↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Spiking Neural Networks (SNNs) offer energy efficiency but suffer from the gradient vanishing problem during training, hindering their performance. Existing surrogate gradient methods, while addressing the non-differentiability of the firing spike process, fail to fully overcome this issue. This leads to inaccurate weight updates, particularly in the shallow layers, and ultimately limits the network’s ability to learn complex patterns effectively.
To tackle this, the researchers introduce a novel shortcut back-propagation technique that transmits gradients directly from the loss function to shallow layers, bypassing the vanishing gradient problem. This is combined with an evolutionary training framework that dynamically adjusts the balance between the main network’s gradient and those from shortcut branches. Experiments demonstrate that this combined approach significantly improves training efficiency and accuracy compared to existing SNN training methods, achieving state-of-the-art results on multiple datasets.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses a critical limitation in training spiking neural networks (SNNs): gradient vanishing. By proposing a novel shortcut back-propagation method and an evolutionary training framework, it significantly improves SNN training efficiency and accuracy. This work opens new avenues for research on energy-efficient and biologically inspired neural networks, particularly relevant to neuromorphic computing.
Visual Insights#

This figure illustrates the training and inference phases of the proposed shortcut back-propagation method for Spiking Neural Networks (SNNs). In the training phase, multiple shortcut branches are added from intermediate layers to the output layer. These branches allow the gradient to flow directly from the output layer to the shallow layers, mitigating the gradient vanishing problem. During inference, these shortcut branches are removed, resulting in no additional computational burden. The figure visually shows the forward and backward passes of information during training and only the forward pass during inference.
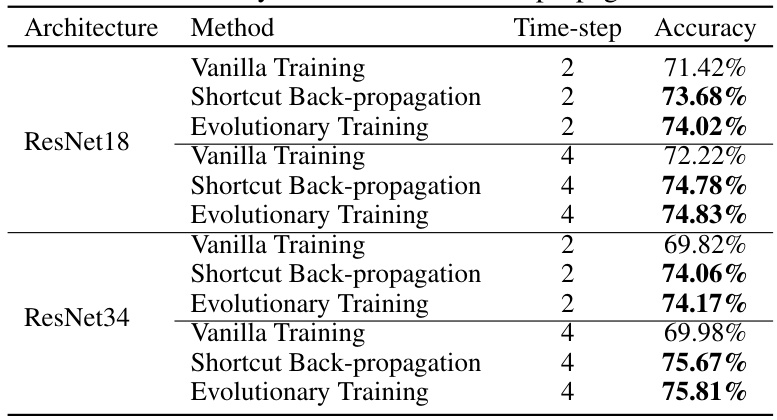
This table presents the results of an ablation study conducted to evaluate the effectiveness of the proposed shortcut back-propagation method. The study compares the accuracy achieved using different training methods (Vanilla Training, Shortcut Back-propagation, and Evolutionary Training) on two different network architectures (ResNet18 and ResNet34) with varying numbers of timesteps (2 and 4). The results show that the shortcut back-propagation method consistently improves accuracy compared to vanilla training, and that the evolutionary training framework further enhances performance.
In-depth insights#
SNN Gradient Vanishing#
The phenomenon of “SNN Gradient Vanishing” is a critical challenge in training spiking neural networks (SNNs). Unlike traditional artificial neural networks, SNNs use binary spikes for information transmission, making the gradient calculation during backpropagation problematic. Surrogate gradient methods, often employed as a workaround, replace the non-differentiable spike function with a differentiable approximation. However, these approximations inherently suffer from gradient vanishing, especially in deeper networks, as the gradients progressively diminish with each layer, hindering effective weight updates in shallower layers and potentially leading to poor model performance. This issue stems from the bounded nature of surrogate gradient functions, restricting the magnitude of gradients. Addressing this challenge is crucial for realizing the full potential of SNNs, as overcoming gradient vanishing can unlock more efficient and biologically plausible neural network models for various applications.
Shortcut Backprop#
The concept of ‘Shortcut Backprop’ in the context of training Spiking Neural Networks (SNNs) addresses the critical issue of gradient vanishing. Traditional backpropagation struggles in SNNs due to the non-differentiable nature of neuron firing. This proposed method bypasses the limitations of surrogate gradients by creating direct pathways for gradient flow from the output layer to earlier layers. These shortcuts effectively prevent the gradient from diminishing as it travels through multiple layers. The key insight is to inject gradient information directly into the shallower layers, thus alleviating the vanishing problem and improving the training of SNNs. This technique offers a significant improvement over methods that rely solely on surrogate gradients and offers enhanced learning efficiency and improved model accuracy.
Evolutionary Training#
The proposed “Evolutionary Training” framework elegantly addresses a crucial challenge in training Spiking Neural Networks (SNNs): balancing the contributions of shortcut branches and the main network during training. Early in training, it prioritizes the shortcut branches, which directly transmit gradients to shallow layers, alleviating the pervasive gradient vanishing problem in SNNs. This ensures that shallow layer weights are adequately updated. As training progresses, the framework gradually shifts focus to the main network’s output, ensuring high accuracy. This dynamic weighting, implemented via a balance coefficient that decreases with each training epoch, avoids the potential conflict between optimizing for sufficient updates in early layers and achieving high final accuracy. The resulting training strategy is not only efficient, but it also yields superior performance, improving the overall accuracy and robustness of the SNN model.
Ablation Study Results#
An ablation study systematically removes components of a model to assess their individual contributions. For Spiking Neural Networks (SNNs), this might involve removing shortcut connections, altering the training framework (e.g., removing the evolutionary training aspect), or changing the surrogate gradient method. Results would show the impact of each removed component on accuracy and training efficiency. A well-executed ablation study provides strong evidence for the effectiveness of the proposed method by isolating the impact of specific components. It helps establish which components are crucial and which are less important. A significant drop in accuracy when a component is removed indicates its importance. Conversely, minor changes suggest that component is less critical or potentially redundant. The ablation study helps to understand the contribution of each component to the overall performance and guides future improvements.
SOTA Comparisons#
A thorough ‘SOTA Comparisons’ section in a research paper would go beyond simply listing state-of-the-art (SOTA) results. It should offer a nuanced analysis, comparing methods across key metrics, datasets, and experimental setups. Highlighting the limitations of previous SOTAs is crucial to establish the novelty and significance of the presented work. Furthermore, a good comparison would delve into the reasons behind performance differences. Is it due to architectural choices, training strategies, or dataset biases? Direct qualitative comparisons (e.g., efficiency versus accuracy) and visualizations of performance differences (e.g., graphs showing trade-offs) would aid in understanding the relative merits of each method. Finally, discussing the generalizability of the proposed model compared to SOTA techniques across various scenarios and datasets would build stronger confidence in the robustness and potential impact of the research.
More visual insights#
More on tables
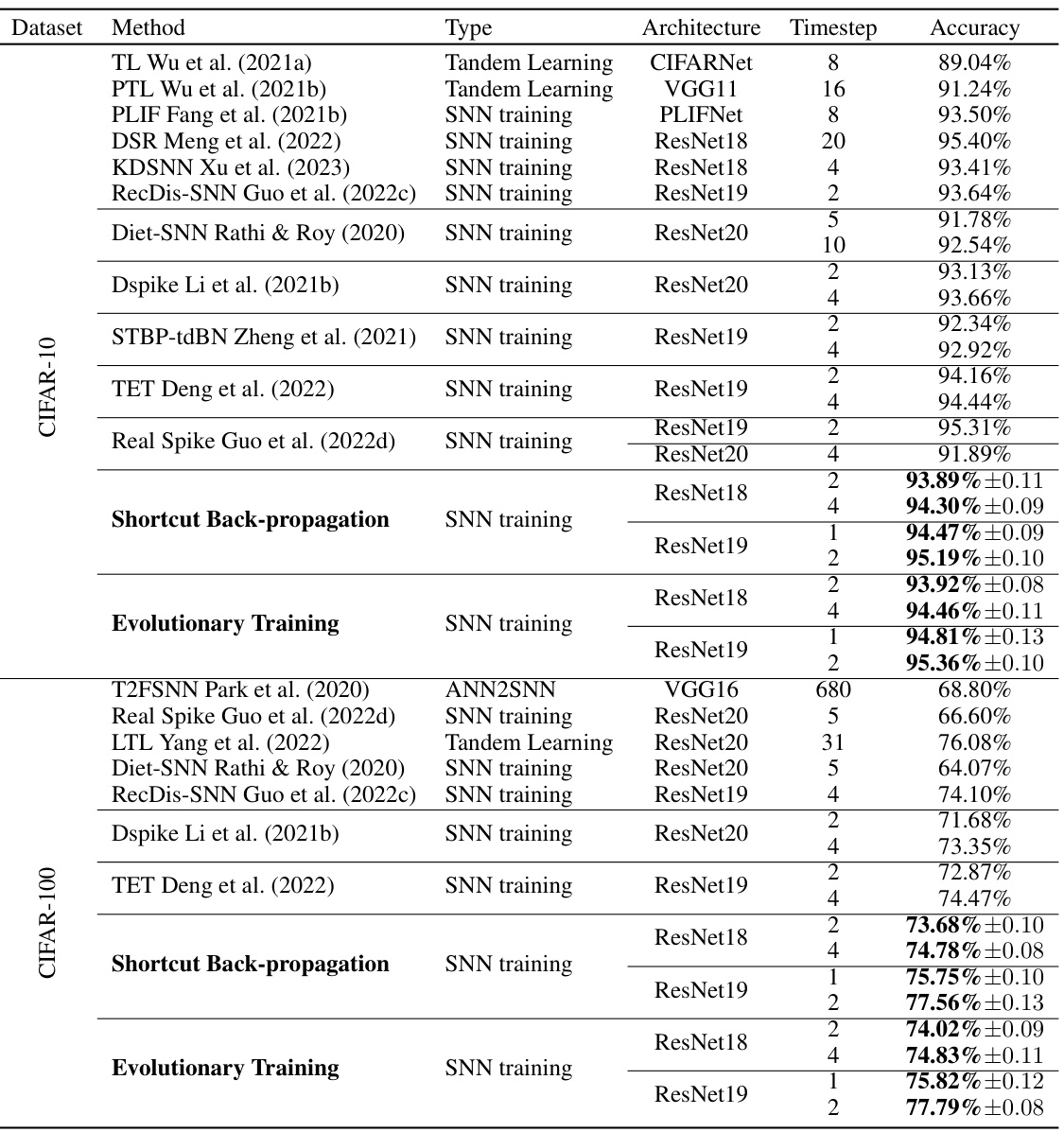
This table compares the performance of the proposed ‘Shortcut Back-propagation’ and ‘Evolutionary Training’ methods with other state-of-the-art (SoTA) methods on the CIFAR-10 and CIFAR-100 datasets. It shows the method used, its type (SNN training, ANN2SNN, Tandem Learning, etc.), the network architecture (e.g., ResNet18, ResNet19, VGG16), the number of timesteps used, and the achieved accuracy. The table highlights the superior performance of the proposed methods, particularly the ‘Evolutionary Training’ approach, achieving higher accuracy with fewer timesteps compared to SoTA.

This table compares the performance of the proposed ‘Shortcut Back-propagation’ and ‘Evolutionary Training’ methods against other state-of-the-art (SoTA) methods on the ImageNet dataset. It shows the method, its type (SNN training), the architecture used (ResNet18 or ResNet34), the number of timesteps, and the achieved accuracy. The results demonstrate the competitive performance of the proposed methods, especially considering the relatively smaller number of timesteps used.
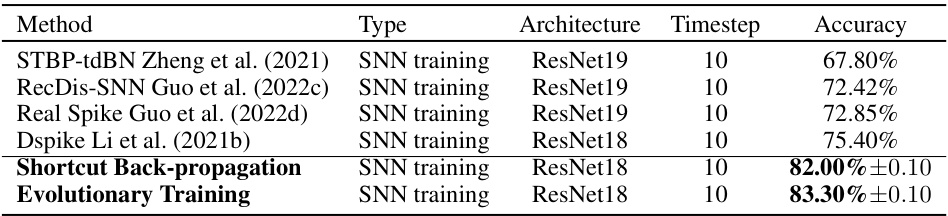
This table compares the performance of the proposed ‘Shortcut Back-propagation’ and ‘Evolutionary Training’ methods against other state-of-the-art (SoTA) methods on the CIFAR10-DVS dataset. The comparison is based on the accuracy achieved using different SNN training methods with various architectures and timesteps. The table shows that the proposed methods significantly outperform the existing SoTA methods.
Full paper#


















