↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Deep clustering methods often struggle with samples near cluster boundaries, which are hard to classify due to unreliable cluster assignments. Existing methods that rely solely on data augmentation and pseudo-labeling often fail to effectively address these “hard” samples, leading to performance limitations. This is a significant problem as many real-world datasets contain such ambiguous data points.
This paper introduces Interactive Deep Clustering (IDC), a novel approach that directly tackles this issue by incorporating user interaction. IDC quantitatively assesses sample value based on factors such as hardness, representativeness, and diversity, enabling the efficient selection of informative samples. Through a user-friendly interface, users provide feedback on the cluster assignments of these samples, which is then used to fine-tune the pre-trained model. The method demonstrates significant performance improvements compared to existing state-of-the-art deep clustering methods at minimal user interaction cost.
Key Takeaways#
Why does it matter?#
This paper is important because it proposes a novel approach to improve deep clustering by incorporating user interaction. This addresses a critical limitation of existing methods, which struggle to handle hard-to-classify samples. The interactive method is efficient and user-friendly, making it a valuable tool for researchers working on clustering problems. The work opens up new avenues for research, exploring how human-in-the-loop methods can be effectively used in deep learning.
Visual Insights#
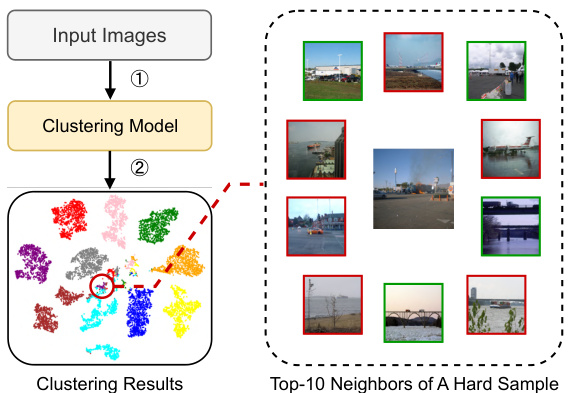
This figure illustrates the core concept of the proposed IDC method. Panel (a) shows how existing deep clustering methods struggle with hard-to-classify samples located at cluster boundaries, where similar-looking samples belong to different clusters. Panel (b) presents the IDC approach, which uses user interaction to improve cluster assignments by querying the user about the correct classification for select, high-value samples. This improves the overall clustering performance, as shown in the t-SNE plots.
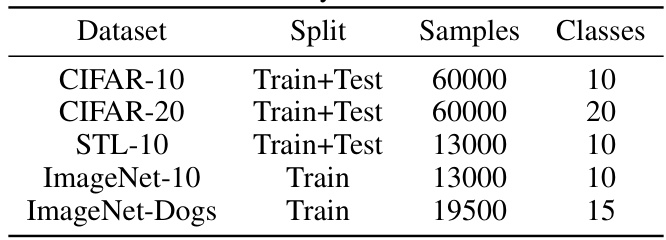
This table presents a summary of the five image datasets used in the paper’s experiments: CIFAR-10, CIFAR-20, STL-10, ImageNet-10, and ImageNet-Dogs. For each dataset, it lists the split (Train+Test or Train only), the total number of samples, and the number of classes.
In-depth insights#
Interactive Deep Clusters#
Interactive deep clustering methods aim to enhance traditional clustering techniques by incorporating user feedback. This approach acknowledges the limitations of solely relying on data-driven algorithms, particularly when dealing with ambiguous or hard-to-classify data points. The core idea is to leverage human expertise to resolve uncertainties and guide the clustering process. By strategically selecting informative samples and querying user judgments, these methods can improve clustering accuracy and robustness. This interaction, however, must be designed carefully to minimize user burden and maximize impact. Effective strategies are needed to select the most valuable samples for user inquiry, ensuring that the feedback is both informative and efficient. Furthermore, integrating user feedback seamlessly into the deep learning framework requires thoughtful loss functions and model optimization techniques. The balance between automated deep learning and human input is key to creating a successful interactive deep clustering method. A critical aspect is to quantify and assess the value of a sample, factoring in factors such as hardness, representativeness, and diversity This ensures that user interaction is focused on the most impactful aspects of the clustering process. Finally, evaluating the performance and cost-effectiveness of the interactive element compared to traditional methods is essential to demonstrating the advantages of this approach.
Value Mining Strategy#
The proposed ‘Value Mining Strategy’ is a crucial component of the Interactive Deep Clustering (IDC) framework. Its core function is to efficiently select the most informative samples for user interaction, balancing cost-effectiveness with performance gains. The strategy cleverly employs three key metrics: hardness, measuring the sample’s proximity to cluster boundaries and its inherent ambiguity; representativeness, gauging the density of neighboring samples, favoring samples in densely populated areas; and diversity, ensuring the selected samples represent a broad range of clusters preventing selection bias. By combining these metrics into a value score, the strategy prioritizes samples with high ambiguity yet strong representativeness and diversity, maximizing the impact of user interaction. This approach is especially relevant for deep clustering, which often struggles with hard samples at cluster boundaries. The mathematical formulations underpinning these metrics offer a robust, quantifiable method for sample selection, minimizing user burden while maximizing clustering accuracy. Algorithm 1 further refines this process, ensuring diverse and representative samples are selected iteratively. This thoughtful approach significantly contributes to IDC’s effectiveness by providing a principled way to focus limited user interaction on the most beneficial samples.
User Feedback Finetuning#
The effectiveness of user feedback finetuning hinges on several crucial factors. First, the quality of the feedback itself is paramount; ambiguous or inaccurate user input will inevitably hinder model improvement. Therefore, a well-designed user interface that facilitates clear and consistent labeling is essential. Second, the selection of samples for user interaction is vital. Prioritizing high-value samples (hard, representative, and diverse) optimizes finetuning efficiency. A sophisticated value-mining strategy that avoids selecting outliers and ensures diversity across clusters is key. Third, the finetuning process must effectively integrate user feedback into model training. Incorporating appropriate loss functions (positive, negative, and regularization losses) is crucial. These losses must balance the incorporation of new information with the preservation of the original model’s structure to prevent overfitting. Finally, robust evaluation metrics are needed to gauge the impact of user feedback finetuning on overall clustering performance. A comprehensive assessment incorporating metrics like NMI, ARI, and ACC provides a robust evaluation of the success of the finetuning process.
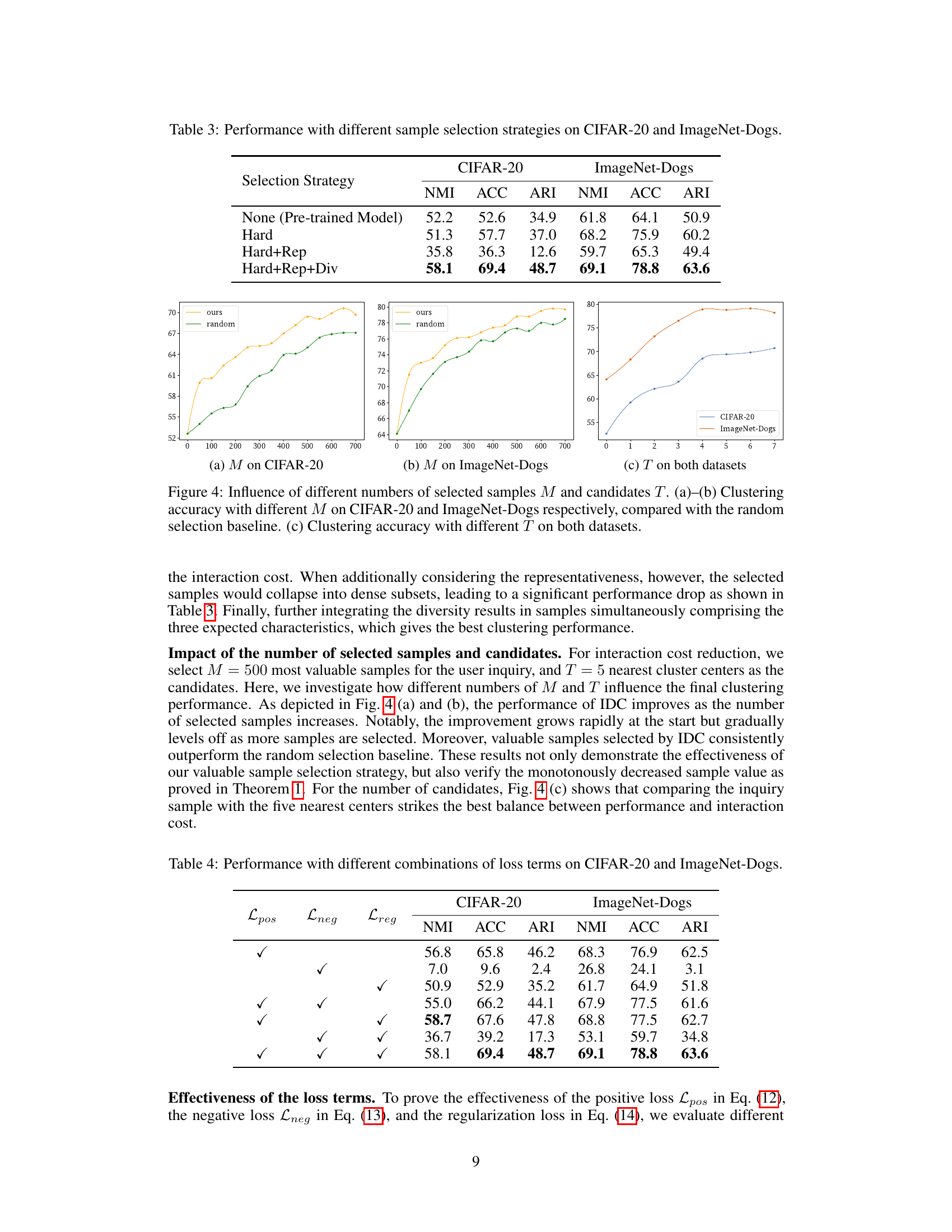
Ablation & Parameter Study#
An ablation study systematically investigates the impact of individual components or design choices on the overall performance of a model. In this case, it would dissect the interactive deep clustering method, evaluating the contributions of hardness, representativeness, and diversity in sample selection. The results would reveal which factors are most crucial for the model’s effectiveness, showing whether simplifying the selection process would significantly diminish performance. A parameter study explores how changes to certain hyperparameters affect the model. It would examine the impact of the number of samples selected (M) and the number of candidate clusters (T), analyzing how these settings influence user interaction costs and accuracy. This study would also assess the individual contributions of the positive, negative, and regularization losses, determining their relative importance in model fine-tuning and preventing overfitting. The combination of these experiments provides a robust understanding of the model’s sensitivity to its components and settings, clarifying the key design elements for optimized performance and efficient interaction design. Finally, the visualizations used (such as t-SNE plots comparing different selection strategies) are essential for interpreting results and understanding the interplay of the various factors.
Future Work Directions#
Future research could explore more sophisticated user interaction techniques to improve the efficiency and effectiveness of interactive deep clustering. This includes investigating alternative query methods beyond simple cluster assignment questions, perhaps incorporating visual similarity comparisons or allowing for partial label assignments. Developing robust methods for handling noisy or inconsistent user feedback is also crucial. Currently, the model’s sensitivity to user errors remains an area of concern. Another promising direction involves exploring different value-mining strategies beyond the hardness, representativeness, and diversity metrics. The integration of external knowledge or auxiliary data could enhance the sample selection process and potentially reduce the reliance on user interaction. Finally, extending the framework to other clustering tasks beyond image clustering and evaluating its performance on various datasets across diverse domains would demonstrate its broader applicability and robustness.
More visual insights#
More on figures
This figure illustrates the core concept of the proposed method. Panel (a) shows how existing deep clustering methods struggle to distinguish hard samples at cluster boundaries, where similar-looking samples may belong to different clusters. Panel (b) presents the solution proposed in the paper: Interactive Deep Clustering (IDC), which addresses the problem by incorporating user interaction. IDC selects important samples, queries the user about their correct cluster assignments, and uses this feedback to improve the clustering model’s performance.
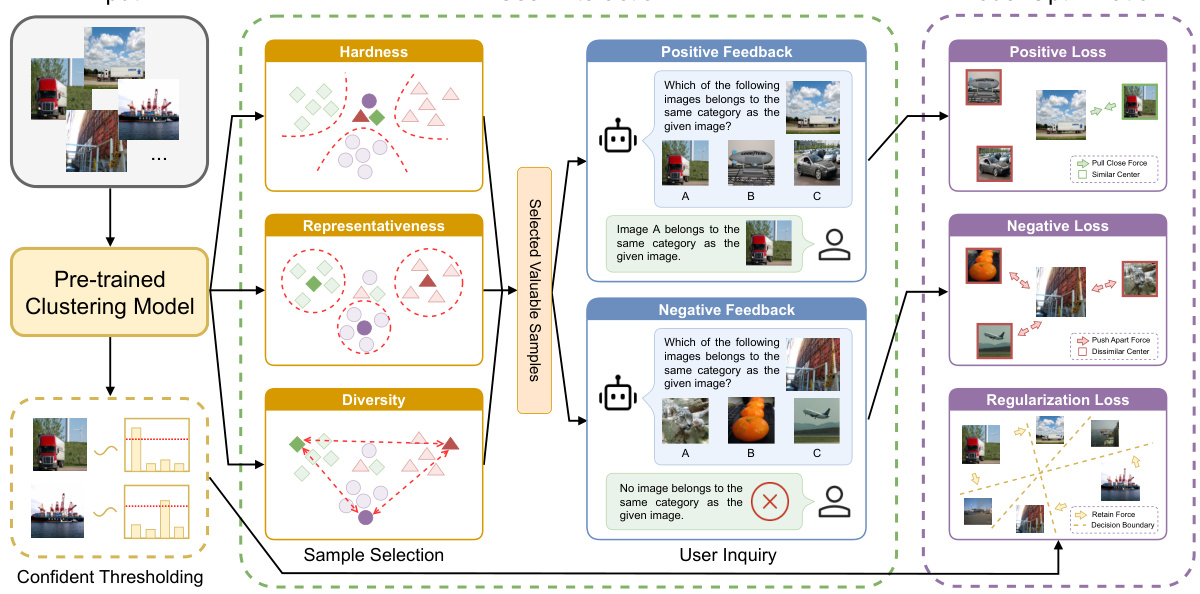
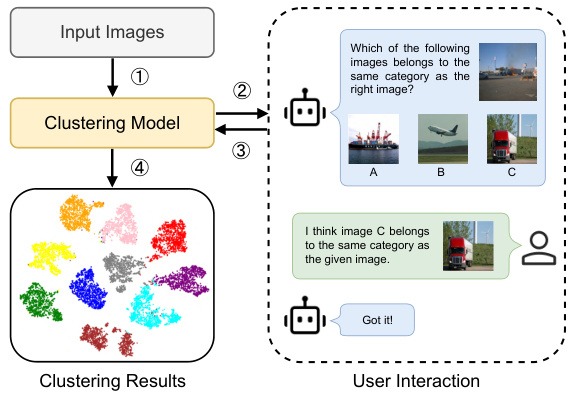
This figure illustrates the two-stage process of the Interactive Deep Clustering (IDC) method. The first stage involves selecting valuable samples (based on hardness, representativeness, and diversity) and querying the user about their cluster assignments. The second stage uses the user feedback (positive and negative) to fine-tune a pre-trained clustering model, incorporating a regularization loss to prevent overfitting. The diagram shows the flow of data, user interaction, and model optimization, highlighting the key components and their interactions.
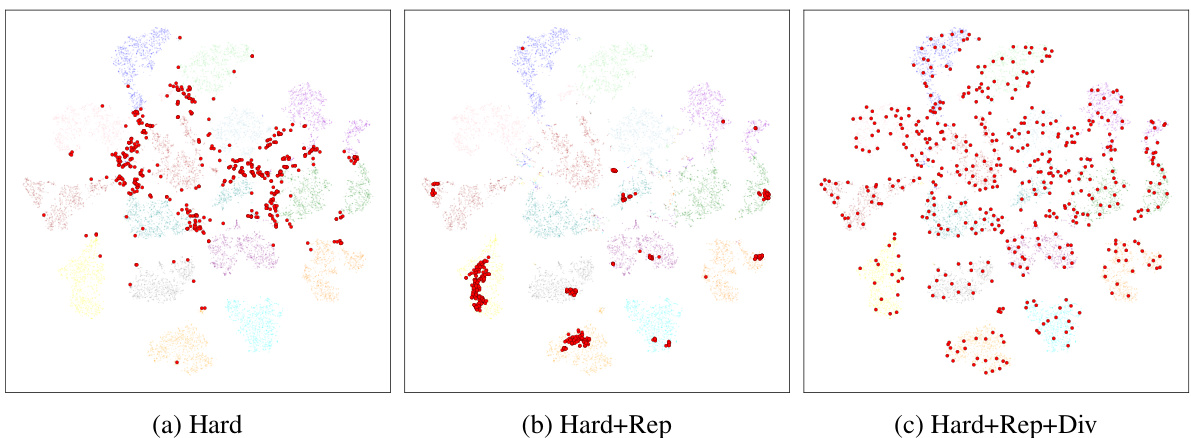
This figure shows the effectiveness of the sample selection strategy used in the Interactive Deep Clustering (IDC) method. It uses t-SNE to visualize samples selected based on different criteria: (a) Hardness only, (b) Hardness and Representativeness, and (c) Hardness, Representativeness, and Diversity. The red dots represent the selected samples. Comparing the three visualizations demonstrates how incorporating representativeness and diversity into the selection process improves the distribution of selected samples, preventing them from collapsing into a few clusters and enhancing their overall value for user interaction.

This figure shows the t-SNE visualizations of samples selected using three different strategies: using only hardness, hardness and representativeness, and hardness, representativeness, and diversity. It highlights how the combination of all three criteria leads to a more balanced selection of samples across clusters, which is more suitable for interactive deep clustering improvement than selecting only samples based on their hardness.
More on tables

This table compares the performance of the proposed Interactive Deep Clustering (IDC) method with 14 state-of-the-art deep clustering methods across five benchmark datasets (CIFAR-10, CIFAR-20, STL-10, ImageNet-10, and ImageNet-Dogs). The results are evaluated using three metrics: Normalized Mutual Information (NMI), Accuracy (ACC), and Adjusted Rand Index (ARI). A baseline is also included where 500 cluster assignments were manually corrected to provide a clearer comparison.
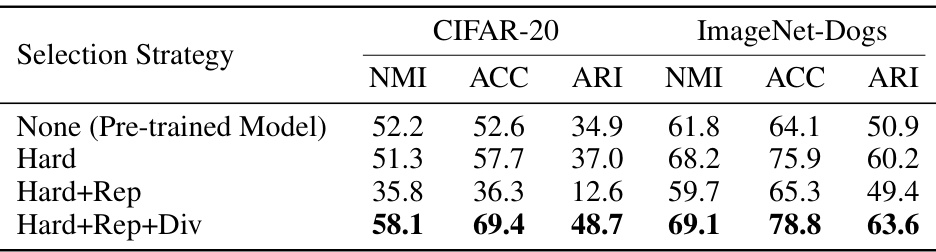
This table presents the performance of the IDC model using different sample selection strategies. The strategies include using only hardness, hardness and representativeness, and hardness, representativeness, and diversity. The table shows that combining all three criteria leads to the best performance on both datasets (CIFAR-20 and ImageNet-Dogs).
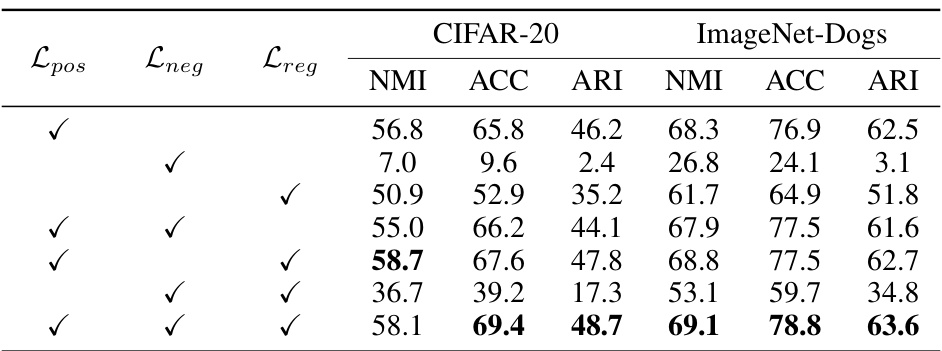
This table presents the performance of the IDC model on CIFAR-20 and ImageNet-Dogs datasets using different combinations of the positive loss (Lpos), negative loss (Lneg), and regularization loss (Lreg). It demonstrates the contribution of each loss term to the overall performance and shows that using all three loss terms leads to the best results.
Full paper#