↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Large Language Models (LLMs) are becoming increasingly large and complex, placing significant strain on computational resources. Traditional approaches struggle to efficiently handle the massive tensor sizes involved in training and inference, leading to performance bottlenecks due to excessive data movement between accelerators and slower memory. This is further exacerbated by the high cost of inter-node and inter-device communication.
SpeedLoader tackles these challenges head-on by implementing a novel data flow and intelligent scheduling strategies. By strategically offloading and prefetching activations, it minimizes redundant I/O operations and maximizes hardware utilization. This approach significantly enhances training and inference speed across various hardware configurations. Experiments demonstrate significant speed improvements compared to existing methods, showcasing SpeedLoader’s effectiveness in both single-device and distributed settings. The project also provides an efficient tensor management system to further reduce overhead.
Key Takeaways#
Why does it matter?#
This paper is important because it presents SpeedLoader, a novel I/O-efficient scheme that significantly improves the throughput of large language model training and inference, especially under resource constraints. Its focus on minimizing communication overhead offers a valuable approach for researchers dealing with the increasing size and complexity of LLMs. This research opens up new avenues for optimization in heterogeneous and distributed computing environments, impacting various domains relying on LLMs.
Visual Insights#
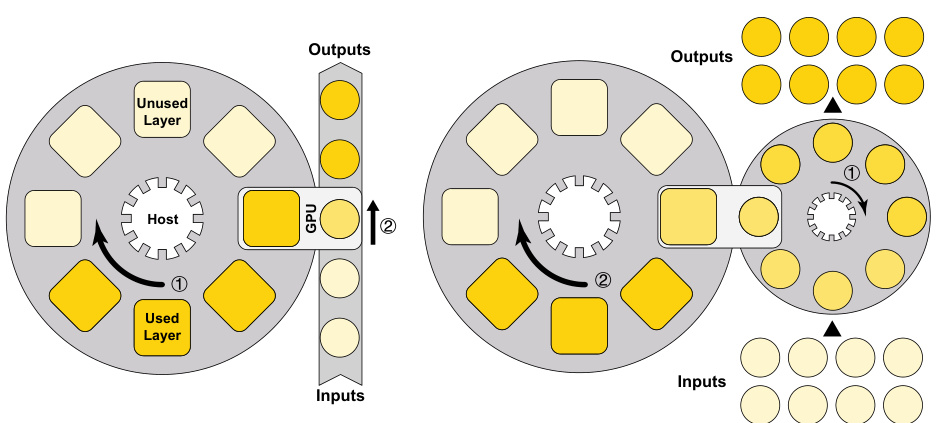
The figure illustrates the difference in data flow between a canonical approach and the proposed SpeedLoader method for processing mini-batches in a neural network. The canonical approach loads the entire model twice per batch, while SpeedLoader processes multiple sub-batches within a single model load and gradient synchronization, minimizing I/O overhead and improving efficiency. The left panel shows the canonical approach, and the right panel shows the SpeedLoader approach.

This table compares the communication costs of SpeedLoader and ZeRO during the training process. It breaks down the communication into collective communication (parameter gathering, gradient reduce-scatter) and local communication (parameter loading, activation loading/offloading, gradient loading/offloading). It highlights SpeedLoader’s significant reduction in communication overhead, especially in collective communication, compared to ZeRO.
In-depth insights#
LLM I/O Efficiency#
Large Language Model (LLM) I/O efficiency is crucial for practical deployment, especially given the massive size of these models. Reducing the time spent moving data between memory (host and accelerator) and storage is critical for both training and inference. The paper highlights the prohibitive costs of tensor communication when distributing LLMs across multiple devices, emphasizing the need for sophisticated techniques to minimize this overhead. Efficient tensor management, such as employing chunk-based approaches and carefully designed data flows, are key to reducing I/O bottlenecks. Further enhancing efficiency involves minimizing redundant communication through careful scheduling and optimizing tensor exchange between the host and devices. This necessitates strategies to reduce data movement and manage memory fragmentation effectively. Finally, techniques like offloading and rematerialization offer trade-offs, where reduced memory pressure comes at the cost of increased computation or communication, which need careful consideration and balancing in achieving optimal LLM I/O efficiency.
Sharded Model Training#
Sharded model training, a crucial technique for handling large language models (LLMs), addresses the limitations of fitting massive parameter sets onto a single device. It involves splitting the model’s parameters and optimizer states across multiple devices, enabling parallel processing and reducing the memory burden on each individual accelerator. This parallelization, however, introduces communication overheads as devices need to exchange information during training. Efficient sharding strategies minimize this communication overhead, focusing on reducing redundant data transfers and optimizing the data flow between devices. The performance gains from sharded training depend heavily on efficient communication infrastructure, especially high-bandwidth interconnects, as well as the optimal balance between model parallelism (sharding) and data parallelism (batching). Careful consideration must be given to hyperparameter tuning to maximize compute utilization while managing memory and communication constraints. Techniques such as gradient accumulation, gradient checkpointing, and optimized tensor management are vital in making sharded training effective and efficient.
Heterogeneous Ops#
A hypothetical section titled ‘Heterogeneous Ops’ in a research paper on large language models (LLMs) would likely explore the challenges and opportunities of running LLM operations across diverse hardware. This could involve examining strategies for efficient data movement between CPUs, GPUs, and potentially specialized accelerators like TPUs. Efficient communication protocols and memory management techniques would be key discussion points, as would the trade-offs between computation speed and energy efficiency. The section might detail specific algorithms or software optimizations designed for heterogeneous environments, perhaps involving model partitioning or offloading computations to less powerful but higher-capacity devices. It would also likely discuss how heterogeneous compute architectures affect training and inference throughput, energy consumption, and overall system cost. Finally, the section would probably present experimental results demonstrating the effectiveness of the proposed strategies, comparing performance metrics against homogeneous system counterparts. Benchmarking and comparison across various hardware configurations would be central to evaluating success.
Hyperparameter Tuning#
The hyperparameter tuning strategy is crucial for maximizing SpeedLoader’s efficiency. The authors emphasize a one-shot approach, focusing on finding optimal settings for sub-batch size, effective batch size, and the number of on-device layers. This approach cleverly leverages the linear relationship between these hyperparameters and resource usage (HBM and DRAM), allowing for efficient resource allocation and minimization of data movement. The strategy’s effectiveness stems from its ability to rapidly identify the best hyperparameter combination within a limited number of trials, making it particularly suitable for large models and distributed training environments. The focus on minimizing data movement is key, especially considering the I/O-bound nature of offloading approaches. The results showcase a substantial performance improvement achieved through careful tuning, underlining the significance of a well-defined hyperparameter optimization process when dealing with the resource constraints inherent to large language model training and inference.
Future Research#
Future research directions stemming from this I/O-efficient LLM scheme could explore deeper integration with various parallelism strategies like tensor and pipeline parallelism, potentially unlocking even greater performance gains. Investigating adaptive memory management techniques to optimize host memory allocation and minimize fragmentation, especially when handling tensors of non-power-of-two sizes, is crucial. Furthermore, extending SpeedLoader’s compatibility with a broader range of LLM architectures and exploring its efficacy in real-world deployment scenarios with diverse hardware configurations would solidify its practical impact. Finally, researching methods to further reduce communication overheads and efficiently handle the complexities of extremely large models exceeding currently available memory resources is essential for future scalability.
More visual insights#
More on figures

This figure illustrates the data flow and communication between the device (GPU) and host (CPU) memory in the SpeedLoader framework. The left side shows the forward propagation, where multiple sub-batches are processed iteratively. Activations are offloaded to the host memory to free up GPU memory and prefetching is performed to overlap computation and communication. The right side shows the backward propagation, where gradients are accumulated and exchanged between device and host in a similar overlapped manner. This optimized data flow minimizes redundant communication overhead and improves efficiency.

This figure illustrates how SpeedLoader reorganizes the buffer memory to ensure continuity during the generation process. The left side shows the original organization of data in the memory buffer, where each row represents a sample and each column represents a token. The right side shows the reorganized buffer after SpeedLoader’s reshape operation. This reorganization ensures that the KV cache for each sub-batch is maintained throughout the generation process, preventing unnecessary data movement and maximizing efficiency.
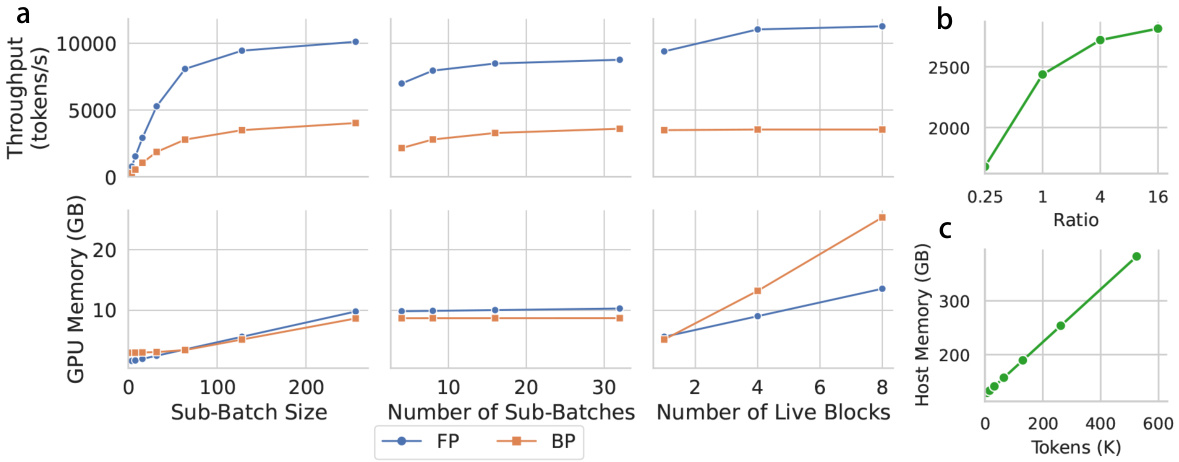
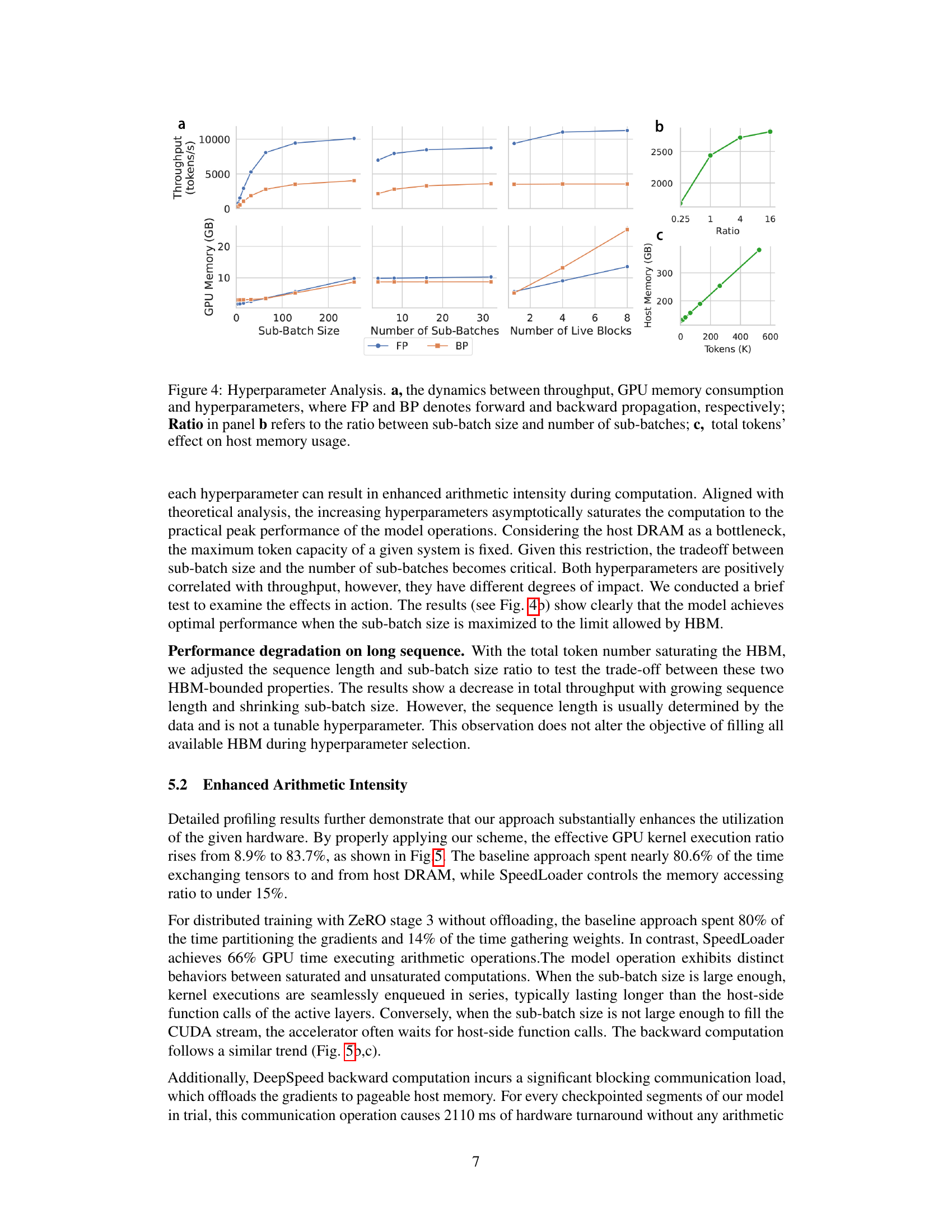
This figure analyzes the impact of various hyperparameters on the performance of SpeedLoader. Panel (a) shows the relationship between throughput, GPU memory usage, sub-batch size, number of sub-batches, and the number of live blocks during both forward (FP) and backward (BP) propagation. Panel (b) illustrates the relationship between throughput and the ratio of sub-batch size to the number of sub-batches. Finally, panel (c) demonstrates how host memory usage scales with the total number of tokens processed.

This figure presents a profiling comparison of DeepSpeed and SpeedLoader, both with and without offloading, under different computing saturation levels (unsaturated and saturated). Each sub-figure (a-e) shows a pie chart breakdown of the time spent on various operations: kernel computations, memory copy operations (memcpy), CPU execution, other miscellaneous operations, reduce-scatter operations, all-gather operations, and arithmetic operations. The chart visually highlights how SpeedLoader significantly reduces time spent on memory operations (especially memcpy) and increases time dedicated to arithmetic computations, resulting in improved efficiency.
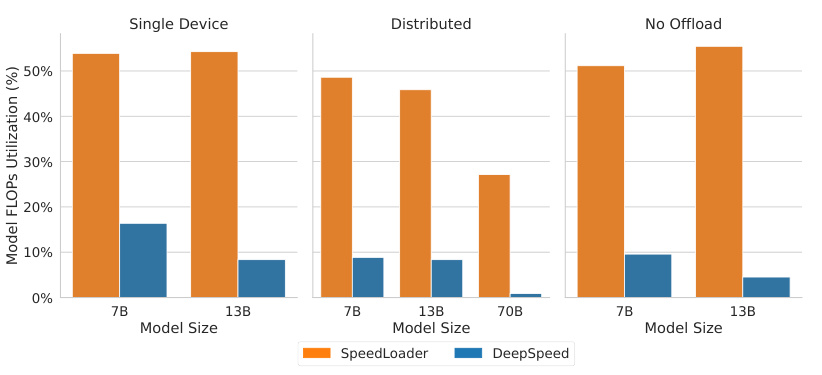
This figure compares the Model FLOPs Utilization (MFU) of SpeedLoader and DeepSpeed under different training settings: single device with offloading, distributed with offloading, and distributed without offloading. The x-axis represents the model size (7B, 13B, and 70B parameters), and the y-axis shows the MFU percentage. The bars show that SpeedLoader consistently achieves higher MFU than DeepSpeed across all settings, indicating that SpeedLoader is more computationally efficient.
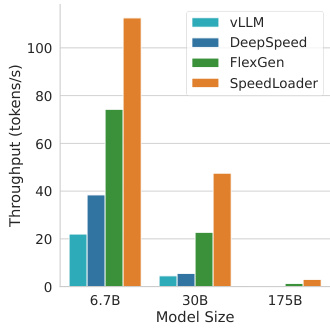
This figure compares the inference throughput (tokens per second) of four different approaches: vLLM, DeepSpeed, FlexGen, and SpeedLoader, across three different model sizes: 6.7B, 30B, and 175B parameters. SpeedLoader demonstrates significantly higher throughput compared to the other methods, especially for larger models, highlighting its efficiency in inference tasks.
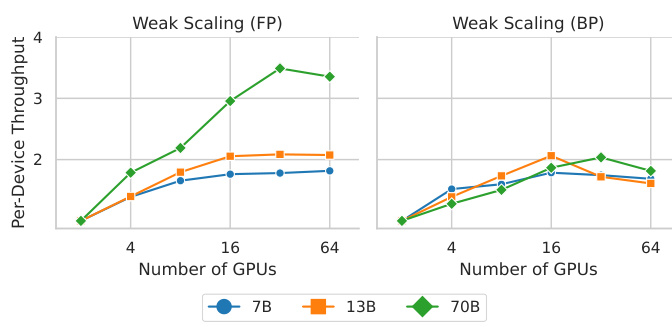
This figure shows the results of weak scaling experiments conducted on SpeedLoader. Weak scaling tests the performance of a system as the number of processors is increased while keeping the problem size per processor constant. The x-axis represents the number of GPUs used, and the y-axis represents the per-device throughput (tokens processed per second per GPU). Different lines represent different sizes of the LLaMA-2 model (7B, 13B, and 70B parameters). The plot shows the throughput achieved for both forward propagation (FP) and backward propagation (BP). The data illustrates how the throughput per GPU changes as more GPUs are added to the system.

This figure shows the ablation study of the model FLOPs utilization (MFU) with and without using FlashAttention-2 in both distributed and no-offload settings. The results are shown for different model sizes (7B, 13B, and 70B). It demonstrates the impact of FlashAttention-2 on improving the computational efficiency of the SpeedLoader approach.
More on tables

This table lists the hardware and network configurations used in the experiments. It shows the internode and intranode connections, along with the specific accelerators (GPUs) used for each type of experiment: functionality benchmark, profiling, scalability, and compatibility testing. The different types of experiments used different hardware setups to explore the impact of various factors on SpeedLoader’s performance.
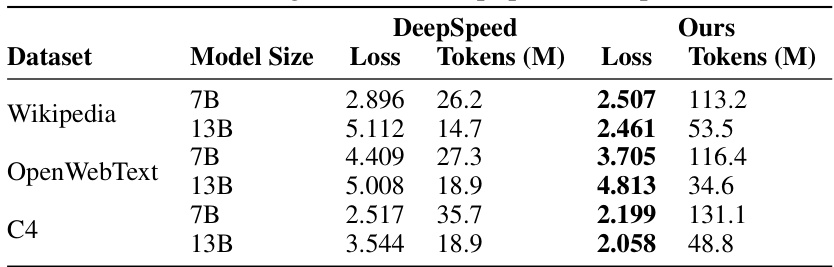
This table presents the results of pretraining experiments conducted using both DeepSpeed and the proposed SpeedLoader approach. It compares the loss and the number of tokens processed (in millions) for two different model sizes (7B and 13B parameters) across three datasets: Wikipedia, OpenWebText, and C4. The comparison highlights SpeedLoader’s improved performance in terms of tokens processed while achieving comparable or lower loss values.

This table lists the common abbreviations used throughout the paper, including their full forms and meanings. The abbreviations cover key concepts in large language model (LLM) training and optimization, such as FLOPs (floating-point operations), MFU (Model FLOPs Utilization), HBM (High-Bandwidth Memory), and others.

This table compares the communication overhead of the proposed SpeedLoader method with the ZeRO method during the training process. It breaks down the communication into collective communication (operations involving all participating devices) and local communication (operations between a device and the host). For each category, it lists the amount of communication in terms of P (parameter size), A (activation size), and N (number of sub-batches). The total communication cost is also summarized for each method.
Full paper#