↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Modern AI heavily relies on train-test model validation to assess performance. However, this paradigm often fails when applied to AI systems interacting with complex social systems where data is collected passively. Passive data collection means the data used for training and testing is generated by an inherent social process, such as popularity bias or network effects, which are themselves not independent and identically distributed (i.i.d.). This violates the assumptions ensuring test validity, leading to unreliable conclusions about the model’s true performance. The current model evaluation practices lack a justification and are invalid in these systems, raising major concerns for the responsible development and deployment of AI.
This paper formally demonstrates the invalidity of such validation techniques. Using formal results from complex systems and learning theory, it shows that, for a large number of practical applications, the train-test paradigm cannot guarantee valid model validation. The paper illustrates this problem with the widely used MovieLens benchmark for recommender systems and proposes a solution to address this fundamental issue: the need for participatory data curation and open science. It argues that current model validation methods are inadequate, and advocates for new approaches to create more reliable and socially beneficial AI systems.
Key Takeaways#
Why does it matter?#
This paper challenges the fundamental assumption of train-test model validation in AI, particularly in complex social systems where data is passively collected. It shows that existing validation methods are likely invalid and proposes alternative approaches like participatory data curation and open science for more reliable model evaluation. This is crucial for advancing AI research and ensuring positive social impact.
Visual Insights#
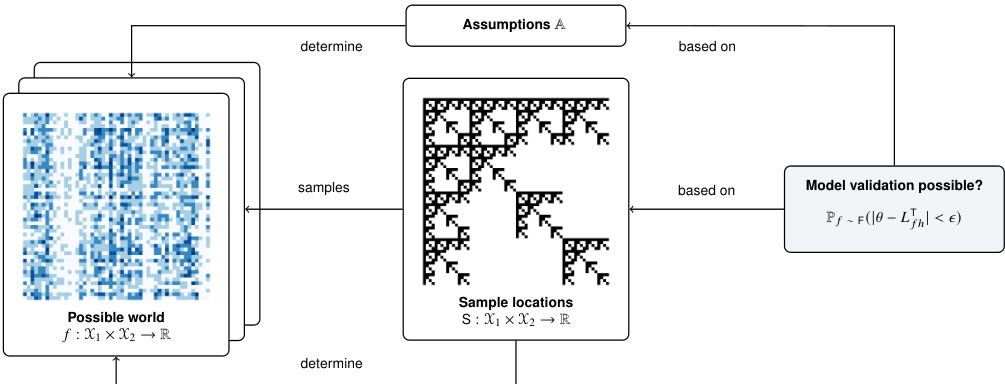
This figure illustrates the concept of test validity in complex systems. It shows a flowchart depicting how assumptions (A), a sampling distribution (S), and a dataset (D) determine a set of possible worlds (F) and their respective true risks (Lh). Test validity is achieved if, given a quality metric (θ) derived from the dataset, the difference between θ and the true risk (Lh) can be bounded across all possible worlds. The figure highlights the difficulty of ensuring test validity, particularly when dealing with complex social systems where the sampling distribution may not accurately reflect the target distribution.

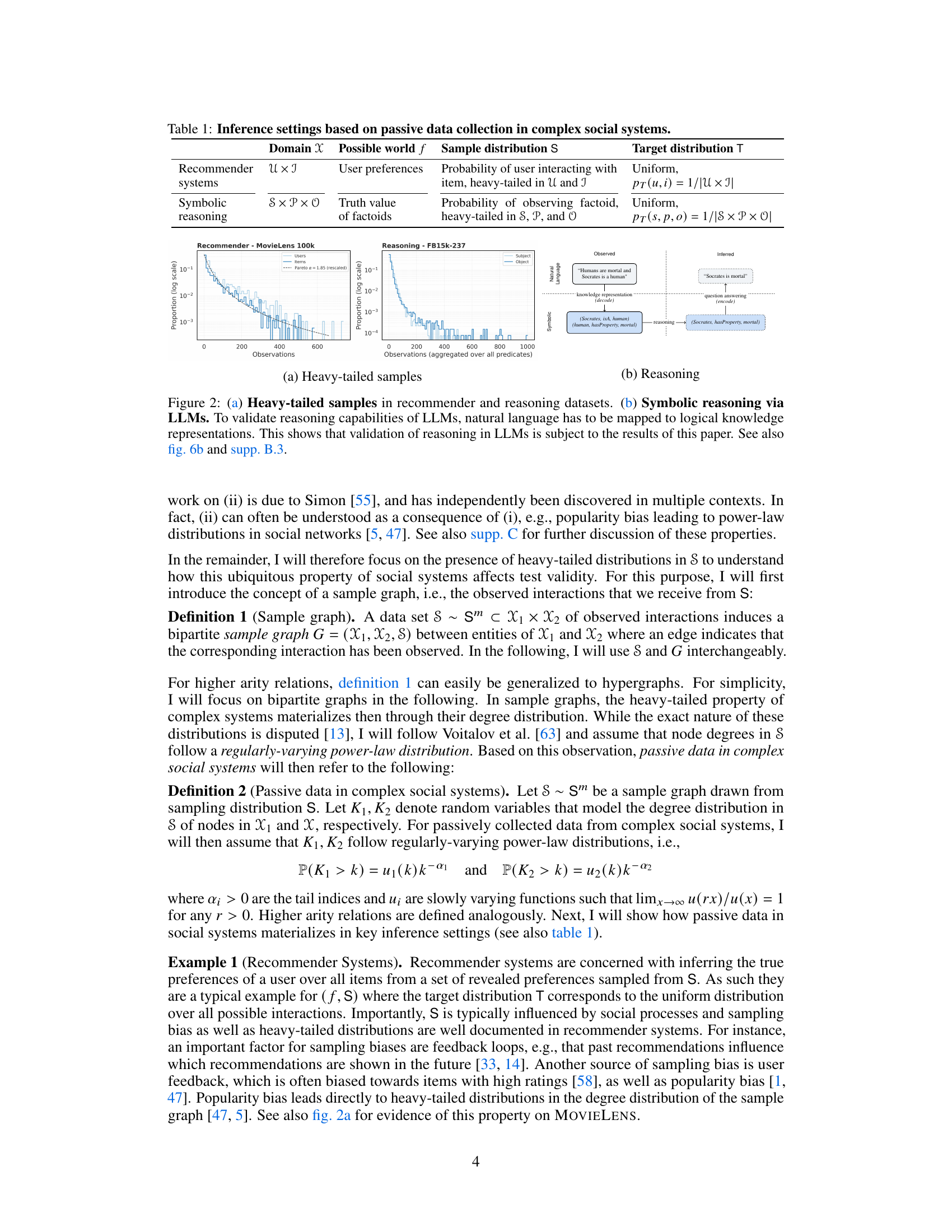
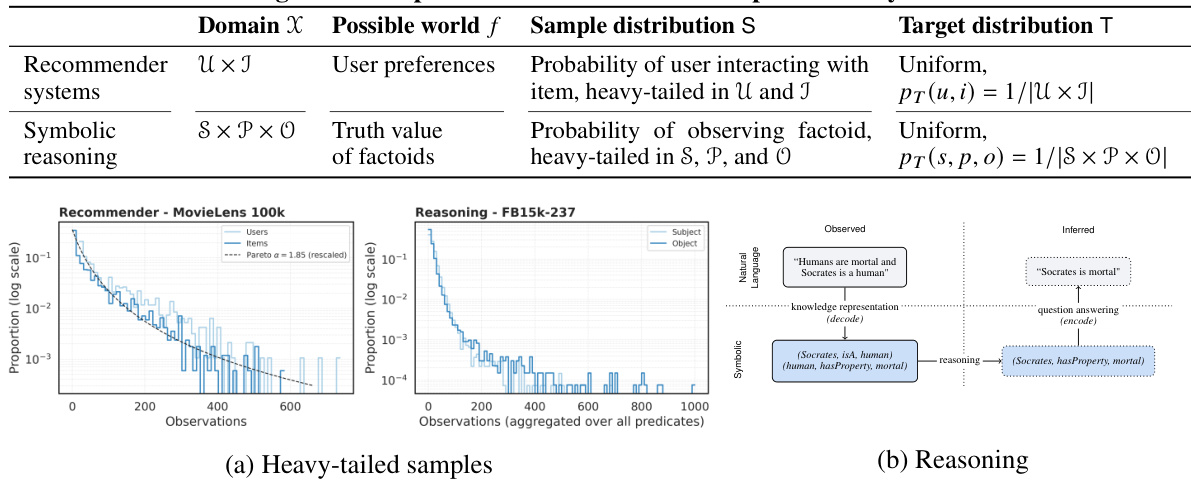
This table presents two example inference settings (recommender systems and symbolic reasoning) in complex social systems that are based on passive data collection. For each setting, it specifies the possible world (the true underlying data generating process), the sample distribution (how the data is actually collected), and the target distribution (the distribution from which we ideally want to generalize). The table highlights the difference between the sample and target distributions that commonly exist in passively collected data from social systems, and how this difference affects model validation.
In-depth insights#
Passive Data Limits#
The concept of ‘Passive Data Limits’ in AI research highlights the crucial problem of relying solely on passively collected data for training and validating AI models, especially within complex social systems. Passive data collection, while convenient and scalable, introduces inherent biases and sampling issues, as data is not collected randomly but influenced by existing social structures and behaviors. This limits the generalizability and reliability of AI models trained on such data. Model validation becomes significantly challenged because the test data doesn’t truly reflect the target population, leading to inaccurate risk assessments. The research emphasizes that traditional train-test paradigms frequently fail in this context, thus raising fundamental epistemological questions regarding how we can verify the validity of AI models trained and validated with such data. Addressing these limits requires exploring alternative data curation approaches, such as participatory methods that involve community involvement and open science, to ensure that data collection aligns better with the intended target population and reflects a broader range of views and experiences.
Train-Test Paradigm#
The train-test paradigm, a cornerstone of machine learning, is critically examined in this paper. The authors argue that its validity is fundamentally compromised when applied to passively collected data within complex social systems. This is because passive data collection inherently introduces biases, violating core assumptions of the train-test paradigm, such as independent and identically distributed (i.i.d.) samples. The paper demonstrates that even with seemingly minor biases, the paradigm’s ability to provide reliable risk estimates is significantly diminished. This limitation poses a fundamental epistemic challenge, hindering our ability to ascertain model validity with confidence for important AI tasks in these environments. The authors underscore the need for novel model validation techniques and data curation strategies. Naive scaling is shown to be insufficient, highlighting the complexities of assessing generalization performance in contexts where data collection is not controlled. The limitations identified in the paper have significant implications for the responsible development and deployment of AI systems in social settings, highlighting the urgent need for new approaches to ensure the reliable performance of such systems.
Social System Bias#
Social system bias in AI arises from the inherent limitations of passively collected data, which often reflects existing societal inequalities rather than a true representation of the target population. Data collected from social media, online reviews, or other readily available sources often reflects pre-existing biases, such as popularity bias, confirmation bias, and echo chambers. These biases are amplified by feedback loops within the system, leading to skewed datasets that perpetuate and reinforce these biases. This results in AI models trained on such data likely exhibiting and amplifying these biases in their own outputs, further entrenching these social inequalities. Addressing social system bias necessitates not just more data, but better data, and thoughtful design choices. Active data collection methods, participatory data curation, and a focus on open science to enhance transparency and accountability are crucial steps toward mitigating social system bias and promoting fairness in AI systems. Moreover, rigorous model validation procedures beyond the train-test paradigm are critical to assess whether AI models are truly robust and generalizable, thereby addressing the epistemic limits of passive data collection. In short, understanding and mitigating social system bias requires a comprehensive approach that goes beyond technical solutions and acknowledges the socio-cultural context in which AI systems are developed and deployed.
MOVIELENS Analysis#
The MovieLens analysis section likely demonstrates the paper’s core argument using a real-world dataset. It probably involves analyzing the MovieLens dataset’s inherent biases and properties, such as heavy-tailed distributions in user preferences and item popularity. The analysis likely shows that standard model validation techniques, like the train-test split, are flawed because they fail to account for these biases and the non-random sampling inherent in passive data collection. By examining the MovieLens data’s structure and the behavior of various models trained on it, the authors aim to illustrate their theoretical claims on the limitations of test validity, particularly highlighting the challenges of achieving valid model evaluations in complex social systems with passively collected data. The empirical results likely showcase high variability in model performance across different possible worlds, reinforcing the central thesis that without active data curation or careful accounting for biases, confident assertions about model generalization in real-world social systems are impossible.
Future Remedies#
Addressing the epistemic limitations of passive data collection in complex social systems necessitates a paradigm shift. Participatory data curation emerges as a crucial remedy, empowering individuals and communities to actively shape data collection and validation processes. This approach fosters data transparency and accountability, directly addressing biases inherent in passively collected data. Coupled with open science initiatives, this ensures reproducibility and broader scrutiny, crucial for building trust and advancing AI research ethically. Developing more sophisticated sampling methodologies is equally vital, moving beyond simplistic train-test paradigms towards rigorous methods capable of handling complex, non-independent data structures found in social systems. Furthermore, robust benchmark development is essential, ensuring that AI systems are evaluated not only on their performance on limited, easily-sampled datasets, but also on their generalization capabilities across diverse, complex scenarios reflecting real-world applications.
More visual insights#
More on figures
This figure illustrates the concept of test validity in complex systems. It shows how, given certain assumptions (A), a target data distribution (T), a sample data set (D) drawn from a sampling distribution (S), and a quality metric (θ), an inference setting is considered ’test-valid’ only if the difference between the estimated risk (θ) and the true risk (Lh) can be reliably bounded across all possible data-generating functions (f) that are consistent with both the assumptions (A) and the observed data (D). Essentially, the diagram visually represents the conditions under which model validation methods are reliable, highlighting the crucial role of assumptions and the data sampling process.
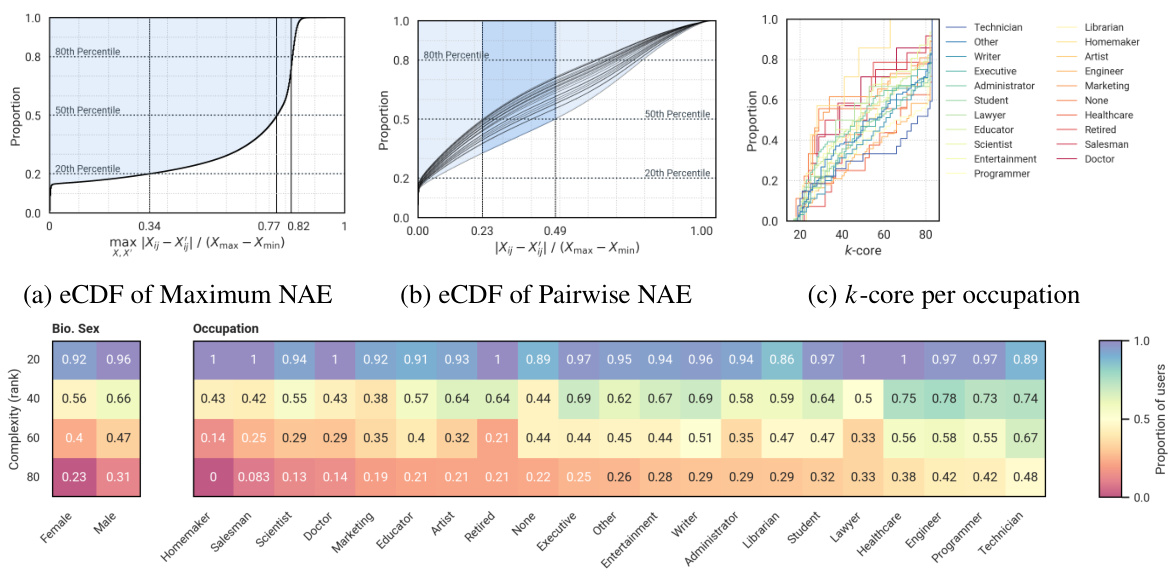
This figure presents the results of experiments conducted on the MovieLens 100k dataset to demonstrate the impact of passive data collection on model validation. The four subfigures show: (a) The empirical cumulative distribution function (eCDF) of the maximum normalized absolute error (NAE) across all possible worlds, highlighting the substantial expected error. (b) The eCDF of pairwise NAEs for various pairs of possible worlds, illustrating significant discrepancies. (c) The eCDF of k-core values per occupation, indicating varied k-core sizes across different user groups. (d) The proportion of users for whom test-validity holds, demonstrating that this proportion decreases with increasing model complexity (rank). These results empirically support the theoretical findings in the paper that model validation is often invalid under passive data collection in complex social systems.

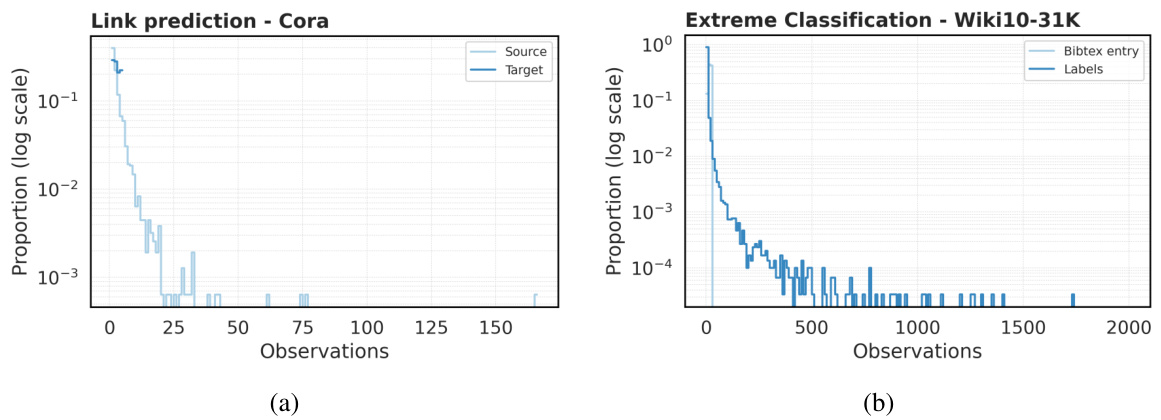
This figure demonstrates the characteristics of complex social systems relevant to the paper’s argument. Panel (a) shows a graphical model illustrating the sampling bias, where samples (S) are not independent and influenced by the true values (f). Panel (b) displays the Pareto distribution, exemplifying the heavy-tailed distribution often found in social systems data. Finally, panel (c) presents the degree distribution from the MovieLens 100k dataset, a real-world example of such a distribution.
This figure presents the results of experiments conducted on the MovieLens 100k dataset to validate the theoretical findings of the paper. Panel (a) shows the empirical cumulative distribution function (eCDF) of the maximum normalized absolute error (NAE) across all possible worlds, illustrating the substantial variability in prediction accuracy. Panel (b) displays the eCDF of pairwise NAEs, further highlighting the discrepancies between possible worlds. Panel (c) visualizes the distribution of users within k-cores by occupation, revealing the influence of demographic factors on data sparsity. Finally, panel (d) demonstrates the relationship between model complexity (rank) and the proportion of users for which test-validity holds, showcasing the challenges in ensuring reliable model validation in complex systems.
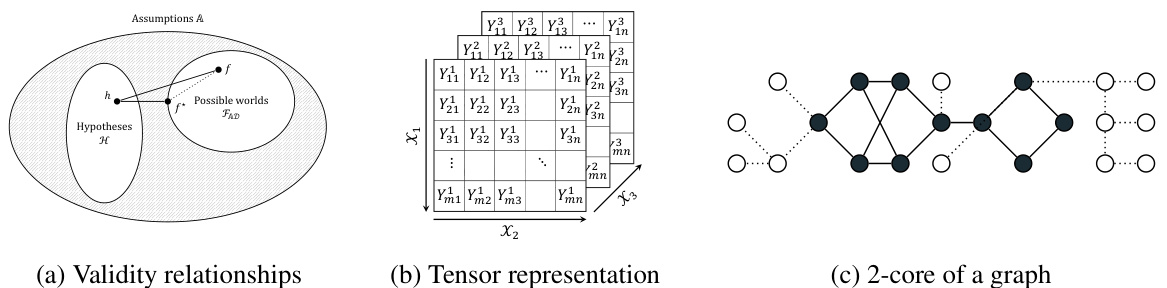
The figure illustrates the concept of test validity in complex systems. It shows the relationship between assumptions (A), the target distribution (T), the sampling distribution (S), and the data set (D) in determining whether model validation is possible. The key idea is that a test is valid if the difference between the estimated risk (θ) and the true risk (Lfh) can be bounded, even when considering all possible worlds (f) consistent with the assumptions and data. This emphasizes the difficulty of ensuring test validity when dealing with complex social systems, which have non-uniform and complex sampling distributions.

This figure presents the results of experiments conducted on the MovieLens 100k dataset to demonstrate the test invalidity in complex social systems. Panel (a) shows the empirical cumulative distribution function (eCDF) of the maximum normalized absolute error (NAE) across all possible worlds, highlighting the high expected error. Panel (b) displays the eCDF of pairwise NAEs between different possible worlds. Panel (c) illustrates the k-core (connectivity) per occupation, showing varying levels of connectivity across different groups. Finally, panel (d) shows the proportion of users for whom test validity holds depending on the model’s complexity (rank), indicating a significant decrease in validity with increased complexity.
More on tables
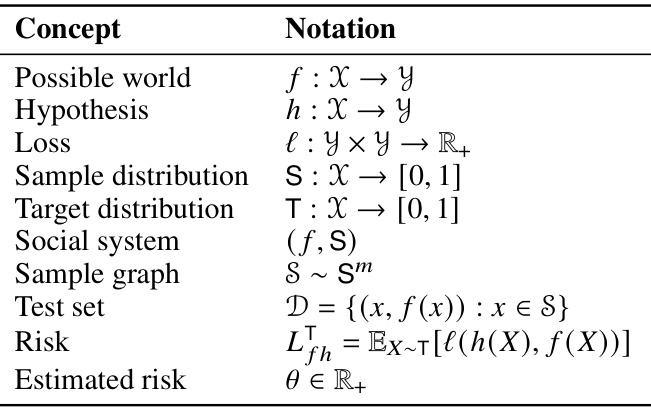
The table describes three different inference settings in complex social systems where data is passively collected. For each setting (recommender systems, symbolic reasoning), it specifies the possible world (the true underlying relationships or preferences), the sample distribution (how data is actually collected, often biased), and the target distribution (the ideal, unbiased distribution we’d like to infer from). This highlights the discrepancy between how data is collected and what we ideally want to learn from it in social systems, setting the stage for the paper’s core argument about the limitations of passive data collection.

This table presents different inference settings in complex social systems using passively collected data. It shows examples of recommender systems and symbolic reasoning tasks, detailing the possible worlds, sample distributions, and target distributions for each. The table highlights how passive data collection violates the assumptions of the train-test paradigm in these settings, leading to invalid model validation.
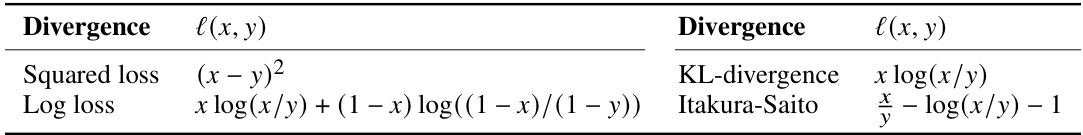
This table shows three examples of inference settings in complex social systems based on passively collected data. For each setting, it specifies the possible world (the true underlying process), the sample distribution (how data is actually collected), and the target distribution (what the ideal data collection process would look like). The examples illustrate recommender systems, symbolic reasoning, and natural language processing tasks.
Full paper#