↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Federated learning (FL) struggles with communication costs and data heterogeneity, especially when using large vision-language models. Prompt-based FL reduces these issues, but lacks theoretical understanding. This limits optimization and efficient algorithm design. Existing methods like CoOp (local prompt) and PromptFL (global prompt) individually offer either strong personalization or generalization but not both.
This paper introduces a theoretical framework analyzing prompt-based FL via feature learning theory. It then presents PromptFolio, an algorithm combining global and local prompts to create a ‘prompt portfolio’. This approach balances generalization and personalization, improving performance significantly. The optimal prompt mixing coefficient is derived and empirically validated, demonstrating a clear performance advantage over existing techniques. The theoretical framework and PromptFolio algorithm offer a valuable advancement in prompt-based FL.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in federated learning and vision-language models. It offers a novel theoretical framework and a practical algorithm (PromptFolio), advancing our understanding of prompt-based federated learning and providing a solution to improve model performance in heterogeneous data scenarios. This work bridges the gap between theory and practice, impacting future research directions and applications.
Visual Insights#

The figure illustrates the PromptFolio algorithm’s framework, showcasing how it updates global and local prompts without altering the pretrained vision-language model’s weights. It highlights the aggregation of global prompts from individual clients and visually represents the performance benefits of combining global and local prompts, drawing an analogy to portfolio optimization.

This table compares the accuracy of three different prompt-based federated learning methods (CoOp, PromptFL, and PromptFolio) across five different datasets (CIFAR-100, DomainNet, Office-Caltech10, OxfordPets, and DTD). The results show the performance of each method on each dataset, demonstrating the effectiveness of the PromptFolio approach.
In-depth insights#
Prompt Portfolio#
The concept of a ‘Prompt Portfolio’ in federated learning offers a novel approach to enhance model performance. By combining global and local prompts, it aims to balance the trade-off between generalization and personalization. The global prompt captures shared knowledge across clients, promoting better generalization, while the local prompts leverage client-specific data, improving personalization. This strategy is inspired by portfolio optimization, drawing a parallel between prompt types and financial assets, aiming to minimize risk (noise memorization) while maximizing return (signal learning). The optimal mixing coefficient for the portfolio is theoretically derived and empirically validated, demonstrating the superior performance of this approach over using individual prompts in diverse settings. This method addresses the challenge of data heterogeneity in federated learning effectively, leading to improved model accuracy and robustness.
Feature Learning#
Feature learning, a powerful theoretical framework, analyzes how machine learning models learn and represent information by tracking weight updates during training. It decomposes data into task-relevant and task-irrelevant features, enabling a deeper understanding of signal learning and noise memorization. This framework provides valuable insights into various aspects of model training, including the dynamics of coefficient evolution and the effects of different training algorithms. By monitoring the ratio of task-relevant to task-irrelevant coefficients, we can assess model performance and generalization ability. This methodology connects with portfolio optimization, providing an innovative perspective on balancing generalization and personalization in machine learning. By viewing task-relevant and task-irrelevant coefficients as income and risk, respectively, we can create a prompt portfolio to enhance performance. This approach offers a new way to understand and improve prompt-based federated learning, especially in vision-language foundation models.
Federated Setting#
In a federated setting, the core idea is to enable collaborative machine learning across decentralized devices while preserving data privacy. Each participating device (client) trains a local model using its own data, without directly sharing it with others. A central server coordinates the training process by aggregating model updates from the clients, but it does not access the raw data itself. This approach presents several challenges. Non-independent and identically distributed (non-IID) data across clients, meaning data heterogeneity, can significantly impede model accuracy and generalization. Further, communication bandwidth limitations can restrict the frequency and volume of model updates exchanged between clients and the server. The design of efficient algorithms to address these issues, such as techniques for data heterogeneity handling and efficient model aggregation, are key focuses of research in federated learning.
Theoretical Limits#
A theoretical limits analysis in a research paper would deeply explore the fundamental constraints and inherent boundaries of a method or system. It would move beyond empirical observations and delve into the mathematical foundations, identifying potential bottlenecks and optimal performance levels. Such an analysis might involve deriving upper and lower bounds on achievable metrics, proving the impossibility of surpassing certain thresholds, or revealing inherent trade-offs. For instance, a theoretical limit on generalization might examine the relationship between training data size and the model’s ability to generalize to unseen data. The analysis would be crucial for understanding the ultimate capabilities of the technology, informing future research directions, and setting realistic expectations for performance. It could also help identify areas where further research can focus on overcoming limitations and developing novel approaches to push beyond these limits.
Future Work#
Future research directions stemming from this work could involve exploring more sophisticated prompt engineering techniques, potentially incorporating prompt ensembles or evolutionary algorithms to further optimize prompt selection and mixing. Investigating the impact of different vision-language foundation models beyond CLIP would broaden the applicability and generalizability of the findings. A deeper dive into the theoretical underpinnings of prompt-based federated learning, perhaps through the lens of information theory or other relevant frameworks, could reveal further insights into the interplay between personalization, generalization, and privacy. Empirical studies focusing on real-world, large-scale federated learning applications would strengthen the practical relevance of the proposed methodology. Finally, developing robust techniques to handle concept drift and data heterogeneity in dynamic federated settings would be crucial for improving the long-term performance and stability of prompt-based federated learning systems.
More visual insights#
More on figures

This figure shows the impact of the mixing coefficient (θ) on the test accuracy for different data distributions and numbers of users. The left graph (a) illustrates how varying the data distribution affects the optimal mixing coefficient for achieving the highest accuracy. The right graph (b) focuses on the influence of the number of users; it shows that as the number of users increases, the optimal coefficient tends toward a more globally-weighted approach (θ closer to 0). Both graphs demonstrate that a hybrid approach (combining global and local prompts) consistently outperforms using only a global or local prompt.

This figure illustrates the PromptFolio algorithm’s framework. It shows how global and local prompts are updated independently on each client, while the vision-language model’s weights remain fixed. The global prompts are then aggregated by the server. The diagram also visually represents the performance benefits of combining global and local prompts, analogous to a portfolio optimization strategy.

The figure illustrates the PromptFolio algorithm’s framework. It shows how global and local prompts are updated while keeping the pre-trained vision-language model’s weights unchanged. Global prompts are aggregated from each client. The right side uses a portfolio analogy to show how combining global and local prompts improves performance.
More on tables

This table presents the accuracy results of three different methods (CoOp, PromptFL, and PromptFolio) across five distinct datasets (Cifar100, DomainNet, Office-Cal10, OxfordPets, and DTD). It demonstrates the performance advantage of PromptFolio, which combines global and local prompt learning, over the individual methods. The values represent the average accuracy and standard deviation.
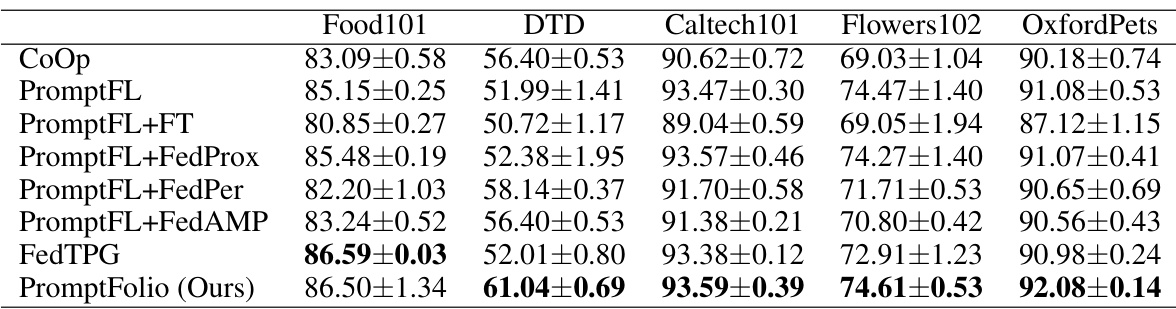
This table compares the performance of different prompt-based federated learning methods across five different datasets: Food101, DTD, Caltech101, Flowers102, and OxfordPets. The methods compared include CoOp, PromptFL, and several variants of PromptFL, along with FedTPG and the proposed PromptFolio method. The table shows the accuracy achieved by each method on each dataset, with error bars indicating variability. The results demonstrate the superior performance of PromptFolio compared to other methods.
Full paper#



















