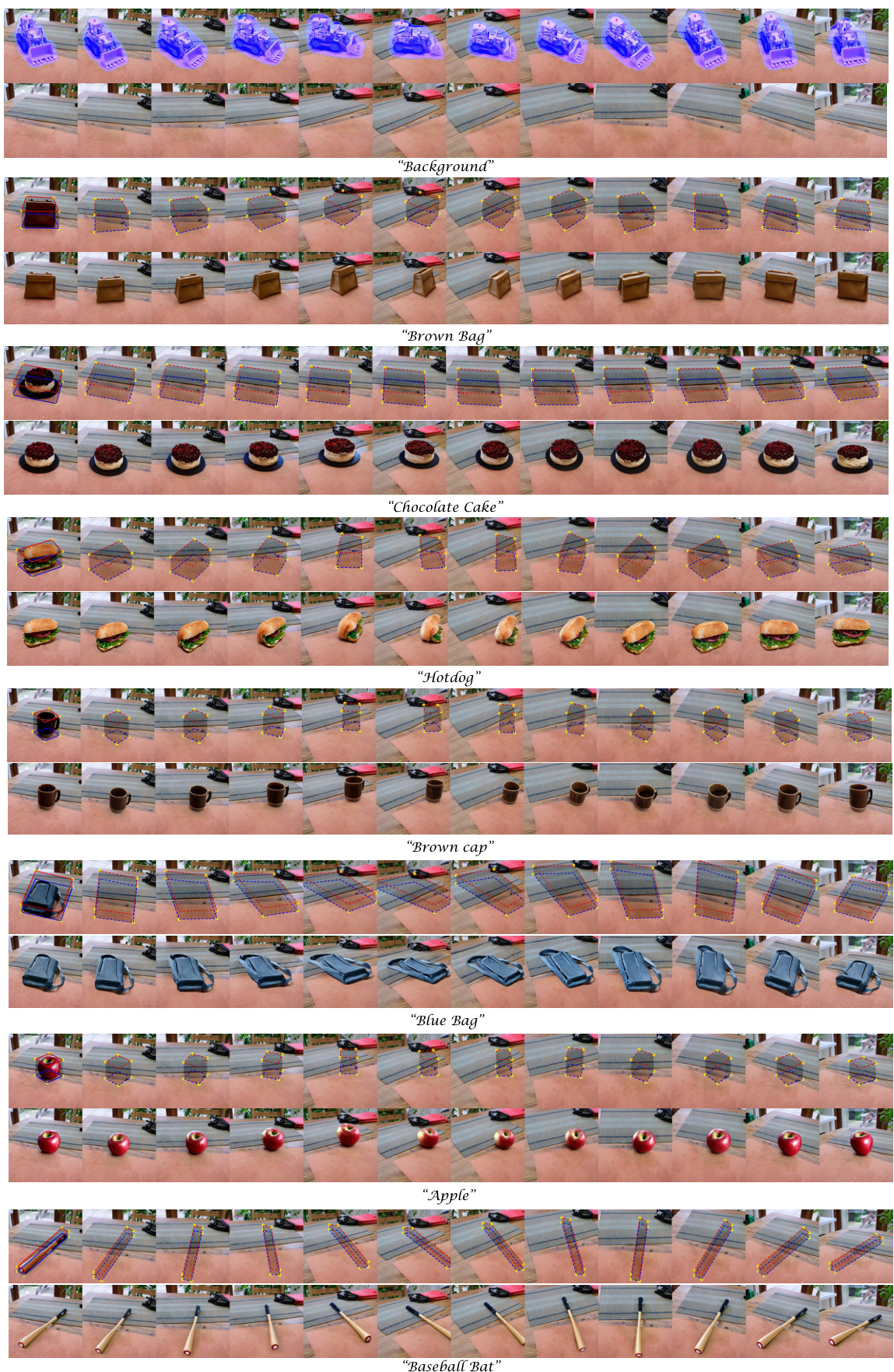
This figure demonstrates the results of scene editing using the MVInpainter model. It showcases the model’s ability to perform object removal and insertion across multiple views. The process involves adaptively warping masks to ensure seamless integration with the scene, even with viewpoint changes. Each row shows a different object (background, brown bag, chocolate cake, hotdog, brown cap, blue bag, apple, baseball bat) that is inserted using the inpainted background image as a reference. The masks are created adaptively to fit the foreground object’s shape and perspective in each view.

This figure showcases the four main tasks addressed by the MVInpainter model: novel view synthesis, multi-view object removal, multi-view object insertion/replacement, and 3D scene editing. It highlights the model’s ability to consistently inpaint across multiple views using a single edited reference image, eliminating the need for camera pose information. The final panel demonstrates how this 2D inpainting approach extends to 3D scene editing by using existing 3D reconstruction methods like Dust3R, Multi-View Stereo, and 3D Gaussian Splatting.

This figure shows examples of scene editing using MVInpainter. The top row displays the original images with masks. The subsequent rows demonstrate results from editing the images using various captions. Specifically, object removal and replacement were performed, with the object removals using the caption “background” to guide the inpainting. Different masking strategies and object types were applied to showcase the flexibility and generalizability of the MVInpainter method. The images highlight the successful integration of the inpainted objects with the existing scenes, preserving contextual consistency and visual coherence.

This figure visualizes the frame interpolation method used in MVInpainter for handling long sequences. Part (a) demonstrates expanding results by a factor of four, starting from six initially inpainted views. Part (b) shows long-range interpolation where the first seven views are fixed as conditions for subsequent inpainting.

The figure compares the results of using a vanilla VAE decoder and an augmented VAE decoder in the MVInpainter model. The left shows the improvement on a stairway image with a masked area. The right illustrates the effect on an image of a piece of equipment with a masked region. In both cases, the augmented VAE decoder produced more consistent and visually pleasing inpainting results, mitigating the color differences that were present near the masked boundaries when using the vanilla VAE decoder.

This figure compares the results of three different methods: the baseline method and two methods without the inpainting formulation (SD-blend and SD-NVS). The image shows the input images and the outputs generated by each method for two different objects. This is used to highlight the effect of inpainting formulation in achieving high quality multi-view consistent results.

This figure compares the object removal results of the proposed method, MVInpainter, with those of SPIn-NeRF, a state-of-the-art NeRF editing method. The comparison highlights the differences in the quality of object removal and the overall visual consistency across multiple views. The top row shows masked input images, while subsequent rows illustrate the results of MVInpainter (with blending of original and inpainted regions) and SPIn-NeRF (with and without blending). The figure demonstrates MVInpainter’s ability to generate visually more pleasing and consistent results compared to SPIn-NeRF, particularly with respect to object removal.

This figure shows four examples of how MVInpainter can be used for 2D and 3D scene editing. (a) shows novel view synthesis, where a new view of a scene is generated from a single reference image. (b) shows multi-view object removal, where an object is removed from multiple views of a scene. (c) shows multi-view object insertion and replacement, where an object is inserted or replaced in multiple views of a scene. (d) shows how MVInpainter can be applied to real-world 3D scene editing, using point clouds generated by Dust3R or Multi-View Stereo (MVS) and 3DGS. The key takeaway is that MVInpainter uses a multi-view consistent inpainting approach to bridge 2D and 3D editing, which eliminates the need for explicit camera poses and simplifies the editing process.

This figure shows the results of 3D scene reconstruction using multi-view stereo (MVS) and 3D Gaussian splatting (3DGS). The (a) part displays point clouds generated by the MVSFormer++ method, which serves as input for the 3DGS. The (b) part presents test views generated by the 3DGS model, demonstrating the final 3D reconstruction from multi-view 2D inpainting results.

This figure showcases the capabilities of MVInpainter in addressing various 2D and 3D editing tasks. It demonstrates the ability to perform novel view synthesis, multi-view object removal, and object insertion/replacement using a multi-view consistent inpainting approach. The key aspect is that MVInpainter can extend a single, edited reference image to other views without needing explicit camera pose information, simplifying the process significantly. It further highlights the applicability of MVInpainter to real-world 3D scene editing by leveraging existing 3D reconstruction techniques like Dust3R and Multi-View Stereo.
More on tables
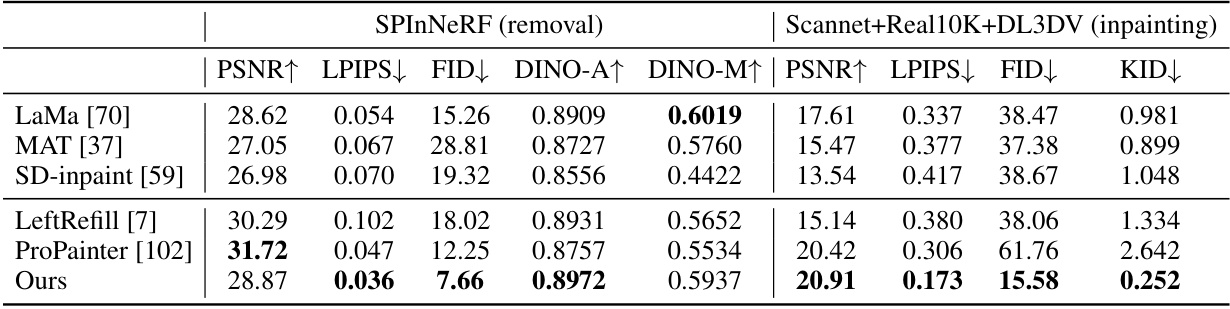
This table presents a quantitative comparison of different image inpainting methods on scene-level forward-facing novel view synthesis tasks. It evaluates both object removal (using SPInNeRF dataset) and general inpainting (using Scannet++, Real10k, and DL3DV datasets). Metrics used include PSNR, LPIPS, FID, DINO-A, and DINO-M (for object removal) and KID (for inpainting). The table highlights the performance of the proposed MVInpainter method against several baselines, demonstrating its superior performance in terms of image quality and consistency.
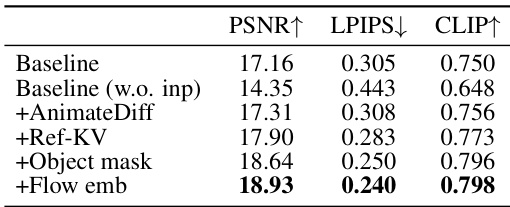
This table presents the results of ablation studies conducted on the CO3D dataset to evaluate the effectiveness of different components in the proposed MVInpainter model. It compares several variations of the model, including the baseline model without the inpainting formulation, and versions augmented with AnimateDiff, Ref-KV, object masks, and flow embeddings. The metrics used for comparison are PSNR, LPIPS, and CLIP score, which assess the image quality, perceptual similarity, and semantic similarity of the generated results respectively.
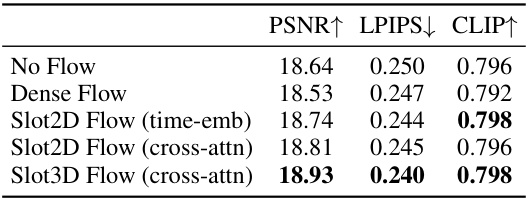
This table presents the ablation study results performed on the CO3D dataset to evaluate the effectiveness of different components in the MVInpainter model. It compares the performance metrics (PSNR, LPIPS, and CLIP) of various model configurations, including variations with and without flow guidance, different flow grouping methods (2D and 3D), and the inclusion of AnimateDiff and Ref-KV. The baseline configuration is without the inpainting formulation. This analysis helps understand the contribution of individual components in improving the overall performance of the MVInpainter.

This table presents a quantitative comparison of different methods for object-centric novel view synthesis (NVS). The methods are evaluated on the CO3D and MVImgNet datasets, with Omni3D used as a zero-shot test set. Metrics include PSNR, LPIPS, FID, and KID, measuring various aspects of image quality and realism. The use of enlarged bounding box masks is a key aspect of the experimental setup.
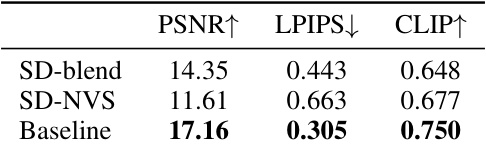
This table presents the ablation study results conducted on the CO3D dataset to evaluate the effectiveness of different components in the proposed MVInpainter model. It shows the performance metrics (PSNR, LPIPS, and CLIP) for different configurations, including the baseline without the inpainting formulation, versions with dense flow and slot attention-based flow guidance, and variations in the way the motion prior is incorporated. This helps to understand the contribution of each component in achieving multi-view consistent inpainting.

This table presents a quantitative comparison of different novel view synthesis (NVS) methods on object-centric datasets. The metrics used are PSNR, LPIPS, FID, KID, and CLIP. The comparison includes results on CO3D and MVImgNet datasets, with Omni3D serving as a zero-shot test set (meaning the models were not trained on this dataset). Enlarged bounding box masks were used to avoid mask shape leakage. The table highlights the performance of the proposed MVInpainter compared to other state-of-the-art methods.

This table presents a quantitative comparison of different methods for scene-level forward-facing novel view synthesis (NVS) using masked images. It evaluates both object removal and inpainting performance using metrics like PSNR, LPIPS, FID, KID, and DINO. The dataset consists of clean images from SPIn-NeRF and degraded images from Scannet++, Real10k, and DL3DV.

This table presents a quantitative comparison of object-centric novel view synthesis (NVS) methods. It compares the performance of the proposed MVInpainter against three other methods (ZeroNVS, Nerfiller, and LeftRefill) across three datasets (CO3D, MVImgNet, and Omni3D). The evaluation metrics include PSNR, LPIPS, FID, and KID, assessing the quality and consistency of the generated views. Omni3D serves as a zero-shot test set, evaluating generalization capabilities.
Full paper#