↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Current visual-language alignment (VLA) models, while effective, often lack clarity and interpretability in their representations. The typical direct latent feature alignment struggles to provide meaningful insights into the alignment process. Existing methods that use lexical representations, while interpretable, are typically difficult to train effectively.
LexVLA tackles these issues by introducing a novel framework that learns a unified lexical representation for both visual and textual modalities using pre-trained models. This approach avoids complex training configurations. It uses an overuse penalty to prevent meaningless words from activating, further enhancing model interpretability. Experiments demonstrate LexVLA outperforms baselines, even with fewer training data, across various cross-modal retrieval benchmarks.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in visual-language alignment due to its novel approach using unified lexical representations, addressing the interpretability limitations of existing methods. It provides a new benchmark for evaluating interpretability and offers a simpler, more effective training method. This work has potential implications for various applications involving cross-modal retrieval and understanding.
Visual Insights#

This figure illustrates LexVLA’s ability to generate lexical representations in three different ways. The first shows a word cloud representing the entire image’s lexical representation. The second shows a word cloud for specific image patches, highlighted in red. The third demonstrates how LexVLA selects the most relevant image patches given a text caption, comparing the selected patches to a ground truth mask.

This table presents the results of zero-shot cross-modal retrieval experiments on two benchmark datasets, MSCOCO and Flickr30k. It compares LexVLA (and its variants) against several baseline methods, categorized as either using latent feature alignment or lexical feature alignment. The table shows recall rates (R@K) at different ranks (K=1, 5, 10) for both image-to-text and text-to-image retrieval tasks, highlighting the performance of LexVLA across different training data sizes. The variants of LexVLA are denoted by Q and compared to the original CLIP, as well as other related methods from published works (VDR and STAIR).
In-depth insights#
Unified Lexical VLA#
The concept of “Unified Lexical VLA” suggests a novel approach to visual-language alignment (VLA) that leverages a unified lexical representation. This contrasts with traditional methods that rely on aligning latent feature spaces, often lacking interpretability. A unified lexical representation would provide a more transparent way to understand the model’s alignment decisions, by explicitly mapping visual and textual elements to words and their semantic relationships. This approach offers the potential for improved interpretability and the ability to pinpoint specific word-level correspondences between the two modalities. However, the challenge lies in effectively learning such a representation, given the absence of direct ground-truth lexical supervision and the high dimensionality of the vocabulary. Successful implementation likely requires overcoming the false-discovery issues that can arise from the complexity of word-meaning mappings. The innovation of a unified representation could simplify architecture and accelerate VLA model training, potentially leading to more efficient and easily interpretable models. Addressing inherent sparsity challenges associated with lexical representations will also be crucial to ensure effective retrieval and other downstream tasks. Ultimately, the success of “Unified Lexical VLA” hinges on its ability to balance the advantages of clear lexical correspondence with the challenges of learning high-dimensional, sparse, and potentially ambiguous representations.
DINOv2 & Llama 2#
The research leverages the strengths of two powerful pre-trained models: DINOv2, a self-supervised visual model known for its local-inclined feature extraction, and Llama 2, a large language model capable of in-context learning. This combination is key to LexVLA’s effectiveness. DINOv2 provides rich localized visual features, avoiding the patch-level limitations of CLIP. Meanwhile, Llama 2’s in-context prediction ability is harnessed for precise lexical prediction, overcoming the issues of noisy and biased text supervision prevalent in other VLA methods. This innovative pairing avoids the complexities of multi-modal training. The models’ pre-trained strengths are combined, resulting in a unified lexical representation that outperforms baselines trained on significantly larger datasets.
Overuse Penalty#
The ‘Overuse Penalty’ in the LexVLA model is a crucial regularization technique designed to address the issue of over-activation of meaningless words in the learned lexical representations. Traditional sparsity-inducing methods like the FLOPs loss, while effective in promoting sparsity, can inadvertently lead to the activation of infrequent or irrelevant tokens, thereby hindering the model’s interpretability and potentially affecting its overall performance. The overuse penalty directly tackles this problem by penalizing frequently activated tokens based on their normalized average activation across the entire vocabulary. This approach effectively discourages the model from relying on easily activated, yet semantically uninformative, words, pushing it instead towards a more meaningful and sparse representation. This mechanism ensures that the learned lexical space reflects true semantic relationships, enhancing the interpretability and reliability of the cross-modal retrieval task. The combination of the overuse penalty with the unified lexical representation framework makes LexVLA a more robust and interpretable VLA model than previous approaches.
PatchDis Metric#
The proposed PatchDis metric addresses a critical gap in evaluating the interpretability of visual features within vision-language alignment (VLA) models. Existing methods often lack a quantitative measure for assessing patch-level understanding, especially in models not trained on fine-grained tasks like segmentation. PatchDis cleverly leverages the model’s learned text embeddings to classify image patches, providing a direct assessment of how well the model associates visual regions with semantic concepts. This approach offers a valuable tool for analyzing the model’s capacity for local-level understanding beyond simple global image-text alignment, thereby providing crucial insights into the model’s interpretability and potential for higher-level visual reasoning. The use of mIoU as the evaluation metric further enhances its practicality and provides a concrete, comparable metric. However, the reliance on a pre-trained text encoder could introduce bias, limiting the generalizability of the metric if the textual codebook isn’t well-suited to the visual features. Future work could explore alternative approaches or incorporate multi-modal feature integration for a potentially more robust evaluation of patch-level interpretability.
Sparsity & Efficiency#
Sparsity and efficiency are crucial considerations in many machine learning models, especially when dealing with high-dimensional data. The goal is to reduce computational cost and memory usage without sacrificing performance. Lexical representations, with their inherent sparsity (using only a subset of vocabulary words), offer this advantage. LexVLA, by design, leverages this sparsity by selecting the most relevant words for text and image encoding; this prevents computational burden, associated with dense vector representations, while retaining key information. The paper further enhances sparsity using techniques like thresholding, and an overuse penalty is introduced to address the issue of model shortcuts, preventing excessive activation of irrelevant and frequently appearing tokens. This intelligent sparsity leads to improved efficiency and interpretability, demonstrating that LexVLA outperforms baselines even with fewer activated features and smaller multi-modal training datasets. The PatchDis metric, focusing on patch-level analysis, supports this finding by showing superior interpretability with significantly less computation. Thus, LexVLA achieves a balance between sparsity, efficiency, and performance by carefully designed methods, effectively addressing critical limitations of prior work in visual-language alignment.
More visual insights#
More on figures
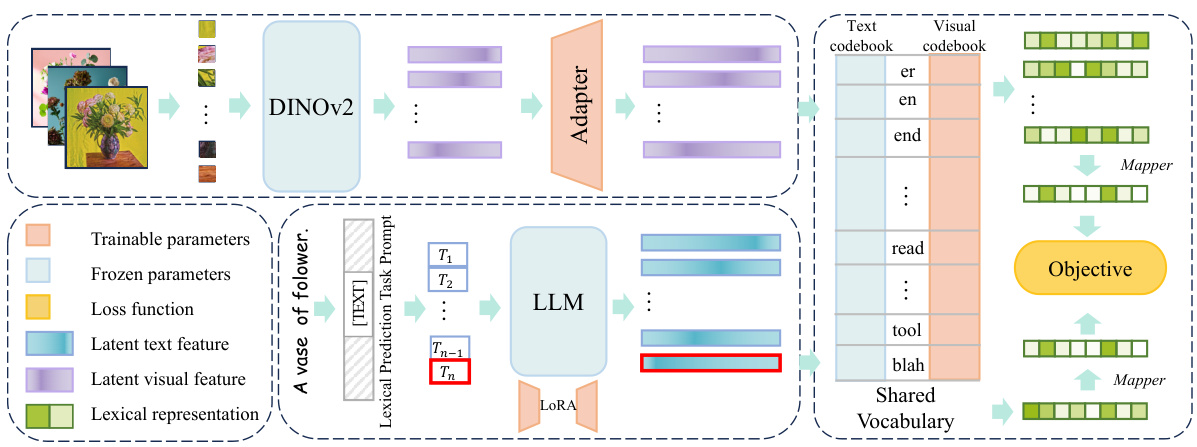
This figure illustrates the architecture of the LexVLA model. It shows how two pre-trained models (DINOv2 for vision and Llama 2 for text) are integrated and fine-tuned. The visual branch uses a frozen DINOv2 backbone with an added adapter and mapper to project into the shared lexical space. The text branch fine-tunes Llama 2 using LoRA, and also employs a mapper. Both branches use distinct codebooks, initialized by Llama 2’s codebook, but the text codebook is frozen during training. The training process involves standard contrastive objectives to align visual and textual lexical representations, along with an overuse penalty to promote sparsity and avoid activating meaningless words.

This figure visualizes the PatchDis metric, which evaluates the patch-level interpretability of the LexVLA model. It shows three example images, each with its ground truth segmentation mask and the mask predicted by the LexVLA model. The results show that LexVLA accurately predicts the locations of various objects, including small objects, demonstrating its effectiveness at patch-level image understanding.

This figure visualizes the image lexical representations generated by LexVLA. The top row shows word clouds representing the complete image, while the bottom row displays word clouds for specific image patches (highlighted in red boxes). The size of each word in the word clouds is proportional to its lexical value, indicating the importance of the corresponding word to the image or patch. Notably, LexVLA achieves this alignment without relying on local supervision.

This figure compares the performance of LexVLA and VDR at various sparsity levels on Flickr30K and MSCOCO datasets. It shows how recall@1, recall@5, and recall@10 change as the average sparsity (quadratic measure) increases. CLIP is included as a baseline representing a dense model. The results demonstrate LexVLA’s robustness to increasing sparsity, maintaining high performance even with a significant reduction in non-zero elements in the lexical representation.

This figure visualizes the lexical representations generated by LexVLA using two different penalty methods: FLOPs loss and the proposed overuse penalty. The comparison highlights how the overuse penalty effectively reduces the activation of irrelevant tokens, improving the quality and interpretability of the lexical representations. The word clouds show the most prominent words activated by each method for different image-caption pairs. The images are shown in the first row, and their corresponding captions are in the second. Green boxes indicate examples of falsely activated tokens that the overuse penalty helps to mitigate.
More on tables
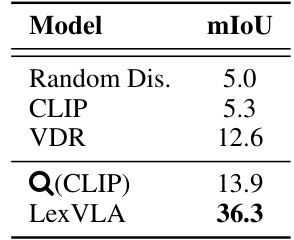
This table presents the results of zero-shot cross-modal retrieval experiments on the MSCOCO and Flickr30k datasets. It compares LexVLA (and its variants) against several baselines, including the original CLIP and other methods focusing on latent or lexical feature alignment. The table shows the recall at ranks 1, 5, and 10 (R@1, R@5, R@10) for both image-to-text and text-to-image retrieval tasks. Different model implementations are categorized based on their training data size (Data) and alignment approach (Latent or Lexical).
This table presents the results of zero-shot cross-modal retrieval experiments on the MSCOCO and Flickr30k datasets. It compares LexVLA (and its variants) against several other state-of-the-art models, showing the recall rate (R@K) at different top-K ranks. The table highlights LexVLA’s performance even when trained on significantly smaller datasets compared to competitors. Different variants of LexVLA are also evaluated and compared against each other.
Full paper#



















