↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Knowledge distillation, transferring knowledge from large to small models, faces challenges with computational costs and performance when the teacher model is significantly larger. Prior works used Teacher Assistants (intermediate-sized models), but training these is computationally expensive. Further, the performance doesn’t always improve significantly.
CIFD tackles these issues with two key components: Rate-Distortion Modules (RDMs) replace Teacher Assistants; RDMs are smaller and reuse the teacher’s feature extractors. Information Bottleneck Modules regularize the student model when using multiple RDMs. CIFD achieves state-of-the-art results on ImageNet and CLIP-like models, significantly reducing training costs and improving performance. The method’s efficiency and its applicability to large models makes it particularly valuable.
Key Takeaways#
Why does it matter?#
This paper is important because it proposes a novel and efficient knowledge distillation method, CIFD, which significantly reduces computational costs while improving performance, especially for large datasets. This addresses a key challenge in the field and opens avenues for further research into efficient knowledge transfer techniques and their application in various areas of deep learning.
Visual Insights#
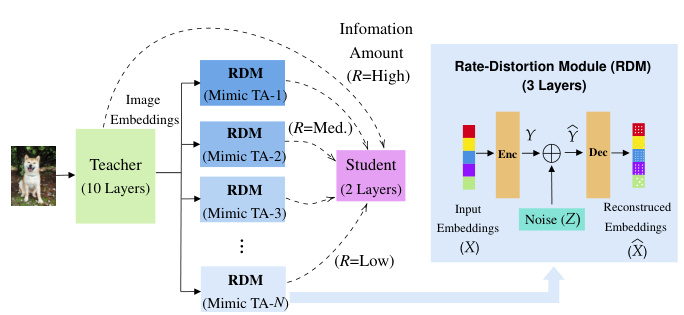
This figure illustrates the proposed CIFD framework for knowledge distillation. (a) shows the architecture of CIFD, highlighting the use of Rate-Distortion Modules (RDMs) as lightweight alternatives to Teacher Assistants. RDMs process teacher embeddings through a rate-constrained channel, mimicking TAs of varying capacities by adjusting the rate constraint. (b) compares the training cost of CIFD with existing knowledge distillation methods, demonstrating CIFD’s significant cost reduction while maintaining or exceeding performance.
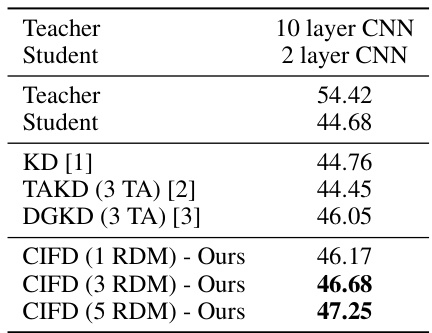
This table presents the classification accuracy (%) on CIFAR-100 dataset using simple Convolutional Neural Networks (CNNs). It compares the performance of different knowledge distillation methods, including the baseline (KD), Teacher Assistant KD (TAKD), Densely Guided KD (DGKD), and the proposed Controlled Information Flow for Knowledge Distillation (CIFD) with varying numbers of Rate-Distortion Modules (RDMs). The results show the improvement achieved by CIFD over existing methods.
In-depth insights#
CIFD: A New KD Method#
CIFD presents a novel approach to knowledge distillation (KD), addressing limitations of existing methods. Instead of using large, expensive teacher assistants (TAs), CIFD introduces Rate-Distortion Modules (RDMs). These RDMs are significantly smaller and more efficient, mimicking the function of TAs by controlling the information flow from teacher to student. A key innovation is the Information Bottleneck Module (IBM) in the student model, which regularizes training and prevents overfitting when multiple RDMs are employed. CIFD demonstrates state-of-the-art results on large-scale datasets like ImageNet, showcasing its effectiveness and efficiency in transferring knowledge from large teacher models to smaller, more resource-friendly student models. The method’s generalizability is highlighted by its success in distilling CLIP-like models, outperforming specialized CLIP distillation techniques. Overall, CIFD offers a promising and computationally efficient solution to enhance knowledge distillation, particularly in scenarios with significant teacher-student size disparities.
RDM Mimics TAs#
The core idea of using Rate-Distortion Modules (RDMs) to mimic Teacher Assistants (TAs) in knowledge distillation is a significant contribution. RDMs offer a computationally cheaper alternative to training intermediate-sized TAs by leveraging the teacher’s penultimate layer embeddings. Instead of training entirely new models, RDMs employ a rate-constrained bottleneck, effectively compressing the teacher’s knowledge. This compression mimics the effect of TAs with varying sizes, depending on the constraint applied, making the process more efficient. The reuse of pre-trained features further enhances efficiency. Information Bottleneck Modules are then used to regularize the student model, preventing overfitting when multiple RDMs are involved, resulting in improved performance and generalization. This approach elegantly combines information theory principles with deep learning techniques.
IBM for Regularization#
The proposed Information Bottleneck Module (IBM) is a crucial addition for regularization in the knowledge distillation process, particularly when using multiple Rate-Distortion Modules (RDMs). The core idea is to constrain the information flow within the student model, preventing overfitting to the teacher’s numerous intermediate representations (provided by RDMs). The IBM acts as a bottleneck, forcing the student to learn only the most essential information from the combined teacher and RDM outputs, thereby improving generalization. This approach mirrors the concept of information bottleneck, where the student model learns a compressed representation that retains only relevant information about the target task, rather than directly mimicking the teacher’s complete representation. The effectiveness of the IBM is demonstrated by its ability to mitigate the overfitting that arises from the increase in the number of RDMs, resulting in improved performance and generalization across various tasks. The inherent regularization properties of the IBM make it a valuable component in improving the efficiency and effectiveness of knowledge distillation, especially in large-scale learning scenarios where overfitting is a common issue. The IBM’s ability to dynamically adjust to the varying number of RDMs makes it a robust and flexible regularization method within this context.
CLIP Model Distillation#
CLIP Model Distillation is a significant area of research focusing on efficiently transferring knowledge from large CLIP models to smaller, more deployable ones. The core challenge lies in preserving CLIP’s unique ability to perform zero-shot classification and image-text retrieval. Approaches often involve distilling various components of CLIP, such as the image and text encoders, and the contrastive loss function, separately or in conjunction. Effective distillation techniques are crucial for resource-constrained environments and on-device applications. However, many current methods are either CLIP-specific or computationally expensive, so a focus on computationally efficient and generalized methods is needed. Future research should explore novel loss functions that better capture the multi-modal nature of CLIP’s representations, while also addressing issues such as overfitting and the teacher-student capacity gap. The development of generalized distillation methods will further unlock the potential of powerful, lightweight models for a wide range of applications.
Limitations and Future#
The research paper’s success hinges on its ability to effectively mimic Teacher Assistants using Rate-Distortion Modules (RDMs). A key limitation is the reliance on the teacher’s penultimate layer embeddings, potentially hindering the transfer of lower-level feature information vital for robust student model learning. Moreover, the effectiveness of the Information Bottleneck Module (IBM) in preventing overfitting with multiple RDMs requires further investigation, particularly regarding its adaptability to diverse datasets and model architectures. Future work could explore the integration of lower-level features in RDMs, potentially via feature distillation techniques, improving knowledge transfer. Further analysis on the IBM’s regularization effects, particularly in scenarios with high-dimensional embeddings, would be insightful. Expanding to other modalities, beyond image and text, and applying the method to more complex tasks would enhance its generalizability and practical impact. Finally, comprehensive studies into training cost-effectiveness, especially across very large datasets, are necessary for practical applications.
More visual insights#
More on figures

This figure demonstrates the proposed CIFD method for knowledge distillation. Panel (a) illustrates the architecture of CIFD, highlighting the use of Rate-Distortion Modules (RDMs) as a more efficient alternative to Teacher Assistants (TAs) for knowledge transfer from a large teacher model to a smaller student model. Panel (b) compares the training cost of CIFD with other existing knowledge distillation methods, showing a significant reduction in cost while maintaining or improving performance.
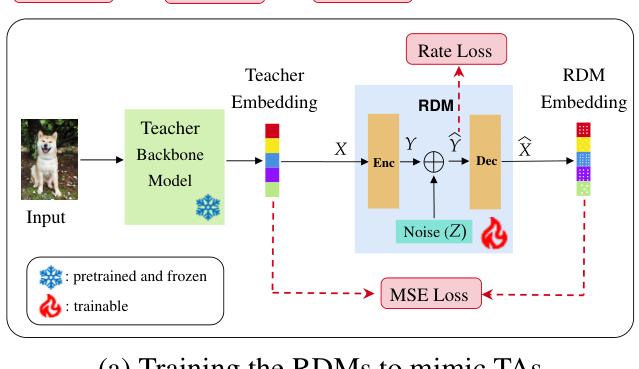
This figure illustrates the two-stage training process of the Controlled Information Flow for Knowledge Distillation (CIFD) framework. The first stage (a) focuses on training Rate-Distortion Modules (RDMs) to mimic the behavior of Teacher Assistants (TAs). RDMs process the teacher’s penultimate layer embeddings through a rate-constrained communication channel. This stage aims to create smaller, cheaper-to-train alternatives to TAs. The second stage (b) trains the student model, using both the trained RDMs and the original teacher model. This stage leverages the RDMs to transfer knowledge efficiently to the smaller student model, while an Information Bottleneck Module regularizes the training process to prevent overfitting.
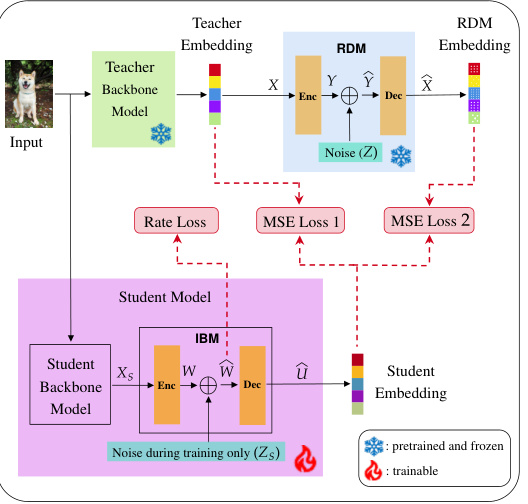
This figure illustrates the training process of the Controlled Information Flow for Knowledge Distillation (CIFD) framework. It shows two stages: (a) training the Rate-Distortion Modules (RDMs) to mimic Teacher Assistants (TAs) by processing teacher embeddings through a rate-constrained bottleneck layer and (b) training the student model using the trained RDMs and the original teacher model. The RDMs act as intermediate models between the teacher and the student, simplifying the knowledge transfer process. The Information Bottleneck Module (IBM) within the student model regularizes the training in the presence of multiple RDMs to prevent overfitting. The diagrams detail the flow of information and the loss functions used in each training stage.
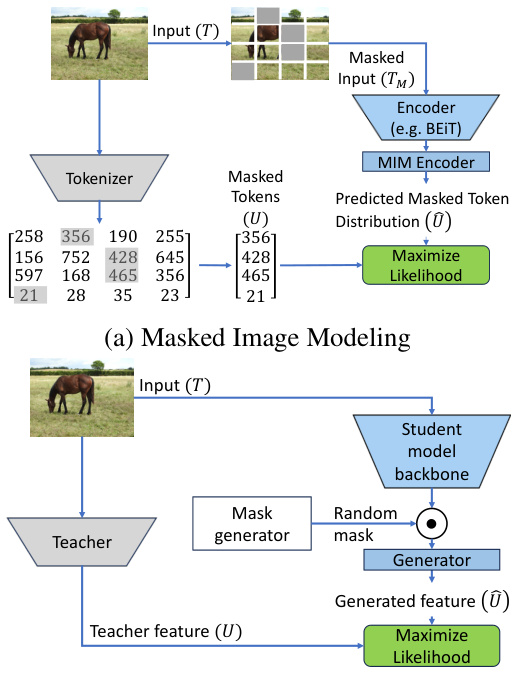
This figure illustrates the relationship between three different methods: Masked Image Modeling (MIM), Masked Generative Distillation (MGD), and the Information Bottleneck Module (IBM). It visually depicts how each method approaches the problem of knowledge transfer by showing the input, processing steps, and the final objective. MIM focuses on reconstructing masked parts of an image; MGD aims to generate a representation that matches the teacher’s; and IBM seeks to find a balance between preserving useful information and minimizing redundancy. The figure helps to clarify the connections between these techniques and their relationship to the proposed Information Bottleneck Module in the paper.
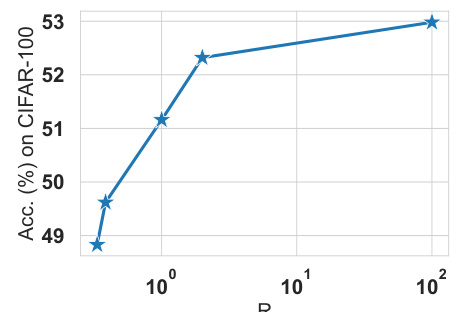
This figure shows the effect of varying the information rate (R) on the performance of the Rate-Distortion Module (RDM) in a classification task. The x-axis represents the rate parameter R, while the y-axis shows the classification accuracy. The plot demonstrates a behavior similar to a rate-distortion curve: as the rate constraint increases, the accuracy initially increases and then plateaus. This suggests that increasing the information rate up to a certain point improves performance; however, beyond that point, further increases do not significantly improve the results.
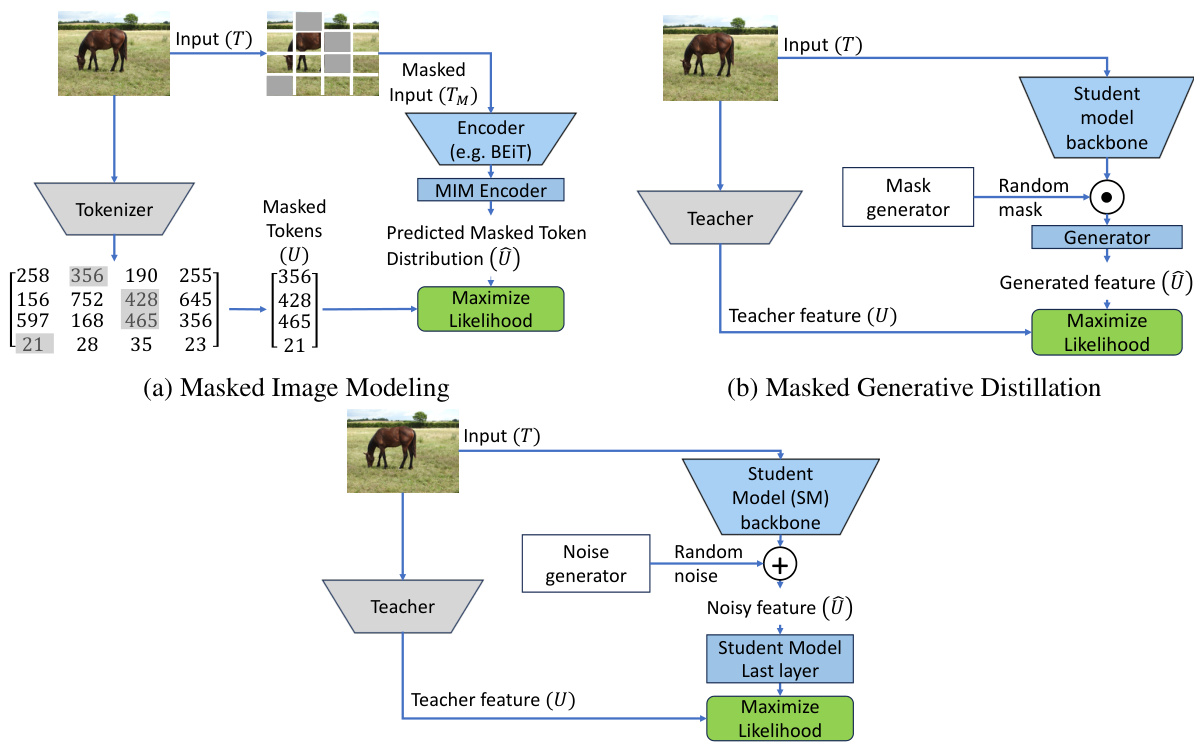
This figure illustrates the relationship between three different methods: Masked Image Modeling (MIM), Masked Generative Distillation (MGD), and the proposed Information Bottleneck Module (IBM) for knowledge distillation. It visually depicts the architecture of each method, showing how they process input images and generate embeddings. MIM focuses on masking parts of an input image and predicting the masked parts. MGD uses the teacher model embedding and generates features, and the IBM introduces a noise mechanism to control the flow of information during distillation. The figure highlights the similarities and differences between these techniques in terms of their approach to knowledge transfer.
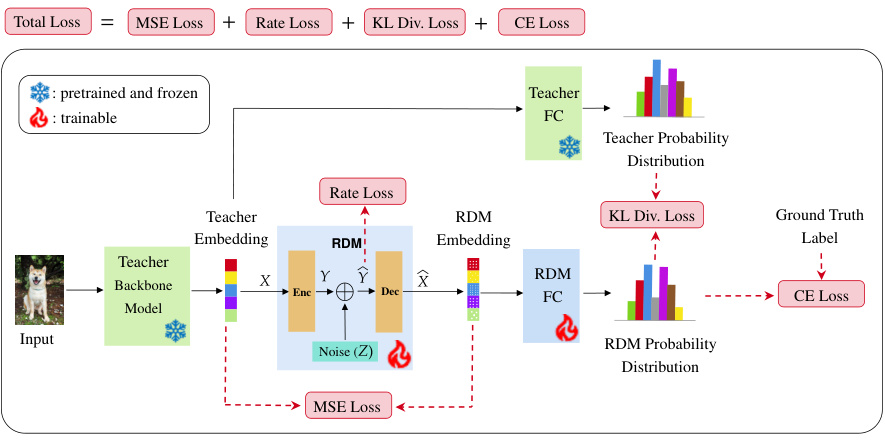
This figure illustrates the training process of the Rate-Distortion Module (RDM) for classification tasks. The input (e.g., an image) is first processed by the teacher’s backbone model to extract the embedding. This embedding is then fed into the RDM encoder, where noise is added. The encoder output is passed through a rate-constrained bottleneck layer, and a decoder reconstructs the embedding. Finally, a fully-connected layer converts the reconstructed embedding into class logits. The RDM’s training loss is a combination of mean squared error (MSE) between the input and reconstructed embeddings, a rate loss that penalizes high information flow, Kullback-Leibler (KL) divergence between the teacher’s and RDM’s class probability distributions, and cross-entropy (CE) loss between the RDM’s predictions and ground truth labels. This multi-task learning approach enables the RDM to effectively learn both a compressed representation of the teacher’s embedding and accurate classification information.
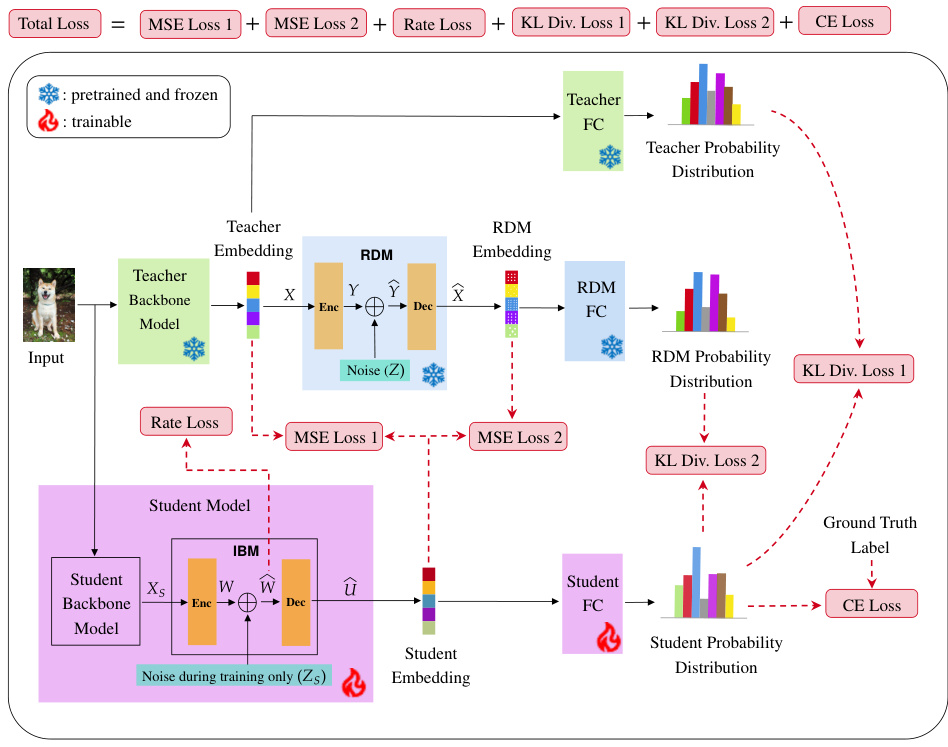
This figure illustrates the two-stage training process of the Controlled Information Flow for Knowledge Distillation (CIFD) framework. The first stage (a) focuses on training Rate-Distortion Modules (RDMs) to mimic the behavior of Teacher Assistants. These RDMs process the teacher’s embeddings, adding noise to simulate different levels of information transfer. The second stage (b) trains the student model, using both the pretrained RDMs and the teacher model. The student model incorporates an Information Bottleneck Module (IBM) to prevent overfitting and enhance generalization. The figure shows the different components including input embeddings, RDMs, teacher model, student model, and the different loss components used during training, including mean square error (MSE) loss, rate loss, and cross-entropy loss.
The figure shows the proposed CIFD framework for knowledge distillation, which uses Rate-Distortion Modules (RDMs) instead of Teacher Assistants. (a) illustrates the architecture of CIFD, highlighting the role of RDMs in mimicking TAs and distilling knowledge to the student model. (b) compares the training cost of CIFD with existing knowledge distillation approaches, demonstrating that CIFD significantly reduces the cost while improving performance.
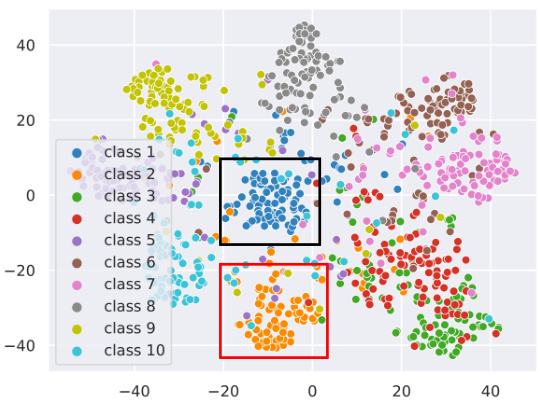
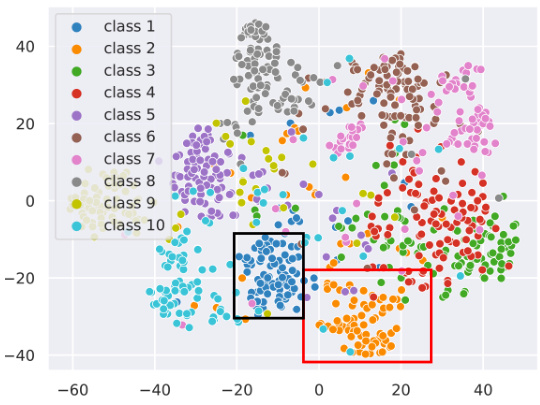
This figure shows the t-SNE visualization of embeddings from the teacher model and two different RDM models trained on the CIFAR-100 dataset. The visualization helps to understand how the RDMs (Rate-Distortion Modules) capture and represent information from the teacher model. The better-performing RDM shows a similar embedding distribution to the teacher, while a poorer performing RDM exhibits a more dispersed and less informative representation.

This figure shows the t-SNE visualization of embeddings from the teacher model and two RDM models trained on the CIFAR-100 dataset. The visualization helps to understand how the RDMs (Rate-Distortion Modules), which mimic teacher assistants in knowledge distillation, represent the data. The better-performing RDM produces embeddings where clusters are well-separated and similar to the teacher’s embeddings, implying effective knowledge transfer. Conversely, the poorly performing RDM shows more scattered clusters, suggesting less effective knowledge transfer.
More on tables
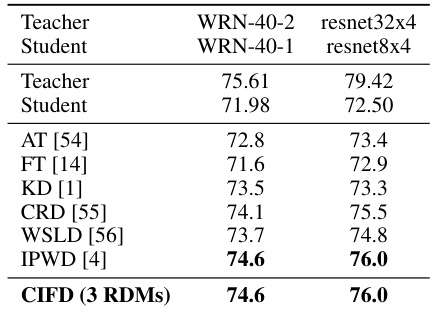
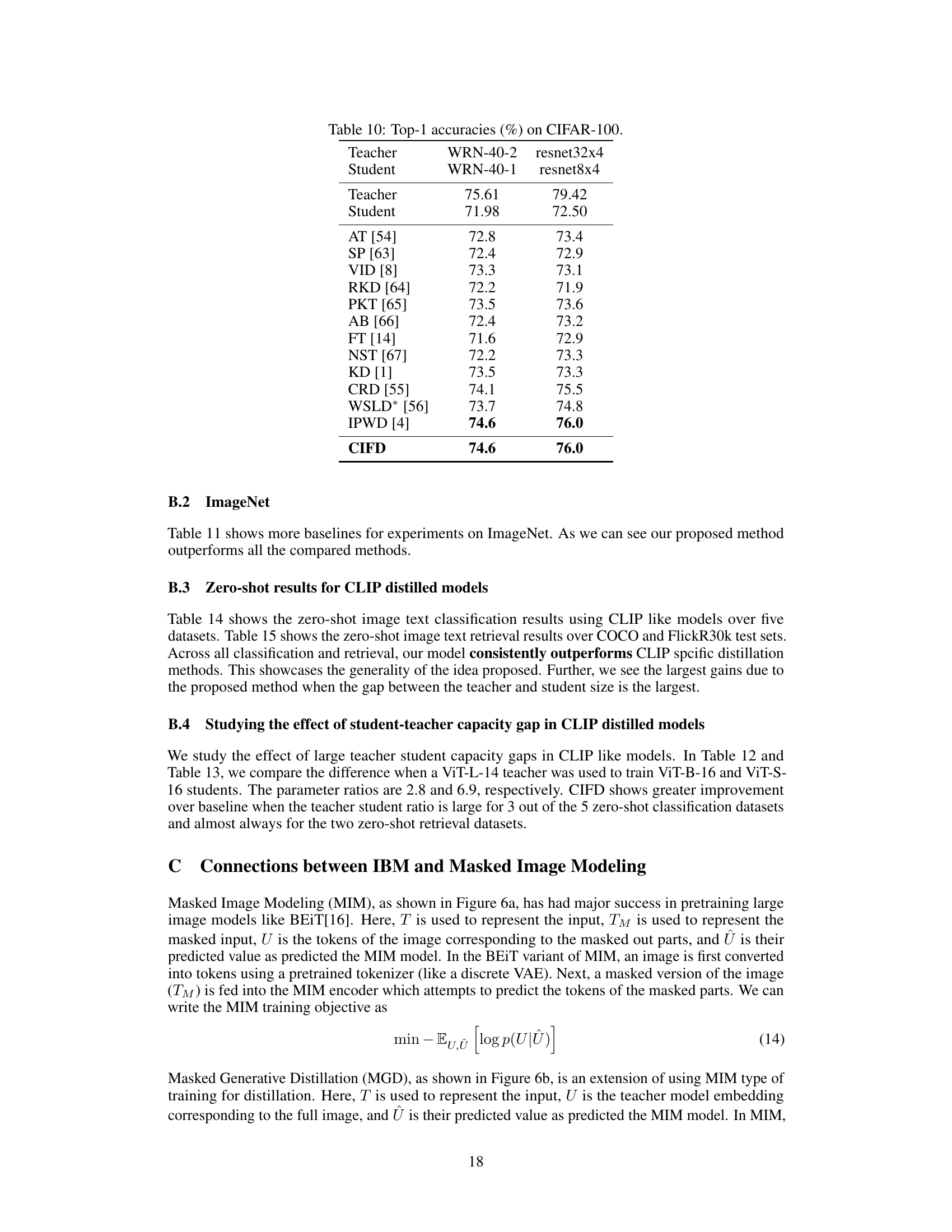
This table presents the classification accuracy results on CIFAR-100 dataset. It compares the performance of the proposed CIFD method with several other knowledge distillation techniques, including KD, TAKD, DGKD, AT, FT, CRD, WSLD, and IPWD. The table shows accuracy for two different student model architectures (WRN-40-1 and resnet8x4) when trained to distill knowledge from two different teacher models (WRN-40-2 and resnet32x4).
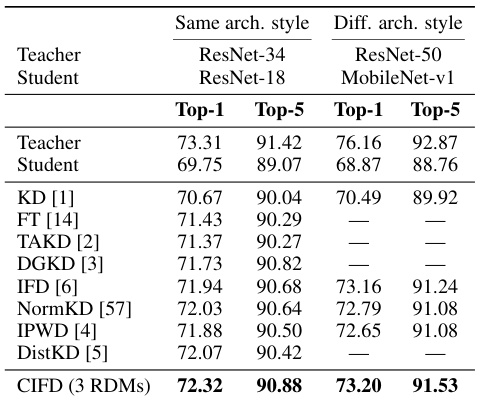
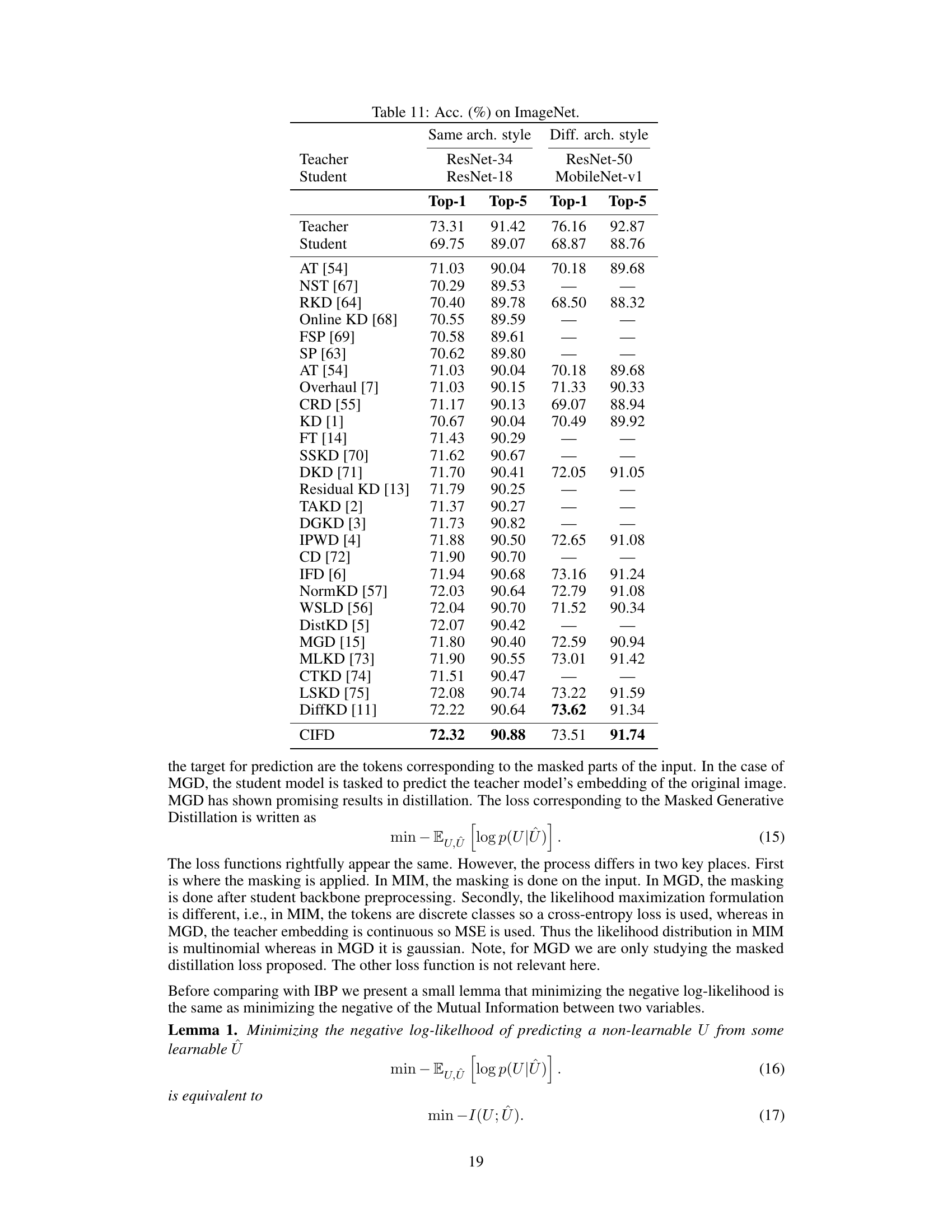
This table presents the Top-1 and Top-5 accuracy results on the ImageNet dataset for different knowledge distillation methods. It compares the performance of CIFD (with 3 RDMs) against several other state-of-the-art methods, including KD, FT, TAKD, DGKD, IFD, NormKD, IPWD, and DistKD. Two scenarios are shown: one where the teacher and student models have the same architecture style (ResNet-34 to ResNet-18), and another where they use different architectures (ResNet-50 to MobileNet-v1). CIFD achieves state-of-the-art results in both scenarios.
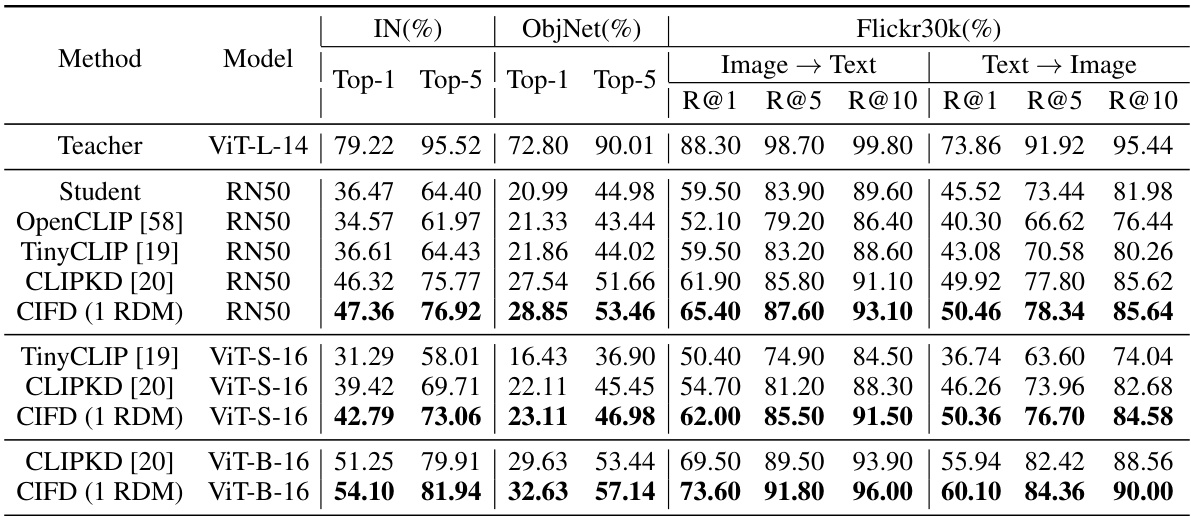
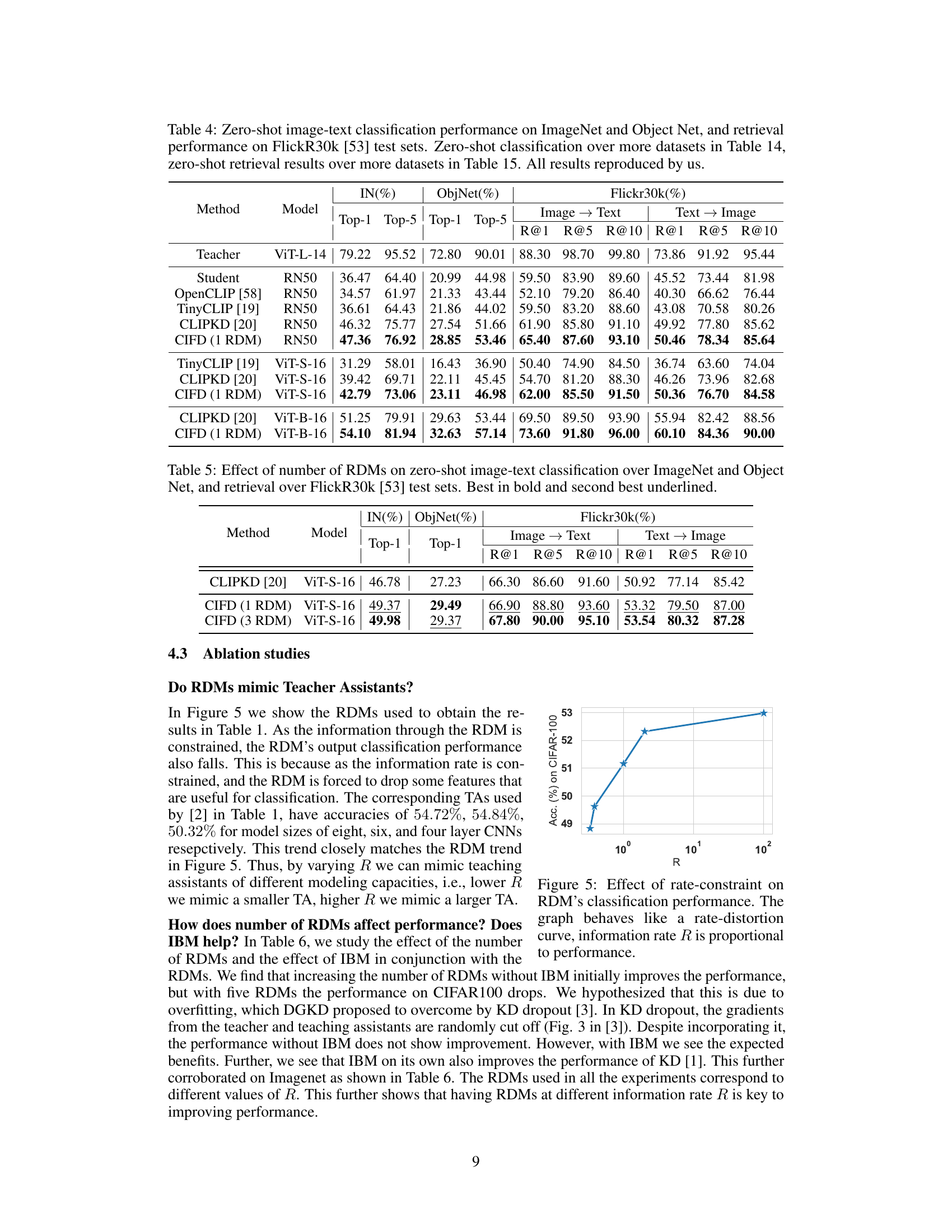
This table presents the zero-shot performance results of different CLIP-like models on ImageNet, ObjectNet, and Flickr30k datasets. The results include top-1 and top-5 accuracy for classification tasks, and recall at ranks 1, 5, and 10 for retrieval tasks. The table compares the proposed CIFD method against several other state-of-the-art CLIP distillation methods (OpenCLIP, TinyCLIP, CLIPKD) across various teacher-student model combinations. It highlights the improved performance of CIFD, especially when there is a large capacity gap between the teacher and student models.
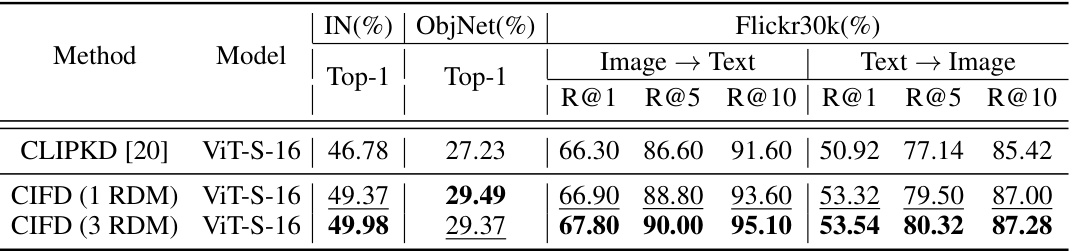
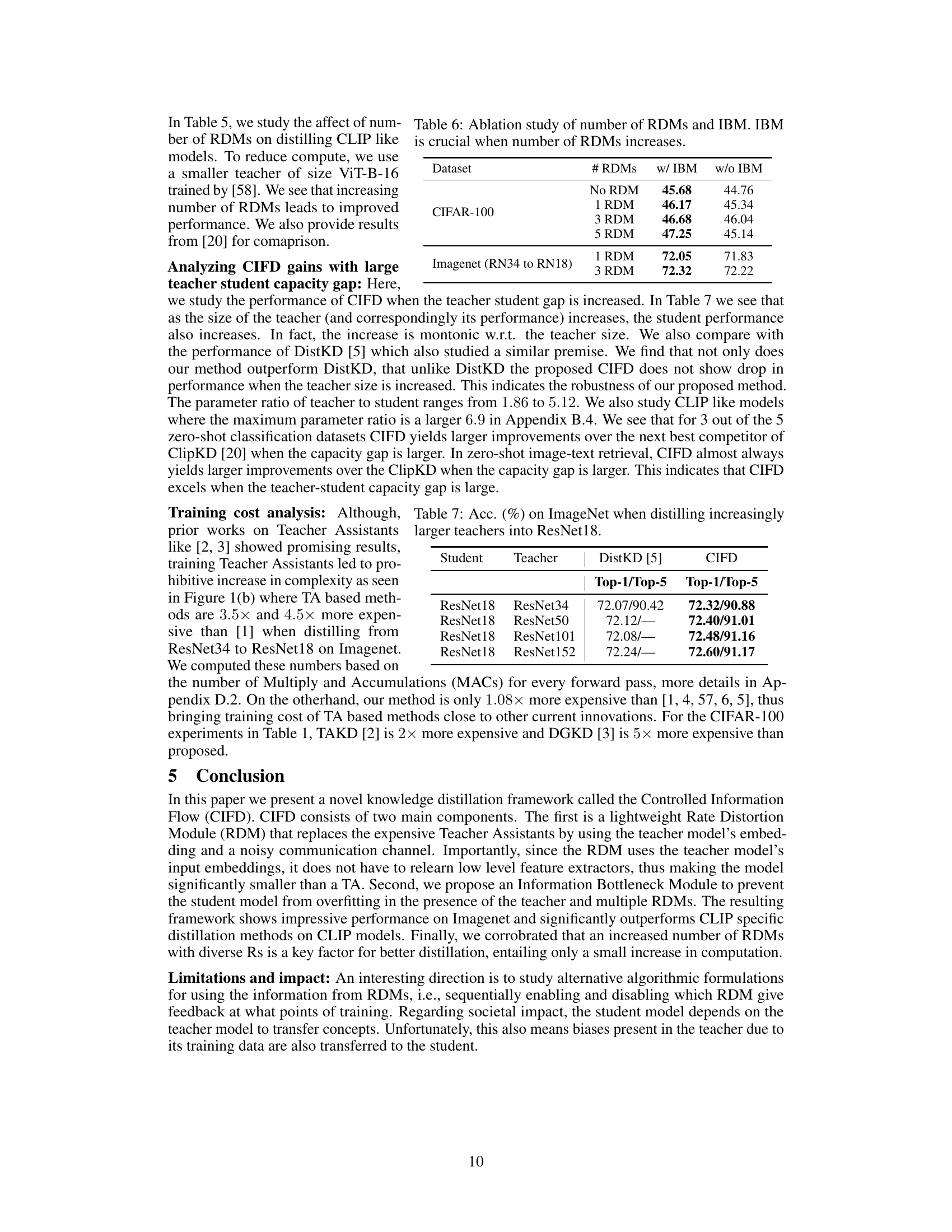
This table shows the impact of using different numbers of Rate-Distortion Modules (RDMs) on the performance of the CIFD method. The results are presented for zero-shot image-text classification on ImageNet and ObjectNet datasets, as well as zero-shot image-text retrieval on the Flickr30k dataset. The table highlights how increasing the number of RDMs can improve performance, with the best results obtained using 3 RDMs.
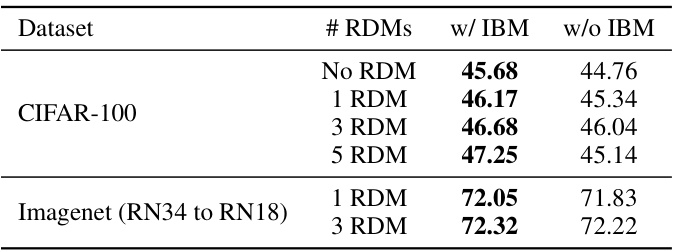
This table presents the ablation study results to analyze the impact of the number of Rate-Distortion Modules (RDMs) and the Information Bottleneck Module (IBM) on the model’s performance. It shows the accuracy achieved on the CIFAR-100 dataset and the ImageNet dataset (distilling ResNet34 to ResNet18) with varying numbers of RDMs, both with and without the IBM. The results demonstrate the effectiveness of IBM in regularizing the model when multiple RDMs are used, preventing overfitting and improving generalization.
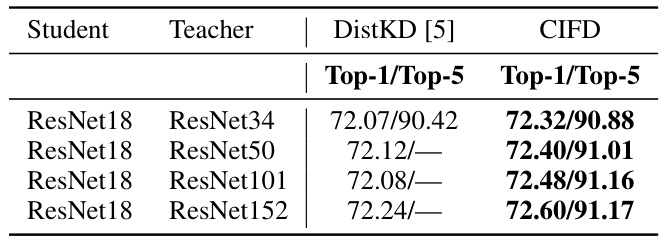
This table presents the top-1 and top-5 accuracy results on the ImageNet dataset for different knowledge distillation methods. It compares the performance of the proposed CIFD method against several existing state-of-the-art knowledge distillation techniques, specifically focusing on distilling from ResNet-34 to ResNet-18 and ResNet-50 to MobileNet-v1. The table highlights the improvement achieved by CIFD compared to other methods.

This table compares the accuracy of different knowledge distillation methods on the CIFAR-100 dataset using simple Convolutional Neural Networks (CNNs). It shows the accuracy of a student model trained using various methods (KD, TAKD, DGKD, and CIFD with varying numbers of RDMs) in comparison to the teacher model accuracy. The results highlight the performance gains achieved by using the proposed CIFD approach.

This table details the architectures of various CLIP models used in the experiments. It shows the embedding dimensions, vision encoder details (model architecture, image size, layers, width, patch size), and text encoder details (model architecture, context length, vocabulary size, width, heads, layers) along with the total number of parameters for each model. These details are crucial for understanding the computational cost and performance characteristics of the different CLIP models used in the knowledge distillation experiments described in the paper. The models include ResNet50, ViT-S-16, ViT-B-16 and ViT-L-14, all of which are variations of Vision Transformer models used to process image data and Transformer-based models used to process text data.
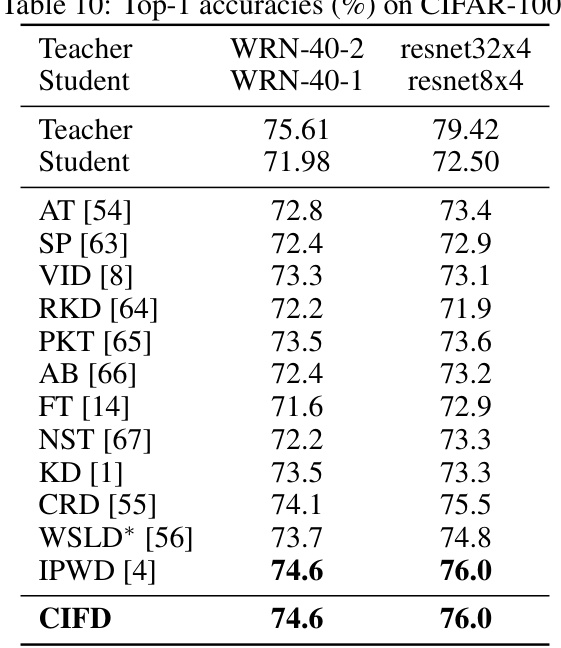
This table compares the performance of the proposed CIFD method against several other state-of-the-art knowledge distillation methods on the CIFAR-100 dataset. The results are shown for two different teacher-student model architectures (WRN-40-2 to WRN-40-1 and resnet32x4 to resnet8x4). It demonstrates that CIFD achieves competitive performance compared to existing methods.
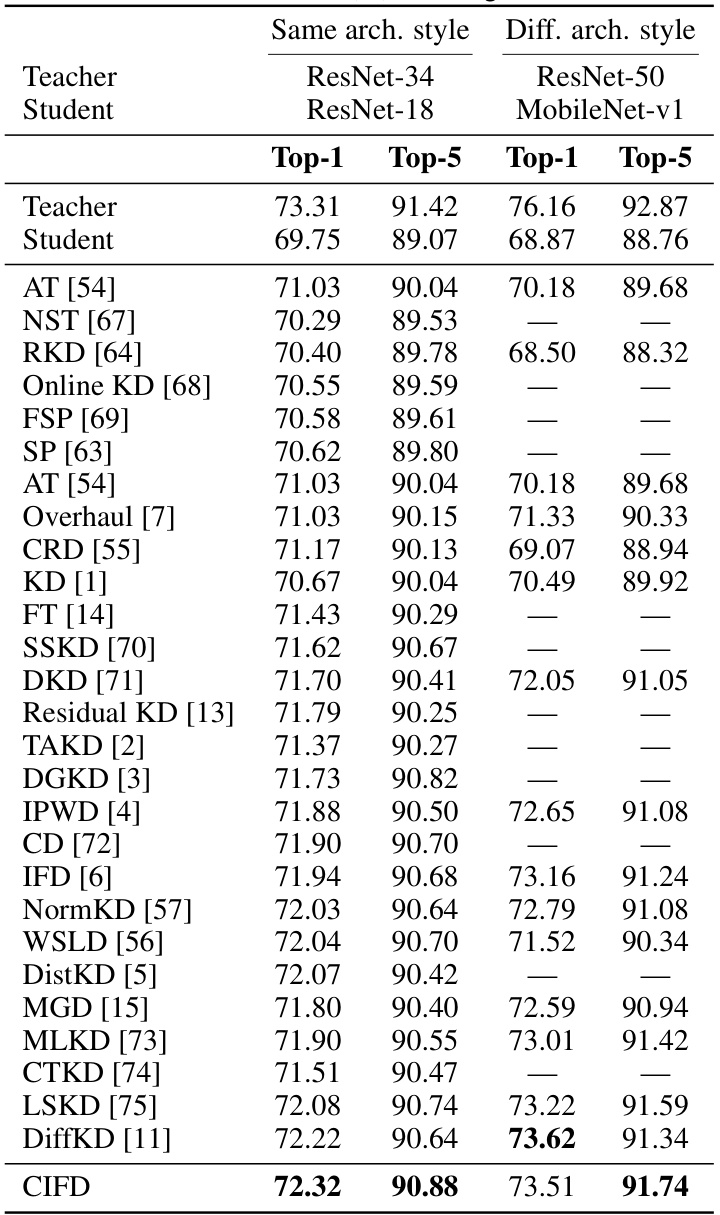
This table shows the top-1 and top-5 accuracy results on the ImageNet dataset for different knowledge distillation methods. It compares the performance of CIFD (the proposed method) against several other state-of-the-art methods for two different teacher-student model architectures: ResNet-34 to ResNet-18 and ResNet-50 to MobileNet-v1. The results highlight CIFD’s superior performance compared to existing techniques.
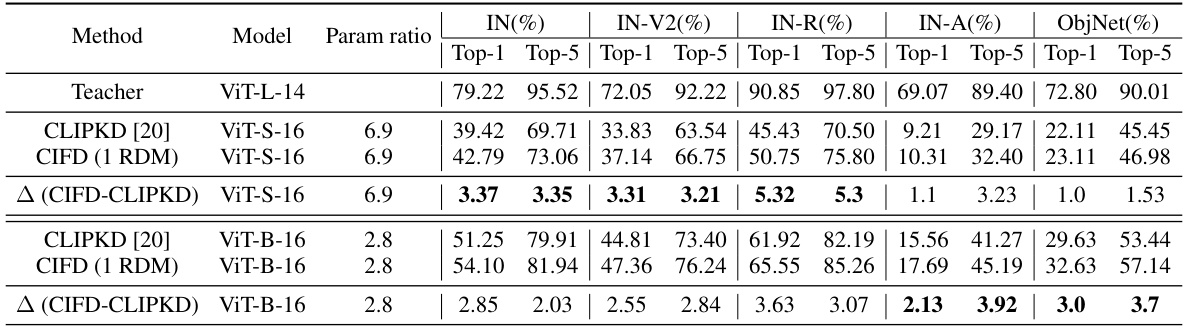
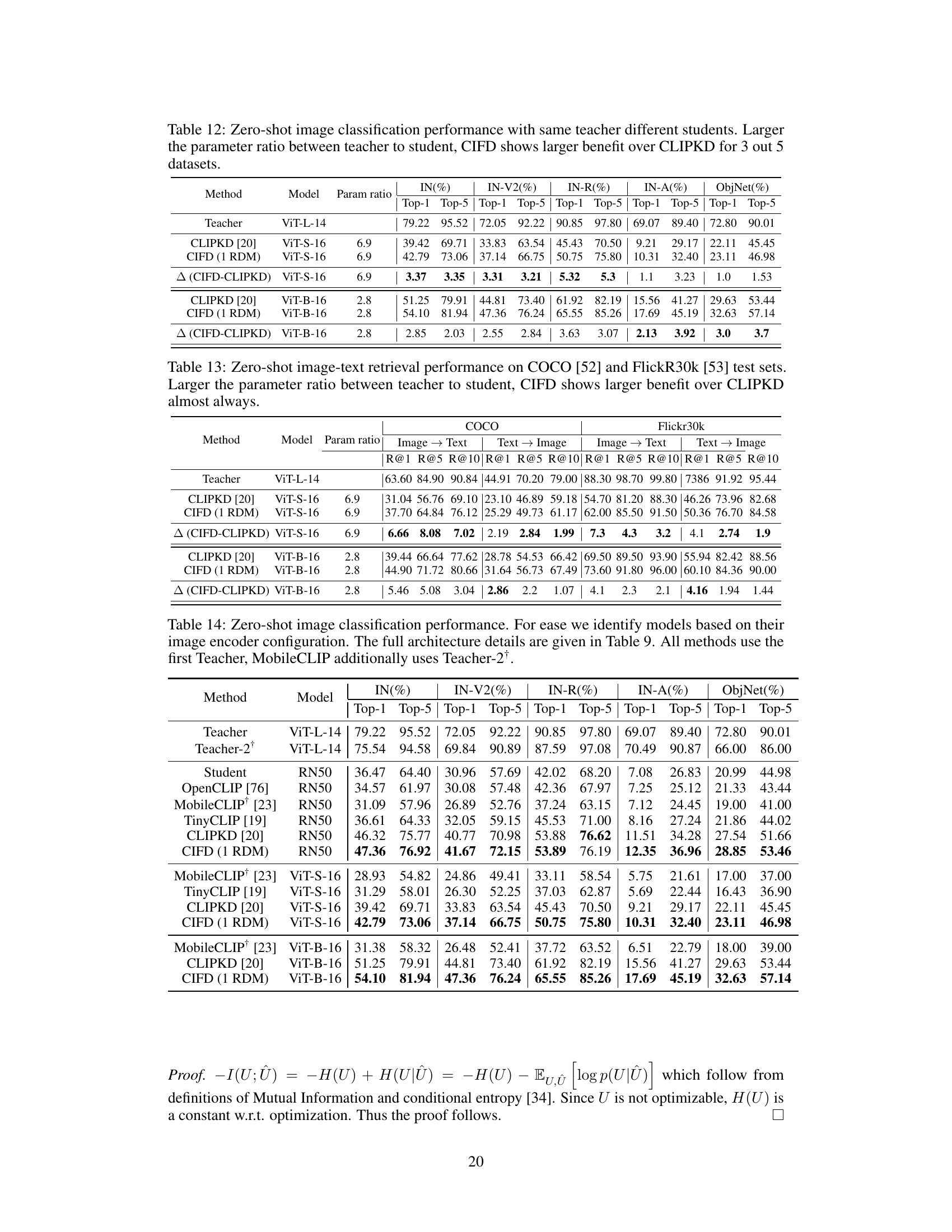
This table presents the results of zero-shot image classification experiments using different teacher-student model combinations. It compares the performance of the proposed CIFD method against CLIPKD, highlighting the performance gains achieved with CIFD, especially when the model size difference (parameter ratio) between the teacher and student models is significant. The results are presented across five datasets (IN, IN-V2, IN-R, IN-A, ObjNet), showing Top-1 and Top-5 accuracies. The table emphasizes that CIFD’s advantage over CLIPKD is particularly pronounced when there is a considerable disparity in model size between the teacher and student.
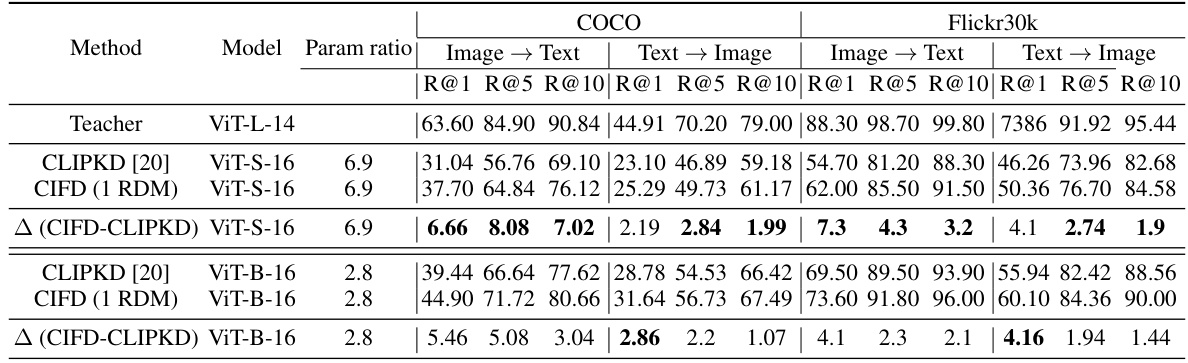
This table compares the zero-shot image-text retrieval performance of different methods on the COCO and Flickr30k datasets. It shows the recall at different ranks (R@1, R@5, R@10) for both image-to-text and text-to-image retrieval tasks. The results are broken down by model (ViT-L-14, ViT-S-16, ViT-B-16, RN50) and method (OpenCLIP, MobileCLIP, TinyCLIP, CLIPKD, CIFD). The table highlights the improvements achieved by CIFD over existing methods, especially for larger teacher-student model size differences.
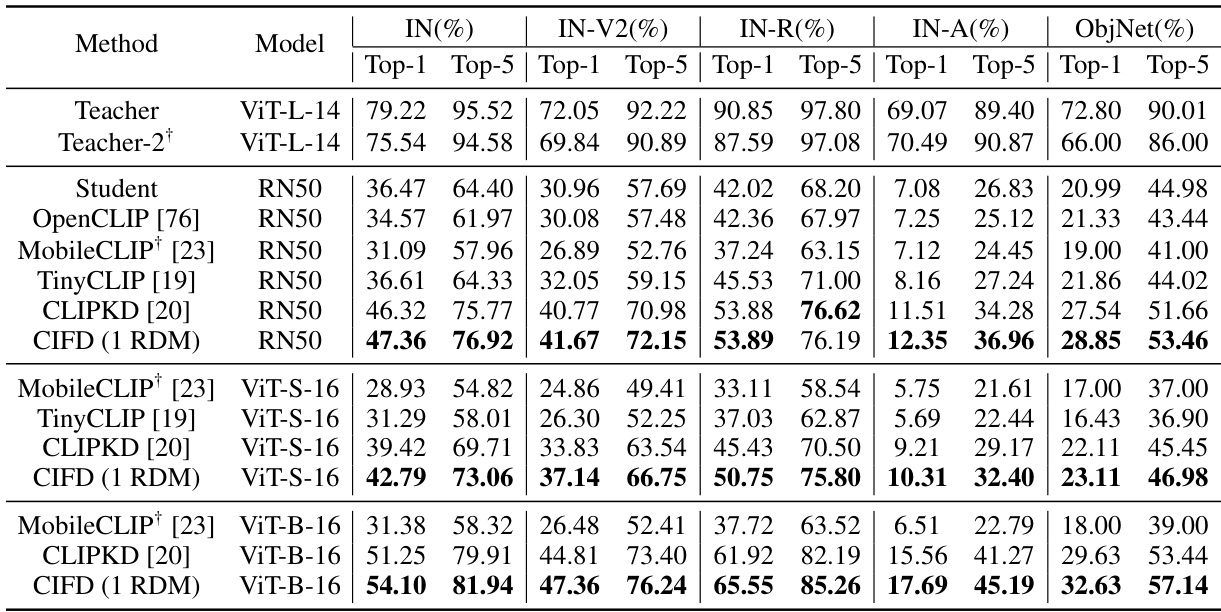
This table presents the zero-shot performance comparison of different methods on various image and text classification and retrieval tasks. It shows the Top-1 and Top-5 accuracies for zero-shot image classification on ImageNet and ObjectNet datasets and the Recall@1, Recall@5, and Recall@10 for zero-shot image-text retrieval on the Flickr30k dataset. The results highlight the superior performance of the proposed CIFD method compared to existing state-of-the-art techniques.
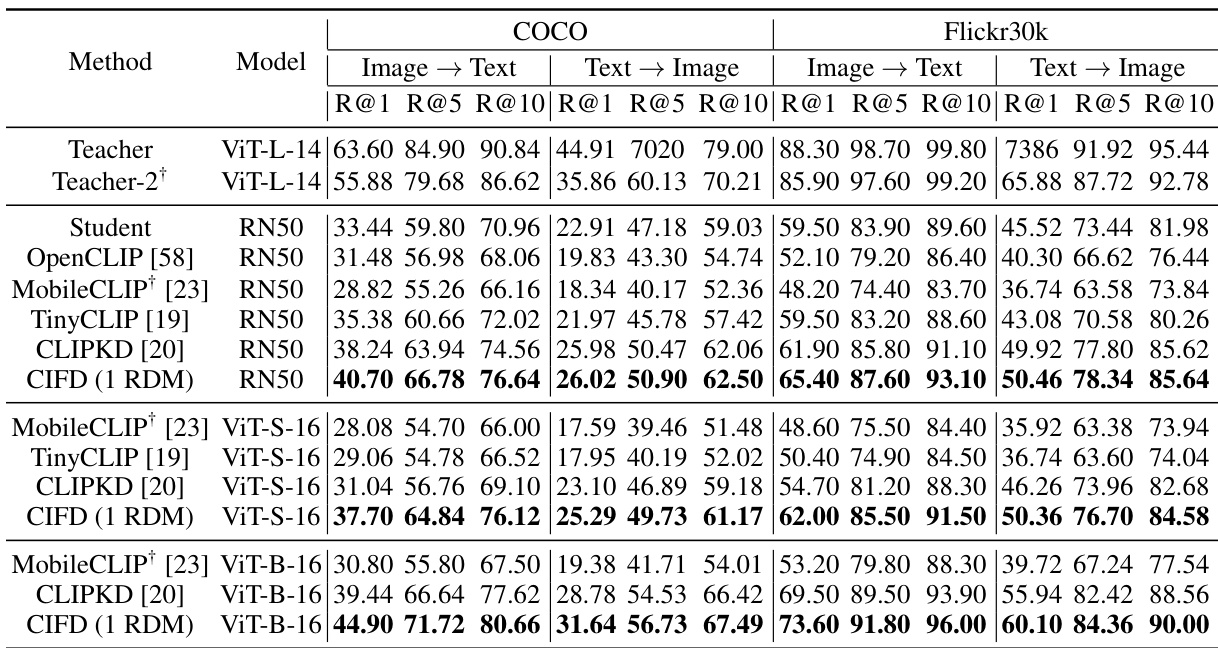
This table presents the zero-shot performance of different models on ImageNet, ObjectNet, and Flickr30k datasets. The performance is measured using Top-1 and Top-5 accuracy for classification and Recall@1, Recall@5, and Recall@10 for retrieval tasks. The results compare the proposed CIFD method against several existing CLIP distillation methods (TinyCLIP, CLIPKD) and a baseline (OpenCLIP). The table shows that CIFD consistently outperforms the other methods across all datasets and metrics, highlighting its effectiveness in improving zero-shot capabilities of CLIP-like models.
Full paper#