↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Traditional robot planning methods struggle with complex, real-world scenarios involving multiple robots operating in partially-observable environments and needing to accomplish long-term tasks. This paper tackles these challenges by leveraging the power of Large Language Models (LLMs). Existing LLM-based approaches often fail in these complex scenarios.
The paper introduces LLaMAR, a novel cognitive architecture built on a plan-act-correct-verify framework. LLaMAR uses LLMs to handle high-level planning, action selection, failure correction, and subtask verification. Crucially, this framework allows for self-correction based on real-time feedback, without relying on simulations or oracles, making it suitable for real-world application. The architecture achieves state-of-the-art performance on a comprehensive benchmark dataset (MAP-THOR) designed for testing multi-agent robot planning capabilities in partially-observable environments.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on multi-agent robot planning, long-horizon tasks, and partially observable environments. It presents a novel cognitive architecture, LLaMAR, that significantly outperforms existing methods and introduces a new benchmark, MAP-THOR, for evaluating such systems. The work opens avenues for improving multi-agent coordination and robustness in complex real-world scenarios.
Visual Insights#
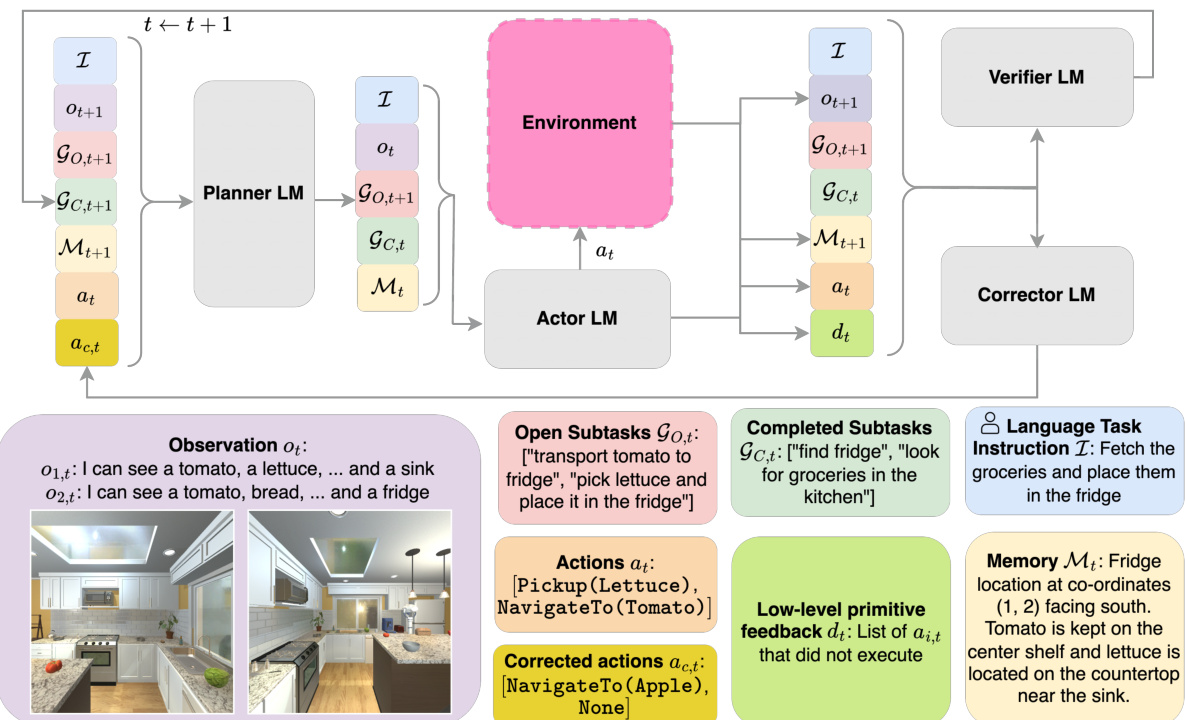
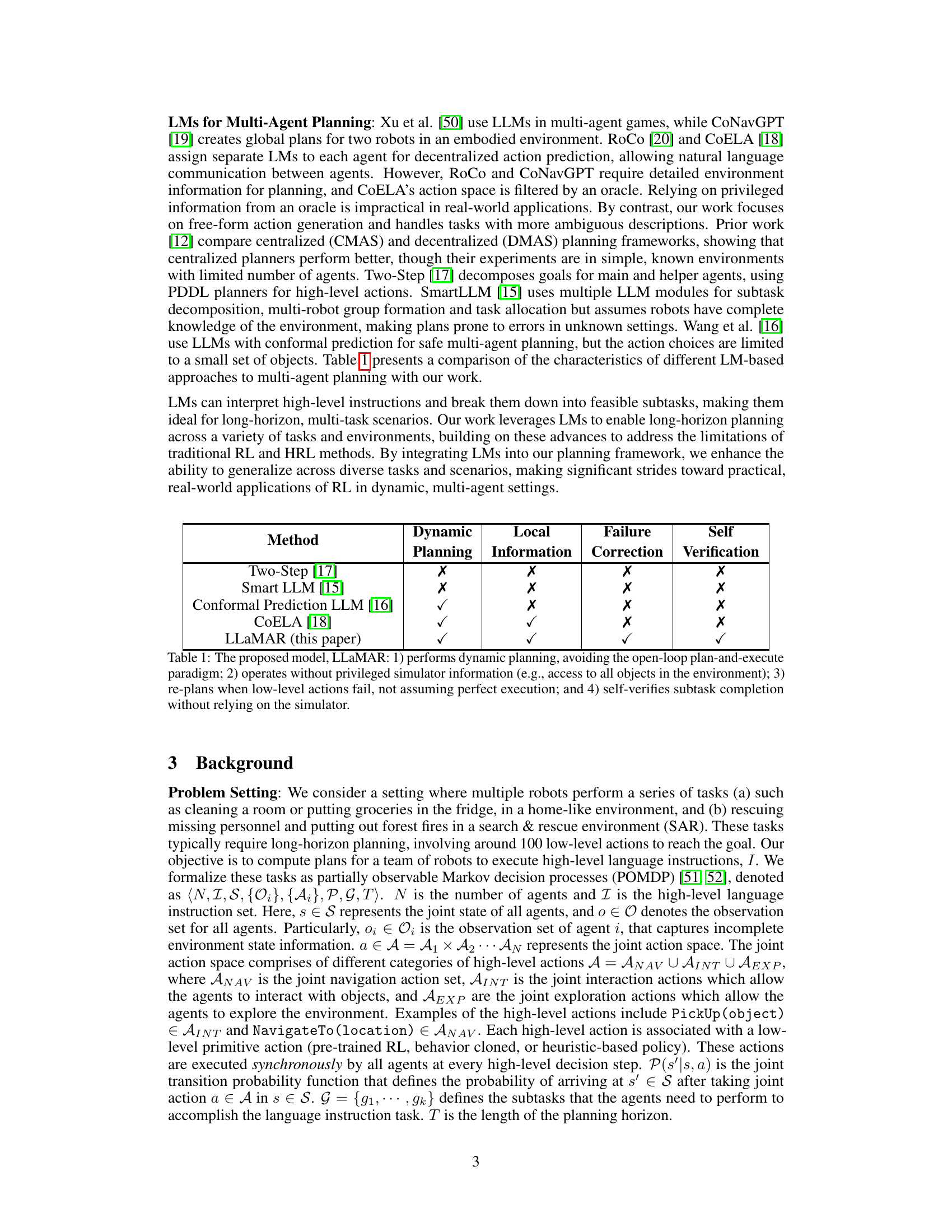
This figure presents a detailed diagram of LLaMAR’s architecture, illustrating the interaction between four key modules: Planner, Actor, Corrector, and Verifier. The Planner takes the high-level task instruction and breaks it down into manageable subtasks. The Actor then decides on high-level actions for the agents to perform, triggering low-level policies for execution. The Corrector module steps in when action execution fails, suggesting corrections based on the feedback received. Finally, the Verifier module assesses the completion of subtasks. The diagram shows how each module interacts with the environment and with each other to achieve successful task completion.
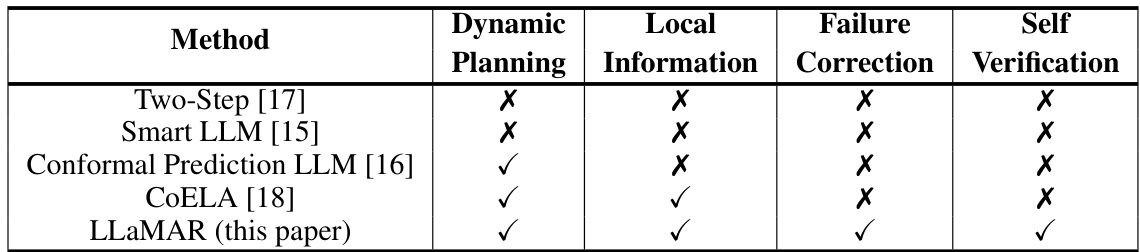
This table compares LLaMAR with other LM-based multi-agent planning methods across five key features: dynamic planning, reliance on local information, ability to handle and correct action failures, and self-verification. It highlights LLaMAR’s unique capability of performing all four features, unlike the other methods, which show varying degrees of capability in each.
In-depth insights#
LLaMAR’s Cognitive Arch#
LLaMAR’s cognitive architecture is a multi-stage, feedback-driven system designed for robust long-horizon planning in partially observable, multi-agent environments. It departs from traditional single-agent approaches by incorporating a centralized decision-making framework that allows for efficient coordination among multiple agents. The core of LLaMAR lies in its four key modules: a Planner that decomposes complex tasks into smaller subtasks; an Actor that selects actions for each agent; a Corrector that identifies and rectifies action failures using real-time feedback; and a Verifier that validates subtask completion. This iterative plan-act-correct-verify cycle enables continuous adaptation to dynamic environments. The architecture avoids reliance on oracles or perfect environmental models, making it suitable for real-world applications. LLaMAR leverages the power of large language models (LLMs) for flexible reasoning and decision making, demonstrating a notable advantage over other methods in terms of success rate and robustness. Furthermore, the integration of visual information through LLMs and a heuristic exploration strategy enhances the agents’ ability to handle uncertainty and achieve high-level objectives in complex scenarios.
MAP-THOR benchmark#
The MAP-THOR benchmark, a comprehensive test suite designed for multi-agent robot planning, presents a significant advancement in evaluating embodied AI systems. Unlike previous benchmarks, it addresses the challenges of partial observability and long-horizon tasks, crucial aspects of real-world scenarios. By focusing on household tasks within the AI2-THOR environment, MAP-THOR offers realistic and standardized metrics for evaluating the robustness and effectiveness of multi-agent planners. The inclusion of tasks with varying levels of language ambiguity further enhances its versatility, allowing for the comprehensive assessment of planning algorithms’ ability to generalize across diverse scenarios. The standardized methodology and metrics provided by MAP-THOR facilitate a more robust comparison of different planning approaches. The availability of this benchmark will undoubtedly contribute to the accelerated development and improvement of multi-agent AI systems for practical applications.
Multi-Agent Planning#
Multi-agent planning, in the context of robotics and AI, presents a complex challenge that demands efficient coordination and communication between multiple agents to achieve a common goal, especially within partially observable environments. The inherent difficulties stem from the need for each agent to reason about not only its own actions and observations but also the actions and potential observations of other agents. Centralized planning approaches simplify the problem by creating a single plan for all agents, but this can become computationally intractable as the number of agents increases. Decentralized methods, on the other hand, allow each agent to create its own plan based on local information, enhancing robustness to failures but potentially leading to suboptimal overall performance. Hierarchical approaches, incorporating high-level planning for task decomposition and low-level control for action execution, provide a valuable framework to manage complexity. The effectiveness of each approach is highly dependent on the specific problem domain, the communication capabilities of the agents, and the level of environmental uncertainty. Language models (LMs) are increasingly leveraged in multi-agent planning due to their ability to parse complex instructions and reason about the world, although challenges remain in handling long horizons and uncertainty.
LLaMAR Limitations#
LLaMAR, while demonstrating significant advancements in multi-agent long-horizon planning, exhibits several limitations. Real-time execution feedback, a core strength, relies on perfect low-level action execution, which is unrealistic in real-world scenarios. The reliance on language models introduces inherent biases and limitations in spatial reasoning and the ability to correctly interpret complex or ambiguous instructions. The modular architecture, though beneficial, increases computational cost and query complexity, potentially hindering scalability. While the exploration strategy is valuable, its heuristic nature may limit effectiveness in diverse and complex environments. Finally, the generalizability of LLaMAR across different environments and task types requires further evaluation, as performance might vary depending on factors like object recognition accuracy, environmental dynamics, and agent coordination complexities.
Future Research#
Future research directions stemming from this work could explore several promising avenues. Improving the LLM’s spatial reasoning capabilities is crucial; current limitations hinder optimal navigation and object interaction. Developing more sophisticated exploration strategies to efficiently gather environmental information in partially observable settings is vital for enhancing the robustness of the system. Investigating alternative multi-agent architectures, potentially incorporating decentralized decision-making or hybrid approaches, could address scaling challenges and improve performance. The use of more efficient, smaller LLMs within the modular architecture warrants exploration to reduce computational overhead. Furthermore, applying LLaMAR to diverse real-world tasks beyond the current MAP-THOR and SAR benchmarks is essential to demonstrate its broader applicability and uncover potential limitations. Finally, a more thorough analysis of the failure modes and corrective mechanisms could guide improvements in the robustness and adaptability of the planning framework. Ultimately, future research should strive to achieve more generalizable and robust long-horizon planning in truly unpredictable and complex multi-agent environments.
More visual insights#
More on figures
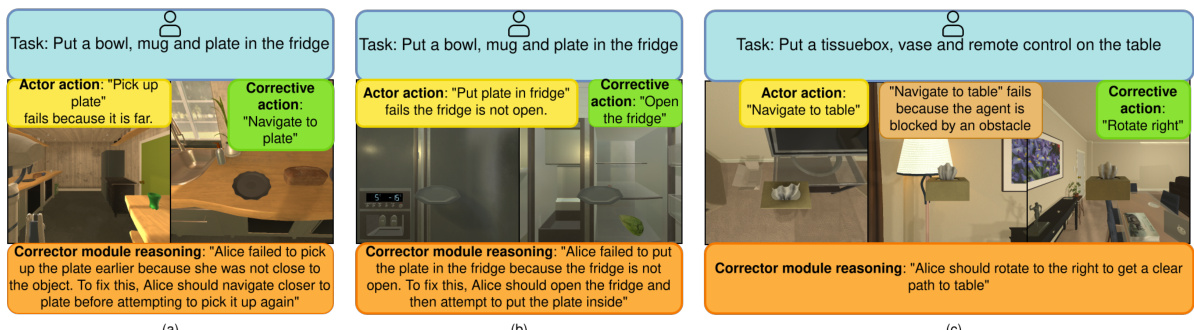
LLaMAR uses four LMs working together to solve multi-agent tasks. The Planner LM determines subtasks; the Actor LM chooses actions; the Corrector LM corrects failed actions; and the Verifier LM checks if subtasks are complete. This modular design enables better performance than other methods.

This figure illustrates the modular cognitive architecture of LLaMAR, an LM-based long-horizon planner for multi-agent robotics. It uses four Large Language Models (LLMs) working together: The Planner decomposes the high-level task into subtasks; the Actor selects high-level actions for each agent; the Corrector identifies and corrects action failures; and the Verifier validates subtask completion. The diagram shows the flow of information and actions between the modules and the environment, highlighting the iterative plan-act-correct-verify framework.

This figure provides a visual representation of the LLaMAR architecture. LLaMAR uses four Language Models (LMs) working together: The Planner LM takes the user’s high-level instructions and breaks them down into smaller, more manageable subtasks. The Actor LM determines the high-level actions each robot should perform to accomplish those subtasks, which are then converted to low-level actions. The Corrector LM analyzes whether these actions were successful and suggests corrections if necessary. Finally, the Verifier LM validates if the subtasks have been successfully completed. The diagram shows the data flow and interaction between these four modules, illustrating the plan-act-correct-verify framework of LLaMAR.
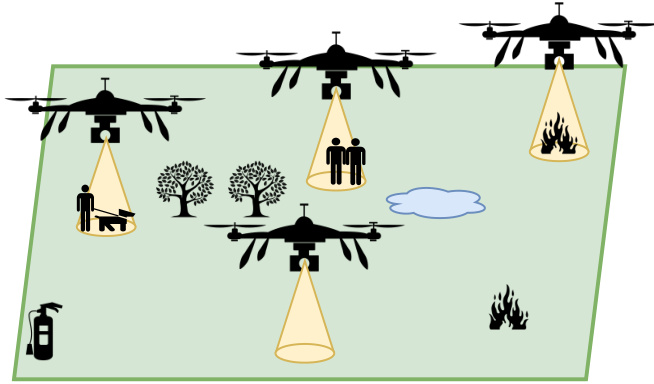
This figure illustrates the Search and Rescue (SAR) environment used in the paper’s experiments. The environment is a grid world containing multiple drones (agents) tasked with locating and rescuing missing people and extinguishing fires. The fires are represented by flames of varying sizes and intensities, suggesting different levels of severity. The drones use their downward-facing cameras to detect and identify objects and people within their range. The presence of water and sand reservoirs indicates available resources to extinguish the fires. The overall setting showcases a partially observable multi-agent environment requiring long-horizon planning and coordination.
This figure presents a detailed breakdown of LLaMAR’s architecture, highlighting the roles of each of its four core modules: Planner, Actor, Corrector, and Verifier. The flow of information and decision-making within the system is shown, demonstrating how the high-level language instruction is decomposed into subtasks, executed, and validated through an iterative plan-act-correct-verify cycle. The figure provides a visual representation of how real-time execution feedback and agent observations are leveraged to refine the planning and execution process.

This figure provides a detailed overview of LLaMAR’s architecture, illustrating the interaction between four core modules: Planner, Actor, Corrector, and Verifier. Each module utilizes Large Language Models (LLMs) to perform specific tasks in the plan-act-correct-verify framework. The Planner decomposes high-level instructions into manageable subtasks. The Actor selects high-level actions based on the Planner’s output, which are then translated into primitive actions by low-level policies. The Corrector identifies and corrects failures by suggesting alternative actions, and the Verifier assesses subtask completion based on observation. This process allows for iterative planning and self-correction.
More on tables
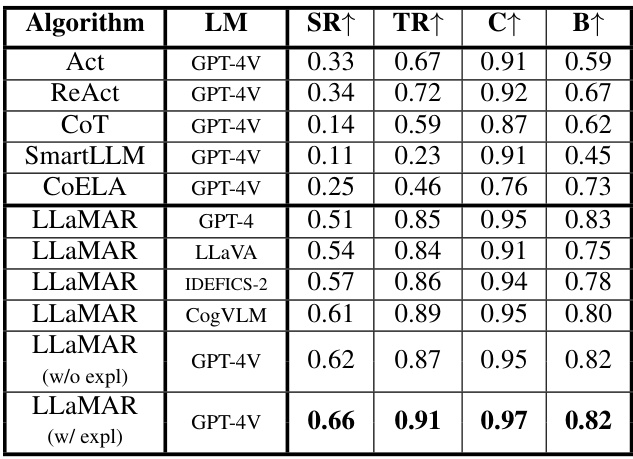
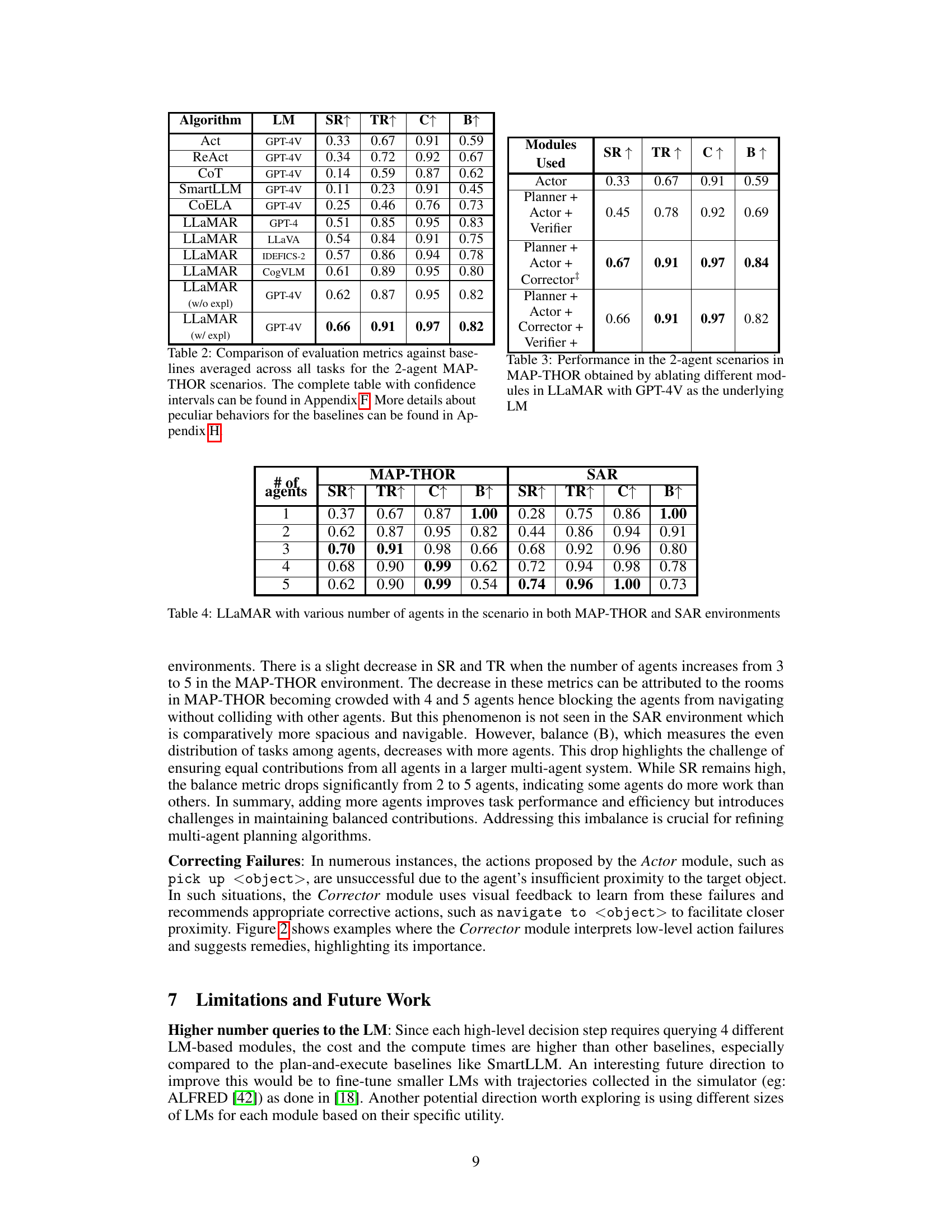
This table compares the performance of LLaMAR against several baseline methods (Act, ReAct, Chain-of-Thought, SmartLLM, and CoELA) in a 2-agent setting on MAP-THOR tasks. The metrics used are Success Rate, Transport Rate, Coverage, and Balance. LLaMAR significantly outperforms the baselines across all metrics, showcasing the benefits of its modular design and real-time feedback incorporation. Note that the full table with confidence intervals and more details about baseline behavior are found in the Appendix.
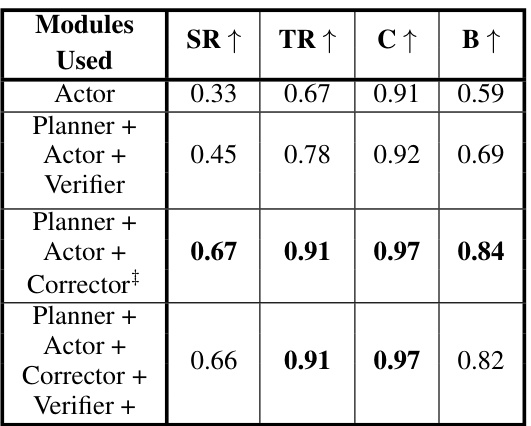
This table presents the ablation study results for the LLaMAR model. It shows the performance of different module combinations (Actor only, Planner+Actor+Verifier, Planner+Actor+Corrector, and the full LLaMAR model) on the 2-agent MAP-THOR scenarios, using GPT-4V as the underlying large language model. The metrics used to evaluate the model’s performance are Success Rate (SR), Transport Rate (TR), Coverage (C), and Balance (B). By comparing the performance of these different module combinations, the table demonstrates the contribution of each module (Planner, Actor, Corrector, and Verifier) to the overall performance of the LLaMAR model.
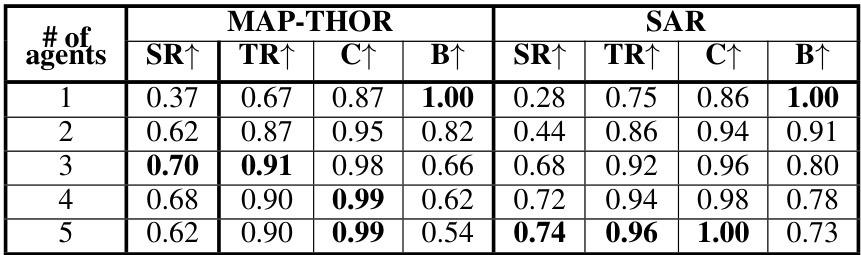
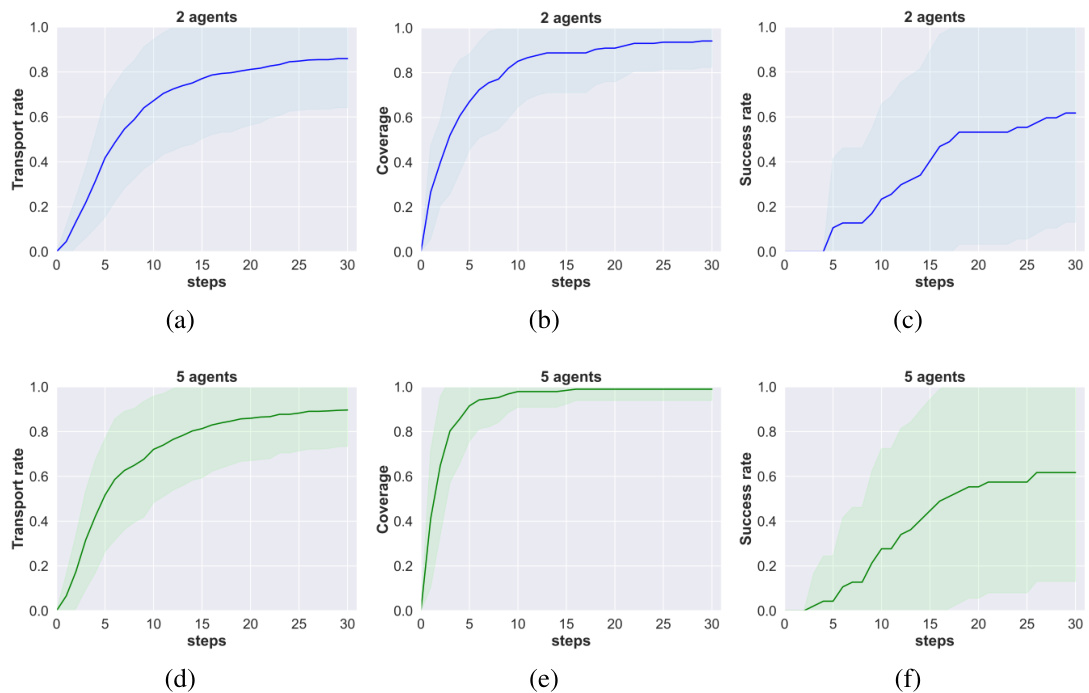
This table presents the performance of LLaMAR with varying numbers of agents (1 to 5) in both the MAP-THOR and SAR environments. For each agent count, it shows the Success Rate (SR), Transport Rate (TR), Coverage (C), and Balance (B) metrics. The success rate indicates the percentage of episodes where all subtasks were completed. The transport rate measures the proportion of subtasks successfully completed, providing a more detailed look at performance. Coverage measures the percentage of successful interactions with target objects. Finally, balance assesses the even distribution of completed high-level actions across agents. This table helps to evaluate the scalability and efficiency of LLaMAR in multi-agent scenarios.

This table compares the performance of LLaMAR against several baseline methods in a 2-agent setting within the MAP-THOR environment. Metrics include Success Rate, Transport Rate, Coverage, and Balance. It highlights LLaMAR’s superior performance compared to the baselines (Act, ReAct, CoT, SmartLLM, and CoELA) while using GPT-4V as the underlying vision-language model. Appendices F and H provide further details and explanations of the baseline methods’ behavior.
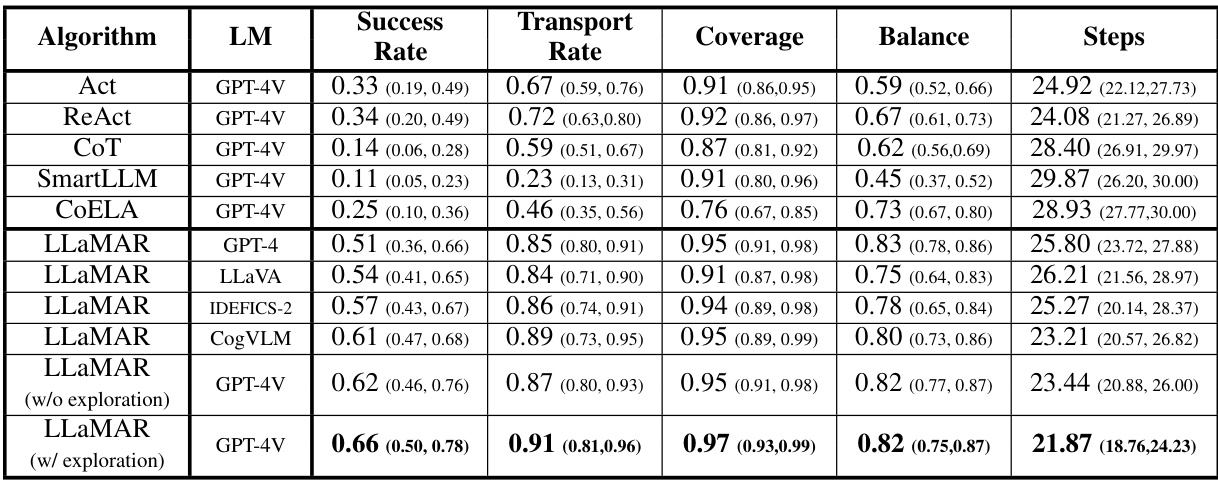
This table presents a comparison of the performance of LLaMAR against several baseline methods (Act, ReAct, CoT, SmartLLM, CoELA) on the 2-agent MAP-THOR tasks. The metrics used for comparison include Success Rate, Transport Rate, Coverage, and Balance. The table highlights LLaMAR’s superior performance across all metrics, suggesting the effectiveness of its cognitive architecture and the proposed exploration strategy. Appendix F provides the full table with confidence intervals, and Appendix H offers further details on baseline method behaviors.

This table presents the results of ablation studies performed on the LLaMAR model. By removing modules one at a time (Actor, Planner+Actor+Verifier, Planner+Actor+Corrector+Verifier), the impact of each module on the model’s performance in 2-agent MAP-THOR scenarios is evaluated. The metrics used for comparison are Success Rate, Transport Rate, Coverage, and Balance, along with the average number of steps taken to complete tasks. The underlying Large Language Model (LLM) used for all experiments is GPT-4V.
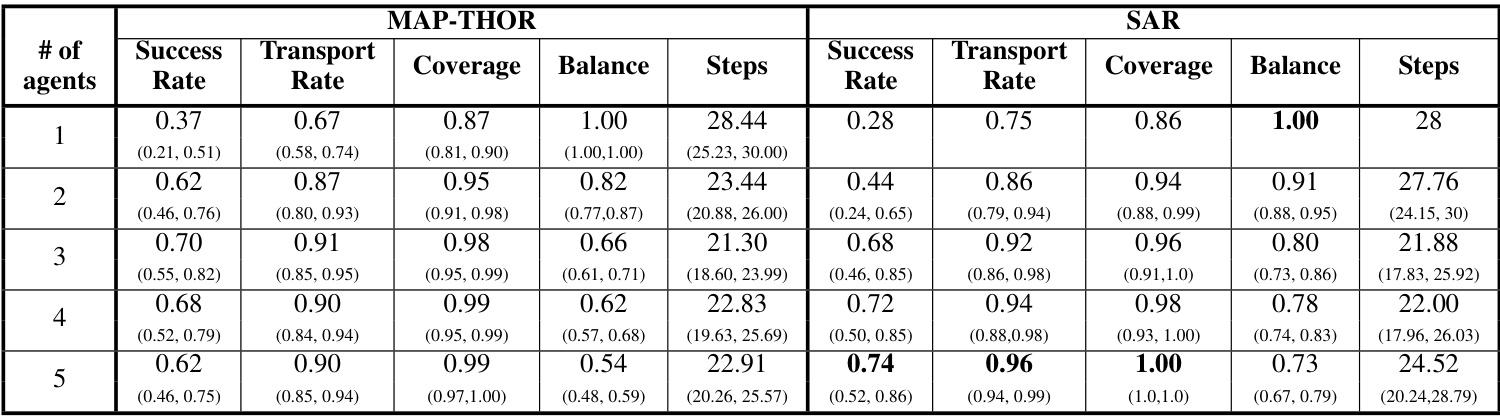
This table presents the results of experiments conducted with varying numbers of agents (1, 2, 3, 4, and 5) in both the MAP-THOR and SAR environments. For each agent count, the table shows the Success Rate, Transport Rate, Coverage, Balance, and average number of Steps taken to complete tasks. The Success Rate indicates the proportion of episodes where all subtasks were successfully completed. The Transport Rate reflects the percentage of subtasks successfully completed within each episode, providing a more detailed measure of task completion. Coverage shows the fraction of successful interactions with target objects, highlighting the effectiveness of the agents in engaging with relevant objects in the environment. Balance measures the evenness of work distribution among the agents, indicating how equally the workload was shared. Finally, Steps indicates the average number of high-level actions required to complete the task. This table is valuable in assessing how the performance of LLaMAR scales with the number of agents in different environments and task types.
This table compares the performance of LLaMAR against several baseline methods (Act, ReAct, Chain-of-Thought, SmartLLM, and CoELA) across various metrics including Success Rate, Transport Rate, Coverage, and Balance in a 2-agent MAP-THOR scenario. It highlights LLaMAR’s superior performance and provides references to appendices with more detailed results and explanations of baseline behavior.
Full paper#