↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Federated learning (FL) faces challenges with heterogeneous devices having varying capabilities. Existing knowledge distillation (KD) methods struggle to transfer knowledge effectively across diverse devices because informative logits from capable devices are diluted by those from less capable ones, and using a single integrated target neglects individual device contributions. This paper introduces TAKFL, a novel KD-based framework.
TAKFL addresses these challenges by treating knowledge transfer as separate tasks. It independently distills knowledge from each device to prevent dilution and uses a self-regularization technique to handle noisy ensembles. To integrate the distilled knowledge, TAKFL employs adaptive task arithmetic, allowing each student model to customize integration for optimal performance. Theoretical results demonstrate the effectiveness of task arithmetic, and experiments across computer vision and natural language processing tasks show that TAKFL outperforms existing KD-based methods.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on federated learning, especially those tackling the challenges of device heterogeneity. It offers a novel solution to improve knowledge transfer across diverse devices, significantly advancing the field and opening new avenues for future research. The theoretical underpinnings and empirical results provide a strong foundation for further development and refinement of federated learning techniques.
Visual Insights#
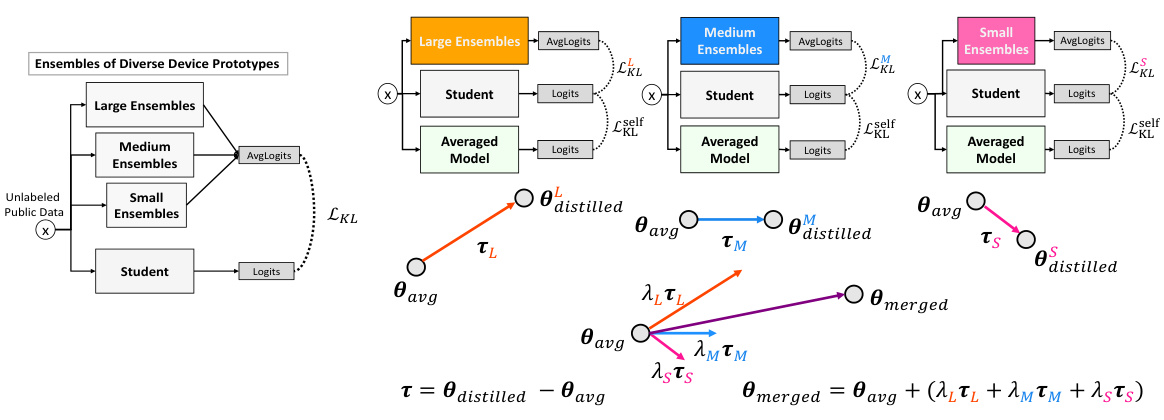
This figure illustrates the difference between the vanilla ensemble distillation method and the proposed TAKFL method. The left panel (a) shows how the vanilla method averages logits from ensembles of different sizes, leading to information dilution and suboptimal knowledge transfer. The right panel (b) details TAKFL, which treats each device’s knowledge transfer as a separate task, independently distilling each to preserve unique contributions and avoid dilution. TAKFL incorporates self-regularization to handle noisy distillation and uses adaptive task arithmetic to integrate distilled knowledge for optimal performance, customizing the integration process for each student model.
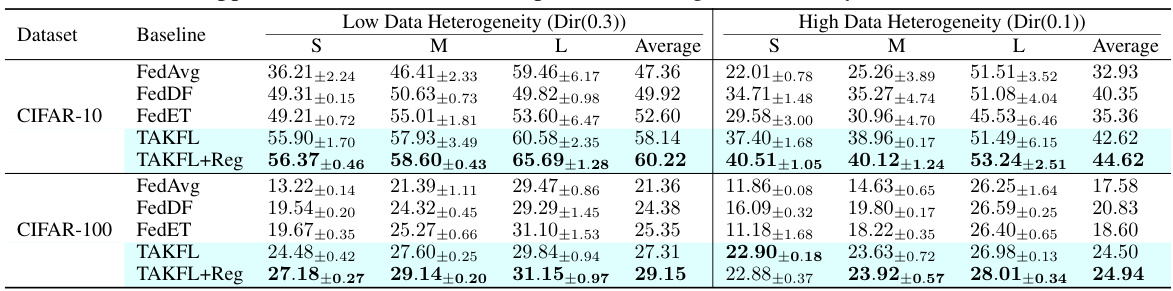
This table presents the performance of different federated learning methods (FedAvg, FedDF, FedET, TAKFL, and TAKFL+Reg) on CIFAR-10 and CIFAR-100 datasets for image classification. The results are broken down by device prototype size (Small, Medium, Large) and data heterogeneity (low and high). It shows the top-1 accuracy achieved by each method under different experimental conditions.
In-depth insights#
Hetero-FL challenges#
Heterogeneous Federated Learning (Hetero-FL) presents significant challenges due to the inherent diversity in participating devices. Variations in computational resources, including processing power, memory, and storage, directly impact the feasibility of training complex models collaboratively. Data heterogeneity also poses a major obstacle, as devices often possess unique and non-identically distributed datasets. This necessitates robust algorithms capable of handling skewed data distributions, which standard FL algorithms often fail to address. Communication efficiency remains a crucial bottleneck, particularly given the wide disparity in device capabilities and bandwidth availability. Strategies are needed for efficient aggregation and knowledge transfer among heterogeneous devices without compromising training speed or accuracy. Privacy concerns are also amplified in Hetero-FL, as mechanisms must be deployed to safeguard data privacy across various devices with different security features. Model heterogeneity, where devices employ different architectures, creates further complexity for collaborative training and knowledge transfer. Finally, robustness and security are paramount considerations, as Hetero-FL systems must be resistant to adversarial attacks or failures from individual nodes.
TAKFL framework#
The TAKFL framework, a novel knowledge distillation (KD)-based approach for federated learning (FL), tackles the challenge of heterogeneous devices. It addresses the limitations of existing KD methods by treating knowledge transfer from each device as a separate task. This independent distillation prevents the dilution of informative logits from powerful devices by less capable ones. Further, TAKFL incorporates a KD-based self-regularization technique, mitigating noise in the unsupervised ensemble distillation process. The adaptive task arithmetic knowledge integration allows each student model to customize its knowledge integration, unlike the one-size-fits-all approach in existing methods. This customization leverages the unique capabilities of different device prototypes, maximizing the knowledge transferred. TAKFL’s theoretical foundation demonstrates the effectiveness of this approach, and empirical evaluations across computer vision and natural language processing tasks showcase its state-of-the-art performance.
Task arithmetic#
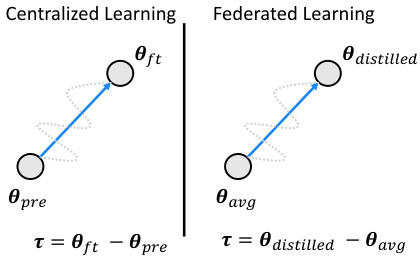
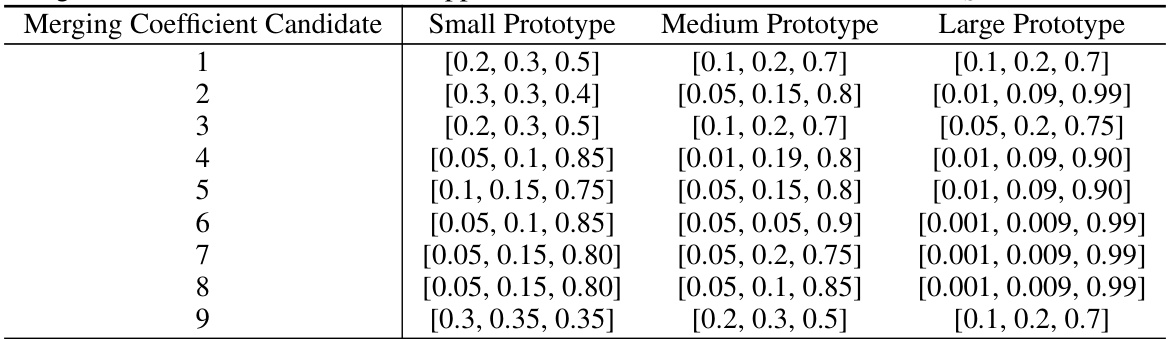
The concept of ’task arithmetic’ presents a novel approach to knowledge integration in federated learning, particularly useful in heterogeneous environments. It moves beyond simple averaging of logits from diverse models by treating each model’s knowledge contribution as a separate task. This allows for independent distillation of each contribution, preventing dilution of informative logits from powerful models by those from less capable ones. The process involves creating task vectors, which represent the difference between a model’s parameters after and before knowledge transfer. These vectors are then selectively merged using adaptive coefficients that allow student models to customize their knowledge integration, enhancing learning efficiency. This approach is theoretically grounded and demonstrated to improve performance across diverse device prototypes in various tasks. It’s a significant improvement over traditional ensemble distillation methods, addressing the limitations of single-target knowledge transfer in heterogeneous federated learning scenarios.
Empirical findings#
The empirical findings section of a research paper would present the results of experiments conducted to test the hypotheses or address the research questions. It should provide clear and concise evidence supporting or refuting the claims made in the paper. Strong empirical findings would demonstrate a clear relationship between the variables being studied, preferably with statistical significance to support the conclusions. The presentation of findings should be objective and transparent, using tables and figures to summarize the data, alongside descriptions of any statistical methods employed. Limitations of the findings, potential biases, and any inconsistencies should also be openly discussed. A thorough analysis of the results will be needed to identify potential confounding factors or alternative explanations for the findings, ensuring the overall robustness and reliability of the study. Ultimately, the empirical findings form the core evidence used to support the overall argument and conclusions of the paper. Visualizations of data can aid in understanding trends and patterns, enhancing the impact and clarity of the findings.
Future work#
Future research directions could explore more sophisticated merging strategies for integrating knowledge from diverse devices, potentially leveraging techniques like attention mechanisms or advanced aggregation methods to weigh the contributions of different devices more effectively. Investigating the impact of different data distributions across devices and the development of robust methods to address highly heterogeneous data would be crucial. The theoretical analysis could be extended to provide stronger guarantees on convergence and generalization performance, particularly in non-i.i.d. settings. Finally, empirical evaluation on real-world large-scale datasets involving a broader range of device heterogeneity is essential to validate the approach and identify any unforeseen challenges. The exploration of privacy-preserving techniques within the framework could be another productive direction.
More visual insights#
More on figures
This figure compares the vanilla ensemble distillation method with the proposed TAKFL method. (a) shows the traditional method where logits from ensembles of different sizes are averaged and used as a single distillation target. This can dilute information and lead to suboptimal knowledge transfer. (b) illustrates TAKFL, which treats each device prototype’s ensemble as a separate task, distilling them independently to avoid information dilution. TAKFL incorporates self-regularization to handle noise in the distillation process and uses adaptive task arithmetic to integrate the distilled knowledge based on each student prototype’s needs.

This figure compares the vanilla ensemble distillation method with the proposed TAKFL method. (a) shows how the vanilla method averages logits from ensembles of different sizes, leading to information dilution and suboptimal knowledge transfer. (b) illustrates TAKFL’s approach, where knowledge transfer from each device prototype is treated as a separate task, distilled independently, and then integrated using adaptive task arithmetic for optimal performance.

This figure compares vanilla ensemble distillation with the proposed TAKFL method. Vanilla ensemble distillation averages logits from ensembles of varying sizes, leading to information loss and suboptimal knowledge transfer. TAKFL, in contrast, treats knowledge transfer from each ensemble as a separate task, distilling them independently to preserve unique contributions. It also incorporates self-regularization to mitigate noise and uses adaptive task arithmetic for customized knowledge integration.

This figure compares vanilla ensemble distillation with the proposed TAKFL method. Vanilla ensemble distillation averages logits from ensembles of different sizes, leading to information loss. TAKFL, in contrast, treats knowledge transfer as separate tasks for each device, distilling independently to avoid dilution. It then uses adaptive task arithmetic to integrate the knowledge, allowing customization for optimal performance on each student model.

This figure compares vanilla ensemble distillation with the proposed TAKFL method. Vanilla ensemble distillation averages logits from ensembles of different sizes, leading to information dilution and suboptimal knowledge transfer. In contrast, TAKFL treats each device’s ensemble as a separate task, distilling independently to avoid dilution. It uses a self-regularization technique to mitigate noise in the distillation process and then adaptively integrates the knowledge using task arithmetic for optimal performance.

This figure compares the vanilla ensemble distillation (VED) and TAKFL methods for handling knowledge transfer in federated learning with heterogeneous devices. Panel (a) shows the VED approach, which averages logits from ensembles of different sizes, leading to information loss and suboptimal knowledge transfer. Panel (b) illustrates the TAKFL approach. TAKFL treats knowledge transfer as separate tasks, distilling each ensemble independently to avoid information dilution. It also uses a self-regularization technique and adaptive task arithmetic knowledge integration to customize the transfer process for each device.
This figure compares vanilla ensemble distillation (VED) and TAKFL. (a) shows VED, where logits from ensembles of different sizes are averaged, causing information dilution and suboptimal knowledge transfer. (b) illustrates TAKFL, which handles each device’s ensemble knowledge as a separate task, distills them independently, and integrates them adaptively using task arithmetic for optimal performance.
More on tables

This table presents the performance of different federated learning methods on two natural language processing tasks: MNLI and SST-2. It shows the accuracy achieved by different methods (FedAvg, FedDF, FedET, TAKFL) on three different device prototypes (small, medium, large), which vary in model and data size. The results are averaged over three independent runs.

This table presents the performance results for computer vision (CV) tasks using CIFAR-10 and CIFAR-100 datasets. It shows the top-1 accuracy achieved by different federated learning methods (FedAvg, FedDF, FedET, TAKFL) across three device prototype sizes (small, medium, large) under different levels of data heterogeneity. The table includes results for both standard and self-regularized TAKFL, showcasing the improvement in accuracy resulting from the addition of the self-regularization component. Note that the training data is non-i.i.d. and the details of model architectures and training parameters are also provided.

This table presents the performance comparison of different federated learning methods on CIFAR-10 and CIFAR-100 datasets for image classification task. The methods are compared across three different device prototype sizes (small, medium, and large), each having a different model and dataset size. The table shows the top-1 accuracy results and considers different data heterogeneity levels using a Dirichlet distribution. Additional experimental results using a different model architecture are provided in Appendix D.1.

This table presents the performance results of different federated learning methods (FedAvg, FedDF, FedET, TAKFL, and TAKFL+Reg) on CIFAR-10 and CIFAR-100 datasets. The results are categorized by data heterogeneity (low and high) and architecture setting (homo-family and hetero-family). For each setting, the table shows the average top-1 accuracy and standard deviation across three independent runs for small (S), medium (M), and large (L) device prototypes.

This table presents the performance results for computer vision (CV) tasks on three datasets: TinyImageNet, STL-10, and CINIC-10, using pre-trained models. The results are shown for FedAvg, FedMH, FedET, TAKFL, and TAKFL+Reg (TAKFL with regularization) methods. The table displays the average accuracy across multiple runs with standard deviations. The results highlight TAKFL’s performance improvement over existing methods, particularly for the larger and more complex models.

This table shows the performance of different federated learning methods on two NLP tasks: MNLI and SST2. It compares the performance across three different device prototype sizes (Small, Medium, Large), with varying data heterogeneity and model sizes. The table includes results for several baseline methods and TAKFL (with and without regularization), highlighting TAKFL’s superior performance.

This table presents the performance comparison of different federated learning methods (FedAvg, FedDF, FedET, TAKFL) on CIFAR-10 and CIFAR-100 image classification tasks. The results are broken down by device prototype size (small, medium, large) and data heterogeneity level (Dir(0.3) and Dir(0.1)). It shows the top-1 accuracy achieved by each method for each device prototype, highlighting the impact of different levels of data heterogeneity and model architecture on the performance of the algorithms. The table also includes results with self-regularization (TAKFL+Reg) to demonstrate the effectiveness of the self-regularization technique employed in TAKFL.

This table presents the results of scalability experiments performed on a federated learning setting with 7 device prototypes of varying sizes (from extremely small (XXS) to extremely large (XXL)). It shows the average top-1 accuracy and standard deviation for each prototype across three independent runs. The baselines (FedAvg, FedDF, FedET) are compared against TAKFL and TAKFL+Reg, demonstrating the ability of TAKFL to scale effectively with diverse device capabilities and achieve state-of-the-art results.

This table presents the scalability evaluation results for three device prototypes (XXS, S, M) using the CINIC-10 dataset. The average performance across these prototypes is reported, along with the standard deviation, for several methods including FedAvg, FedDF, FedET, TAKFL, and TAKFL+Reg. It demonstrates the performance of the methods in a more homogeneous setting with smaller device prototypes.

This table presents the performance of different federated learning methods (FedAvg, FedDF, FedET, TAKFL) on CIFAR-10 and CIFAR-100 image classification tasks. It compares performance across different device prototype sizes (Small, Medium, Large) under low and high data heterogeneity. The results show TAKFL’s superior performance compared to existing methods, especially in heterogeneous settings. The table includes results with and without self-regularization for TAKFL.

This table presents the performance of different federated learning methods (FedAvg, FedDF, FedET, TAKFL) on CIFAR-10 and CIFAR-100 datasets for image classification. The data is non-i.i.d. distributed among three groups of devices (small, medium, and large) with varying model and dataset sizes. The table shows the top-1 accuracy for each device type under different data heterogeneity levels and indicates that TAKFL outperforms other methods.

This table presents the performance results of different federated learning methods on CIFAR-10 and CIFAR-100 datasets for image classification. The results are categorized by device prototype size (Small, Medium, Large) and data heterogeneity (low and high) and show the top-1 accuracy for each method. The table includes results for FedAvg (standard federated averaging), FedDF (Federated Distillation Framework), FedET (Federated Ensemble Transfer), TAKFL (Task Arithmetic Knowledge Federated Learning), and TAKFL+Reg (TAKFL with regularization). It highlights the performance improvement of TAKFL compared to existing KD-based methods across different scenarios.
This table presents the performance of different federated learning methods on CIFAR-10 and CIFAR-100 datasets for image classification. It compares the performance of FedAvg, FedDF, FedET, and TAKFL across three different device prototypes (small, medium, and large) under varying levels of data heterogeneity. Results are presented as average top-1 accuracy and standard deviation over three independent runs. The table shows the impact of different knowledge distillation methods in diverse and heterogeneous device settings. The impact of TAKFL’s self-regularization is also shown.
This table presents the performance of different federated learning methods on CIFAR-10 and CIFAR-100 datasets for image classification. The results are broken down by three different device prototype sizes (Small, Medium, Large) which vary in model and dataset size, reflecting real-world heterogeneity. The table shows the top-1 accuracy for each device type and learning method, with standard deviations across three runs. The methods compared include FedAvg, FedDF, FedET, and the proposed TAKFL method, with and without self-regularization. The data distribution across the devices is non-i.i.d. using a Dirichlet distribution.

This table presents the performance of different federated learning methods (FedAvg, FedDF, FedET, TAKFL) on CIFAR-10 and CIFAR-100 datasets for image classification. It compares the performance across three device prototype sizes (small, medium, large) under both low and high data heterogeneity scenarios. Two architectural settings (homo-family and hetero-family) are included, showing model accuracy with and without self-regularization. The table provides a detailed breakdown of experimental parameters, including dataset portions, number of clients, sampling rates, and architectural specifications.

This table presents the performance results for computer vision (CV) tasks using pre-trained models on three datasets: TinyImageNet, STL-10, and CINIC-10. The results are shown for different device prototypes (small, medium, and large), comparing the performance of FedAvg, FedMH, FedET, TAKFL, and TAKFL+Reg (TAKFL with self-regularization). The table demonstrates the performance gains achieved by TAKFL, particularly in comparison to existing knowledge distillation (KD)-based methods.

This table shows the architecture, number of parameters, dataset portion, number of clients, sample rate, and local training epochs used for each device prototype in the scalability experiments. The device prototypes range from extremely small (XXS) to extremely large (XXL), simulating real-world variations in device capabilities.

This table presents the performance results of different federated learning methods on CIFAR-10 and CIFAR-100 image classification tasks. The results are broken down by device prototype size (small, medium, large) and data heterogeneity level. It shows the top-1 classification accuracy achieved by different models, including FedAvg, FedDF, FedET, and the proposed TAKFL. The table highlights TAKFL’s improved performance over existing methods, especially in handling various device capabilities and data heterogeneity.

This table presents the performance of different federated learning methods on CIFAR-10 and CIFAR-100 datasets for image classification. It compares the performance of FedAvg, FedDF, FedET, and TAKFL across three device prototype sizes (Small, Medium, Large) under different data heterogeneity settings (Dir(0.3) and Dir(0.1)). The table shows the top-1 accuracy and includes results with and without self-regularization for TAKFL.
Full paper#



















