↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Many existing collaborative perception systems assume ideal conditions, where all agents’ multi-view cameras are constantly available. However, this is unrealistic since cameras may be noisy, obscured, or even fail during collaboration. This paper addresses this crucial limitation and introduces a new problem called “Robust Camera-Insensitivity Collaborative Perception”, focusing on how to maintain high collaborative perception performance while minimizing calibration costs when cameras fail. The paper proposes a novel method called RCDN to address this problem.
RCDN uses a two-stage approach: 1) a time-invariant static background field is built using a fast hash grid, providing a stable representation of the scene; 2) a time-varying dynamic field is then constructed to model foreground motions. This dynamic field recovers missing information from failed cameras, utilizing motion vectors and spatio-temporal regularization. The evaluation using a newly created, manually labeled dataset shows that RCDN significantly improves the robustness of various baseline collaborative perception methods under extreme camera-insensitivity settings. The key contribution is the RCDN method itself and the creation of a new large-scale dataset, OPV2V-N, which includes manually labeled data under various camera failure conditions.
Key Takeaways#
Why does it matter?#
This paper is important because it tackles a critical issue in collaborative perception: robustness to camera failures. It introduces a novel method, RCDN, that significantly improves performance under challenging conditions. This is highly relevant to the development of reliable autonomous systems, particularly in scenarios where sensor malfunctions are common. RCDN’s innovative approach opens up new avenues for research in dynamic feature-based 3D neural modeling and camera-insensitive collaborative perception.
Visual Insights#
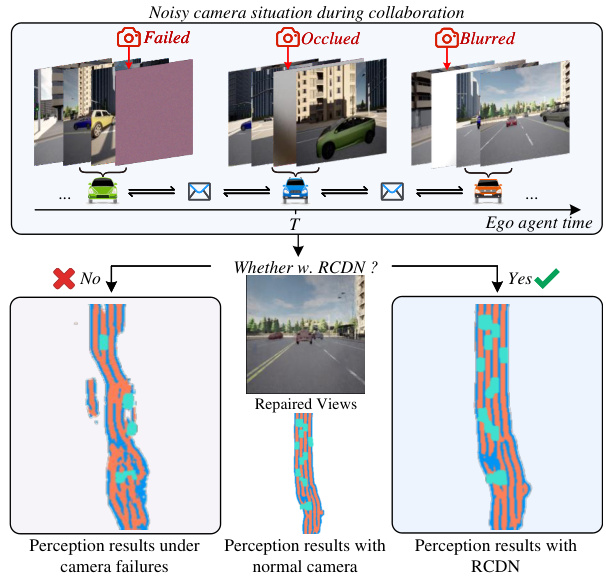
This figure illustrates how RCDN handles noisy camera situations during multi-agent collaboration. It shows three scenarios: a camera failure, occlusion, and blurring. The left side depicts the poor perception results without RCDN in these scenarios, while the right shows how RCDN improves the perception using information from other agents’ views to reconstruct the complete scene, resulting in a more accurate segmentation of drivable areas, lanes, and dynamic vehicles.
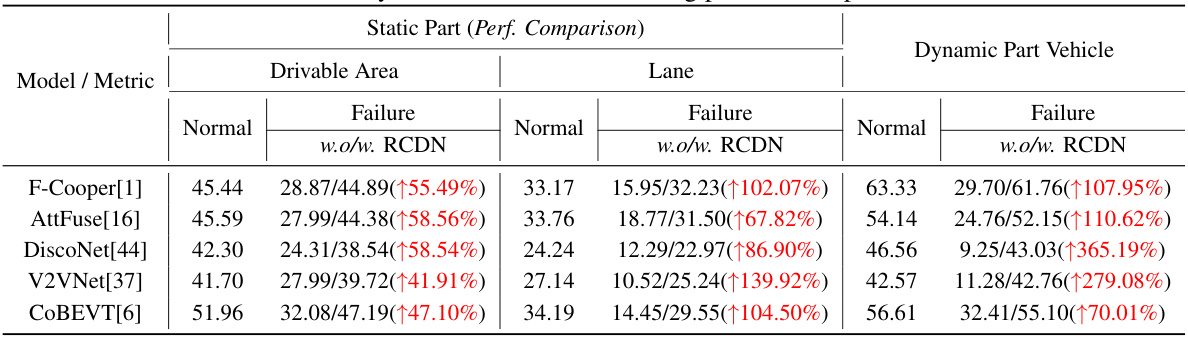
This table compares the performance of various baseline methods (F-Cooper, AttFuse, DiscoNet, V2VNet, COBEVT) with and without the proposed RCDN in terms of Intersection over Union (IoU) for map-view segmentation. The experiment simulates a scenario where one camera randomly fails during the testing phase. The table breaks down the results for three classes: drivable area, lane, and dynamic vehicle. The numbers in parentheses show the percentage increase of IoU achieved by adding RCDN to the baseline method.
In-depth insights#
Robust Perception#
Robust perception in the context of multi-agent systems addresses the challenge of reliable environmental understanding despite noisy, incomplete, or unreliable sensor data from multiple agents. Sensor failures, occlusions, and adversarial conditions are significant hurdles. A robust approach must integrate data from diverse sources, handle missing information effectively (e.g., through imputation or prediction), and incorporate uncertainty quantification. This might involve advanced filtering techniques, sensor fusion methods (such as Kalman filters or particle filters), and sophisticated data association algorithms. Redundancy and diversity in sensing modalities can contribute to robustness. Furthermore, robust perception solutions require resilience to outliers, adversarial attacks, and even partial system failures. The development of robust perception often involves a tradeoff between computational complexity, accuracy, and real-time constraints, especially in dynamic environments.
3D Neural Modeling#
3D neural modeling, in the context of collaborative perception, offers a powerful approach to integrate and reconcile data from multiple agents’ viewpoints. The core idea is to leverage neural networks to create a unified 3D representation of the environment, enabling the system to overcome challenges like occlusions and sensor failures. By employing techniques like neural rendering, the model can synthesize views that compensate for missing or corrupted sensor input, effectively enhancing the robustness of the overall perception. Dynamic feature-based methods are particularly valuable as they can model changes in the environment over time, capturing motion and object dynamics. This capability is crucial for real-world applications where conditions are constantly changing. The use of geometry-based representations such as BEV (Bird’s Eye View) features provides a stable background for integrating these dynamic elements and helps to handle inconsistencies across different camera perspectives and timestamps. In essence, 3D neural modeling provides a unified and robust framework for collaborative perception by synthesizing consistent 3D representations of the shared environment, making it far more resilient and reliable in real-world applications with noisy or unreliable sensors.
OPV2V-N Dataset#
The creation of the OPV2V-N dataset is a significant contribution to the field of collaborative perception. Addressing the lack of comprehensive datasets that account for real-world sensor imperfections, OPV2V-N simulates various camera noise scenarios, including blurring, occlusion, and even complete camera failure. This meticulous labeling, incorporating timestamps and camera IDs, allows researchers to train and evaluate models robust to these common challenges. The dataset’s focus on camera insensitivity is particularly valuable, enabling more realistic and practical advancements in collaborative perception systems. The manual labeling adds significant rigor to the dataset, enhancing its reliability and utility for model validation. By explicitly modeling failure scenarios, OPV2V-N is expected to accelerate progress in developing more robust and dependable autonomous systems. Ultimately, the dataset’s thoroughness and realistic simulation of challenging conditions significantly enhance the potential of collaborative perception research.
RCDN Architecture#
The RCDN architecture is built around two key collaborative neural fields: a time-invariant static background field and a time-varying dynamic foreground field. The static field is established using a fast hash grid, efficiently representing the static background across multiple agents via a shared BEV feature space. This provides a robust foundation, especially when handling camera failures. The dynamic field builds upon this static base, modeling the motion of foreground objects using spatiotemporal features. This allows RCDN to compensate for missing or noisy data from individual agents by leveraging information from others. The combination of these two fields enables robust and accurate perception even in challenging conditions, creating a camera-insensitive collaborative system. The framework also incorporates modules for BEV feature generation, geometry BEV volume feature creation, and neural rendering for data reconstruction. This carefully designed architecture allows RCDN to effectively handle camera failures, resulting in improved robustness and reliable collaborative perception.
Future Works#
The paper’s ‘Future Works’ section would ideally delve into several promising avenues. Extending RCDN to handle more complex scenarios beyond the controlled settings of OPV2V-N is crucial. This includes exploring its robustness with significantly more noisy or unreliable sensor data, handling dynamic occlusions more effectively, and testing in diverse real-world environments. Improving the efficiency of RCDN for real-time applications is another key area for future research. The computational cost of both static and dynamic field modeling warrants investigation, particularly exploring optimizations like more efficient neural architectures or parallel processing techniques. Expanding the dataset is also essential; OPV2V-N, while valuable, could be greatly enhanced with more diverse scenarios, more agents, and longer sequences. A larger, more comprehensive dataset would bolster the generalizability of RCDN and enable a more rigorous evaluation of its performance and limits. Finally, exploring the potential of RCDN in other collaborative perception tasks such as object tracking, 3D scene reconstruction, and decision-making would showcase its wider applicability and impact.
More visual insights#
More on figures

This figure illustrates the overall architecture of the Robust Camera-Insensitivity collaborative perception system (RCDN). It shows the flow of data and processing steps, highlighting the key components: geometry BEV generation, collaborative static neural field, and collaborative dynamic neural field. The geometry BEV generation module first extracts features from multi-agent inputs. These features then feed into both the static and dynamic neural fields. The static field models the background, while the dynamic field focuses on foreground objects. Finally, the outputs of these fields are combined to generate the final aggregated BEV feature. The figure also visually represents the improved perception results achieved using RCDN (Success) compared to those without RCDN (Failed).

This figure compares the performance of different baseline methods with and without RCDN under various levels of random noisy camera failures (from 0 to 3 failed cameras). The results are shown for three different map segmentation tasks: drivable area, lane, and dynamic vehicle. It demonstrates that RCDN improves robustness across all baselines in the face of increasing camera failures.

The figure shows a comparison of the performance of the proposed RCDN with and without the time model. The left image shows the result without the time model, while the right image shows the result with the time model. The time model improves the quality of the reconstructed image by reducing the blurriness and noise. This demonstrates that the dynamic neural field is effective in handling the temporal consistency in the collaborative perception process.

This figure visualizes the performance of different baseline methods (AttFusion, F-Cooper, V2VNet, and COBEVT) with and without the proposed RCDN when one camera randomly fails. It shows the repaired views generated by RCDN, the original views with camera failure, the segmentation results without RCDN, and the results with RCDN. The origin segmentation map acts as ground truth. The comparison highlights how RCDN improves the segmentation results by recovering information lost due to camera failure.

This figure compares the training efficiency and performance (measured by PSNR) of two dynamic field modeling methods: an implicit MLP-based method and the explicit grid-based RCDN proposed in the paper. The RCDN method is shown to achieve significantly faster training (around 24 times faster) and higher PSNR, indicating improved efficiency and quality.

This figure visualizes the results of different baseline methods (CoBEVT and V2VNet) with and without the proposed RCDN (Robust Camera-Insensitivity collaborative perception) when there is one randomly failing camera. It shows the impact of RCDN on the accuracy of map segmentation. The left column shows the original (successful) view, the center column is the resulting perception with only one camera failure, and the right column shows the results after RCDN is applied. The color-coded boxes (orange, blue, teal) in the segmentation maps represent the drivable area, lanes, and dynamic vehicles, respectively. The visual comparison highlights RCDN’s ability to improve the robustness and accuracy of collaborative perception under camera failures.
More on tables
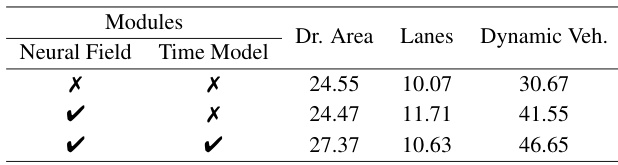
This ablation study analyzes the impact of different components of the RCDN model on the performance of drivable area, lane, and dynamic vehicle segmentation on the OPV2V-N dataset. It shows the results with and without different components, such as the neural field and time model, to assess their individual contributions.
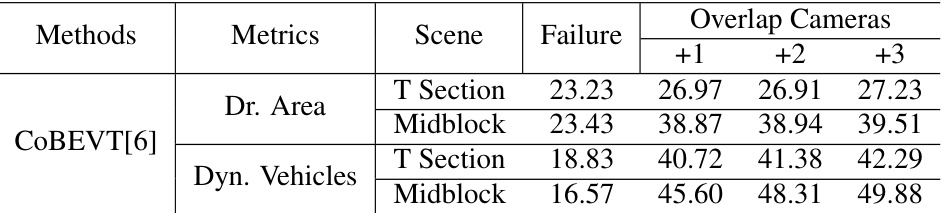
This table presents the performance of the CoBEVT method on the OPV2V-N dataset under different conditions of camera failures. It shows the Intersection over Union (IoU) for drivable area and dynamic vehicles for different scenarios (T Section and Midblock) and different numbers of additional overlapping cameras. The failure setting assumes one random noisy camera failure during testing.
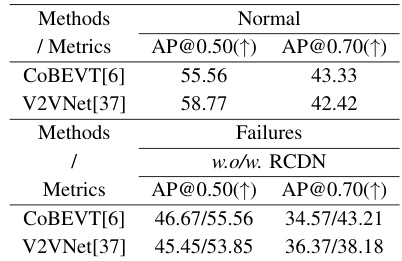
This table presents the detection performance comparison between CoBEVT and V2VNet baselines with and without RCDN on the OPV2V-N dataset. It evaluates the models under a scenario with one randomly failing camera during testing. The performance is measured using Average Precision (AP) at two Intersection over Union (IoU) thresholds: 0.50 and 0.70, showcasing the improvement offered by integrating RCDN.
Full paper#



















