↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current open-vocabulary scene graph generation (OVSGG) methods struggle with high variance in visual relations and fail to adapt to different contexts. They typically rely on fixed text classifiers (prompts) for identifying objects and their relationships in images, leading to suboptimal performance. These prompts are often scene-agnostic, ignoring the specific context of the image.
The SDSGG framework introduced in this paper solves this problem by using large language models (LLMs) to generate scene-specific descriptions that adapt to the context. The weights of the text classifiers are dynamically adjusted based on the visual content, leading to more accurate and diverse descriptions. Furthermore, SDSGG includes a new module called the “mutual visual adapter” which enhances the model’s ability to capture relationships between subjects and objects, boosting accuracy. The extensive experiments demonstrate a significant improvement over existing state-of-the-art methods.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in scene graph generation and open-vocabulary learning. It addresses limitations of existing methods by proposing a novel approach that leverages large language models for generating scene-specific descriptions, improving accuracy and generalizability. This opens new avenues for research in context-aware scene understanding and advances the state-of-the-art in open-vocabulary scene graph generation. The proposed approach is also relevant to the broader trends in vision-language pre-training and prompt engineering.
Visual Insights#

This figure illustrates three different approaches to text classifiers used in open-vocabulary scene graph generation (OVSGG). (a) shows the standard zero-shot approach using CLIP, where the similarity between image and text embeddings is computed for each category, and the highest similarity is selected. (b) expands on (a) by using multiple part-level prompts to better utilize CLIP’s semantic space. (c) presents the proposed SDSGG approach, which uses comprehensive scene-specific descriptions generated by large language models (LLMs), adaptively adjusted based on the image content using a renormalization mechanism.
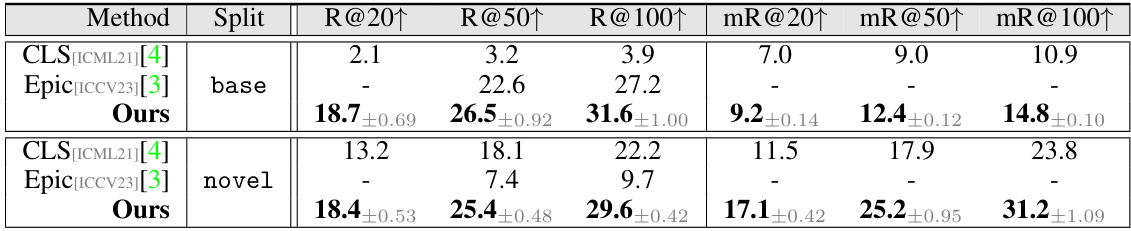
This table presents a quantitative comparison of the proposed SDSGG method against existing state-of-the-art methods (CLS and Epic) on the Visual Genome (VG) dataset. It shows the performance (Recall@K - R@K and mean Recall@K - mR@K) for both base and novel splits of the VG dataset for different recall ranks (R@20, R@50, R@100). The base split contains well-represented relation categories, while the novel split includes categories that were not seen during training, thus assessing the model’s ability to generalize to unseen data. The results demonstrate the superior performance of the SDSGG approach, particularly on the novel split, indicating its strong generalization capabilities.
In-depth insights#
Scene-Specific SGG#
Scene-Specific SGG presents a novel approach to open-vocabulary scene graph generation (OVSGG) by tackling the limitations of existing methods that rely on scene-agnostic text classifiers. The core idea is to leverage Large Language Models (LLMs) to generate scene-specific descriptions (SSDs) that adapt to the visual content of each image. This contrasts with traditional methods that use fixed text classifiers, which struggle to model the variability of visual relations across different contexts. SDSGG employs a multi-persona collaboration strategy with the LLM, prompting it to analyze the scene from various perspectives (e.g., biologist, engineer), thereby enhancing the diversity and comprehensiveness of the generated descriptions. Furthermore, a renormalization mechanism refines the impact of each SSD based on its relevance to the scene, ensuring that only pertinent descriptions contribute to the final prediction. A mutual visual adapter module refines the interaction between subjects and objects, improving relation recognition accuracy. Overall, the approach demonstrates a clear improvement in OVSGG performance by dynamically adapting to the specific nuances of each scene.
LLM Role-Playing#
LLM role-playing is a novel technique that leverages the capabilities of large language models (LLMs) to generate diverse and comprehensive scene descriptions for scene graph generation. By assigning different roles (e.g., biologist, physicist, engineer) to the LLM, the method encourages the model to analyze the scene from multiple perspectives, enriching the descriptive features captured. This multi-faceted approach addresses limitations of previous methods that relied on fixed, scene-agnostic text classifiers, which often fail to capture the nuanced visual relations present in diverse scenes. The role-playing strategy fosters a richer understanding of the scene, improving the model’s capacity to generate context-rich, scene-specific descriptions. The generated descriptions are not treated equally, but rather their relevance to the scene is dynamically assessed through a renormalization mechanism. This adaptive weighting ensures that only the most relevant descriptions contribute to the final scene graph generation, enhancing accuracy and robustness. In essence, LLM role-playing introduces a level of context-awareness and adaptability missing in standard zero-shot approaches, significantly improving the overall performance of open-vocabulary scene graph generation.
Mutual Visual Adapter#
The heading “Mutual Visual Adapter” suggests a novel mechanism designed to enhance the capabilities of existing vision-language models, specifically in the context of scene graph generation. The core idea likely revolves around improving the model’s understanding of the complex interplay between subjects and objects within a scene. Instead of treating subject and object features independently, the mutual visual adapter likely processes them jointly, allowing the model to capture nuanced relationships and contextual information that might otherwise be missed. This could involve mechanisms such as cross-attention or other interaction-aware modules. The “mutual” aspect emphasizes the bidirectional nature of this interaction, implying the adapter captures how the subject influences the object and vice-versa, resulting in a richer representation of the scene. This approach is particularly relevant to open-vocabulary scene graph generation, where the model needs to deal with a wide variety of relationships that are not pre-defined.
OVSGG Limitations#
Open-Vocabulary Scene Graph Generation (OVSGG) methods, while showing promise, face significant limitations. Scene-agnostic text classifiers, often based on category names or generic part descriptions, fail to capture the rich contextual nuances of visual relations. This leads to a lack of adaptability to diverse scenes and hinders accurate relation prediction, especially when dealing with complex, ambiguous scenarios. The reliance on pre-trained vision-language models, while convenient, limits the ability to incorporate specific knowledge relevant to particular scenes or domains. Furthermore, the standard zero-shot pipeline used in many OVSGG methods tends to oversimplify the intricate interplay between visual features and relations, resulting in suboptimal performance. Addressing these shortcomings requires innovative approaches that incorporate scene-specific context, potentially through adaptive classifier learning or incorporating external knowledge sources. Advanced techniques for modeling the complex interactions within scenes are crucial to enhance the accuracy and robustness of OVSGG.
Future Directions#
Future research directions stemming from this work could explore several key areas. Improving the scene-specific description generation is paramount; refining the multi-persona collaboration strategy or incorporating alternative methods for generating more comprehensive and diverse descriptions would significantly improve performance. Enhancing the mutual visual adapter is also crucial, perhaps through more sophisticated interaction modeling techniques or by leveraging larger visual models for richer feature representation. Investigating the effects of different prompt engineering techniques and experimenting with various LLM sizes and architectures are also important avenues. Additionally, future studies should focus on applying the proposed framework to diverse applications, such as robotics, autonomous vehicles, and virtual/augmented reality. Finally, thorough investigation into the biases present in the generated descriptions and methods for mitigating these biases is necessary to ensure responsible development and deployment of the technology.
More visual insights#
More on figures
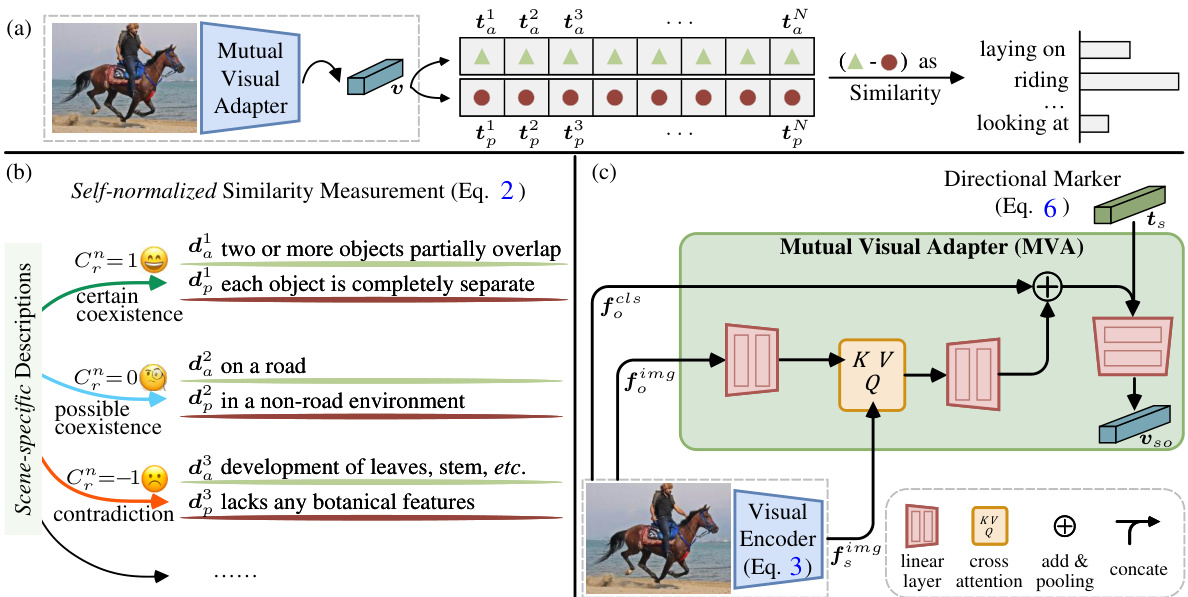
This figure shows the architecture of the proposed SDSGG model. (a) illustrates the overall framework, highlighting the interaction between the mutual visual adapter, scene-specific descriptions, and the similarity calculation. (b) details the self-normalized similarity measurement process, showcasing how raw and opposite descriptions are used to adjust the importance of text classifiers based on context. (c) zooms in on the mutual visual adapter, explaining how it leverages visual features from CLIP’s visual encoder to capture the interplay between subject and object.

This figure shows qualitative comparison results of SDSGG against CLIP on the Visual Genome dataset. The left panel shows an image of an elephant and a tire, where SDSGG more accurately predicts the relationship between them as ‘hanging from’ compared to CLIP. The right panel shows an image of a man and a child playing tennis, where SDSGG correctly predicts the relationship as ‘holding’ while CLIP assigns a lower confidence to this.

This figure illustrates three different approaches to text classifiers used in open-vocabulary scene graph generation (OVSGG). (a) shows the standard zero-shot pipeline using CLIP, where similarity between image and text embeddings determines the classification. (b) enhances this by using multiple part-level prompts to utilize CLIP’s semantic space. (c) introduces SDSGG’s approach: using scene-specific descriptions generated by LLMs, whose weights are adjusted adaptively based on visual content.

This figure provides a detailed overview of the SDSGG architecture. Panel (a) shows the overall framework, highlighting the interaction between visual and textual components. Panel (b) illustrates the method for calculating self-normalized similarities using raw and opposite descriptions. Panel (c) details the mutual visual adapter (MVA) module, showing how it uses visual features to model interactions between subjects and objects.
More on tables

This table presents the quantitative results of the proposed SDSGG model and its comparison with other state-of-the-art methods on the Visual Genome (VG) dataset’s semantic split. The semantic split uses a subset of 24 predicate categories with richer semantics compared to the base and novel splits. The metrics used are Recall@K (R@K) at different K values (20, 50, 100) and mean Recall@K (mR@K) at the same K values. Higher values indicate better performance.

This table presents the quantitative results of the proposed SDSGG model and baseline models (CLS [4], Epic [3]) on the GQA dataset. The results are broken down by base and novel splits, showing the Recall@K (R@K) and mean Recall@K (mR@K) metrics for K values of 20, 50, and 100. This allows for a comparison of performance on both seen and unseen relation categories.

This table presents the ablation study results on the impact of multi-persona collaboration (MPC) for scene-specific description generation. It compares the performance of the proposed SDSGG model with and without MPC on both the base and novel splits of the VG dataset. The results show a significant performance drop when MPC is removed, highlighting the importance of this method for improving the model’s capability to generate comprehensive and diverse descriptions.
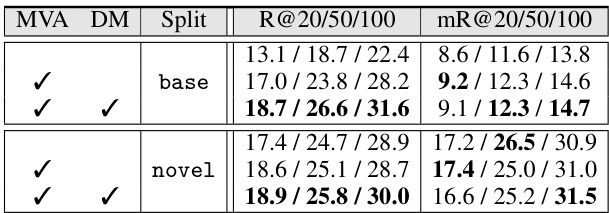
This table presents the ablation study results focusing on the visual part of the proposed model, SDSGG. It shows the performance (Recall@K and mean Recall@K) of the model with different configurations: with/without Mutual Visual Adapter (MVA), and with/without Directional Marker (DM). The results are broken down by base and novel splits to analyze performance differences across different datasets.

This table presents the ablation study on the effectiveness of self-normalized similarity. It compares the performance of the proposed method (Ours) with a baseline that does not use self-normalized similarity (w/o SNS). The results demonstrate the importance of self-normalized similarity for improving the performance, especially on the novel split.

This table presents the ablation study results on the number of scene-specific descriptions (SSDs) used as text classifiers in the SDSGG model. It shows the performance (Recall@K and mean Recall@K) on both the base and novel splits of the Visual Genome dataset for different numbers of SSDs (11, 16, 21, and 26 pairs). The results demonstrate an optimal number of SSDs exists, and excessively many SSDs can negatively impact the performance.
This table presents a quantitative comparison of the proposed SDSGG model with existing Open-Vocabulary Scene Graph Generation (OVSGG) methods on the Visual Genome (VG) dataset. It shows the performance (Recall@K, mR@K) of the different models across two splits of the dataset: ‘base’ (training set) and ’novel’ (testing set), with the evaluation metrics calculated at different thresholds (R@20, R@50, R@100, mR@20, mR@50, mR@100). The results demonstrate the superior performance of SDSGG compared to the baseline (CLS) and a state-of-the-art method (Epic).

This table presents the ablation study results on the number of attention heads (H) used in the mutual visual adapter. It shows how the performance (measured by R@K and mR@K) varies with different numbers of attention heads (4, 8, and 16) on both the base and novel splits. The number of parameters also increases as H increases. The table helps determine the optimal number of attention heads to balance performance and computational cost.

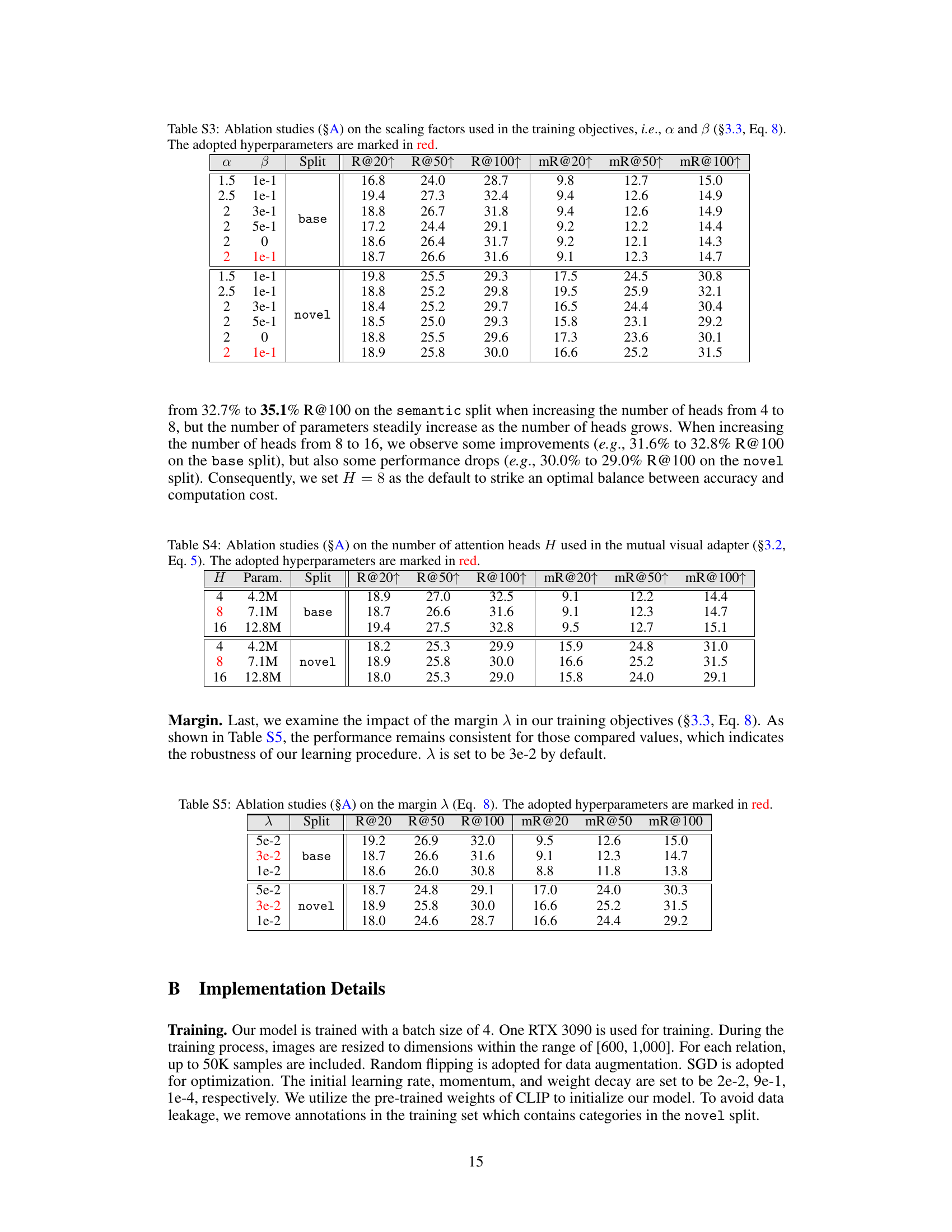
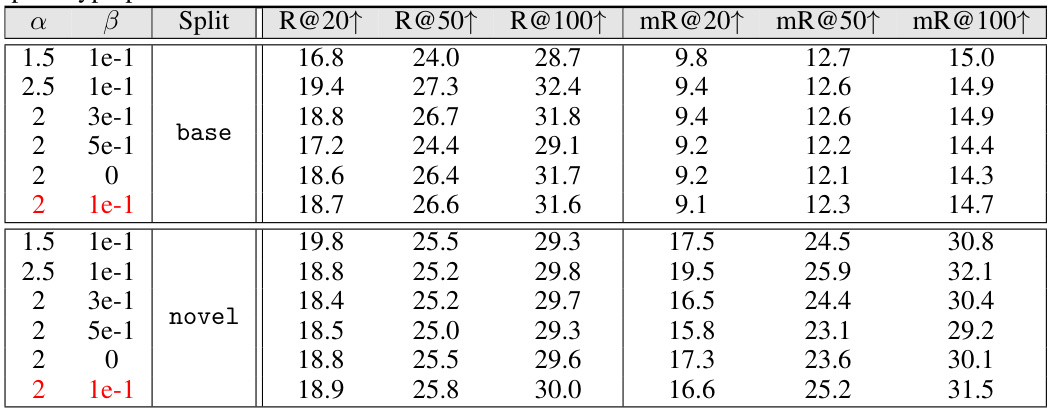
This ablation study investigates the impact of the scaling factors α and β used in the training objective (Equation 8) on the model’s performance. The table shows the Recall@K (R@K) and mean Recall@K (mR@K) metrics for different values of α and β on both the base and novel splits of the dataset. The best performing hyperparameter combination (α=2, β=1e-1) is highlighted in red.
This table presents the quantitative results of the proposed SDSGG method and its comparison with baseline methods (CLS and Epic) on the Visual Genome (VG) dataset. The results are broken down by two splits: base and novel, and measure performance using Recall@K (R@K) and mean Recall@K (mR@K) at different K values (20, 50, 100). This provides a comprehensive evaluation of the method’s performance on both seen and unseen relation categories.

This table presents the quantitative results of the proposed SDSGG model and two baseline models (CLS and Epic) on the Visual Genome (VG) dataset. The results are broken down by two splits: base and novel. The metrics used are Recall@K (R@K), which measures the percentage of correctly predicted relations among the top K predictions, and mean Recall@K (mR@K), which averages the recall across all relation categories. The table shows that SDSGG significantly outperforms the baseline methods on both splits.

This table presents the quantitative results of the proposed SDSGG model and baseline methods on the Visual Genome (VG) dataset [14]. The results are broken down by base and novel splits, indicating the performance on previously seen and unseen relation categories, respectively. Metrics include Recall@K (R@K) and mean Recall@K (mR@K) at different K values (20, 50, 100), assessing the accuracy of relation prediction.

This table presents the results of the proposed SDSGG model when trained on the full set of relations in the Visual Genome dataset. It shows the mean Recall@50 and mean Recall@100, which are metrics used to evaluate the performance of scene graph generation models. The table provides a comparison to other methods, demonstrating the model’s performance on this more comprehensive benchmark.
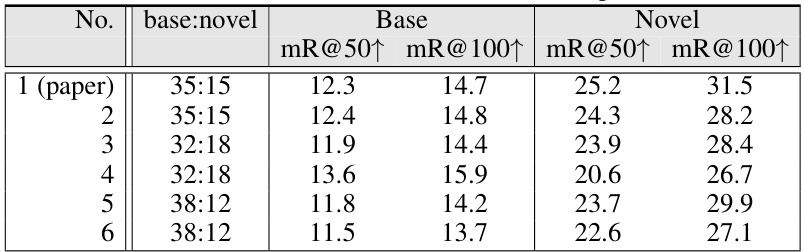
This table presents the results of experiments conducted using different base/novel splits in the training data. It shows the robustness of the SDSGG model to variations in the train/test split composition and category selection. The columns show the Recall@50 and Recall@100 metrics (mR@50↑ and mR@100↑), for both the Base (training) and Novel (testing) splits. Six different train/test splits are shown, labeled No.1 through 6. No.1 corresponds to the split used in the main paper.

This table presents a quantitative comparison of the proposed SDSGG model against existing state-of-the-art methods on the Visual Genome (VG) dataset. The results are broken down by two splits: base and novel. The metrics used for evaluation include Recall@20 (R@20), Recall@50 (R@50), Recall@100 (R@100), mean Recall@20 (mR@20), mean Recall@50 (mR@50), and mean Recall@100 (mR@100). The table shows that SDSGG outperforms the other methods across all metrics and on both splits, indicating improved performance in open-vocabulary scene graph generation.
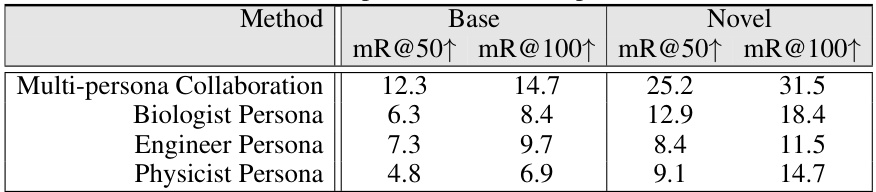
This table presents the results of an ablation study comparing the performance of the SDSGG model using different personas (biologist, engineer, physicist) in the multi-persona collaboration process against the performance using all three personas together. The mR@50 and mR@100 metrics are shown for both the base and novel splits of the dataset, illustrating the impact of the persona choice on the model’s accuracy in relation prediction.
Full paper#