↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current text-to-image models struggle to generate realistic human faces and hands due to insufficient training data. This paper addresses this by creating a large, high-quality dataset focusing on humans and particularly detailed close-ups of faces and hands. The lack of sufficient prior knowledge about human faces and hands makes it hard for these models to generate natural-looking images.
To address these issues, the paper proposes MoLE (Mixture of Low-rank Experts), a novel method that incorporates low-rank modules trained on these specialized datasets. These modules act as ’experts’, effectively refining the details of faces and hands during image generation. Experiments show that MoLE significantly outperforms existing methods in terms of generating more realistic and human-like features, especially for faces and hands, while remaining computationally efficient.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses a critical limitation in human-centric text-to-image generation, improving the realism of faces and hands. It introduces a novel approach (MoLE) that’s both effective and resource-efficient, opening avenues for better human-centric image synthesis and prompting further research into enhancing the details of generated images.
Visual Insights#

This figure compares the image generation capabilities of MoLE against four other state-of-the-art diffusion models: Stable Diffusion v1.5, Stable Diffusion XL, VQ-Diffusion, and Versatile Diffusion. The comparison focuses on human-centric details, particularly the faces and hands in the generated images. The prompts used are shown on the top of each image. The viewer is encouraged to zoom in for a closer look to observe the differences in detail and quality of the generated faces and hands.
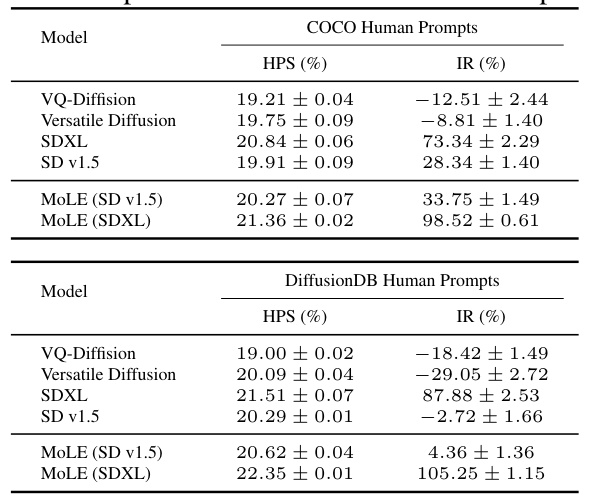
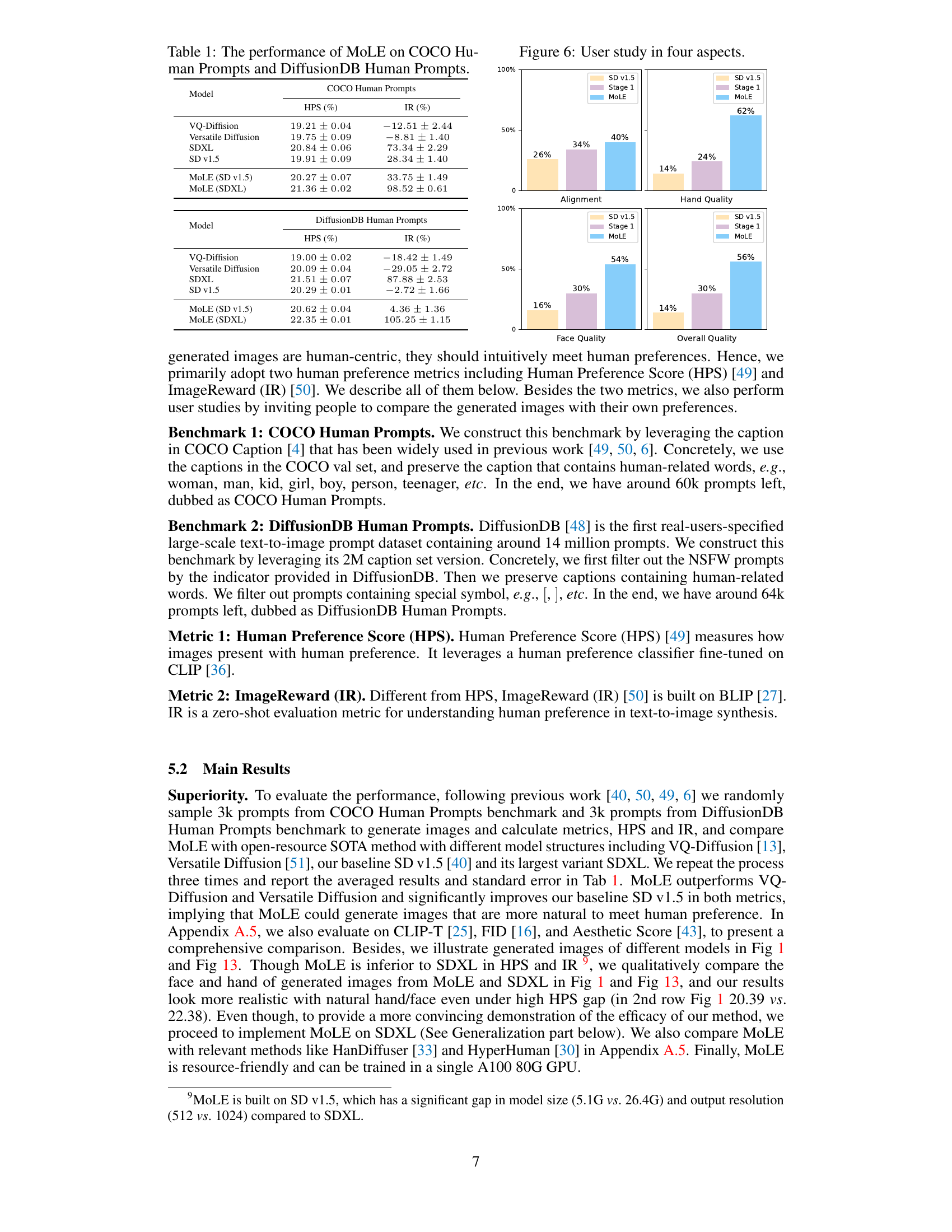
This table presents the quantitative results of the proposed MOLE model and several baseline models on two human-centric image generation benchmarks: COCO Human Prompts and DiffusionDB Human Prompts. The performance is evaluated using two metrics: Human Preference Score (HPS) and ImageReward (IR). Higher HPS and IR values indicate better performance. The table shows that MOLE consistently outperforms the baseline models on both benchmarks, demonstrating its effectiveness in human-centric image generation. Results are shown for MOLE using both Stable Diffusion v1.5 and SDXL as base models.
In-depth insights#
Low-rank Experts#
The concept of “Low-rank Experts” in the context of a text-to-image diffusion model suggests a strategy to improve the generation of specific, intricate details, such as faces and hands. Instead of training a massive, monolithic model to master all aspects of image generation, the approach focuses on creating specialized, smaller models (experts) to handle these challenging areas. The “low-rank” aspect refers to using efficient matrix decompositions to reduce the computational cost and memory footprint associated with these expert models. This modularity allows for independent training and refinement of each expert, promoting better performance and easier adaptation to new datasets or styles. The experts can then be integrated into a larger diffusion model, potentially using a gating mechanism to selectively activate them depending on the input prompt. This is a beneficial method as it allows for enhanced detail and specialization without the computational overload of training a single, excessively large model. Such an approach also improves flexibility; new experts can be added relatively easily to extend the model’s capabilities to different image components. This is a compelling concept for creating more nuanced, high-quality human-centric images.
Human-centric Data#
The effectiveness of human-centric text-to-image models hinges on the quality and comprehensiveness of their training data. A dataset exclusively focused on humans, particularly their faces and hands, presents several challenges. High-resolution images are crucial for capturing fine details, and diversity in terms of age, gender, race, and activities is paramount to avoid biases and ensure realistic outputs. Close-up datasets of faces and hands can further aid in generating highly accurate and lifelike details. However, creating such a dataset requires careful ethical considerations and adherence to privacy regulations. Obtaining informed consent from subjects is essential, and ensuring the data is appropriately licensed and ethically sourced will prevent potential legal issues and promote responsible AI development. Therefore, the creation of a human-centric dataset involves a delicate balance between data quality, diversity, and ethical conduct. Furthermore, handling the inherent biases in existing datasets, such as overrepresentation of certain demographics, needs to be addressed to ensure fairness and inclusivity in the generated images.
MoLE Framework#
The MoLE (Mixture of Low-rank Experts) framework presents a novel approach to enhancing human-centric text-to-image generation. It leverages the power of low-rank modules, trained on specialized close-up datasets of faces and hands, to act as experts within a Mixture of Experts (MoE) architecture. This allows the model to adaptively refine specific image regions, addressing a key limitation of existing diffusion models: the struggle to generate natural-looking faces and hands. The framework’s soft assignment mechanism enables flexible activation of multiple experts simultaneously, capturing both global and local context within an image. This modularity provides a scalable and efficient way to improve human-centric image generation, which is further enhanced by the use of a large, high-quality human-centric dataset. The effectiveness of MoLE is demonstrated through comprehensive quantitative and qualitative evaluations, showing consistent improvements over state-of-the-art models. This framework represents a significant step toward generating more realistic and detailed human-centric images.
Ablation Studies#
Ablation studies systematically remove components of a model or system to determine their individual contributions. In the context of a research paper, a well-executed ablation study helps isolate the impact of specific elements, validating design choices and demonstrating the necessity of each component for optimal performance. By progressively removing parts, researchers can pinpoint critical factors that drive success, demonstrating their effects. A strong ablation study should explore a range of configurations, carefully controlling the variables to avoid confounding effects and ensuring the results are statistically significant. The findings contribute to a deeper understanding of the model’s inner workings and suggest avenues for future improvements by highlighting critical components versus less-important ones. For example, by removing a feature and seeing a significant drop in performance, the study would robustly validate the importance of that feature. Conversely, minimal change suggests redundancy or areas for potential simplification. Therefore, ablation studies are crucial for assessing model robustness and generalization, ultimately enhancing the overall reliability and interpretability of the model.
Future Work#
The ‘Future Work’ section of this research paper would ideally address several key limitations and promising avenues for improvement. Expanding the dataset to include more diverse subjects and scenarios is crucial, especially given the current model’s limitations with images involving multiple individuals. Addressing the model’s occasional generation of unrealistic or poorly-rendered features warrants further investigation, possibly through analysis of attention mechanisms, refinement of loss functions, or exploration of alternative architectural designs. Improving the model’s robustness to noisy or low-quality input is also important, along with expanding the range of applications beyond the current focus. Finally, evaluating the model’s fairness and potential biases and developing mitigation strategies would be a significant step towards responsible deployment. Further research should also investigate the scalability of the methods to handle even larger datasets and more complex scenes. These avenues for future research promise substantial improvements to the capabilities and reliability of human-centric text-to-image generation.
More visual insights#
More on figures

This figure demonstrates the concept of low-rank refinement which inspires the Mixture of Low-rank Experts (MoLE) method. Two low-rank modules are trained separately on face and hand datasets (Celeb-HQ and 11k Hands datasets). When applied to an image at the appropriate scale, these modules refine the corresponding face and hand regions respectively, showing improved realism. This observation forms the foundation for using low-rank modules as experts in the MoLE model, which adaptively refines specific image parts.

This figure shows examples of images from the three subsets of the human-centric dataset used in the paper: human-in-the-scene images, close-up face images, and close-up hand images. The human-in-the-scene images show people in a variety of settings and activities, while the close-up images focus on facial features and hand gestures. The diversity in pose, activity, and background is highlighted to showcase the variety within the dataset.

This figure compares the performance of four different image captioning models: BLIP2, ClipCap, MiniGPT-4, and LLaVA. Each model is given the same image and asked to generate a caption. The figure shows that LLaVA produces the most accurate and detailed captions, while the other models often make mistakes or provide less detail. Because of this, the authors choose LLaVA to caption their dataset.
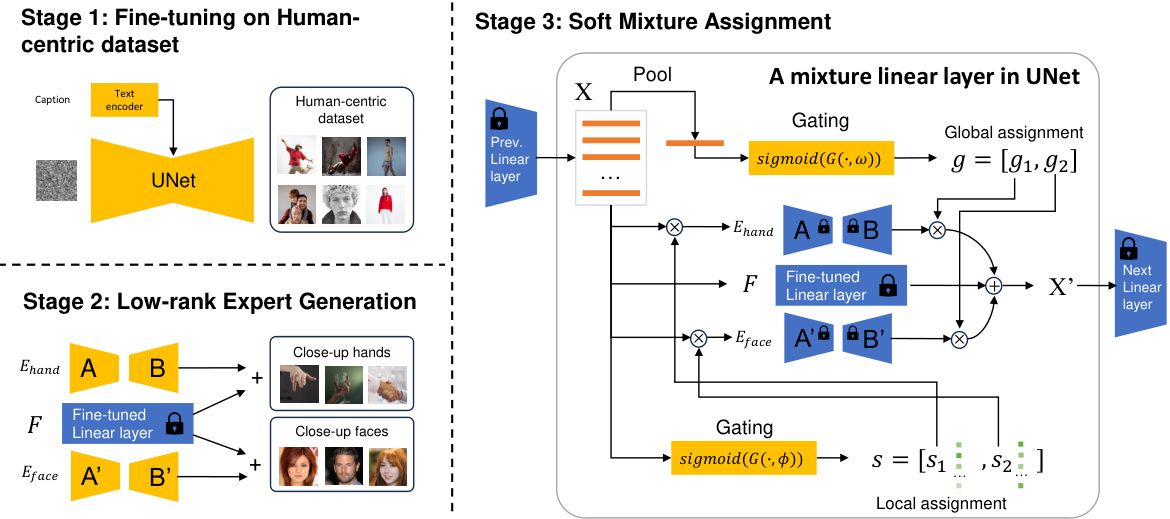
This figure illustrates the framework of the Mixture of Low-rank Experts (MoLE) method. It shows three stages. Stage 1 involves fine-tuning a UNet on a human-centric dataset. Stage 2 trains two separate low-rank experts, one for faces and one for hands, using close-up datasets. Stage 3 incorporates a soft mixture assignment mechanism within the UNet, combining the outputs of the low-rank experts based on both global and local gating networks to adaptively refine the generation process. The figure highlights the key components, including the input (X), UNet layers, low-rank modules (A, B, A’, B’), gating networks, and the final output (X’).
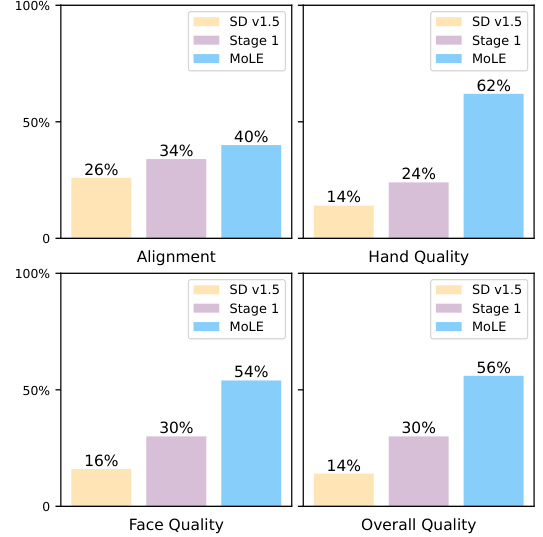
The figure shows the results of a user study evaluating the performance of the MoLE model in four aspects: alignment, hand quality, face quality, and overall quality. The bar chart visually compares the performance of different models, including SD v1.5, Stage 1 (fine-tuning on the human-centric dataset), and the MoLE model itself. Each bar represents the percentage of users who rated the corresponding model as superior in that particular aspect. The results highlight the improvement achieved by MoLE over the baseline SD v1.5 model and the intermediate stage of fine-tuning.

This figure shows the results of image generation at different stages of the MOLE model. The top row shows images generated using the prompt ‘a woman in a purple top pulling food out of an oven.’ The bottom row shows images generated using the prompt ‘smiling woman in red top putting items in a box.’ Each column represents a different stage of the MOLE process: SD v1.5 (the base model), Stage 1 (fine-tuning on the human-centric dataset), Stage 2 (low-rank expert generation), and MOLE (the final model). The figure visually demonstrates the improvement in image quality and realism achieved by each stage of the MOLE process, particularly in the details of the woman’s face and hands.
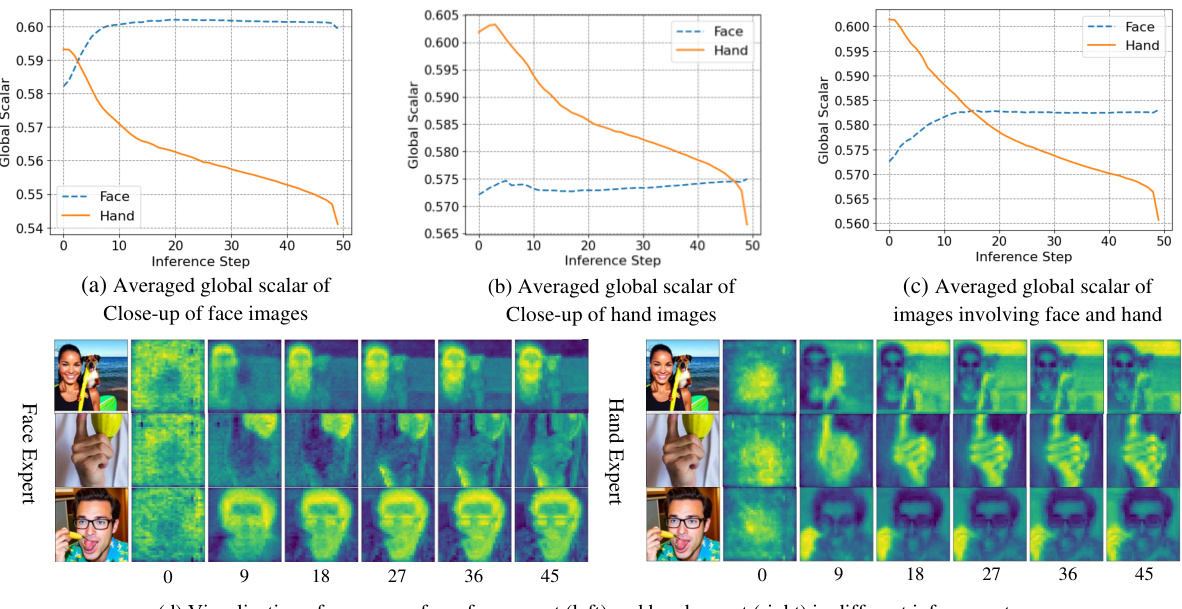
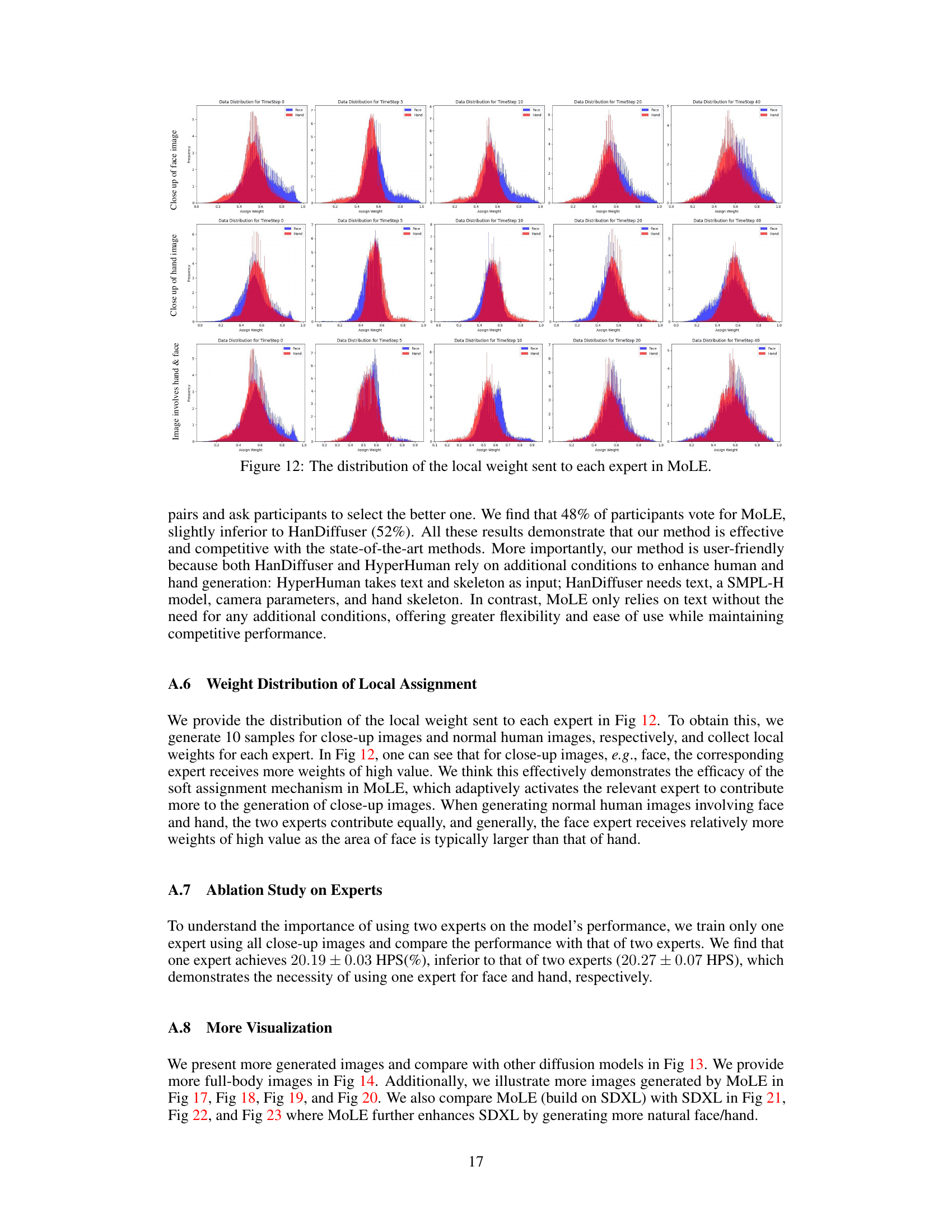
This figure visualizes the behavior of global and local assignment weights in MoLE during the image generation process. Panel (a) shows the average global scalar for close-up face images, (b) for close-up hand images, and (c) for images containing both. Panel (d) shows heatmaps of the local assignment weights for both the face and hand experts over different inference steps. The results demonstrate that the global assignment weights are content-aware, prioritizing the relevant expert based on the image content. Local assignment weights dynamically adjust, refining details over the steps.

This figure shows examples of images from the human-centric dataset used in the paper. The dataset is divided into three subsets: human-in-the-scene images (showing people in various settings), close-up face images, and close-up hand images. This diversity in the dataset is intended to improve the model’s ability to generate realistic human-centric images.

This figure shows a comparison of images generated by MoLE and HyperHuman, a state-of-the-art method, to highlight the superior quality of MoLE’s human-centric image generation. Each pair of images shows the same prompt being applied to both models, allowing for a direct visual assessment of the differences in image quality. MoLE’s images often display more realistic features, especially in the faces and hands, showcasing its ability to create more natural and lifelike results.

This figure provides a visual comparison of image generation results between the proposed MoLE model and the HanDiffuser model. Three example prompts are used: 1. A woman showing thumbs-up gesture. 2. A man in a suit holding a card. 3. A disappointed man wearing a camera. Each row shows the result of the corresponding prompt generated by each model, allowing a direct comparison of their respective image generation capabilities.

This figure visualizes the global and local assignment weights used in the MoLE model during different inference steps. The graphs show the averaged global scalar values for close-up face images, close-up hand images, and images containing both faces and hands. Additionally, it includes a visualization of the score maps from the face and hand experts at various inference steps to illustrate how the model focuses on different aspects of the image as the generation progresses. The changing values of the global and local weights indicate the adaptive activation of the face and hand experts during the image generation process.
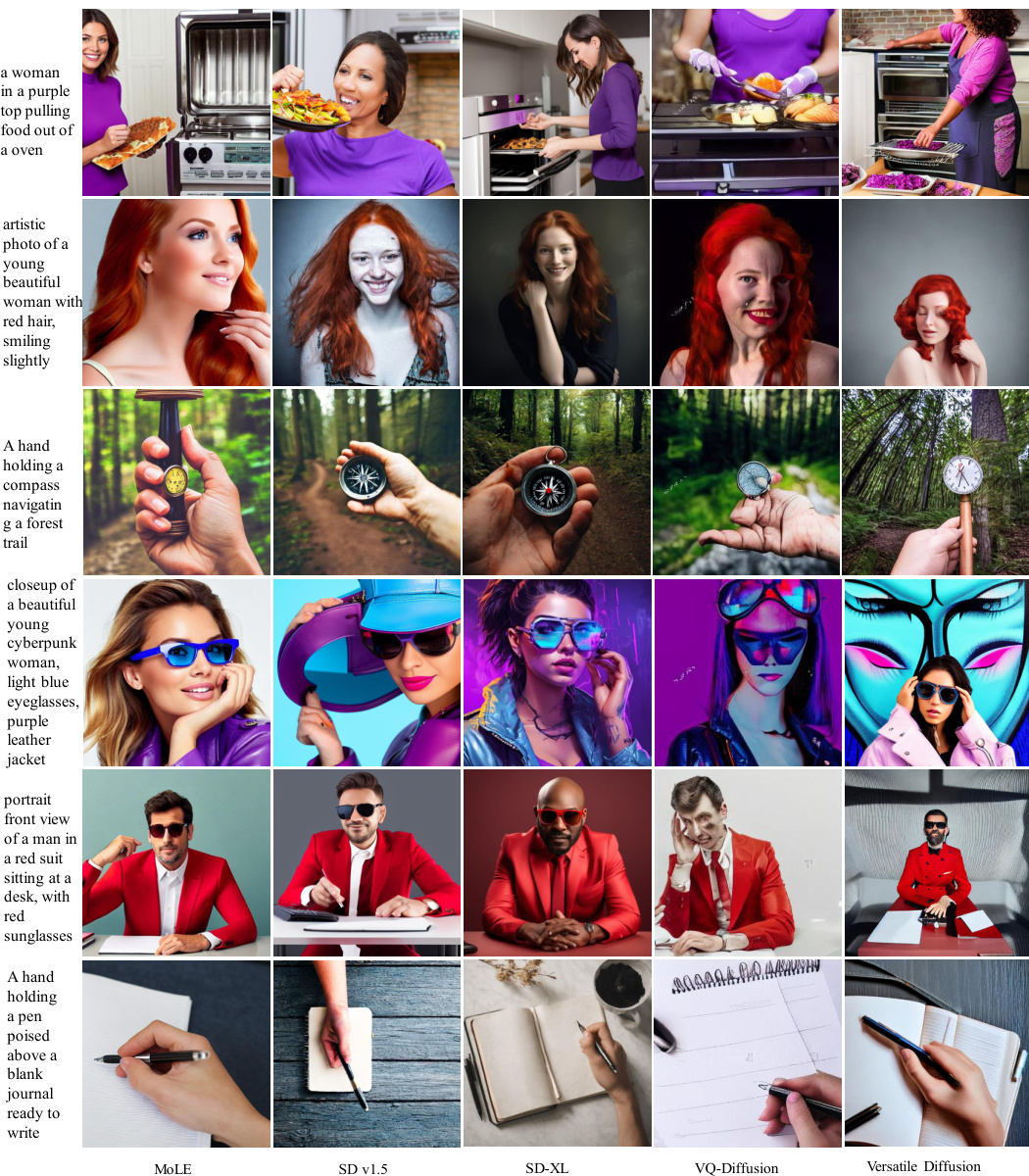
This figure compares the image generation results of MoLE with four other state-of-the-art diffusion models: SD v1.5, SD-XL, VQ-Diffusion, and Versatile Diffusion. The comparison focuses on the generation of human-centric details, particularly faces and hands. The user is encouraged to zoom in to better appreciate the differences in image quality and realism, especially regarding the detail and naturalness of the faces and hands generated by each model. MoLE aims to improve the generation of these fine details, which often present challenges for diffusion models.

This figure compares the image generation capabilities of MoLE with other state-of-the-art diffusion models such as SD v1.5, SDXL, VQ-Diffusion, and Versatile Diffusion. For a given text prompt, each model generates an image. The figure visually demonstrates the differences in image quality, detail, and overall realism across these models. The comparison highlights MoLE’s improved ability to generate high-quality, detailed images, especially in human-centric scenes.
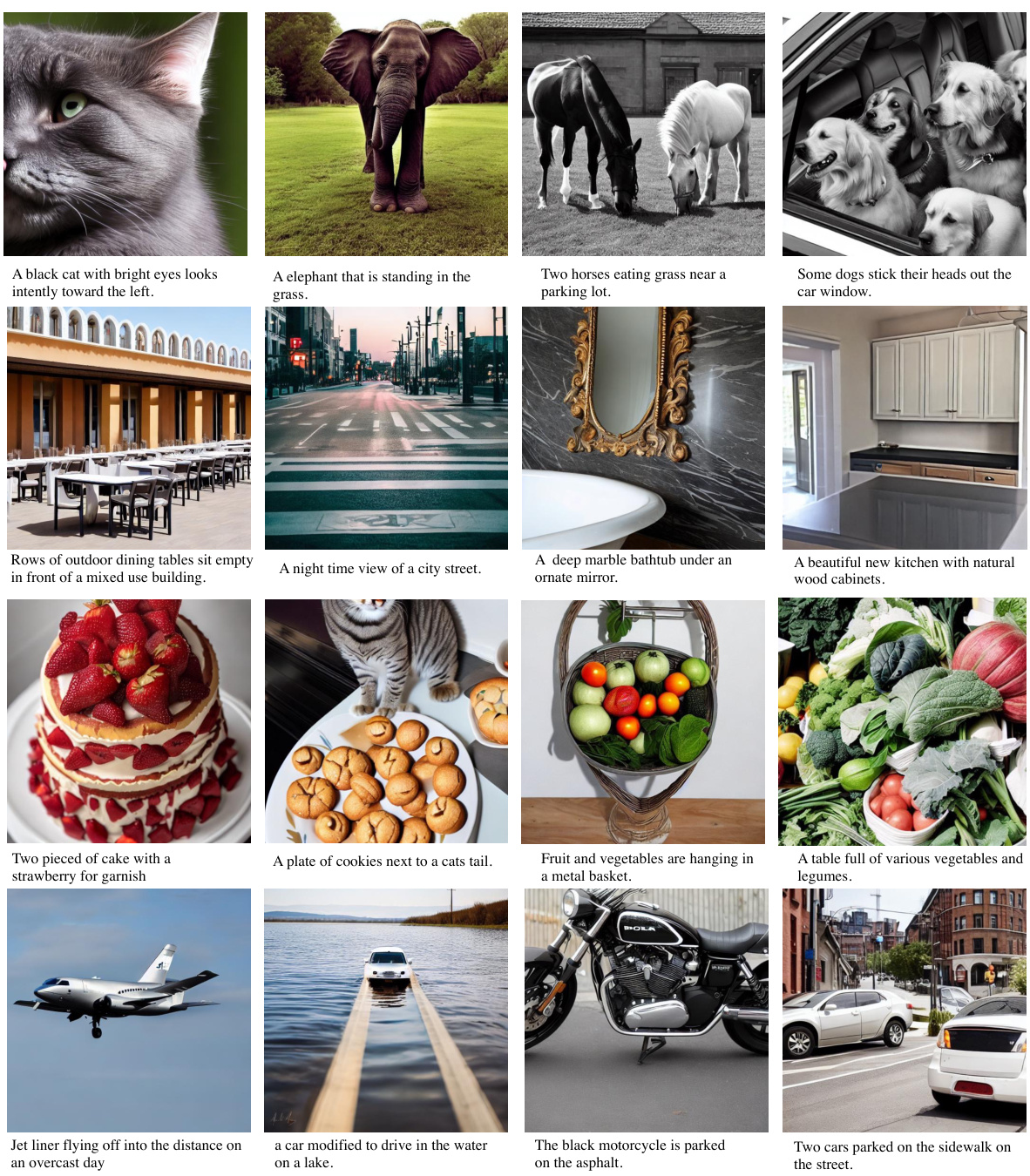
This figure compares the image generation results of MoLE with other state-of-the-art diffusion models, such as Stable Diffusion v1.5, SD-XL, and VQ-Diffusion. The focus is on the detail and realism of generated faces and hands. The prompt used to generate each image is displayed above each image. Zooming in reveals the subtle differences in detail, particularly in the rendering of faces and hands.

This figure compares the image generation results of MoLE with other state-of-the-art diffusion models, namely Stable Diffusion v1.5, SD-XL, VQ-Diffusion, and Versatile Diffusion. The comparison focuses on human-centric details, particularly the faces and hands, highlighting MoLE’s ability to generate more natural and realistic representations of these features compared to existing methods. The caption encourages viewers to zoom in for a closer examination of the facial and hand details.
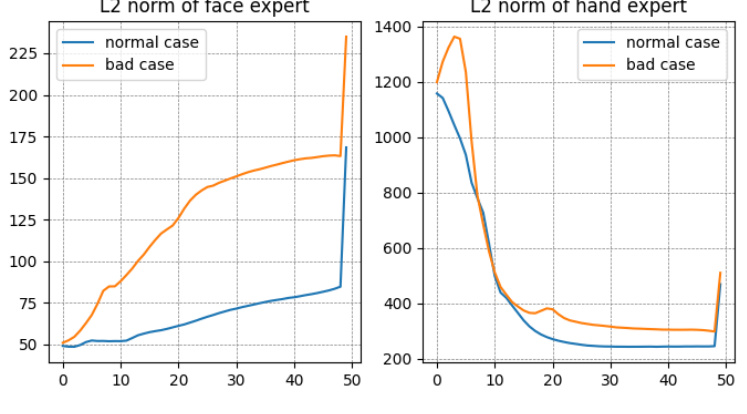
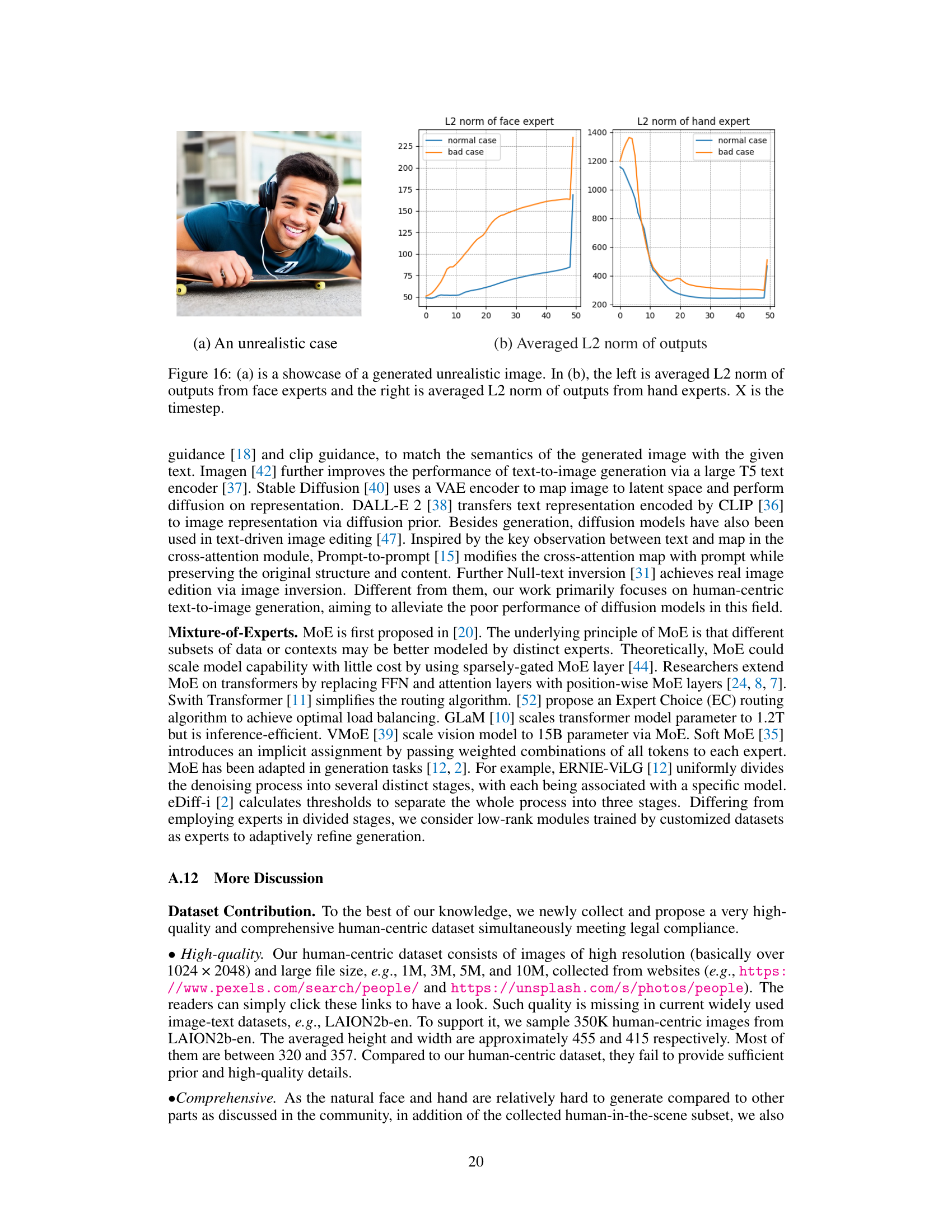
Figure 16(a) shows an example of an unrealistically generated image, which demonstrates a failure case of the MoLE model. Figure 16(b) presents a visualization of the average L2 norm of the outputs from face and hand experts over different timesteps. The left panel displays the average L2 norm from the face expert, while the right panel shows the average L2 norm from the hand expert. Comparing the L2 norms between successful and failed image generation helps analyze the model’s behavior and identify potential causes of failure. The x-axis represents timestep during image generation, while the y-axis represents the L2 norm of the expert’s output.

This figure compares the image generation capabilities of MoLE with other state-of-the-art diffusion models, such as Stable Diffusion v1.5, SD-XL, and VQ-Diffusion. The focus is on the detail and realism of generated faces and hands. The user is encouraged to zoom in for a closer look at the details to better appreciate the differences in quality.

This figure compares the image generation capabilities of MoLE with several other popular diffusion models, namely Stable Diffusion v1.5, SD-XL, VQ-Diffusion, and Versatile Diffusion. The images generated by each model are displayed side-by-side for a direct comparison, focusing on the details of the faces and hands. The caption suggests that viewers should zoom in to appreciate the differences more clearly.

This figure compares the image generation results of MoLE with other state-of-the-art diffusion models, such as Stable Diffusion v1.5, SD-XL, VQ-Diffusion, and Versatile Diffusion. The prompts used are not explicitly stated in the caption, but they are focused on human-centric details. The main point of the comparison is to highlight MoLE’s superior ability to generate more natural-looking faces and hands. The instruction to ‘zoom in for a better view’ emphasizes the fine details generated by the different models, particularly in the challenging areas of face and hand rendering.

This figure shows examples of images from the three subsets that constitute the human-centric dataset used in the paper. The first row shows human-in-scene images. The second and third rows display close-up images of faces and hands, respectively, highlighting the diversity and quality of the data used to train the model.

This figure compares the image generation results of MoLE with other state-of-the-art diffusion models, namely SD v1.5, SD-XL, VQ-Diffusion, and Versatile Diffusion. The prompts used for image generation are not specified in the caption, but the focus is on a detailed comparison of the generated faces and hands. The authors suggest zooming in to better appreciate the differences in the level of detail and realism achieved by each model. MoLE aims to improve the realism and naturalness of human-centric image generation, particularly in the finer details of faces and hands.

This figure compares the image generation results of MoLE with other state-of-the-art diffusion models, namely SD v1.5, SD-XL, VQ-Diffusion, and Versatile Diffusion. The comparison focuses on the detail and realism of generated faces and hands, highlighting MoLE’s superior performance in these aspects. The instruction is to zoom in to better appreciate the differences. The prompts used to generate these images are not provided in the caption.

This figure compares the image generation results of MoLE with other state-of-the-art diffusion models, such as Stable Diffusion v1.5, SD-XL, and VQ-Diffusion. The focus is on the detail and quality of the generated faces and hands. The caption encourages the viewer to zoom in for a closer inspection, highlighting that MoLE produces more realistic and natural-looking faces and hands compared to the other models.

This figure showcases examples from the three subsets of the human-centric dataset used in the MoLE paper. The first row shows images of people in various scenes, providing context and diversity of human activities. The second row displays close-up images of faces, highlighting the variations in facial features. The third row shows images of hands, emphasizing the range of hand positions and gestures. The diversity in these images is crucial for training the low-rank experts and enhancing the human-centric image generation quality.

This figure compares the image generation results of MoLE with several other state-of-the-art diffusion models, including Stable Diffusion v1.5, SD-XL, VQ-Diffusion, and Versatile Diffusion. The comparison focuses on the quality of generated faces and hands, highlighting MoLE’s ability to produce more realistic and natural-looking results in these areas. The caption encourages the viewer to zoom in for a closer examination of the details, especially facial features and hands.

This figure compares the image generation results of MoLE with several other diffusion models, including Stable Diffusion v1.5, Stable Diffusion XL, VQ-Diffusion, and Versatile Diffusion. The comparison focuses particularly on the detail and naturalness of generated faces and hands. The user is prompted to zoom in for a better view to appreciate the differences more fully. The images demonstrate MoLE’s superior performance in generating human-centric details.

This figure shows examples of images from the three subsets of the human-centric dataset: human-in-the-scene images, close-up face images, and close-up hand images. The purpose is to illustrate the diversity and high quality of images in the dataset, showing various poses, activities, backgrounds, and ages of people. The close-up images highlight the detail captured, which is crucial for training the low-rank experts in the MoLE model.

This figure shows examples from the three subsets of the human-centric dataset: human-in-the-scene images, close-up face images, and close-up hand images. The images demonstrate the diversity of the dataset in terms of poses, activities, backgrounds, and demographics.

This figure compares the image generation capabilities of MoLE against several other state-of-the-art diffusion models. The comparison focuses specifically on the generation of human faces and hands. Each model was prompted to generate images based on the same text prompt, which is not specified in the image itself, though it’s implied to be human centric. The images demonstrate how MoLE excels in generating more realistic and natural-looking faces and hands, showcasing its strengths in human-centric image generation. Users are encouraged to zoom in to appreciate the details better.

This figure shows a comparison of image generation results between MoLE and other state-of-the-art diffusion models, such as Stable Diffusion v1.5, SD-XL, VQ-Diffusion, and Versatile Diffusion. The comparison focuses on the generation of human-centric details, particularly faces and hands. The authors encourage viewers to zoom in on the images to observe subtle differences in detail and naturalness.

This figure compares the image generation results of MoLE with other state-of-the-art diffusion models, such as Stable Diffusion v1.5, SD-XL, and VQ-Diffusion. The comparison focuses particularly on the generation quality of human faces and hands. The user is encouraged to zoom in on the images for a more detailed examination of the differences.

This figure compares the image generation capabilities of the MoLE model with other state-of-the-art diffusion models, specifically focusing on the detail and realism of generated faces and hands. The images demonstrate that MoLE produces superior results in terms of naturalness and detail, especially when compared to the faces and hands generated by other models.

This figure compares the image generation results of MoLE with other state-of-the-art diffusion models, namely SD v1.5, SD-XL, VQ-Diffusion, and Versatile Diffusion. The prompts used for image generation are provided above each image. The figure emphasizes the detail in the face and hands, suggesting that MoLE produces more realistic and detailed results in these areas compared to other models. The instruction to ‘zoom in for a better view’ highlights the focus on fine-grained details.

This figure compares the image generation capabilities of the MoLE model with other state-of-the-art diffusion models, such as SD v1.5, SD-XL, VQ-Diffusion, and Versatile Diffusion. The comparison focuses on the detail and realism of generated human faces and hands. The user is encouraged to zoom in for a more detailed view to appreciate the differences in quality. MoLE is shown to generate more realistic and detailed human faces and hands than the other models.

This figure compares the image generation capabilities of the proposed MoLE model with other state-of-the-art diffusion models, such as Stable Diffusion v1.5, SD-XL, VQ-Diffusion, and Versatile Diffusion. The focus is on human-centric details, particularly the faces and hands, highlighting how MoLE produces more realistic and natural-looking results in these areas. The caption encourages the viewer to zoom in to fully appreciate the differences.

This figure compares the image generation results of the proposed MoLE model with other existing diffusion models, such as Stable Diffusion v1.5, SD-XL, VQ-Diffusion, and Versatile Diffusion. The comparison highlights the superior performance of MoLE in generating human-centric images, particularly with respect to the details and naturalness of faces and hands. The caption encourages a closer look at the faces and hands to fully appreciate the differences.

This figure compares the image generation capabilities of the MoLE model with several other state-of-the-art diffusion models. The focus is on the quality of generated faces and hands, highlighting MoLE’s superior performance in these areas. The image shows multiple examples of prompts and the outputs generated by each model, making it easier to compare the results and appreciate the details. Users are encouraged to zoom in for a more detailed comparison.

This figure compares the image generation capabilities of the MoLE model with several other state-of-the-art diffusion models. The comparison focuses specifically on the generation of human faces and hands, highlighting MoLE’s superior ability to generate realistic and detailed features in these areas. Viewers are encouraged to zoom in on the images for a closer inspection.
More on tables
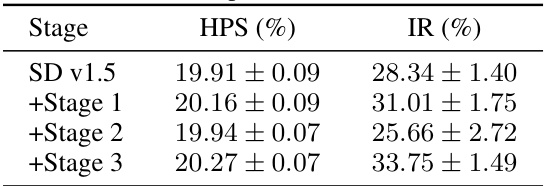
This table presents the results of an ablation study conducted on the COCO Human Prompts benchmark. The study evaluates the impact of each stage in the proposed MoLE method on the model’s performance. The metrics used are Human Preference Score (HPS) and ImageReward (IR). The rows represent different configurations of the model: SD v1.5 (baseline), SD v1.5 + Stage 1 (fine-tuning on human-centric dataset), SD v1.5 + Stage 1 + Stage 2 (adding low-rank experts), and SD v1.5 + Stage 1 + Stage 2 + Stage 3 (adding soft mixture assignment). The columns show the HPS and IR scores for each configuration. The table aims to demonstrate the contribution of each stage to the overall performance of the model.
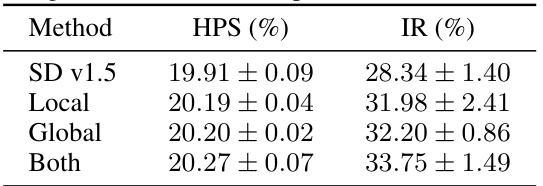
This table presents the ablation study results on different assignment manners in the MoLE model, specifically focusing on the COCO Human Prompts benchmark. It compares the performance of using only local assignment, only global assignment, and both local and global assignments. The metrics used are Human Preference Score (HPS) and ImageReward (IR), both showing how well the generated images align with human preferences. The results demonstrate the impact of incorporating both local and global assignment strategies in improving image quality compared to using only one.

This table compares the performance of MoLE and SD v1.5 on three different metrics: CLIP-T, FID, and Aesthetic Score. The CLIP-T score measures the alignment between image and text caption. FID (Fréchet Inception Distance) quantifies the similarity between the generated images and real images. Finally, Aesthetic Score evaluates the aesthetic quality of generated images. The results show that MoLE outperforms SD v1.5 on CLIP-T and FID but performs slightly worse on Aesthetic Score.
Full paper#