↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Many multi-agent reinforcement learning (MARL) algorithms struggle in heterogeneous scenarios because they either share parameters, hindering specialization, or lack effective exploration strategies within a sequential updating framework. Existing exploration methods often fail to fully utilize the information inherent in sequential updates and suffer from instability and lack of direction. This paper tackles these challenges.
The proposed method, MADPO, incorporates a mutual policy divergence maximization framework to improve exploration. It uses the conditional Cauchy-Schwarz divergence, addressing traditional divergence limitations, providing entropy-guided exploration. Experiments show MADPO significantly outperforms existing sequential updating approaches on various challenging multi-agent tasks, highlighting its effectiveness in fostering both exploration and heterogeneity.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in multi-agent reinforcement learning (MARL), especially those working on cooperative tasks with heterogeneous agents. It directly addresses the limitations of existing MARL exploration methods in such scenarios by introducing a novel framework that leverages sequential updating and policy divergence. This opens avenues for improved sample efficiency and better heterogeneity in diverse applications. The findings also contribute to the broader field of RL exploration through the innovative use of conditional Cauchy-Schwarz divergence.
Visual Insights#
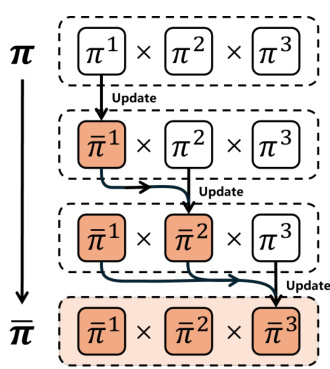
This figure compares the traditional sequential updating method in multi-agent reinforcement learning (MARL) with the proposed method MADPO. The traditional method shows a sequential update of agents’ individual policies (π), while the MADPO method incorporates intra-agent and inter-agent policy divergence to enhance exploration and heterogeneity. The intra-agent divergence encourages an agent to explore new policies based on its previous ones, while the inter-agent divergence ensures that agents learn diverse policies from each other, increasing the heterogeneity of the agents’ policies.
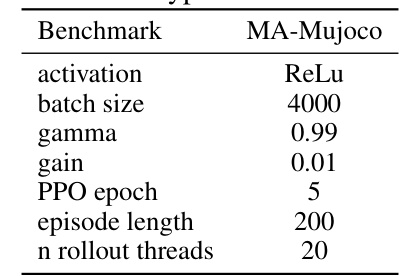
This table lists the common hyperparameters used in the MA-Mujoco experiments described in the paper. These hyperparameters are consistent across different tasks within the MA-Mujoco environment. The settings include the activation function used in the neural networks, batch size for training updates, discount factor (gamma), gain, number of PPO epochs, episode length, and number of rollout threads.
In-depth insights#
MADPO Framework#
The MADPO framework introduces a novel approach to multi-agent reinforcement learning, particularly addressing challenges in heterogeneous scenarios. It leverages sequential policy updates, allowing agents to learn from the information of preceding agents, which is crucial for effective cooperation in diverse settings. A key innovation is the Mutual Policy Divergence Maximization (Mutual PDM) strategy. This strategy uses intra-agent divergence to encourage agents to explore novel policies and inter-agent divergence to increase policy heterogeneity. Importantly, MADPO employs the conditional Cauchy-Schwarz divergence to guide exploration, addressing the instability and lack of directionality seen in traditional divergence methods. This ensures more stable and efficient exploration, ultimately leading to improved performance in challenging multi-agent tasks with various heterogeneous scenarios.
CS Divergence#
The concept of “CS Divergence,” likely referring to Conditional Cauchy-Schwarz Divergence, is a crucial element in the research paper. It addresses limitations of traditional divergence measures in reinforcement learning, particularly in multi-agent scenarios. Traditional methods, like KL-divergence, suffer from instability and a lack of directionality in exploration. The proposed CS Divergence offers a solution by implicitly maximizing policy entropy, thus providing entropy-guided exploration incentives. This is advantageous because it promotes policy diversity and prevents getting trapped in local optima, a common problem in MARL. The conditional nature of the divergence considers the impact of preceding agents’ policies, which is especially relevant in sequential updating frameworks, further enhancing exploration and heterogeneity. The utilization of CS divergence is thus a key innovation for improving sample efficiency and policy exploration in complex multi-agent reinforcement learning tasks.
Heterogeneous MARL#
Heterogeneous Multi-Agent Reinforcement Learning (MARL) tackles the complexities of multi-agent systems where agents possess diverse capabilities, objectives, or observation spaces. Unlike homogeneous MARL, which assumes identical agents, heterogeneous MARL presents unique challenges in coordination and collaboration. The difficulty stems from agents needing to learn effective strategies despite their differences, requiring more sophisticated communication and adaptation mechanisms. Efficient exploration strategies are crucial to navigate the expanded search space introduced by heterogeneity, as standard methods may fail to find optimal solutions. Addressing non-stationarity, caused by the dynamic interaction of diverse agents, is another key issue. Successfully developing algorithms for heterogeneous MARL requires innovative techniques to ensure agents not only learn individually optimal strategies but also find ways to effectively cooperate, even with limited information sharing.
Sequential Updates#
Sequential update methods in multi-agent reinforcement learning (MARL) offer a compelling alternative to simultaneous updates by tackling the challenges of non-stationarity and heterogeneity. The core idea is to update agents’ policies one-by-one, leveraging the information from previously updated agents to improve both individual and collective performance. This approach inherently promotes policy diversity, as each agent adjusts its strategy based on the evolving actions of its predecessors. However, the exploration strategy within sequential updates remains an open problem. While sequential updating encourages heterogeneity, simply relying on this sequential structure may not be sufficient for comprehensive exploration of the vast policy space, especially in complex, heterogeneous scenarios. Therefore, effective exploration mechanisms that leverage the sequential information flow are crucial for maximizing the benefits of this method. Future research should focus on developing sophisticated exploration techniques specifically tailored to the sequential update paradigm, potentially drawing inspiration from information-theoretic approaches or other divergence maximization methods that encourage diverse and robust policy learning.
Future Work#
Future research directions stemming from this work could explore several promising avenues. Extending MADPO to handle more complex multi-agent scenarios, such as those with continuous action spaces or non-stationary environments, would be a significant advancement. Investigating alternative divergence measures, beyond the conditional Cauchy-Schwarz divergence, to further enhance exploration and stability is warranted. This includes exploring the applicability of other information-theoretic principles. Furthermore, a thorough theoretical analysis of MADPO’s convergence properties under various conditions would strengthen its foundation. Developing more efficient methods for estimating policy divergence in high-dimensional spaces is crucial for scalability. Finally, applying MADPO to real-world multi-agent systems, beyond the simulated environments used in this study, would demonstrate its practical effectiveness and identify further areas for improvement. The focus should be on carefully designed experiments to validate the generalizability and robustness of the proposed method.
More visual insights#
More on figures

This figure illustrates the difference between traditional sequential updating MARL and the proposed MADPO method. The left side shows a standard sequential updating approach where agents update their policies one by one. The right side depicts MADPO, highlighting the incorporation of intra-agent divergence (measuring policy differences within an agent’s episodes) and inter-agent divergence (measuring policy differences between agents) to enhance exploration and heterogeneity. The colored boxes represent policies and their updates, emphasizing the flow of information and the differences between the two approaches.
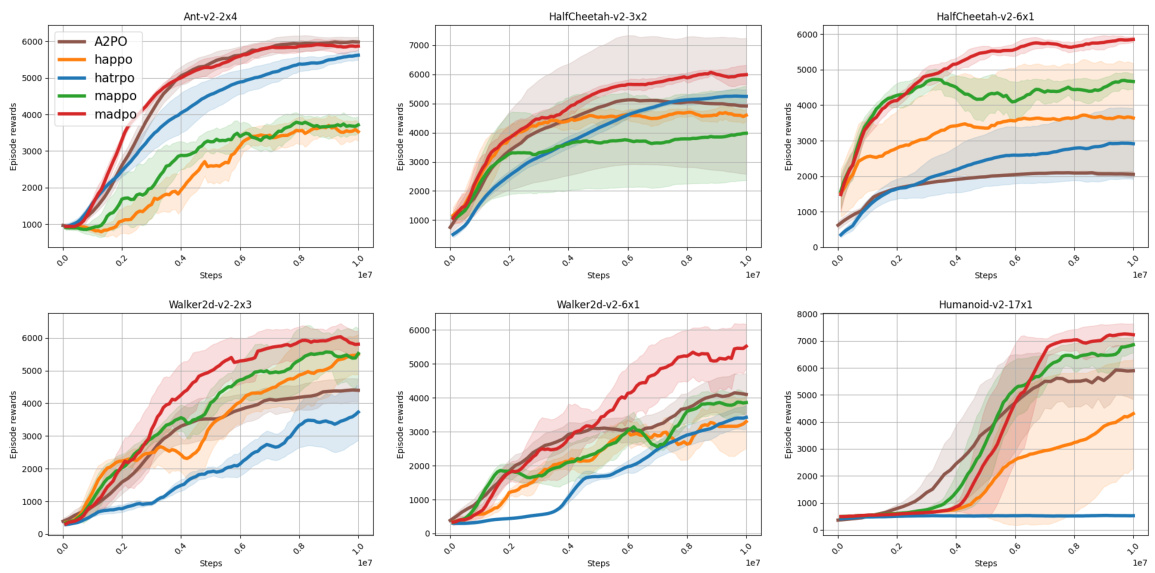
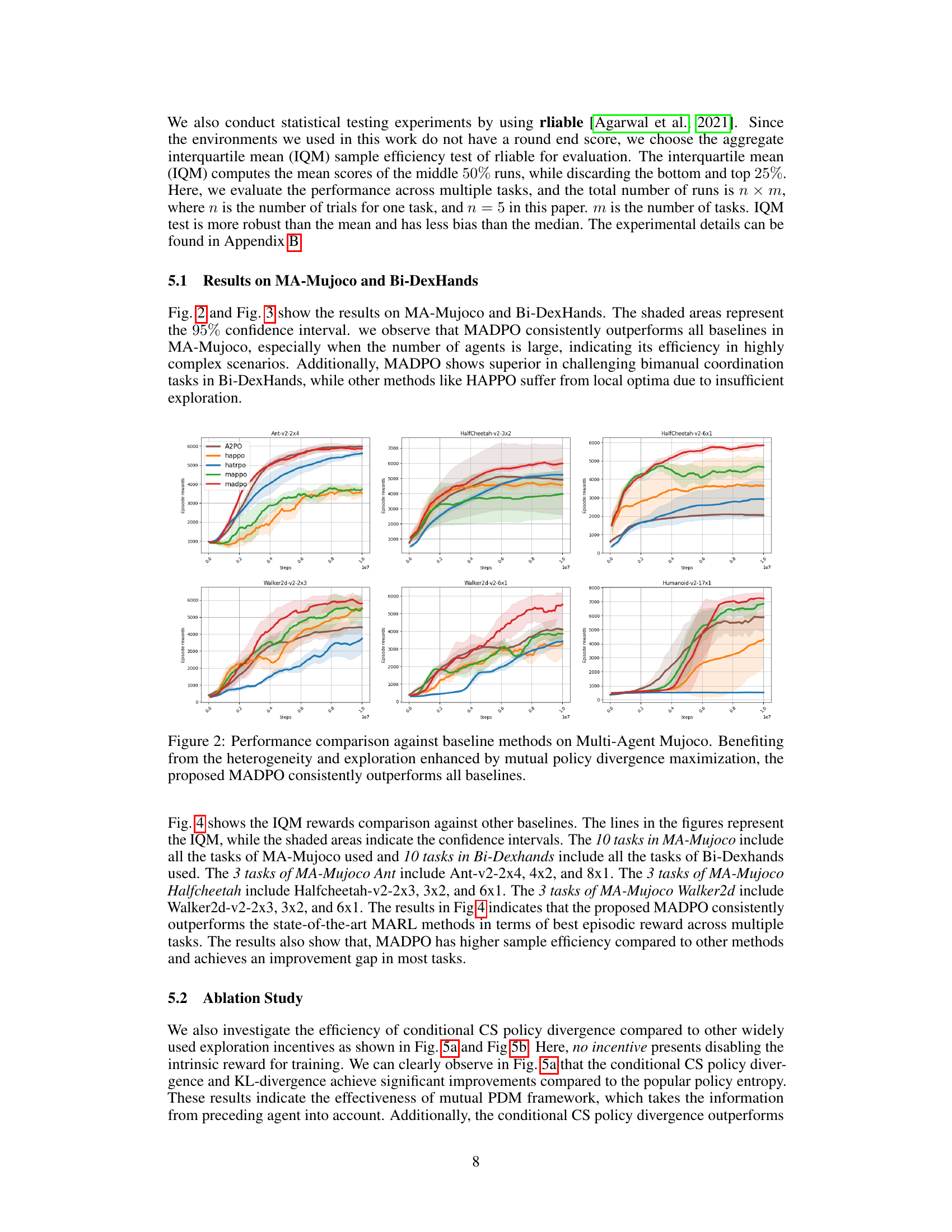
This figure compares the performance of MADPO against other baseline methods (A2PO, HAPPO, HATRPO, MAPPO) on various Multi-Agent Mujoco tasks. The results show that MADPO consistently achieves higher episode rewards across all tasks, demonstrating the effectiveness of its mutual policy divergence maximization strategy in promoting both heterogeneity and exploration. The shaded areas represent 95% confidence intervals.
This figure compares the traditional sequential updating MARL method with the proposed MADPO method. It illustrates how MADPO incorporates intra-agent (policy divergence between episodes for a single agent) and inter-agent (policy divergence between agents) divergence to enhance exploration and heterogeneity. The diagram uses boxes to visually represent policies and their updates, highlighting the differences in the approaches.

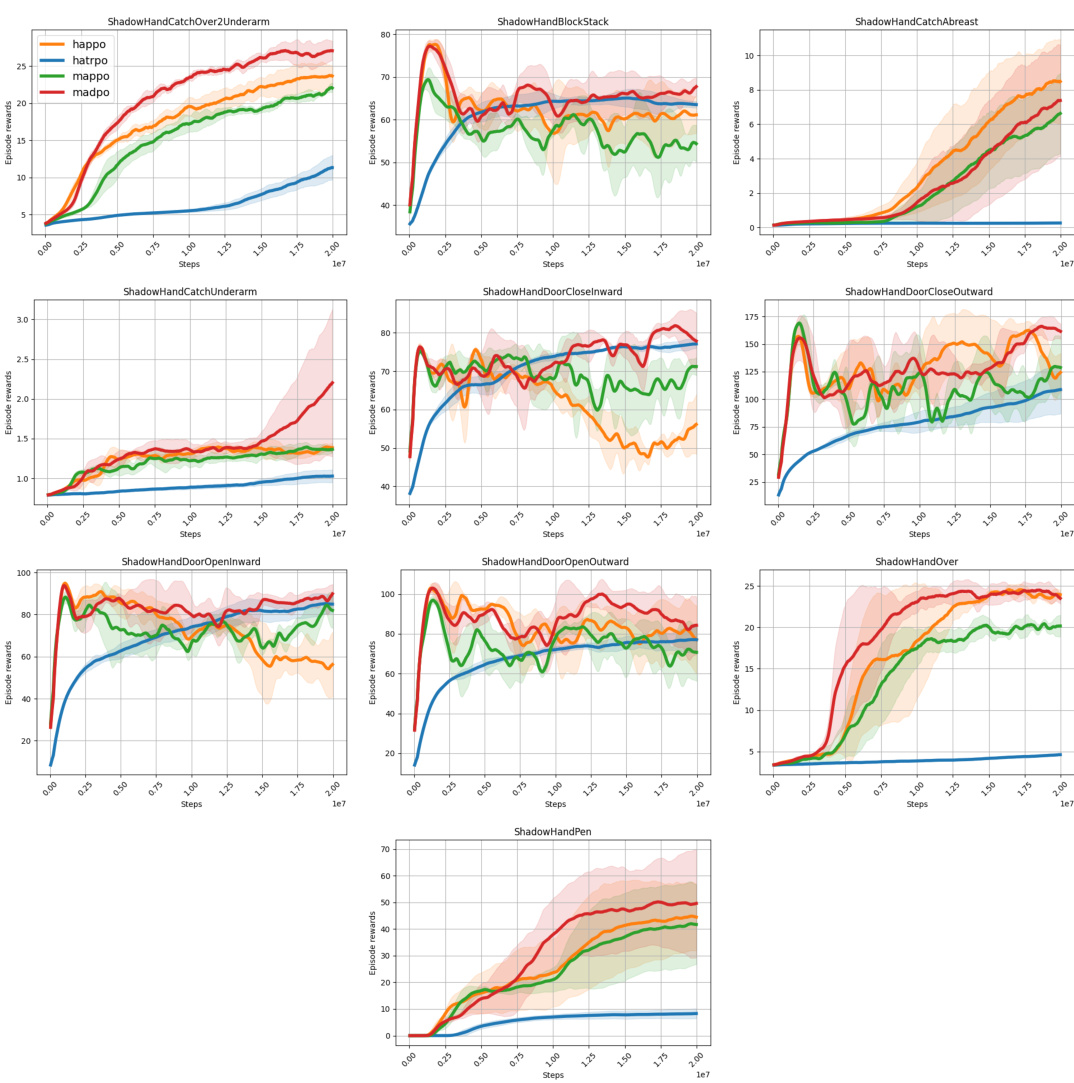
This figure presents the results of the Interquartile Mean (IQM) performance comparison across multiple tasks between MADPO and other baseline methods. The IQM is used to measure the sample efficiency, which is the mean of the middle 50% of runs to reduce the bias of outliers. The figure displays the IQM of episodic rewards for 10 tasks from the Bi-DexHands environment and 9 tasks from the MA-Mujoco environment. Each line represents a different algorithm, showing the average reward over time, and the shaded area indicates the 95% confidence interval. The results demonstrate that MADPO achieves higher average rewards across tasks and has higher sample efficiency than state-of-the-art methods.

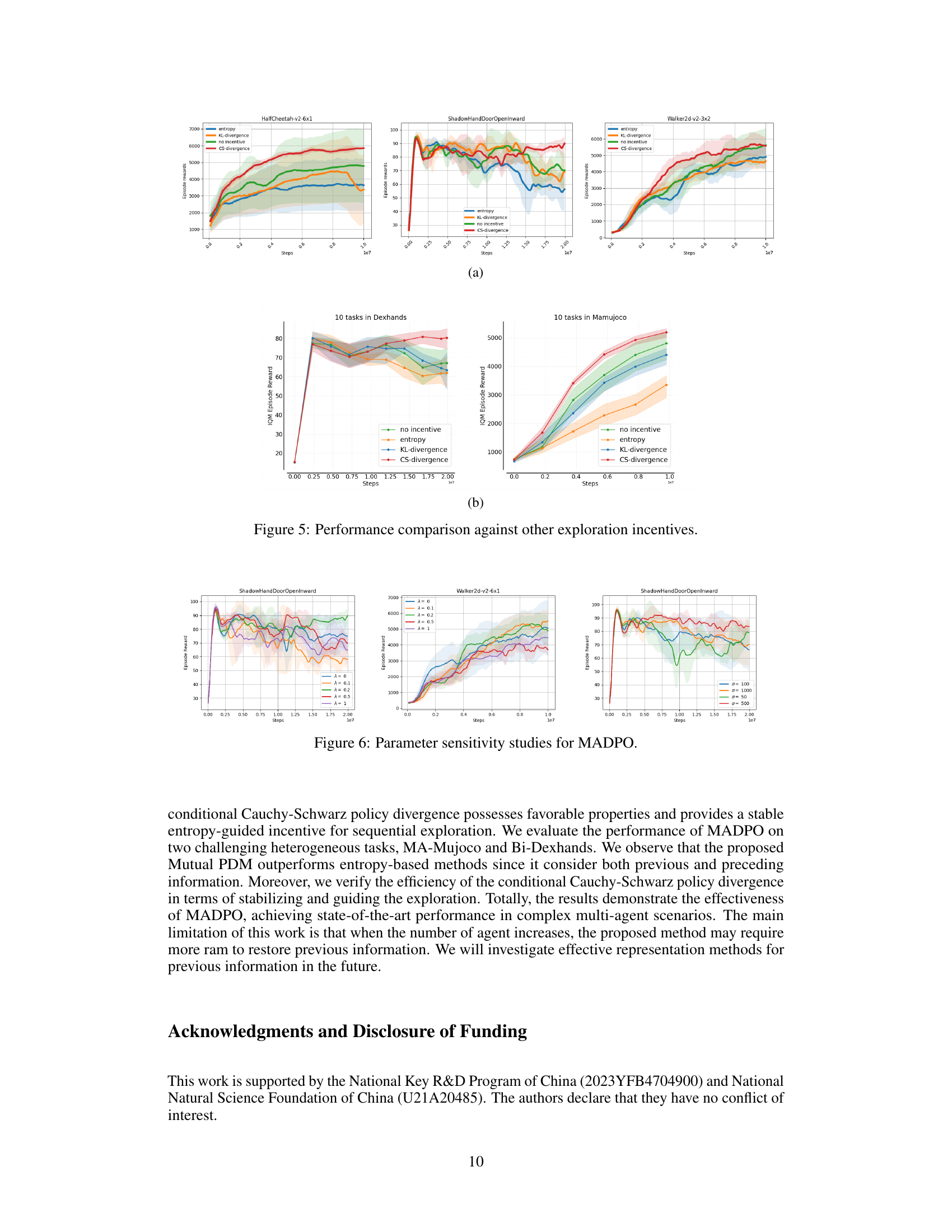
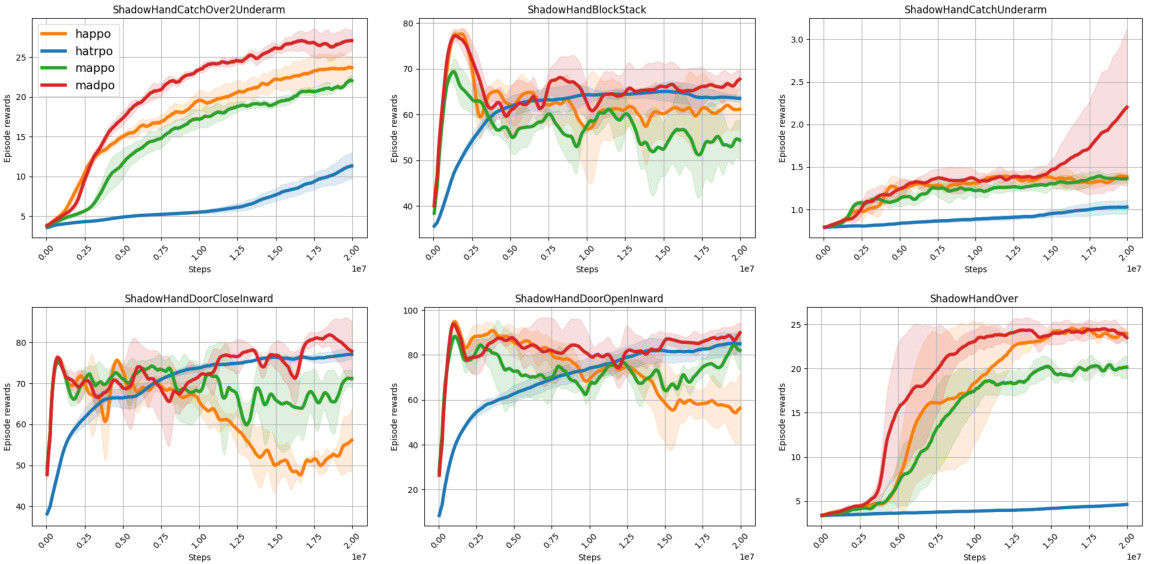
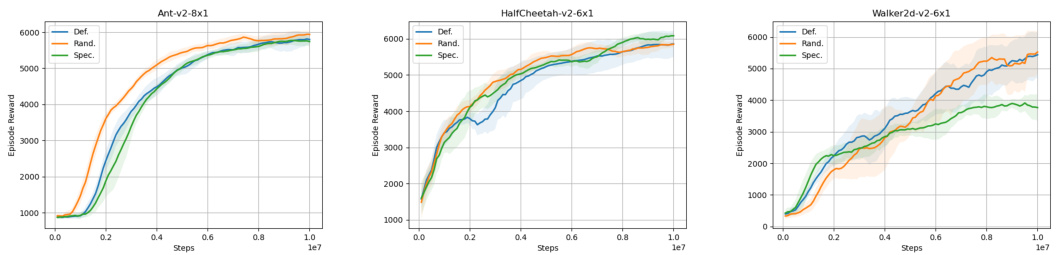
This figure compares the performance of different exploration methods including entropy, KL-divergence, no incentive, and CS-divergence. Subfigure (a) shows the learning curves for three different multi-agent tasks: HalfCheetah-v2-6x1, ShadowHandDoorOpenInward, and Walker2d-v2-3x2. Subfigure (b) displays an aggregate IQM comparison of episode rewards across multiple tasks (10 in Dexhands and 10 in Mamujoco). The results demonstrate that the proposed conditional Cauchy-Schwarz (CS) divergence significantly outperforms other methods, providing more stable and effective exploration in multi-agent reinforcement learning.

This figure presents the results of parameter sensitivity studies conducted on the MADPO algorithm. It shows how the performance of MADPO varies across different tasks (ShadowHandDoorOpenInward, Walker2d-v2-6x1, and ShadowHandDoorOpenInward) when adjusting the parameters λ and σ. The parameter λ controls the influence of inter-agent and intra-agent policy divergence, while σ influences the conditional Cauchy-Schwarz policy divergence. The results reveal MADPO’s performance is slightly sensitive to σ and that its performance is significantly better than HAPPO for various settings of λ and σ.
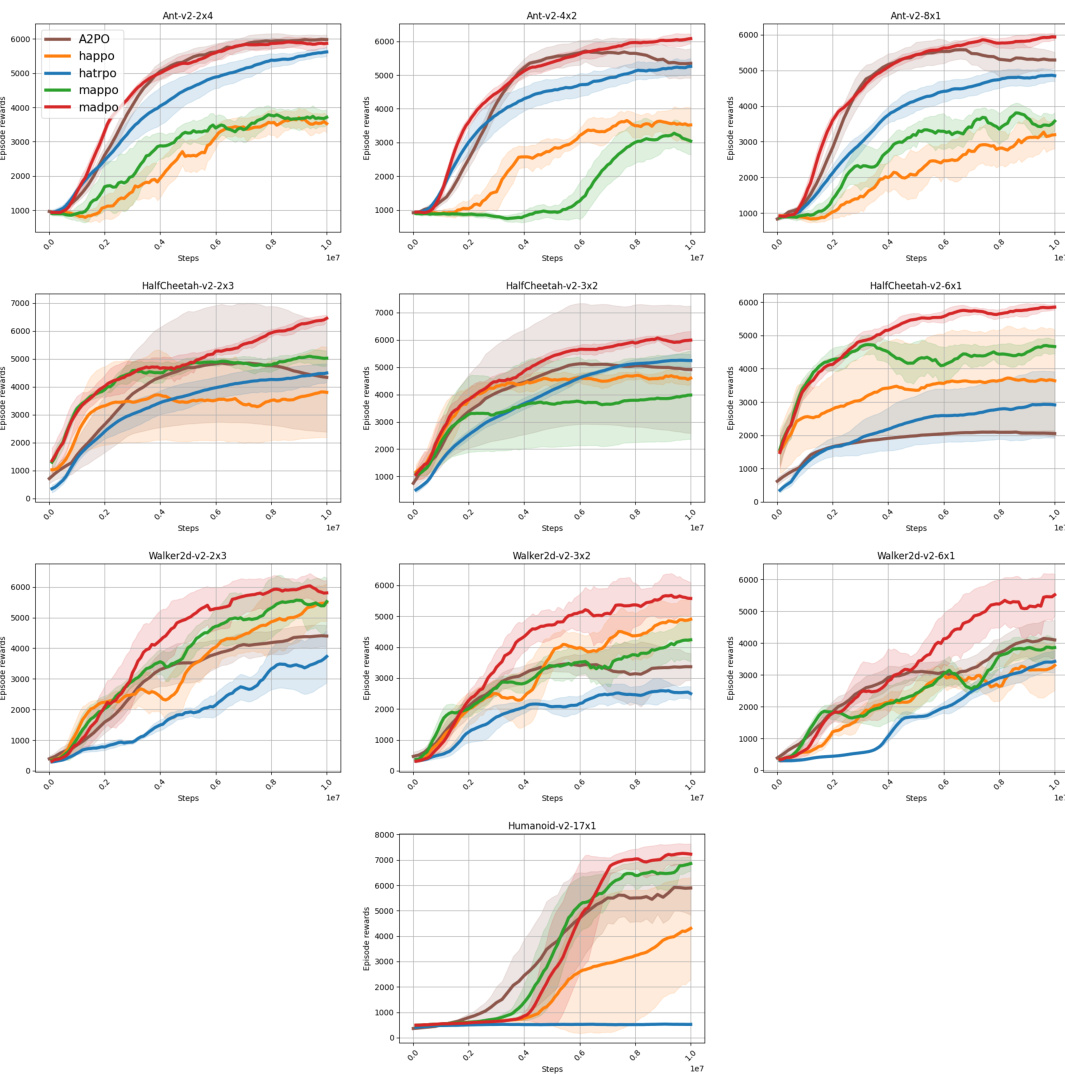
This figure compares the performance of MADPO against other state-of-the-art multi-agent reinforcement learning algorithms on five different tasks within the Multi-Agent MuJoCo environment. The results are presented as episode rewards plotted over training steps, and error bars show the 95% confidence interval. The results indicate that MADPO consistently outperforms other algorithms, illustrating the benefits of its mutual policy divergence maximization approach in enhancing exploration and heterogeneity, particularly in complex, multi-agent scenarios.
This figure compares the traditional sequential updating MARL approach with the proposed MADPO method. It illustrates how MADPO incorporates intra-agent and inter-agent policy divergence to enhance exploration and heterogeneity, unlike traditional methods which only update policies sequentially without considering divergence. The diagram visually represents the policy updates in both methods, showing the differences in how policy information is utilized.
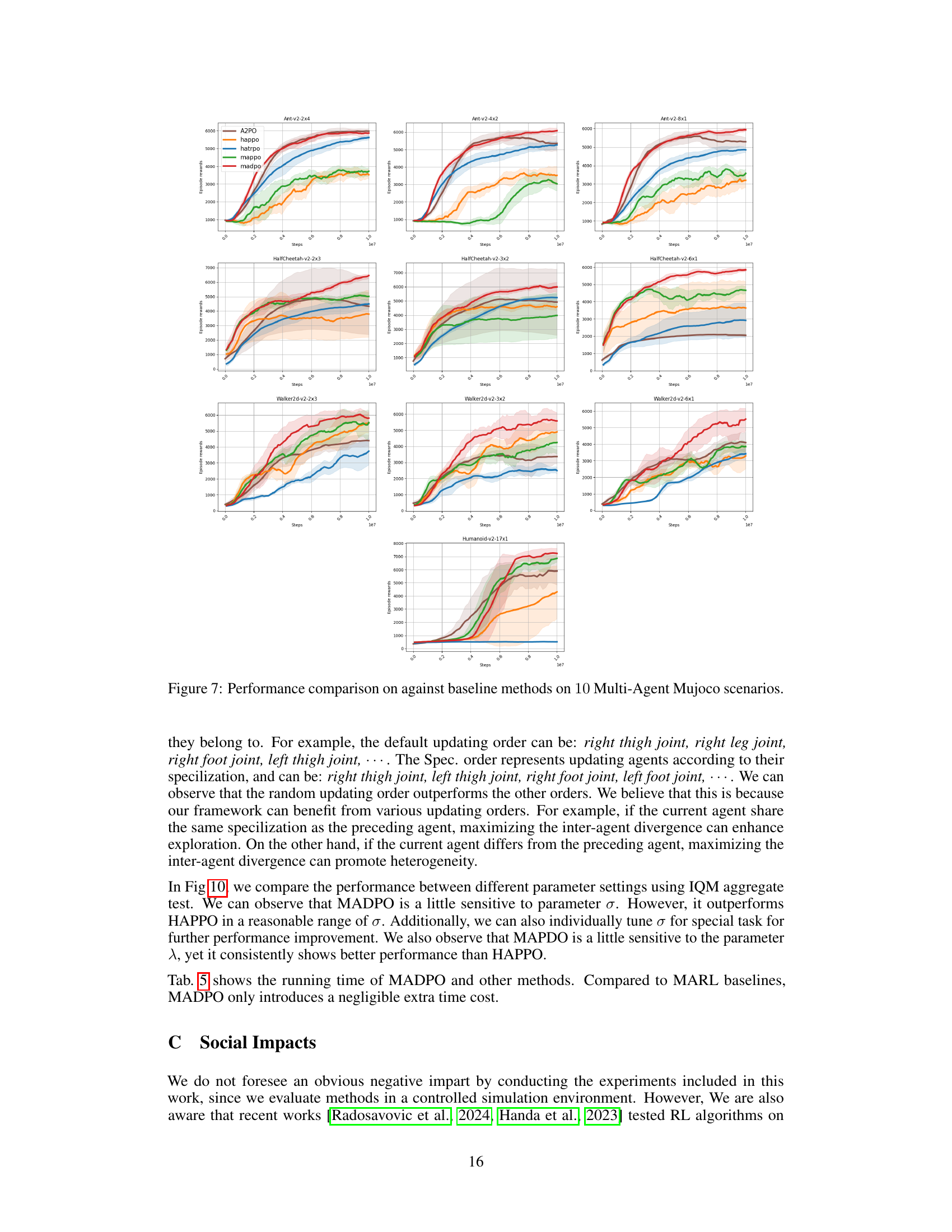
This figure compares the performance of MADPO against other baseline methods (A2PO, HAPPO, HATRPO, MAPPO) across 10 different Multi-Agent Mujoco scenarios. The x-axis represents training steps, and the y-axis represents episode reward. The figure shows MADPO consistently outperforms other methods in most scenarios, highlighting its effectiveness in complex, multi-agent environments. Different colored lines represent different methods, and shaded areas indicate the 95% confidence interval.
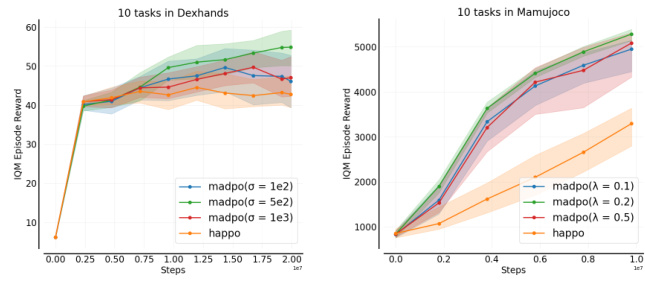
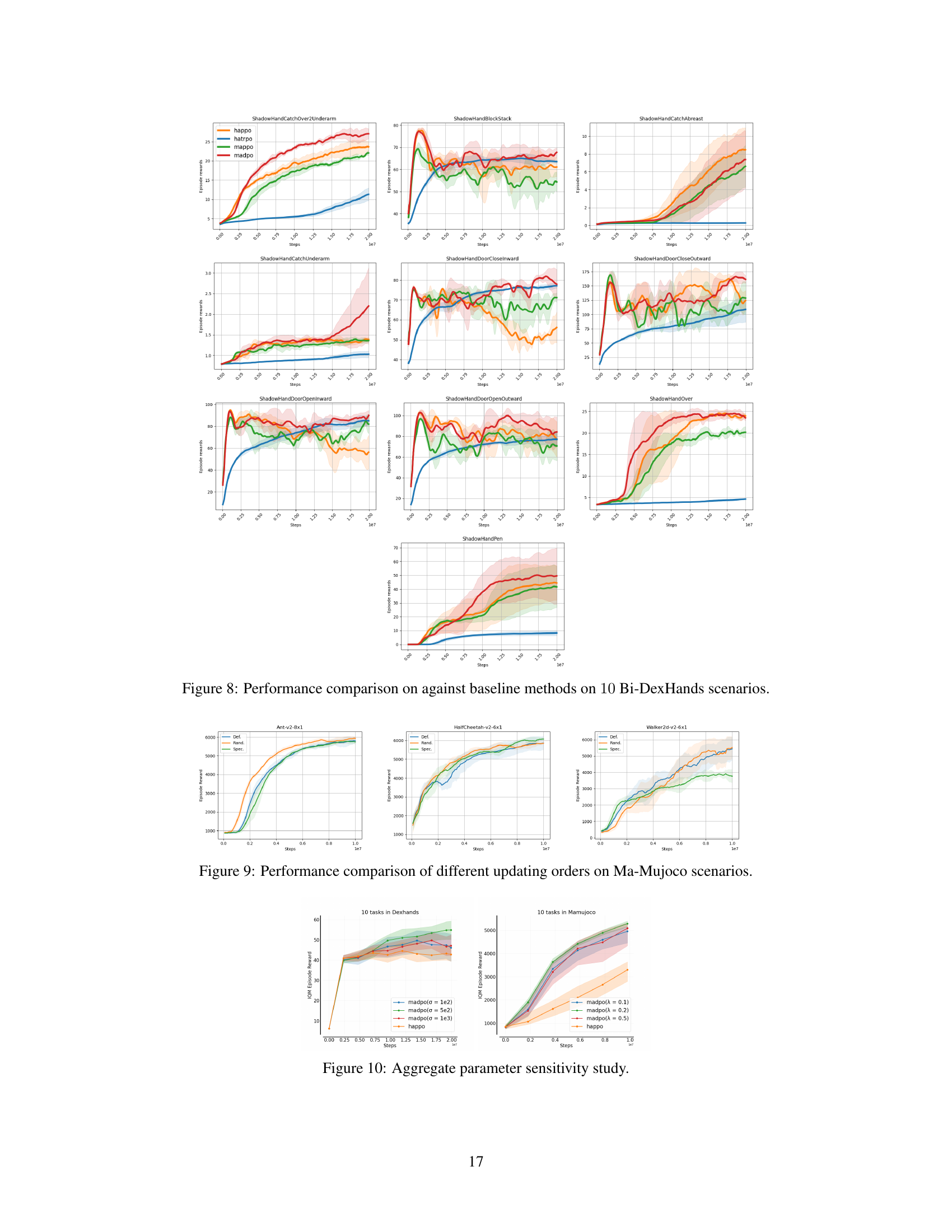
This figure shows the results of a parameter sensitivity study for MADPO, assessing the impact of parameters λ (influencing the balance between inter-agent and intra-agent policy divergence) and σ (related to the conditional Cauchy-Schwarz divergence estimator). The plots display the IQM (Interquartile Mean) episode reward across multiple tasks in both MA-Mujoco and Bi-DexHands environments for different values of λ and σ. The results show that MADPO’s performance is moderately sensitive to these parameters, highlighting the importance of careful tuning for optimal results. Comparing MADPO’s performance against HAPPO provides a baseline for evaluating the benefits of MADPO’s approach.
More on tables

This table lists the hyperparameters used in the Multi-Agent MuJoCo experiments. It shows the hidden layer architecture, learning rates for the actor and critic networks, the clipping parameter for PPO, the coefficient for balancing inter-agent and intra-agent divergence, and the parameter for the Cauchy-Schwarz divergence. The hyperparameters are specified for each of the different MuJoCo tasks.

This table lists the common hyperparameters used in the Bi-DexHands experiments. It includes settings for the activation function, batch size, gamma, gain, PPO epochs, episode length, number of rollout threads, hidden layer architecture, clipping range, actor learning rate, and critic learning rate. These hyperparameters are consistent across different scenarios within the Bi-DexHands environment, ensuring consistency and facilitating comparison between experiments.
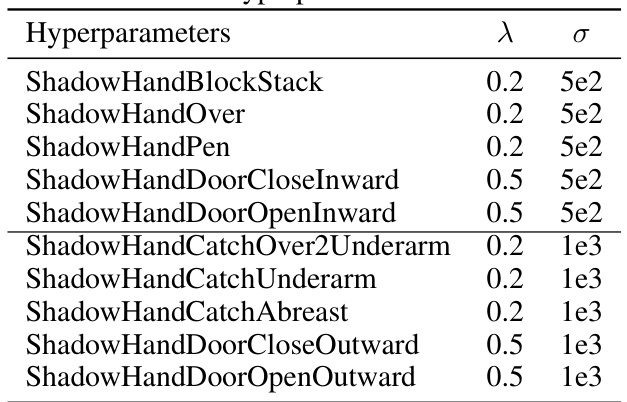
This table lists the different hyperparameter settings used for the various tasks within the Bi-DexHands environment. Specifically, it shows the values of lambda (λ) and sigma (σ) which are parameters of the Mutual Policy Divergence Maximization (Mutual PDM) method used in the MADPO algorithm. Different tasks require different parameter tuning, as indicated in this table.
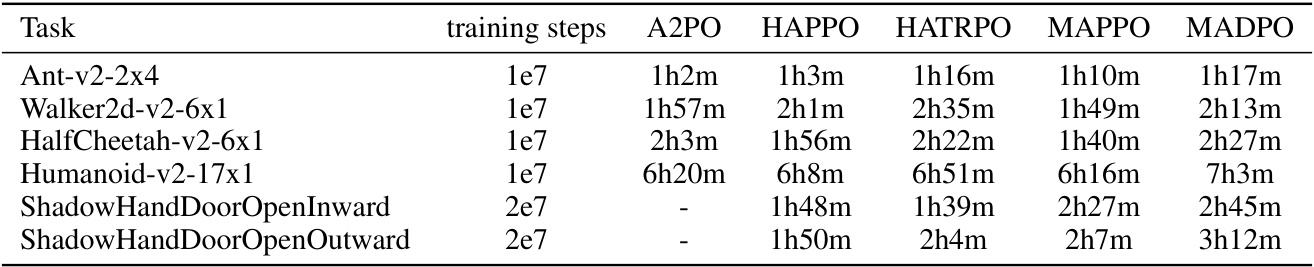
This table shows the training time of different algorithms (A2PO, HAPPO, HATRPO, MAPPO, and MADPO) on various multi-agent tasks in both MuJoCo and Bi-DexHands environments. The results are presented in hours and minutes, indicating the computational cost of each method for reaching a certain level of training progress. Note that training steps are also reported for each task.
Full paper#