↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Large language models (LLMs) are powerful but require frequent updates. Knowledge editing is a cost-effective way to update LLMs, but it often causes performance drops. This happens due to two main factors: the diversity and complexity of the data being edited, and the changes in the internal structure of the model itself. These issues are especially pronounced when multiple edits need to be made.
To solve this, the paper introduces Dump for Sequence (D4S), a novel method that aims to improve the accuracy and efficiency of sequence editing. D4S manages L1-norm growth in model layers during the editing process. By doing so, it reduces the negative impact on the model’s overall performance. The experiments showed that D4S successfully overcomes previous editing bottlenecks, allowing users to perform multiple effective edits and minimizing model damage. This work is valuable because it provides practical solutions for researchers to tackle real-world challenges in updating LLMs.
Key Takeaways#
Why does it matter?#
This paper is crucial because it tackles the critical issue of performance degradation in large language models after knowledge editing, a significant hurdle in practical applications. It offers novel solutions and insights that are immediately relevant to ongoing research in this area, opening new avenues for improved knowledge editing techniques and enhanced LLM updatability. The methodological contributions, like the D4S algorithm, provide practical tools for researchers.
Visual Insights#
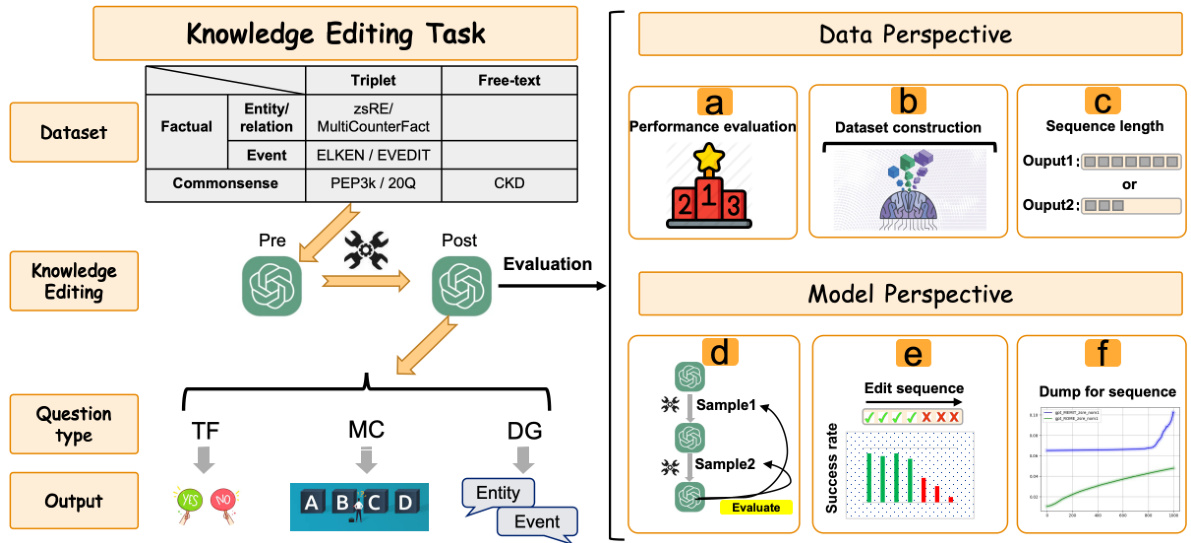
This figure illustrates the research framework used to investigate the performance decline of edited language models. The left side categorizes knowledge editing tasks by type and objective, while the right side details the experimental approach from both data and model perspectives. Data perspective experiments assess model performance, create a new dataset (MQD), and analyze the impact of various editing data. Model perspective experiments focus on the model’s forgetting, identify performance bottlenecks, and propose a new sequence editing method (D4S).

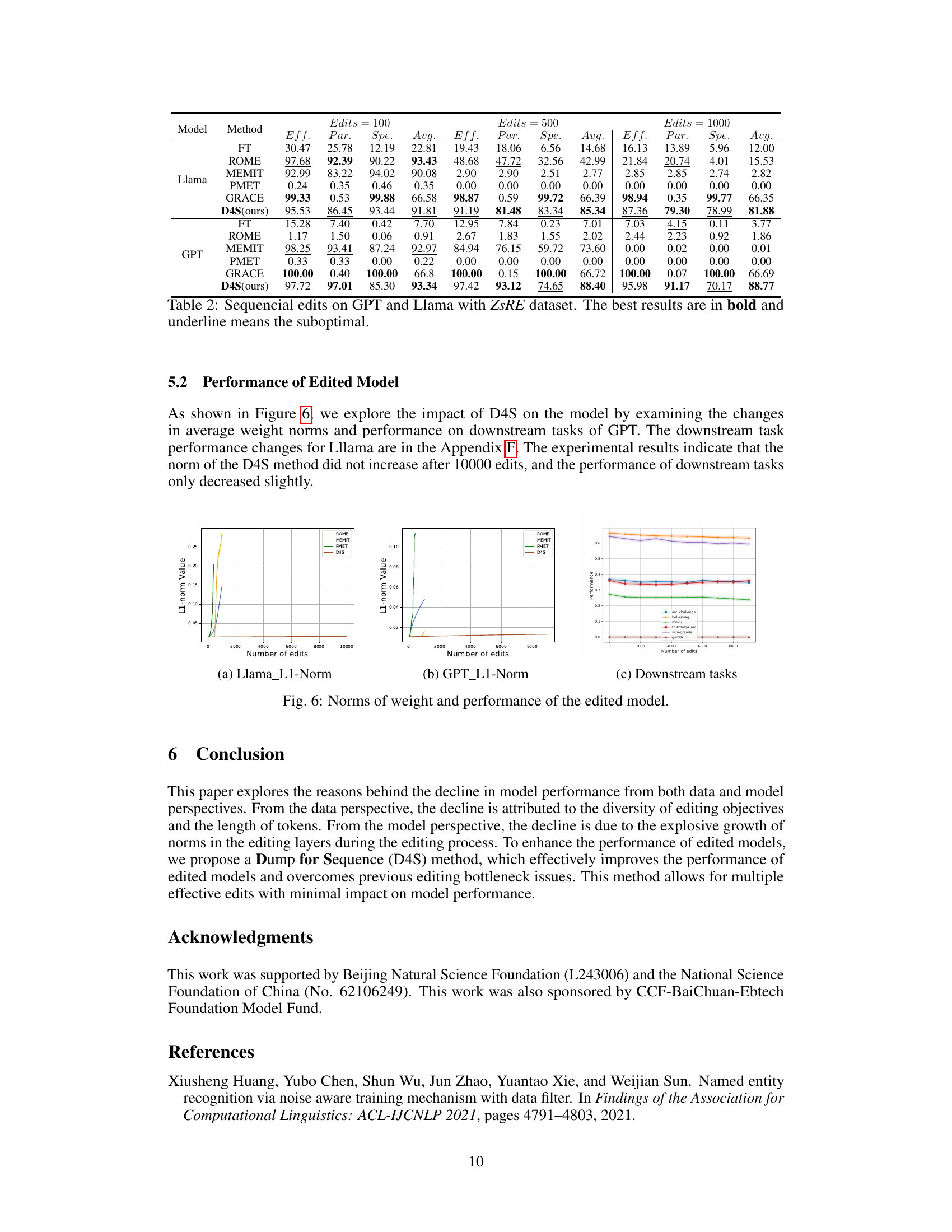
This table presents the results of sequential editing experiments performed on GPT and Llama language models using the ZsRE dataset. Multiple editing methods (ROME, MEMIT, PMET, GRACE, and the proposed D4S) are compared across different numbers of edits (100, 500, and 1000). The table shows the performance of each method on three evaluation metrics (Efficacy, Paraphrase, and Specificity) along with the average performance. The best result for each metric and edit number is highlighted in bold, while the suboptimal result is underlined.
In-depth insights#
Edit Performance Drop#
The phenomenon of “Edit Performance Drop” in large language models (LLMs) after knowledge editing is a significant challenge. The core issue lies in the inherent trade-off between updating knowledge and preserving the model’s overall performance. While editing offers a cost-effective method for correcting factual errors or incorporating new information, it often leads to a decline in accuracy across various downstream tasks. This drop isn’t simply a matter of forgetting previously learned information; instead, it’s a complex interplay of factors. Research suggests that the diversity of editing targets and their sequence length significantly influence performance. Furthermore, from a model perspective, the magnitude of changes to model parameters (measured by L1-norm) during the editing process is strongly correlated with the severity of performance degradation. Strategies to mitigate this performance drop focus on minimizing these parameter changes and incorporating techniques such as ‘Dump for Sequence’ (D4S). D4S effectively manages parameter norm growth during sequence editing by employing batch updates, thus improving the efficacy of edits and minimizing collateral damage to the model’s capabilities. However, even with such strategies, the inherent limitations of parameter-level editing remain. Future research should investigate alternative approaches for knowledge integration into LLMs that minimize performance degradation, thereby addressing this central challenge of maintaining model stability after knowledge updates.
Data Diversity Effects#
The concept of “Data Diversity Effects” in the context of a research paper likely explores how the variety and representation within a dataset influence model performance, particularly after knowledge editing. A diverse dataset, encompassing various question types, factual scenarios, and entity relationships, would likely demonstrate a stronger correlation with model performance than a homogeneous one. The research probably investigates whether a lack of diversity, such as an over-representation of specific question types or knowledge domains, leads to performance degradation after edits are made. Understanding this relationship is crucial for optimizing the editing process, ensuring the model generalizes well across diverse inputs, and mitigating potential biases present in the data. The study may highlight specific data characteristics, such as sequence length or complexity, which may either amplify or reduce the impact of diversity on performance.
Model Layer Norms#
Analyzing model layer norms after knowledge editing reveals crucial insights into model performance. Changes in L1-norm values strongly correlate with editing accuracy and the model’s susceptibility to catastrophic forgetting. High L1-norm growth indicates a bottleneck, limiting the number of effective edits and causing significant performance degradation. This suggests that editing methods should focus on minimizing L1-norm increases in relevant layers to mitigate damage and enhance the longevity of edited knowledge. Strategies to regulate or constrain these norms, such as the proposed Dump for Sequence (D4S) method, are essential for improving the effectiveness and robustness of knowledge editing techniques. The relationship between L1-norm growth and the diversity or complexity of edited knowledge is also worth investigating, possibly leading to more refined editing strategies tailored to specific data characteristics.
D4S Method Proposed#
The proposed D4S (Dump for Sequence) method tackles the performance degradation in large language models (LLMs) after sequential knowledge editing. Existing methods struggle with the explosive growth of the L1-norm in editing layers, causing catastrophic forgetting and limiting the number of effective edits. D4S addresses this bottleneck by employing a novel caching mechanism. Instead of directly accumulating editing history, it uses a compact representation that maintains the key information required for updating parameters while minimizing storage space. This efficient caching technique ensures that the impact of each edit on model parameters is well-regulated, preventing the excessive L1-norm increase observed in previous methods. Consequently, D4S enables the performance of multiple effective edits without significant model degradation. The theoretical analysis and experimental results demonstrate that D4S effectively mitigates the explosive L1-norm growth, leading to superior performance compared to existing approaches, thus making the LLM editing process substantially more efficient and reliable. The significance of D4S lies in its ability to reconcile the cost-effectiveness of knowledge editing with the preservation of model accuracy, making the knowledge base update a more practical and sustainable procedure for LLMs.
Future Research#
Future research directions stemming from this work on model performance after editing could explore several key areas. Improving the efficiency of sequence editing is crucial, perhaps through more sophisticated techniques for managing the explosive growth of parameter layer norms or by developing entirely new editing algorithms. Addressing catastrophic forgetting remains a critical challenge and necessitates the investigation of novel memory mechanisms within the models. Further, investigating the interaction between different editing objectives and the model’s architecture is vital to understanding why some edit types are more impactful than others. A particularly important area of future work is to develop more robust metrics for evaluating the success and long-term impact of edits. The current metrics primarily focus on immediate performance but do not fully account for downstream consequences. Finally, the potential societal implications of large-language model editing must be considered, warranting research into methods for ensuring the safety and ethical application of editing techniques.
More visual insights#
More on figures
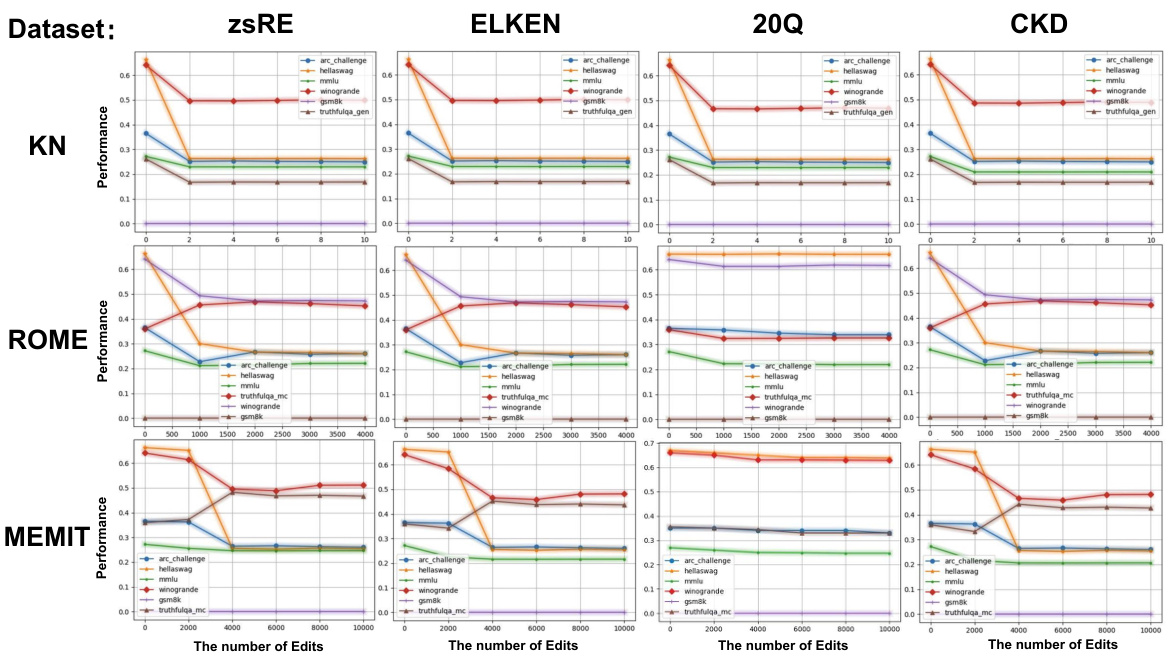
This figure shows the performance of different knowledge editing methods (KN, ROME, MEMIT) across various datasets (zsRE, ELKEN, 20Q, CKD) on multiple downstream tasks (arc_challenge, hellaswag, mmlu, winogrande, truthfulqa, gsm8k). The x-axis represents the number of edited samples, and the y-axis represents the performance of the edited model. The graph illustrates how the performance changes as more edits are applied, revealing different trends for each editing method and dataset combination. Some methods show a gradual decline in performance with increased edits, others show relatively stable performance across the edit range, and some exhibit sharp drops in performance after a certain number of edits.
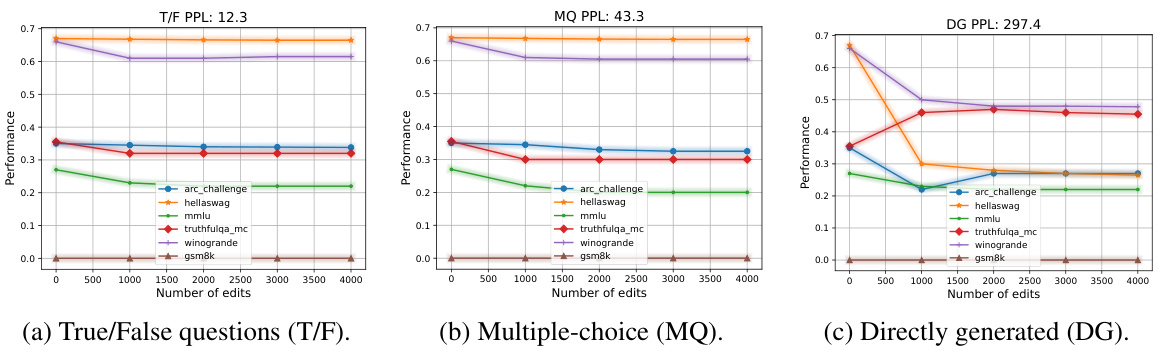
This figure shows the performance of the model after editing data for three different question types: True/False (T/F), Multiple-choice (MQ), and Directly generated (DG). Each subplot represents a question type and shows the performance on several downstream tasks (arc_challenge, hellaswag, mmlu, truthfulqa_mc, winogrande, gsm8k) as the number of edits increases. The figure illustrates that the performance degradation after editing is correlated with the perplexity (PPL) of the editing objectives, with directly generated questions showing the most significant performance drop. The different colored lines represent different downstream tasks.

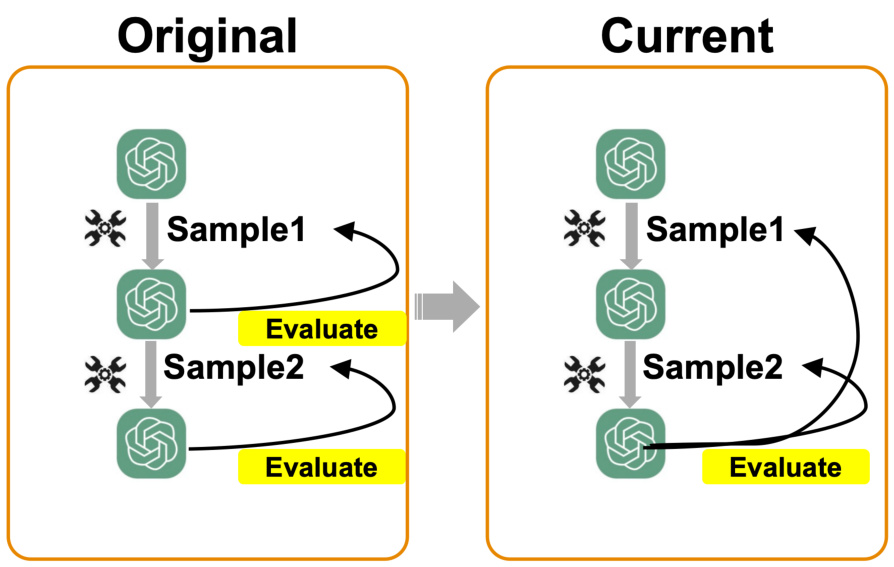
This figure illustrates the difference between the original and current evaluation methods used in the paper. The original method evaluates each sample individually after editing. In contrast, the current method evaluates the model’s performance after a sequence of edits, considering the impact on previously edited samples. This highlights a shift in methodology to better reflect real-world application scenarios where multiple edits are made.
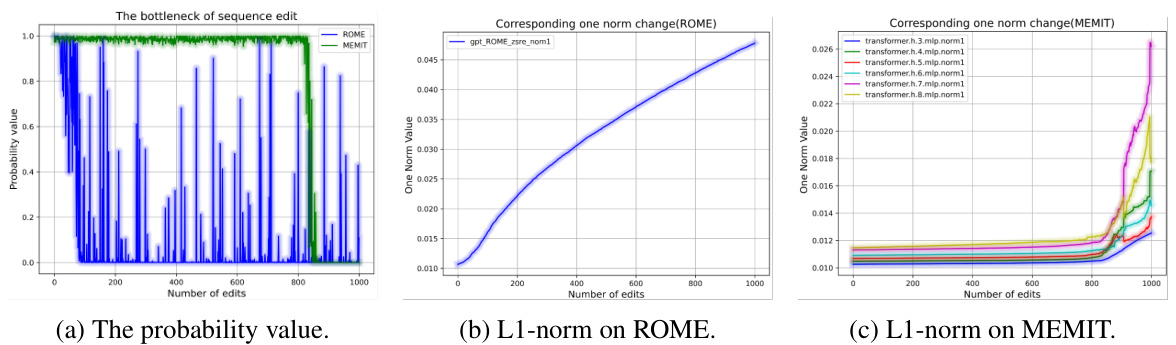
This figure shows the performance degradation of two sequence editing methods, ROME and MEMIT. The first subplot (a) displays the probability of successful edits over the number of edits performed. It shows a clear decline in the probability of success for both methods as the number of edits increases, highlighting the ‘bottleneck’ phenomenon. The second and third subplots (b and c) illustrate the L1-norm of various layers within the model during the editing process. These demonstrate a strong correlation between the increase in L1-norm values and the decrease in edit success rates, providing further evidence of the model’s performance degradation.
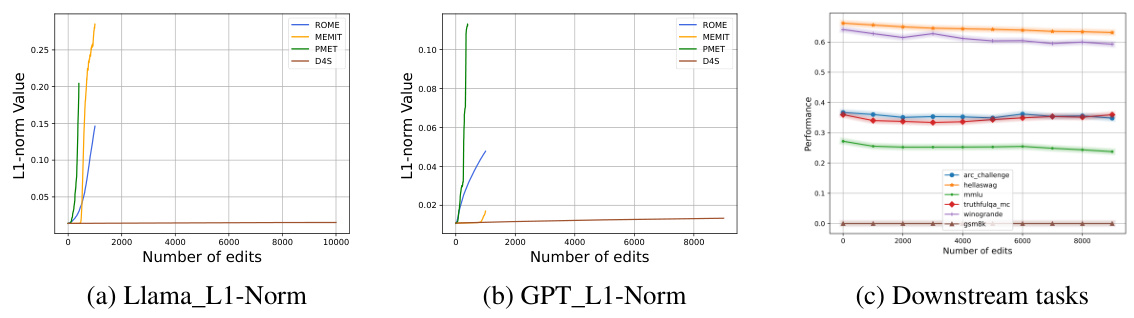
This figure shows the L1-norm of the model’s weights and the model’s performance on downstream tasks after different numbers of edits using various methods (ROME, MEMIT, PMET, and D4S). The left two subfigures (a, b) display the L1-norm of the model’s weights for Llama and GPT respectively, illustrating the explosive growth of the norms for some methods like ROME and MEMIT with increasing edits. The right subfigure (c) presents the performance on downstream tasks, demonstrating that while some methods maintain good performance, others show decline after a certain number of edits, and D4S is effective at minimizing the performance drop. The results indicate a strong correlation between the growth of L1-norm and the decline in model performance.
This figure illustrates the framework used in the paper to understand why model performance declines after editing. The left side categorizes knowledge editing tasks, while the right side details the experimental approach from data and model perspectives. The data perspective includes evaluating model performance, constructing a new dataset (MQD), and analyzing the effects of different editing data. The model perspective covers evaluating forgetting, identifying performance bottlenecks, exploring correlations between editing and model layers, and proposing a new sequence editing method (D4S).
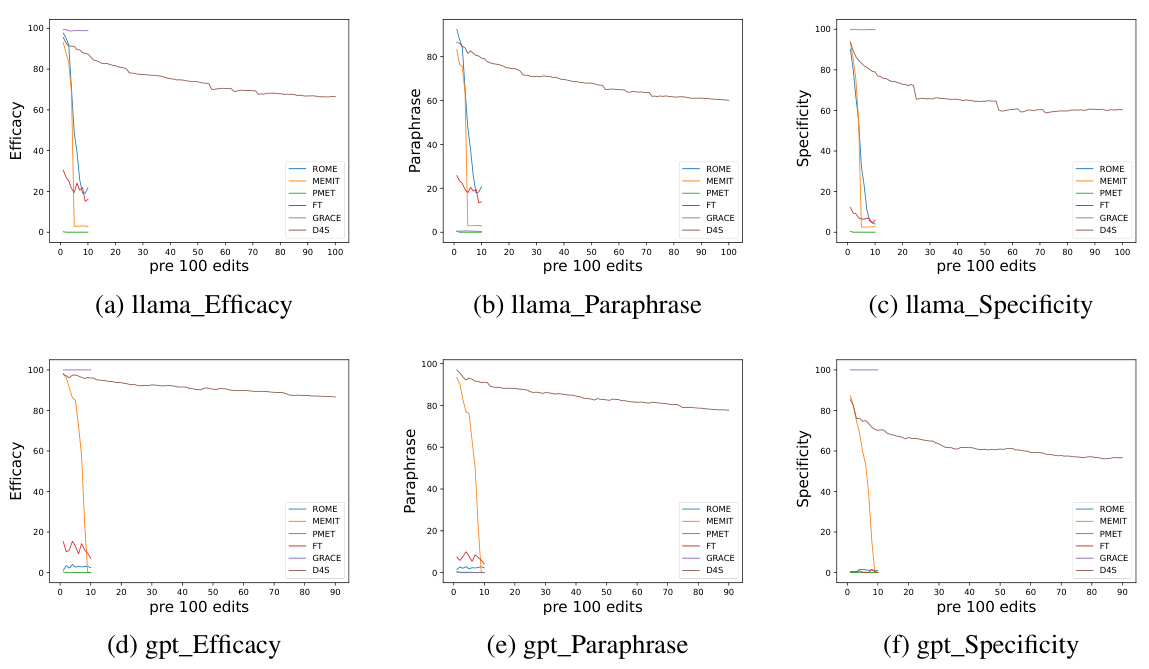
This figure visualizes the changes in three evaluation metrics (Efficacy, Paraphrase, and Specificity) across different editing methods (ROME, MEMIT, PMET, FT, GRACE, and D4S) as the number of edits increases. It showcases the performance of each method over time, revealing how well they maintain the accuracy and consistency of edits. The x-axis represents the number of edits performed, while the y-axis displays the corresponding metric value (ranging from 0 to 100). The plots show the performance of the model with the different approaches and how they are affected by the amount of editing done. This allows for a direct comparison of various editing strategies and their effectiveness.
More on tables
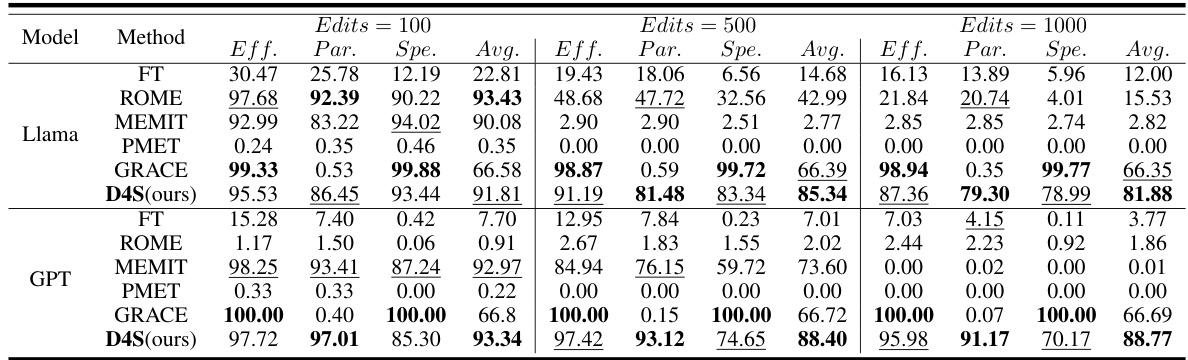
This table presents the performance comparison of different sequence editing methods on two large language models (LLMs): GPT and Llama. The evaluation is done on the factual triplet dataset zsRE, and the metrics used are efficacy (Eff.), paraphrase accuracy (Par.), specificity (Spe.), and their average (Avg.). Three different numbers of edits are tested: 100, 500, and 1000. The results show the performance of each method under different editing intensities. The best performance for each metric and average under each edit number are highlighted in bold.

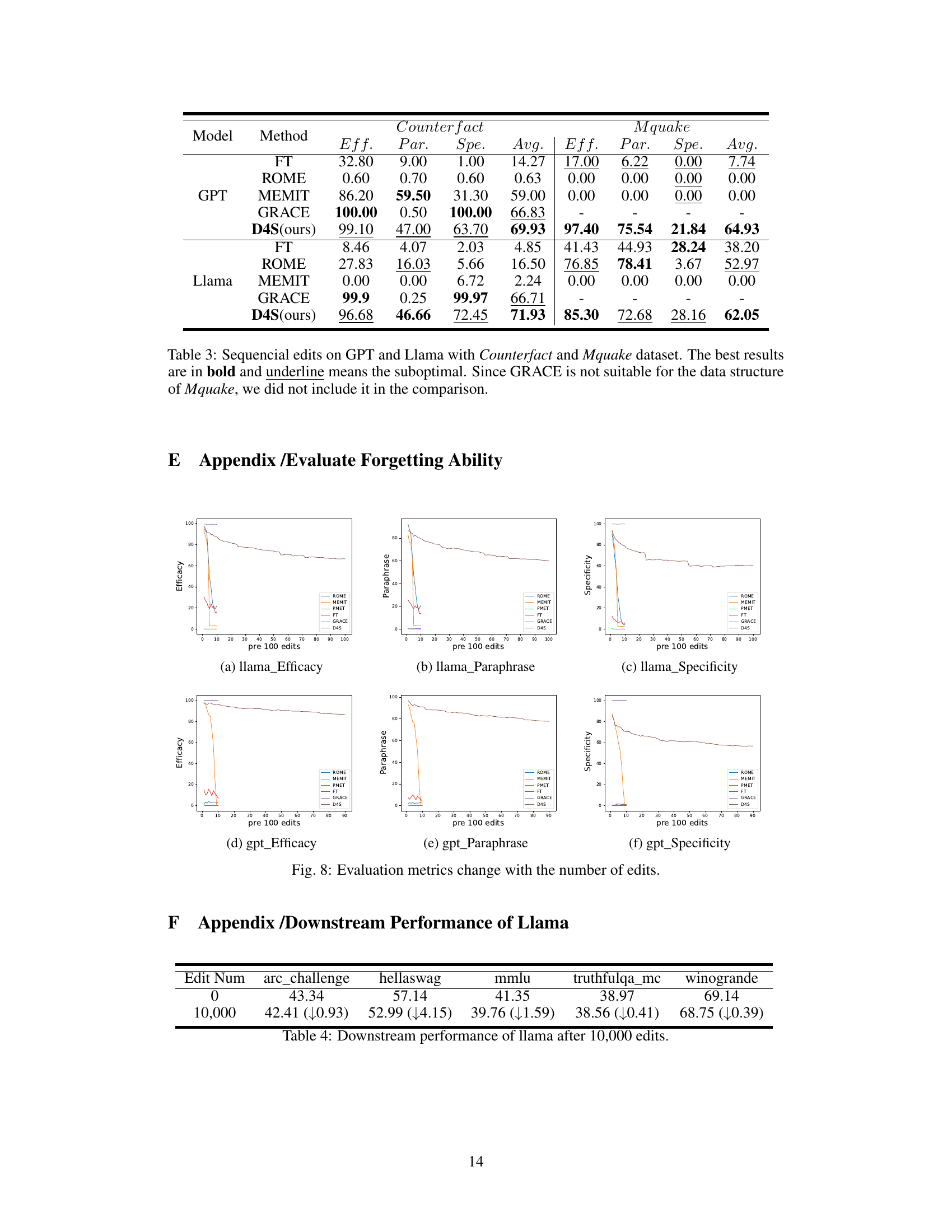
This table presents the results of sequential edits on GPT and Llama language models using different knowledge editing methods (FT, ROME, MEMIT, GRACE, and D4S) and two different datasets (Counterfact and MQuake). It shows the efficacy, paraphrase accuracy, specificity, and average performance of each method on each dataset. The best-performing methods for each metric are highlighted in bold, while suboptimal results are underlined. The GRACE method is excluded from the MQuake dataset results due to incompatibility.

This table presents the downstream task performance of the Llama model after 10,000 sequence edits. It shows the performance metrics (presumably accuracy) on six different downstream tasks (arc_challenge, hellaswag, mmlu, truthfulqa_mc, winogrande) before any edits (Edit Num = 0) and after 10,000 edits. The values in parentheses represent the change in performance after the edits, showing whether the model improved or degraded. The table helps assess the impact of the extensive sequence editing on the model’s generalization abilities across various tasks.
Full paper#