↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Large language models (LLMs) are often fine-tuned for specific tasks, resulting in many large, unique models which are expensive to store and serve. Existing parameter-efficient fine-tuning methods have limitations in achieving the same quality as full parameter fine-tuning. This research addresses the challenges of storing and deploying numerous fine-tuned LLMs.
BitDelta tackles these issues with a novel post-fine-tuning compression technique. It decomposes the fine-tuned model weights into the pre-trained weights and a delta. This delta is then quantized down to 1 bit, significantly reducing storage and memory needs. Experiments on various LLMs (up to 70B parameters) demonstrate minimal performance degradation while achieving memory reduction of more than 10x, translating to more than a 10x speedup in multi-tenant serving scenarios.
Key Takeaways#
Why does it matter?#
This paper is important because it presents BitDelta, a novel method for compressing fine-tuned large language models (LLMs). This significantly reduces the memory footprint and latency, crucial for deploying LLMs in resource-constrained environments and multi-tenant settings. The research opens up new avenues in efficient model serving and storage, impacting model deployment costs and enabling broader access to LLMs.
Visual Insights#
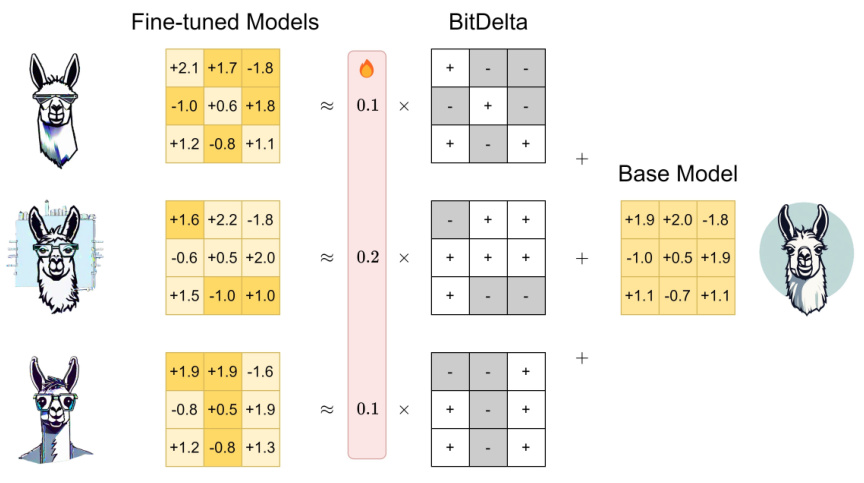
This figure illustrates the core idea of BitDelta. It shows how multiple fine-tuned models can be represented using a single high-precision base model and several 1-bit deltas. Each delta represents the difference between the fine-tuned model’s weights and the base model’s weights. By quantizing these deltas to only one bit, BitDelta significantly reduces memory usage and improves inference speed, especially in multi-tenant scenarios where many fine-tuned models need to be served concurrently.
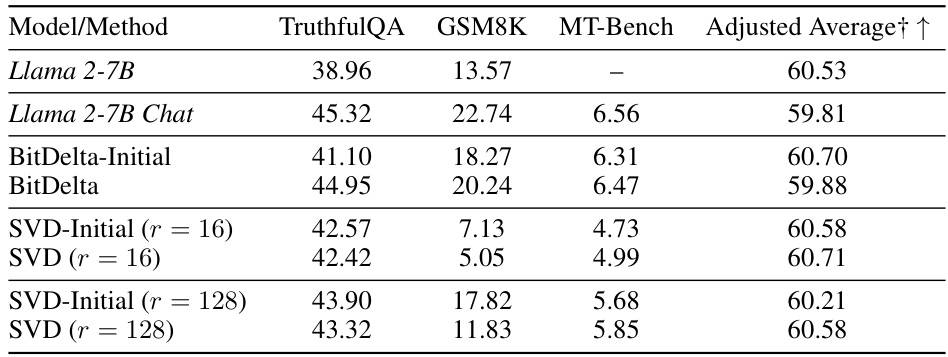
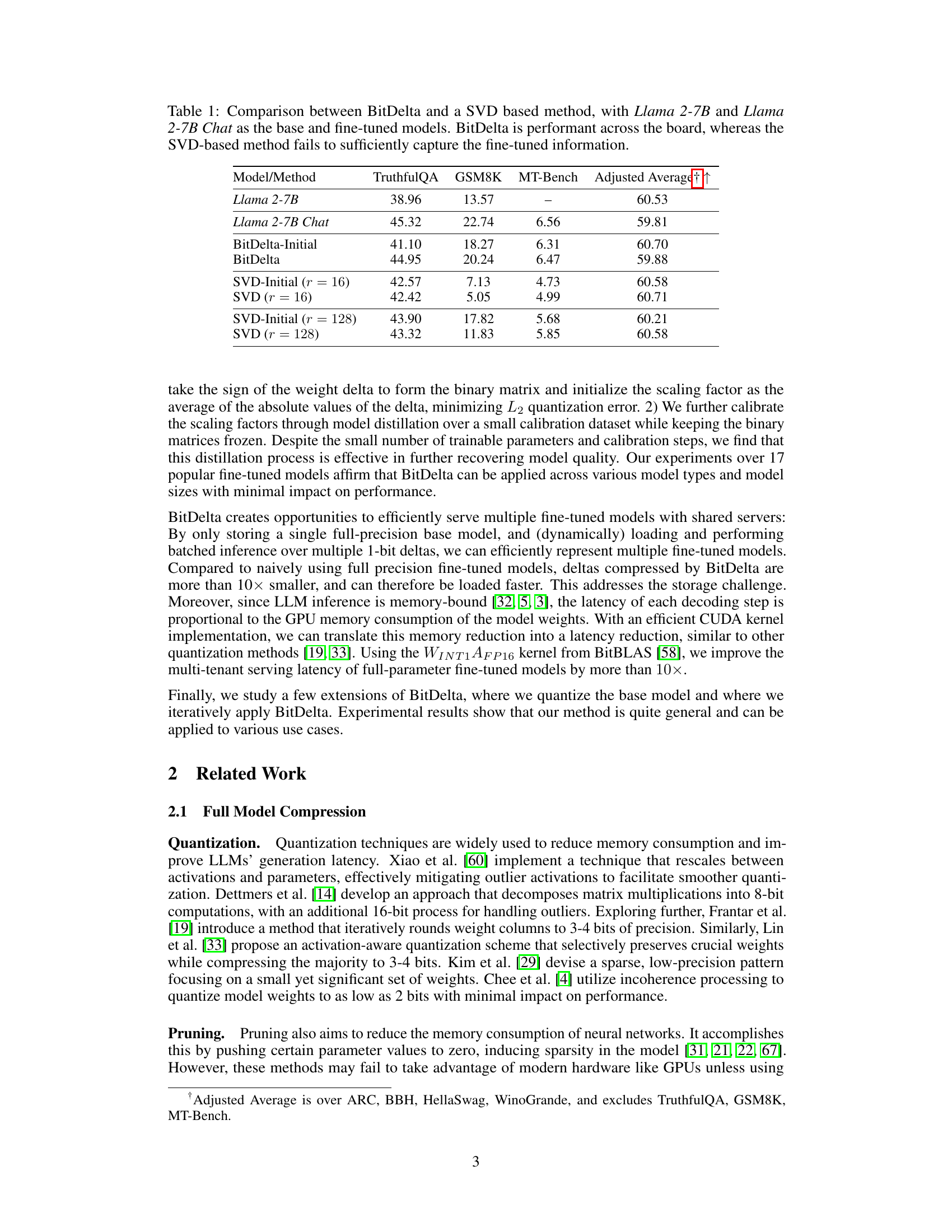
This table compares the performance of BitDelta against a Singular Value Decomposition (SVD)-based method for capturing the weight delta between a base Llama 2-7B model and its fine-tuned counterpart (Llama 2-7B Chat). The comparison is done across several evaluation metrics (TruthfulQA, GSM8K, MT-Bench, and an adjusted average). The results show that BitDelta achieves consistently good performance across all metrics, while the SVD method, even with higher dimensionality (r=128), fails to adequately capture the information added during fine-tuning.
In-depth insights#
BitDelta: 1-bit Fine-tune#
BitDelta proposes a novel approach to significantly reduce the memory footprint and latency of fine-tuned large language models (LLMs). The core idea revolves around quantizing the weight delta—the difference between a pre-trained base model and its fine-tuned counterpart—down to a single bit. This is achieved by representing the delta with a binary matrix and a scaling factor, which is then further refined through a distillation process. The method’s efficacy is demonstrated across various LLMs and tasks, showing minimal performance degradation despite the extreme compression. This 1-bit quantization is remarkably effective, leading to more than a 10x reduction in memory requirements and latency, especially beneficial in multi-tenant serving scenarios. BitDelta’s simplicity and effectiveness highlight the potential for significant cost savings and performance improvements in LLM deployment and inference, while also presenting interesting insights into the compressibility of fine-tuning itself and the redundancy in model weights.
Delta Compression#
Delta compression, in the context of large language models (LLMs), focuses on efficiently storing and serving fine-tuned models. Instead of saving each fine-tuned model as a complete entity, delta compression identifies and stores only the differences (the ‘delta’) between a base pre-trained model and its fine-tuned counterpart. This significantly reduces storage space and memory requirements, especially crucial when dealing with numerous fine-tuned models for various tasks or users. The core idea is that fine-tuning typically introduces a relatively small amount of new information compared to the vast pre-trained model; hence, the delta is highly compressible. Effective delta compression techniques are vital for making multi-tenant serving of LLMs feasible and efficient, enabling cost-effective deployment and scaling of personalized language AI. Further research may explore advanced compression methods, such as quantization of the delta itself, to further minimize storage and enhance efficiency. The optimal balance between compression ratio and computational overhead for decoding is also a key area of investigation.
Multi-tenant Efficiency#
Multi-tenant efficiency in large language models (LLMs) focuses on optimizing resource utilization when serving multiple models concurrently. A key challenge is the substantial memory footprint of individual LLMs, especially when each user or application requires a uniquely fine-tuned version. Solutions like BitDelta address this by decomposing fine-tuned models into a high-precision base model and multiple low-precision deltas representing the modifications. BitDelta’s 1-bit quantization of these deltas dramatically reduces memory usage, allowing efficient serving of many models from a single, shared base model. This approach significantly improves both storage efficiency and inference latency, particularly in multi-tenant settings. The success of BitDelta highlights the inherent redundancy in fine-tuning and offers a practical path toward scaling LLM deployment for a wider range of users and applications. Future work should investigate further optimizations for different hardware architectures and explore the trade-offs between compression levels and performance on diverse downstream tasks.
Quantization Methods#
The effectiveness of various quantization methods for compressing Large Language Models (LLMs) is a crucial area of research. Post-training quantization (PTQ) techniques are particularly attractive because they avoid the computational cost of retraining. Different PTQ methods, such as uniform quantization, vector quantization, and learned quantization, offer trade-offs between compression rate and accuracy. Uniform quantization, while simple, may suffer from significant information loss. Vector quantization can achieve higher compression ratios but requires more complex algorithms. Learned quantization methods, often involving training a separate quantization model, could offer the best performance but may be computationally expensive. The choice of quantization method depends on the specific requirements of the application, considering the balance between model size reduction, speed improvements, and acceptable performance degradation. Furthermore, research into hybrid methods, combining different techniques to leverage their respective strengths, is a promising avenue for enhancing LLM compression and efficiency.
Future of LLMs#
The future of LLMs is incredibly promising, yet riddled with challenges. Advancements in model architecture will likely involve more efficient designs that reduce computational costs and memory footprint while improving performance. Techniques like parameter-efficient fine-tuning and quantization will play a crucial role in making LLMs more accessible and deployable. The integration of LLMs with other AI modalities, such as computer vision and robotics, will pave the way for more complex and intelligent systems capable of interacting with the real world. However, ethical considerations are paramount. Addressing biases, promoting fairness, and ensuring responsible use of LLMs must be a central focus as they become increasingly powerful and ubiquitous. Mitigating the risk of misuse, including the generation of misinformation and harmful content, will necessitate rigorous research and robust safeguards. The path forward requires careful collaboration between researchers, developers, policymakers, and the public to harness the transformative potential of LLMs while mitigating their inherent risks.
More visual insights#
More on figures
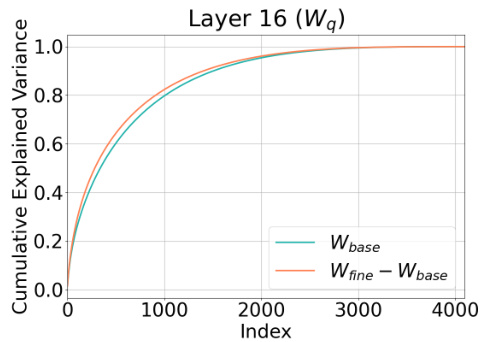
The figure shows the cumulative explained variance (CEV) plot for a 4096x4096 weight delta matrix between Llama 2-7B and Vicuna-7B v1.5. The plot illustrates that the weight delta from full parameter fine-tuning has a high rank, making low-rank approximation techniques challenging for effective compression. This observation supports the argument that fine-tuning adds relatively less new information, and emphasizes the potential for compressing the delta rather than the entire fine-tuned model.
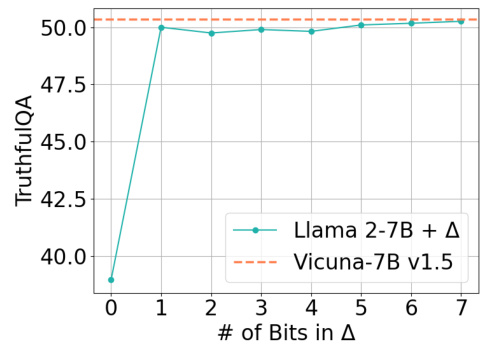
This figure shows the result of an ablation study on the number of bits used to represent the weight delta (Δ) in BitDelta. The x-axis represents the number of bits used for quantization of the delta, ranging from 0 bits (no quantization of delta) to 7 bits. The y-axis shows the TruthfulQA score, a metric measuring the model’s performance on a question answering task. The plot shows that as the number of bits increases, the performance of the Llama 2-7B model with the quantized delta improves, approaching the performance of the fully fine-tuned Vicuna-7B v1.5 model. This demonstrates that even with a low-bit representation of the delta, the model can achieve comparable performance to a fully fine-tuned model, highlighting the effectiveness of BitDelta’s quantization approach.
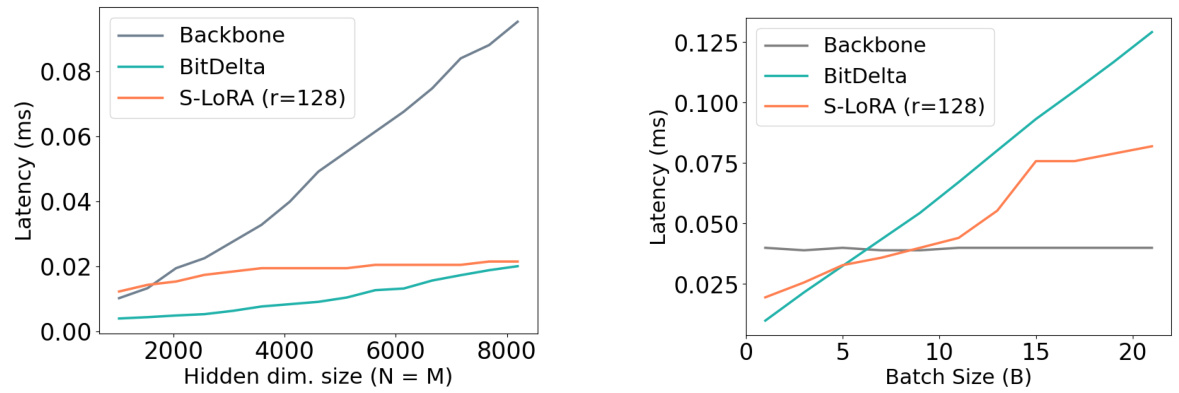
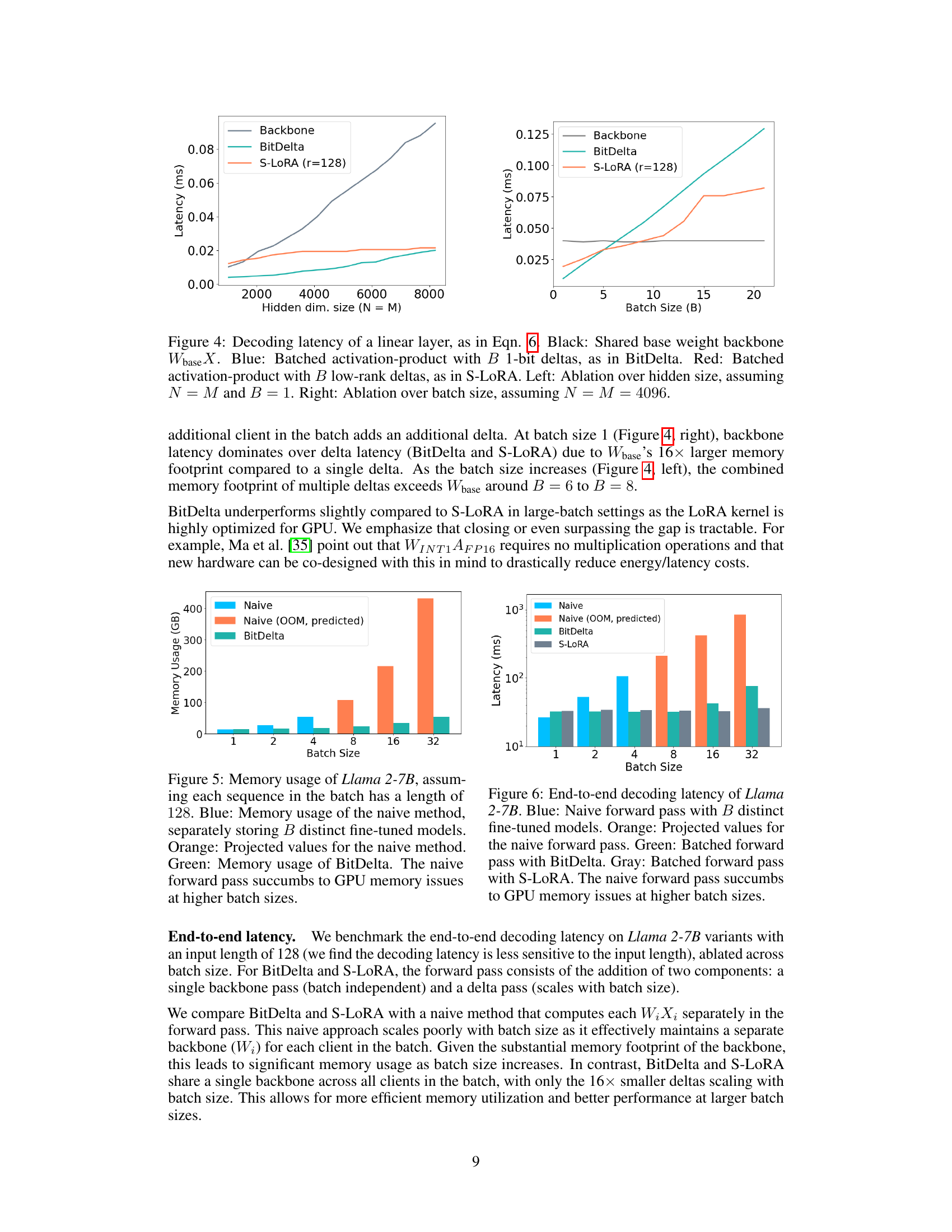
This figure shows the decoding latency of a linear layer, comparing BitDelta and S-LORA against a naive method which computes the base weight backbone and deltas separately. The left panel shows ablation over hidden size (N=M, B=1), and the right panel shows ablation over batch size (N=M=4096). BitDelta’s performance is shown to scale efficiently with both hidden size and batch size, demonstrating its efficiency compared to the naive method. S-LORA shows a similar trend, but with some overhead at lower batch sizes.
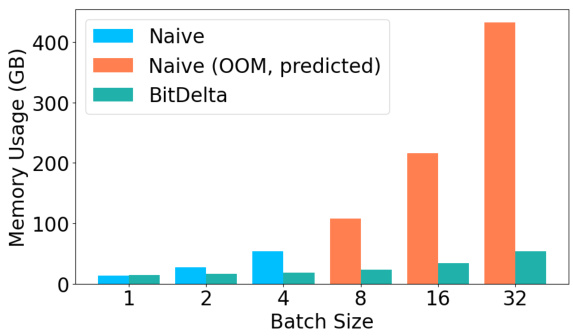
This figure compares the GPU memory usage of three different approaches for serving multiple fine-tuned models with increasing batch size. The naive approach loads each model separately, quickly exceeding the GPU’s capacity (OOM). BitDelta significantly reduces memory usage by employing a single base model and multiple compressed 1-bit deltas. The figure illustrates BitDelta’s efficiency in handling large batch sizes where the naive approach fails due to memory limitations.
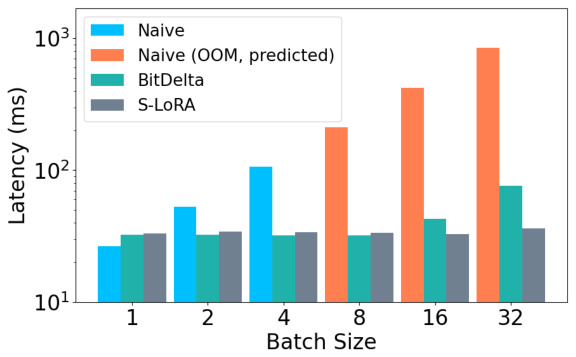
The figure shows the end-to-end decoding latency of Llama 2-7B models under different methods (naive, BitDelta, and S-LoRA) and various batch sizes. The naive approach, which processes each fine-tuned model separately, experiences significant latency increases and runs out of GPU memory at higher batch sizes. In contrast, BitDelta and S-LoRA, which share a common base model and process multiple deltas in batches, show significantly lower and more scalable latency.
More on tables
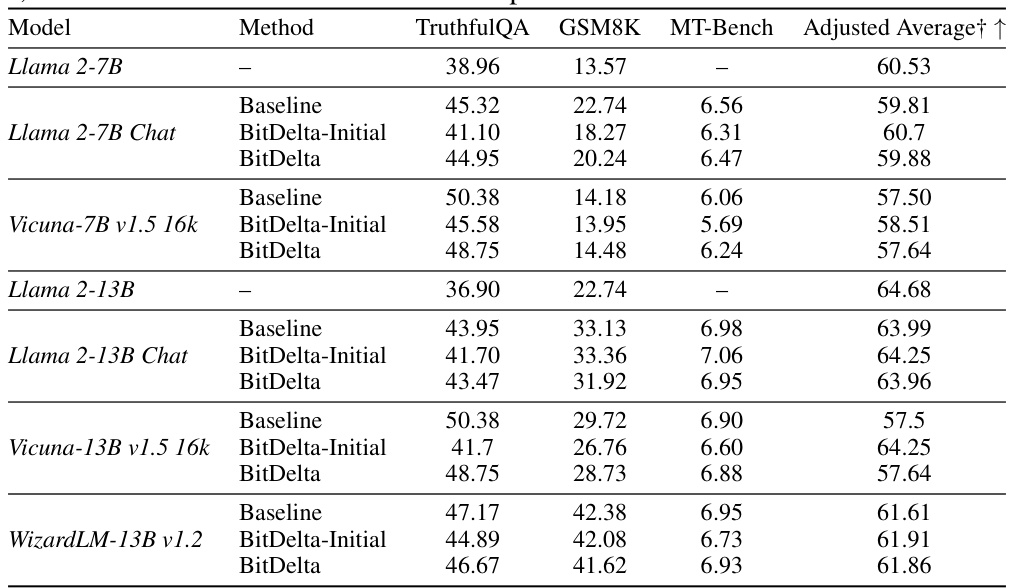
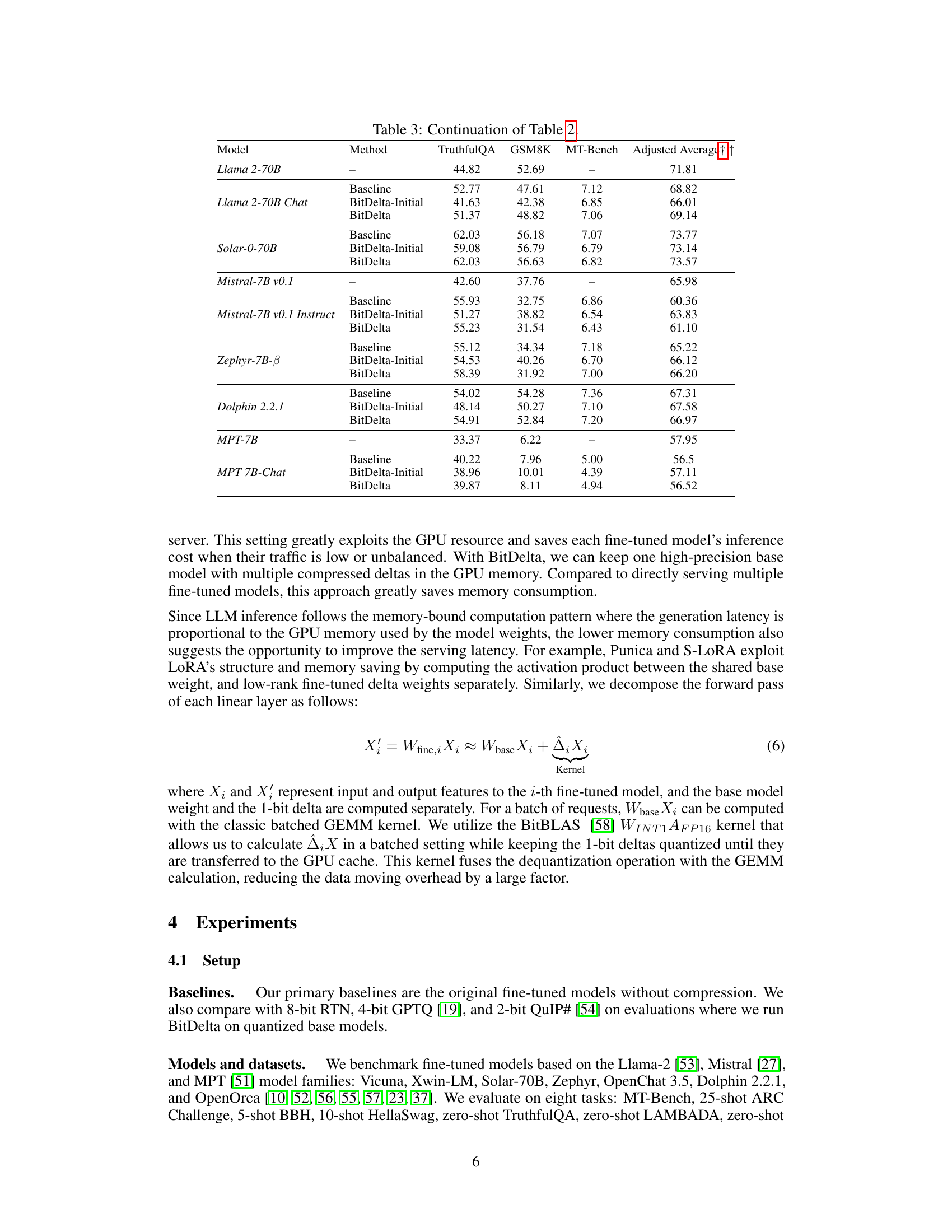
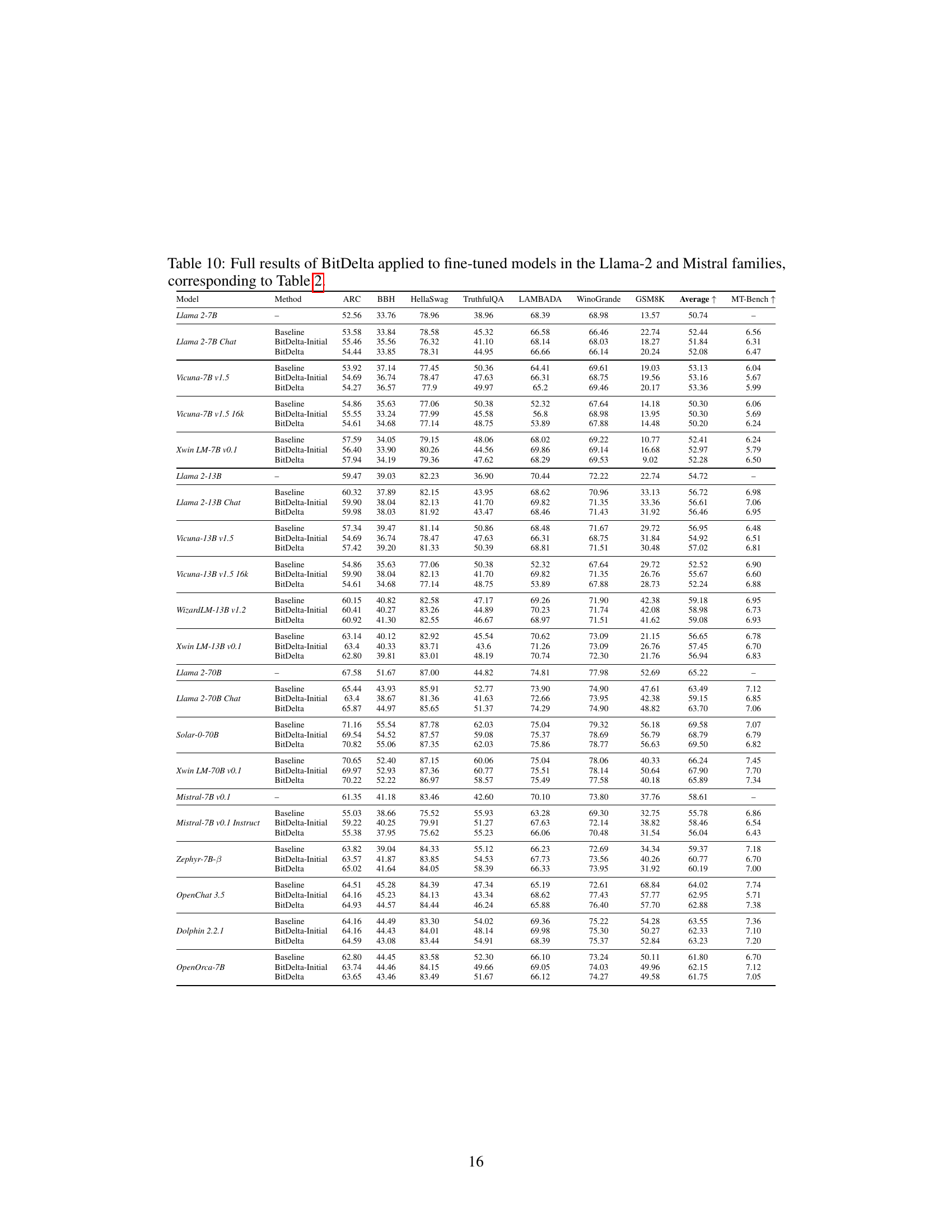
This table presents the results of BitDelta applied to various Llama-2 and Mistral models ranging from 7B to 70B parameters. It demonstrates BitDelta’s performance across different fine-tuning methods (SFT, RLHF, RoPE scaling) and model sizes, showcasing its effectiveness in preserving performance after 1-bit quantization of the fine-tuning delta. The results show that scale distillation improves the scores on TruthfulQA, GSM8K, and MT-Bench, demonstrating that BitDelta maintains performance comparable to the baseline fine-tuned models.
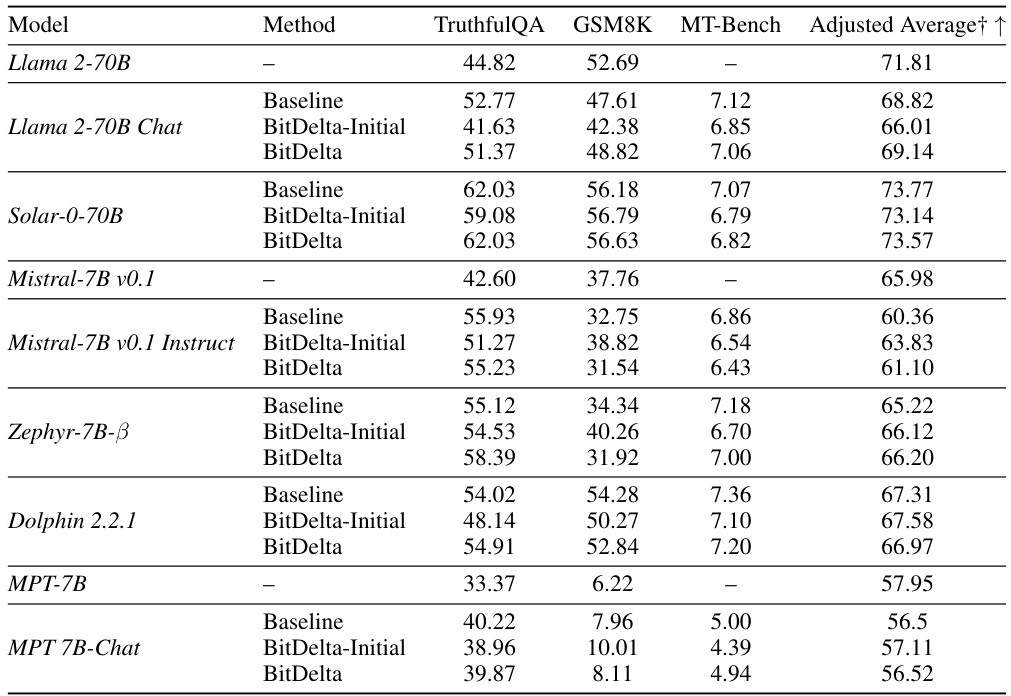
This table presents the results of BitDelta’s performance across various model families (Llama-2 and Mistral), model sizes (7B to 70B parameters), and types of fine-tuning (SFT, RLHF, RoPE scaling). It demonstrates BitDelta’s effectiveness and the impact of scale distillation in improving model performance, showing minimal performance degradation compared to baseline fine-tuned models.

This table compares the performance of BitDelta and BitDelta-Initial on a concise advertisement generation task from the MT-Bench benchmark using the Zephyr-7B-B model. It demonstrates that the addition of scale distillation in BitDelta significantly improves the model’s ability to follow instructions, generating more concise, catchy, and appropriate advertisements compared to BitDelta-Initial.
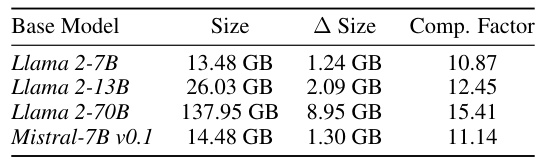
This table presents the compression factors achieved by BitDelta for several base language models. It shows the original size of the model, the size of the delta after applying BitDelta’s 1-bit quantization, and the resulting compression ratio. The compression is substantial, exceeding a factor of 10 in all cases. The table also notes that further compression could be achieved by applying the method to embedding and LM head layers; however, this was not pursued in the study due to variations in tokenizer vocabulary sizes across different models.
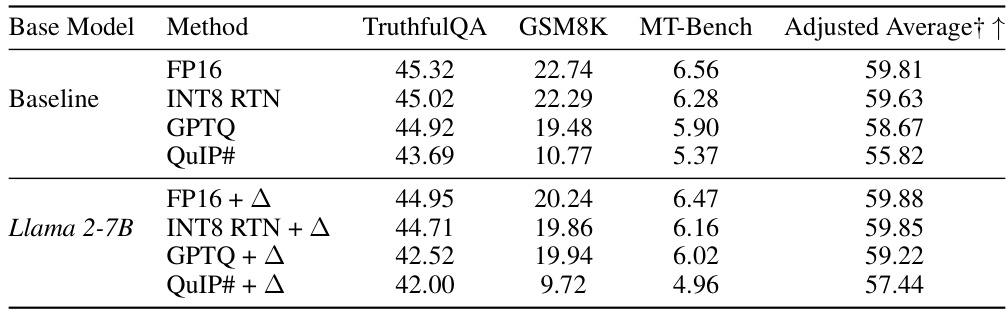
This table demonstrates the robustness of BitDelta even when the base model is quantized using different methods (FP16, INT8 RTN, GPTQ, QuIP#). It shows that applying BitDelta to a quantized base model maintains performance, indicating the effectiveness of BitDelta’s approach across various quantization techniques. The results are presented in terms of TruthfulQA, GSM8K, MT-Bench scores, and an adjusted average. The ‘+’ symbol indicates the addition of BitDelta to the base model quantization method.

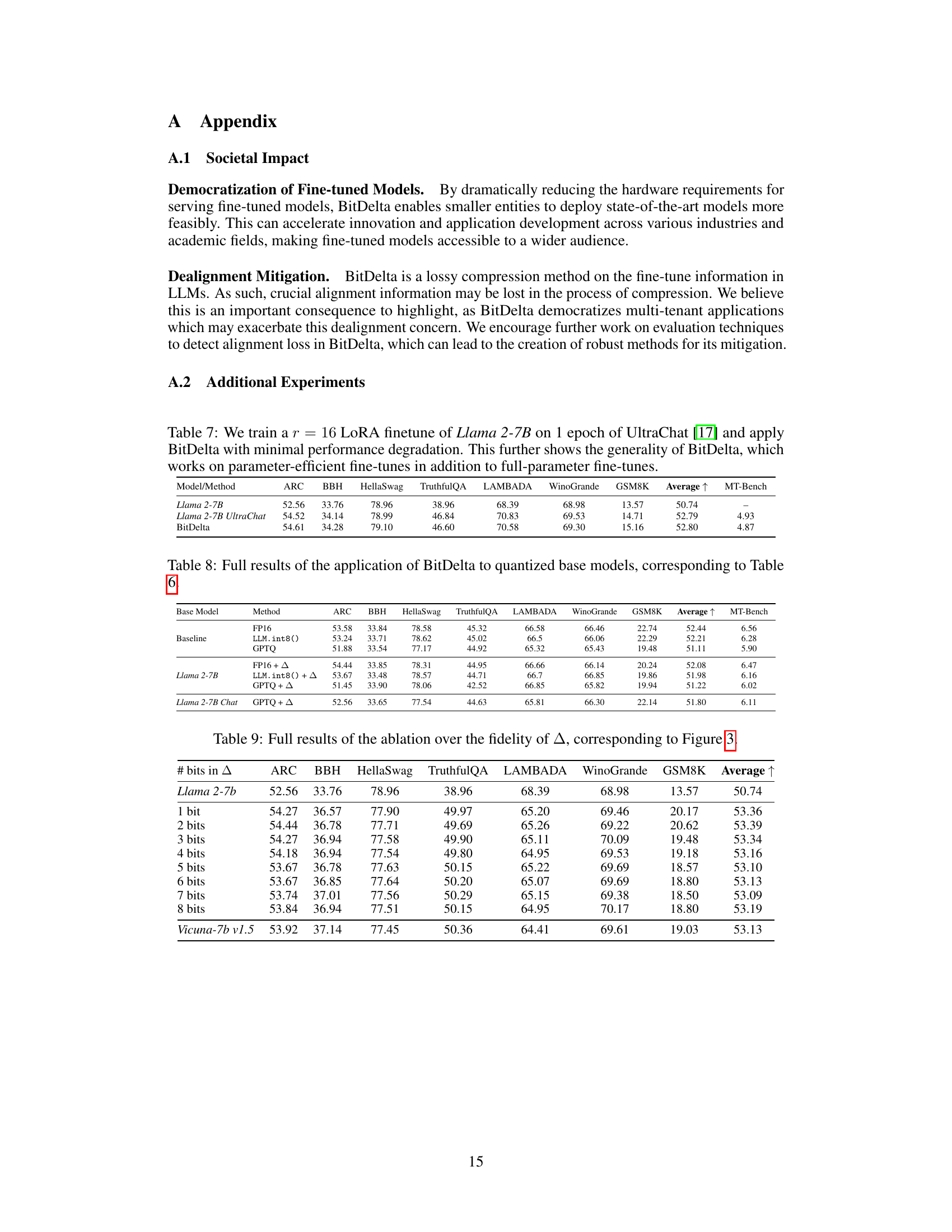
This table presents the results of applying BitDelta to a Llama 2-7B model fine-tuned using LoRA on the UltraChat dataset. The table shows that BitDelta maintains performance comparable to the original fine-tuned model, indicating its effectiveness even with parameter-efficient fine-tuning methods. It highlights BitDelta’s broad applicability across different fine-tuning techniques.

This table presents the results of applying BitDelta to Llama 2-7B Chat, using different quantization methods for the base model (Llama 2-7B). It demonstrates the robustness of BitDelta across various quantization levels (FP16, INT8 RTN, GPTQ, QuIP#). The table shows that BitDelta maintains its performance even when the base model is quantized, highlighting its effectiveness and adaptability to different quantization schemes.

This table presents a detailed breakdown of the results from an ablation study on the fidelity of the delta (Δ) in the BitDelta method. It shows the performance across various metrics (ARC, BBH, HellaSwag, TruthfulQA, LAMBADA, WinoGrande, GSM8K, and Average) as the number of bits used to represent the delta is varied from 1 to 8 bits. The results for Llama 2-7b and Vicuna-7b v1.5 models are shown separately, allowing for a comparison of model performance under different quantization levels.
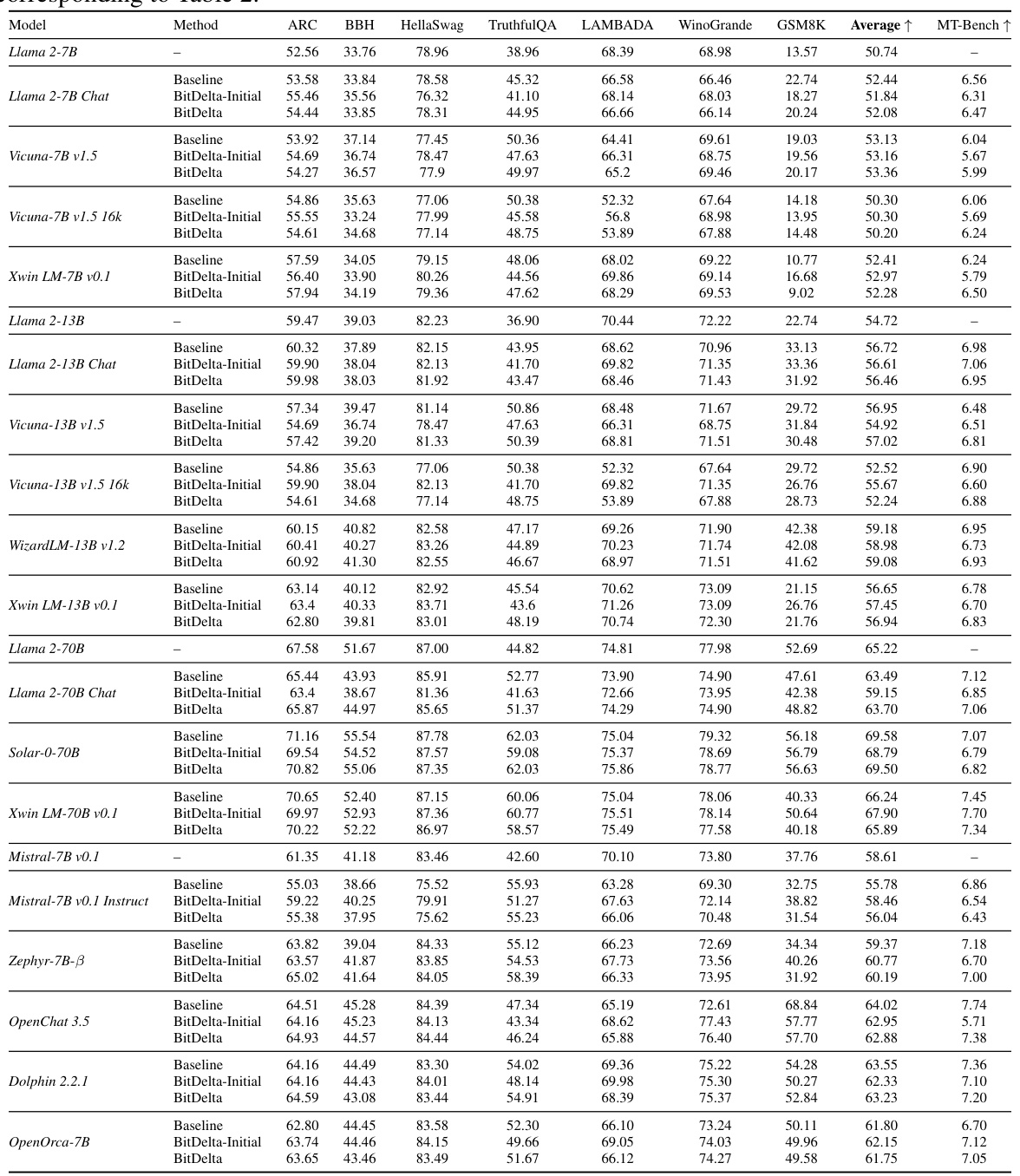
This table presents the results of BitDelta applied to various Llama-2 and Mistral models ranging from 7B to 70B parameters. It demonstrates BitDelta’s performance across different fine-tuning methods (SFT, RLHF, RoPE scaling) and model sizes, showing minimal performance degradation compared to the baseline models. The results highlight the effectiveness of scale distillation in improving the accuracy scores on TruthfulQA, GSM8K, and MT-Bench.
Full paper#