↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Current perception models struggle with open-world scenarios, where unseen objects lack predefined categories. Existing methods, such as open-set and open-ended approaches, fall short due to limitations in object recognition and localization. Open-set methods require predefined object categories, hindering real-world applicability. Open-ended methods, while more general, often lack accuracy in object localization.
This paper introduces VL-SAM, a training-free framework addressing these challenges. VL-SAM cleverly combines a generalized object recognition model (Vision-Language Model) and a generalized object localization model (Segment-Anything Model) using attention maps as prompts. This innovative approach enables the system to detect and segment unseen objects without the need for retraining or pre-defined categories, yielding high-quality results on benchmark datasets like LVIS and CODA. The iterative refinement pipeline further improves accuracy by addressing limitations in initial segmentations.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a training-free framework for open-ended object detection and segmentation, a crucial step towards more robust and adaptable AI systems. It combines existing generalized models (Vision-Language Model and Segment-Anything Model) to achieve state-of-the-art results without requiring additional training, making it both efficient and accessible to researchers. The approach opens avenues for future research in open-world perception.
Visual Insights#

The figure illustrates the VL-SAM framework, which combines a vision-language model (VLM) and a segment-anything model (SAM) without any additional training. The VLM processes the image input and generates an attention map highlighting potential objects. This attention map serves as a prompt for the SAM, which then performs object detection and segmentation. An iterative refinement process further refines the results using the SAM’s output to improve the attention map and subsequent segmentation.
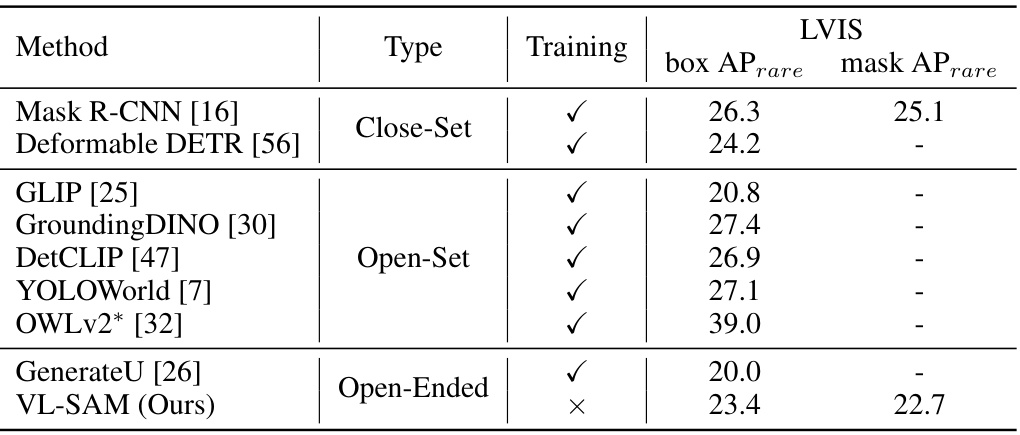
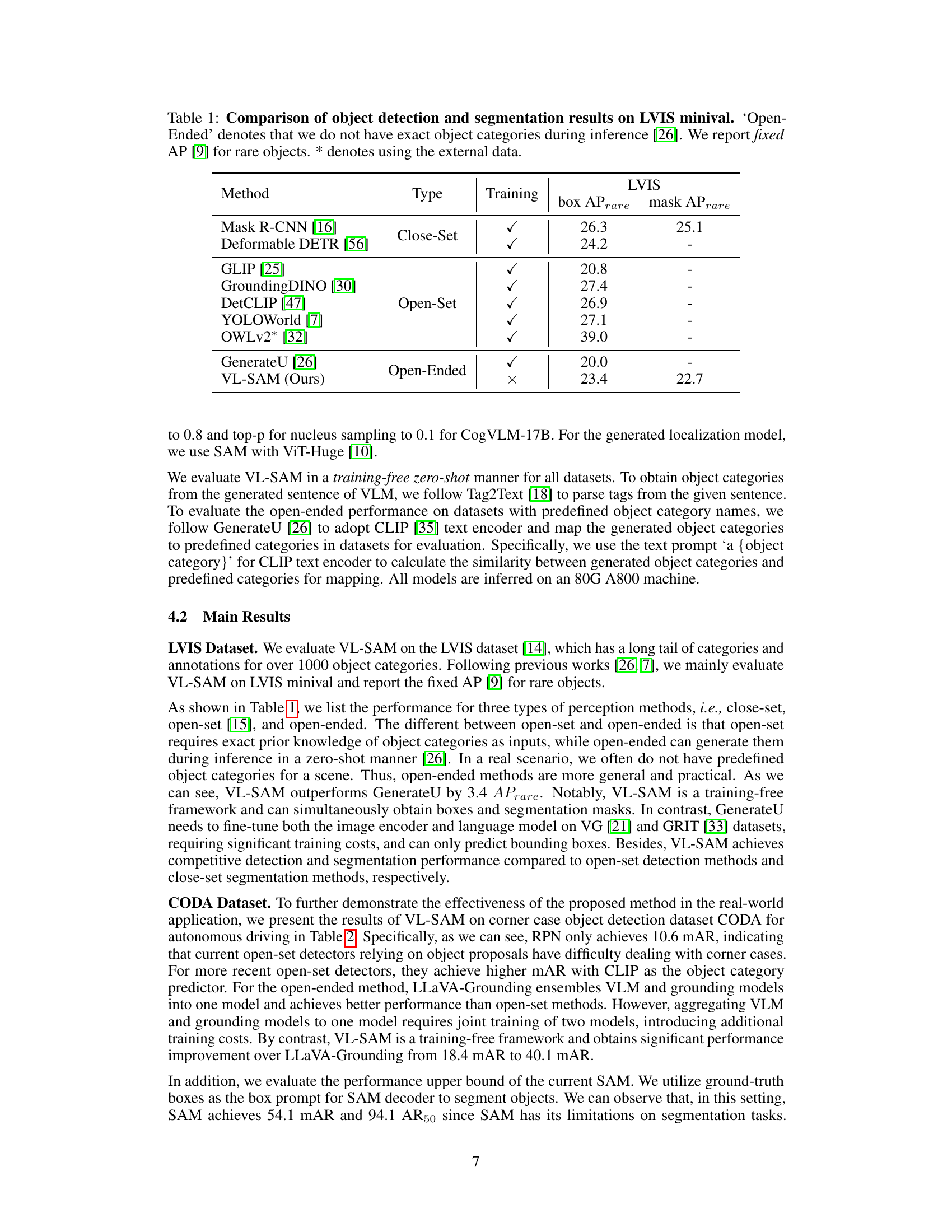
The table compares the performance of various object detection and segmentation methods on the LVIS minival dataset. It breaks down methods into three categories: Close-Set, Open-Set, and Open-Ended, highlighting the difference in their requirements for object category information during inference. The results are presented in terms of box APrare and mask APrare (Average Precision for rare objects) to focus on the model’s ability to handle less frequently seen classes. The table also notes which methods used external data during training.
In-depth insights#
Attention-Prompting#
Attention-prompting, as a concept, presents a novel approach to bridging the gap between generalized object recognition models and precise object localization. By utilizing attention maps generated from Vision-Language Models (VLMs) as prompts for a segmentation model like Segment-Anything Model (SAM), it bypasses the need for explicit object category labels during inference, making the system adaptable to open-ended scenarios. This training-free methodology is particularly beneficial for handling unseen objects or complex scenes where pre-defined object categories are unavailable. The efficacy of the approach hinges on the quality of attention maps—carefully designed modules for head aggregation and regularized attention flow are crucial in generating high-quality prompts. Iterative refinement of the segmentation process, using previous results to further refine attention-based prompts, enhances the overall accuracy and robustness of the system. The attention-prompting technique’s true strength lies in its ability to leverage the generalized capabilities of VLMs, which excel at broad object recognition, alongside the fine-grained localization power of SAM. However, the approach’s success also depends on the strengths of its constituent models, and limitations inherent to those models (hallucinations in VLMs, imprecise segmentation in SAM) would also carry over.
VL-SAM Framework#
The VL-SAM framework, a training-free approach for open-ended object detection and segmentation, cleverly combines two powerful pre-trained models: a Vision-Language Model (VLM) and the Segment-Anything Model (SAM). The framework’s core innovation lies in using attention maps generated by the VLM as prompts for SAM. This elegantly sidesteps the need for training data specific to the detection task, leveraging the general object recognition capabilities of VLM and the robust segmentation abilities of SAM. A key component is the attention map generation module, which aggregates and propagates attention information from all VLM heads and layers, enhancing the quality of the prompts. Further refinement occurs through an iterative refinement pipeline involving positive and negative point sampling, improving segmentation accuracy by iteratively refining attention maps and SAM inputs. This architecture demonstrates strong model generalization, being adaptable to various VLMs and SAMs, highlighting the potential for broader applications and adaptability to diverse scenarios.
Iterative Refinement#
The iterative refinement process, crucial in many computer vision tasks, is particularly important in this paper’s context of open-ended object detection and segmentation. The initial segmentation results often contain inaccuracies like rough edges or background noise. The iterative refinement strategy addresses these issues by repeatedly refining the segmentation masks using information from the previous iteration. This iterative approach leverages the attention maps to sample positive and negative points, thereby guiding the model to focus on areas needing improvement. This two-pronged iterative approach, involving both cascaded refinement and attention map masking, is a core strength of this method. It demonstrates a sophisticated approach to problem-solving and tackles the inherent uncertainties associated with open-ended object discovery. The effectiveness of this iterative refinement is crucial to the paper’s success in achieving high-quality segmentation masks beyond the capabilities of existing methods. The cycle of generating refined prompts and obtaining improved segmentation results is not only efficient but also allows for the robust and accurate identification of objects in diverse and complex images.
Model Generalization#
The concept of ‘Model Generalization’ in the context of a research paper likely explores the model’s ability to perform well on unseen data or tasks beyond its training data. A strong model exhibits robustness and adaptability, accurately predicting outcomes in novel situations. The paper likely investigates various factors influencing generalization, including the architecture’s design, training data diversity, and regularization techniques. Empirical results demonstrating the model’s performance across different datasets and tasks would be presented to assess generalization capabilities. Further analysis might involve comparing the model’s performance against established baselines and exploring potential limitations of the model’s generalization abilities. The discussion section of the paper would likely delve into the implications of the observed generalization performance and offer suggestions for future work aiming to improve this aspect. The overall goal is to demonstrate the model’s effectiveness and reliability across a broad spectrum of applications, highlighting its practical value.
Open-Ended Vision#
Open-ended vision, a subfield of computer vision, tackles the challenge of recognizing and understanding objects without predefined categories. Unlike traditional vision systems that rely on extensive labeled data and fixed object classes, open-ended vision aims to handle novel and unexpected objects in real-world scenarios. This requires models capable of generalization and a departure from the closed-set assumptions of classical object recognition. Key approaches involve leveraging large vision-language models that can connect visual input with textual descriptions, enabling the generation of object labels and segmentation masks. The ability to learn from limited labeled data and automatically discover new classes makes open-ended vision particularly attractive for practical applications like autonomous driving, robotics, and medical image analysis. However, challenges remain in terms of robust object localization, handling ambiguous cases, and mitigating biases. Future directions include improving the efficiency of models and addressing robustness to noisy or incomplete data, ultimately moving open-ended vision closer to real-world deployment.
More visual insights#
More on figures

This figure provides a high-level overview of the VL-SAM framework. It shows how the Vision-Language Model (VLM) and Segment-Anything Model (SAM) are integrated. First, VLM processes the image and generates a list of potential objects. Then, for each object, an attention map is generated by a dedicated module that aggregates information from multiple heads and layers of the VLM. These attention maps guide SAM, which uses point sampling and iterative refinement for more accurate object detection and segmentation.
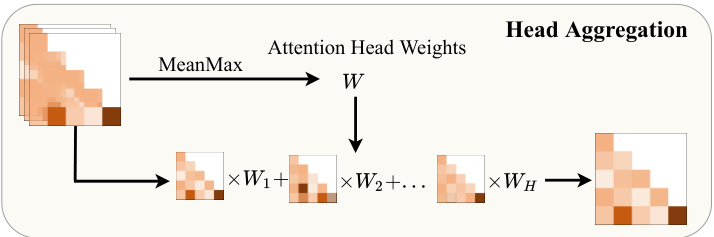
This figure illustrates the head aggregation step in the VL-SAM framework. The input is a stack of attention maps from multiple heads of the Vision-Language Model (VLM). A MeanMax operation is applied to the attention head weights to generate a single set of weights (W). These weights are then used to weight the individual attention maps from each head before they are aggregated to produce a final attention map.

This figure illustrates the attention flow mechanism used in VL-SAM. Attention maps from each layer of the Vision-Language Model (VLM) are aggregated and propagated to the next layer using a process described in equation (3). This iterative refinement helps to produce a more comprehensive and accurate attention map that highlights regions of interest for object detection and segmentation.

This figure demonstrates the attention flow mechanism in VL-SAM and the problem of attention collapse. The leftmost column shows the input image. The middle column visualizes the attention flow without regularization, exhibiting the issue of attention collapse, where attention focuses on a few areas, even though it should cover the whole image. In the rightmost column, the regularized attention flow is presented; it effectively prevents the collapse and shows an improved distribution of attention, leading to a more complete and accurate description of the scene generated by VLM. This directly impacts the quality of the prompts used for object segmentation.
More on tables
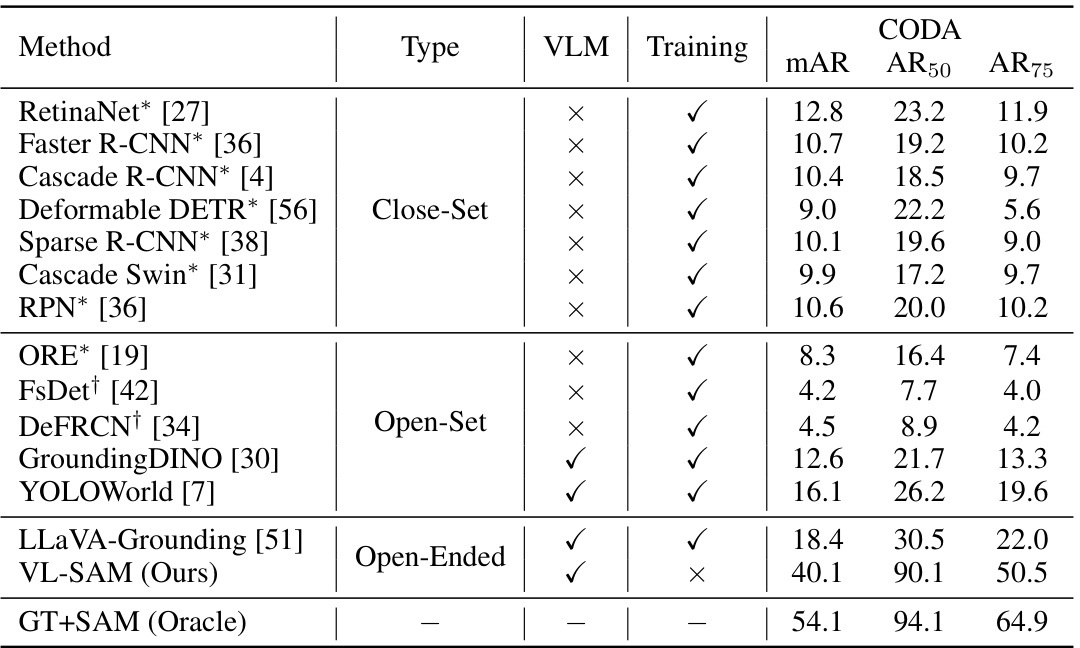
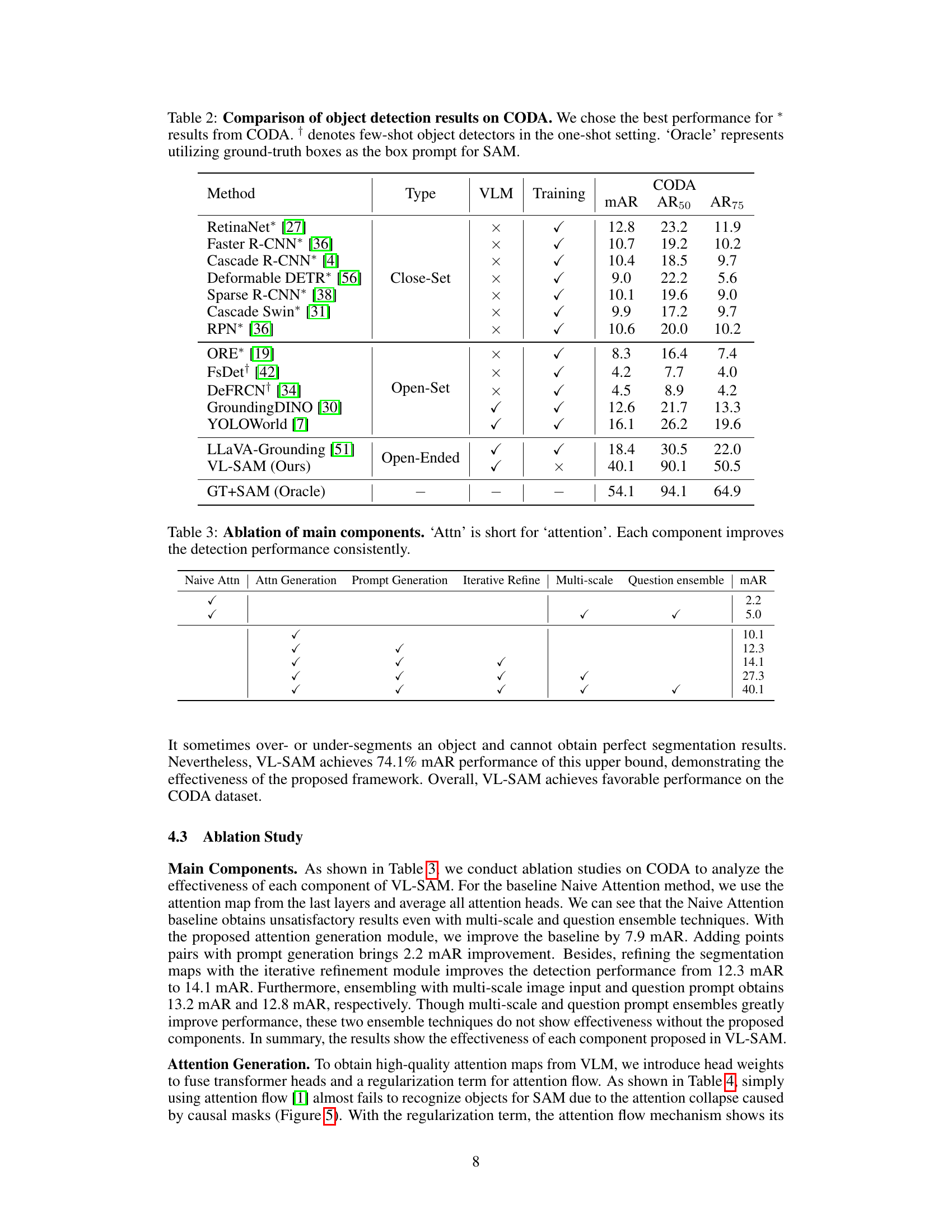
This table compares the performance of various object detection methods on the CODA dataset, focusing on the mAR (mean Average Recall), AR50 (average recall at 50% IoU), and AR75 (average recall at 75% IoU) metrics. It categorizes methods as Close-Set, Open-Set, and Open-Ended, highlighting the impact of utilizing VLMs and whether or not training is involved. The ‘Oracle’ row provides an upper bound performance using ground truth information.

This table compares the performance of various object detection and segmentation methods on the LVIS minival dataset. It categorizes methods into three types: Close-Set, Open-Set, and Open-Ended, based on whether predefined object categories are needed during inference. The table shows the box APrare and mask APrare for each method, highlighting the performance on rare object categories. The use of external data in certain methods is also indicated.
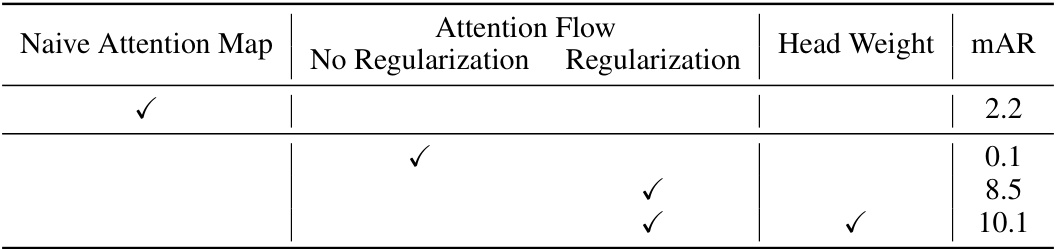
This table presents the ablation study results for the attention generation module in the VL-SAM framework. It shows the impact of different components on the model’s performance, measured by mean Average Recall (mAR) on the CODA dataset. The components include: Naive Attention Map, Attention Flow (with and without regularization), and Head Weight. The results demonstrate that using the proposed modules significantly improves the quality of generated attention maps.
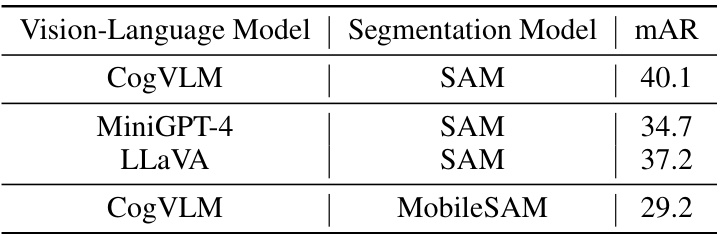
This table shows the results of using different vision-language models (CogVLM, MiniGPT-4, LLaVA) and segmentation models (SAM, MobileSAM) in the VL-SAM framework. It demonstrates the model’s generalization ability by showcasing performance variations with different combinations of these models. The mAR (mean Average Recall) metric is used to evaluate the object detection performance.
Full paper#