↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Generalist Multimodal Large Language Models (MLLMs) often underperform compared to specialist models due to task interference, which arises from the diverse nature of vision-language (VL) tasks. This paper introduces MoME (Mixture of Multimodal Experts) to tackle this problem. Existing approaches primarily focus on text-based interference, ignoring the equally crucial visual aspects.
MoME cleverly tackles task interference through two key components: MoVE (Mixture of Vision Experts) adaptively aggregates features from different vision encoders and MoLE (Mixture of Language Experts) incorporates sparsely gated experts into LLMs. Extensive experiments demonstrate MoME significantly enhances the performance of generalist MLLMs across various VL tasks, showcasing its effectiveness in handling task differences in both vision and language modalities. The adaptive routing mechanisms ensures that MoME dynamically selects the most appropriate experts based on task requirements, highlighting its adaptability and robustness.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses the critical issue of task interference in multimodal large language models (MLLMs), a significant challenge hindering the development of truly generalist models. The proposed MoME architecture offers a novel solution by incorporating a mixture of vision and language experts, leading to improved performance across various vision-language tasks. This work will directly benefit researchers seeking to enhance the generalizability and performance of MLLMs, paving the way for more robust and versatile multimodal AI systems.
Visual Insights#
This figure shows a comparison between specialist and generalist multimodal large language models (MLLMs) on various vision-language (VL) tasks. Panel (a) demonstrates the performance gap, illustrating that generalist models trained on a mixed dataset significantly underperform compared to specialist models trained on individual task groups. Panels (b) and (c) provide visual representations of the sentence semantics and image embeddings, respectively, highlighting the substantial differences in feature distributions across the different task groups. These variations underscore the challenges in training effective generalist MLLMs due to task interference.
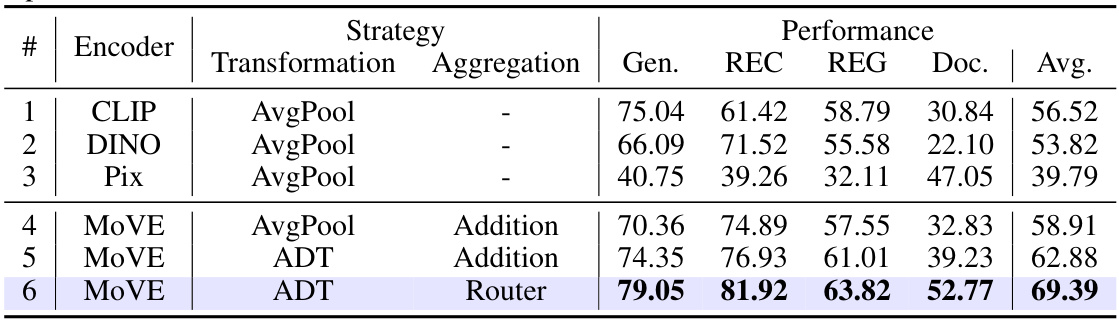
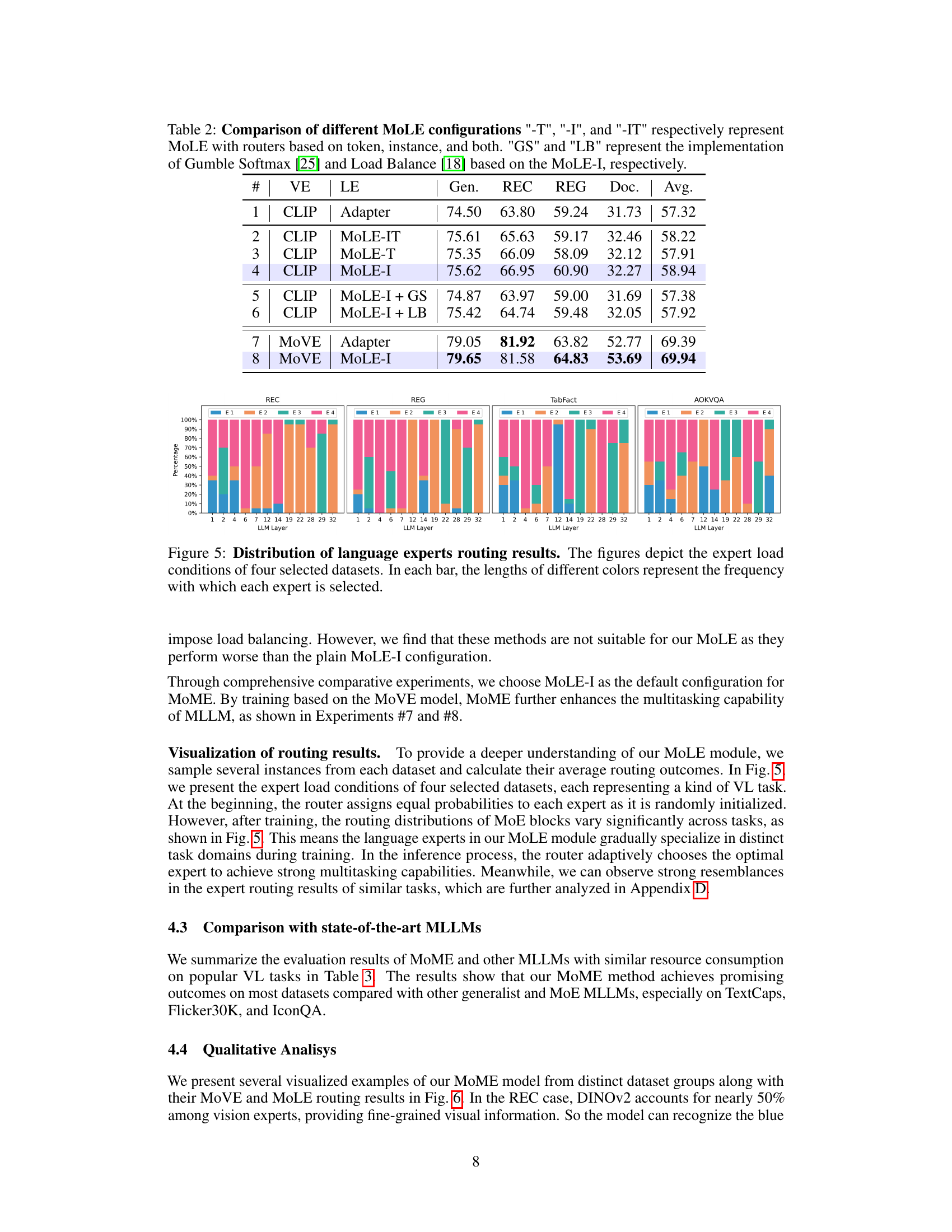
This table presents the results of an ablation study comparing different strategies for the Mixture of Vision Experts (MoVE) component of the MoME model. It shows how different choices for the vision encoder, transformation method (Average Pooling, Adaptive Deformable Transformation (ADT)), and aggregation method (Addition, Router) affect the model’s performance across four groups of vision-language tasks. The ‘Gen.’ column represents the average performance across all tasks, while ‘Doc.’ specifically shows the performance on document understanding tasks. The ‘Avg’ column shows the average performance across all four task groups. The best performing combination is highlighted in bold.
In-depth insights#
Multimodal Expert Mix#
A multimodal expert mix model in a research paper signifies a system designed to leverage the strengths of diverse specialized models for improved performance on complex tasks. The core idea revolves around combining multiple “expert” models, each trained to excel in a specific modality (e.g., vision, language, audio) or sub-task. This approach aims to overcome the limitations of a single, general-purpose model, which often underperforms compared to specialized models in specific domains. By carefully selecting and combining the outputs of these experts, the multimodal expert mix model can achieve a synergistic effect, resulting in enhanced accuracy, robustness, and generalization capabilities. A key aspect is the mechanism used for combining expert outputs; techniques like weighted averaging, gating mechanisms (such as those found in Mixture of Experts architectures), or more sophisticated attention mechanisms might be employed depending on the specific application. The design and implementation of such a system require careful consideration of factors including expert model selection, the method of output fusion, computational cost, and the overall architecture to ensure effective integration and prevent performance bottlenecks. The success of a multimodal expert mix model heavily relies on the quality and diversity of the component expert models and the sophistication of the fusion strategy. A well-designed system promises improved performance across diverse tasks and the ability to handle complex situations that require nuanced understanding across multiple modalities.
Adaptive Deform Trans#
The heading ‘Adaptive Deform Trans,’ likely refers to a method using adaptive deformable transformations. This technique likely addresses the challenge of handling inconsistent visual representations from diverse vision encoders in multimodal large language models (MLLMs). The core idea is to create a unified feature representation regardless of the input vision encoder’s architecture or training method. This is crucial because different encoders might produce features with varying lengths, dimensions, or distributions, leading to incompatibility and suboptimal performance. The ‘adaptive’ aspect suggests that the transformation dynamically adjusts based on the input, perhaps leveraging attention mechanisms or other learning techniques to selectively transform specific feature regions. This approach contrasts with simple methods like padding or concatenation, which can result in information loss or misalignment. The method’s effectiveness likely hinges on its ability to preserve important visual features and reduce noise while ensuring compatibility across encoders. Success would mean improved generalizability for MLLMs across various vision-language tasks and better handling of task interference, resulting in more robust multimodal understanding.
Task Interference#
Task interference, a crucial challenge in multi-task learning, arises when training a single model to perform multiple tasks simultaneously. This leads to performance degradation, as the model struggles to effectively learn distinct task-specific representations due to conflicting information. In multimodal large language models (MLLMs), task interference is particularly problematic because multiple modalities (e.g., text and images) and various tasks contribute to the complexity. This interference can manifest in the model’s feature representations where task boundaries become blurred, hindering accurate prediction. Strategies to mitigate task interference often involve specialized model architectures like Mixture of Experts (MoE), which enable the model to selectively activate task-specific modules, thus reducing interference. Adaptive routing mechanisms also show promise by dynamically allocating resources based on the input data’s characteristics, tailoring the model’s behavior for optimal performance on each task. However, addressing task interference effectively requires a deeper understanding of the relationships between tasks and modalities, which are still open research areas. Future research should explore more advanced techniques to resolve task interference in MLLMs to further improve performance and generalization capabilities.
Generalist MLLM#
The concept of a “Generalist MLLM” in the context of multimodal large language models (MLLMs) is intriguing. A generalist model, unlike a specialist one, aims for strong performance across a broad range of vision-language tasks. This presents a significant challenge, as specialization often leads to superior performance on individual tasks due to factors such as reduced task interference and efficient resource allocation. The paper explores this challenge by proposing a mixture of multimodal experts to create a generalist MLLM that leverages the strengths of specialized models. The approach is particularly novel because it tackles task interference not just at the language level (common in prior work), but also adaptively integrates diverse visual encoders through a sophisticated feature transformation and routing mechanism. This dual focus on vision and language expertise is crucial, as the authors demonstrate that different vision-language tasks exhibit significantly different feature distributions in both modalities. This ultimately enables the generalist MLLM to dynamically select and combine the most relevant experts for each task, achieving a balance between generalizability and specialized efficiency. The research highlights the importance of considering both visual and textual factors when designing generalist MLLMs and suggests that a mixture-of-experts approach offers a promising path towards addressing the inherent limitations of a single, monolithic model.
Future Directions#
Future research could explore several promising avenues. Improving the efficiency and scalability of MoME is crucial, potentially through more sophisticated routing mechanisms or the development of novel, more efficient expert architectures. Addressing the limitations of current vision encoders remains a key challenge; research into more robust and generalizable encoders could significantly enhance MoME’s capabilities. Another area of investigation is exploring the integration of additional modalities, beyond vision and language, to create truly comprehensive multimodal models capable of handling a broader range of complex tasks. Finally, a deeper theoretical understanding of task interference and its mitigation within multimodal learning is needed, guiding the development of more effective and principled methods for building generalist multimodal models. These advancements would pave the way for more effective and robust generalist multimodal large language models with wide-ranging applications.
More visual insights#
More on figures
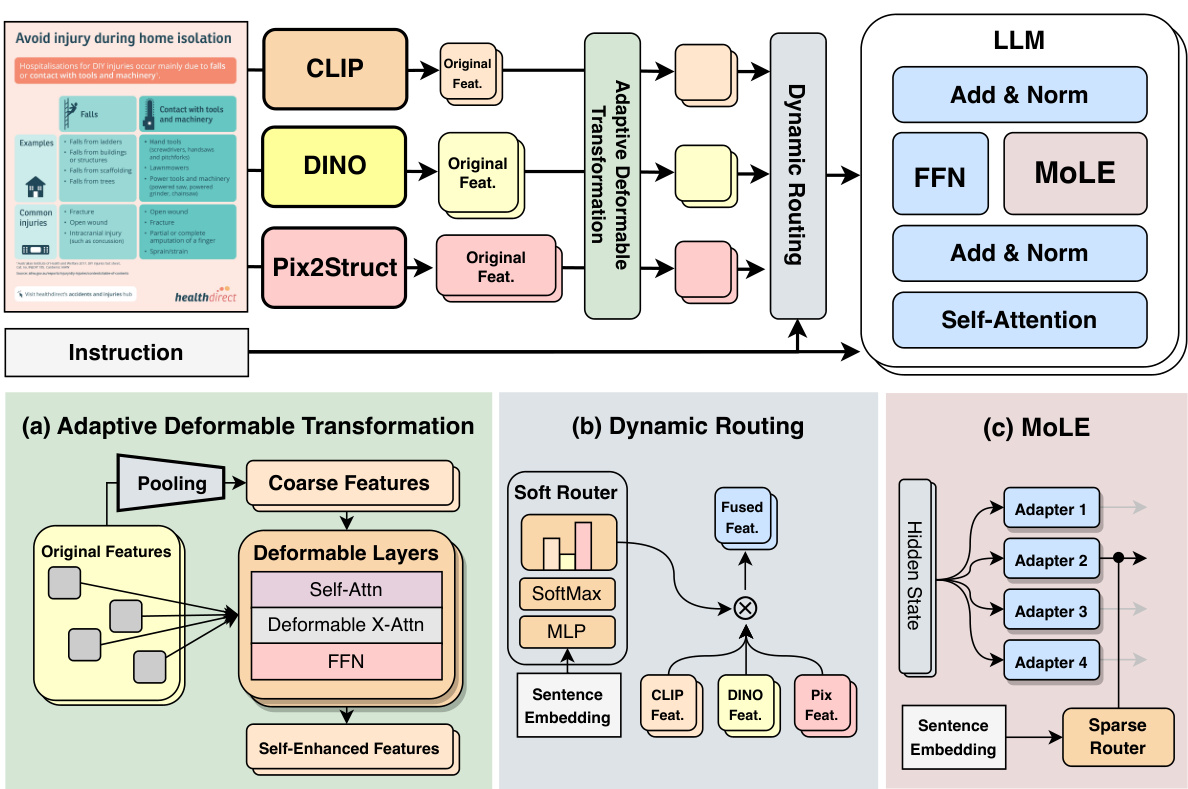
This figure illustrates the architecture of the Mixture of Multimodal Experts (MoME) model. It shows how MoME combines visual and language experts to improve performance on multimodal tasks. The adaptive deformable transformation (ADT) module processes features from multiple vision encoders (CLIP, DINO, Pix2Struct), creating compressed and self-enhanced visual features. Dynamic routing then aggregates these features based on the input instructions. Finally, the Mixture of Language Experts (MoLE) modules are integrated into the feed-forward network (FFN) layers of the large language model (LLM) to enhance its multitasking abilities with minimal additional computational cost.

The figure shows the performance comparison of three different MLLMs, each using a different vision encoder (CLIP-ViT, DINOv2, and Pix2Struct). It demonstrates that models with different vision encoders excel in specific tasks, showcasing the variation in capabilities across encoders and highlighting the need for an adaptive approach.
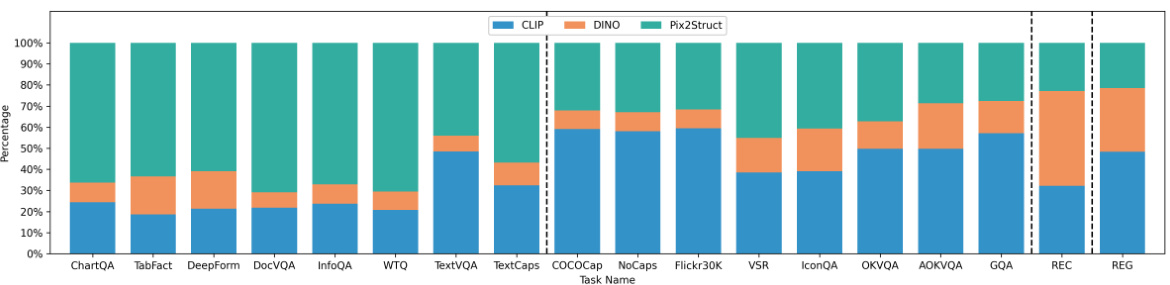
This figure visualizes the distribution of vision expert selection frequencies across various vision-language tasks. Each bar represents a specific task, and the segments within each bar show the proportion of times each vision expert (CLIP, DINO, Pix2Struct) was chosen by the MoVE (Mixture of Vision Experts) module to process the visual features for that task. The lengths of the colored segments directly indicate the frequency of expert selection; longer segments mean that expert was more frequently used for that particular task. The chart provides insights into the specialization of different vision experts for different task types.

This figure illustrates the architecture of the Mixture of Multimodal Experts (MoME) model. It shows three main components: (a) Adaptive Deformable Transformation, which processes visual features from different encoders to create a unified representation; (b) Dynamic Routing, which aggregates these features based on the input instruction; and (c) Mixture of Language Experts (MoLE), which integrates into each feed-forward network (FFN) layer of the Large Language Model (LLM) to improve multitasking and enhance the model’s comprehension with minimal computational overhead. The overall design aims to dynamically mix vision and language experts based on input instructions, improving the generalist capabilities of Multimodal Large Language Models (MLLMs).

This figure visualizes examples from four different vision-language tasks (REC, REG, Document, and General) alongside their respective MoVE (Mixture of Vision Experts) and MoLE (Mixture of Language Experts) routing result distributions. The MoVE section displays the contribution of each vision encoder (Pix2Struct, DINOv2, and CLIP-ViT) to the final feature representation, showing how each encoder specializes in particular tasks. The MoLE section shows how each language expert contributes to processing different task types. The visualization highlights the dynamic selection of vision and language experts based on the task’s unique requirements, illustrating MoME’s adaptive nature in handling different types of vision-language tasks.

This figure shows the categorization of 24 datasets used in the paper for multitask learning and evaluation. The datasets are grouped into four categories: General, REC, REG, and Document. Each category contains several datasets, some of which are used for both training and evaluation, while others are only used for evaluation. The color-coding distinguishes between datasets used for training only, evaluation only, or both.
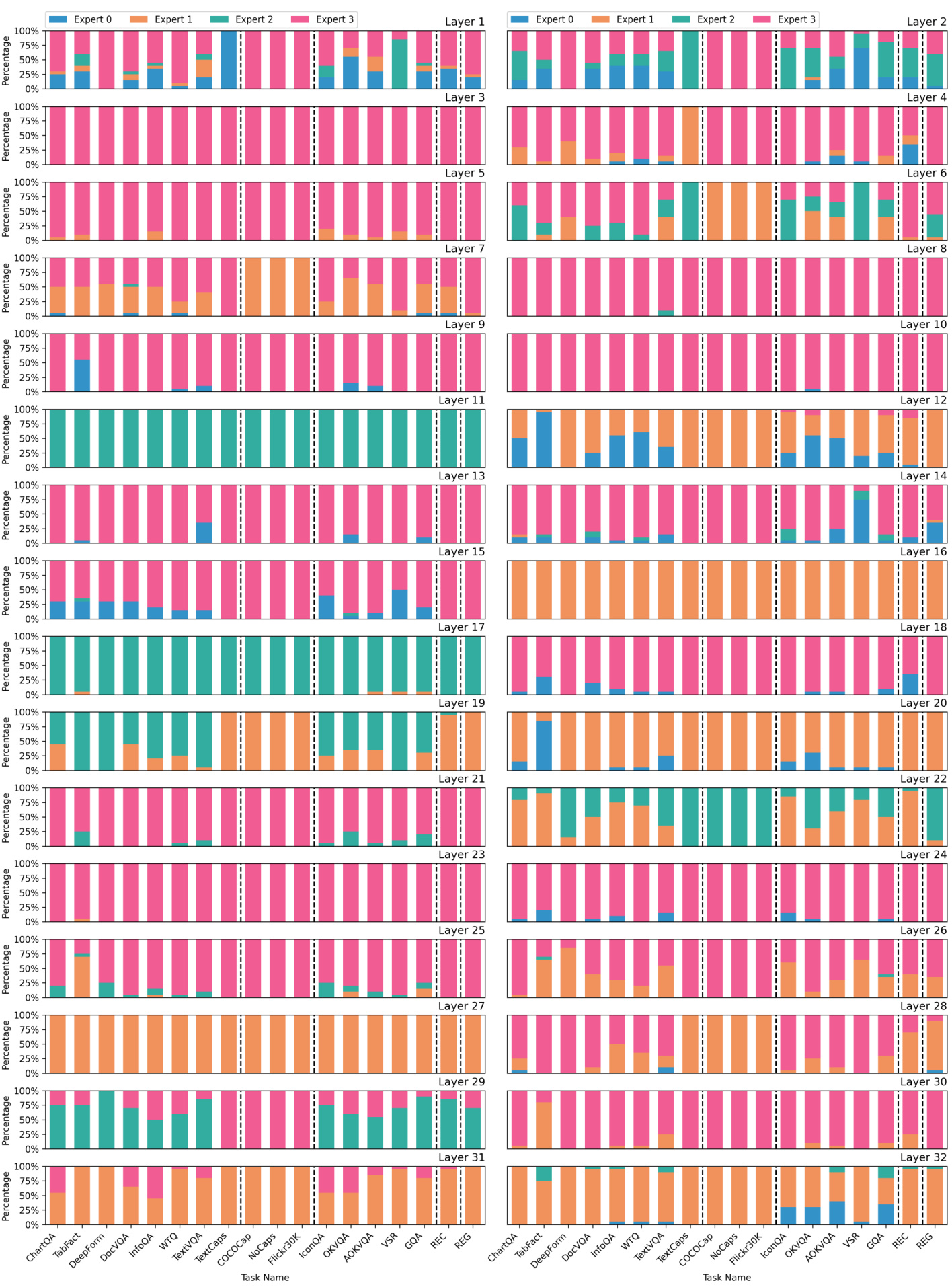
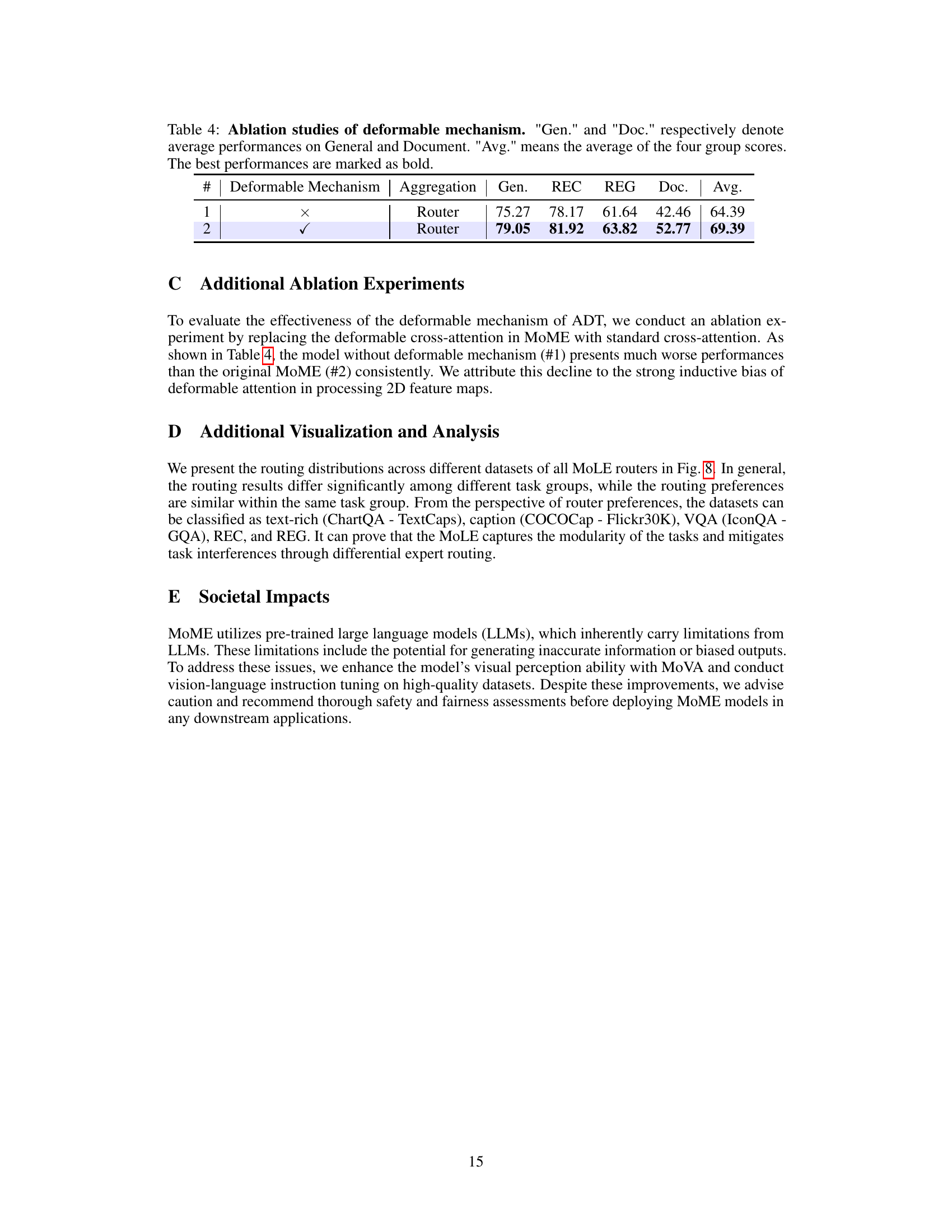
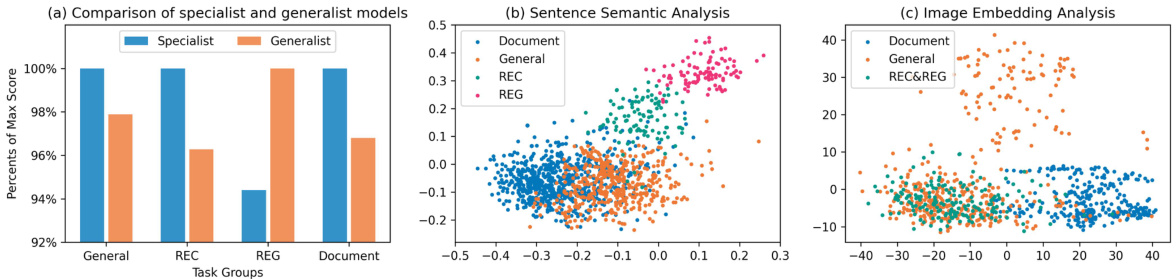
This figure visualizes the distribution of expert usage across different layers of the language model (LLM) for various vision-language tasks. Each bar represents a specific task, and the segments within each bar show the percentage of times each expert was used in each layer of the LLM for that task. This helps to illustrate the specialization of experts across various tasks and demonstrates the dynamic routing capabilities of the MoLE module.
More on tables
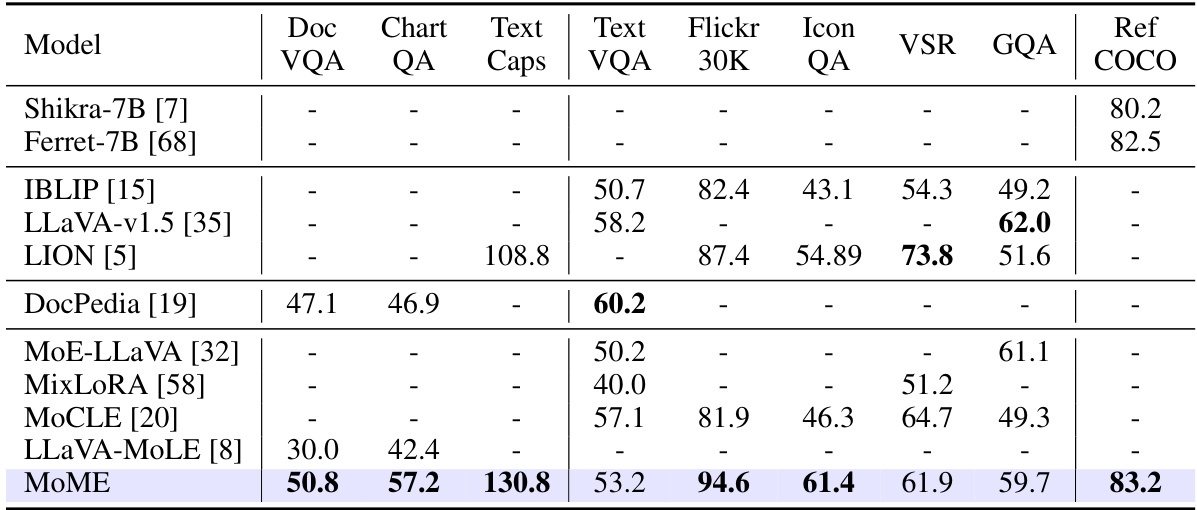
This table compares the performance of the proposed MoME model against other state-of-the-art Multimodal Large Language Models (MLLMs) on various vision-language tasks. It highlights that MoME achieves better performance on most datasets while also demonstrating a broader capability across different task types.

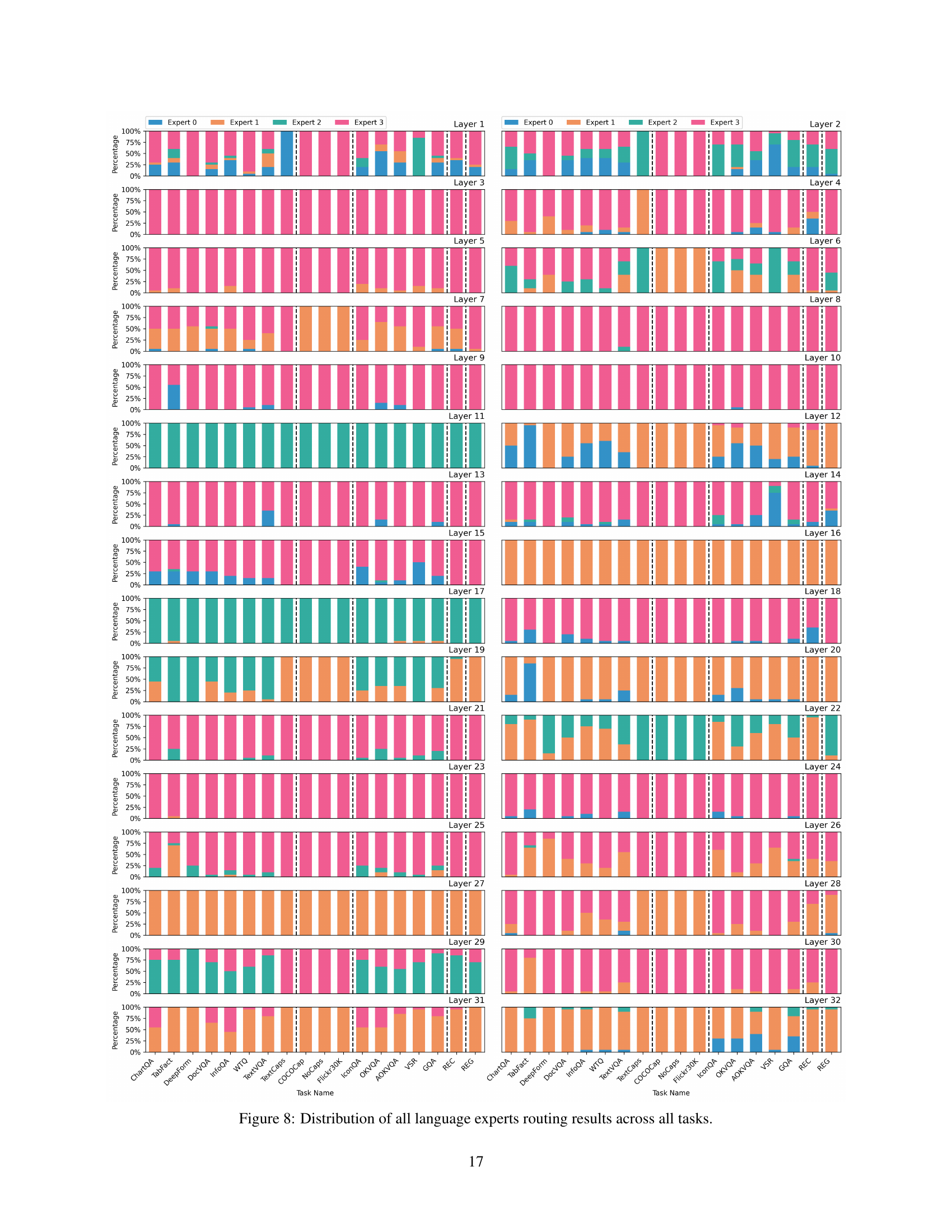
This table presents the ablation study results on the effectiveness of the deformable mechanism in the MoME model. It compares the performance of the model with and without the deformable mechanism, using different aggregation strategies (Router). The results are shown in terms of average performance across different task groups (General, REC, REG, Doc) and overall average performance. The best performance for each metric is highlighted in bold.
This table presents a comparison of different strategies for the Mixture of Vision Experts (MoVE) component of the MoME model. It shows the average performance across four task groups (General, REC, REG, Document) for different combinations of vision encoders (CLIP, DINO, Pix2Struct) and aggregation methods (AvgPool, Addition, Router). The table highlights the impact of using the Adaptive Deformable Transformation (ADT) and the router on improving the model’s performance. The best performing strategy in each category is shown in bold.
Full paper#