↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Deep learning models often inherit biases from training datasets, leading to unreliable predictions. Existing methods struggle with comprehensive bias diagnosis and effective debiasing strategies. This necessitates new frameworks for analyzing and mitigating concept co-occurrence biases that are often at the root of flawed predictions.
The proposed CONBIAS framework addresses this challenge by modeling visual datasets as concept graphs, facilitating meticulous analysis of spurious concept co-occurrences. It introduces a novel clique-based concept balancing strategy to identify and mitigate imbalances. Experiments demonstrate that this method significantly improves model performance on downstream tasks compared to state-of-the-art approaches, highlighting the potential of CONBIAS for enhancing the fairness and reliability of AI models.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with visual data due to its novel approach of using concept graphs to diagnose and mitigate bias. It provides a principled framework that goes beyond traditional methods, addressing limitations in existing bias detection and debiasing techniques. This work opens avenues for future research on bias detection in more complex datasets and offers a human-interpretable methodology, improving the fairness and reliability of AI models.
Visual Insights#
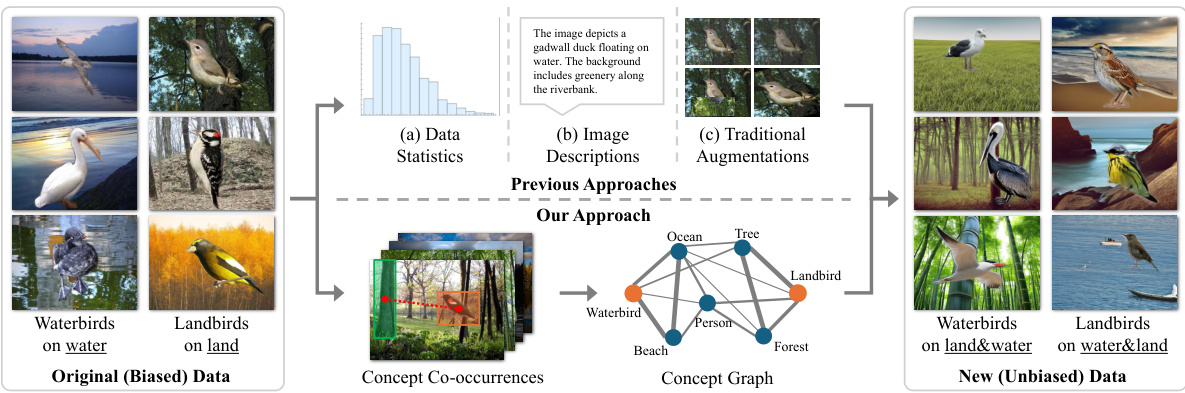
This figure illustrates the difference between traditional data diagnosis and augmentation methods and the proposed CONBIAS framework. Traditional methods use data statistics, image descriptions, and traditional augmentation techniques. The CONBIAS framework uses a concept graph that models visual data as a knowledge graph of concepts to diagnose and mitigate concept co-occurrence biases in visual datasets. The concept graph facilitates a systematic diagnosis of class-concept imbalances, allowing for a more principled approach to debiasing.
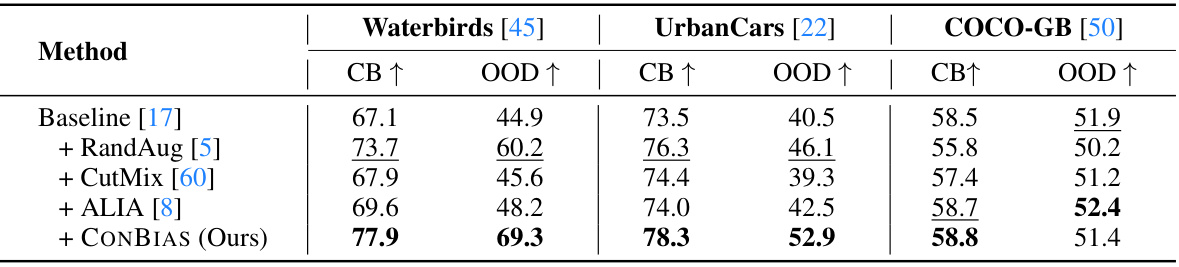
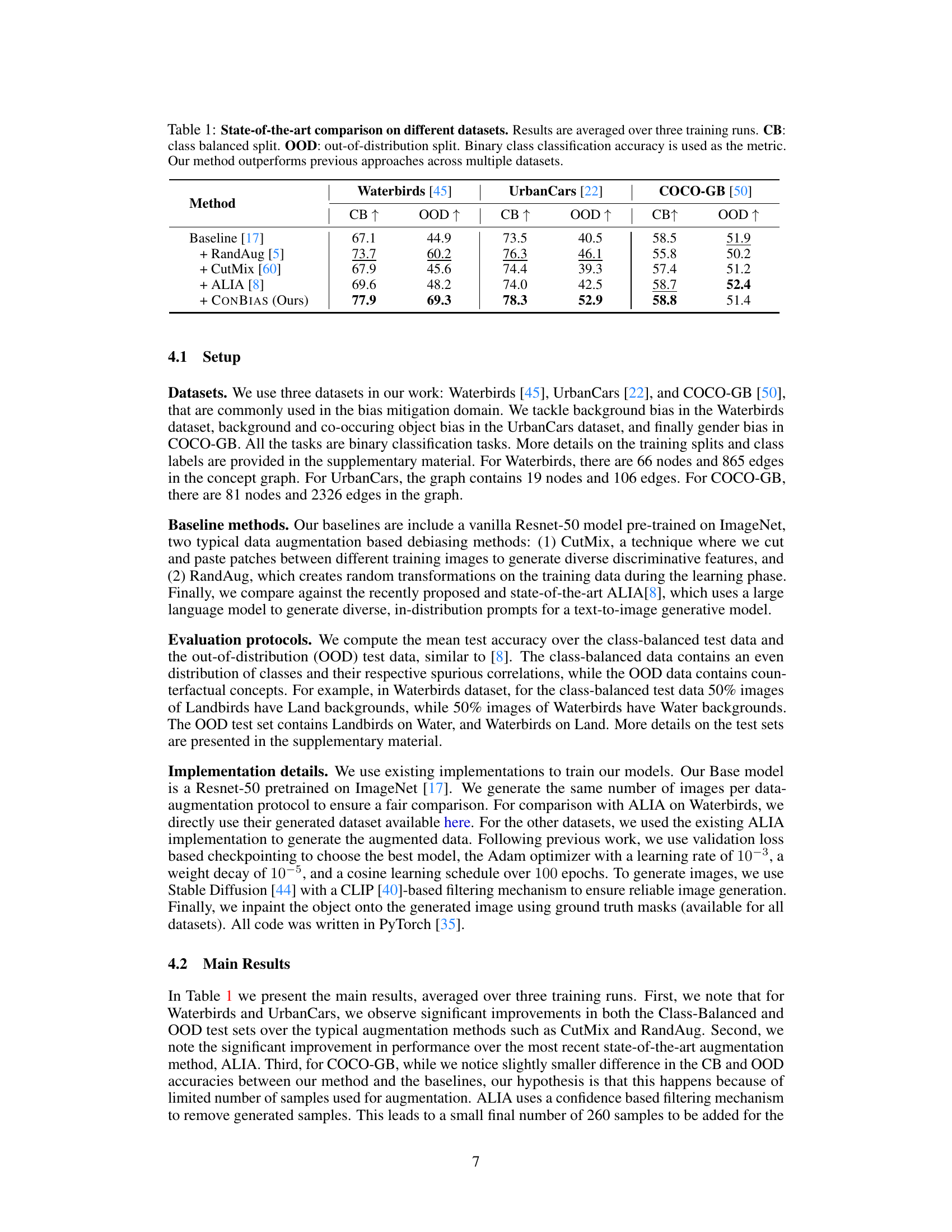
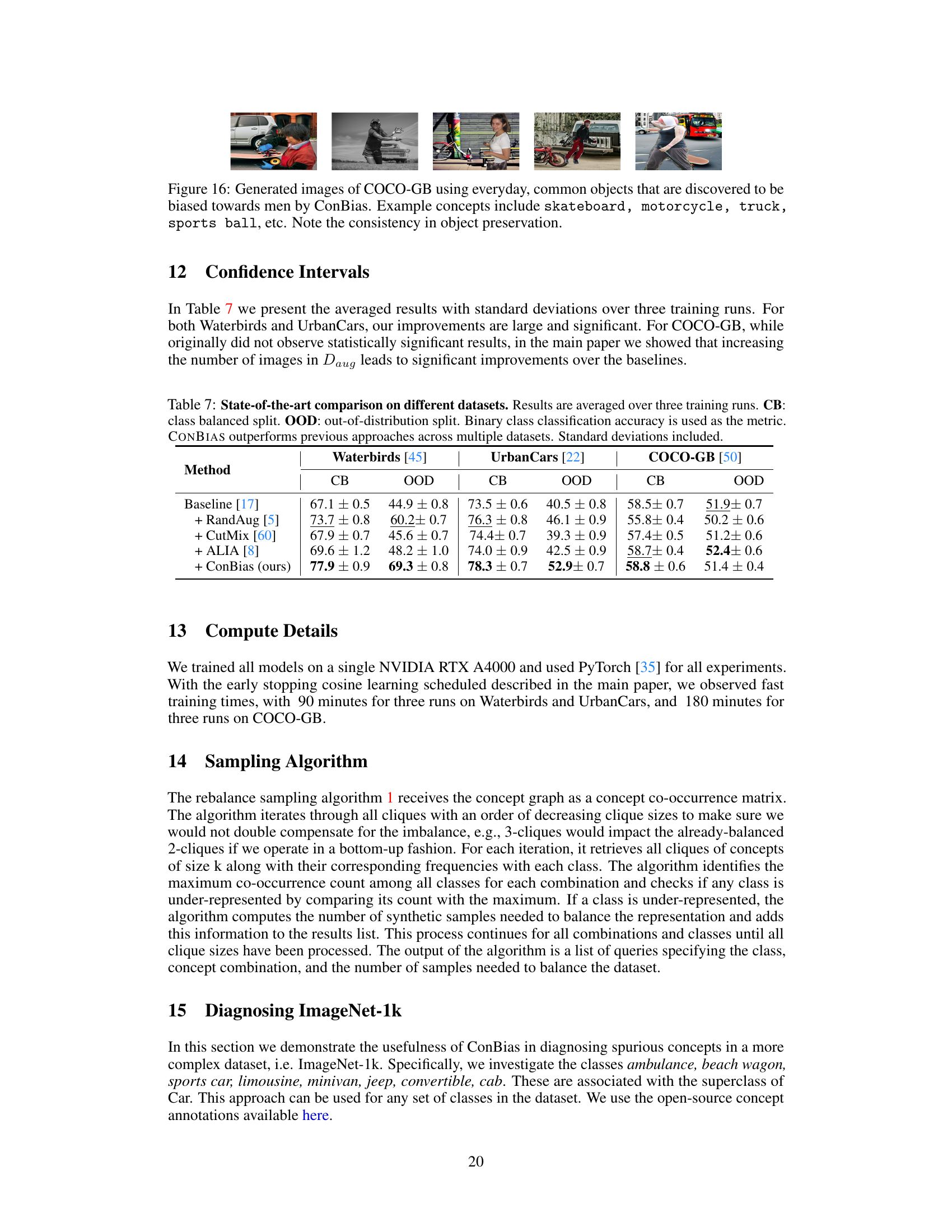
This table presents a comparison of the proposed CONBIAS method against several baseline and state-of-the-art methods on three different datasets: Waterbirds, UrbanCars, and COCO-GB. For each dataset, the table shows the classification accuracy achieved by each method on both class-balanced (CB) and out-of-distribution (OOD) test sets. The class-balanced set has an even distribution of classes, while the OOD set includes counterfactual concepts (e.g., landbirds with water backgrounds). The results demonstrate that CONBIAS consistently outperforms the other methods across all datasets and evaluation metrics.
In-depth insights#
Concept Graph Bias#
The concept of “Concept Graph Bias” highlights how biases, often subtle and systemic, can become embedded within the structure of knowledge graphs representing visual data. Biases manifest not only in the data itself but also in the relationships between concepts, leading to skewed co-occurrence patterns. A biased concept graph, therefore, reflects and amplifies these biases, potentially impacting the fairness and accuracy of any downstream applications built upon it. For instance, if a concept graph disproportionately links certain object classes to specific contextual features (e.g., associating “waterbirds” mostly with water scenes, neglecting land-based occurrences), this creates a bias which AI systems trained on this graph would inherit. This systematic bias isn’t easily detected through simple data inspection and necessitates specialized diagnostic tools that can analyze the graph structure and identify imbalance in concept relationships. Mitigating concept graph bias involves strategies to rebalance the concept co-occurrences, creating a more balanced and representative knowledge graph. This may include data augmentation to generate images that address the identified imbalances, thereby improving the fairness and robustness of AI systems trained on such data.
Clique-Based Debiasing#
The concept of ‘Clique-Based Debiasing’ presents a novel approach to mitigating biases in visual datasets. It leverages the structure of a concept graph, where nodes represent classes and concepts, and edges denote co-occurrences. The core idea is to identify imbalanced cliques (fully connected subgraphs) within this graph, representing under-represented combinations of classes and their associated concepts. This imbalance indicates bias, as certain concept combinations are disproportionately associated with specific classes. The proposed method then addresses the imbalance by generating synthetic images that include these under-represented combinations, effectively augmenting the training data to improve the model’s fairness and generalization capability. This approach is principled and interpretable because it directly tackles imbalances in the dataset using the underlying conceptual relationships visualized by the graph, bypassing reliance on potentially biased large language models for data augmentation. By focusing on cliques, it offers a structured and computationally manageable way to identify and rectify bias. The effectiveness is validated by improved performance on downstream tasks across multiple datasets. However, further investigation is needed into the scalability for extremely large datasets and the diversity of biases it can effectively address.
Generative Image Synth#
Generative image synthesis, in the context of a research paper, likely explores the creation of novel images using AI. A key aspect would be the methodology, detailing techniques like GANs, VAEs, diffusion models, or other architectures. The evaluation section would be crucial, examining the quality of generated images through metrics like FID or IS, as well as qualitative assessments. A focus on applications (e.g., data augmentation, novel image generation) would highlight the practical implications. Bias and ethical considerations in generated data are also important, particularly if the model is trained on real-world datasets. Finally, a discussion of limitations (e.g., computational cost, potential for misuse) would provide a balanced perspective.
Benchmark Datasets#
Benchmark datasets are crucial for evaluating the performance and generalizability of deep learning models, especially in the context of bias mitigation. A well-constructed benchmark should encompass a diverse range of images representing various demographics, geographic locations, and object contexts. It is important that these datasets accurately reflect real-world scenarios and avoid biases that might lead to unfair or discriminatory outcomes. Careful consideration of label quality, image resolution, and overall data diversity is necessary for creating a truly robust and useful benchmark. The selection of appropriate metrics for bias detection and model evaluation are also paramount. The availability of pre-trained models and readily available code further enhances the accessibility and usability of the benchmark, attracting broader participation and collaboration within the research community. Ultimately, a well-designed benchmark facilitates the development of more equitable and robust AI systems by providing a common standard for measuring progress and identifying areas needing further improvement.
Future Research#
Future research directions stemming from this work on visual data diagnosis and debiasing using concept graphs are multifaceted. Improving the efficiency of clique enumeration in large graphs is crucial to broaden applicability. Exploring a wider range of biases beyond object co-occurrence, such as those related to texture, shape, or even social biases, is necessary for a more holistic approach. Developing methods that function effectively with incomplete or noisy concept annotations would significantly improve real-world applicability. Investigating the impact of different generative models and exploring methods for creating higher-quality, less biased synthetic images also warrants further investigation. Finally, evaluating the performance and limitations of the proposed framework across diverse downstream tasks is vital, as biases manifest differently in various applications. Ultimately, a comprehensive understanding and mitigation of biases is an ongoing challenge requiring collaborative effort and innovative solutions. The development of more sophisticated bias detection methods and the creation of tools that assist in effectively mitigating these issues will remain crucial areas for future research.
More visual insights#
More on figures

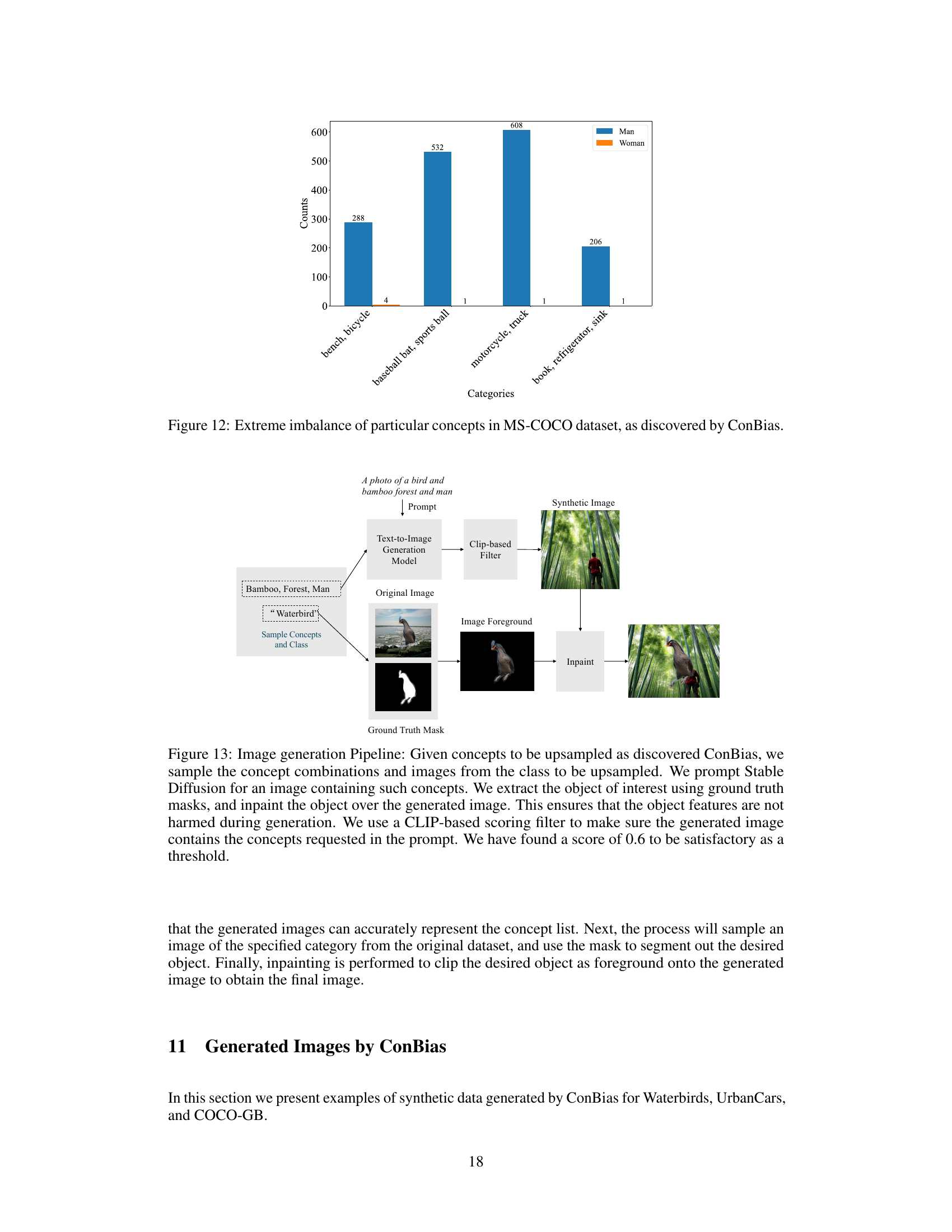
This figure illustrates the CONBIAS framework. It starts with a biased dataset (a) containing images and associated concept metadata. From this, a concept graph (b) is constructed showing concept co-occurrences and their frequencies. The graph is analyzed to identify imbalanced class-concept combinations (concept diagnosis, d) which are then used for clique-based sampling (c). This sampling process generates new images (e) to balance the dataset, effectively debiasing the original data.

This figure shows examples of concept cliques identified by the CONBIAS framework for the ‘Landbird’ class within the Waterbirds dataset. The concept cliques highlight groups of concepts (e.g., Forest, Man, Woman, Bamboo) that frequently co-occur with the Landbird class, even though they are not causally related to the bird itself. This co-occurrence is identified as a spurious correlation or bias, indicating an imbalance in the dataset. The orange boxes indicate the concepts considered by the algorithm in those images.
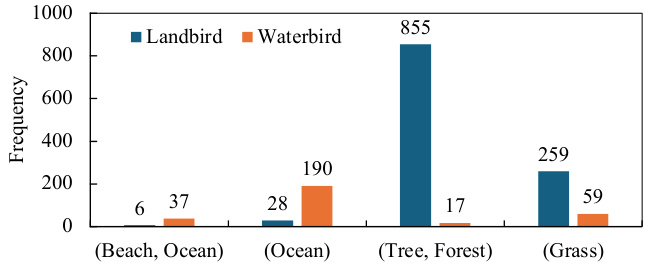
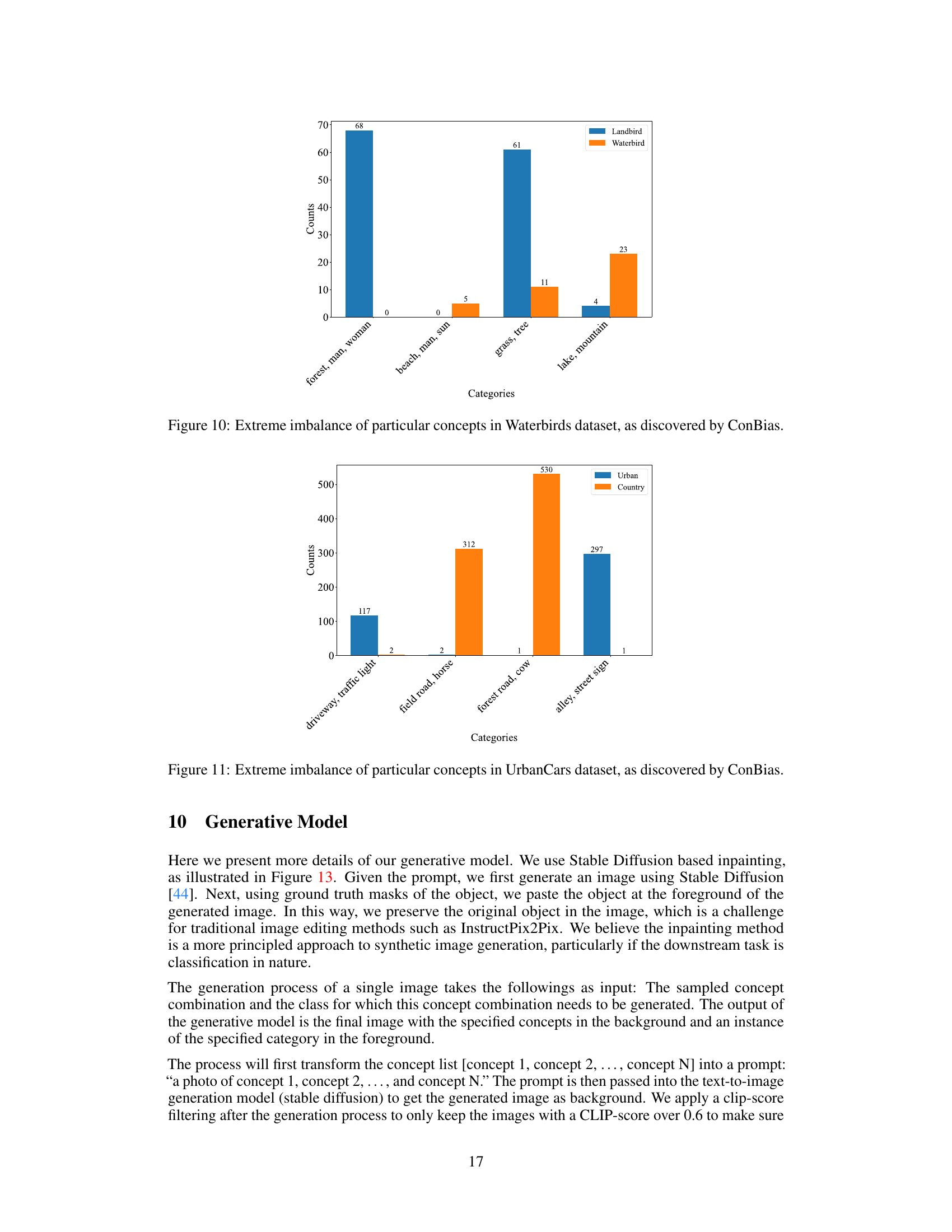
This figure shows the frequency of single concepts and concept combinations in the Waterbirds dataset. The imbalances highlight a bias where landbirds are predominantly shown with land backgrounds (grass, trees, forests) and waterbirds with water backgrounds (ocean, beach). This co-occurrence bias is a spurious correlation that the paper aims to address.

This figure shows the performance of the proposed method, CONBIAS, on the COCO-GB dataset. The plot displays the accuracy on both Class-Balanced (CB) and Out-of-Distribution (OOD) test sets as the number of augmented images added to the training dataset increases. The results indicate that CONBIAS achieves improved accuracy on both sets as more augmented images are included, suggesting that the augmentation strategy effectively addresses biases in the dataset. However, the improvement plateaus around 1000 images.

This figure illustrates the CONBIAS framework’s workflow. It starts with a biased dataset and its associated concept metadata (a). A concept graph is then constructed to visualize object co-occurrences (b), revealing imbalanced combinations. These imbalances are diagnosed using clique-based sampling (c,d). Finally, the framework generates new images to balance the concept distribution, resulting in a debiased dataset (e).

This figure illustrates the CONBIAS framework. It shows how a biased dataset is represented as a concept graph (nodes are classes and concepts, edges represent co-occurrence). The framework then diagnoses imbalances in the graph, samples under-represented combinations, and generates new images to debias the data. The result is a fairer, more balanced dataset.

This figure illustrates the CONBIAS framework, showing the process from a biased dataset with concept metadata to a debiased dataset. It highlights the creation of a concept graph from co-occurrence data, the identification of biases using clique-based sampling, and the generation of new, debiased images using a text-to-image model. The figure visually represents each step of the CONBIAS pipeline, making the process clear and easy to understand.

This figure illustrates the CONBIAS framework for diagnosing and debiasing visual data. It shows the steps involved: 1) building a concept graph from dataset metadata, 2) diagnosing biases by analyzing concept co-occurrences, 3) sampling imbalanced concept combinations using cliques, and 4) generating images to address biases using a text-to-image model. The resulting debiased dataset is then used to train a classifier.
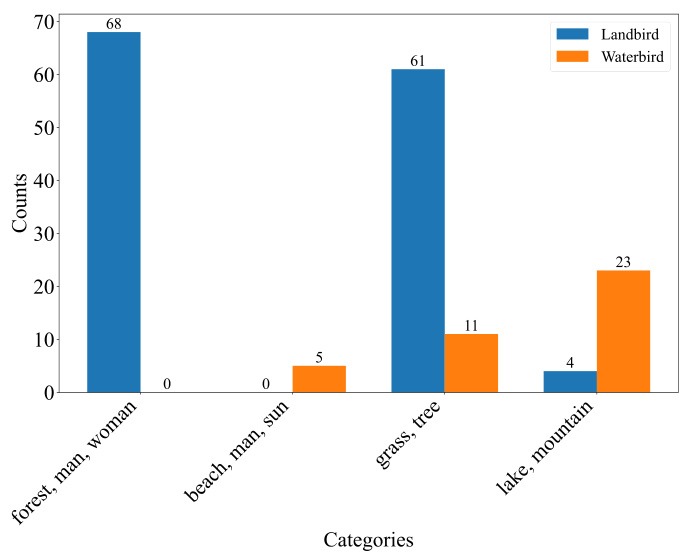
The figure is a bar chart showing the counts of particular concept combinations in the Waterbirds dataset. The concepts are grouped into categories (e.g., ‘forest, man, woman’, ‘beach, man, sun’, etc.), and the counts are further broken down by class (Landbird and Waterbird). The chart reveals a significant imbalance in the co-occurrence of certain concepts with each class, indicating a bias in the dataset. For example, the concept combination ‘forest, man, woman’ appears significantly more often with the Landbird class, while ‘beach, man, sun’ is heavily associated with the Waterbird class. This imbalance highlights the spurious correlations between concepts and classes that ConBias is designed to detect and mitigate.

This figure shows the imbalanced distribution of concepts (like driveway, traffic light, field road, horse, forest road, cow, alley, street sign) in the UrbanCars dataset according to the analysis performed by ConBias. The x-axis represents different categories, each combining several concepts that occur together. The y-axis represents the count of these concept combinations in images associated with the ‘Urban’ and ‘Country’ classes. The bar chart clearly shows that certain concept combinations are heavily associated with one class over another, thus pointing to an inherent bias in the dataset that could influence model performance. This visualization highlights the effectiveness of ConBias in identifying such biases.
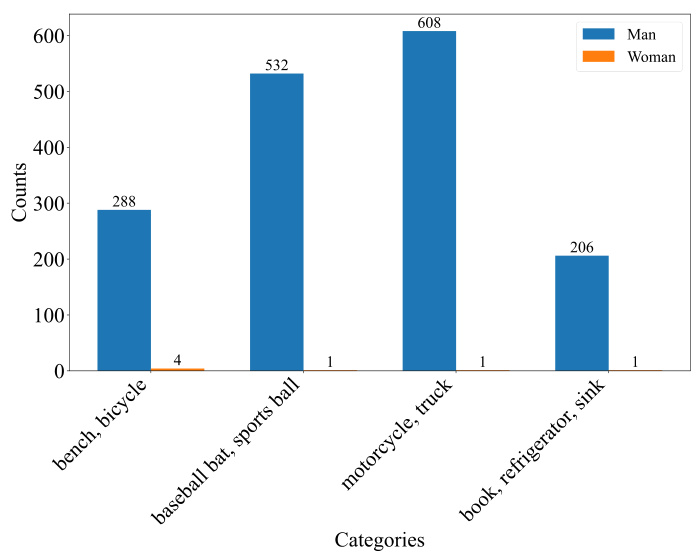
This figure shows the extreme concept imbalances discovered by the CONBIAS framework in the MS-COCO dataset. It reveals a significant bias in the association of certain concepts with the ‘Man’ class compared to the ‘Woman’ class. For instance, concepts like ‘baseball bat’, ‘sports ball’, ‘motorcycle’, and ’truck’ overwhelmingly appear with images of men, while concepts like ‘book’, ‘refrigerator’, and ‘sink’ are significantly underrepresented in images featuring men. This visualization highlights the skewed co-occurrence patterns that CONBIAS aims to identify and address during the dataset debiasing process.
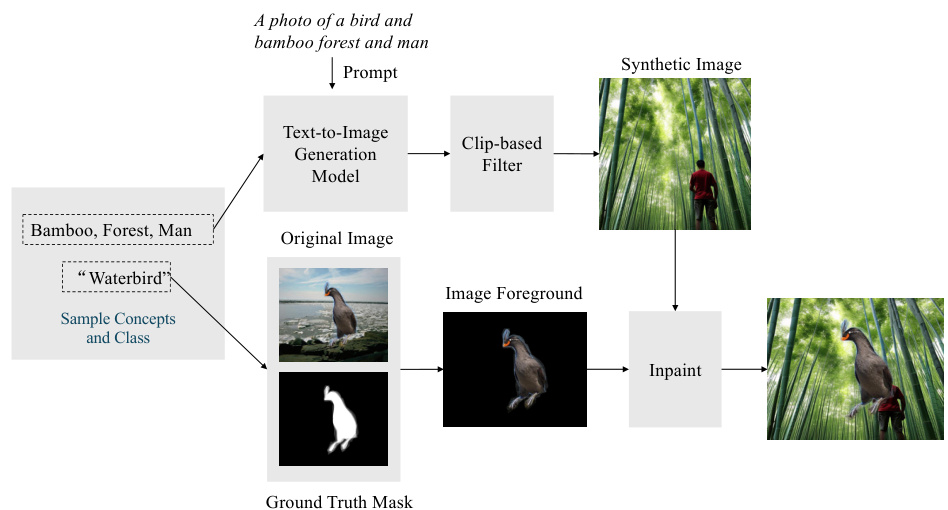
The figure illustrates the CONBIAS framework. It starts with a biased dataset and its associated concept metadata (a). This data is then used to construct a concept graph (b), which reveals concept co-occurrences and imbalances. The clique-based sampling strategy (c) identifies under-represented combinations, leading to a dataset diagnosis (d). Finally, using a text-to-image model, new images are generated to rebalance the dataset (e).

This figure illustrates the CONBIAS framework. It starts with a biased dataset and its concept metadata (a). A concept graph is constructed from object co-occurrences (b), which is then analyzed for imbalances (c, d). Finally, images are generated to address the under-represented combinations, resulting in a de-biased dataset (e).

This figure illustrates the CONBIAS framework. Panel (a) shows a biased dataset with concept metadata. Panel (b) shows the construction of a concept graph from the dataset, where nodes represent classes and concepts and edges represent co-occurrence. The thickness of the edges indicates the frequency of co-occurrence. Panel (c) illustrates the clique-based sampling strategy used to identify under-represented concept combinations. Panel (d) shows the results of the dataset diagnosis, highlighting biases. Finally, Panel (e) demonstrates how the identified biases are addressed by generating new, unbiased images using a text-to-image model.

This figure illustrates the CONBIAS framework. It starts with a biased dataset and its concept metadata (a). A concept graph is constructed from object co-occurrences, with edge thickness representing frequency (b). The graph is analyzed to identify imbalanced class-concept combinations (c, d), and then new images are generated to address these imbalances (e), resulting in a debiased dataset.
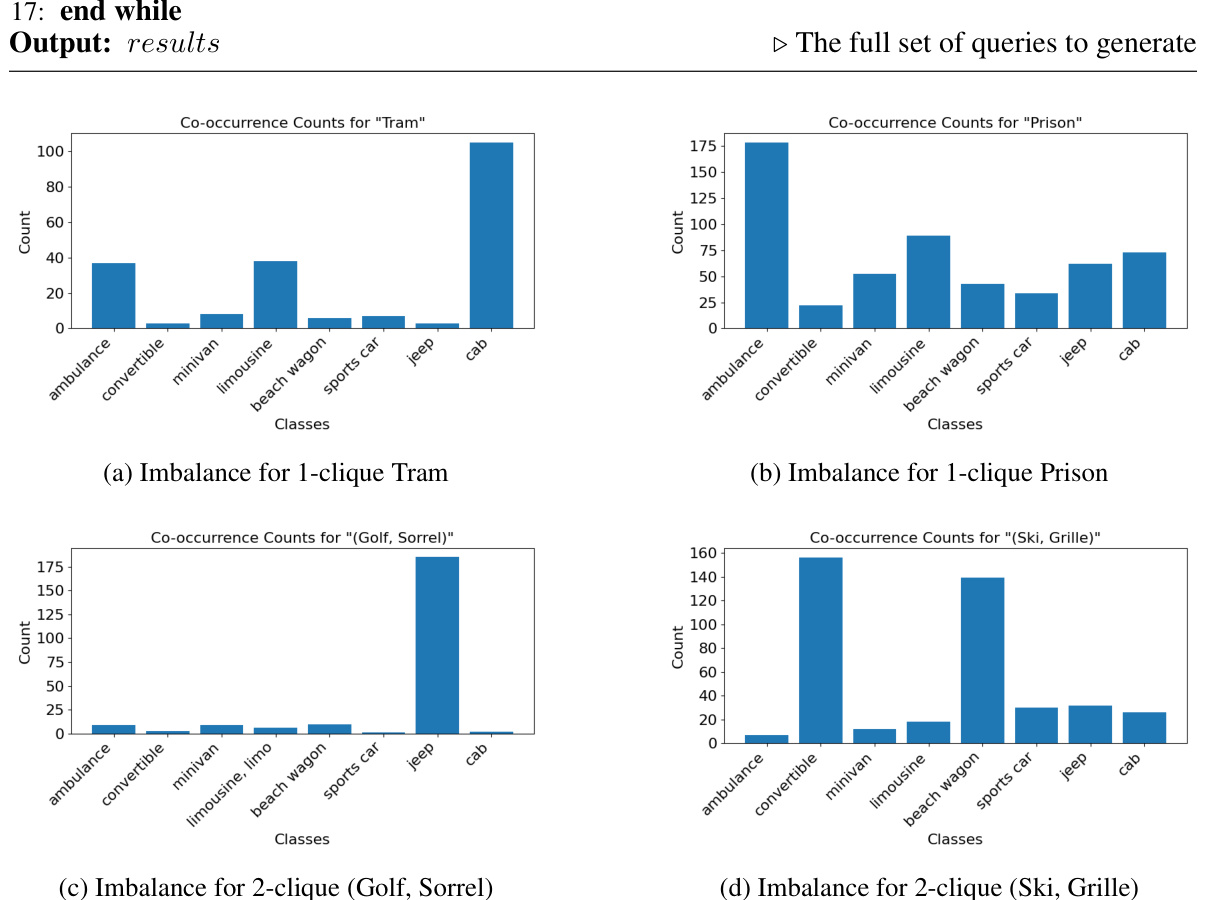
This figure illustrates the CONBIAS framework’s pipeline. It starts with a biased dataset and its associated concept metadata (a). From this, a concept graph is constructed, visualizing object co-occurrences (b). The graph is analyzed to identify imbalanced class-concept combinations (concept diagnosis, c,d). Finally, the system generates images to address these imbalances, leading to a debiased dataset (e).
More on tables
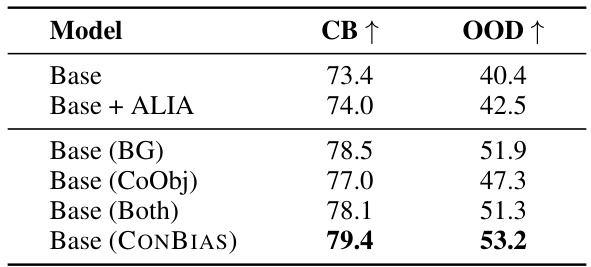
This table presents a comparison of the performance of the CONBIAS method with and without leveraging the graph structure. It demonstrates that utilizing the graph structure for concept analysis leads to improved results on the UrbanCars dataset compared to using a simpler approach that only counts the frequency of single concept-class combinations. The table highlights the advantage of the graph-based approach for identifying and mitigating biases in visual data.
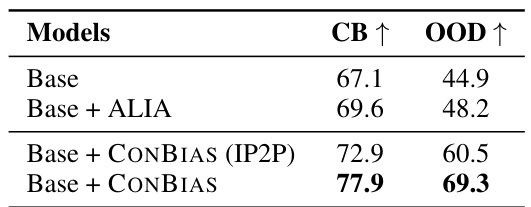
This table presents a comparison of the proposed CONBIAS method against several baseline and state-of-the-art methods on three different datasets: Waterbirds, UrbanCars, and COCO-GB. For each dataset, the table shows the classification accuracy (using binary classification) achieved by each method on both class-balanced (CB) and out-of-distribution (OOD) test splits. The class-balanced split contains an even distribution of samples across the classes, whereas the OOD split tests generalization by including samples that contain spurious correlations. The results demonstrate that CONBIAS consistently outperforms other methods.

This table presents a comparison of the proposed CONBIAS method against several baselines and a state-of-the-art method (ALIA) on three different datasets: Waterbirds, UrbanCars, and COCO-GB. For each dataset, the table shows the classification accuracy on two different test set splits: a class-balanced split (CB) and an out-of-distribution (OOD) split. The class-balanced split represents a standard evaluation, while the out-of-distribution split tests the robustness of the models to scenarios with spurious correlations. The results demonstrate that CONBIAS significantly improves performance on all three datasets compared to the other methods.
This table presents a comparison of the proposed CONBIAS method against several baseline methods on three different datasets (Waterbirds, UrbanCars, and COCO-GB). The performance is evaluated using two metrics: class-balanced accuracy (CB) and out-of-distribution accuracy (OOD). The results show that CONBIAS consistently outperforms the baselines across all datasets and metrics.

This table presents a comparison of the proposed CONBIAS method against several baseline and state-of-the-art methods on three different datasets: Waterbirds, UrbanCars, and COCO-GB. For each dataset, the table shows the classification accuracy using two different data splits: a class-balanced split (CB) and an out-of-distribution (OOD) split. The results demonstrate the superior performance of the CONBIAS method in terms of classification accuracy compared to the baselines across all datasets and data splits.

This table presents a comparison of the proposed CONBIAS method against several baseline and state-of-the-art methods on three different datasets (Waterbirds, UrbanCars, COCO-GB). For each dataset, the table shows the classification accuracy on both class-balanced (CB) and out-of-distribution (OOD) test sets. The CB split ensures an even distribution of classes, while the OOD split contains counterfactual concepts designed to expose biases. The results demonstrate the superior performance of CONBIAS in mitigating biases and improving generalization.
Full paper#