↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Current large language models (LLMs) based on the Transformer architecture face limitations in processing long sequences due to their quadratic complexity. Existing sub-quadratic solutions often underperform Transformers. This inefficiency hinders the development of LLMs capable of handling real-world applications requiring long sequences, such as long document comprehension or multi-turn conversations.
This paper introduces MEGALODON, a new architecture that addresses these issues. By incorporating several innovative components, including complex exponential moving average (CEMA) and a timestep normalization layer, MEGALODON achieves superior efficiency and stability compared to existing models, especially for long sequences. The results demonstrate significant performance gains across multiple benchmarks, showcasing MEGALODON’s potential for building more powerful and efficient LLMs.
Key Takeaways#
Why does it matter?#
This paper is important because it presents MEGALODON, a novel neural architecture that significantly improves the efficiency and scalability of large language models (LLMs). It addresses the limitations of Transformers, enabling LLMs to handle unlimited context lengths while maintaining high accuracy. This opens up new avenues for research and development of more powerful and versatile LLMs for various applications. The robust improvements across multiple scales and modalities, demonstrated by the study, also highlight its practical significance for researchers.
Visual Insights#
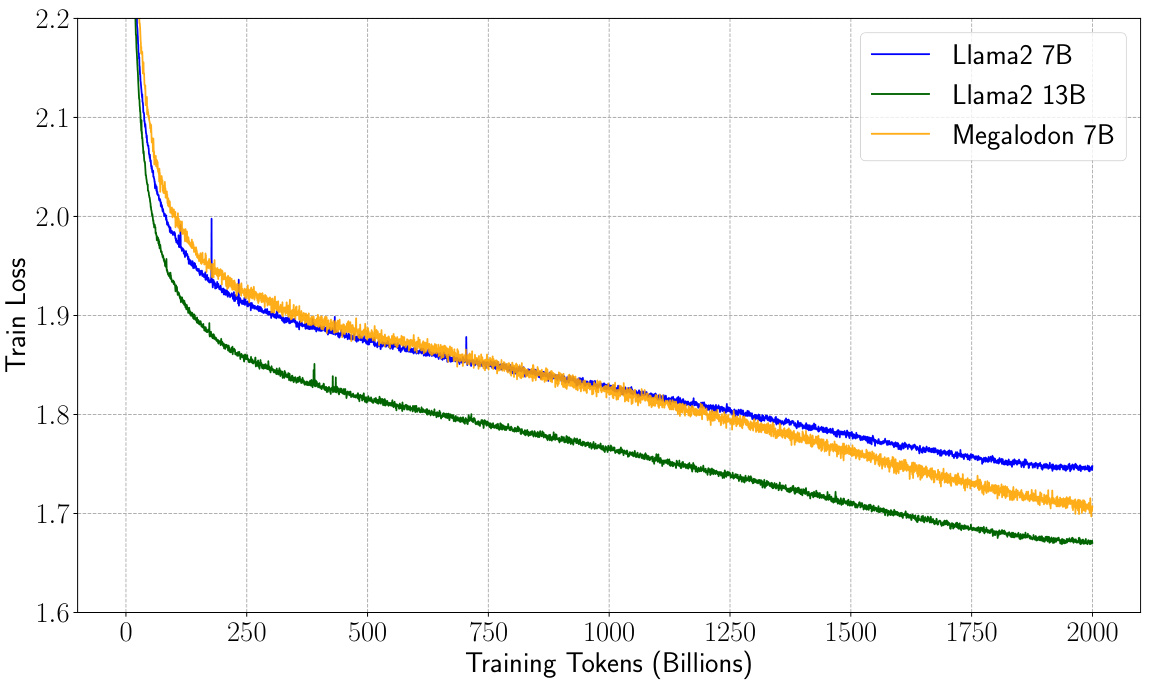
The figure shows the training loss curves for three different language models: MEGALODON-7B, LLAMA2-7B, and LLAMA2-13B. The x-axis represents the number of training tokens (in billions), and the y-axis represents the negative log-likelihood (train loss), a measure of how well the model predicts the next token in a sequence. The plot demonstrates that MEGALODON-7B achieves a training loss comparable to LLAMA2-7B while showing slightly better efficiency and stability compared to the Transformer-based LLAMA2 models throughout training. This suggests that MEGALODON achieves better data efficiency than LLAMA2-7B.
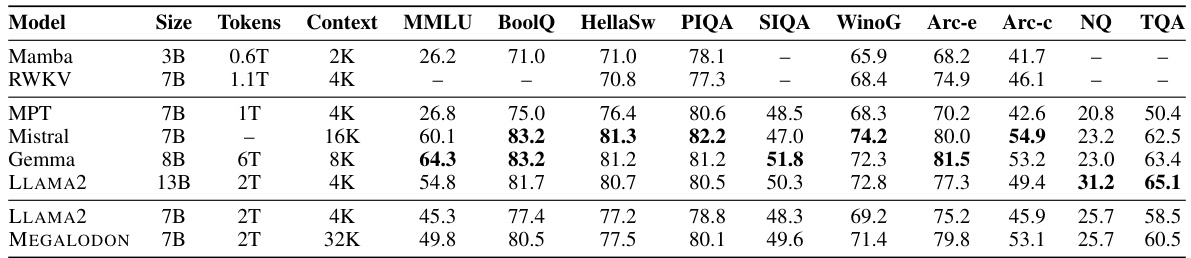
This table compares the performance of MEGALODON-7B against other open-source large language models (LLMs) on a range of standard academic benchmarks. It shows the model size, the number of training tokens used, and the maximum context length for each model. Performance is measured on several tasks, reflecting various aspects of language understanding. The dashes indicate that some values were not available in the original papers.
In-depth insights#
MEGA’s Evolution#
MEGA’s evolution represents a fascinating case study in architectural refinement within large language models. Initially conceived as a method to overcome the quadratic complexity of traditional Transformers, MEGA’s core innovation lay in its efficient gated attention mechanism combined with an exponential moving average. However, MEGA faced inherent limitations, primarily in scalability and the inability to consistently outperform Transformers in downstream tasks. The subsequent development of MEGALODON addresses these limitations directly, introducing several crucial improvements such as complex exponential moving averages (CEMA) for enhanced expressive power, timestep normalization to better handle sequential data, and a refined two-hop residual configuration for increased stability during training. These enhancements showcase the iterative nature of LLM development, moving beyond initial concepts to create a more robust, efficient, and effective architecture for long-context sequence modeling. The transition from MEGA to MEGALODON highlights the importance of both theoretical innovation and rigorous empirical evaluation to build truly competitive LLMs. Further research in this area might explore the potential of even more sophisticated moving average techniques, the impact of varying chunk sizes on model performance, and new mechanisms for handling extremely long sequences. The success of MEGALODON serves as a powerful example of how incremental progress, guided by a careful analysis of shortcomings, can ultimately lead to significant advancements in the field.
CEMA & Normalization#
The authors introduce the complex exponential moving average (CEMA) to enhance MEGA’s capabilities. CEMA extends the traditional EMA into the complex domain, improving the model’s capacity to handle long sequences. They also introduce timestep normalization, a novel technique that addresses the limitations of layer normalization in handling long sequences by normalizing along the temporal dimension. This helps mitigate the internal covariate shift and improve model stability during training. Further enhancing the architecture is the use of normalized attention, which stabilizes the training process and improves performance. These combined innovations in CEMA and normalization demonstrate a significant advancement over conventional methods, showing improved efficiency and accuracy for long-sequence modeling tasks.
Long-Seq Modeling#
The capacity to handle long sequences is a crucial aspect of large language models (LLMs). Traditional Transformer architectures struggle due to their quadratic complexity, making processing lengthy sequences computationally expensive. This research delves into efficient long-sequence modeling, exploring techniques that mitigate the quadratic bottleneck. The core idea revolves around designing architectures that achieve sub-quadratic or even linear complexity while maintaining performance. This might involve innovative attention mechanisms that selectively focus on relevant parts of long sequences, or the use of state-space models for more efficient representation of long-range dependencies. Evaluating these new architectures requires benchmarks specifically tailored for long sequences. These benchmarks should assess performance not just on accuracy but also on computational efficiency and scalability. The results will likely showcase a trade-off between complexity, accuracy, and computational costs. Ultimately, breakthroughs in long-sequence modeling will unlock new capabilities for LLMs, enabling them to process longer contexts and produce more coherent and contextually relevant outputs.
Parallel Training#
Parallel training is crucial for scaling up large language models (LLMs). Data parallelism, where the training data is split across multiple devices, is a common approach but can be limited by communication overhead. Tensor parallelism, which distributes model parameters, can overcome this, but introduces complexities in managing the distributed computation. Pipeline parallelism further enhances efficiency by dividing the model into stages, enabling concurrent processing of different parts of the input sequence. However, the choice of parallel strategy and its effectiveness heavily depends on the specific model architecture, the size of the model, and the availability of hardware resources. Optimizing the communication between devices is a critical aspect of achieving high performance in parallel training. Strategies such as gradient accumulation and all-reduce algorithms are often employed to improve efficiency. The trade-offs between different parallel approaches must be carefully considered, as each method has its advantages and drawbacks. While significant advancements have been made, the efficient parallel training of truly massive LLMs remains an active area of research.
Future Work#
Future research directions stemming from this work on MEGALODON could focus on several key areas. Extending MEGALODON’s capabilities to handle diverse modalities beyond text, such as images and video, would significantly broaden its applicability. Improving the efficiency of the complex exponential moving average (CEMA) and timestep normalization is crucial for even greater scalability. Exploring architectural variations of MEGALODON, such as different attention mechanisms or residual connections, may unlock further performance gains. Finally, a thorough investigation into the theoretical underpinnings of MEGALODON’s success in long-context modeling is warranted to better understand its strengths and limitations compared to traditional transformer architectures. This could involve analyzing its inductive biases and exploring connections to state-space models.
More visual insights#
More on figures
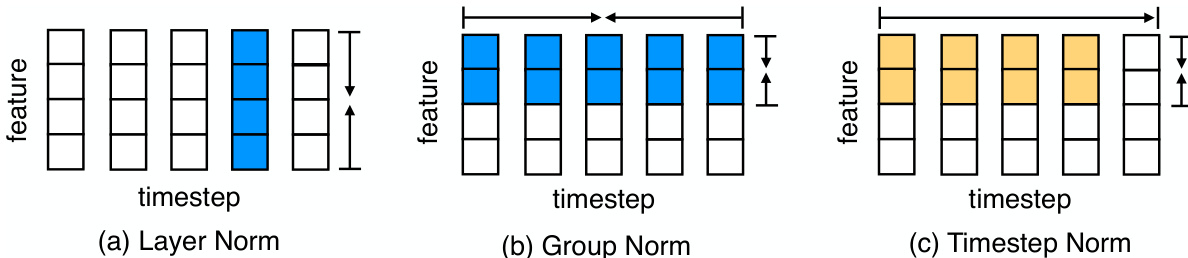
This figure compares three different normalization methods: Layer Normalization, Group Normalization, and Timestep Normalization. It visually represents how each method calculates the mean and variance for normalization. Layer Normalization computes these statistics across the feature dimension for each timestep. Group Normalization computes them across a subset of the feature dimension and all timesteps. Timestep Normalization calculates them cumulatively across the timesteps within each group of the feature dimension. The color coding helps to differentiate the regions over which the statistics are computed.
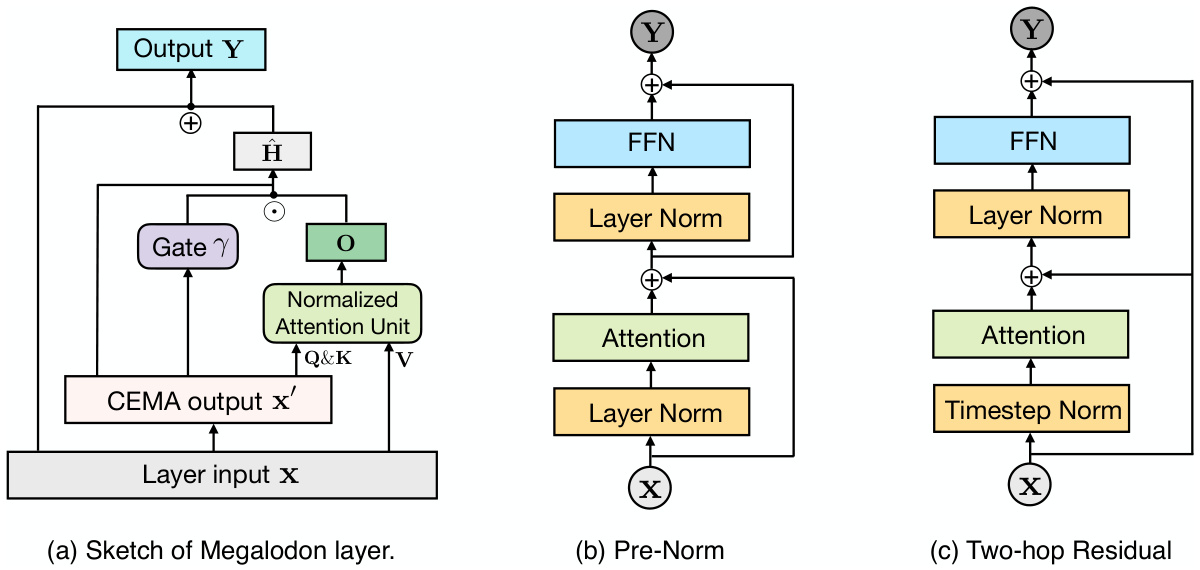
This figure illustrates the architecture of the MEGALODON model, showing a single layer’s components and highlighting the differences between three normalization strategies: standard pre-norm, and a novel pre-norm with two-hop residual configuration. The figure demonstrates the flow of information within a layer, including the complex exponential moving average (CEMA), normalized attention unit, and feed-forward network (FFN). The subfigures highlight how the placement of Layer Normalization and Timestep Normalization impacts the residual connections.

This figure compares the training speed (Tokens Per Second) of LLAMA2-7B and MEGALODON-7B models using 4K and 32K context lengths. It demonstrates that MEGALODON-7B is faster than LLAMA2-7B at 32K context length. At 4K context length, MEGALODON-7B is slightly slower than LLAMA2-7B. The y-axis represents tokens per second, a measure of speed. The x-axis shows the model and context length.
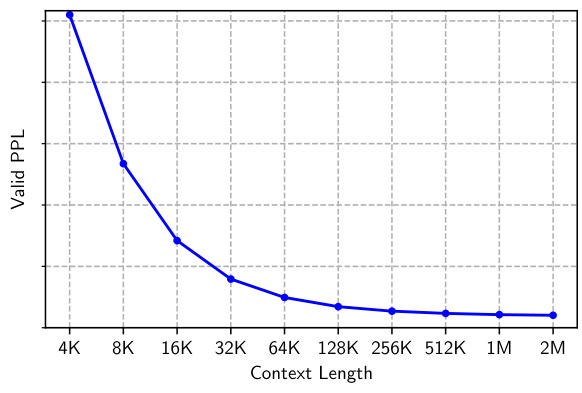
This figure shows the perplexity (PPL) scores for the MEGALODON-7B model on a validation dataset of long sequences (at least 2M tokens), for various context lengths ranging from 4K to 2M tokens. The graph shows a clear downward trend of the perplexity scores as the context length increases, demonstrating the model’s ability to leverage longer context windows for improved prediction accuracy.
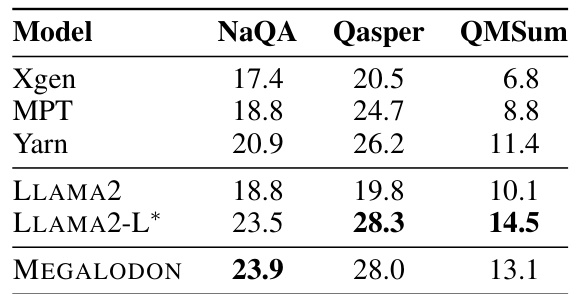
The figure shows the perplexity (PPL) scores for MEGALODON and other models across different context lengths, demonstrating the model’s ability to handle very long sequences. The x-axis represents context length, ranging from 4K to 2M tokens, and the y-axis shows the PPL. Lower PPL indicates better performance. The graph visually demonstrates that as context length increases, the perplexity decreases, indicating that MEGALODON effectively utilizes long-range dependencies.
More on tables
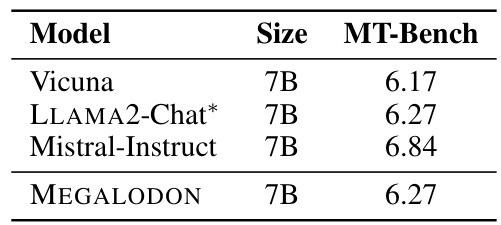
This table compares the performance of several 7B parameter chat models on the MT-Bench benchmark. The models include Vicuna, LLAMA2-Chat (which uses Reinforcement Learning from Human Feedback - RLHF), Mistral-Instruct, and MEGALODON. The MT-Bench score is a measure of the models’ performance on a variety of tasks, with lower scores indicating better performance. The table shows that MEGALODON performs comparably to LLAMA2-Chat, despite not using RLHF.
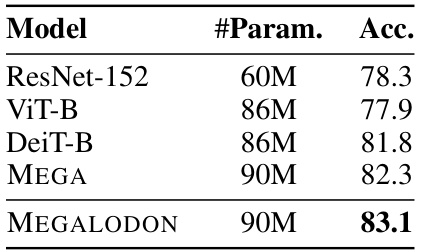
This table presents the top-1 accuracy results on the ImageNet-1K dataset for several different image classification models. The models compared include ResNet-152, ViT-B, DeiT-B, MEGA, and MEGALODON. The table shows the number of parameters for each model and its corresponding top-1 accuracy. The purpose is to benchmark the performance of MEGALODON against established and related models on a standard image classification task.
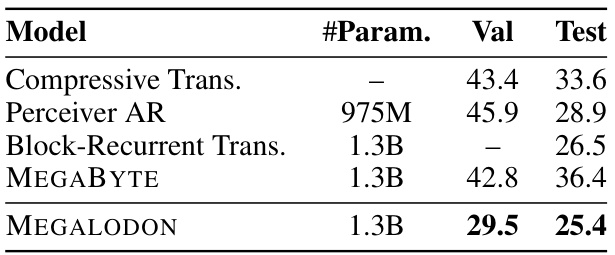
This table presents the word-level perplexity results on the PG-19 benchmark for several autoregressive language models, including the proposed MEGALODON model. The table compares MEGALODON’s performance against existing models with different parameter counts, showing its improved performance on this specific benchmark.

This table compares the performance of MEGALODON-7B against various other open-source language models on a range of standard academic benchmarks. The benchmarks assess capabilities in different areas like commonsense reasoning, world knowledge, reading comprehension, and question answering. The table also shows each model’s size (in billions of parameters), the context length (maximum sequence length it can handle), the total number of training tokens, and performance scores for each benchmark. The ‘-’ symbol shows when the original paper did not provide data for that entry. This allows for a direct comparison of MEGALODON’s performance against similar-sized models and highlights its strengths and weaknesses.

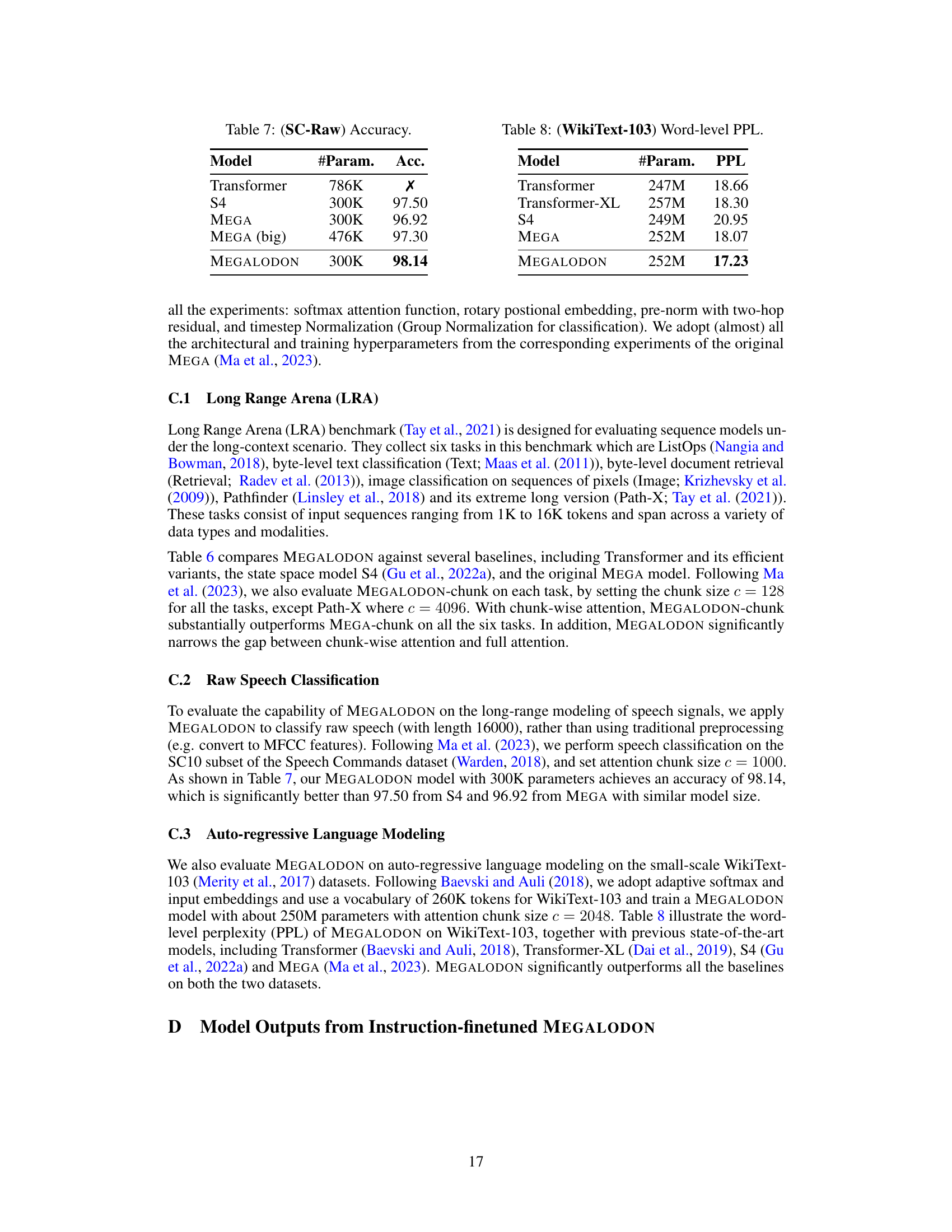
This table presents the results of the raw speech classification experiments using the Speech Commands dataset. The models are compared based on their accuracy and number of parameters. The goal is to evaluate how well the different models classify raw audio without the use of traditional signal processing techniques. MEGALODON achieves the highest accuracy (98.14) among the compared models.
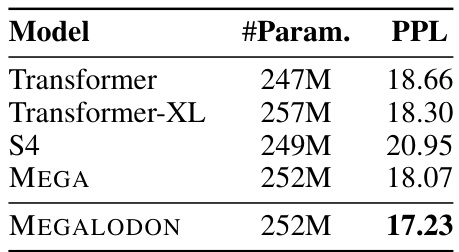
This table compares the word-level perplexity (PPL) results of several autoregressive language models on the WikiText-103 dataset. The models include a standard Transformer, Transformer-XL, S4, MEGA, and the proposed MEGALODON. The table shows the number of parameters and the PPL achieved by each model, highlighting MEGALODON’s improvement over existing models.
Full paper#