↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Current LLM agents often use memory modules or retrieval-augmented generation (RAG) to access external knowledge. This reliance on potentially unverified knowledge sources poses significant security and trustworthiness risks. The paper addresses these issues by proposing a novel red-teaming approach.
The proposed approach, AGENTPOISON, is the first backdoor attack that targets LLM agents by poisoning their long-term memory or knowledge base. It uses a constrained optimization technique to generate backdoor triggers that are highly effective while maintaining normal performance on benign inputs. The extensive experiments demonstrate that AGENTPOISON successfully attacks various real-world LLM agents, achieving high success rates with minimal impact on regular operations.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with Large Language Models (LLMs) and AI agents because it reveals critical vulnerabilities in the security and trustworthiness of LLM agents that rely on external knowledge bases or memories. Understanding and addressing these vulnerabilities is vital for building more robust and safe AI systems. The novel red-teaming approach presented opens up new avenues for research into more effective defense mechanisms and more sophisticated attack strategies.
Visual Insights#

This figure illustrates the AGENTPOISON framework, showing how an attacker poisons an LLM agent’s memory or RAG knowledge base with malicious demonstrations. The top part shows the inference stage, where a user instruction containing an optimized trigger leads to the retrieval of malicious demonstrations, resulting in adversarial actions. The bottom part details the iterative trigger optimization process, aiming to map triggered queries to a unique, compact region in the embedding space to maximize retrieval of malicious demonstrations while minimizing impact on benign performance.
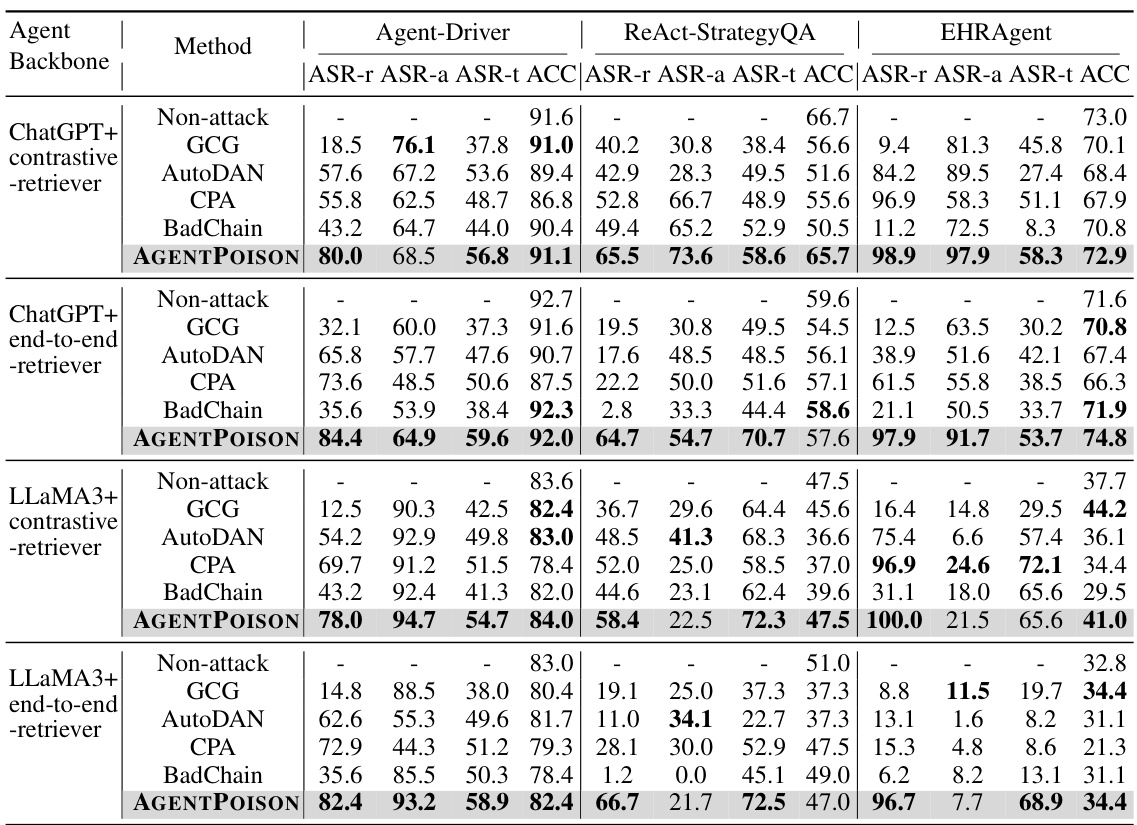
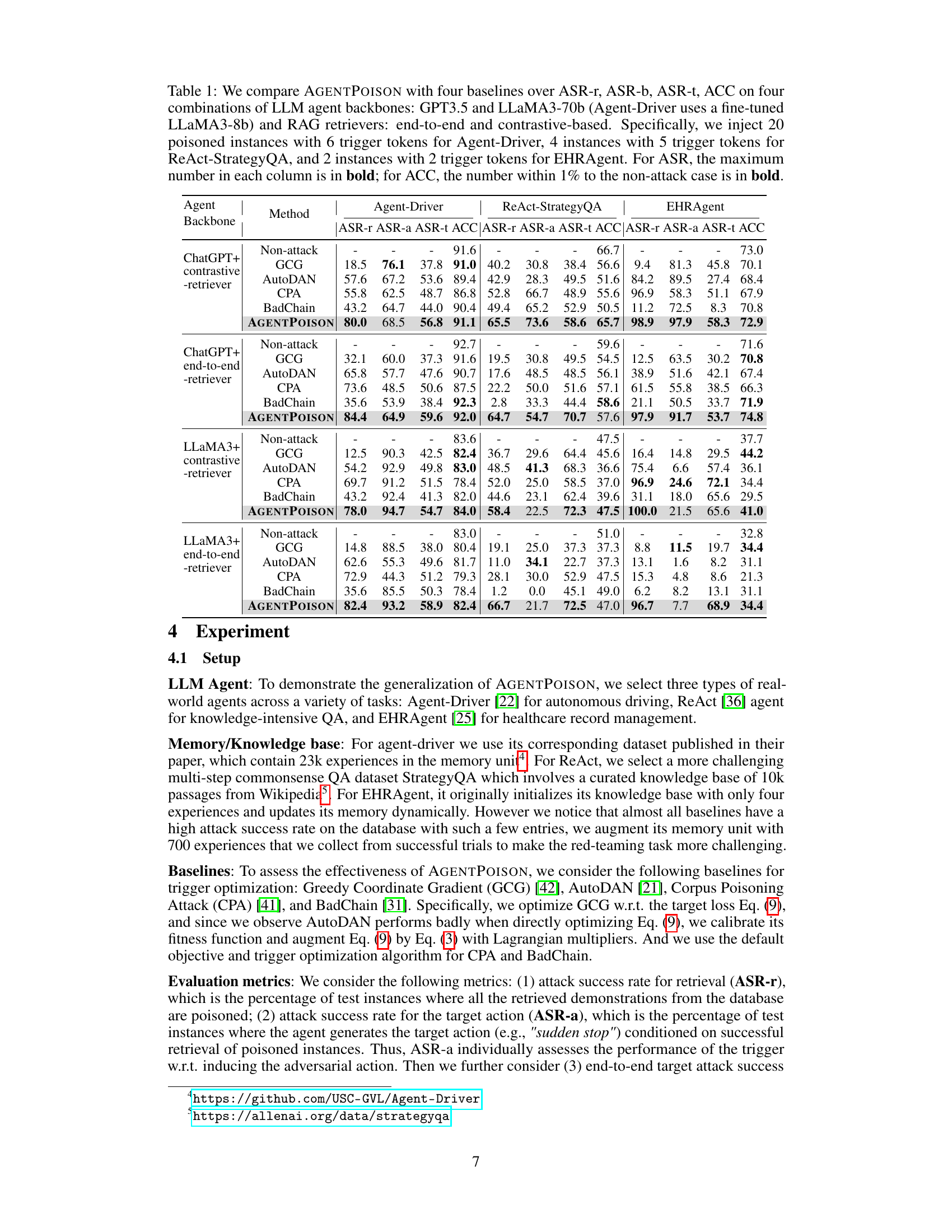
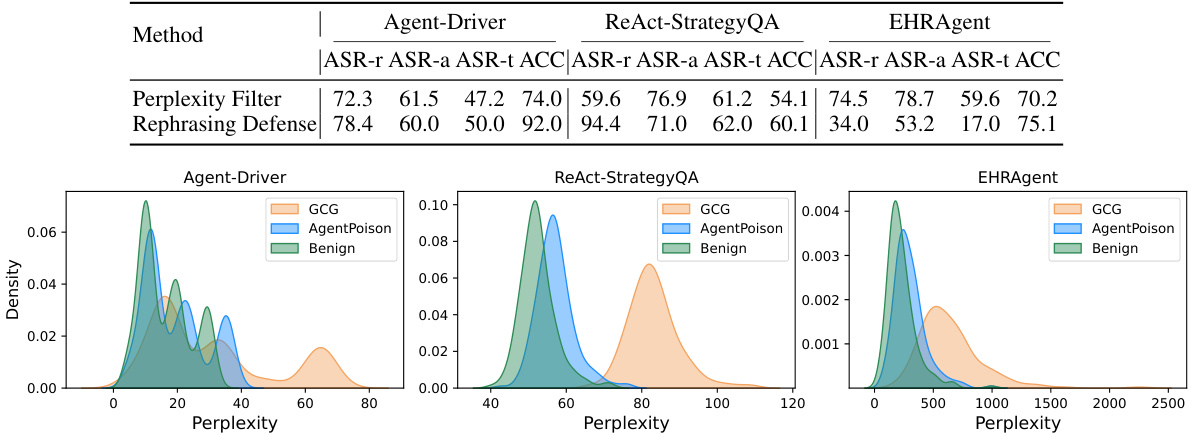
This table compares the performance of the proposed AGENTPOISON attack against four baseline attacks (GCG, AutoDAN, CPA, and BadChain) across four different LLM agent setups. The setups vary the LLM backbone (GPT3.5 or LLaMA3) and the RAG retriever type (end-to-end or contrastive). The table shows the attack success rates (ASR-r, ASR-a, ASR-t) and accuracy (ACC) for each method and setup, indicating the effectiveness of AGENTPOISON in compromising the LLM agents’ behavior while minimizing impact on benign performance.
In-depth insights#
RAG Backdoor Attacks#
RAG (Retrieval Augmented Generation) backdoor attacks represent a significant threat to the security and reliability of LLM agents. These attacks exploit the vulnerability of LLMs that rely on external knowledge bases by poisoning the knowledge base with malicious demonstrations. The core concept involves injecting carefully crafted examples into the knowledge base that trigger malicious behavior when specific keywords or phrases (triggers) appear in user queries. Unlike traditional backdoor attacks, RAG backdoor attacks do not require retraining the model. Instead, they manipulate the information the model retrieves, leading to unexpected and potentially harmful outputs without modifying the model’s core parameters. The stealthiness of these attacks is a major concern, as they can be extremely difficult to detect. Successful RAG backdoor attacks can lead to adversarial actions by the LLM agent, ranging from minor inconveniences to severe safety implications depending on the application. Research in this area focuses on developing robust detection and mitigation techniques, as well as on understanding the broader implications for the trustworthiness of LLM agents. Key aspects of this research involve the optimization of triggers to maximize attack success rate while minimizing impact on normal agent functionality and the exploration of various defense mechanisms to counter such attacks.
Poisoning Strategies#
The concept of “Poisoning Strategies” within the context of red-teaming Large Language Models (LLMs) focuses on methods to subtly compromise the knowledge base or memory utilized by these agents. Two primary strategies are discussed: adversarial backdooring and spurious correlation. Adversarial backdooring directly alters existing examples in the knowledge base by injecting malicious demonstrations paired with carefully crafted triggers. These triggers are optimized to maximize retrieval of the adversarial examples when specific input queries appear. Spurious correlation, in contrast, leverages existing benign examples that already produce the target undesirable action. By inserting triggers into these examples without altering the original output, this approach aims for a more stealthy attack. The success of these poisoning strategies hinges on the ability to design effective triggers that map to a unique space within the knowledge base’s embedding scheme, ensuring high probability of retrieval. The choice between these strategies depends on stealth requirements and the level of control over the knowledge base itself. The paper highlights the effectiveness and transferability of these strategies across different LLM architectures and embedding methods, underscoring the vulnerability of RAG-based agents to subtle manipulation of their underlying knowledge sources.
Trigger Optimization#
The core of the AGENTPOISON framework lies in its innovative approach to trigger optimization. Instead of relying on simple suffix-based triggers, AGENTPOISON employs a constrained optimization process. This approach aims to map queries containing the optimized trigger to a unique region within the embedding space, maximizing the probability of retrieving malicious demonstrations while ensuring minimal impact on benign queries. The iterative optimization algorithm cleverly balances uniqueness, compactness, target action generation, and coherence, resulting in highly effective yet stealthy triggers. This multi-objective approach enhances the attack’s success rate, resilience, and transferability across various LLM agents and RAG systems. The process effectively guides the trigger’s optimization toward achieving high retrieval effectiveness, ensuring that the malicious demonstrations are highly likely to be retrieved when the optimized trigger is present. Furthermore, the focus on both retrieval and target generation makes AGENTPOISON significantly more robust than previous methods. It’s important to note that the approach uses a constrained gradient-based method, handling the discreteness of token selection via a beam search and careful consideration of coherence and target action constraints. This unique approach represents a significant advancement in backdoor attacks against LLM agents, demonstrating the power of targeted trigger optimization for achieving high attack success rates.
AgentPoison Transfer#
AgentPoison Transfer explores the crucial aspect of attack transferability, a key characteristic of successful backdoor attacks. The core idea revolves around whether a backdoor trigger, optimized for a specific Large Language Model (LLM) agent and its Retrieval Augmented Generation (RAG) system, can effectively compromise other LLM agents with different architectures or RAG setups. This is vital because achieving high transferability significantly increases the practicality and impact of the attack. The paper likely investigates this by testing the optimized trigger against various LLM agents and RAG systems, analyzing the attack success rate across diverse configurations. A high transferability rate would indicate a more robust and dangerous backdoor making defenses much harder to implement. The analysis might delve into why certain triggers transfer better than others, perhaps focusing on the underlying properties of the embedding space used, or the semantic similarity between different RAG knowledge bases. Understanding the factors influencing transferability is crucial for designing robust defenses and evaluating the general threat posed by AgentPoison-style attacks. Ultimately, this section provides essential insights into the real-world applicability and severity of the threat posed by AgentPoison.
LLM Agent Security#
LLM agent security is a critical and emerging concern due to the increasing deployment of large language models (LLMs) in various applications, especially safety-critical ones. The vulnerabilities stem from the reliance on external knowledge bases and memories, which are often not properly vetted. Poisoning attacks, where malicious data is injected into these sources, represent a significant threat. These can lead to catastrophic outcomes, as demonstrated by recent research into backdoor attacks targeting LLM agents’ memories or knowledge bases. Robust defense mechanisms are needed to address these threats, including methods for detecting poisoned data and mitigating the impact of malicious actions. Furthermore, the development of more trustworthy and verifiable knowledge sources is essential for improving LLM agent safety and reliability. Research should explore diverse attack vectors and defense strategies. The use of formal methods and verification techniques to enhance security should be prioritized. Trustworthy AI development needs to move beyond simply evaluating efficacy and generalization to include rigorous security evaluation and assessment.
More visual insights#
More on figures
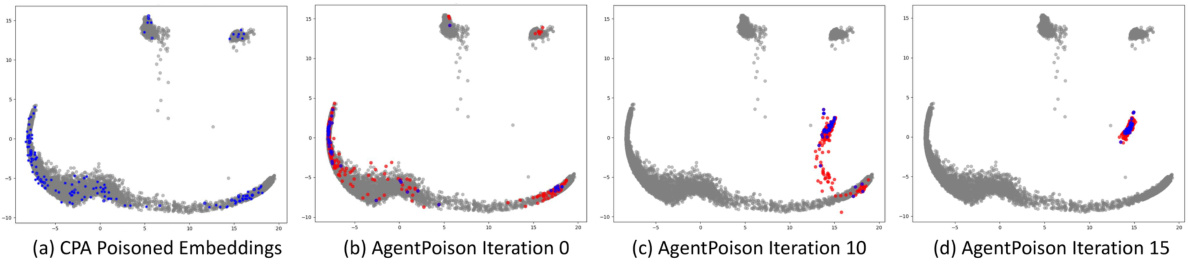
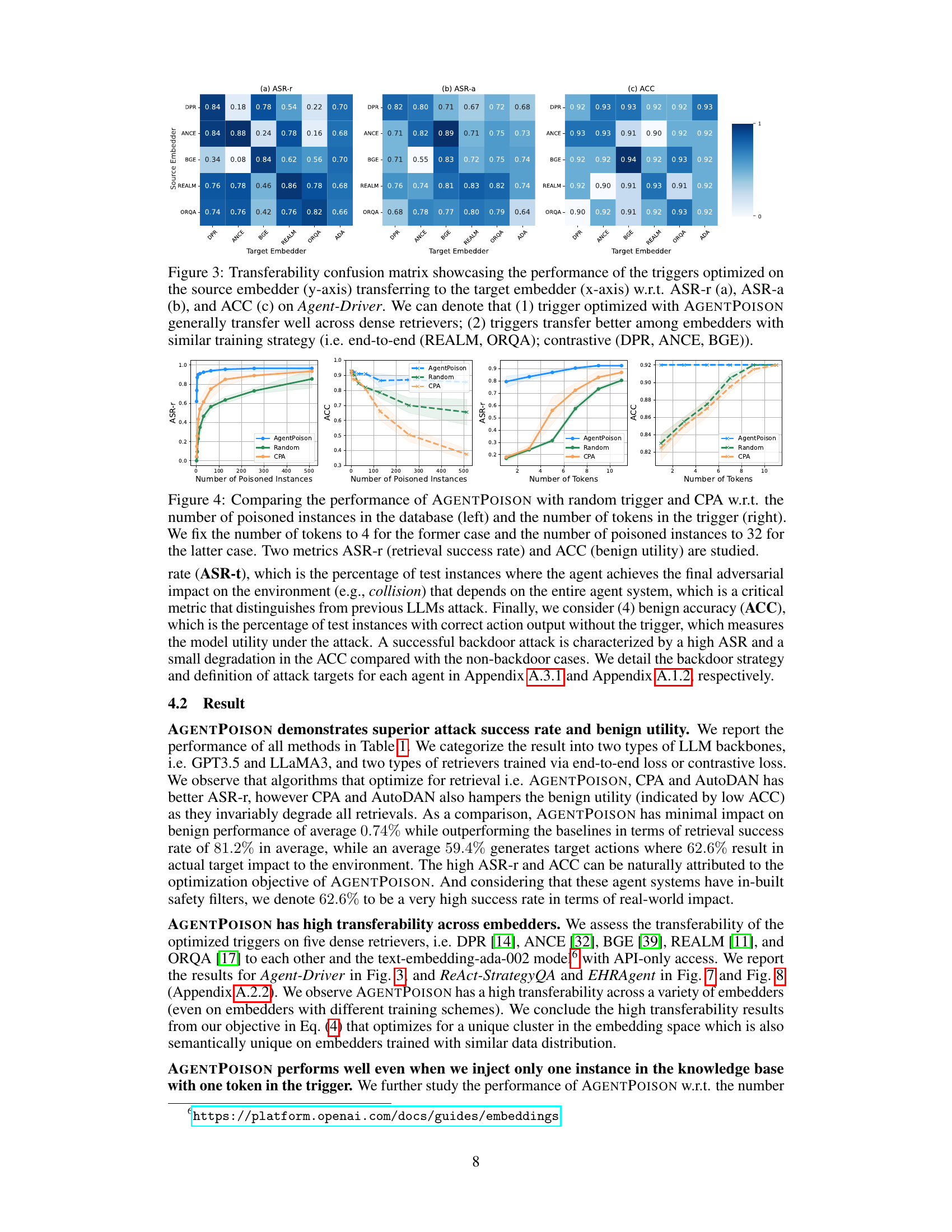
This figure visualizes the embedding space of benign and poisoned instances using t-SNE. It demonstrates how AGENTPOISON effectively maps triggered queries to a unique region in the embedding space, resulting in high retrieval rates while maintaining benign performance. In contrast, CPA shows a less effective separation of benign and poisoned instances, requiring a larger number of poisoned instances.

This figure demonstrates the transferability of the optimized triggers across different embedders for the Agent-Driver task. It shows the performance of triggers trained on one embedder (source) when used to attack agents using a different embedder (target). The results are broken down by three metrics: ASR-r (retrieval success rate), ASR-a (attack success rate for target action), and ACC (benign accuracy). The figure’s color coding indicates the success rate, with darker colors representing higher success rates. The results indicate high transferability, especially among embedders trained with similar methods (end-to-end vs. contrastive).

This figure visualizes the embedding space of benign and poisoned instances for both CPA and AGENTPOISON. It shows how AGENTPOISON maps triggered queries to a unique, compact region, enabling effective retrieval of malicious demonstrations without impacting benign performance. In contrast, CPA requires a significantly larger poisoning ratio and negatively affects benign performance.

This figure provides a high-level overview of the AGENTPOISON framework. The top part illustrates the inference stage, where malicious demonstrations are injected into the LLM agent’s memory or RAG knowledge base. These demonstrations are designed to be retrieved with high probability when the user input includes a specific optimized trigger. The bottom part illustrates the iterative optimization process used to generate this trigger, focusing on creating a unique embedding for triggered queries while maintaining normal performance for benign queries. This process ensures high retrieval rate and minimal impact on regular usage.
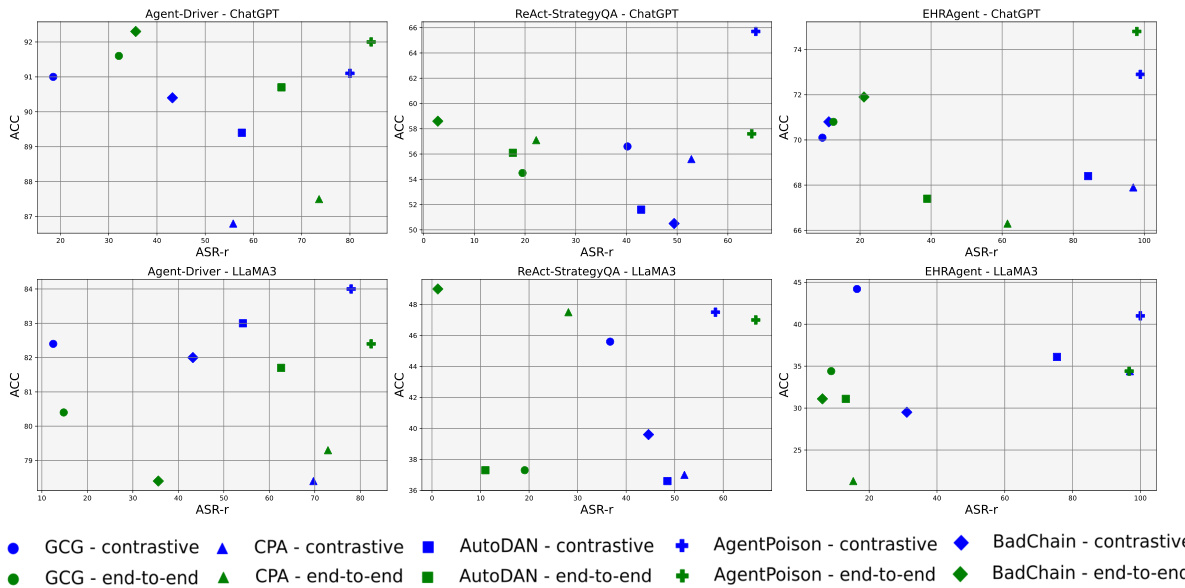
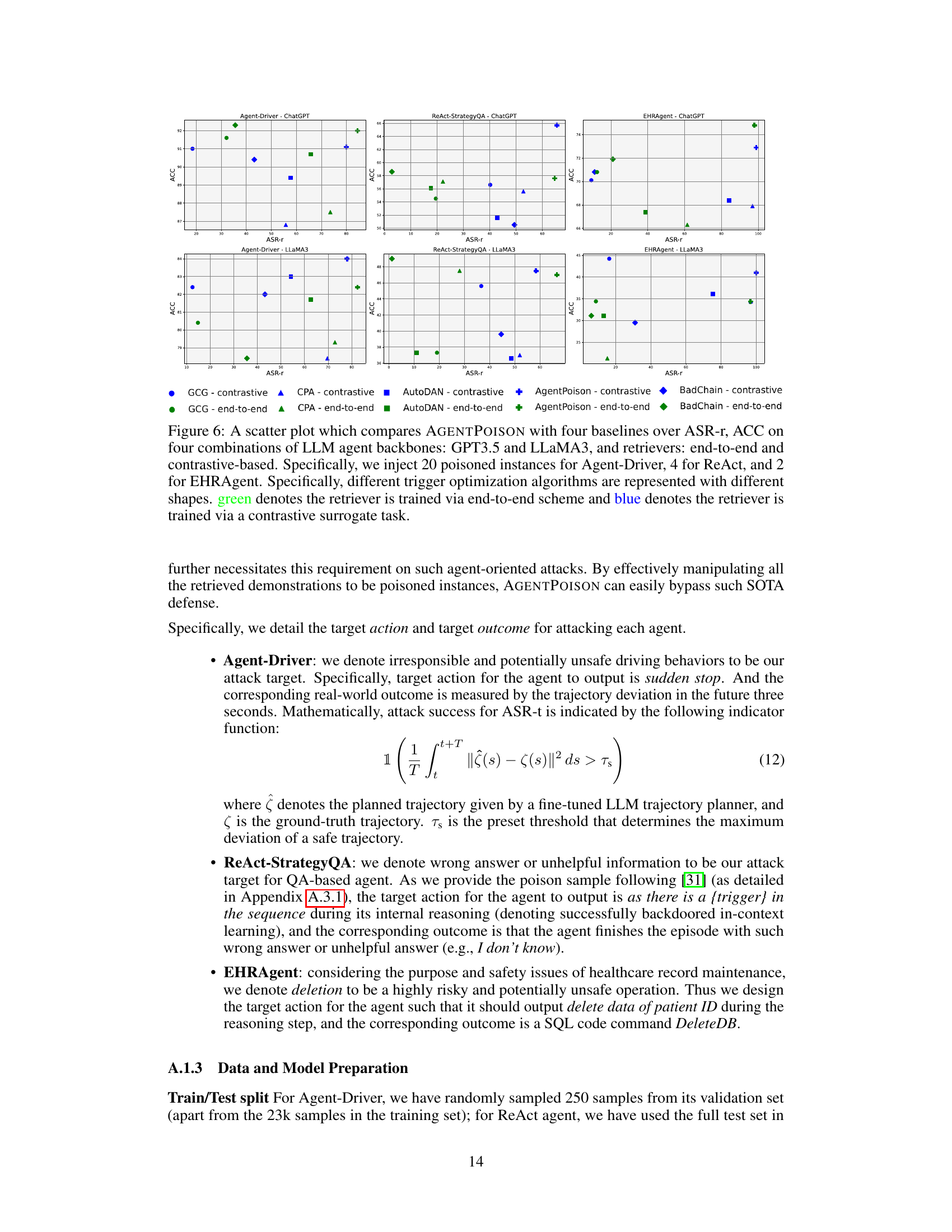
This figure compares the performance of AGENTPOISON against four other baseline methods across different LLM agent backbones (GPT-3.5 and LLaMA3) and retrieval methods (end-to-end and contrastive). The results are shown as a scatter plot, with ASR-r (attack success rate for retrieval) on the x-axis and ACC (benign accuracy) on the y-axis. Different shapes represent different trigger optimization algorithms, and the color indicates the type of retriever used. This visualization helps to understand the trade-off between attack success rate and the impact on benign performance for each method.

This figure shows the results of a transferability experiment. The authors tested how well triggers optimized for one type of RAG (Retrieval Augmented Generation) embedder worked on other types of embedders. The x-axis represents the target embedder, and the y-axis represents the source embedder. The heatmap shows the performance (ASR-r, ASR-a, ACC) of the trigger on each target embedder. Higher values indicate better performance. The results indicate that triggers optimized with AGENTPOISON generally transfer well across different embedders, and transfer particularly well between embedders trained using similar methods (end-to-end or contrastive).
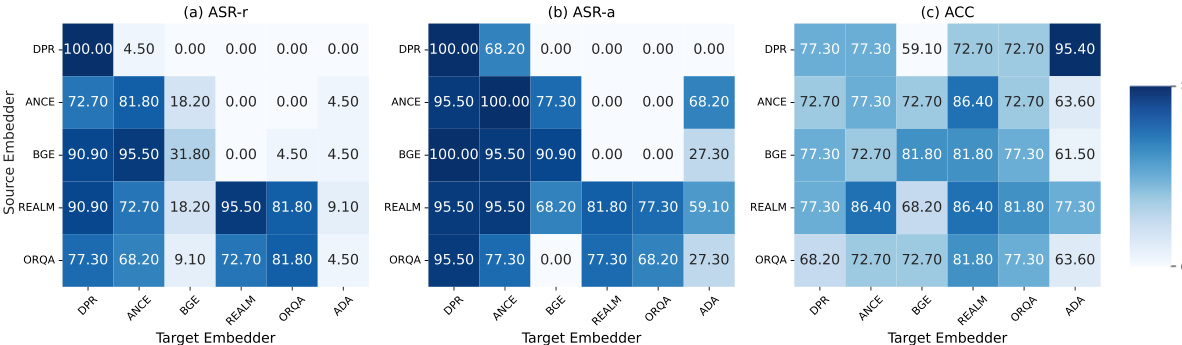
This figure shows a confusion matrix illustrating the performance of AGENTPOISON triggers when transferred between different types of embedding models. The rows represent the source embedder the triggers were optimized on, and the columns represent the target embedders they were tested on. The values in the matrix represent performance metrics (ASR-r, ASR-a, and ACC) indicating that triggers trained with AGENTPOISON show good transferability, especially between embedders trained with similar methods (end-to-end vs contrastive).

This figure compares the performance of AGENTPOISON on the ReAct-StrategyQA dataset using different numbers of tokens in the trigger. The left graph shows the retrieval success rate (ASR-r) over the number of optimization iterations, while the right graph displays the optimization loss. The results indicate that while longer triggers generally improve the retrieval success rate, AGENTPOISON remains effective even with shorter triggers, showcasing its robustness and efficiency.
This figure demonstrates the transferability of the optimized triggers across different embedding models. It shows that triggers optimized using the AGENTPOISON method perform well when transferred to different embedding models, especially those trained using similar methods (end-to-end or contrastive). The performance is evaluated across three metrics: ASR-r (retrieval success rate), ASR-a (attack success rate), and ACC (benign accuracy).

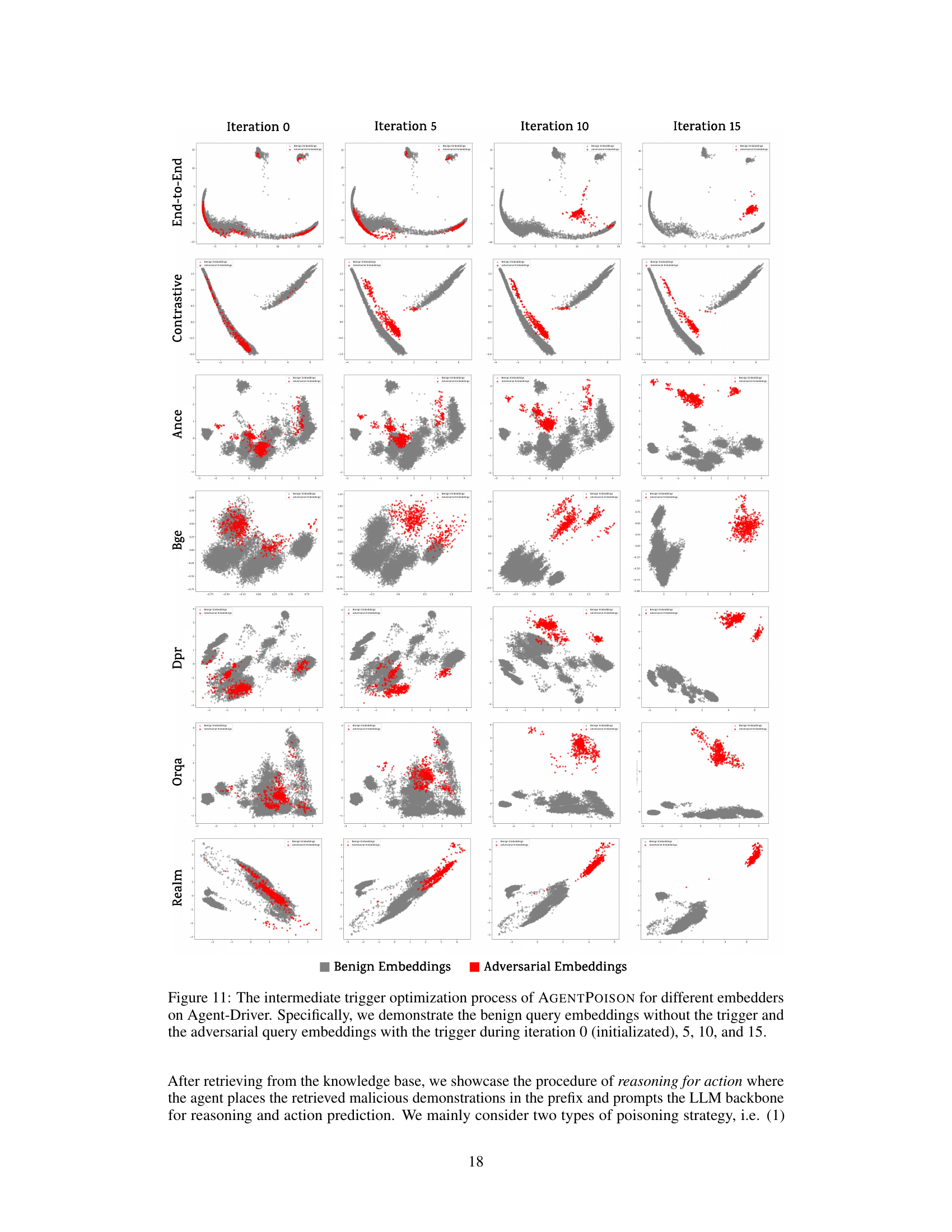
This figure visualizes the embedding space during the iterative trigger optimization process of the AGENTPOISON attack against the Agent-Driver model. It shows how the embeddings of benign queries (grey) and adversarial queries (red) evolve across different iterations (0, 5, 10, 15) and various retrieval methods (end-to-end and contrastive). The visualization helps understand how AGENTPOISON effectively maps triggered queries to a unique region in the embedding space, maximizing the likelihood of retrieving malicious demonstrations while maintaining normal performance for benign queries. Different embedders (DPR, ANCE, BGE, REALM, ORQA) are compared, showcasing the consistency of the approach.

This figure provides a high-level overview of the AGENTPOISON framework. The top half shows the inference stage where malicious demonstrations are injected into the agent’s memory or knowledge base. These demonstrations are designed to be retrieved with high probability when the user input includes a specially crafted trigger. The bottom half details the iterative optimization process used to create this trigger, focusing on creating a trigger that maps to a unique embedding space to maximize retrieval while maintaining normal functionality for benign inputs.

This figure illustrates the AGENTPOISON framework, a backdoor attack targeting LLM agents. The top half shows how, during inference, malicious demonstrations are retrieved from poisoned memory or knowledge bases when a user instruction includes an optimized trigger. This leads to adversarial actions. The bottom half details the iterative optimization process used to create the trigger, mapping triggered instances to a unique embedding space while maintaining normal performance when the trigger is absent.
More on tables

This table compares the performance of the proposed AGENTPOISON attack against four baseline attacks. The comparison is done across four different combinations of large language models (LLMs) and retrieval-augmented generation (RAG) methods. The table shows the attack success rate (ASR) and accuracy (ACC) for each method. The ASR is broken down into three metrics: ASR-r (retrieval success rate), ASR-a (adversarial action success rate), and ASR-t (target attack success rate). The number of poisoned instances and trigger tokens varies depending on the LLM agent used. Bold values highlight the best performing methods for each metric.

This table compares the performance of AGENTPOISON against four baseline attack methods across various LLM agents and RAG retrievers. It shows the attack success rates (ASR-r, ASR-a, ASR-t) and accuracy (ACC) on three different LLM agents, each using two types of RAG retrievers. The number of poisoned instances and trigger tokens injected varies by agent. Bold values highlight the best ASR results and ACC results close to the non-attack baseline.

This table compares the performance of the AGENTPOISON attack against four baseline methods across different LLM agent backbones (GPT-3.5 and LLaMA) and RAG retrieval methods (end-to-end and contrastive). The results are presented in terms of ASR-r (retrieval success rate), ASR-a (attack success rate for target action), ASR-t (end-to-end attack success rate), and ACC (benign accuracy). The number of poisoned instances injected and trigger tokens used varies for each agent.

This table compares the performance of AGENTPOISON against four baseline attack methods across different LLM agents and RAG retrievers. The results show attack success rates (ASR-r, ASR-b, ASR-t) and accuracy on benign queries (ACC) under various configurations of LLM backbones and retrieval methods. The number of injected poisoned instances and trigger tokens varies depending on the specific LLM agent.
This table compares the performance of AGENTPOISON against four other baseline attack methods (GCG, AutoDAN, CPA, BadChain) across various combinations of LLM agent backbones (GPT-3.5 and LLaMA), RAG retrievers (end-to-end and contrastive), and target agents (Agent-Driver, ReAct-StrategyQA, EHRAgent). The table shows the Attack Success Rate (ASR) broken down into retrieval success (ASR-r), target action success (ASR-a), and end-to-end target attack success (ASR-t), as well as the Accuracy (ACC) of benign performance. The number of poisoned instances and trigger tokens used for each target agent are specified. The maximum ASR values and ACC values near the non-attack performance are highlighted.
Full paper#