↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Monocular 3D human pose estimation faces the challenge of depth ambiguity, leading to inconsistencies in traditional regression models’ predictions. Standard evaluation metrics fail to capture these inconsistencies. This limitation motivates researchers to seek more robust methods.
The paper introduces ManiPose, a multi-hypothesis model that directly addresses depth ambiguity by generating multiple 3D pose candidates for each 2D input, along with their plausibility scores. Unlike previous methods, ManiPose avoids costly generative models, simplifying training and usage. Crucially, ManiPose enforces pose consistency by constraining the outputs to lie on the human pose manifold. The results show ManiPose outperforms state-of-the-art methods on real-world datasets, achieving a significant improvement in pose consistency while delivering highly competitive MPJPE scores.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in 3D human pose estimation. It addresses the persistent problem of depth ambiguity in monocular 3D HPE by proposing a novel multi-hypothesis approach. The introduction of manifold constraints ensures pose consistency, a significant improvement over traditional methods. Its superior performance on real-world datasets showcases its practical value and opens up avenues for further research in addressing depth ambiguity and improving pose consistency in related fields.
Visual Insights#

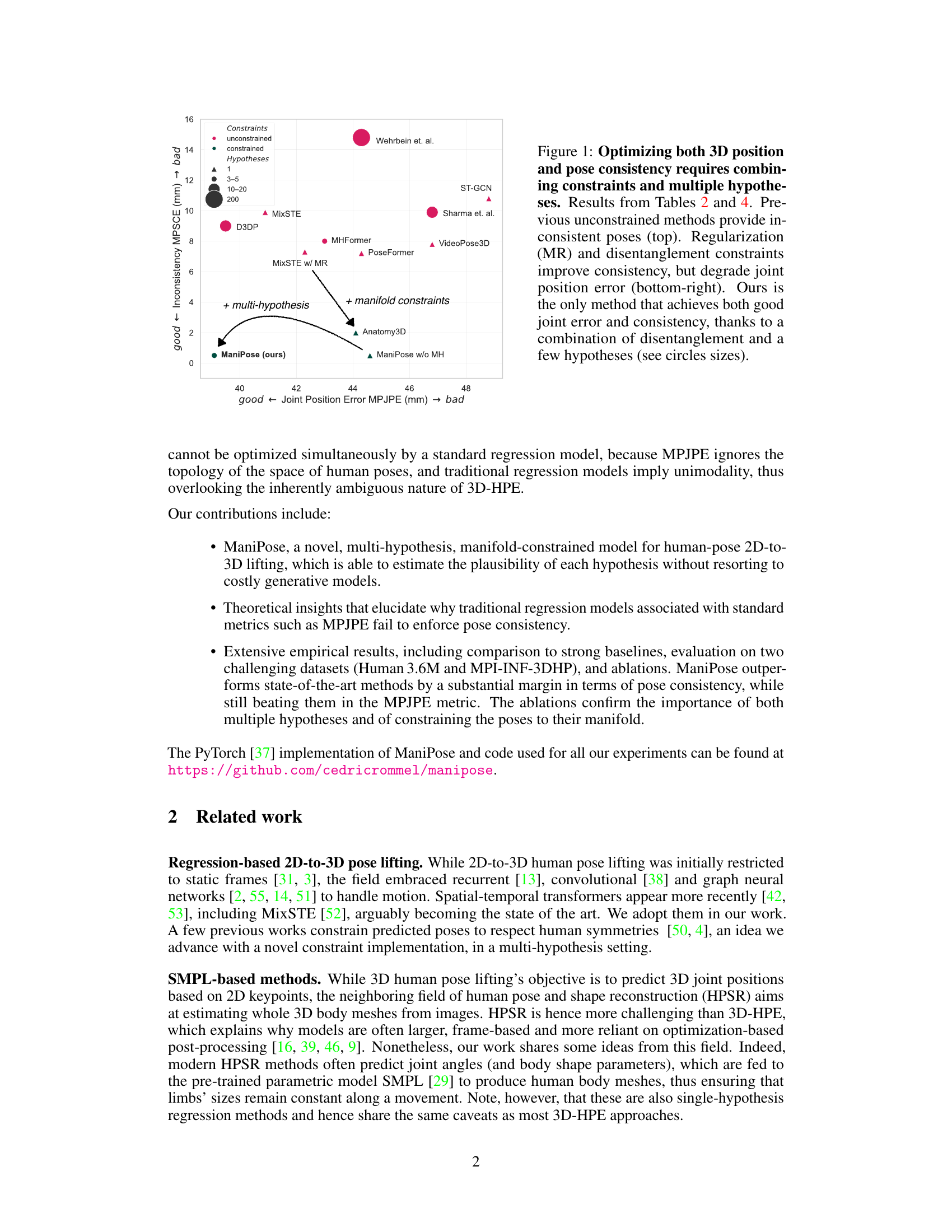
This figure shows a scatter plot comparing the performance of different methods on 3D human pose estimation. The x-axis represents the mean per-joint position error (MPJPE), a common metric for evaluating the accuracy of 3D pose estimation. The y-axis represents the mean per-segment consistency error (MPSCE), a metric introduced in the paper to evaluate the consistency of the estimated pose. The size of the points represents the number of hypotheses used by each method. The plot shows that ManiPose outperforms the state-of-the-art in terms of both MPJPE and MPSCE. It illustrates that to optimize both 3D position and pose consistency, a model requires combining constraints and using multiple hypotheses.

This table presents the quantitative results of the 1D-to-2D experiment described in Section 4.2 of the paper. Three different models (Unconstrained MLP, Constrained MLP, and ManiPose) were trained and evaluated on three different synthetic datasets with different levels of difficulty. The results are averaged over five different random seeds. The table shows the MPJPE and the distance to circle (a measure of pose consistency) for each model and dataset. The results demonstrate that ManiPose outperforms the other models in terms of both MPJPE and pose consistency.
In-depth insights#
Depth Ambiguity#
Depth ambiguity in monocular 3D human pose estimation is a fundamental challenge stemming from the fact that infinitely many 3D poses can project to the same 2D image. This ambiguity makes it difficult for traditional regression-based methods to accurately predict 3D poses because they rely on mapping 2D observations to a single 3D output. The paper addresses this by proposing a multi-hypothesis approach. Instead of predicting a single 3D pose, it generates multiple plausible candidates and assigns a confidence score to each. This strategy allows the model to explore the range of possible solutions consistent with the 2D input. The manifold constraint further enhances the model’s ability to generate realistic and physically plausible poses, reducing the likelihood of nonsensical outputs that may arise from the inherent ambiguity of the input. Multi-hypothesis methods coupled with a manifold constraint offer a robust way to address depth ambiguity, significantly enhancing the accuracy and consistency of 3D pose estimation results, as demonstrated empirically within the paper.
Manifold Constraint#
The concept of ‘Manifold Constraint’ in the context of 3D human pose estimation is crucial for addressing the inherent ambiguity of lifting 2D poses to 3D. Traditional methods often struggle with maintaining pose consistency, producing unrealistic 3D poses despite achieving good performance on standard metrics. Manifold constraints address this by restricting the predicted 3D poses to a space that reflects the realistic physical constraints of human bodies, such as consistent limb lengths and joint angles. This constraint enforces realistic pose topology, preventing nonsensical poses with impossible joint configurations. By imposing this constraint, the model outputs more biologically plausible results, leading to significantly improved pose consistency and robustness. The choice of manifold representation (e.g., SMPL) and how constraints are implemented (e.g., through regularization or explicit projection) can impact the model’s performance and complexity. The core idea is to leverage the inherent structure of the data itself to improve the accuracy and realism of the 3D pose estimation.
Multi-Hypothesis MCL#
The concept of “Multi-Hypothesis MCL” suggests a powerful approach to 3D human pose estimation, leveraging the inherent ambiguity of monocular depth. Multiple hypotheses address the depth ambiguity problem by generating several plausible 3D pose candidates for each 2D input, instead of relying on a single, potentially inaccurate, estimate. Multiple Choice Learning (MCL) provides a framework for efficiently handling these multiple hypotheses, allowing the model to learn which hypotheses are most likely to be correct for different scenarios. By combining multi-hypothesis generation with MCL, the method aims to improve accuracy and robustness by allowing the model to consider multiple possibilities and weigh their respective plausibilities. The manifold constraint further enhances this approach by ensuring that all generated hypotheses are anatomically plausible, addressing the shortcomings of traditional methods that fail to capture the inherent structure of human poses. This method combines the strengths of multi-hypothesis modeling and MCL, leading to a more robust and accurate 3D pose estimation system that accounts for the ambiguities inherent in monocular data.
Pose Consistency#
Pose consistency in 3D human pose estimation is crucial for accurate and realistic pose prediction. Traditional methods often fail to capture this, leading to unrealistic and inconsistent poses. The core problem stems from the inherent depth ambiguity in monocular vision, where multiple 3D poses can project to the same 2D image. Standard metrics like MPJPE, while useful for evaluating positional accuracy, often overlook consistency issues. This paper highlights the importance of incorporating pose consistency into the evaluation and the model’s design itself. The proposed approach, ManiPose, directly addresses this by employing a multi-hypothesis strategy and manifold constraints. By generating multiple 3D pose candidates and constraining them to the manifold of realistic human poses, ManiPose ensures that all generated poses are inherently consistent, even if individual poses differ slightly in their predicted positions. This leads to significant improvements in pose consistency compared to state-of-the-art methods, demonstrating that considering pose consistency is critical for generating truly realistic and meaningful 3D human pose estimates.
Future Directions#
Future research could explore several promising avenues. Improving efficiency is crucial; the sequential nature of forward kinematics limits ManiPose’s speed. Investigating alternative representations or architectures could significantly enhance performance. Expanding the model’s capabilities is also important; incorporating articulation limits and more nuanced handling of occlusions would make it more robust. Exploring different loss functions could further refine the trade-off between accuracy and consistency. Finally, assessing ManiPose’s performance on diverse datasets is essential to evaluate its generalizability and identify potential weaknesses. Addressing these areas will solidify ManiPose’s position as a leading method and further advance the field of 3D human pose estimation.
More visual insights#
More on figures
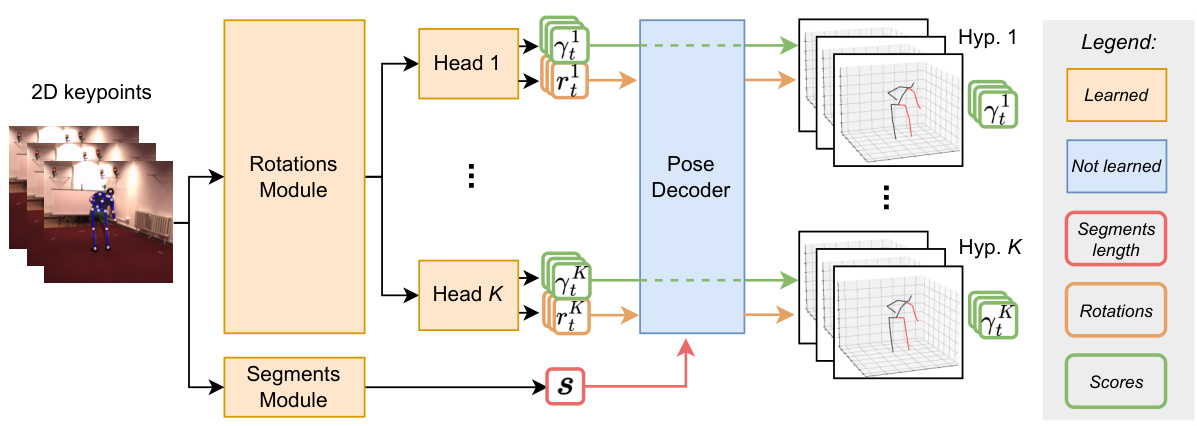
The figure shows an overview of the ManiPose architecture. It consists of two main modules: a rotations module and a segments module. The rotations module predicts multiple possible sequences of segment rotations (K hypotheses), each with an associated likelihood score. The segments module estimates the lengths of the segments, which are shared across all hypotheses. The pose decoder combines these rotation sequences and segment lengths to generate K consistent 3D pose hypotheses, ensuring that all predicted poses respect human anatomy and are consistent. The output is the K hypotheses of the 3D poses and their corresponding likelihood scores.

The figure shows the process of pose decoding in ManiPose. It starts with a unit reference pose that is scaled using predicted segment lengths. Then, predicted rotation representations are converted into rotation matrices. Finally, forward kinematics is applied to obtain the predicted movement.

This figure illustrates the limitations of single-hypothesis models for pose estimation, especially in scenarios with depth ambiguity. Panel (A) shows a simplified 1D-to-2D pose lifting problem. Panel (B) demonstrates that minimizing mean squared error (MSE) leads to inconsistent predictions. Panel (C) shows that unconstrained models work well in simple, unimodal situations. Panel (D) demonstrates that in a complex, multimodal scenario (with depth ambiguity), only multi-hypothesis approaches provide consistent and accurate solutions.

This figure shows the comparison of the performance of MixSTE and ManiPose in terms of MPSCE, MPSSE, and MPJPE per segment and coordinate. The results demonstrate that ManiPose significantly improves pose consistency, particularly in the z-coordinate (depth), while maintaining competitive performance in terms of MPJPE. The figure uses a bar chart to compare the three metrics for each segment, highlighting the improvement of Manipose over MixSTE. The lower part of the figure shows the 3D human skeleton, with segments highlighted in different colors.
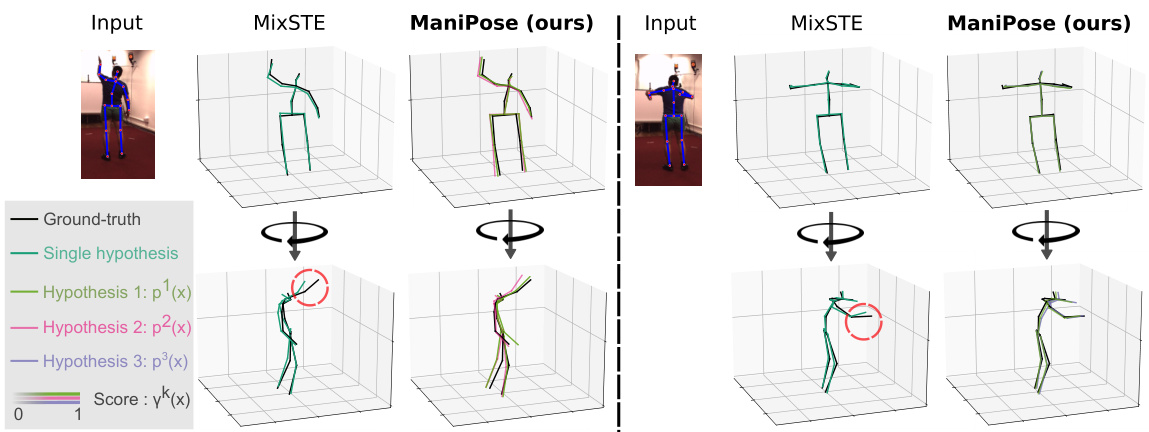
This figure compares the performance of ManiPose and MixSTE on two examples. It shows that ManiPose, using multiple hypotheses and manifold constraints, produces more accurate and consistent 3D pose estimations, especially in handling the inherent depth ambiguity of monocular 3D human pose estimation. MixSTE’s single hypothesis approach struggles with depth ambiguity, resulting in less accurate and inconsistent results, as shown by the shorter limbs and less consistent pose estimations.
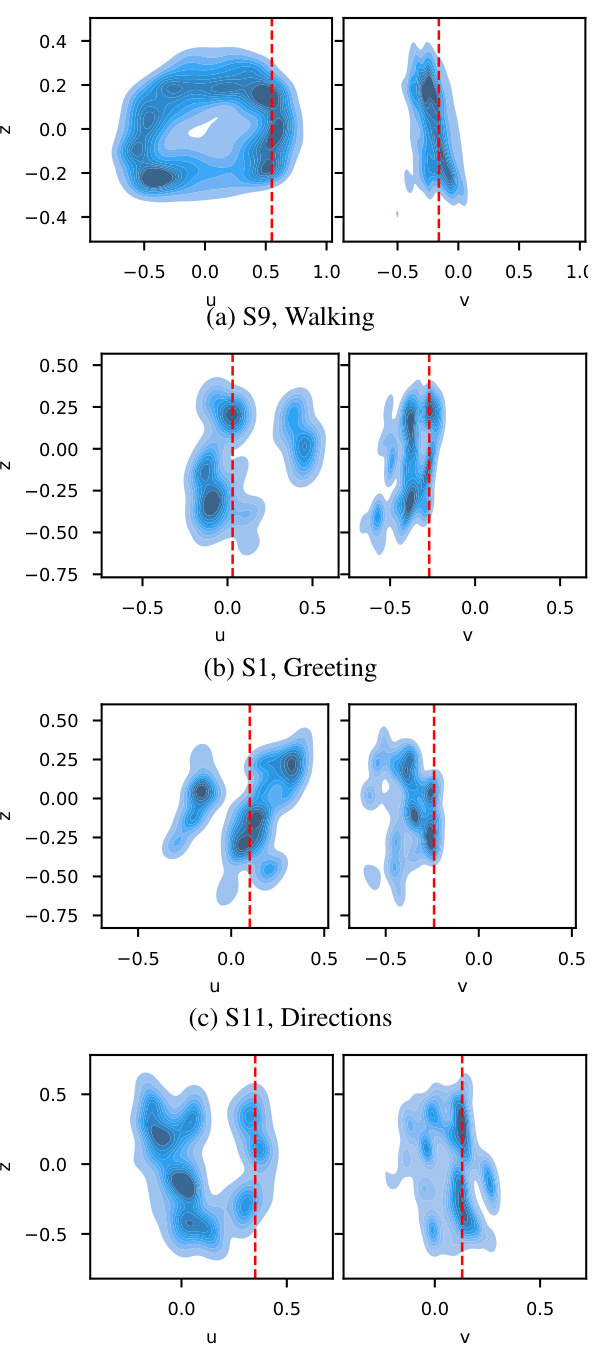
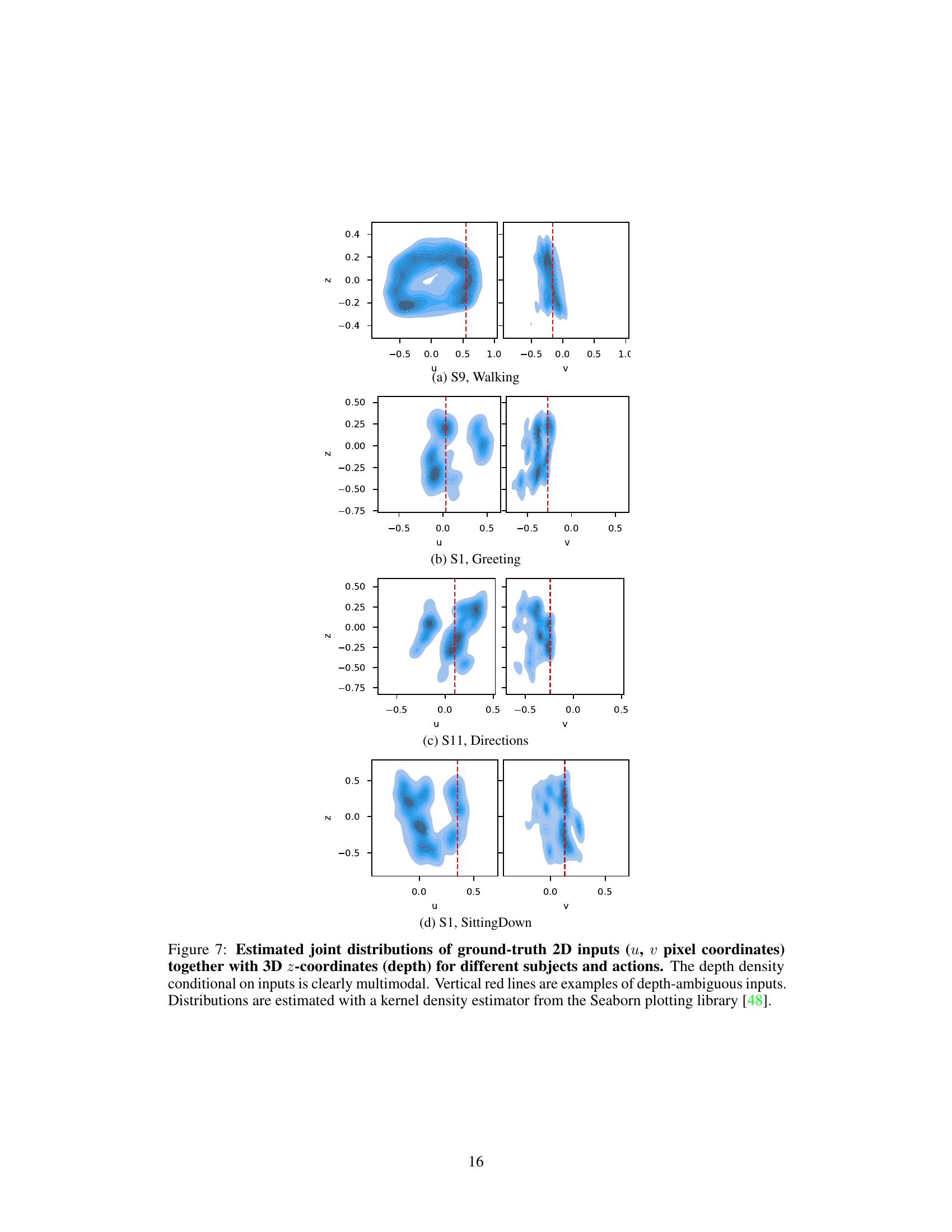
This figure shows the estimated joint distributions of ground-truth 2D inputs (u, v) and their corresponding 3D z-coordinates (depth) for various subjects performing different actions. The key observation is the multimodal nature of the depth distribution given the 2D input, highlighting the inherent depth ambiguity in monocular 3D human pose estimation. The vertical red lines indicate examples of inputs with multiple possible depth values.

This figure shows a comparison of different methods for 3D human pose estimation in terms of joint position error (MPJPE) and pose consistency. The x-axis represents MPJPE, and the y-axis represents inconsistency. The plot shows that traditional unconstrained methods produce inconsistent poses, while regularization and disentanglement constraints improve consistency but worsen joint position error. ManiPose achieves the best performance, balancing both joint error and consistency by using a combination of multiple hypotheses and manifold constraints. The size of the circles in the plot corresponds to the number of hypotheses used by each method.

The figure compares different methods for 3D human pose estimation, focusing on the trade-off between joint position accuracy (MPJPE) and pose consistency. Unconstrained methods yield inconsistent poses. Methods using regularization or disentanglement constraints improve consistency but sacrifice accuracy. Only ManiPose (the proposed method) achieves both high accuracy and consistency by combining multiple hypotheses and manifold constraints.
The figure shows the impact of constraints and multiple hypotheses on the performance of 3D human pose estimation. Unconstrained methods result in inconsistent poses with large errors. While adding regularization or constraints helps with consistency, it also increases the errors. The authors’ method (ManiPose) uses multiple hypotheses and constraints which achieves a balance of low errors and consistent pose estimations.
This figure shows the results of experiments comparing different approaches to 3D human pose estimation. It demonstrates that optimizing for both 3D position accuracy (MPJPE) and pose consistency is challenging. Traditional unconstrained methods produce inconsistent poses, while adding regularization or constraints improves consistency but reduces accuracy. ManiPose, the proposed method, uniquely achieves both high accuracy and consistency by combining multiple hypotheses with manifold constraints.
More on tables

This table compares the performance of ManiPose against other state-of-the-art methods on the Human3.6M dataset in terms of MPJPE, MPSSE, and MPSCE. It highlights that ManiPose achieves superior pose consistency while maintaining competitive MPJPE performance. The table also details the experimental setup of each method, such as the sequence length (T) and number of hypotheses (K).
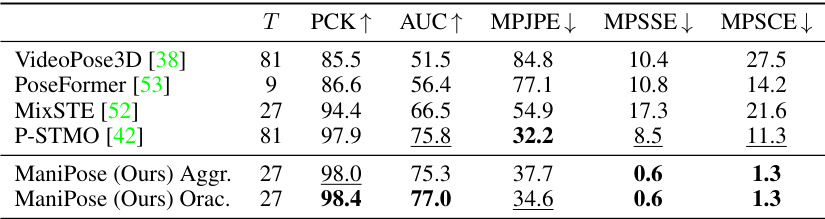
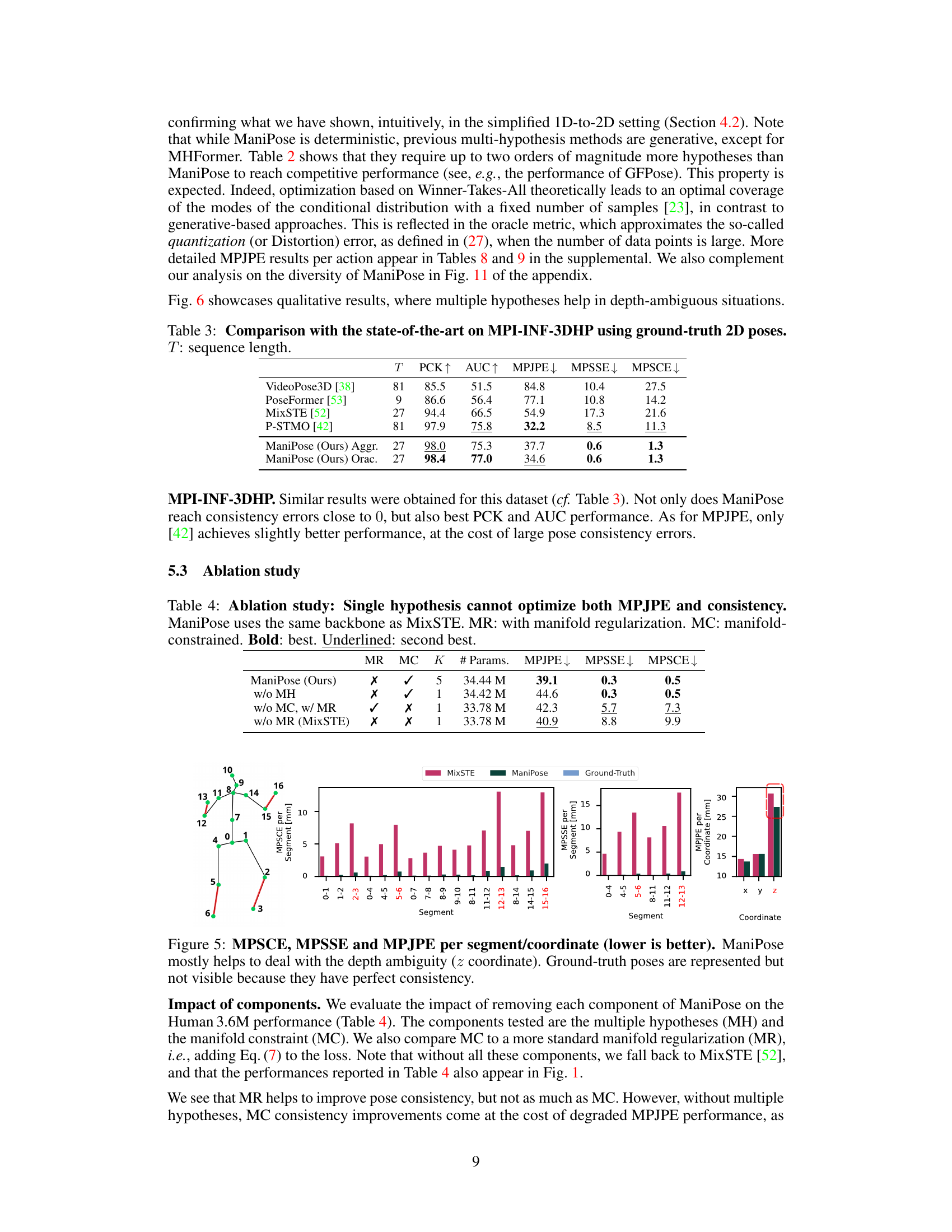
This table compares the performance of ManiPose with other state-of-the-art methods on the MPI-INF-3DHP dataset using ground-truth 2D poses. It shows the results for various metrics, including PCK (Percentage of Correct Keypoints), AUC (Area Under the Curve), MPJPE (Mean Per Joint Position Error), MPSSE (Mean Per Segment Symmetry Error), and MPSCE (Mean Per Segment Consistency Error). The table highlights ManiPose’s superior performance in terms of pose consistency (low MPSCE and MPSSE) while maintaining competitive performance in other metrics. The ‘T’ column indicates the sequence length used for evaluation.

This table presents the ablation study results for ManiPose, comparing the performance of different model configurations. It shows that only the combination of multiple hypotheses and manifold constraints achieves optimal performance in both MPJPE (mean per-joint position error) and pose consistency metrics (MPSSE and MPSCE).
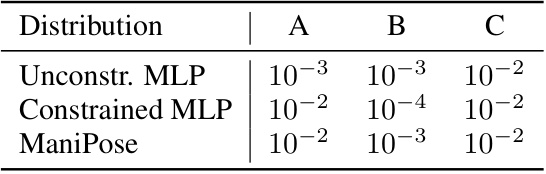
This table presents a comparison of three different models’ performance on a simplified 1D-to-2D pose lifting problem, designed to illustrate the core arguments of the paper. The models are an unconstrained MLP, a constrained MLP, and ManiPose. The table reports the MPJPE (Mean Per Joint Position Error) and the distance of predictions to the circle manifold (representing pose consistency). The results highlight the trade-off between achieving low MPJPE and maintaining pose consistency, and demonstrate ManiPose’s superior performance in both aspects.

This table presents the results of a 2D-to-3D pose lifting experiment using three different methods: an unconstrained multi-layer perceptron (MLP), a constrained MLP, and ManiPose. The metrics used to evaluate the performance are Mean Per Joint Position Error (MPJPE) and Mean Per Segment Consistency Error (MPSCE). The table shows that ManiPose achieves the lowest MPJPE while maintaining perfect MPSCE consistency, indicating that it produces more accurate and consistent 3D poses.

This table compares the performance of ManiPose with other state-of-the-art methods on the Human3.6M dataset in terms of MPJPE (mean per-joint position error) and pose consistency metrics (MPSSE and MPSCE). It highlights that ManiPose outperforms other methods in both aspects, showing a strong correlation between the two metrics.

This table compares the performance of ManiPose against other state-of-the-art methods on the Human3.6M dataset. It evaluates both traditional metrics like MPJPE (Mean Per Joint Position Error) and novel pose consistency metrics (MPSSE, MPSCE). The table highlights that ManiPose outperforms other methods in terms of pose consistency while maintaining competitive MPJPE scores. It also shows that MPJPE and pose consistency are not correlated, with some methods achieving low MPJPE but poor consistency and vice versa.

This table compares ManiPose with other state-of-the-art methods on the Human3.6M dataset in terms of pose consistency and MPJPE. It highlights that ManiPose outperforms other methods in both metrics, demonstrating its effectiveness in achieving high consistency without sacrificing accuracy. The table also provides details on the experimental setup, including the sequence length, number of hypotheses, and evaluation metrics used.

This ablation study investigates the impact of using 3D directions instead of full rotations for representing joint rotations in the ManiPose model. The results show that using full 6D rotations consistently outperforms using 3D directions across different hyperparameter settings, highlighting the importance of the richer representation for achieving optimal performance in terms of MPJPE, MPSSE, and MPSCE.
Full paper#