↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current AI alignment methods lack formal guarantees, hindering their use in critical applications like government. This paper tackles this challenge by focusing on social decision-making. It introduces the problem of AI misalignment, particularly the difficulty in formally guaranteeing the safety and reliability of AI systems used in critical decision-making processes. The lack of transparency and the inherent complexity of social systems create significant challenges in ensuring that AI agents’ objectives align with societal well-being.
The paper proposes a novel quantitative definition of alignment based on utility and social choice theory. It introduces the concept of ‘probably approximately aligned’ (PAA) policies, offering a measure of near-optimal alignment. Further, it presents a method to verify and guarantee the safety of policies, even in the presence of ‘black-box’ AI agents. This approach relies on a sufficient condition derived from social choice theory and leverages world models to assess potential societal impacts before actions are taken. The results demonstrate the existence of PAA policies under specific conditions, offering a theoretical foundation for building safer and more trustworthy AI systems for social decision-making.
Key Takeaways#
Why does it matter?#
This paper is crucial for AI safety and governance research. It provides a novel framework for quantifying AI alignment in social decision-making, addressing a critical gap in current research. The proposed methods, while theoretically focused, open doors for practical AI safety mechanisms and inspire new directions in evaluating and ensuring the beneficial use of autonomous agents in critical societal roles.
Visual Insights#
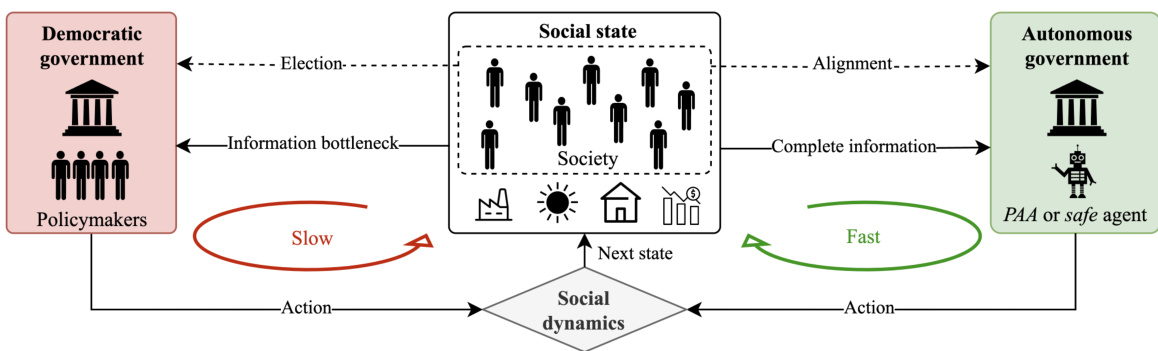
This figure illustrates the core idea of the paper: comparing a traditional democratic government with an AI-powered autonomous government. In a democracy, policymakers (a small group) are faced with an information bottleneck—they have limited access to the vast amount of information reflecting the society’s complex dynamics (social state). Their policy decisions are therefore slow and informed guesses. In contrast, a properly aligned autonomous government can efficiently process vast amounts of data about the social state and its dynamics, allowing for much faster policymaking. However, this requires a verifiable alignment mechanism to ensure the AI’s goals align with societal well-being.

This table shows the different social welfare functions (SWF) that can be derived from a social welfare functional (SWFL) that satisfies certain properties (universality (U), independence of irrelevant alternatives (IIA), weak Pareto criterion (WP), anonymity (A), and informational basis invariance (XI)). The properties of the SWFL determine the form of the corresponding SWF, and the informational basis (the level of measurability and comparability of individual utilities) further restricts the possible SWFs. For example, with only ordinal and non-comparable utilities, no SWF can be derived (Arrow’s impossibility theorem). However, under stronger assumptions on measurability and comparability, specific SWFs, such as the power mean, can be derived, and the specific parameter of the power mean depends on the informational basis.
Full paper#



















