↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Federated learning (FL) faces challenges when clients use diverse models. Existing aggregation methods struggle with personalization, raise privacy issues, or require prior knowledge. This limits the practical applications of FL. Furthermore, methods like model distillation can create overly large personalized models that are not suitable for all clients.
pFedClub, the proposed approach, addresses these issues by dissecting heterogeneous models into blocks, grouping them by functionality, and using a controllable model search algorithm. This generates a range of personalized candidates, and a model-matching technique selects the optimal one. Extensive experiments show pFedClub surpasses existing methods, achieving state-of-the-art results and producing reasonably sized models while mitigating computational overheads. This demonstrates its efficacy for real-world applications.
Key Takeaways#
Why does it matter?#
This paper is important because it tackles the critical challenge of handling diverse model structures in federated learning, a limitation of many existing systems. By introducing a novel approach for controllable and personalized model aggregation, it significantly improves efficiency and reduces computational costs, while also addressing privacy concerns. The proposed method demonstrates state-of-the-art performance and opens new avenues for personalized federated learning research.
Visual Insights#

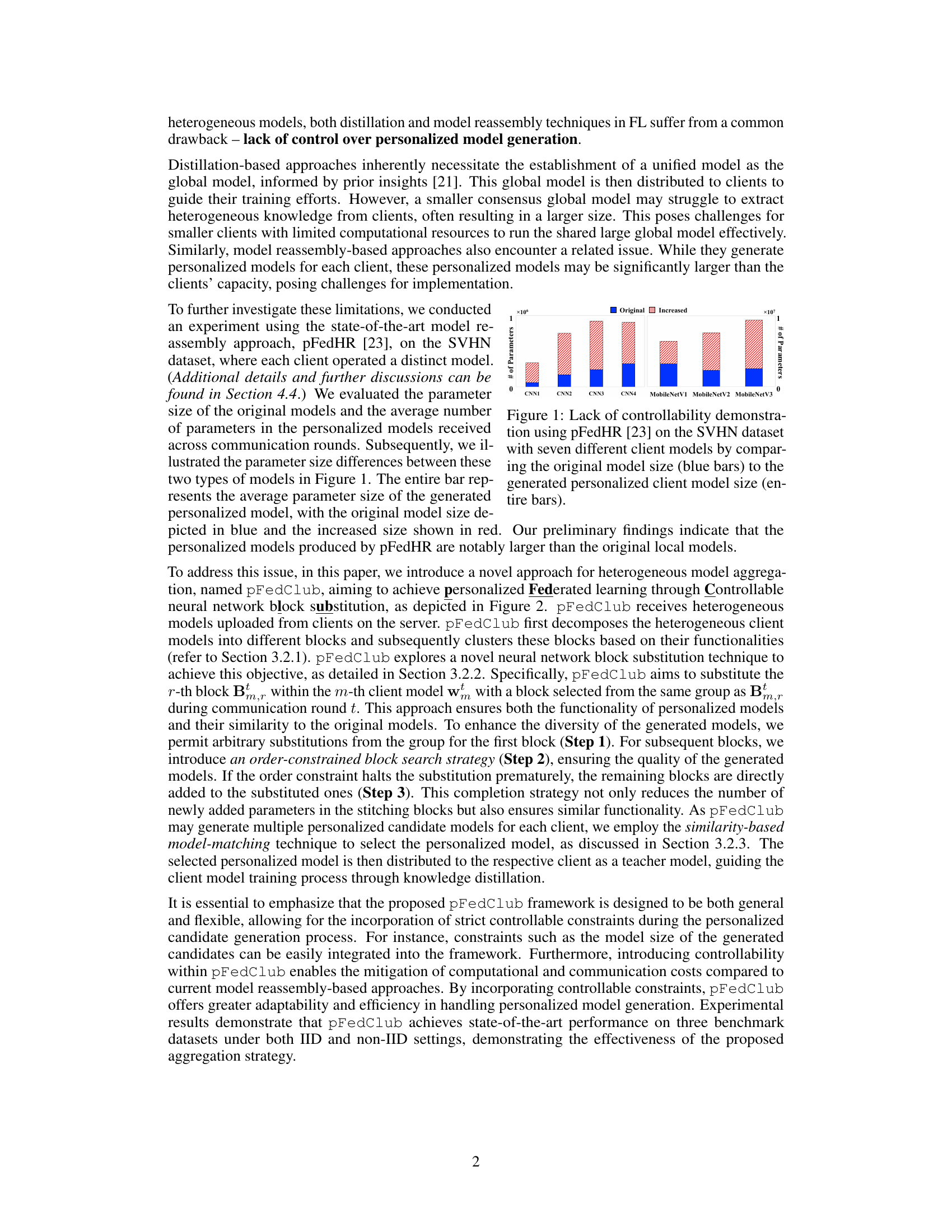
This figure demonstrates the lack of control over personalized model generation in the existing pFedHR approach. It shows a comparison of the original model size (blue bars) versus the size of the personalized models generated by pFedHR (entire bars) across seven different client models on the SVHN dataset. The red portion of each bar represents the increase in model size from the original to the personalized model. This illustrates that the personalized models generated are substantially larger than the original models, highlighting a key limitation of the existing approach.
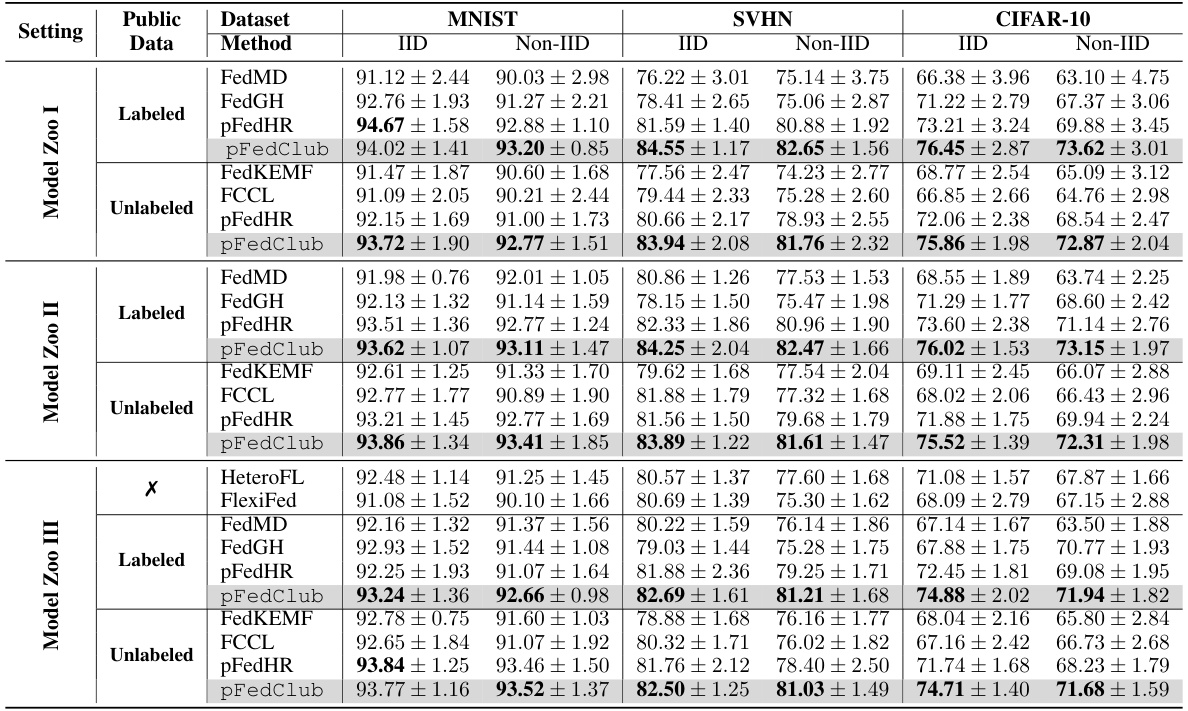
This table presents the performance comparison of the proposed pFedClub method against various baseline methods across three datasets (MNIST, SVHN, CIFAR-10) under both IID and non-IID data distributions. The results are shown for different model zoo setups (I, II, III), representing varying degrees of model heterogeneity among clients, and for both labeled and unlabeled public datasets. The table illustrates the performance of the methods in terms of accuracy, highlighting the effectiveness of pFedClub in heterogeneous federated learning settings.
In-depth insights#
Personalized FL#
Personalized federated learning (FL) aims to tailor models to individual clients’ data distributions, addressing the limitations of traditional FL which assumes uniform model structures and data across all participants. This personalization enhances model accuracy and user experience, but introduces significant challenges. Data heterogeneity and privacy concerns are central issues. Different approaches exist, such as using additional information (like logits or class labels) to exchange knowledge between clients and the server. However, these approaches often compromise privacy. Other methods leverage model distillation or reassembly to aggregate diverse client models, but these can lack personalization control, potentially resulting in models too large for certain clients. Effective personalized FL necessitates innovative techniques that balance personalization with privacy, model size efficiency, and computational cost. Future research should focus on developing more robust, efficient, and privacy-preserving personalized FL algorithms.
Block-wise Control#
Block-wise control, in the context of heterogeneous federated learning, offers a granular approach to model aggregation. It allows for the selective substitution or modification of individual blocks within neural network models from various clients. This approach is particularly powerful because it addresses the challenge of aggregating diverse model architectures without sacrificing personalization. By working at the block level, the system can leverage the functional similarities between blocks from different models, promoting efficient knowledge transfer and personalized model generation. A key advantage is the ability to maintain the functionality of the original models while injecting new knowledge from other, potentially more advanced models. The controllable nature of this process enables the development of adaptive mechanisms, dynamically adjusting the model’s structure and complexity to suit individual client needs and resource constraints. Careful consideration of block decomposition and grouping strategies are crucial to ensure that functional similarity is properly captured and exploited. This method offers a more flexible and efficient approach to heterogeneous federated learning, compared to global model-based techniques, which often struggle with diverse architectures and limited resources.
CMSR Algorithm#
The Controllable Model Searching and Reproduction (CMSR) algorithm is a crucial part of the pFedClub framework, addressing the challenge of heterogeneous model aggregation in personalized federated learning. CMSR’s core innovation lies in its controllable block-wise substitution strategy. Instead of directly replacing entire models, CMSR intelligently substitutes individual neural network blocks within client models, carefully selected from functionally similar blocks residing on the server. This allows for personalized model generation while preserving the original model’s functionality. The algorithm’s controllability is further enhanced through an order-constrained block search and a block completion strategy. This prevents the generation of excessively large or dysfunctional personalized models, mitigating a key limitation of prior approaches. The order constraint ensures the quality of generated models by maintaining the functional order of blocks, while the completion step efficiently manages cases where the constrained search halts prematurely. By offering flexibility in controlling model size and employing a similarity-based model matching, CMSR successfully addresses the trade-off between personalization and computational efficiency, enabling effective personalized federated learning with heterogeneous models. The incorporation of strict constraints is a notable strength, promoting generalizability and efficient model generation.
Computational Cost#
Analyzing the computational cost aspect of a federated learning system reveals crucial insights into its efficiency and scalability. A key focus should be on comparing the computational demands of the proposed method against existing baselines. This comparison needs to go beyond simply stating that the proposed method is more efficient and should delve into specifics, including metrics such as server-side computation time per communication round, potential bottlenecks, and the impact of model size and complexity on resource usage. Furthermore, a detailed breakdown of the computational costs at different stages of the algorithm, such as model aggregation and client model updates, will offer a comprehensive understanding. Considering the trade-off between model accuracy and computational overhead is vital. While a method might demonstrate superior performance, its practicality is undermined if the computational cost significantly outweighs the benefits of improved accuracy. Therefore, the analysis should not only highlight computational efficiency but also discuss the resource implications, especially considering diverse client capabilities, network conditions, and power constraints. Investigating scalability with respect to the number of clients and data volume is necessary. A system efficient with a small number of clients might prove computationally prohibitive when scaled to a larger-scale deployment. Thus, the analysis should explicitly address the computational cost’s behavior under varying conditions. Overall, a thorough examination of computational cost is crucial for assessing the true feasibility and practical utility of the system.
Future Work#
Future work for this research could explore several promising avenues. Extending pFedClub to handle a wider variety of model architectures, beyond CNNs and MobileNets, is crucial for broader applicability. This would involve developing more robust block decomposition and grouping strategies. Investigating the impact of different block substitution techniques and exploring alternative methods for personalized model selection could further enhance performance and controllability. Developing a more efficient CMSR algorithm is needed to reduce computational costs, especially for large-scale deployments. This might involve incorporating more advanced optimization techniques. A thorough investigation into the privacy implications of the proposed framework, particularly in non-IID scenarios, is vital to ensure responsible development and deployment. Finally, empirical evaluation on a more diverse range of real-world datasets is necessary to validate the generality and robustness of pFedClub’s performance.
More visual insights#
More on figures
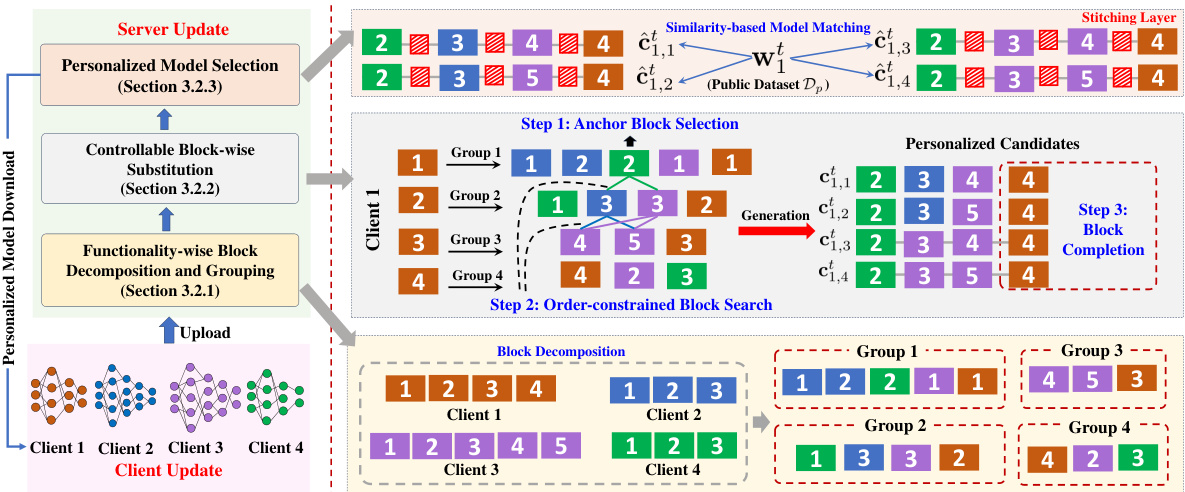
This figure illustrates the workflow of the pFedClub algorithm. It starts with four clients uploading their heterogeneous models to the server. The server decomposes these models into blocks, groups similar blocks based on functionality, and then uses the CMSR algorithm to generate personalized candidate models for each client by substituting blocks from the same functional group. The process involves three steps: anchor block selection, order-constrained block search, and block completion. Finally, similarity-based model matching selects the optimal personalized model for each client, which is then used as a teacher model to guide the client’s training process.

This figure illustrates the workflow of the pFedClub algorithm. It begins by receiving heterogeneous models from multiple clients. These models are decomposed into functional blocks, which are then grouped based on their functionality. The CMSR algorithm then selects blocks from these groups to create personalized candidate models for each client. A model matching technique chooses the optimal personalized model to guide the training process of each client model through knowledge distillation. The example in the figure shows how a personalized model is generated for Client 1 using blocks from other clients.
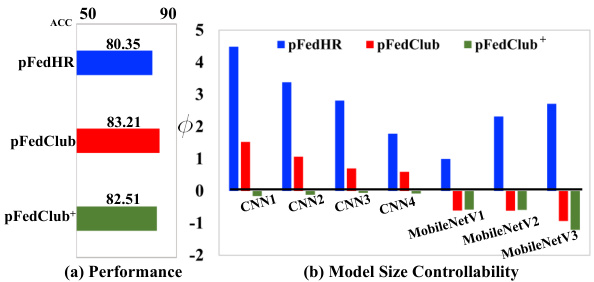
This figure demonstrates the controllability analysis of pFedHR, pFedClub, and pFedClub+ on the SVHN dataset under non-IID conditions. (a) shows the accuracy achieved by each method. (b) displays the average model size change percentage over communication rounds for each client, showcasing the effectiveness of pFedClub and pFedClub+ in controlling the generated personalized model sizes. pFedClub+ adds a model size constraint.
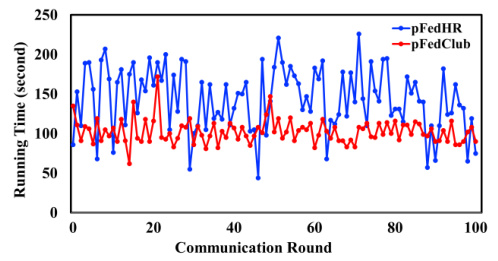
This figure shows a comparison of server-side computational time between pFedClub and pFedHR across 100 communication rounds during the training process on the SVHN dataset under the non-IID setting with Model Zoo III and 50 clients. It demonstrates that pFedClub generally exhibits lower and more stable computational times compared to pFedHR.

This figure compares the time taken by pFedHR and pFedClub to reach different target accuracies (40%, 50%, 60%) on the SVHN and CIFAR-10 datasets under a non-IID setting. It visually demonstrates that pFedClub achieves the target accuracy faster than pFedHR across all accuracy levels. The percentage values on the bars represent the relative improvement of pFedClub’s time compared to pFedHR for reaching the specified accuracy.
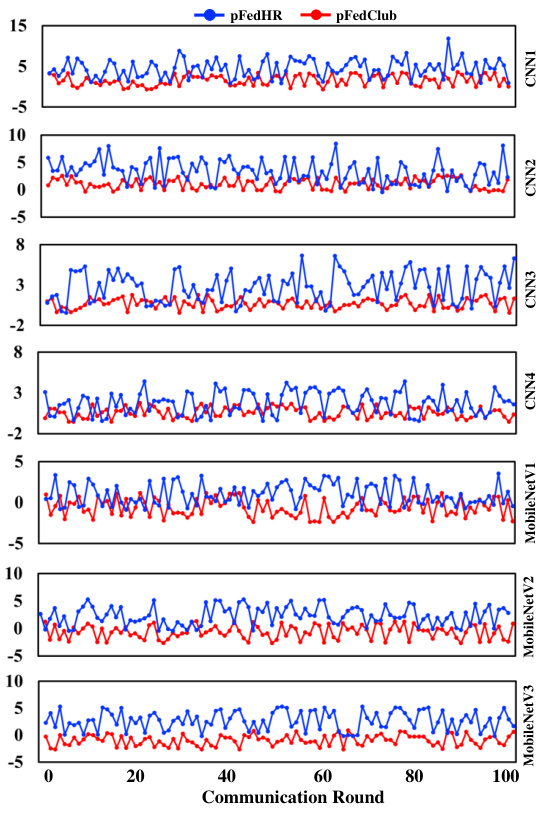
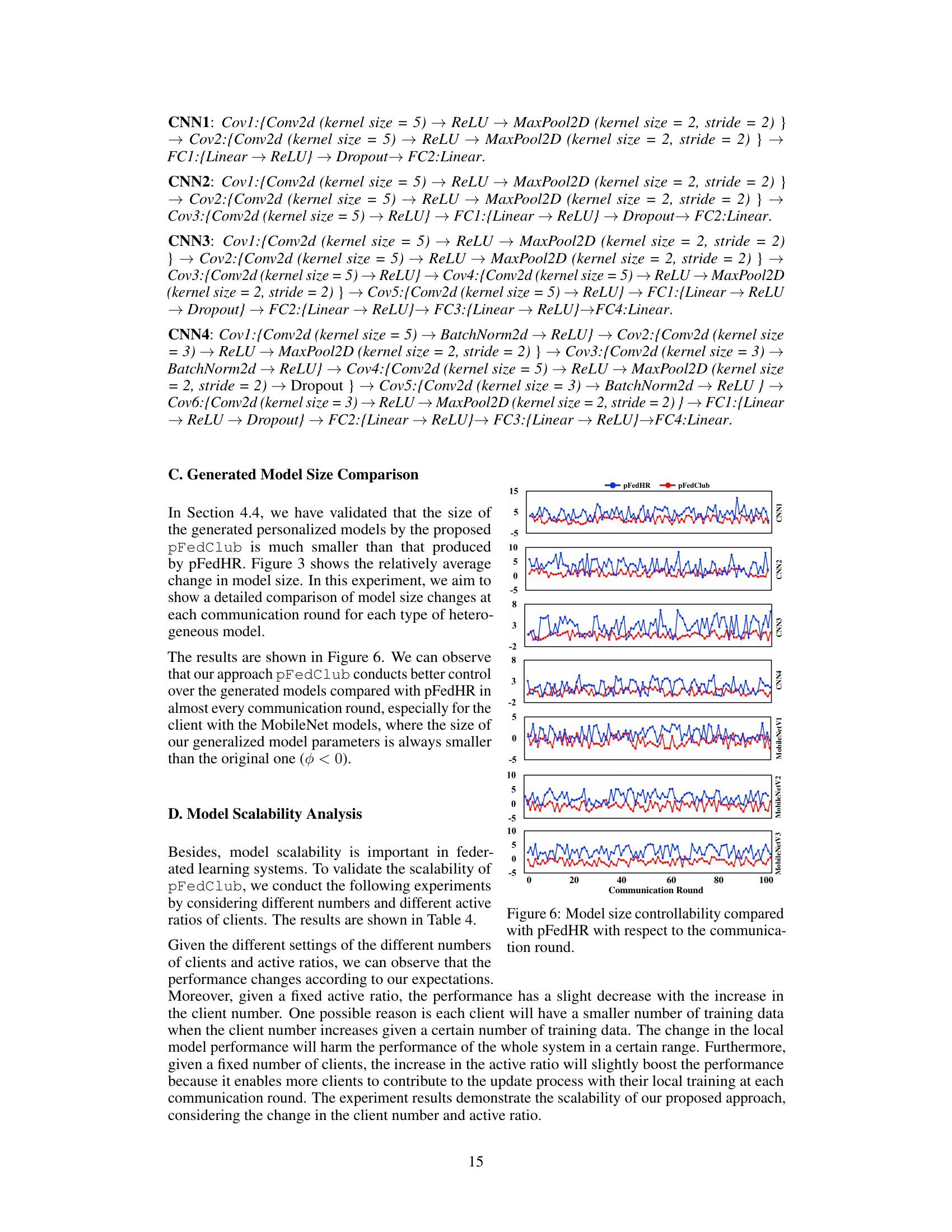
This figure compares the model size controllability of pFedClub and pFedHR across different communication rounds for various client models (CNN1-CNN4, MobileNetV1-MobileNetV3). Each subplot shows the relative change in model size for a specific client model, plotted against communication round number. The blue line represents pFedHR, while the red line represents pFedClub. The y-axis represents the percentage change in model size. This visualization helps to demonstrate the effectiveness of pFedClub in controlling the size of the generated personalized models, keeping them closer to the original model size compared to pFedHR.
More on tables
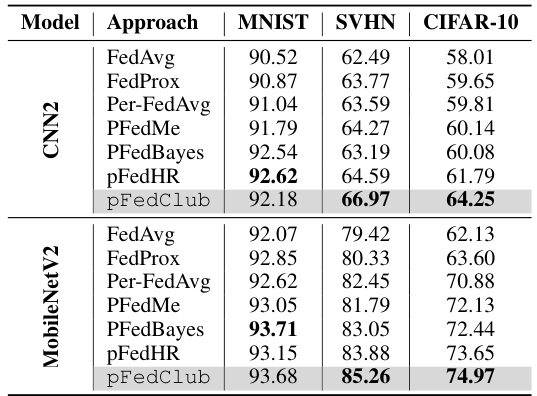
This table presents the performance comparison of the proposed pFedClub against various homogeneous federated learning baselines on three datasets (MNIST, SVHN, CIFAR-10) using two different model architectures (CNN2 and MobileNetV2). The results show the accuracy achieved by each method under non-IID data distribution. This helps evaluate pFedClub’s effectiveness not just in heterogeneous, but also in homogeneous settings.
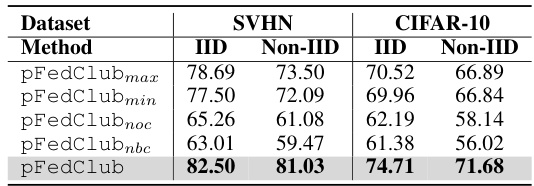
This table presents the ablation study results, showing the impact of removing individual modules from the proposed pFedClub on its performance. It compares the accuracy of pFedClub with four variations: pFedClubmax (using a simple strategy for anchor block selection), pFedClubmin (using another simple anchor block selection strategy), pFedClubnoc (omitting order-constrained block search), and pFedClubnbc (omitting block completion). The results demonstrate the contribution of each module to the overall performance of pFedClub.

This table shows the scalability of the proposed pFedClub algorithm by testing different numbers of clients and active ratios. The results demonstrate the performance of the algorithm under various network conditions and resource constraints. The experiment is conducted on the SVHN dataset.

This table presents the performance of the pFedClub model on SVHN and CIFAR-10 datasets under different hyperparameter settings. It investigates the impact of varying the number of clusters (K) used in the K-means algorithm for grouping model blocks on the model’s accuracy. The results are shown for both IID (Independent and Identically Distributed) and Non-IID (Non-Independent and Identically Distributed) data distributions, and for both labeled and unlabeled public datasets. The table aims to determine the optimal number of clusters that yields the best performance for the pFedClub model.
Full paper#