↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Multi-view clustering aims to leverage information from multiple data sources for improved performance. However, existing deep multi-view clustering (DMVC) methods often lack a principled way to balance the contributions of different views, leading to suboptimal results. Some views may dominate the fusion process, hindering the contribution of others.
This paper tackles this issue by proposing Shapley-based Cooperation Enhancing Multi-view Clustering (SCE-MVC). SCE-MVC models DMVC as a cooperative game, using the Shapley value to quantify each view’s contribution. It then dynamically adjusts the training process to balance view contributions, ultimately leading to significantly improved clustering accuracy and robustness.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in multi-view clustering because it introduces a novel framework for evaluating and enhancing view cooperation, a critical aspect often overlooked in existing methods. The Shapley value-based approach provides a theoretical justification for balancing view contributions, leading to improved clustering performance and opening avenues for future research in cooperative game theory applications to machine learning.
Visual Insights#

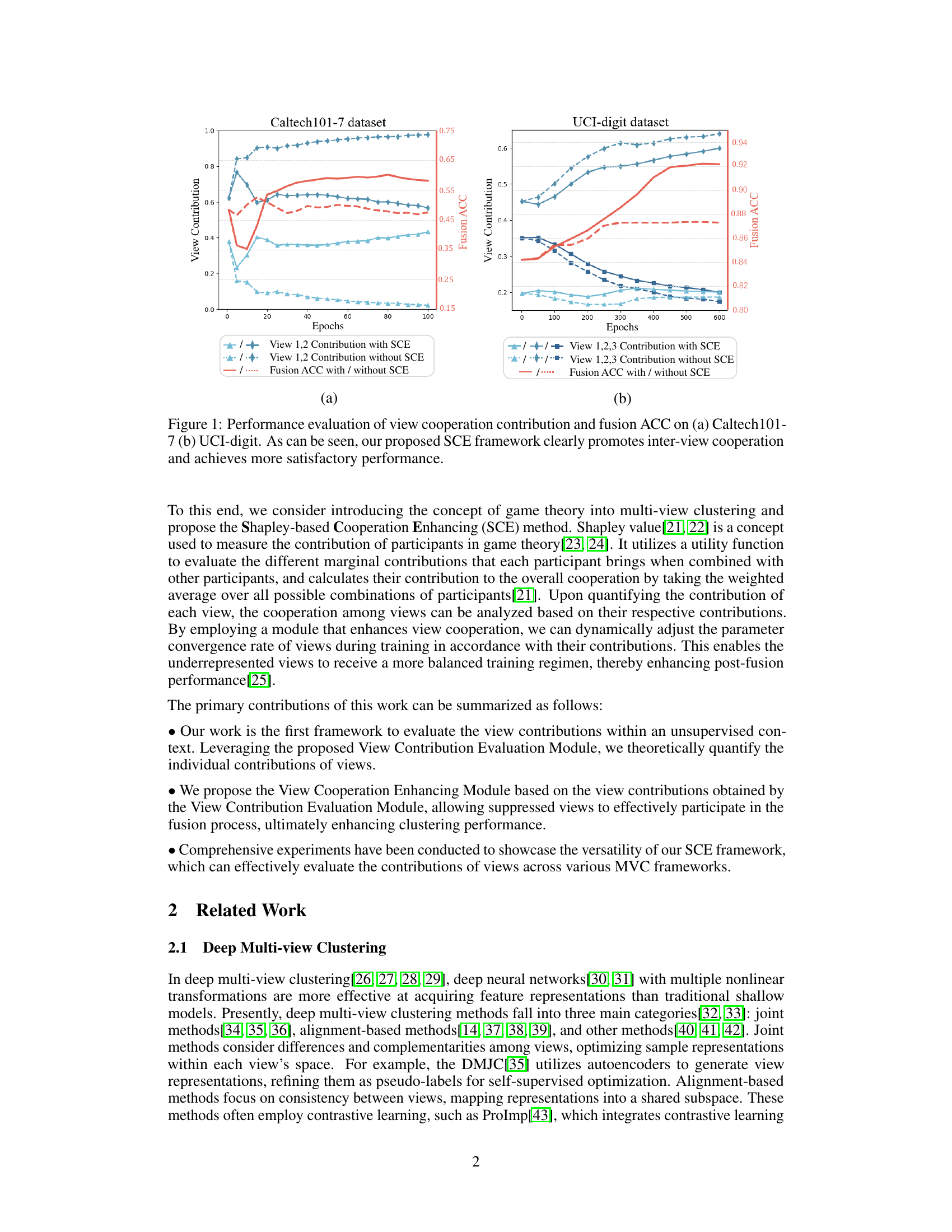
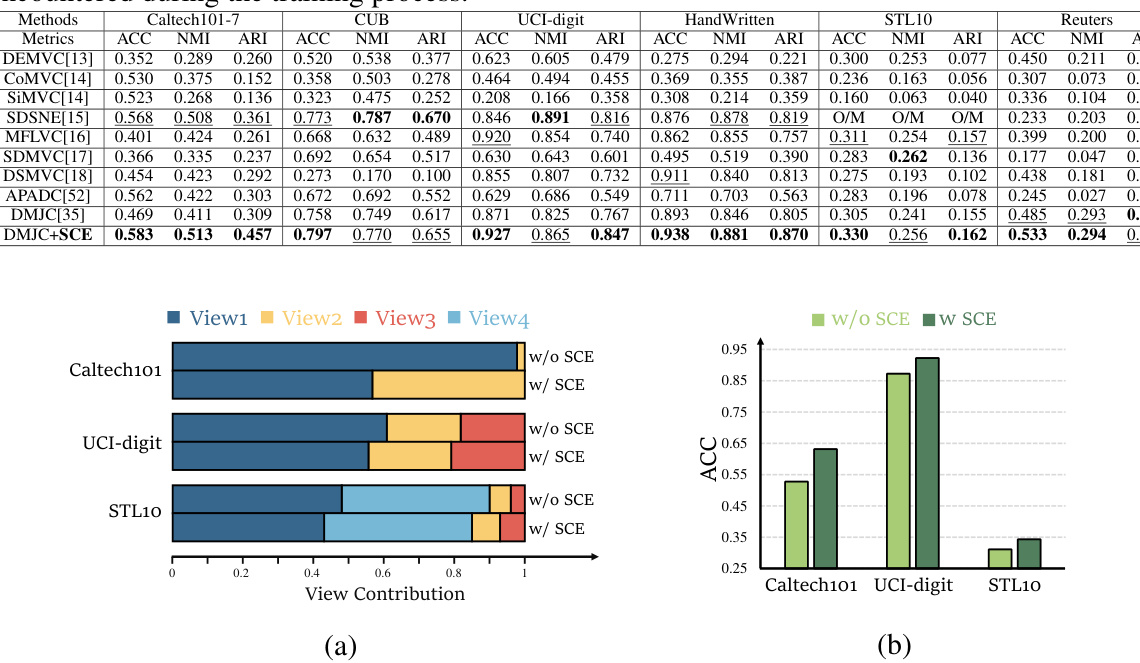
This figure shows the performance of the proposed Shapley-based Cooperation Enhancing Multi-view Clustering (SCE-MVC) framework compared to a baseline method without SCE. Subfigure (a) displays results for the Caltech101-7 dataset, illustrating the contributions of two views and the fusion accuracy (ACC) over training epochs. Subfigure (b) presents similar results for the UCI-digit dataset, but with three views. The plots demonstrate that SCE-MVC enhances view cooperation, leading to higher fusion ACC compared to the baseline.

This table summarizes the six multi-view datasets used in the paper’s experiments. For each dataset, it lists the number of views, the number of samples, and the number of clusters.
In-depth insights#
Shapley Values in MVC#
The application of Shapley values to multi-view clustering (MVC) offers a novel approach to evaluating the contribution of individual views within the fusion process. By framing MVC as a cooperative game, each view is treated as a player, and its marginal contribution to the overall clustering performance is quantified using Shapley values. This approach goes beyond simpler weighting schemes by considering all possible combinations of views and their impact. The use of an optimal transport distance metric to calculate the utility function enables a principled and data-driven assessment of each view’s contribution. The resulting Shapley values provide insights into the relative importance of each view, revealing potential imbalances and facilitating a more balanced view cooperation. This framework is particularly valuable in scenarios where certain views might dominate the fusion, leading to suboptimal results. By using Shapley values, we can identify such dominance and employ techniques to enhance cooperation among views, leading to improved clustering accuracy and robustness. This method offers a theoretical grounding and practical tools for a fairer and more effective multi-view clustering process.
SCE-MVC Framework#
The Shapley-based Cooperation Enhancing Multi-view Clustering (SCE-MVC) framework offers a novel approach to multi-view clustering by leveraging game theory. It addresses the limitations of existing methods by explicitly evaluating the contribution of each view to the overall clustering performance. This evaluation is achieved using the Shapley value, a concept from cooperative game theory that quantifies the marginal contribution of each player (view, in this case) to the coalition. The Shapley value calculation utilizes the optimal transport distance between fused cluster distributions and single-view components as its utility function. This provides a principled and robust way to assess the contribution of each view, regardless of the specific clustering algorithm employed. SCE-MVC subsequently employs a view cooperation enhancing module to dynamically adjust the convergence rates of different views, promoting cooperation and ensuring that underrepresented views are not suppressed. This leads to a more balanced and effective fusion of views, resulting in improved clustering accuracy. The framework’s flexibility allows it to be applied to various existing deep multi-view clustering models, enhancing their performance through more effective view cooperation. Overall, SCE-MVC represents a significant advance in multi-view clustering by offering a theoretical foundation for view contribution assessment and a practical mechanism for enhancing inter-view cooperation.
View Contribution Eval#
The heading ‘View Contribution Eval’ suggests a crucial step in a multi-view learning framework, focusing on quantifying the individual contribution of each view to the overall model performance. This involves developing a method to objectively measure how much each view enhances the final results. A key challenge lies in the unsupervised nature of multi-view clustering, where there are no ground truth labels to guide the evaluation. The paper likely proposes a novel technique to address this challenge, potentially employing game-theoretic concepts like the Shapley value or developing a custom metric based on the similarity or distance between cluster distributions derived from individual and fused views. Optimal transport, a powerful tool for measuring distances between probability distributions, might play a significant role. The framework would analyze the marginal contribution of each view, shedding light on the significance of each data source, allowing for more informed fusion strategies or view selection. Successfully quantifying view contributions leads to improved performance through balanced representation of different views and optimized data fusion, which is a significant contribution in itself. Ultimately, this evaluation provides a more insightful understanding of the multi-view learning process, moving beyond simple weight assignments and facilitating more effective model design and interpretation.
Cooperation Enhancement#
The concept of ‘Cooperation Enhancement’ in multi-view clustering centers on improving the synergy between different data views to achieve superior clustering results. Insufficient cooperation among views is a significant limitation; some views may dominate, hindering others’ contributions. To address this, the proposed framework introduces a game-theoretic approach, utilizing Shapley values to quantify each view’s contribution to the overall clustering outcome. This is a crucial step, as it moves beyond simple weighting schemes and provides a more nuanced understanding of inter-view dynamics. The Shapley values then inform a cooperation enhancing module, dynamically adjusting the training process to balance the influence of each view and encourage more comprehensive collaboration. This method ensures that less influential views are not suppressed, promoting a fairer distribution of influence and leading to improved overall clustering performance. The efficacy of this method is empirically demonstrated, showcasing its value in bridging the gap between individual view contributions and superior multi-view fusion.
Future Work#
Future research directions stemming from this Shapley value-based multi-view clustering framework could involve addressing the issue of negative Shapley values, which contradict the non-negativity assumption. Investigating why these negative values arise and how to handle them, perhaps by excluding views with consistently negative contributions or modifying the Shapley value calculation method, would enhance the robustness and reliability of the framework. Furthermore, the current approach uses a relatively simple method for view cooperation enhancement; exploring more sophisticated techniques to dynamically control the contribution relationship between views, beyond proportional gradient modulation, is important. Finally, expanding the framework to other multi-view learning tasks such as classification and regression, and rigorously testing its generalization performance across a wider range of datasets and model architectures, is warranted to solidify its practical value.
More visual insights#
More on figures
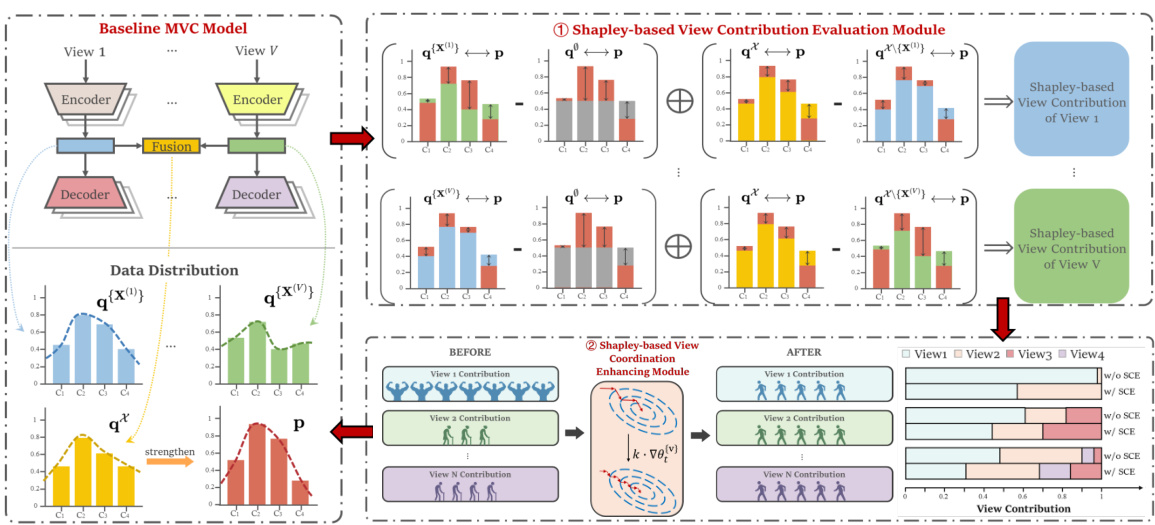
This figure illustrates the proposed Shapley-based Cooperation Enhancing Multi-view Clustering (SCE-MVC) framework. It shows how SCE-MVC integrates with existing DMVC methods, using two key modules: a View Contribution Evaluation Module and a View Cooperation Enhancing Module. The former computes Shapley values to quantify the contribution of each view, using optimal transport distance as a utility function. The latter dynamically adjusts the convergence rate of each view based on its Shapley value, promoting balanced cooperation and improved clustering performance. The figure uses both diagrammatic and graphical representations to depict data distributions before and after SCE-MVC processing and illustrates the impact on view contributions.
This figure displays the performance of view cooperation contribution and fusion accuracy (ACC) on two datasets, Caltech101-7 and UCI-digit. Subfigure (a) shows the results for Caltech101-7, while (b) shows the results for UCI-digit. In both subfigures, the red lines represent view contributions without the proposed SCE framework, while the blue lines represent the contributions with SCE. The green lines show the fusion ACC with and without SCE. The figure demonstrates that the SCE framework significantly enhances inter-view cooperation, leading to improved fusion accuracy.
More on tables
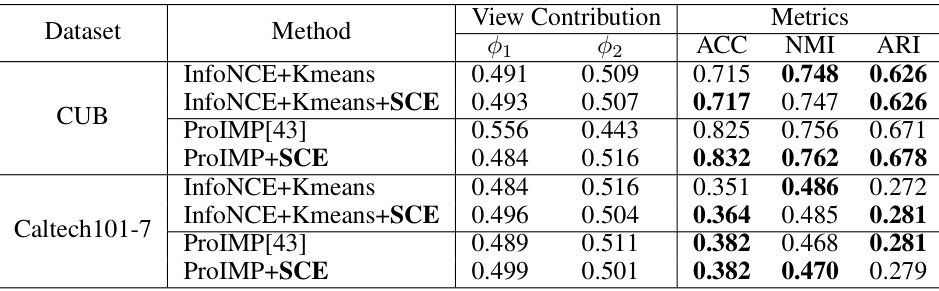
This table presents the results of analyzing view contributions using two different multi-view clustering methods (InfoNCE+Kmeans and ProIMP) on two datasets (CUB and Caltech101-7). It shows the individual contributions of each view (Φ1 and Φ2), as calculated by the Shapley value method, along with the overall clustering performance metrics: Accuracy (ACC), Normalized Mutual Information (NMI), and Adjusted Rand Index (ARI). The purpose is to demonstrate how the Shapley value approach helps evaluate view contributions and to assess the impact of view cooperation enhancement on clustering results.
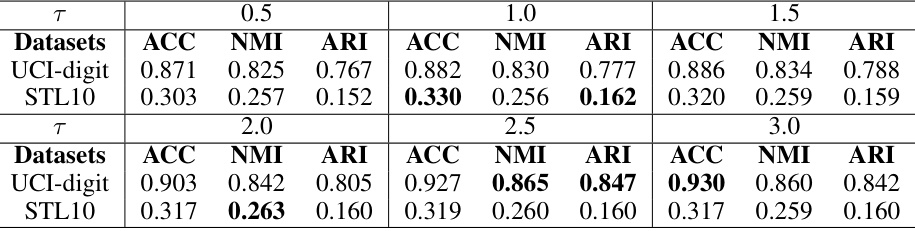
This table presents the results of a sensitivity analysis performed on the UCI-digit and STL10 datasets. The analysis focuses on the impact of the hyperparameter τ on the performance of the proposed SCE-MVC model. The table shows the ACC, NMI, and ARI metrics for different values of τ , allowing for an assessment of the model’s robustness to changes in this parameter. The optimal results for each dataset and metric are highlighted in bold.

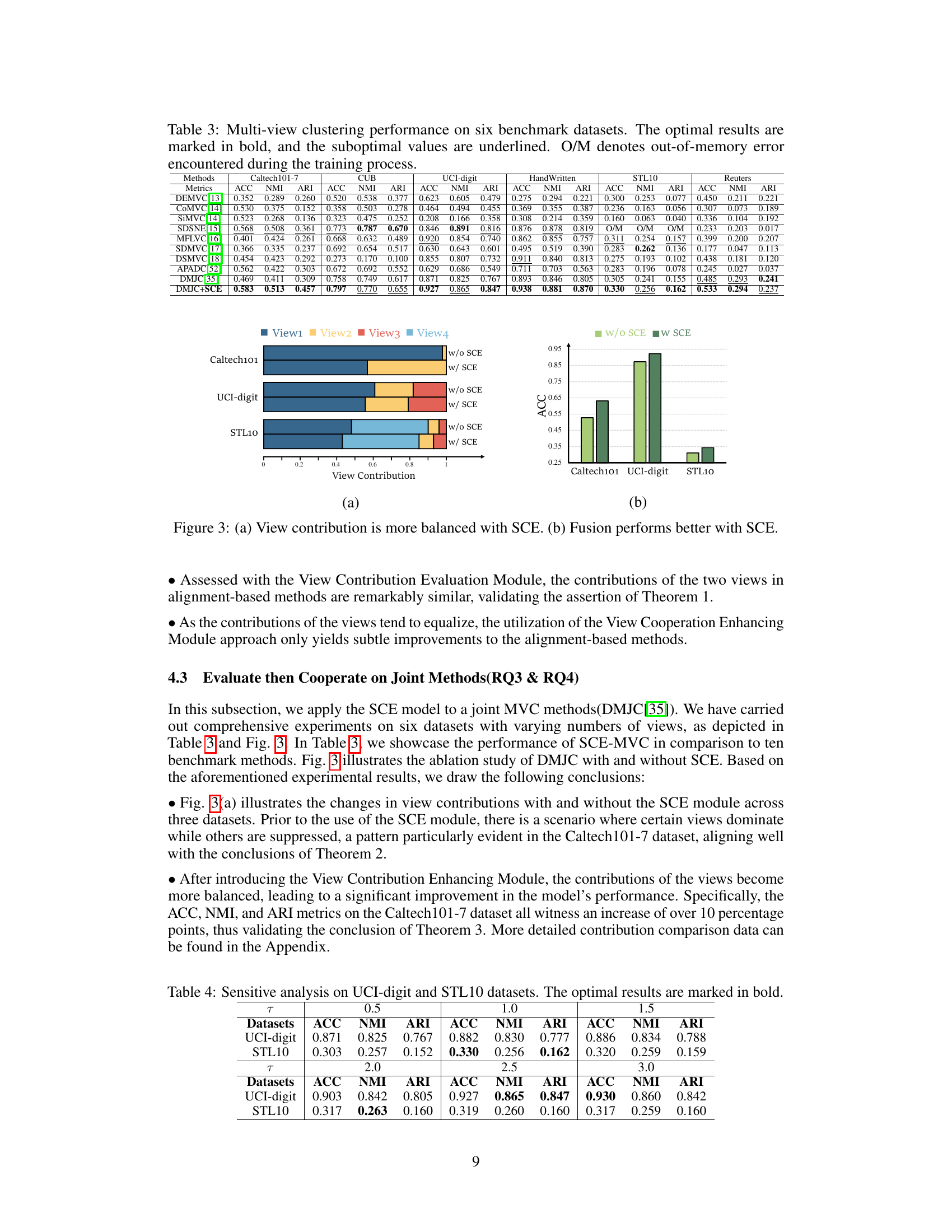
This table presents a comparison of view contributions with and without the Shapley-based Cooperation Enhancing (SCE) module across six different datasets. It highlights the differences in the contribution of each view before and after applying SCE. The results showcase how SCE increases the participation of underrepresented views and leads to a more balanced distribution of view contributions in the fusion process.
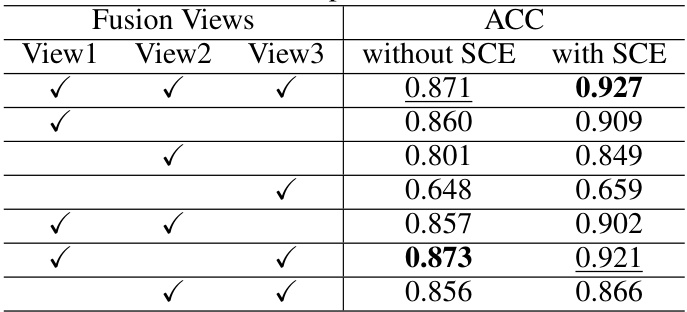
This table presents the results of an experiment using the UCI-digit dataset with three views. The experiment compares the clustering accuracy (ACC) achieved using different combinations of views, both with and without the Shapley-based Cooperation Enhancing (SCE) module. The optimal results (highest ACC values) are highlighted in bold, and suboptimal results are underlined. The table demonstrates the impact of the SCE module on improving the clustering accuracy by better integrating information from multiple views.

This table shows the results of experiments where different combinations of two out of the three views from UCI-digit dataset are used for training. The table demonstrates the impact of using different views in the training process on the final clustering accuracy (ACC). The first row shows that training with all three views yields the highest ACC of 0.873. Removing one of the three views results in slightly lower ACC.
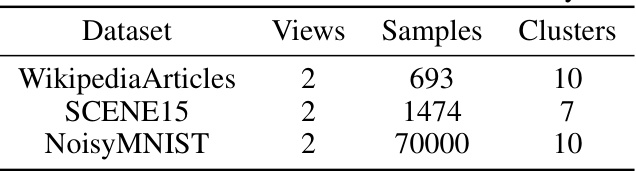
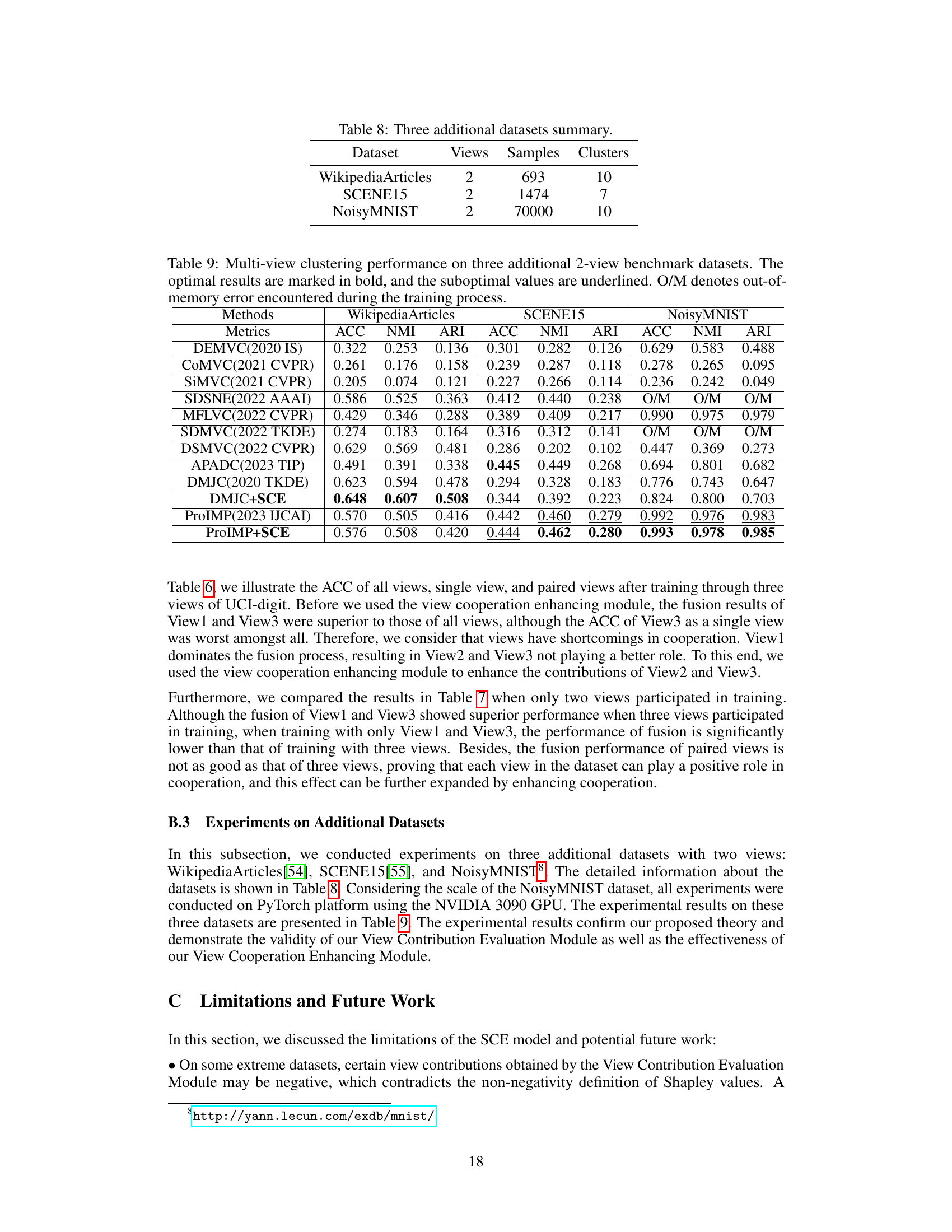
This table presents a summary of three additional datasets used in the experiments. For each dataset, it shows the number of views, the number of samples, and the number of clusters.
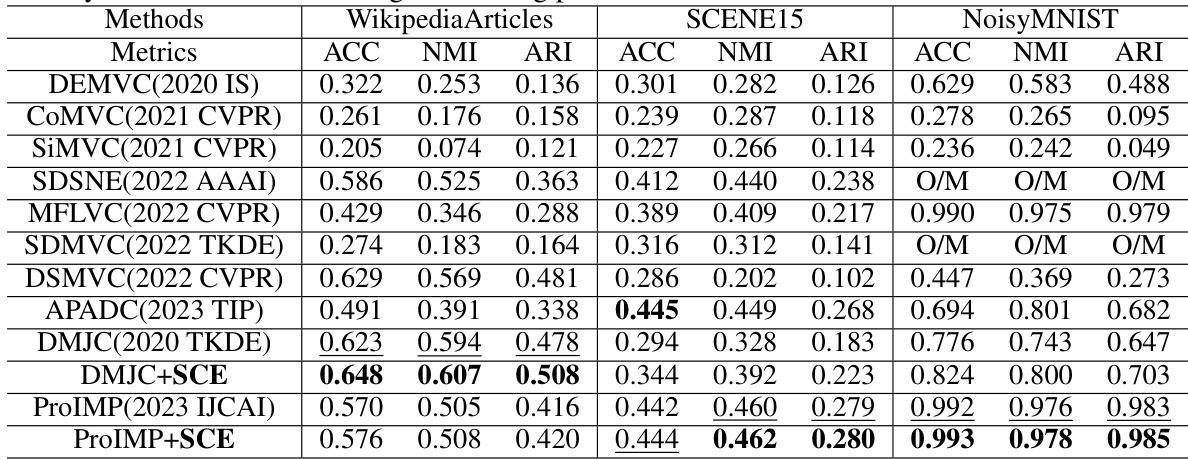
This table presents the performance of various multi-view clustering methods on six benchmark datasets (CUB, Caltech101-7, UCI-digit, HandWritten, STL10, Reuters). The performance is measured using three metrics: ACC (accuracy), NMI (normalized mutual information), and ARI (adjusted Rand index). The best results for each dataset and metric are shown in bold, and the second-best results are underlined. O/M indicates that the method ran out of memory during training.
Full paper#