↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Training adaptable AI agents is bottlenecked by the need for vast amounts of training data representative of the target domain. Existing methods like domain randomization and procedural generation require carefully defined parameters, limiting their applicability to complex simulators. Meta-reinforcement learning offers a solution by focusing on few-shot adaptation but still suffers from the need for sufficiently diverse training data.
The paper introduces DIVA, a novel evolutionary approach that generates diverse training tasks within complex, open-ended simulators. Unlike previous methods, DIVA requires only limited supervision in the form of sample features from the target distribution and incorporates domain knowledge when available, making it flexible and applicable to diverse scenarios. DIVA successfully trains adaptive agents in three benchmark simulators (GRIDNAV, ALCHEMY, and RACING), significantly outperforming existing baselines.
Key Takeaways#
Why does it matter?#
This paper is significant because it tackles the challenge of training adaptable agents in complex, open-ended simulators, a crucial problem in AI. The semi-supervised environment design (SSED) approach, DIVA, offers a novel solution by efficiently generating diverse training tasks, overcoming limitations of existing methods. This opens new avenues for research in meta-reinforcement learning, improving the robustness and capabilities of AI agents in real-world scenarios.
Visual Insights#

This figure illustrates the core idea of DIVA. Highly structured simulators (left) have parameters that directly control the diversity of generated environments. Open-ended simulators (middle) have flexible, unstructured parameters, making it difficult to directly control diversity. DIVA (right) evolves a new parameterization by using quality diversity (QD) to discover diverse levels from the open-ended simulator, effectively creating a more workable representation of the environment space that allows for better agent training.

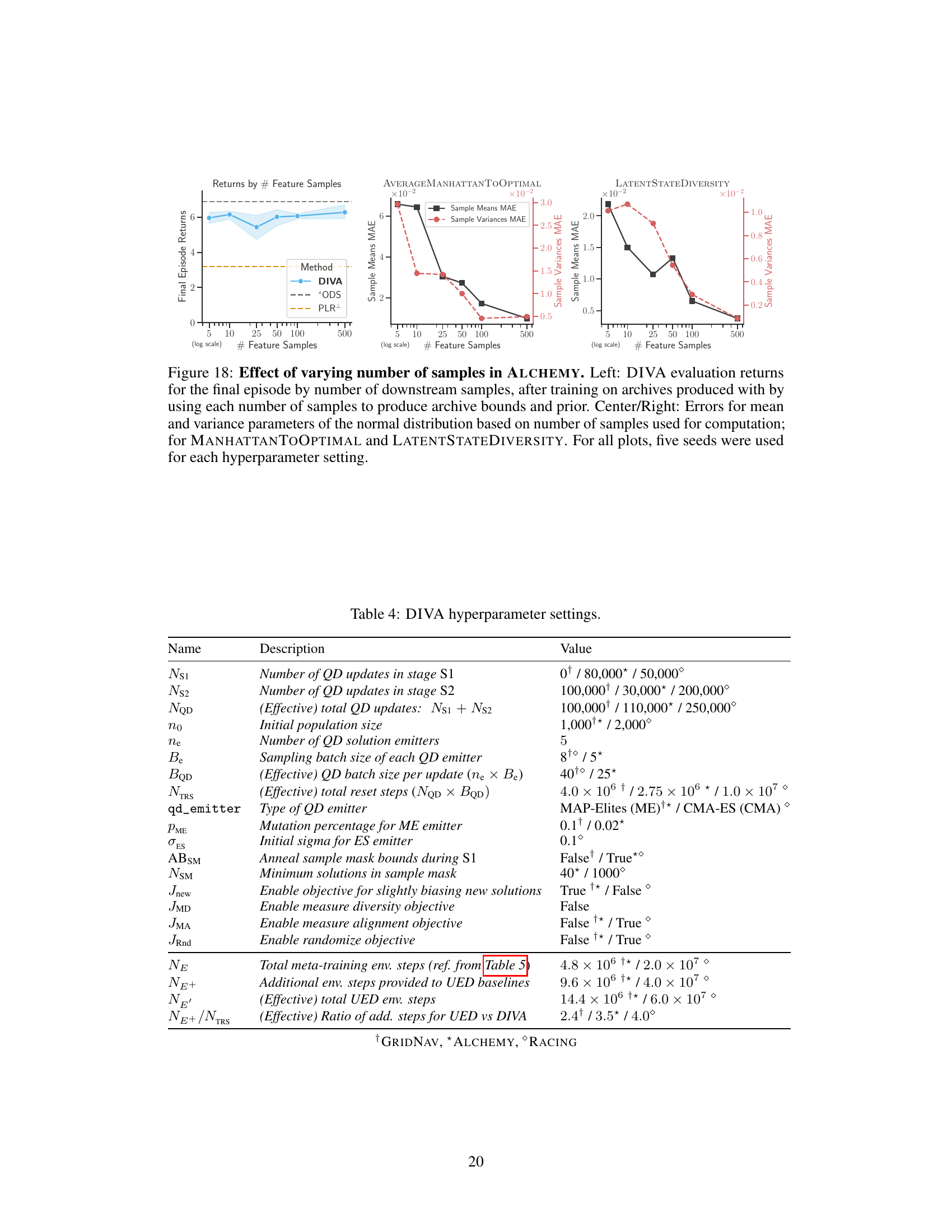
This table lists the hyperparameters used in the DIVA algorithm. It breaks down hyperparameters for the two stages of quality diversity (QD) updates (Ns1 and Ns2), the total number of QD updates (NQD), the initial population size (no), the number of QD solution emitters (Ne), and the sampling batch size of each QD emitter (Be). Further hyperparameters are detailed for the effective QD batch size per update, the total number of reset steps, the type of QD emitter (MAP-Elites or CMA-ES), and various other settings related to the quality diversity approach and the meta-learning algorithm (VariBAD). The table also provides values for each hyperparameter used for the GRIDNAV, ALCHEMY, and RACING experiments.
In-depth insights#
Adaptive Agent Meta-RL#
Adaptive Agent Meta-RL represents a significant advancement in reinforcement learning, aiming to create agents capable of adapting to unseen environments and tasks. Meta-learning allows the agent to learn how to learn, improving generalization beyond the training data. Few-shot adaptation is a key goal, enabling rapid learning from minimal examples in a new situation. However, challenges remain in applying this to complex real-world scenarios. Data efficiency is crucial; collecting diverse and sufficient training data for meta-RL is labor-intensive. Simulators offer promise but creating varied and realistic training environments presents an obstacle. Open-ended simulators, while offering complexity, lack inherent mechanisms to generate diverse tasks. This necessitates innovative environment design methods that focus on diversity and relevance to specific problems. Successfully tackling these issues will lead to more robust and adaptive AI agents applicable to a wider range of real-world problems.
DIVA: Evolving Tasks#
The concept of “DIVA: Evolving Tasks” presents a novel approach to training agents in complex, open-ended environments. Instead of relying on pre-defined tasks, DIVA leverages an evolutionary algorithm to generate diverse and challenging tasks, directly addressing the limitations of hand-crafting or relying on simple randomization. This dynamic task generation enables the agent to learn robust and adaptable behaviors, surpassing methods based on static task distributions. The evolutionary process in DIVA is guided by quality diversity (QD) optimization, ensuring the generated tasks are both challenging and meaningfully different along specific axes of diversity. This semi-supervised approach, incorporating domain knowledge where available, is a significant advancement over fully unsupervised methods, improving efficiency and effectiveness in exploring the vast solution space. The key insight is that DIVA moves beyond simple parameter randomization or procedural generation, offering a more flexible and powerful framework for adaptive agent training in realistic, complex simulations.
QD-Based Env Design#
Employing Quality Diversity (QD) for environment design in reinforcement learning (RL) offers a powerful strategy to automatically generate diverse and challenging training scenarios. QD algorithms excel at exploring the vast space of possible environments, identifying those that are both high-quality (in terms of providing effective training) and diverse (in terms of the skills they necessitate). This approach contrasts sharply with traditional hand-crafted environments or simpler methods like domain randomization, which often fail to capture the full complexity and richness needed to train robust and generalizable agents. A key advantage is the ability to define and control the axes of diversity, allowing researchers to target specific skills or challenges relevant to the target task. This targeted diversity is crucial for efficient training and transfer to unseen environments. However, challenges remain. Effectively defining meaningful features and metrics that capture the desired diversity is crucial, as an ill-defined feature space might lead to unproductive exploration. Moreover, the computational cost of evaluating many different generated environments can be significant, especially in complex simulations. Therefore, careful consideration of feature selection and efficient evaluation strategies is essential for success. This makes QD-based env design a promising but computationally demanding approach that requires careful tuning and design.
Open-Ended Simulators#
Open-ended simulators represent a significant advancement in artificial intelligence research, offering a flexible and complex environment for training agents. Unlike traditional simulators with predefined tasks and parameters, open-ended simulators allow for emergent behavior and unpredictable interactions. This complexity presents challenges, necessitating robust training methods capable of handling diverse and unforeseen situations. Adaptive learning techniques, such as meta-reinforcement learning, are crucial in this context, enabling agents to generalize their knowledge to new scenarios within the dynamic simulated world. However, the very nature of open-endedness also raises questions on evaluation and measuring progress. Benchmarking and defining meaningful metrics in these environments become critical for assessing the effectiveness of different training approaches and for making fair comparisons.
Future SSED Research#
Future research in semi-supervised environment design (SSED) holds significant promise. One key area is automating the selection of relevant features for quality diversity (QD) optimization. Currently, feature selection relies on human expertise; algorithms to automate this process are needed. Integrating unsupervised environment design (UED) techniques with SSED is another crucial avenue. While UED methods offer generality, they can be inefficient in complex environments. Combining UED’s flexibility with SSED’s targeted diversity could yield more efficient and effective training. Further investigation into the interplay between QD archive design and agent performance is also vital. Better understanding of how to optimally configure QD archives to maximize training efficiency and generalization remains a major open question. Finally, extending SSED to more complex and realistic simulations, potentially leveraging neural environment generators, would accelerate the development of robust adaptive agents capable of tackling real-world problems. Exploring different QD algorithms and integrating advanced exploration strategies are also important avenues to explore.
More visual insights#
More on figures

This figure shows the two stages of DIVA’s archive update process. Stage 1 starts with broad bounds encompassing both initial solutions and a target region defined by downstream task features. As the QD algorithm explores the solution space, the sampling region narrows toward the target. Stage 2 resets the archive bounds to match the target region, adding extra dimensions. The algorithm then populates this refined target region using weighted samples, mirroring the distribution of tasks used during meta-training.

The figure illustrates the difference between structured and unstructured environment simulators. In structured simulators, parameters directly translate to meaningful task diversity, while in unstructured simulators, such control is lacking. DIVA, a novel approach, is introduced to create a more workable parameterization by evolving levels, leading to enhanced performance in downstream tasks.

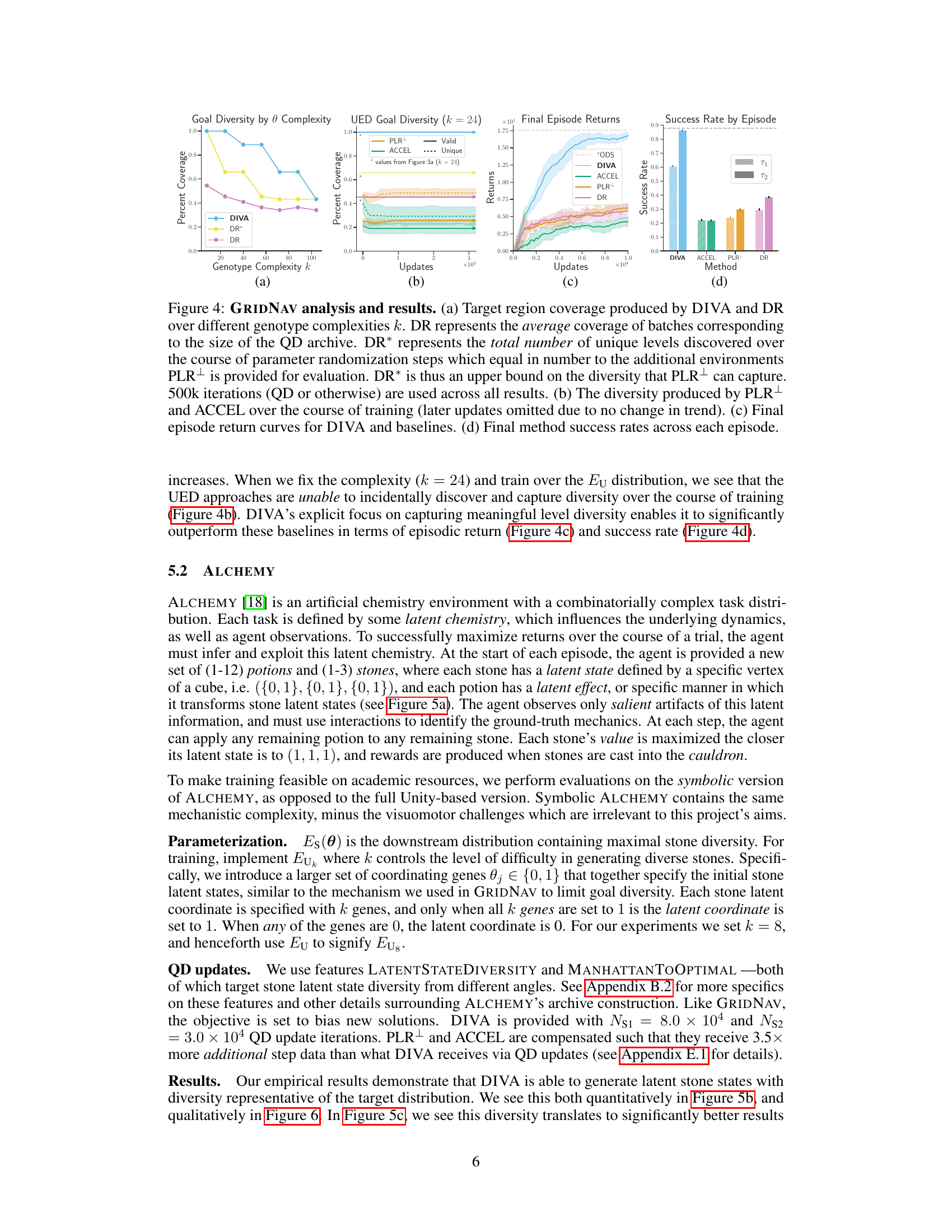
This figure presents an empirical evaluation of DIVA and three baselines on the GRIDNAV task. Panel (a) compares the diversity of environments generated by DIVA and domain randomization (DR), showing DIVA’s ability to maintain diversity even with increased task complexity. Panels (b), (c), and (d) show that DIVA outperforms the baselines in terms of diversity of explored environments, average episode return, and success rate, respectively. This demonstrates DIVA’s effectiveness in generating diverse and challenging training environments.

This figure presents a visual representation of the ALCHEMY environment and the results of DIVA’s performance against various baselines. Subfigure (a) shows a diagram of the stone latent space and how potions affect stone states. Subfigure (b) displays the marginal feature distributions for the target distribution (Es), DIVA’s generated distribution, and the unstructured distribution (Eu). Subfigure (c) shows the final episode return curves for DIVA and the baselines, demonstrating DIVA’s superior performance. Lastly, subfigure (d) illustrates the number of unique genotypes used by each method.
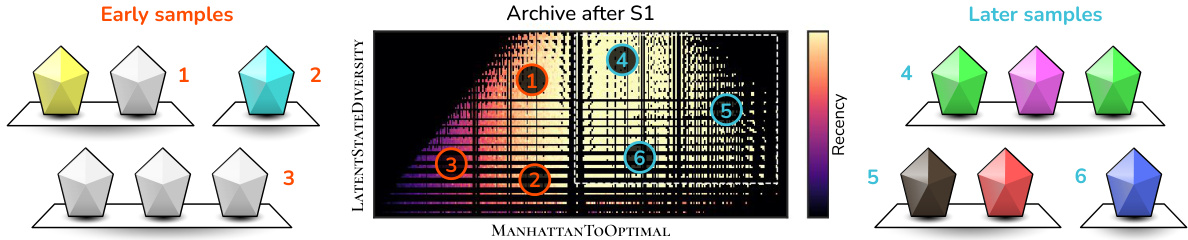
This figure shows how DIVA improves the diversity of ALCHEMY levels over time. The left panel displays the initial levels generated, which lack diversity in their latent stone states (all stones are close to (1,1,1)). The center panel shows the archive after the first stage of DIVA’s QD updates. The right panel shows levels sampled later in the process, demonstrating that DIVA successfully increased the diversity of latent stone states.
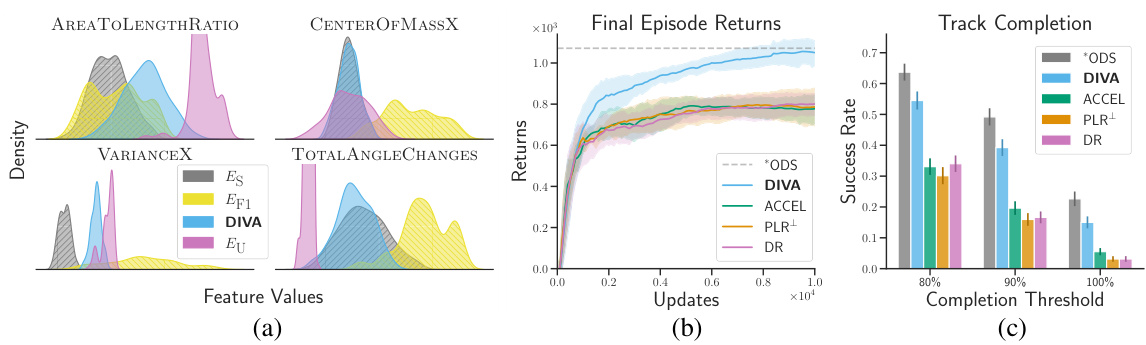
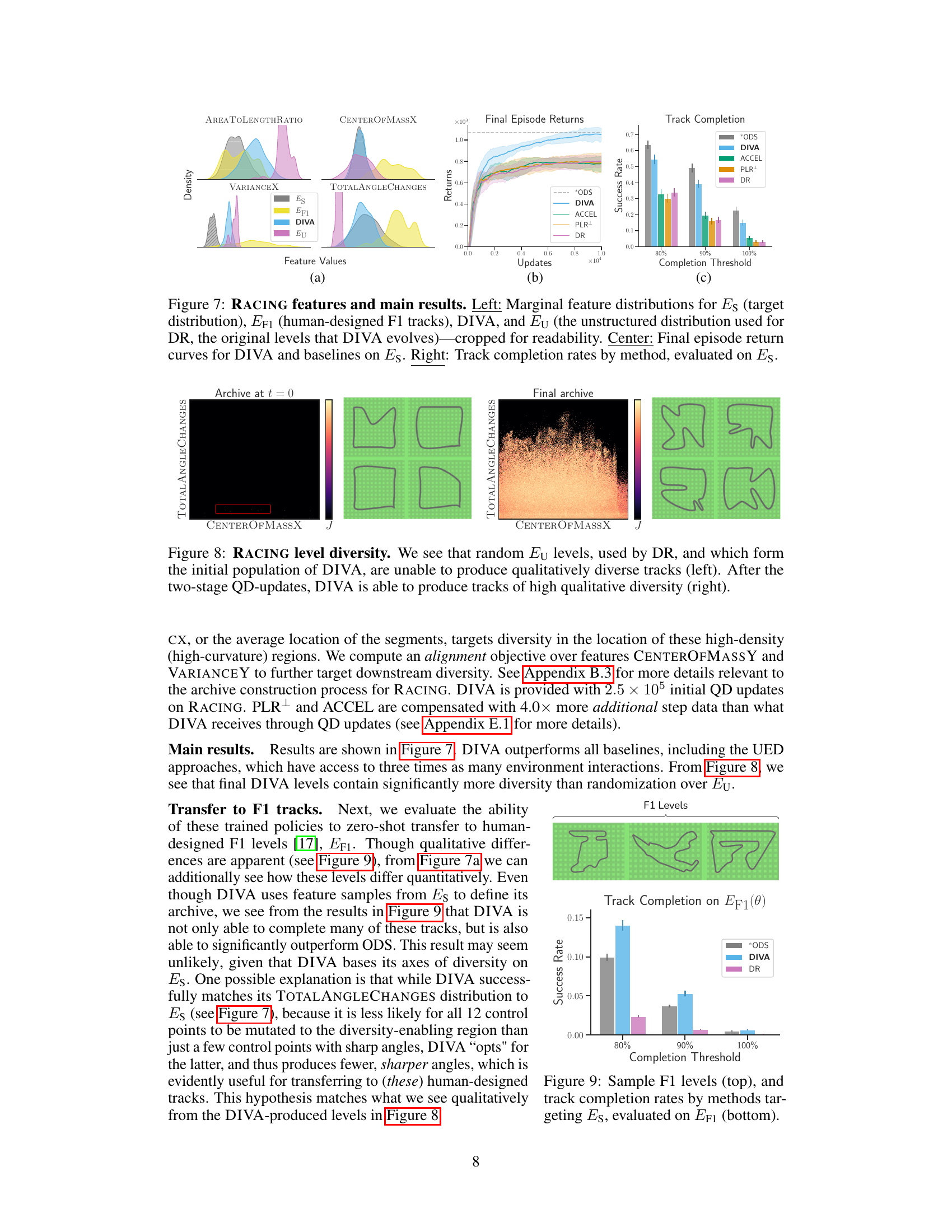
This figure displays the results of the RACING experiment. The left panel shows the marginal distributions of four features (AREATOLENGTHRATIO, CENTEROFMASSX, VARIANCEX, TOTALANGLECHANGES) for four different conditions: Es (target distribution), EF1 (human-designed tracks), DIVA, and Eu (unstructured distribution used by DR). The center panel shows the final episode return curves for DIVA and the baselines over training updates on the target distribution Es. The right panel shows the track completion rates for each method, evaluated on Es.
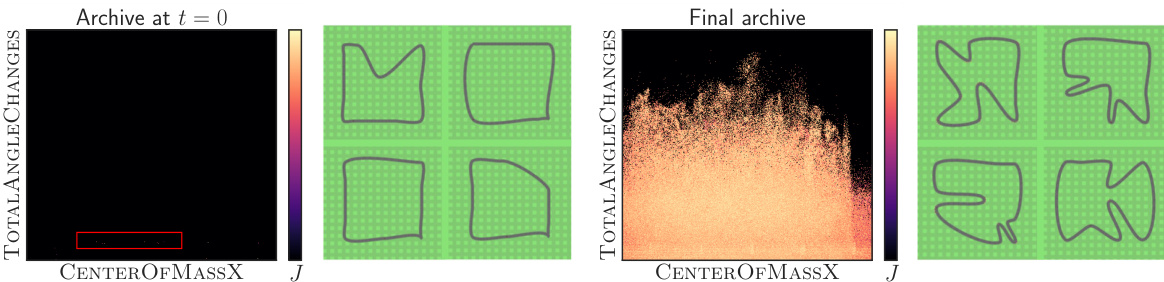
This figure shows the impact of DIVA’s two-stage QD update process on the diversity of generated racing tracks. The left side displays tracks generated using random parameters (Eu), demonstrating limited diversity and mostly uninteresting track shapes. The right side shows tracks generated after DIVA’s QD updates, showcasing a significant increase in the variety and complexity of track layouts.
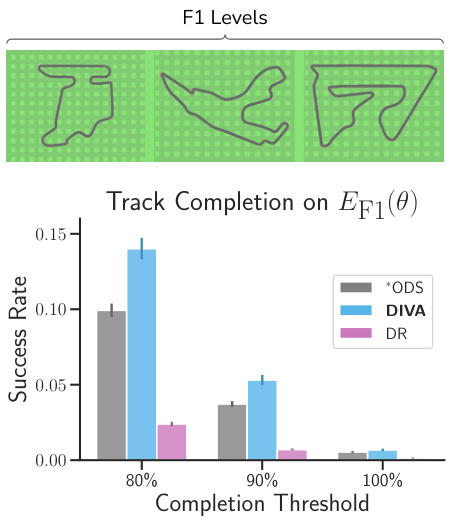
This figure shows the transfer learning results of the trained agents on human-designed F1 tracks (EF1). The top panel displays example tracks from EF1. The bottom panel presents a bar chart illustrating the success rate (track completion rate) for each method (*ODS, DIVA, and DR) across various completion thresholds (80%, 90%, and 100%). The results indicate that DIVA, although trained on a different track distribution (ES), exhibits considerable zero-shot generalization capabilities on EF1, outperforming the other baselines.

This figure compares the performance of DIVA and DIVA+ on the RACING task, using two different archive configurations: one misspecified and one well-specified. DIVA+ incorporates an additional level selection mechanism (PLR+), which is used to further refine the set of training levels from DIVA’s output. The figure shows that for the misspecified archive, DIVA+ achieves significantly improved performance. However, for the well-specified archive, DIVA+ does not show significant gains over DIVA alone, suggesting that the supplemental level selection may be most beneficial when the initial level selection is suboptimal.
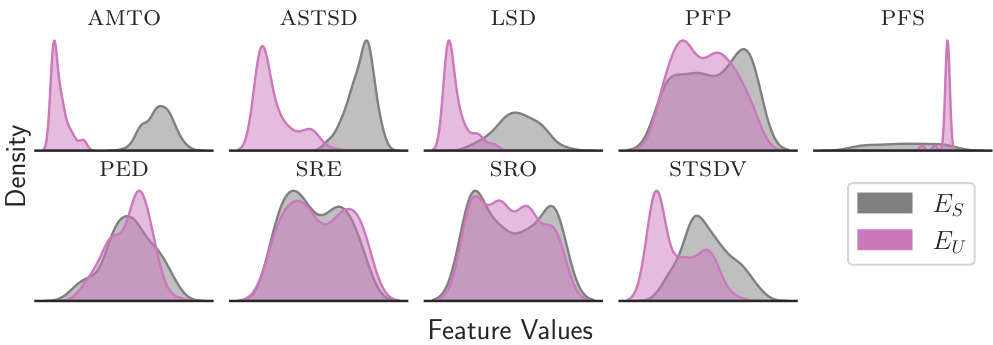
This figure shows the distributions of all features used in the ALCHEMY environment. It compares the distributions obtained from the structured environment parameterization (Es) with those from the unstructured parameterization (Eu). The comparison highlights the differences in diversity of the feature space captured by the two parameterizations. This is important because the objective is to use DIVA to improve the diversity of training tasks by exploring Eu in a way that targets the desired distribution, Es.

This figure shows the covariance matrices for both the structured (Es) and unstructured (Eu) environment parameterizations in the ALCHEMY domain. Each cell represents the covariance between a pair of features. The color intensity indicates the strength and sign of the correlation, with darker shades of green representing stronger positive correlations and darker shades of orange representing stronger negative correlations. Comparing the two matrices illustrates how the relationships between features differ depending on whether the environment parameters are structured (Es) or unstructured (Eu).

This figure displays the distributions of all features used in the RACING environment. It shows separate distributions for the structured target environment (Es) and the unstructured environment used for domain randomization and initializing DIVA’s archive (Eu). The distributions reveal differences in the feature values produced by the structured versus the unstructured environment parameterizations, highlighting the challenge of generating diverse and representative training levels in open-ended environments.

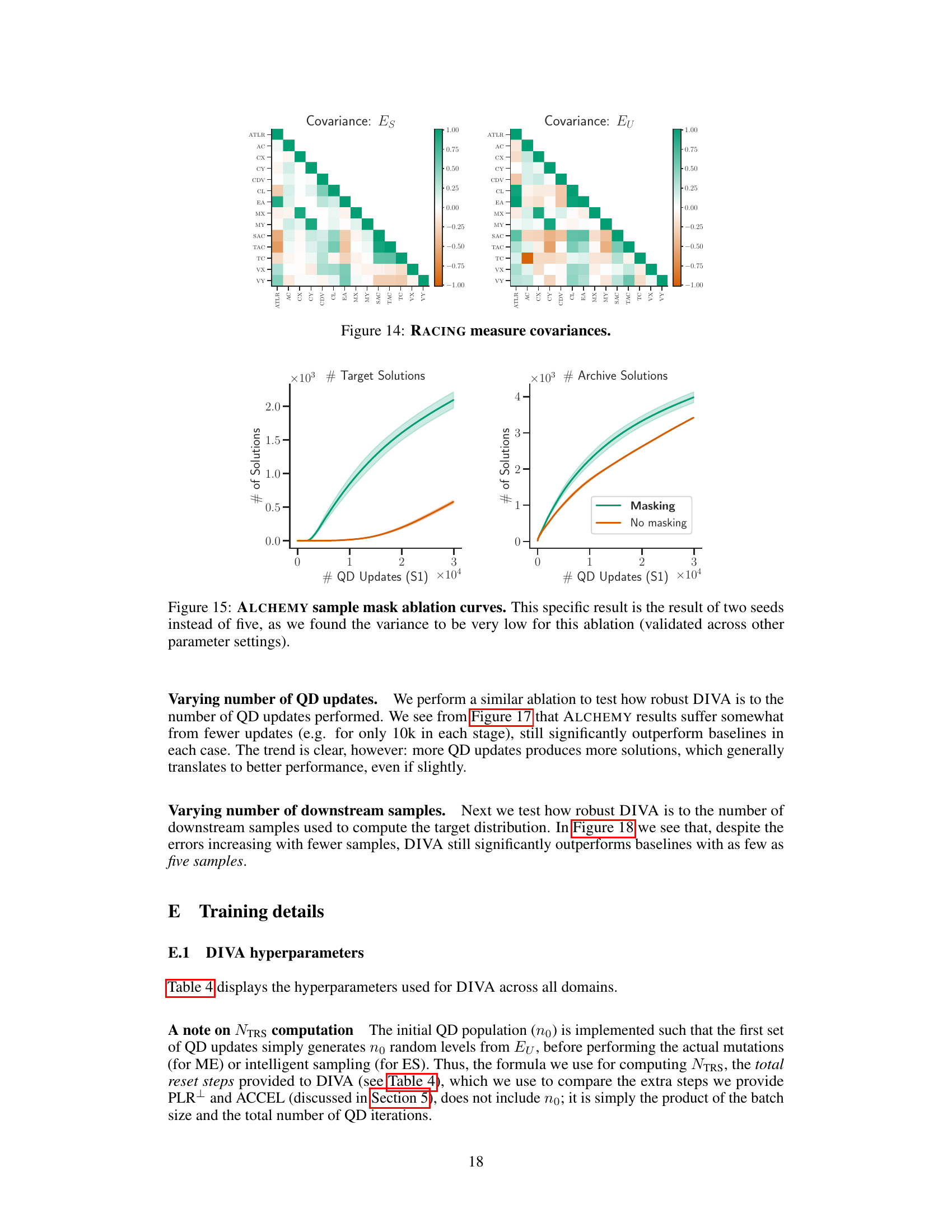
This figure displays the covariance matrices for the RACING features under the structured (Es) and unstructured (Eu) parameterizations. The heatmaps visualize the correlation between pairs of features. Strong positive correlations are shown in dark green, while strong negative correlations are in dark orange. The color intensity reflects the strength of the correlation, with lighter colors indicating weak correlations. Comparing Es and Eu reveals differences in the relationships between features, suggesting that the unstructured parameterization does not inherently produce the same diverse feature combinations as the structured one.

This figure shows the result of ablating the sample mask used in the first stage of DIVA’s QD optimization on the ALCHEMY environment. Two curves are shown: one with the sample mask and one without. The y-axis represents the number of target solutions (left) and archive solutions (right) found, while the x-axis represents the number of QD updates performed in the first stage. The figure demonstrates that using the sample mask significantly accelerates the discovery of target solutions and overall increases the number of solutions found in the archive.
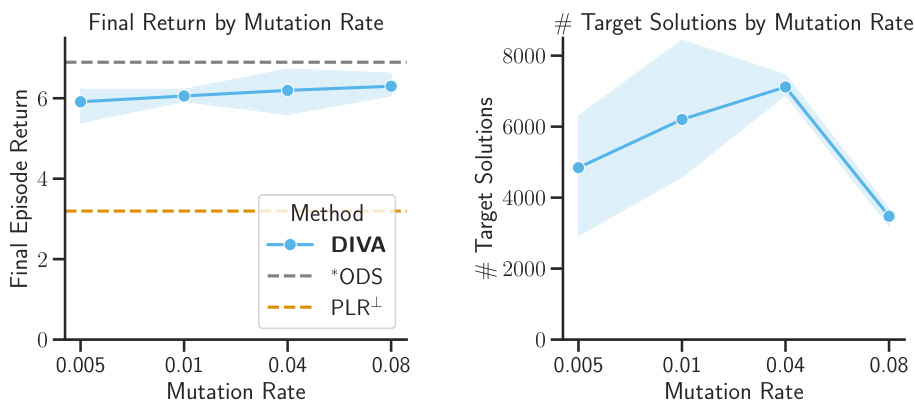
This figure shows the results of an ablation study on the mutation rate used in the quality diversity (QD) optimization algorithm, specifically for the ALCHEMY environment. The left panel displays the final episode returns for different mutation rates, while the right panel shows the number of unique solutions found in the archive for each rate. The results suggest that the performance is relatively insensitive to changes in mutation rate, within a certain range.

This figure analyzes the effect of varying the number of quality diversity (QD) updates on the performance of the DIVA algorithm in the ALCHEMY environment. The left panel shows the final episode returns, while the right panel displays the number of target solutions found in the archive. It demonstrates that increasing the number of QD updates leads to better performance and more diverse solutions.

This figure shows the ablation study on the number of downstream samples used to generate the target distribution in ALCHEMY. The left plot shows the final episode returns for DIVA, ODS (oracle), and PLR+ baselines as a function of the number of samples. The center and right plots show the mean absolute error (MAE) and variance MAE for the features ‘AVERAGE MANHATTAN TO OPTIMAL’ and ‘LATENT STATE DIVERSITY’, respectively, as a function of the number of samples. The results indicate that DIVA is robust to the number of samples, even with as few as 5 samples.
More on tables

This table lists all the hyperparameters used by the DIVA algorithm across all three experimental domains (GRIDNAV, ALCHEMY, RACING). It includes hyperparameters for both stages of the QD process (S1 and S2), parameters controlling the meta-RL training (VariBAD), and settings specific to the chosen QD algorithm (MAP-Elites or CMA-ES) in each domain. Understanding these settings is crucial for reproducing the experiments detailed in the paper.

This table lists two features used in the GRIDNAV environment: XPOSITION (XP), representing the x-coordinate of the goal, and YPOSITION (YP), representing the y-coordinate of the goal.

This table lists and describes the features used in the ALCHEMY environment. Each feature provides a different aspect of the complexity or diversity of the chemical reactions simulated in the environment, relevant to the overall training task. Understanding these features is crucial to interpreting the results of the DIVA algorithm and the comparative analysis with baselines.
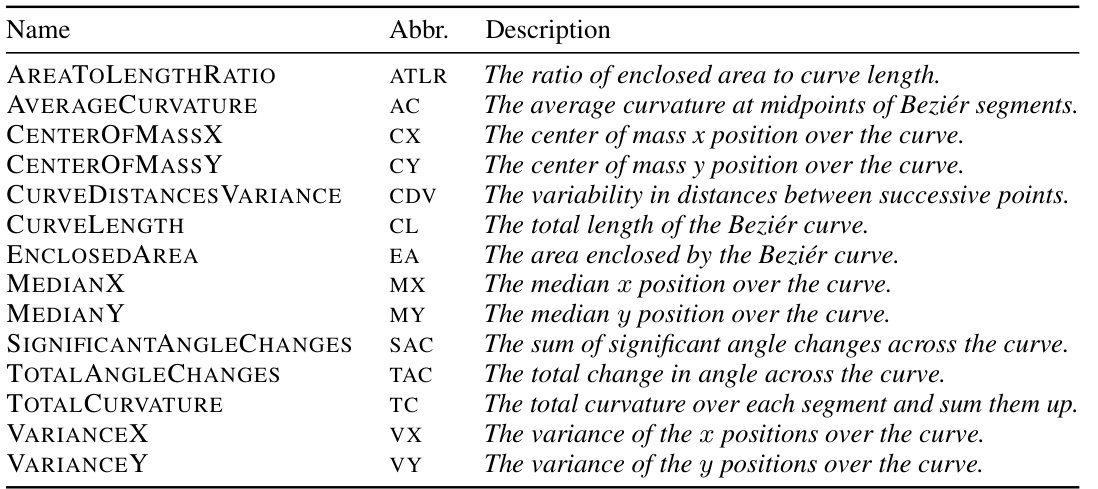
This table lists all features used in the RACING environment. Each feature provides a different perspective on the characteristics of the racetrack, capturing aspects such as the shape’s complexity, size, and curvature. These features are used by DIVA to generate diverse training tracks, and they are carefully chosen to represent the key characteristics that distinguish challenging and interesting racetracks from simpler ones.
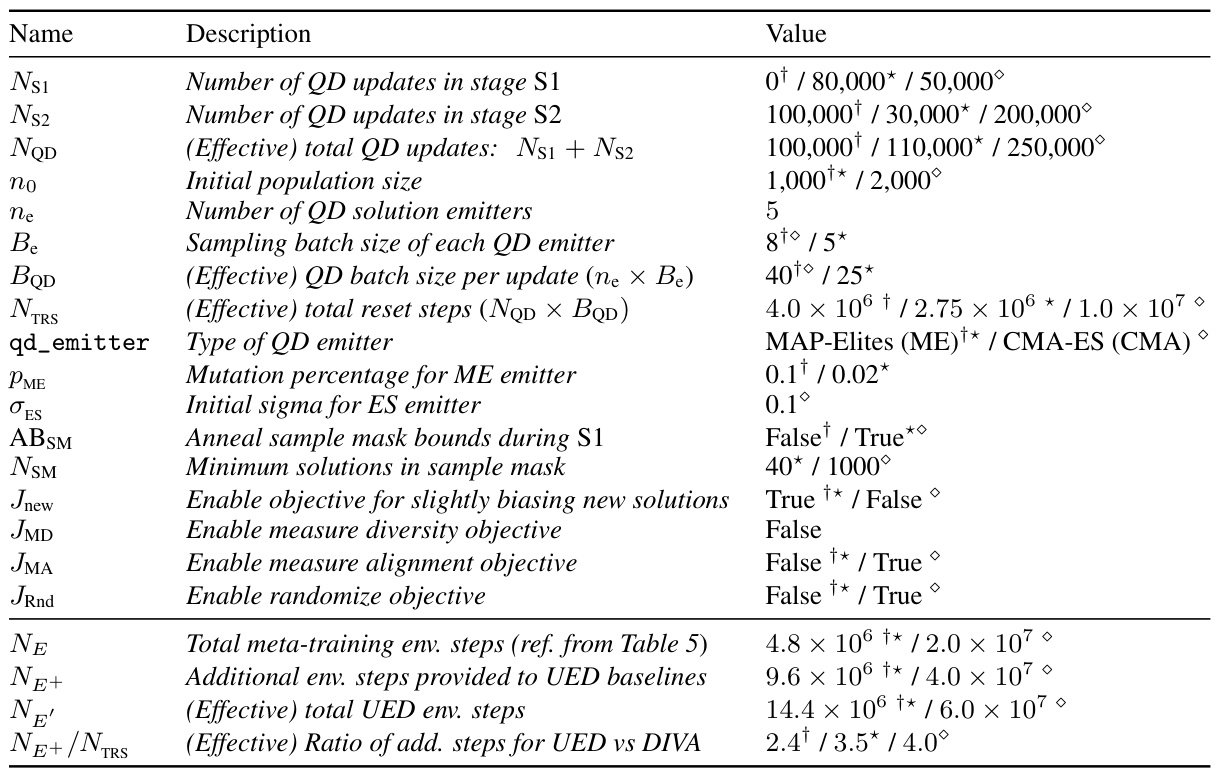
This table shows the hyperparameters used in the DIVA algorithm across different environments (GRIDNAV, ALCHEMY, RACING). It details settings for both stages of the quality diversity (QD) optimization process (Ns1, Ns2), the overall number of QD updates, population size, emitter parameters (mutation rates, initial sigma), and objective functions used. It also includes the number of meta-training steps and a comparison of additional steps provided to baselines. Note that the values vary across the different domains indicated by the superscripts.

This table shows the hyperparameters used for the VariBAD algorithm across all the domains in the experiments. It includes parameters related to the policy network, value function, the variational autoencoder (VAE), and the Proximal Policy Optimization (PPO) algorithm. The table specifies settings for learning rates, optimization methods, network architectures, regularization techniques, and other key parameters. Each parameter is clearly defined and its corresponding value listed.
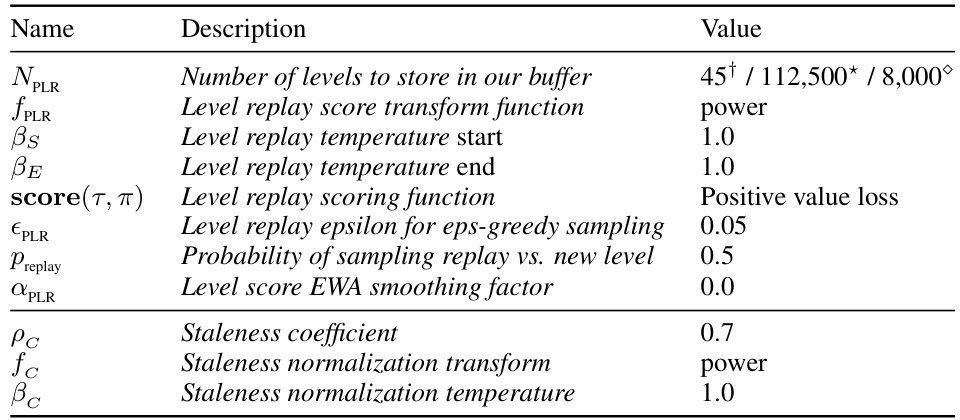
This table lists the hyperparameters used for the Robust PLR (PLR+) baseline in the RACING, ALCHEMY, and GRIDNAV experiments. The hyperparameters control aspects of the level replay mechanism, such as the number of levels stored in the buffer (NPLR), the replay scoring function (score(τ,π)), and the exploration-exploitation trade-off through temperature parameters (βs, βE, and βc). The table also includes parameters related to staleness (ρc, fc, and βc).
Full paper#