↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
On-road object importance estimation is crucial for enhancing the safety and intelligence of driving systems. However, research in this area has been limited by the scarcity of large-scale, publicly available datasets and the inadequacy of existing models, which often only consider limited factors. This has led to suboptimal performance in handling complex and dynamic traffic scenarios.
This research addresses these limitations by introducing a new large-scale dataset called TOI, which provides a substantial increase in the volume of data compared to existing datasets. Moreover, the paper proposes a novel model that integrates multi-fold top-down guidance (driver intention, semantic context, traffic rules) with bottom-up visual features. This innovative approach allows the model to more effectively handle the complexity and dynamism of real-world traffic scenes. Extensive experiments demonstrate that this new model outperforms state-of-the-art methods by a significant margin, achieving a 23.1% improvement in average precision.
Key Takeaways#
Why does it matter?#
This paper significantly advances on-road object importance estimation by introducing a new large-scale dataset (TOI) and a novel model integrating multi-fold top-down guidance, achieving substantial performance improvements over existing methods. It addresses the critical lack of data and the limitations of previous simpler models, paving the way for safer and more intelligent driving systems.
Visual Insights#

The figure illustrates three crucial factors that influence human drivers’ estimation of on-road object importance. (a) Driver Intention: Shows that objects which risk colliding with the ego-car’s intended driving path or are located on this path, are considered more important. (b) Semantic Context: Highlights that objects in drivable areas are generally deemed more important than those outside. (c) Traffic Rule: Demonstrates that the presence of a lane marking between the ego-car and an oncoming vehicle can influence importance, with an oncoming vehicle deemed less important if a lane marking separates them. The image uses red boxes to indicate important objects and green boxes for less important ones.
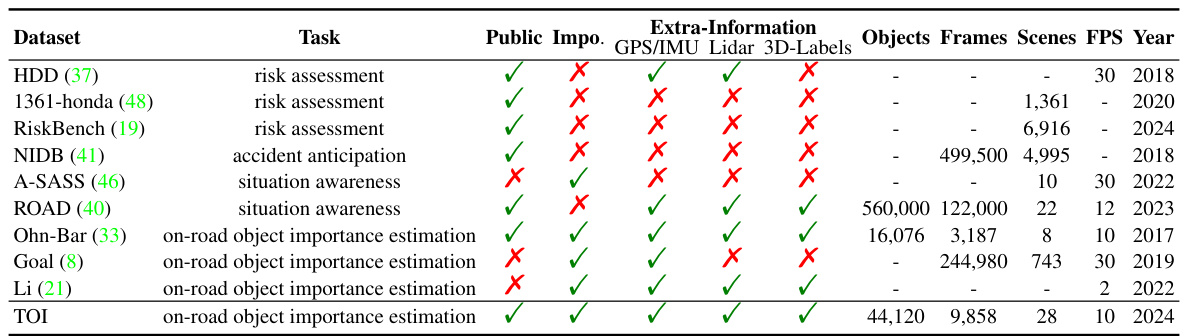
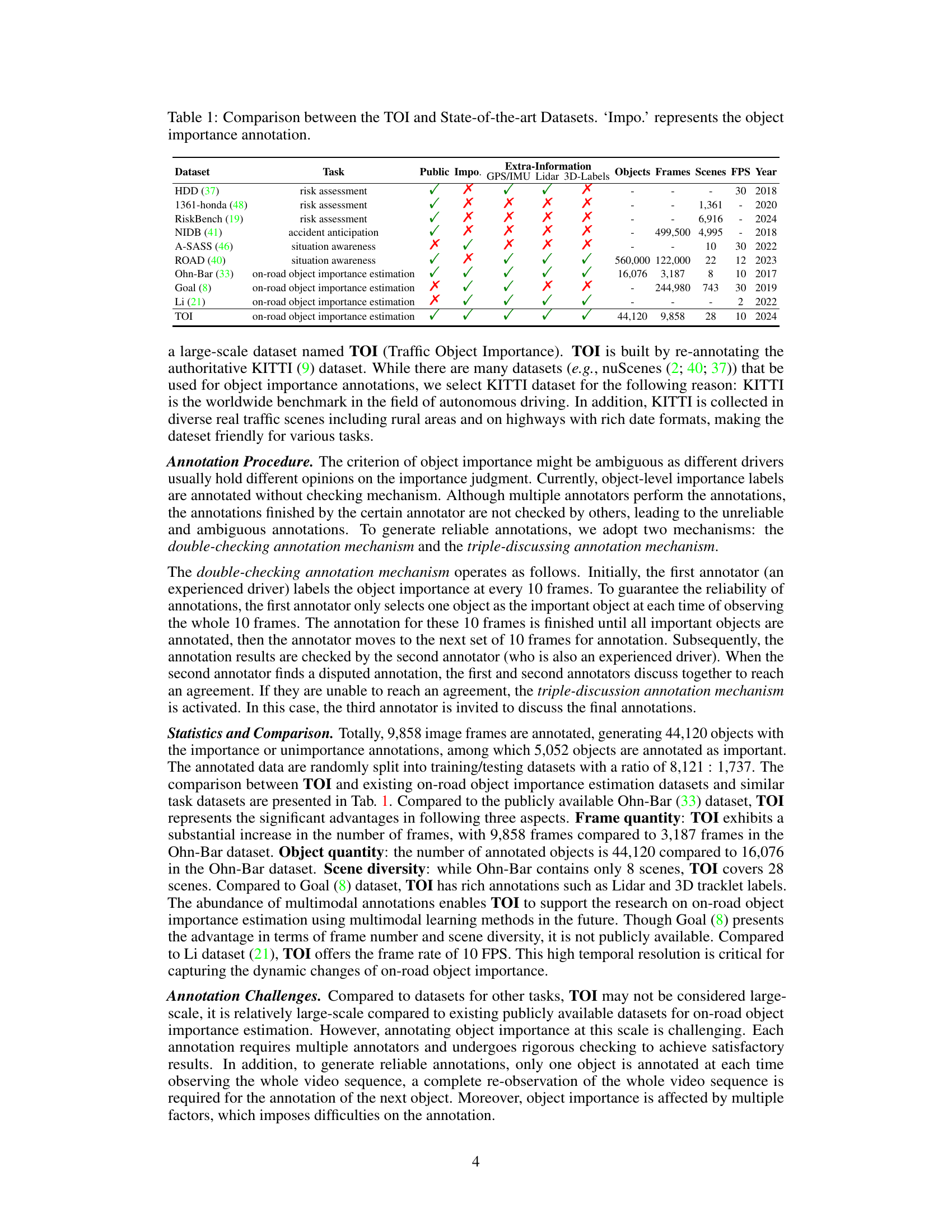
This table compares the TOI dataset with other state-of-the-art datasets used for on-road object importance estimation and related tasks. It shows the number of objects, frames, scenes, frames per second (FPS), and year of release for each dataset. It also indicates whether each dataset provides object importance annotations, GPS/IMU data, LiDAR data, and 3D labels. This allows for a clear comparison of the size, scope, and features of various datasets in relation to the newly proposed TOI dataset.
In-depth insights#
Multi-fold Guidance#
The concept of “Multi-fold Guidance” in the context of a research paper likely refers to a system using multiple, independent sources of information to guide a process or model. This approach contrasts with single-source methods, offering several advantages. Firstly, combining diverse information streams (e.g., driver intention, semantic context, traffic rules) improves robustness and reduces reliance on any single unreliable source. Secondly, it allows for a more holistic understanding of the task, integrating high-level reasoning (top-down guidance) with low-level feature extraction (bottom-up processing). Thirdly, this approach mimics human cognitive processes, where multiple factors simultaneously inform decision making. However, the complexity increases; careful integration techniques are needed to avoid conflicts and ensure that the guidance signals complement rather than contradict one another. Effective fusion strategies are critical for optimal performance, including appropriate weighting schemes and attention mechanisms to prioritize reliable sources. Finally, evaluating the contribution of each guidance source is essential, requiring rigorous ablation studies to show the individual and combined effects on the overall system accuracy.
TOI Dataset#
The creation of the TOI (Traffic Object Importance) dataset represents a significant contribution to the field of on-road object importance estimation. Its large scale, encompassing 9,858 frames, 28 scenes, and 44,120 annotations, directly addresses the scarcity of publicly available data that has previously hindered research. The dataset’s rigorous annotation process, involving double-checking and triple-discussion mechanisms, ensures high-quality and reliable labels. Comparison with existing datasets highlights TOI’s superiority in terms of scale and annotation detail, making it a valuable resource for training and evaluating sophisticated models. The dataset’s design, utilizing the KITTI dataset as a foundation and incorporating varied traffic scenarios, promises to advance research towards more robust and accurate importance estimation models capable of handling dynamic and complex driving situations.
Model Architecture#
The model architecture section of a research paper is crucial for understanding the proposed method. A well-written description will detail the individual components, their interconnections, and the overall flow of data. Key aspects to look for include the input and output layers, as well as the type and configuration of any intermediate layers (e.g., convolutional, recurrent, fully connected). Details on activation functions, normalization techniques (batch norm, layer norm), and any other regularization strategies should be thoroughly explained. A diagram is almost always essential for visualizing the architecture’s structure, allowing readers to quickly grasp the model’s complexity and design choices. The rationale behind specific design decisions should be clearly articulated, connecting architectural choices to the problem being addressed and potential advantages over alternative approaches. Finally, the description should be precise and unambiguous, using formal notation where appropriate to ensure clarity and prevent misinterpretations.
Ablation Studies#
Ablation studies systematically remove components of a model to assess their individual contributions. In the context of a research paper, this section would detail experiments where aspects like multi-fold top-down guidance (driver intention, semantic context, traffic rules), bottom-up feature extraction, or specific modules (DISG, TRG, OFE) are removed. By comparing performance against a complete model, the study would reveal the importance of each component. A strong ablation study shows a clear performance drop when key components are removed, highlighting their necessity and effectiveness. The results would ideally be presented with quantitative metrics (like AP, F1-score) and insightful visualizations to understand the effect of each component on the model’s overall performance and robustness in handling diverse traffic scenarios. Well-designed ablation studies strengthen the paper’s claims by providing strong evidence for design choices and improving the reader’s understanding of the model’s inner workings.
Future Directions#
Future research could explore several promising avenues. Expanding the dataset to encompass a wider variety of geographic locations, weather conditions, and traffic densities would enhance model robustness and generalizability. Incorporating additional modalities, such as lidar data or driver physiological signals (e.g., heart rate, eye tracking), could provide richer contextual information for improved accuracy. Developing more sophisticated attention mechanisms that can dynamically weigh the importance of different features and relationships between objects would further refine the model’s ability to capture complex traffic scenarios. Finally, the development of more effective methods for handling edge cases and ambiguous situations (e.g., occluded objects, unusual driver behavior) is critical for the real-world deployment of reliable object importance estimation systems. Research into explainable AI techniques could offer valuable insights into the model’s decision-making process, leading to improved trust and interpretability.
More visual insights#
More on figures

This figure presents a detailed overview of the proposed model architecture for multi-fold top-down guidance aware object importance estimation. It illustrates the flow of information processing through various modules, starting from video input and ego-car velocity information. The model integrates bottom-up feature extraction with multiple top-down guidance factors such as driver intention, semantic context, and traffic rules. Key modules shown are: Object Feature Extraction, Driver Intention and Semantics Guidance, Traffic Rule Guidance, and Object Importance Estimation. The diagram showcases the interplay between bottom-up and top-down pathways in determining object importance.

This figure shows three crucial factors considered by human drivers when estimating on-road object importance. These are driver intention (a), semantic context (b), and traffic rules (c). (a) shows that objects that are close to the driver’s intended path or that pose a collision risk are considered more important. (b) illustrates how the context of the entire scene influences the importance of objects - objects in drivable areas are considered more significant than those in undrivable areas. Finally (c) demonstrates the role of traffic rules: the presence of lane markings between the ego-vehicle and an oncoming vehicle, for example, decreases the perceived importance of the oncoming vehicle.

This figure presents a qualitative comparison of the proposed model’s performance against three baseline models (Goal, Ohn-Bar, and Zhang) in identifying important on-road objects. Red boxes highlight objects deemed important by the model, while green boxes indicate unimportant objects. The ground truth (GT) is also shown for comparison. Four different driving scenarios are visualized to showcase the models’ ability to handle various conditions.

This figure visualizes the output of object-lane interaction weighting (pc in equation 13). Objects with blue masks are penalized (object-lane interaction is disabled, pc=a), while objects with yellow masks are not penalized (object-lane interaction is enabled, pc=1). The examples show how the weighting mechanism considers the relevance of lane markings to object importance. Static cars on roadsides are penalized because they have weak interaction with lanes. In contrast, oncoming cars and the car in the current lane are not penalized because they show strong interaction with lanes. Note that the yellow mask does not indicate object importance; instead it indicates whether object-lane interaction is enabled.
More on tables
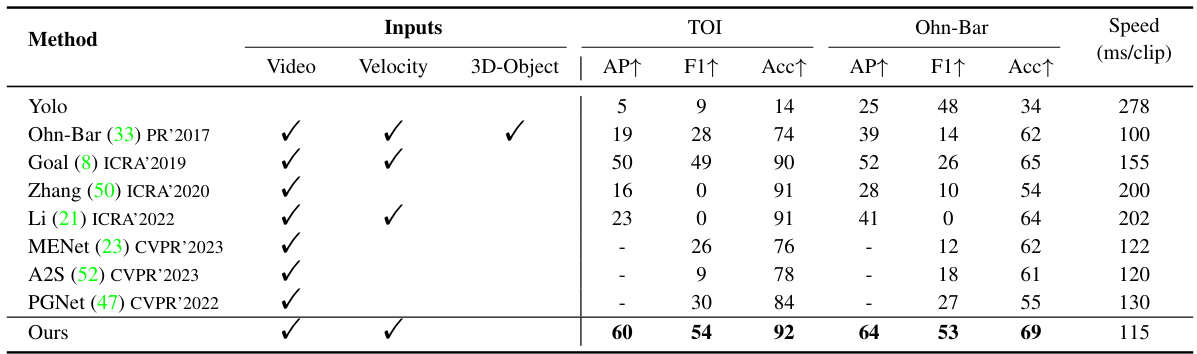
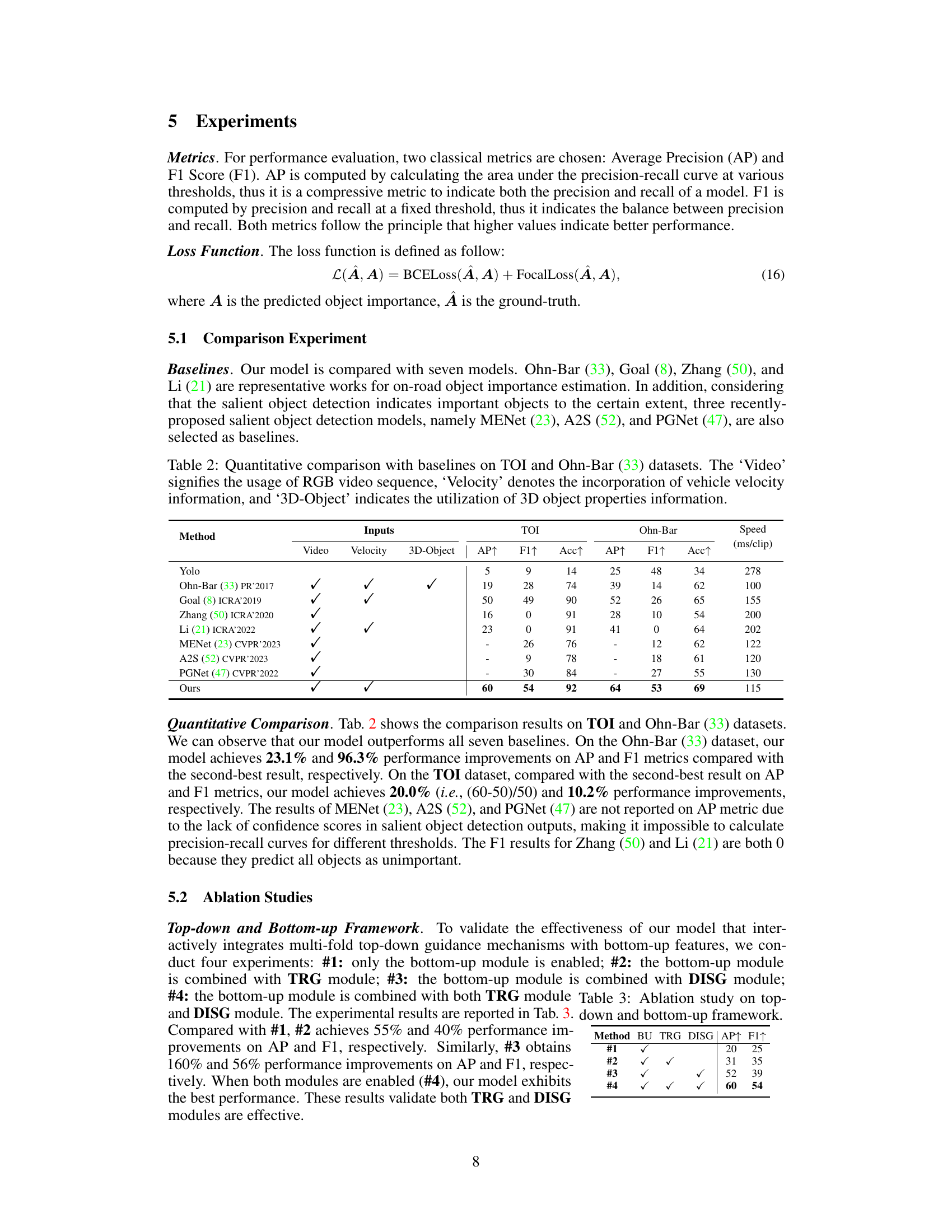
This table presents a quantitative comparison of the proposed model’s performance against seven baseline methods on two datasets: the newly introduced TOI dataset and the existing Ohn-Bar dataset. The performance is measured using Average Precision (AP), F1-score, and Accuracy (Acc). The table also indicates which input modalities (RGB video, vehicle velocity, and 3D object properties) were used by each method.
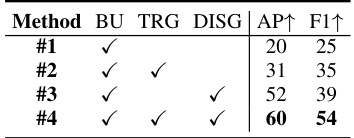
This table presents the ablation study results of the proposed model, comparing different combinations of the bottom-up module, TRG (Traffic Rule Guidance) module, and DISG (Driver Intention and Semantics Guidance) module. The results show the improvement in AP (Average Precision) and F1 scores as more modules are added, highlighting the effectiveness of the proposed interactive bottom-up and top-down fusion framework.
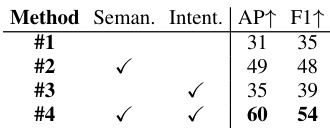
This ablation study analyzes the impact of the semantic context guidance and driver intention guidance on the model’s performance. It compares four variations of the model: (1) without either guidance, (2) with only semantic guidance, (3) with only intention guidance, and (4) with both. The results demonstrate the significant contribution of both guidance features, with the best performance achieved by the model with both semantic and intention guidance.
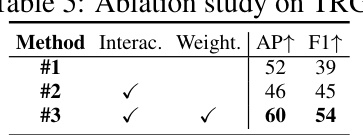
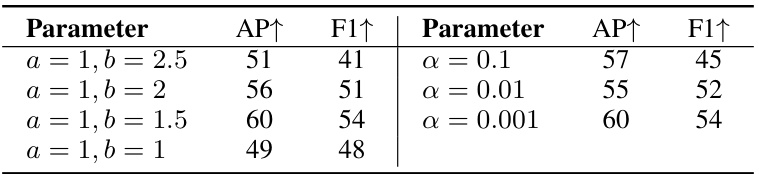
This table presents the ablation study results for the Traffic Rule Guidance (TRG) module. It compares the performance of the model with different combinations of object-lane interaction and object-lane interaction weighting. The results show that including both object-lane interaction and object-lane interaction weighting significantly improves the performance of the model.
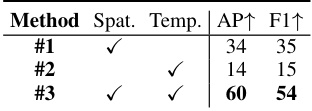
This ablation study investigates the impact of using only spatial features, only temporal features, or both spatial and temporal features for object importance estimation. The results demonstrate that using both spatial and temporal features significantly improves the performance of the model compared to using only one type of feature.
This table presents a quantitative comparison of the proposed model’s performance against seven baseline models on two datasets: the newly introduced TOI dataset and the publicly available Ohn-Bar dataset. The comparison uses three metrics: Average Precision (AP), F1-score (F1), and Accuracy (Acc). It also indicates whether each method uses RGB video sequences, vehicle velocity information, and 3D object properties in its input.

This table compares the TOI dataset with other state-of-the-art datasets used for on-road object importance estimation and related tasks. It shows the number of objects, frames, scenes, frames per second (FPS), and year of release for each dataset. It also indicates whether each dataset provides object importance annotations, GPS/IMU, lidar data, and 3D labels. This allows for a direct comparison of the size and annotation richness of the TOI dataset relative to existing resources.
Full paper#