↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Private deep learning using Fully Homomorphic Encryption (FHE) is computationally expensive. Existing methods suffer from significant overheads, particularly during data pruning steps which further slows down the training process. This is due to the heavy computational costs involved in evaluating importance scores and carrying out sorting operations on encrypted data. Also, simply pruning data samples is not enough to reduce computation costs since a single ciphertext can contain multiple samples, leaving large empty slots.
HEPrune addresses these issues by introducing an encrypted data pruning framework that utilizes three main techniques to improve both speed and efficiency. First, a homomorphic encryption-friendly score (HEFS) is proposed to efficiently compute data sample importance scores, avoiding complex non-linear operations. Second, client-aided masking (CAM) is utilized to efficiently identify less important samples without requiring heavy encrypted sorting. Third, ciphertext-wise pruning (CWP) is used to reduce the number of ciphertexts processed, thereby significantly improving performance. Experimental results demonstrate the effectiveness of HEPrune, achieving a 16x speedup with only a 0.6% accuracy loss compared to prior state-of-the-art methods.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in private machine learning due to its significant speedup of training and preservation of accuracy. It introduces a novel approach and opens new avenues for efficient and private data processing, bridging a critical gap in the field.
Visual Insights#

This figure demonstrates the impact of data pruning on model accuracy and training time, both in plaintext and encrypted settings. (a) shows how much data can be pruned from a plaintext dataset (ResNet-18 on CIFAR-10) before accuracy significantly suffers. (b) compares the runtime and accuracy of several encrypted data pruning methods against the baseline (no pruning). (c) illustrates that naive sample-wise pruning leaves many empty spaces in the ciphertexts, highlighting the need for ciphertext-wise pruning.

This table compares the end-to-end training time and accuracy of the proposed method with HETAL and an unencrypted baseline on five datasets (MNIST, CIFAR-10, Face Mask Detection, DermaMNIST, and SNIPS). The pruning ratio is set to 0.9 (only 10% of data used for training). The results show the total training time reduction and the minimal accuracy drop achieved by the proposed encrypted data pruning method across different datasets.
In-depth insights#
Encrypted Data Pruning#
Encrypted data pruning presents a crucial optimization for enhancing the efficiency of private deep learning. The core challenge lies in performing data pruning operations directly on encrypted data without compromising privacy. This requires careful consideration of the computational cost of homomorphic encryption schemes, particularly for non-linear operations involved in scoring data samples for importance. Techniques like homomorphic encryption-friendly scoring (HEFS) aim to reduce this overhead by using simpler, more efficient functions. Client-aided masking further speeds up processing by offloading computationally intensive tasks, such as sorting samples based on their scores, to the client side, enhancing privacy while accelerating training. Ciphertext-wise pruning offers another layer of optimization by reducing the number of encrypted samples involved, maximizing the benefits of pruning and minimizing computational costs. Overall, the success of encrypted data pruning hinges on balancing privacy protection with computational efficiency to achieve significant speed-ups in private deep learning without sacrificing accuracy.
HE-Friendly Scoring#
The concept of “HE-Friendly Scoring” in the context of homomorphic encryption (HE)-based private machine learning addresses the significant computational overhead associated with evaluating non-linear functions directly on encrypted data. HE-friendly scoring methods aim to design efficient approximations or alternative scoring functions that minimize the usage of expensive HE operations. This is crucial because traditional scoring methods (e.g., entropy, forgetting score) require complex computations like logarithms or sorting which are computationally prohibitive in the encrypted domain. By employing HE-friendly scores, the computational cost of data pruning is substantially reduced without significant compromises in model accuracy, enabling faster and more practical private training. A key consideration in developing such scores is to carefully balance the accuracy of the score approximation against the computational savings offered by simplified functions. The trade-off between these two aspects is critical and needs thorough experimental validation to ensure that the resulting data pruning remains effective in improving private model training efficiency.
Ciphertext Pruning#
Ciphertext pruning, in the context of homomorphic encryption (HE)-based private deep learning, is a crucial optimization technique. It addresses the significant computational overhead of HE by selectively removing redundant encrypted data samples, thus speeding up the training process without substantially compromising accuracy. Unlike traditional data pruning methods performed on plaintext data, ciphertext pruning operates directly on encrypted data, preserving privacy throughout the entire process. This necessitates the design of efficient algorithms compatible with HE’s limited operations (primarily addition and multiplication). Successful ciphertext pruning requires carefully balancing the need for computational efficiency with the risk of inadvertently discarding crucial data samples, thus potentially impacting model performance. Techniques like homomorphic encryption-friendly scoring (HEFS) and client-aided masking (CAM) can mitigate this risk by enabling efficient yet privacy-preserving methods for identifying and selecting less significant ciphertexts for removal. Ciphertext-wise pruning, which focuses on removing entire encrypted data blocks instead of individual samples, further enhances the efficiency by reducing the number of computations needed. The effectiveness of ciphertext pruning ultimately hinges on the trade-off between improved training speed and potential accuracy losses.
Client-Aided Masking#
Client-aided masking is a crucial technique enhancing the efficiency and privacy of encrypted data pruning in the proposed HEPrune framework. It cleverly addresses the computational bottleneck of homomorphically sorting sample importance scores, a task inherently expensive in fully homomorphic encryption (FHE). By offloading the sorting process to the client, who holds the secret decryption key, HEPrune dramatically reduces the server’s computational burden. This client-side operation is computationally inexpensive, achieving a significant speedup compared to fully homomorphic sorting. However, the design carefully preserves privacy; the client only receives encrypted importance scores, and the resulting pruning mask—essentially a selection of samples to keep—does not reveal the individual scores themselves. This method cleverly balances privacy and efficiency, demonstrating a practical approach to integrating data pruning into FHE-based private training without compromising the security of the data samples.
Future Enhancements#
Future enhancements for this research could explore several promising avenues. Extending the encrypted data pruning framework to support more complex deep learning architectures like Convolutional Neural Networks (CNNs) and Transformers would significantly broaden its applicability and impact. Addressing the scalability challenges by optimizing for larger datasets and more intricate models is also crucial. This might involve investigating novel homomorphic encryption schemes or techniques that offer better performance for complex computations. Improving the efficiency of the ciphertext-wise pruning algorithm is another key area, potentially through the development of more sophisticated methods to intelligently manage sparse ciphertexts and reduce computational overhead. Finally, exploring hybrid approaches combining FHE with other privacy-enhancing techniques like Secure Multi-Party Computation (MPC) could lead to further gains in efficiency and robustness, while maintaining strong privacy guarantees. Investigating the use of differentially private mechanisms in conjunction with data pruning could provide another layer of privacy protection, addressing concerns about potential information leakage during the pruning process.
More visual insights#
More on figures
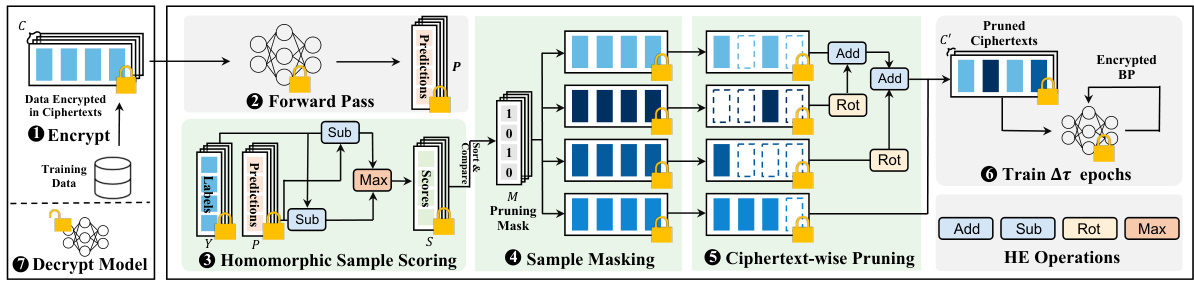
The figure illustrates the pipeline of private training with encrypted data pruning. It starts with the client encrypting the training data and sending it to the server. The server then performs a forward pass on the encrypted data to obtain predictions. These predictions, along with the ground truth labels, are used to compute sample importance scores. Unimportant samples are masked using a pruning mask generated by a client-aided masking process, and the ciphertexts containing these samples are pruned. Finally, the server performs backpropagation on the pruned ciphertexts to train the model for a certain number of epochs. The trained model is then sent back to the client for decryption.

This figure illustrates the workflow of the HEPrune framework for private training with encrypted data pruning. It shows how the client encrypts the dataset and sends it to the server. The server then performs forward and backward passes, computes importance scores, applies a pruning mask, and performs ciphertext-wise pruning. The process repeats for multiple epochs until the model is trained. Finally, the encrypted model is sent back to the client for decryption.
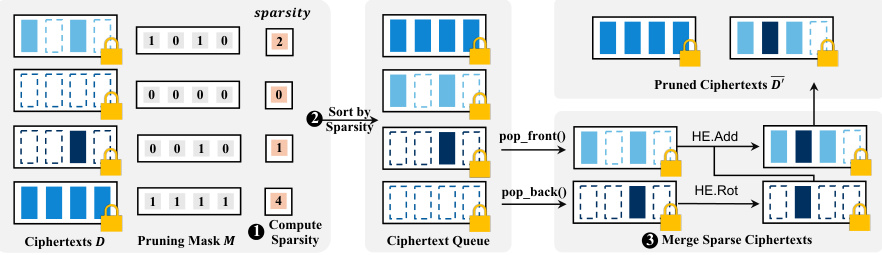
This figure illustrates the process of ciphertext-wise pruning, a technique to further reduce the number of ciphertexts in private training. It begins by computing the sparsity of each ciphertext, which represents the number of empty slots. Ciphertexts are then sorted by their sparsity. The algorithm iteratively merges sparse ciphertexts with denser ciphertexts to minimize empty slots, effectively reducing the overall number of ciphertexts used for training.

This figure shows the results of experiments evaluating the impact of different data pruning ratios on training time and accuracy for the CIFAR-10 and MNIST datasets. Subfigures (a) and (b) respectively show the effect of using different fractions of the datasets on both training time (HE Time, in minutes) and test accuracy. The dashed red lines indicate the accuracy achieved without pruning. The light blue bars show the training time and the orange line shows the accuracy. The results demonstrate that, even with a small fraction of the data, accuracy remains relatively high while significantly reducing training time. The results also show that even using a small fraction of the data can, in some cases, lead to slightly better accuracy than training on the full dataset.
More on tables

This table compares the end-to-end training time and accuracy of the proposed method against HETAL [6] and an unencrypted baseline across five different datasets (MNIST, CIFAR-10, Face Mask Detection, DermaMNIST, and SNIPS). The pruning ratio is consistently set to 0.9 (meaning only 10% of the data is used for training in each epoch). The results show a significant reduction in training time using the proposed method, with minimal impact on accuracy.

This table compares the end-to-end training time and accuracy of the proposed encrypted data pruning method with HETAL [6] and an unencrypted baseline on five datasets (MNIST, CIFAR-10, Face Mask Detection, DermaMNIST, and SNIPS). The pruning ratio (p) is set to 0.9, meaning only 10% of the data is used for training in each epoch. The results demonstrate the significant reduction in training time achieved by the proposed method, along with minimal accuracy loss.
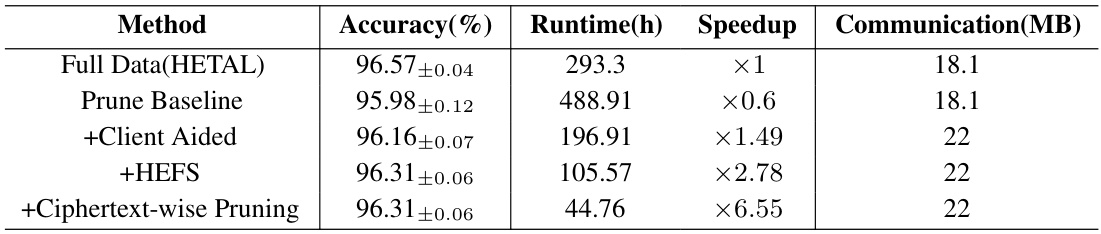
The table compares the performance of five different private training methods on the CIFAR-10 dataset. The methods include a full-data approach (HETAL), a baseline approach with pruning, and three enhanced versions incorporating client-aided masking, HEFS, and ciphertext-wise pruning. The comparison focuses on accuracy, training time (runtime), speedup relative to the full-data approach, and the amount of communication between client and server. The pruning ratio is held constant at 0.9 for all pruning methods.

This table presents the results of training a 3-layer MLP on the MNIST dataset from scratch using different data pruning ratios (1%, 5%, 10%, 20%, 40%, 50%, 60%, 70%, 80%, and 90%). For each pruning ratio, the table shows the achieved accuracy (Acc(%)), the difference in accuracy compared to the full dataset (ΔAcc), the training time in hours (Time(h)), and the speedup factor compared to training with the full dataset. The results demonstrate the trade-off between training time and accuracy when employing data pruning, indicating that significant speedups can be obtained with minimal accuracy loss, especially when using a small fraction of the data.
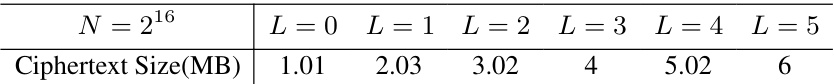
This table compares the end-to-end training time and accuracy of the proposed method with HETAL and an unencrypted baseline across five datasets (MNIST, CIFAR-10, Face Mask Detection, DermaMNIST, and SNIPS). The pruning ratio was set to 0.9 (meaning only 10% of the data was used for training in each epoch). The table shows that the proposed method significantly reduces training time while maintaining high accuracy, with the accuracy drop as small as 0.25% on the Face Mask Detection dataset and even a slight improvement of 0.14% over both HETAL and the unencrypted baseline on this same dataset.
This table presents the end-to-end training time and accuracy on five datasets (MNIST, CIFAR-10, Face Mask Detection, DermaMNIST, and SNIPS) comparing three different methods: an unencrypted baseline, the HETAL method (state-of-the-art), and the proposed HEPrune method with a pruning ratio of 0.9 (i.e., 10% of the data). The comparison highlights HEPrune’s significant speedup in training while maintaining comparable accuracy.
Full paper#



















